Grafana 系列文章(九):開源雲原生紀錄檔解決方案 Loki 簡介
簡介
Grafana Labs 簡介
Grafana 是用於時序資料的事實上的儀表盤解決方案。它支援近百個資料來源。
Grafana Labs 想從一個儀表盤解決方案轉變成一個可觀察性 (observability) 平臺,成為你需要對系統進行偵錯時的首選之地。
完整的可觀察性
可觀察性。關於這意味著什麼,有很多的定義。可觀察性就是對你的系統以及它們的行為和表現的可見性。典型的是這種模式,即可觀察性可以分成三個部分(或支柱):指標 (Metrics)、紀錄檔 (Logs) 和跟蹤 (Traces);每個部分都相互補充,幫助你快速找出問題所在。
下面是在 Grafana Labs 部落格和演講中反覆出現的一張圖:
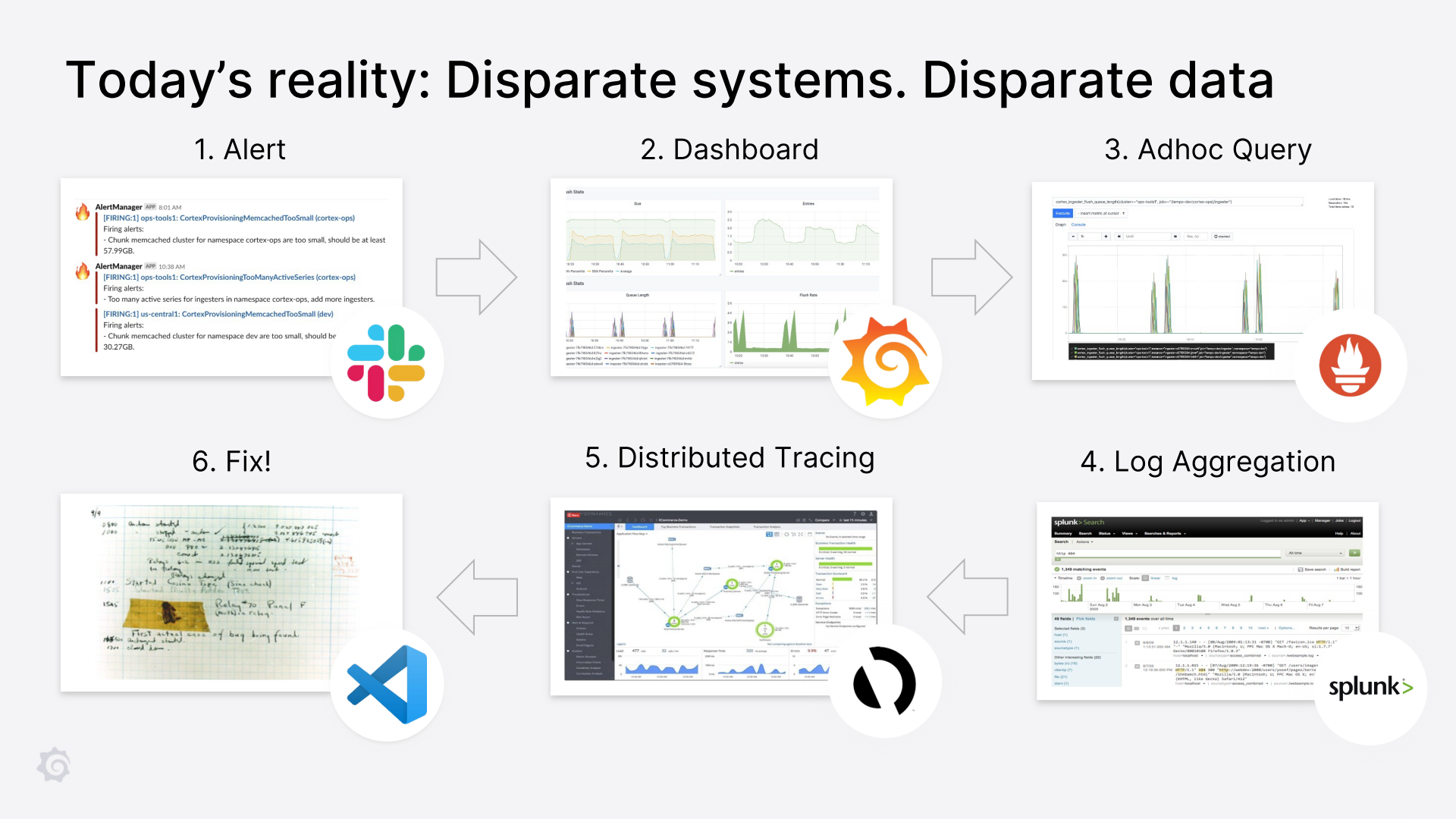
Slack 向我發出警告,說有問題,我就開啟 Grafana 上服務的相關儀表盤。如果我發現某個面板或圖表有異常,我會在 Prometheus 的使用者介面中開啟查詢,進行更深入的研究。例如,如果我發現其中一個服務丟擲了 500 個錯誤,我會嘗試找出是否是某個特定的處理程式/路由丟擲了這個錯誤,或者是否所有的範例都丟擲了這個錯誤,等等。
接下來,一旦我有了一個模糊的心理模型,知道什麼地方出了問題,我就會看一下紀錄檔(比如在 splunk 上)。在 Loki 之前,我習慣於使用 kubectl 來獲取相關的紀錄檔,看看錯誤是什麼,以及我是否可以做些什麼。這對錯誤來說很有效,但有時我會因為高延遲而放棄。之後,我從 traces (比如 AppD) 中得到更多的資訊,關於什麼是慢的,哪個方法/操作/功能是慢的。或者使用 Jaeger 來獲得追蹤資訊。
雖然它們並不總是直接告訴我哪裡出了問題,但它們通常讓我足夠近距離地檢視程式碼並找出哪裡出了問題。然後,我可以擴充套件服務(如果服務超載)或部署修復。
Loki 專案背景
Prometheus 工作得很好,Jaeger 也漸入佳境,而 kubectl 也很不錯。標籤 (label) 模型很強大,足以讓我找到出錯服務的根源。如果我發現 ingester 服務在出錯,我會做:kubectl --namespace prod logs -l name=ingester | grep XXX,以獲得相關的紀錄檔,並通過它們進行 grep。
