.Net6 微服務之Polly入門看這篇就夠了
前言
O(∩_∩)O 大家好!
書接上文,本文將會繼續建立在 .Net6 使用 Ocelot + Consul 看這篇就夠了 專案的基礎上進行Polly的介紹,然後這篇文章只是個人學習與分享,不喜勿噴,謝謝!
什麼是Polly?

Polly 是一個 .NET 彈性和瞬態故障處理庫,允許開發人員以流暢和執行緒安全的方式表達重試、斷路器、超時、隔板隔離、速率限制和回退等策略。
https://github.com/App-vNext/Polly
為什麼要用到Polly?
在單體專案中,一個業務流程的執行在一個程序中就完成了,但是在微服務專案中往往會涉及到多個服務甚至多臺機器,而這些服務之間一般都是需要使用網路來進行通訊,然而網路又是不可靠的,所以往往會因為網路資源,網路連線等問題來影響業務流程的處理,所以在這種情況下我們就需要一些保護機制來保障我們服務的正常執行,而本文介紹的 Polly 就提供了一些很好的應對方案。
在我們正式介紹Polly之前,我們先簡單介紹一下一些故障的代名詞,網上已經有大量的介紹了,所以這裡只會簡單介紹,助於理解。
什麼是服務雪崩?
在微服務中,服務A呼叫服務B,服務B可能會呼叫服務C,服務C又可能呼叫服務D等等,這種情況非常常見。如果服務D出現不可用或響應時間過長,就會導致服務C原來越多的執行緒處於網路呼叫等待狀態,進而影響到服務B,再到服務A等,最後會耗盡整個系統的資源,導致整體的崩潰,這就是微服務中的「雪崩效應」。
什麼服務熔斷?
熔斷機制就是應對雪崩效應的一種鏈路保護機制。其實,對於熔斷這個詞我們並不陌生,在日常生活中經常會接觸到,比如:家用電力過載保護器,一旦電壓過高(發生漏電等),就會立即斷電,有些還會自動重試,以便在電壓正常時恢復供電。再比如:股票交易中,如果股票指數過高,也會採用熔斷機制,暫停股票的交易。同樣,在微服務中,熔斷機制就是對超時的服務進行短路,直接返回錯誤的響應資訊,而不再浪費時間去等待不可用的服務,防止故障擴充套件到整個系統,並在檢測到該服務正常時恢復呼叫鏈路。
什麼是服務降級?
當我們談到服務熔斷時,經常會提到服務降級,它可以看成是熔斷器的一部分,因為在熔斷器框架中,通常也會包含服務降級功能。
降級的目的是當某個服務提供者發生故障的時候,向呼叫方返回一個錯誤響應或者替代響應。從整體負荷來考慮,某個服務熔斷後,伺服器將不再被呼叫,此時使用者端可以自己準備一個原生的fallback回撥,這樣,雖然服務水平下降,但總比直接掛掉的要好。比如:呼叫聯通介面伺服器傳送簡訊失敗之後,改用移動簡訊伺服器傳送,如果移動簡訊伺服器也失敗,則改用電信簡訊伺服器,如果還失敗,則返回「失敗」響應;再比如:在從推薦商品伺服器載入資料的時候,如果失敗,則改用從快取中載入,如果快取也載入失敗,則返回一些本地替代資料。
在某些情況下,我們也會採取主動降級的機制,比如雙十一活動等,由於資源的有限,我們也可以把少部分不重要的服務進行降級,以保證重要服務的穩定,待度過難關,再重新開啟。
專案准備
.Net 6
Visual Studio 2022
https://github.com/fengzhonghao8-24/.Net6.Polly
Polly的基本使用
//當我們的程式碼觸發HttpRequestException異常時,才進行處理。
Policy.Handle<HttpRequestException>();
//只有觸發SqlException異常,並且其異常號為1205的時候才進行處理
Policy.Handle<SqlException>(ex => ex.Number == 1205)
//使用 Or<T> 來實現同時處理多種異常
Policy
.Handle<HttpRequestException>()
.Or<OperationCanceledException>()
//根據返回結果進行故障定義
Policy.HandleResult<HttpResponseMessage>(r => r.StatusCode == HttpStatusCode.NotFound)
var policy = /*策略定義*/;
var res = await policy.ExecuteAsync(/*業務程式碼*/);
//指定多個策略
Policy.Wrap(retry, breaker, timeout).ExecuteAsync(/*業務程式碼*/);
//或者
Policy.Wrap(waitAndRetry.Wrap(breaker)).ExecuteAsync(action);
想了解更多用法請移步官網https://github.com/App-vNext/Polly/wiki
接下來繼續介紹幾種主要的策略
然後這裡說明一下,專案範例都是基於上篇文章的專案,然後在此基礎上我們新建立了一個控制檯專案PollyConsole用於演示,存取的服務為ServiceA專案。
專案安裝Nuget包:

超時策略
Polly 中關於超時的兩個策略:一個是悲觀策略(Pessimistic),一個是樂觀策略(Optimistic)。其中,悲觀策略超時後會直接拋異常,而樂觀策略則不會,而只是觸發CancellationTokenSource.Cancel函數,需要等待委託自行終止操作。一般情況下,我們都會用悲觀策略。
程式碼演示:
我們這裡設定了一個超時時間不能超過 5 秒(方便測試),否則就認為是錯誤的結果的超時策略場景。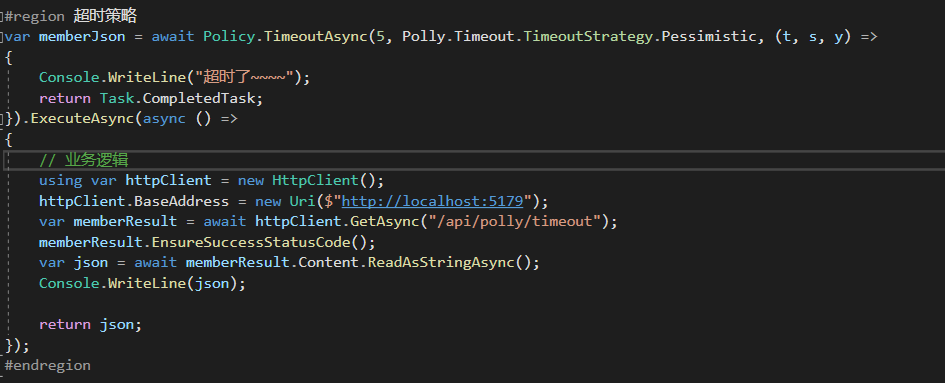

悲觀策略
執行回撥,拋異常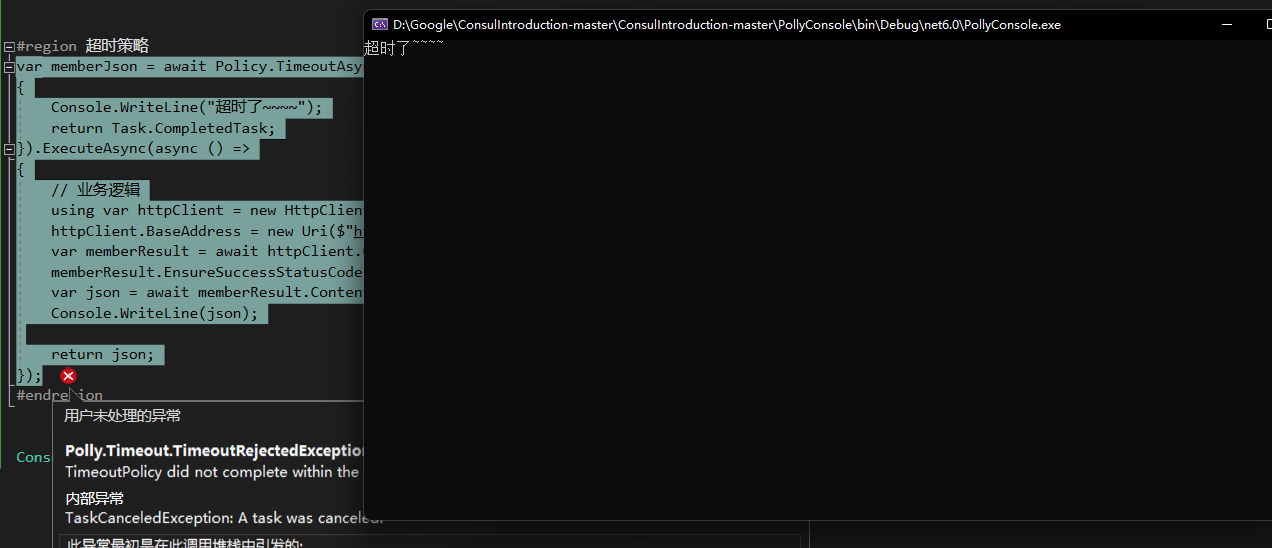
樂觀策略
執行效果,不會拋異常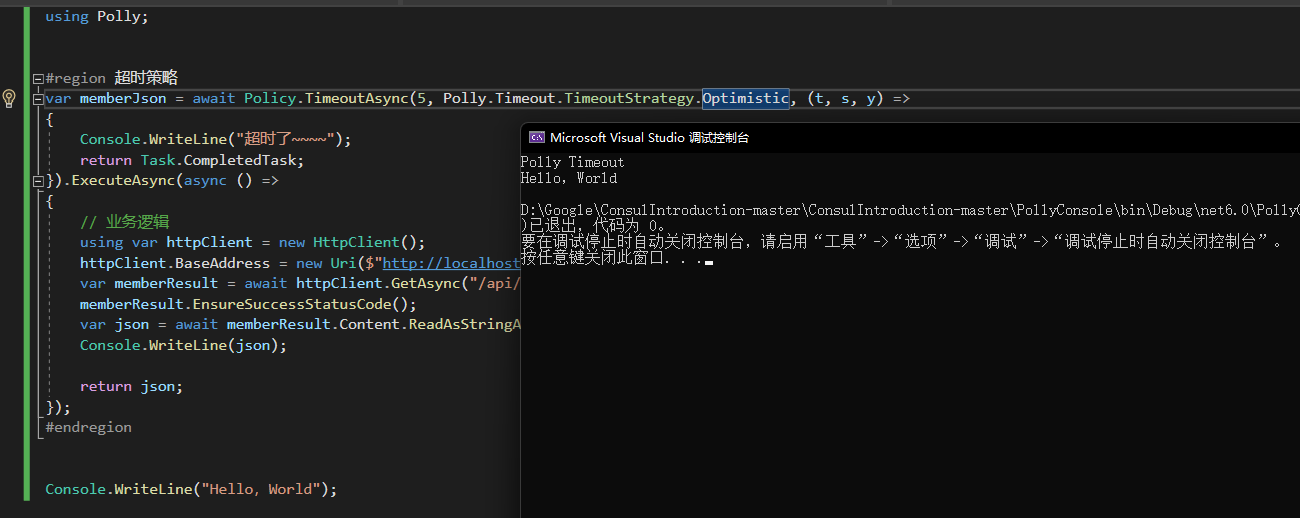
重試策略
請求異常
當發生 HttpRequestException 的時候觸發 RetryAsync 重試,並且最多重試3次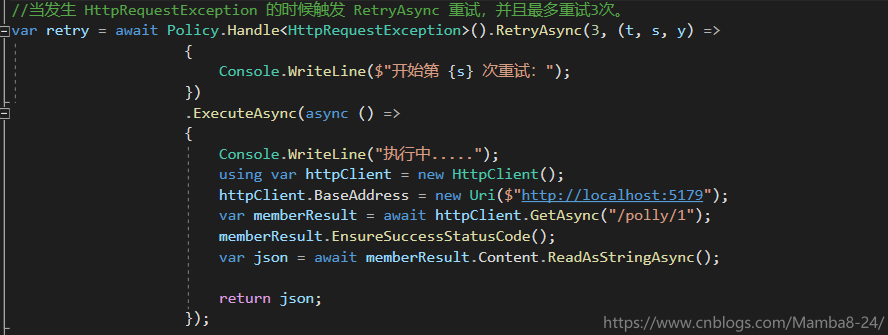
當前並不存在 /polly/1 api 所以用來模擬重試策略,看看執行效果: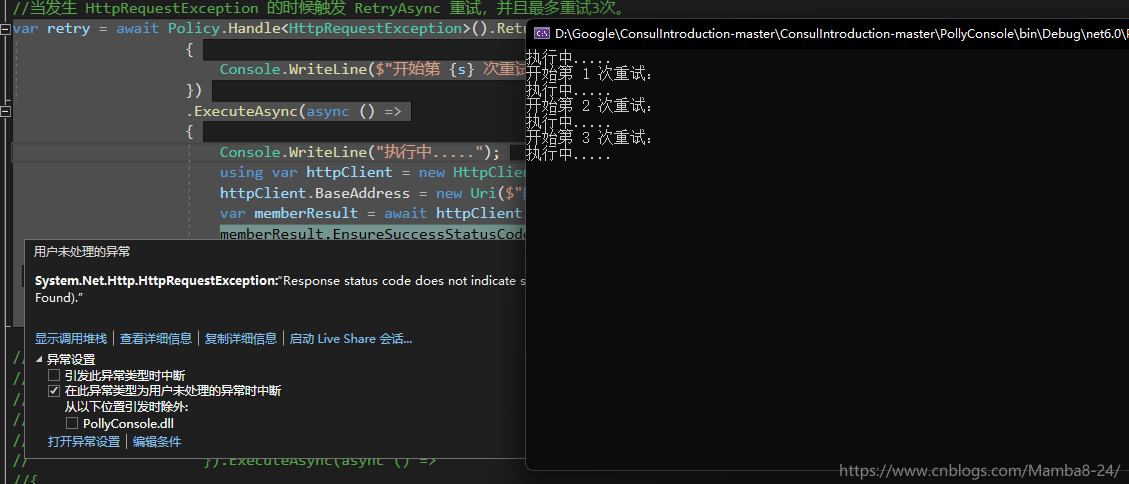
響應異常
當請求結果為 Http Status_Code 500 的時候進行3次重試
我們先在ServiceA服務新增測試介面,然後在PollyConsole專案請求介面,完成測試效果。
ServiceA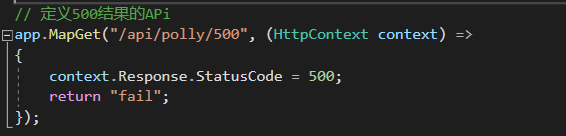
PollyConsole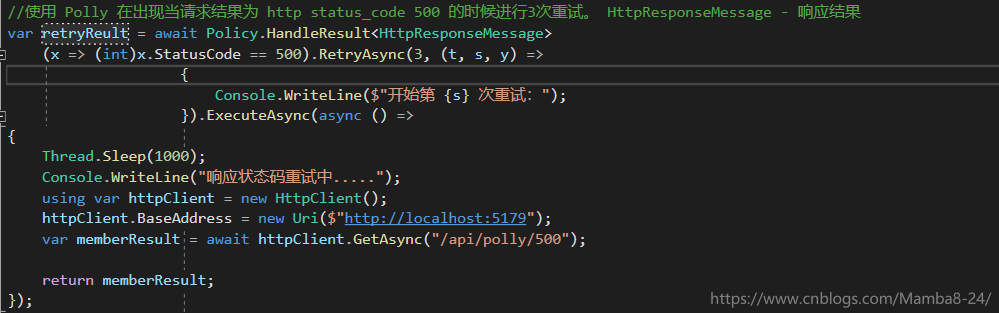
看看執行效果: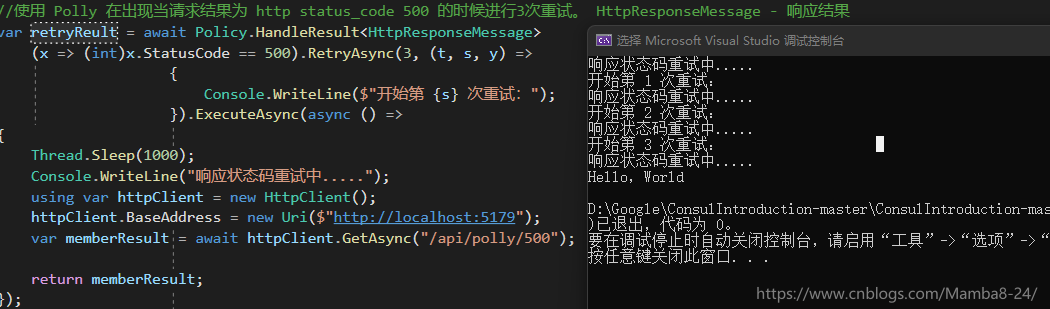
降級策略
策略模擬邏輯:
首先我們使用 Policy 的 FallbackAsync("FALLBACK") 方法設定降級的返回值。當我們服務需要降級的時候會返回 "FALLBACK" 的固定值。
同時使用 WrapAsync 方法把重試策略包裹起來。這樣我們就可以達到當服務呼叫失敗的時候重試3次,如果重試依然失敗那麼返回值降級為固定的 "FALLBACK" 值。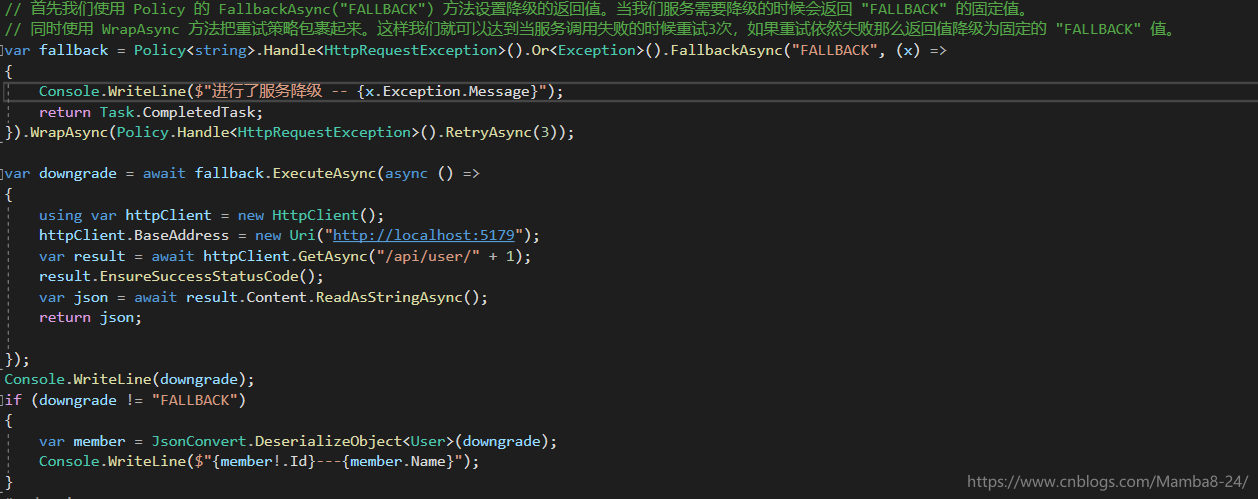
首選我們先正常存取
然後我們停掉被存取的服務 ServiceA
熔斷策略與策略包裹(多種策略組合)
首先定義熔斷策略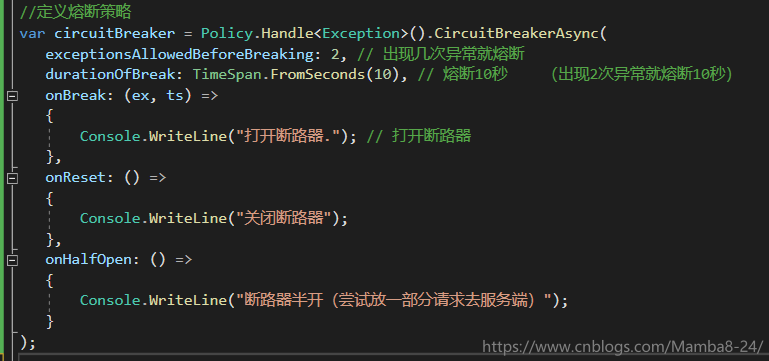
然後定義重試策略與降級策略並進行策略包裹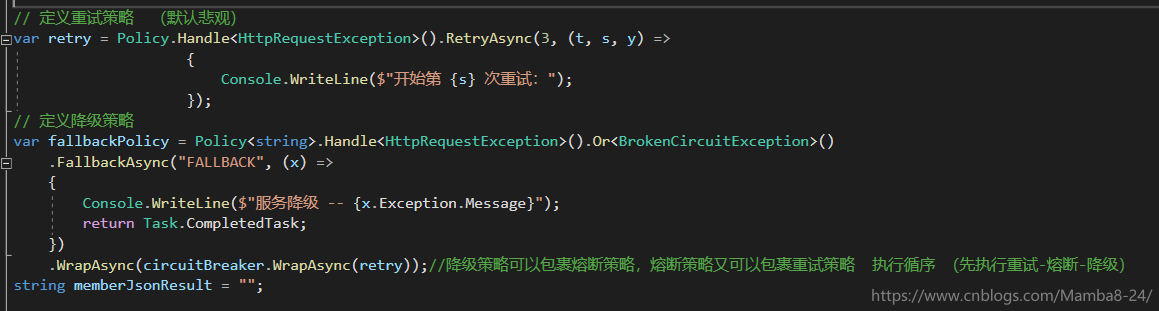
定義降級方法(模擬)與最終測試方法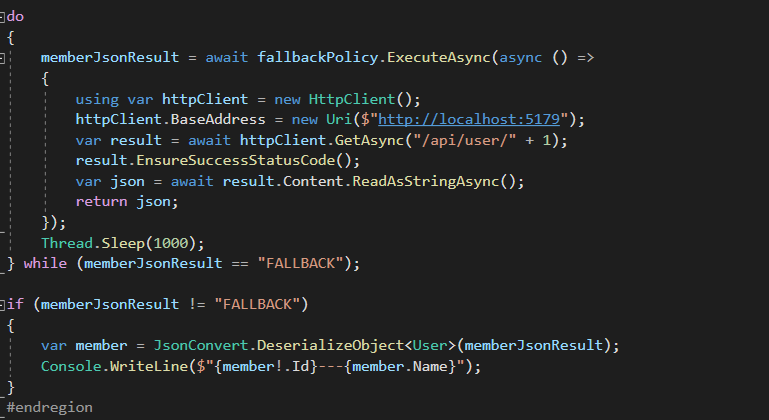
策略模擬邏輯:
傳送請求,觀察請求結果,當請求出現異常的時候會進行三次重試,重試後還不行,就會開啟斷路器10s,10s內不會往伺服器端傳送任何請求,只會請求降級方法,10s後為斷路器改為半開狀態,會嘗試釋放部分流量去伺服器端,再次觀察請求結果..........
看看測試效果(當前模擬服務不通的情況):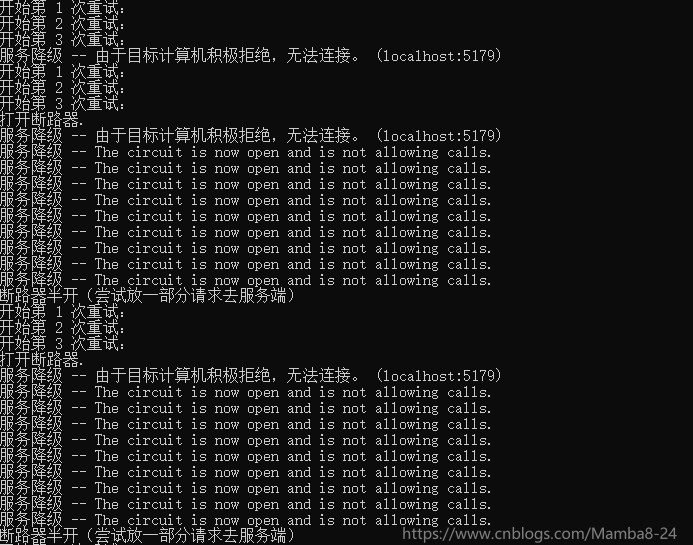
然後啟動被請求的服務,模擬在服務正常情況下的效果: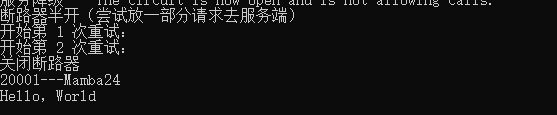
到這裡,我們對於幾種策略的演示就差不多大功告成了。如有理解不對的地方還請告知。
本文只是基本的策略演示,實際專案需要結合HttpClientFactory 使用。
結尾
以上都只是我的個人理解,然後也有參考官網以及大佬的文章,文章中如有什麼不妥的地方歡迎指正,共同進步。後續有時間還會繼續學習相關技術知識,歡迎Star與關注。謝謝