論文翻譯:2022_PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement
部落格地址:凌逆戰 (轉載請註明出處)
論文地址:PercepNet+: 用於實時語音增強的相位和訊雜比感知 PercepNet
參照格式: Ge X, Han J, Long Y, et al. PercepNet+: A Phase and SNR Aware PercepNet for Real-Time Speech Enhancement[J]. arXiv preprint arXiv:2203.02263, 2022.
摘要
PercepNet是RNNoise的最新擴充套件,是一種高效、高質量和實時的全頻帶語音增強技術,在各種公共深度噪聲抑制任務中顯示出了良好的效能。本文提出了一種名為PercepNet+的新方法,通過四個顯著改進來進一步擴充套件PercepNet。首先,我們引入一種相位感知結構,通過分別新增複數特徵和複數子帶增益作為深度網路的輸入和輸出,將相位資訊利用到PercepNet中。然後,專門設計了訊雜比(SNR)估計器和SNR切換後處理,以緩解原始PercepNet在高訊雜比條件下出現的過衰減(OA)。此外,用TF-GRU代替GRU層來建模時間和頻率依賴性。最後,我們提出以多目標學習的方式整合複數子帶增益損失、訊雜比、基音濾波強度和OA損失,以進一步提高語音增強效能。實驗結果表明,提出的PercepNet+無論在PESQ還是STOI上都明顯優於原PercepNet,且模型規模沒有增加太多。
索引術語: 語音增強,相位感知結構,訊雜比開關後處理,多目標學習
1 引言
語音增強(SE)旨在提高噪聲條件下的語音感知質量和可理解性。最近,基於深度學習的SE方法[1,2]表現出優於大多數傳統方法的效能,如對數譜幅度估計[3]、譜減法[4]等。在許多場景中,如電信和線上會議,要求SE系統同時滿足良好的去噪效能和實時約束。對於實時SE,目前主流的方法可以分為兩類。
- 一種是基於U-Net結構的端到端系統[5,6],如DCCRN[7]、DCCRN+[8]、DPCRN[9]等。
- 一種是感知驅動的混合訊號處理/深度學習方法,如RNNoise[10]及其擴充套件,如PercepNet[11]、Personalized PercepNet[12]等。
我們的工作重點是改進PercepNet,因為它在提高語音感知質量和噪聲抑制方面具有出色的能力。
PerceptNet[11]旨在以低複雜度增強全頻帶(48 kHz取樣)噪聲語音,並已被證明即使在少於5%的CPU核心(1.8 GHz Intel i7-8565U CPU)上執行也能實時提供高質量的語音增強。與最先進的端到端SE方法的傅立葉變換bin不同,PerceptNet的特點是語音短時傅立葉變換(STFT)頻譜從0到20 kHz只有34個頻段,根據人類聽力等效矩形頻寬(ERB)尺度[13],這大大降低了系統的計算複雜度。結合基音濾波器和包絡後濾波的設計,PercepNet可以產生高質量的增強語音。
然而,我們發現,與低訊雜比的增強帶噪語音相比,當輸入帶噪語音的訊雜比相對較高時,PercepNet的過衰減(OA)要嚴重得多,它顯著地損害了增強語音的感知質量(甚至比原始噪聲語音更嚴重)。這種更嚴重的質量損害可能是由於對頻帶增益的不準確估計,以及通過包絡後濾波進一步增強語音以去除殘留噪聲,因為從人類的感知來看,高訊雜比噪聲語音實際上是一個純淨語音。此外,在PercepNet處理過程中,只對語音譜包絡進行增強,直接利用噪聲語音的相位重構目標純淨語音。所有這些提到的問題可能會限制PercepNet的效能。
為了開發一個效能更好、更健壯的實時SE系統,在本研究中,我們重點對PercepNet進行改進,進一步增強其語音去噪能力,實現更好的語音感知質量。主要貢獻如下:
- 引入相位感知結構,通過新增複數子帶特徵作為附加的深度網路輸入,用子帶實部和虛部增益代替原有的能量增益,利用相位資訊實現純淨語音的構建;
- 為了解決增強高訊雜比帶噪語音的過衰減問題,減輕感知質量的損害,設計了訊雜比估計器和訊雜比開關後處理來控制殘餘噪聲的去除程度;