如果我發現某個特定的範例出錯了,或者我想跟蹤某個服務的紀錄檔,我必須使用單獨的 pod 來跟蹤,因為 kubectl 不允許你根據標籤選擇器來跟蹤。這並不理想,但對於大多數的使用情況來說是可行的。
只要 pod 沒有崩潰或者沒有被替換,這就可以了。如果 pod 或節點被終止了,紀錄檔就會永遠丟失。另外,kubectl 只儲存最近的紀錄檔,所以當我們想要前一天或更早的紀錄檔時,我們是盲目的。此外,不得不從 Grafana 跳到 CLI 再跳回來的做法並不理想。我們需要一個能減少上下文切換的解決方案,而我們探索的許多解決方案都非常昂貴,或者不能很好地擴充套件。
這是意料之中的事,因為它們比 select + grep 做得更多,而這正是我們所需要的。在看了現有的解決方案後,Grafana Labs 決定建立自己的。
Loki
由於對任何開源的解決方案都不滿意,Grafana Labs 開始與人交談,發現很多人都有同樣的問題。事實上,Grafana Labs 已經意識到,即使在今天,很多開發人員仍然在 SSH 和 grep/tail 機器上的紀錄檔。他們所使用的解決方案要麼太貴,要麼不夠穩定。事實上,人們被要求減少紀錄檔,Grafana Labs 認為這是一種反模式的紀錄檔。Grafana Labs 認為可以建立一些 Grafana Labs 內部和更廣泛的開源社群可以使用的東西。Grafana Labs 有一個主要目標:
- 保持簡單。只支援 grep!
Grafana Labs 還瞄準了其他目標:
- 紀錄檔應該是便宜的。不應要求任何人少記錄紀錄檔。
- 易於操作和擴充套件
- 指標 (Metrics)、紀錄檔 (Logs)(以及後來的追蹤 (traces))需要一起工作
最後一點很重要。Grafana Labs 已經從 Prometheus 收集了指標的後設資料,所以想利用這些後設資料進行紀錄檔關聯。例如,Prometheus 用 namespace、service name、範例 IP 等來標記每個指標。當收到警報時,使用後設資料來找出尋找紀錄檔的位置。如果設法用同樣的後設資料來標記紀錄檔,我們就可以在度量和紀錄檔之間無縫切換。你可以在 這裡 看到 Grafana Labs 寫的內部設計檔案。下面是 Loki 的演示視訊連結: