MATLAB實現隨機森林(RF)迴歸與自變數影響程度分析
本文介紹基於MATLAB,利用隨機森林(RF)演演算法實現迴歸預測,以及自變數重要性排序的操作。
本文分為兩部分,首先是對程式碼進行分段、詳細講解,方便大家理解;隨後是完整程式碼,方便大家自行嘗試。另外,關於基於MATLAB的神經網路(ANN)程式碼與詳細解釋,我們將在後期部落格中介紹。
1 分解程式碼
1.1 最優葉子節點數與樹數確定
首先,我們需要對RF對應的葉子節點數與樹的數量加以擇優選取。
%% Number of Leaves and Trees Optimization
for RFOptimizationNum=1:5
RFLeaf=[5,10,20,50,100,200,500];
col='rgbcmyk';
figure('Name','RF Leaves and Trees');
for i=1:length(RFLeaf)
RFModel=TreeBagger(2000,Input,Output,'Method','R','OOBPrediction','On','MinLeafSize',RFLeaf(i));
plot(oobError(RFModel),col(i));
hold on
end
xlabel('Number of Grown Trees');
ylabel('Mean Squared Error') ;
LeafTreelgd=legend({'5' '10' '20' '50' '100' '200' '500'},'Location','NorthEast');
title(LeafTreelgd,'Number of Leaves');
hold off;
disp(RFOptimizationNum);
end
其中,RFOptimizationNum是為了多次迴圈,防止最優結果受到隨機干擾;大家如果不需要,可以將這句話刪除。
RFLeaf定義初始的葉子節點個數,我這裡設定了從5到500,也就是從5到500這個範圍內找到最優葉子節點個數。
Input與Output分別是我的輸入(自變數)與輸出(因變數),大家自己設定即可。
執行後得到下圖。
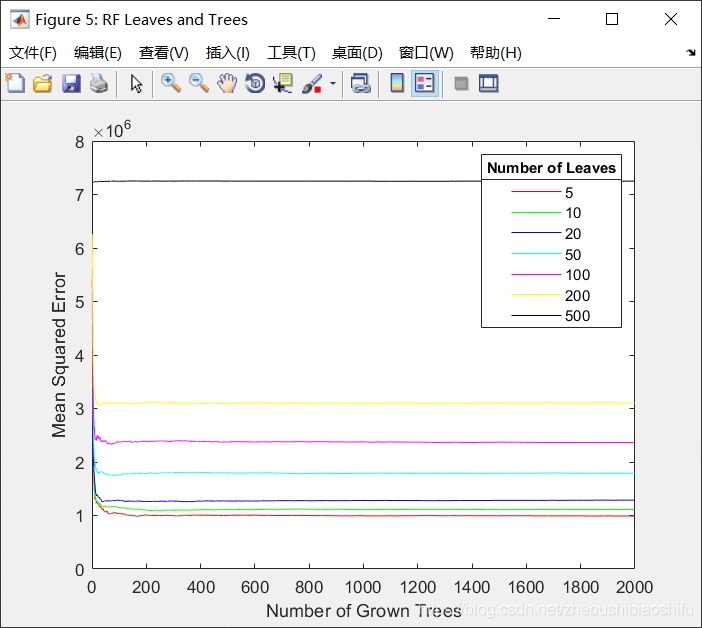
首先,我們看到MSE最低的線是紅色的,也就是5左右的葉子節點數比較合適;再看各個線段大概到100左右就不再下降,那麼樹的個數就是100比較合適。
1.2 迴圈準備
由於機器學習往往需要多次執行,我們就在此先定義迴圈。
%% Cycle Preparation
RFScheduleBar=waitbar(0,'Random Forest is Solving...');
RFRMSEMatrix=[];
RFrAllMatrix=[];
RFRunNumSet=10;
for RFCycleRun=1:RFRunNumSet
其中,RFRMSEMatrix與RFrAllMatrix分別用來存放每一次執行的RMSE、r結果,RFRunNumSet是迴圈次數,也就是RF執行的次數。
1.3 資料劃分
接下來,我們需要將資料劃分為訓練集與測試集。這裡要注意:RF其實一般並不需要劃分訓練集與測試集,因為其可以採用袋外誤差(Out of Bag Error,OOB Error)來衡量自身的效能。但是因為我是做了多種機器學習方法的對比,需要固定訓練集與測試集,因此就還進行了資料劃分的步驟。
%% Training Set and Test Set Division
RandomNumber=(randperm(length(Output),floor(length(Output)*0.2)))';
TrainYield=Output;
TestYield=zeros(length(RandomNumber),1);
TrainVARI=Input;
TestVARI=zeros(length(RandomNumber),size(TrainVARI,2));
for i=1:length(RandomNumber)
m=RandomNumber(i,1);
TestYield(i,1)=TrainYield(m,1);
TestVARI(i,:)=TrainVARI(m,:);
TrainYield(m,1)=0;
TrainVARI(m,:)=0;
end
TrainYield(all(TrainYield==0,2),:)=[];
TrainVARI(all(TrainVARI==0,2),:)=[];
其中,TrainYield是訓練集的因變數,TrainVARI是訓練集的自變數;TestYield是測試集的因變數,TestVARI是測試集的自變數。
因為我這裡是做估產迴歸的,因此變數名稱就帶上了Yield,大家理解即可。
1.4 隨機森林實現
這部分程式碼其實比較簡單。
%% RF
nTree=100;
nLeaf=5;
RFModel=TreeBagger(nTree,TrainVARI,TrainYield,...
'Method','regression','OOBPredictorImportance','on', 'MinLeafSize',nLeaf);
[RFPredictYield,RFPredictConfidenceInterval]=predict(RFModel,TestVARI);
其中,nTree、nLeaf就是本文1.1部分中我們確定的最優樹個數與最優葉子節點個數,RFModel就是我們所訓練的模型,RFPredictYield是預測結果,RFPredictConfidenceInterval是預測結果的置信區間。
1.5 精度衡量
在這裡,我們用RMSE與r衡量模型精度。
%% Accuracy of RF
RFRMSE=sqrt(sum(sum((RFPredictYield-TestYield).^2))/size(TestYield,1));
RFrMatrix=corrcoef(RFPredictYield,TestYield);
RFr=RFrMatrix(1,2);
RFRMSEMatrix=[RFRMSEMatrix,RFRMSE];
RFrAllMatrix=[RFrAllMatrix,RFr];
if RFRMSE<400
disp(RFRMSE);
break;
end
disp(RFCycleRun);
str=['Random Forest is Solving...',num2str(100*RFCycleRun/RFRunNumSet),'%'];
waitbar(RFCycleRun/RFRunNumSet,RFScheduleBar,str);
end
close(RFScheduleBar);
在這裡,我定義了當RMSE滿足<400這個條件時,模型將自動停止;否則將一直執行到本文1.2部分中我們指定的次數。其中,模型每一次執行都會將RMSE與r結果記錄到對應的矩陣中。
1.6 變數重要程度排序
接下來,我們結合RF演演算法的一個功能,對所有的輸入變數進行分析,去獲取每一個自變數對因變數的解釋程度。
%% Variable Importance Contrast
VariableImportanceX={};
XNum=1;
% for TifFileNum=1:length(TifFileNames)
% if ~(strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeArea') | ...
% strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeYield'))
% eval(['VariableImportanceX{1,XNum}=''',TifFileNames(TifFileNum).name(4:end-4),''';']);
% XNum=XNum+1;
% end
% end
for i=1:size(Input,2)
eval(['VariableImportanceX{1,XNum}=''',i,''';']);
XNum=XNum+1;
end
figure('Name','Variable Importance Contrast');
VariableImportanceX=categorical(VariableImportanceX);
bar(VariableImportanceX,RFModel.OOBPermutedPredictorDeltaError)
xtickangle(45);
set(gca, 'XDir','normal')
xlabel('Factor');
ylabel('Importance');
這裡程式碼就不再具體解釋了,大家會得到一幅圖,是每一個自變數對因變數的重要程度,數值越大,重要性越大。
其中,我註釋掉的這段是依據我當時的資料情況來的,大家就不用了。
更新:這裡請大家注意,上述程式碼中我註釋掉的內容,是依據每一幅影象的名稱對重要性排序的X軸(也就是VariableImportanceX)加以註釋(我當時做的是依據遙感影象估產,因此每一個輸入變數的名稱其實就是對應的影象的名稱),所以使得得到的變數重要性柱狀圖的X軸會顯示每一個變數的名稱。大家用自己的資料來跑的時候,可以自己設定一個變數名稱的欄位元胞然後放到VariableImportanceX,然後開始figure繪圖;如果在輸入資料的特徵個數(也就是列數)比較少的時候,也可以用我上述程式碼中間的這個for i=1:size(Input,2)迴圈——這是一個偷懶的辦法,也就是將重要性排序圖的X軸中每一個變數的名稱顯示為一個正方形,如下圖紅色圈內。這裡比較複雜,因此如果大家這一部分沒有搞明白或者是一直報錯,在本文下方直接留言就好~
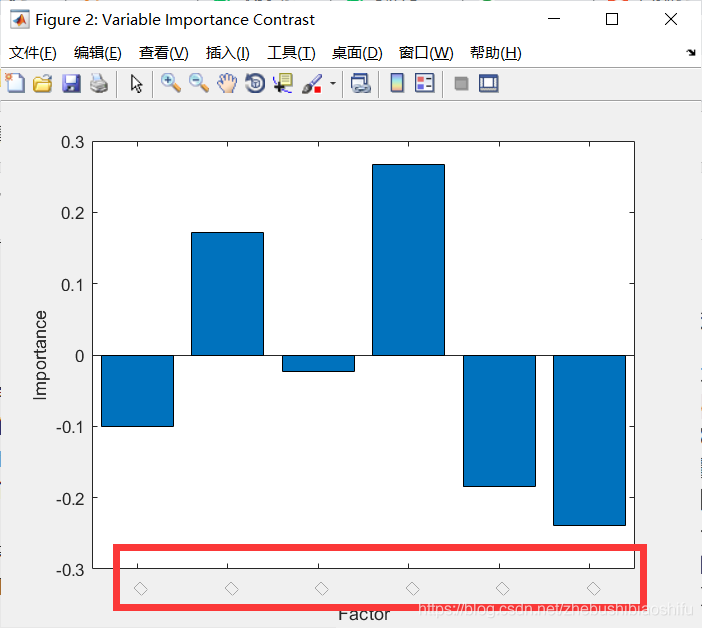
1.7 儲存模型
接下來,就可以將合適的模型儲存。
%% RF Model Storage
RFModelSavePath='G:\CropYield\02_CodeAndMap\00_SavedModel\';
save(sprintf('%sRF0410.mat',RFModelSavePath),'nLeaf','nTree',...
'RandomNumber','RFModel','RFPredictConfidenceInterval','RFPredictYield','RFr','RFRMSE',...
'TestVARI','TestYield','TrainVARI','TrainYield');
其中,RFModelSavePath是儲存路徑,save後的內容是需要儲存的變數名稱。
2 完整程式碼
完整程式碼如下:
%% Number of Leaves and Trees Optimization
for RFOptimizationNum=1:5
RFLeaf=[5,10,20,50,100,200,500];
col='rgbcmyk';
figure('Name','RF Leaves and Trees');
for i=1:length(RFLeaf)
RFModel=TreeBagger(2000,Input,Output,'Method','R','OOBPrediction','On','MinLeafSize',RFLeaf(i));
plot(oobError(RFModel),col(i));
hold on
end
xlabel('Number of Grown Trees');
ylabel('Mean Squared Error') ;
LeafTreelgd=legend({'5' '10' '20' '50' '100' '200' '500'},'Location','NorthEast');
title(LeafTreelgd,'Number of Leaves');
hold off;
disp(RFOptimizationNum);
end
%% Notification
% Set breakpoints here.
%% Cycle Preparation
RFScheduleBar=waitbar(0,'Random Forest is Solving...');
RFRMSEMatrix=[];
RFrAllMatrix=[];
RFRunNumSet=50000;
for RFCycleRun=1:RFRunNumSet
%% Training Set and Test Set Division
RandomNumber=(randperm(length(Output),floor(length(Output)*0.2)))';
TrainYield=Output;
TestYield=zeros(length(RandomNumber),1);
TrainVARI=Input;
TestVARI=zeros(length(RandomNumber),size(TrainVARI,2));
for i=1:length(RandomNumber)
m=RandomNumber(i,1);
TestYield(i,1)=TrainYield(m,1);
TestVARI(i,:)=TrainVARI(m,:);
TrainYield(m,1)=0;
TrainVARI(m,:)=0;
end
TrainYield(all(TrainYield==0,2),:)=[];
TrainVARI(all(TrainVARI==0,2),:)=[];
%% RF
nTree=100;
nLeaf=5;
RFModel=TreeBagger(nTree,TrainVARI,TrainYield,...
'Method','regression','OOBPredictorImportance','on', 'MinLeafSize',nLeaf);
[RFPredictYield,RFPredictConfidenceInterval]=predict(RFModel,TestVARI);
% PredictBC107=cellfun(@str2num,PredictBC107(1:end));
%% Accuracy of RF
RFRMSE=sqrt(sum(sum((RFPredictYield-TestYield).^2))/size(TestYield,1));
RFrMatrix=corrcoef(RFPredictYield,TestYield);
RFr=RFrMatrix(1,2);
RFRMSEMatrix=[RFRMSEMatrix,RFRMSE];
RFrAllMatrix=[RFrAllMatrix,RFr];
if RFRMSE<1000
disp(RFRMSE);
break;
end
disp(RFCycleRun);
str=['Random Forest is Solving...',num2str(100*RFCycleRun/RFRunNumSet),'%'];
waitbar(RFCycleRun/RFRunNumSet,RFScheduleBar,str);
end
close(RFScheduleBar);
%% Variable Importance Contrast
VariableImportanceX={};
XNum=1;
% for TifFileNum=1:length(TifFileNames)
% if ~(strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeArea') | ...
% strcmp(TifFileNames(TifFileNum).name(4:end-4),'MaizeYield'))
% eval(['VariableImportanceX{1,XNum}=''',TifFileNames(TifFileNum).name(4:end-4),''';']);
% XNum=XNum+1;
% end
% end
for i=1:size(Input,2)
eval(['VariableImportanceX{1,XNum}=''',i,''';']);
XNum=XNum+1;
end
figure('Name','Variable Importance Contrast');
VariableImportanceX=categorical(VariableImportanceX);
bar(VariableImportanceX,RFModel.OOBPermutedPredictorDeltaError)
xtickangle(45);
set(gca, 'XDir','normal')
xlabel('Factor');
ylabel('Importance');
%% RF Model Storage
RFModelSavePath='G:\CropYield\02_CodeAndMap\00_SavedModel\';
save(sprintf('%sRF0410.mat',RFModelSavePath),'nLeaf','nTree',...
'RandomNumber','RFModel','RFPredictConfidenceInterval','RFPredictYield','RFr','RFRMSE',...
'TestVARI','TestYield','TrainVARI','TrainYield');
至此,大功告成。