- 我們用TF-GRU結構替換PercepNet中的前兩個GRU[14]層,以很好地學習時間尺度的時間和頻率依賴性;
- 基於上述修正,我們最終提出通過多目標訓練的方式學習復增益、訊雜比、原基音濾波強度以及OA損耗,進一步提高SE效能。
與PercepNet相比,我們提出的PercepNet+在公共VCTK[17]測試集上實現了0.19 PESQ[15]和2.25% STOI[16]的絕對增益,在模擬測試集[18]上實現了0.15 PESQ和2.93% STOI增益。
2 PercepNet
PercepNet是一種感知驅動的方法,用於對全頻頻段語音[11]進行低複雜度的實時增強。它從34個三角形頻帶中提取各種手工製作的基於erb的子帶聲學特徵作為模型輸入。該模型輸出能量增益,然後將$\hat{g}_b$與帶噪語音的基音濾波頻譜相乘以去除背景噪聲,其中基音濾波器為梳狀濾波器,旨在去除基音諧波[19]之間的噪聲。每個ERB頻段的基音濾波器的效果由基音濾波器強度$\hat{r}_b$控制。$\hat{g}_b$和$\hat{r}_b$都是由一個深度神經網路(DNN)自動學習的,該神經網路主要由兩個折積層和五個GRU層組成。DNN模型利用當前幀和三個額外的未來幀的特徵來計算其輸出,這使PercepNet實現了30毫秒的 lookahead。通過包絡後濾波,進一步增強去噪後的語音。更多細節可在[11]中找到。
3 提出的PercepNet+
如第一節所述,我們將PercepNet擴充套件到PercepNet+的四個新方面: 相位感知結構、訊雜比估計器和訊雜比切換後處理、多目標損失函數和更新的TF-GRU塊。圖1展示了PercepNet+的整個框架,所有暗紅色的塊和線都是我們對原始PercepNet[11]的改進。

圖1:擬議的PercepNet+演演算法框架。所有暗紅色的塊和線是我們對原來的PercepNet[11]的改進
(a) PercepNet+概述
(b) PercepNet+的DNN模型架構
3.1 相位感知結構
由於PercepNet的DNN輸入特徵與34個ERB頻段繫結,如圖1所示,原始70維聲學特徵$f_o$由68維頻段相關特徵(34為頻譜能量,34為pitch coherence(相干))、一個基音週期[20]和一個基音相關[21]組成。對於每個頻段$b$,DNN模型輸出兩個元素:能量增益$\hat{g}_b$和基音濾波強度$\hat{r}_b$。這些特徵只關注增強噪聲譜包絡和基音諧波,而忽略了相位資訊[22]對人的感知有顯著影響的重要性。
為了利用PercepNet+中的相位資訊,我們將噪聲語音$y(n)$的STFT的實部和虛部直接連線到每個ERB頻段,形成一個共68維的復特徵$f_c$。然後,如圖1(b)所示,將線性變換後的(FC層)$f_o$和$f_c$連線起來,訓練改進後的DNN模型。在增加復特徵的同時,我們還將原有的能量增益替換為複數增益,以更加關注相位,如圖1(b)所示。具體而言,我們提出網路學習實部增益和虛部增益$g_b^r$和$g_b^i$,以重建目標純淨語音幅值和相位譜,並定義為:
$$公式1:g_b^r(t)=\frac{\left\|X_b^r(t)\right\|_2}{\left\|Y_b^r(t)\right\|_2}, \quad g_b^i(t)=\frac{\left\|X_b^i(t)\right\|_2}{\left\|Y_b^i(t)\right\|_2}$$
其中,$X_b(t)$和$Y_b(t)$為幀$t$中ERB頻段$b$的純淨訊號$x(n)$及其噪聲訊號$y(n)$的復值頻譜,$||·||_2$表示L2-norm運算。
3.2 SNR估計和SNR切換後處理
在去除噪聲的過程中容易產生語音失真,嚴重損害語音感知質量[23]。在PercepNet中,這種失真可能是由於能量增益估計的不準確和包絡後濾波設計的不適當。在PercepNet+中,我們提出了一個訊雜比估計器,並設計了一個切換訊雜比的後處理,以緩解PercepNet中的語音失真。
訊雜比估計器:該估計器的靈感來自於文獻[8,24]。如圖1(b)所示,它由一個GRU和一個具有sigmoid啟用函數的全連線(FC)層組成,在多目標學習框架下預測幀級訊雜比,以保持良好的語音質量。第$t$幀$y(n)$歸一化ground-truth訊雜比$S(t)$[0,1]定義為
$$公式2:\begin{aligned}
&S(t)=\frac{Q(t)-\mu}{\sigma} \text { with } \\
&Q(t)=20 \log _{10}\left(X_m(t) / N_m(t)\right)
\end{aligned}$$
式中,$\mu$和$\sigma $為全噪聲語音訊雜比$Q(t)$的均值和標準差,$X_m(t)$和$N_m(t)$分別為純淨語音和噪聲的幅度譜。
SNR切換的MMSE-LSA後處理:儘管後處理模組被證明在去除殘留噪聲方面非常有效[25,26],但我們在實驗中發現,在幾乎沒有噪聲的測試樣本中,後處理模組可能會損害感知質量。因此,在我們的PercepNet+中,如圖1(a)所示,使用每一幀的預測訊雜比$\hat{S}$來控制是否需要執行後處理模組。我們稱這種策略為SNR切換後處理。如果$\hat{S}$大於預先設定的閾值,經$\hat{g}_b^r$和$\hat{g}_b^i$增強的頻譜$\hat{X}_c$將直接成為最終輸出。否則,$\hat{X}_c$將通過後處理進一步增強,去除殘留噪聲。
此外,我們發現,傳統的基於MMSE-LSA[3]的後處理在最近的端到端SE系統中取得了顯著的效果[8,27]。因此,在PercepNet+中,我們還將訊雜比切換後處理模組中的原始包絡後濾波替換為MMSE-LSA,如下所示
$$公式3:G(t)=\operatorname{MMSE-LSA}(\xi(t), \gamma(t))$$
$$公式4:\hat{X}(t)=G(t)*\hat{X}_c(t)$$
其中,$G(t)$為MMSE-LSA幀級增益,$\hat{X}_c(t)$為經過幀$t$復增益增強的頻譜,$\hat{X}(t)$為最終增強的清晰語音,如圖1(a)所示,$\xi (t)$、$\gamma (t)$為先驗和後驗幀級訊雜比,定義為[3]。
3.3 多目標損失函數
PercepNet中DNN模型的原始損失函數$L_P$有兩個部分:能量增益損失$L_g$和基音濾波強度損失$Lr$定義為:
$$公式5:\begin{aligned}
L_g &=\sum_b\left(g_b^\lambda-\hat{g}_b^\lambda\right)^2+C_1 \sum_b\left(g_b^\lambda-\hat{g}_b^\lambda\right)^4 \\
L_r &=\sum_b\left(\left(1-r_b\right)^\lambda+\left(1-\hat{r}_b\right)^\lambda\right)^2 \\
L_P &=\alpha L_g+\beta L_r
\end{aligned}$$
其中$g_b$,$\hat{g_b}$, $r_b$, $\hat{r_b}$是 ground-truth和DNN的預測的頻帶能量增益和基音濾波強度。$C_1$、$\lambda$、$\alpha $、$\beta$為偵錯引數。
除了訊雜比開關後處理,[28]的結果表明[29]中提出的不對稱損耗$L_{OA}$可以有效地緩解過衰減問題。因此,我們將其適應於$L_g$,以解決在高訊雜比條件下的質量下降問題
$$公式6:h(x)= \begin{cases}0, & \text { if } x \leq 0 \\ x, & \text { if } x>0\end{cases}$$
$$公式7:L_{O A}(g_b, \hat{g}_b)=|h(g_b-\hat{g}_b)|^2$$
$$公式8:L_g^{\prime}=\delta L_g+(1-\delta) L_{O A}$$
在PercepNet+中,我們沒有使用$L_P$,而是使用Eq.(8)分別度量估計的$\hat{g}_b^r$、$\hat{g}_b^i$與它們的ground truth之間的差值。綜合考慮原$L_r$和訊雜比$L_{SNR}(S, \hat{S})$的均方誤差(MSE)損失,最後使用以下整體多目標損失函數$L_{P+}$聯合訓練PercepNet+的DNN模型
$$公式9:\begin{aligned}
&L_{P+}=C_2 L_g^{\prime}\left(g_b^r, \hat{g}_b^r\right)+C_2 L_g^{\prime}\left(g_b^i, \hat{g}_b^i\right) \\
&\quad+C_3 L_{S N R}(S, \hat{S})+C_4 L_r\left(r_b, \hat{r}_b\right)
\end{aligned}$$
其中$C_2$, $C_3$, $C_4$是微調損失權重引數。
3.4 TF-GRU Block
PercepNet在時間維度上用GRU層建模時間依賴性。受[30]的啟發,我們使用另一個GRU層來建模頻譜模式的頻率演化。具體而言,如圖1(b)所示,我們將PercepNet中的兩個GRU層替換為兩個提議的TF-GRU塊,每個TF-GRU由一個Time-GRU (TGRU)層和一個Frequenecy-GRU (FGRU)層組成。FGRU學習頻率方面的依賴關係,TGRU學習時間方面的依賴關係。然後將TGRU和FGRU的輸出連線起來,形成最終的TF-GRU輸出。調整一個TF-GRU的引數數量,使其與原始PercepNet中的一個GRU層保持一致。
4 實驗步驟
4.1 資料集
在最初的PercepNet[11]中使用的訓練資料是不公開的,因此我們使用在[10]中用於訓練RNNoise模型的公共資料集作為我們的訓練集。純淨語音資料來自McGill TSP語音資料庫[31]和NTT多語種語音資料庫[32]。各種噪聲源的使用,包括電腦風扇,辦公室,人群,飛機,汽車,火車,建築。總的來說,我們有6小時的純淨語音和4小時的噪聲資料,這遠遠少於PercepNet[11]中使用的120小時語音加80小時噪聲資料。該訓練對通過動態混合噪聲和語音進行模擬,隨機訊雜比範圍為-5 ~ 20dB。一半的語音是由來自RIR噪聲設定[33]的房間脈衝響應(RIR)折積的。
使用兩個評估集來檢驗所提出的技術,一個是公共噪聲VCTK測試集[17],來自8個說話人的824個樣本。另一個是我們自己模擬的一個名為DNOISE[18]的測試集,訊雜比範圍為-5 ~ 20dB。DNOISE由108個樣本組成,語音資料來自WSJ0[34]資料集,噪聲資料來自RNNoise演示網站[35],包括辦公室、廚房、汽車、街道和嘈雜聲。
4.2 設定
所有訓練和測試資料取樣為48kHz。幀的提取使用Vorbis視窗[36],大小為20毫秒,重疊為10毫秒。批大小設定為32。使用Adam優化器[37],初始收益率設定為0.001。我們將損失函數權重$\lambda$、$\alpha$、$\beta$、$\delta $分別設為0.5、4.0、1.0和0.7。$C_1$、$C_2$、$C_3$、$C_4$分別設為10、4、1和1。PercepNet+的DNN網路層引數如圖1(b)所示。為了使結果具有可比性,所有其他設定都與[11]中的原始PercepNet和[10]中的RNNoise相同。用PESQ和STOI分別衡量語音質量和可解性。
5 結果和討論
5.1 基線
RNNoise(開源的)和它的擴充套件percepnet(非開源的)都被作為我們的基線。表1給出了VCTK測試集上的比較結果。模型1和3是在PercepNet[11]中發表的結果,其中模型在非公開的120小時語音和80小時噪聲資料上進行訓練,而模型2和4是我們實現的RNNoise和PercepNet模型,僅在6小時語音和4小時噪聲資料上進行訓練。很明顯,PercepNet的表現明顯優於它最初的RNNoise,我們的模型的PESQ分數只比[11]中的那些略差,即使我們的模型和模型1,3之間有一個非常大的訓練資料大小差距(190小時)。因此,我們認為我們對PercepNet的實現是正確的,可以作為我們PercepNet+的基線。
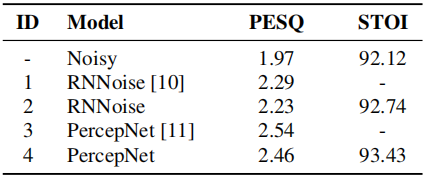
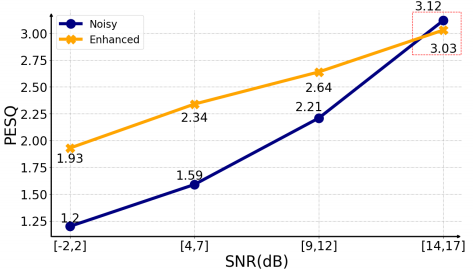
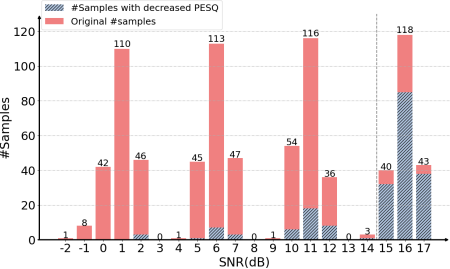
另外,詳細的基線結果分析如圖2和圖3所示,將整個VCTK測試集分為4級訊雜比範圍,觀察PecepNet在不同訊雜比條件下的去噪效能和行為。從圖2中,我們發現SNR>14dB的樣本在增強後的PESQ降低了。同時,在圖3中,對比紅色和對應的淡藍色部分的直方圖,可以看出PESQ的下降大部分發生在較高訊雜比的情況下,PESQ下降的樣本共202個,其中76.35%的樣本訊雜比大於14dB。這說明原來的PercepNet OA較重,或者在高訊雜比條件下不能很好地執行。因此,在本研究中,我們將14dB作為我們提出的訊雜比切換後處理閾值。
5.2 PercepNet+結果
表2:各種模型在VCTK和D-NOISE測試集上的PESQ和STOI(%)
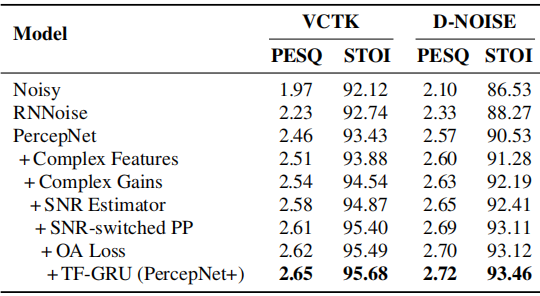
表3:在VCTK子測試集上,PercepNet+具有(或不具有)過衰減(OA)損失和SNR開關的PESQ得分
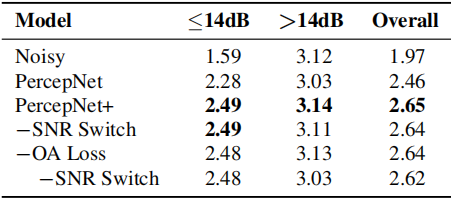
表2顯示了PercepNet+中所有提出的技術在VCTK和我們模擬的DNOISE測試集上的效能比較。與PercepNet相比,在VCTK測試集上,提出的PercepNet+顯著提高了PESQ從2.46提高到2.65,STOI從93.43%提高到95.68%。具體而言,附加的複雜特徵和增益導致PESQ和STOI的絕對增長分別為0.08和1.11%。在訊雜比估計器的幫助下,我們獲得了0.04的PESQ和0.27%的STOI改進。當採用訊雜比切換後處理(PP)和過衰減損失時,PESQ和STOI分別達到2.62和95.49%。最後,我們看到更新後的TF-GRU結果進一步提高了效能。此外,在D-NOISE測試集上,我們從所有提出的PercepNet+技術中獲得了一致的效能收益,總體PESQ為0.15,STOI為2.93%。此外,提出的PercepNet+有8.5M可訓練引數,與PercepNet相比增加了0.5M,實時因子(RTF)等於0.351,這是在一臺Intel(R) Xeon(R) CPU E5-2650 [email protected]單執行緒機器上測試的。因此,我們可以得出結論,PercepNet+在沒有顯著增加神經網路引數的情況下,已經大大超過了PercepNet。
5.3 SNR-sensitive 技術的效能
我們進一步研究了所提出的OA loss和SNR切換PP在解決高訊雜比條件下增強後語音感知質量下降問題上的有效性。兩個VCTK子測試集($>$14dB和$\le $14dB)的結果如表3所示。對比前兩行的pesq,我們發現在高訊雜比的情況下,PercepNet確實會損害感知質量,如圖2所示。然而,在PercepNet+中,我們看到這個問題被提出的OA 損失或訊雜比切換PP有效地緩解了。當兩種技術都被應用時,效能進一步略有提高,而不影響低訊雜比條件下的語音感知質量。
6 結論
在本文中,我們提出PercepNet+,通過在幾個方面擴充套件高質量、實時和低複雜度的PercepNet來進一步提高語音增強,包括學習相位資訊的相位感知結構,兩個SNRsensitive改進,在去除噪聲的同時保持語音感知質量,更新的TF-GRU,同時建模時間和頻率尺度依賴,以及進一步提高系統效能的多目標學習。重要的是,由於提出的OA損失和訊雜比切換的後期處理,原始PercepNet在高訊雜比條件下對語音感知質量的嚴重損害已經很好地解決了。實驗結果表明,所提出的PercepNet+在PESQ和STOI方面都明顯優於原始的PercepNet。一些有噪聲和增強的樣本,包括D-NOISE測試集可以從[18]中找到。
7 參考文獻
[1] Y. Xu, J. Du, L. Dai, and C. Lee, A regression approach to speech enhancement based on deep neural networks, in IEEE/ACM Transactions on Acoustics, Speech, and Signal Processing, vol. 23, no. 1, 2015, pp. 7 19.
[2] Y. Wang, A. Narayanan, and D. Wang, On training targets for supervised speech separation, in IEEE/ACM Transactions on Acoustics, Speech, and Signal Processing, vol. 22, no. 12, 2014, pp. 1849 1858.
[3] Y. Ephraim and D. Malah, Speech enhancement using a minimum mean-square error log-spectral amplitude estimator, in IEEE/ACM Transactions on Acoustics, Speech, and Signal Processing, vol. 33, no. 2, 1985, pp. 443 445.
[4] S. F. Boll, Suppression of acoustic noise in speech using spectral subtraction, in IEEE/ACM Transactions on Acoustics, Speech, and Signal Processing, vol. 27, no. 2, 1979, pp. 113 120.
[5] O. Ronneberger, P. Fischer, and T. Brox, U-net: Convolutional networks for biomedical image segmentation, in International Conference on Medical image computing and computer-assisted intervention, 2015, pp. 234 241.
[6] X. Li, H. Chen, X. Qi, Q. Dou, C.-W. Fu, and P.-A. Heng, Hdenseunet: Hybrid densely connected unet for liver and tumor segmentation from ct volumes, in IEEE Transactions on Medical Imaging, vol. 37, no. 12, 2018, pp. 2663 2674.
[7] Y. Hu, Y. Liu, S. Lv, M. Xing, S. Zhang, Y. Fu, J. Wu, B. Zhang, and L. Xie, DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement, in Proceedings of INTERSPEECH, 2020, pp. 2472 2476.
[8] S. Lv, Y. Hu, S. Zhang, and L. Xie, DCCRN+: Channel-Wise Subband DCCRN with SNR Estimation for Speech Enhancement, in Proceedings of INTERSPEECH, 2021, pp. 2816 2820.
[9] X. Le, H. Chen, K. Chen, and J. Lu, DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement, in Proceedings of INTERSPEECH, 2021, pp. 2811 2815.
[10] J.-M. Valin, A Hybrid DSP/Deep Learning Approach to RealTime Full-Band Speech Enhancement, in Proceedings of IEEE Multimedia Signal Processing (MMSP), 2018, pp. 1 5.
[11] J.-M. Valin, U. Isik, N. Phansalkar, R. Giri, K. Helwani, and A. Krishnaswamy, A Perceptually-Motivated Approach for LowComplexity, Real-Time Enhancement of Fullband Speech, in Proceedings of INTERSPEECH, 2020, pp. 2482 2486.
[12] R. Giri, S. Venkataramani, J.-M. Valin, U. Isik, and A. Krishnaswamy, Personalized PercepNet: Real-Time, LowComplexity Target Voice Separation and Enhancement, in Proceedings of INTERSPEECH, 2021, pp. 1124 1128.
[13] B. Moore, An introduction to the psychology of hearing, Brill, 2021.
[14] K. Cho, B. van Merrienboer, D. Bahdanau, and Y. Bengio, On the properties of neural machine translation: Encoder-decoder approaches, in Proceedings of Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation (SSST-8), 2014, pp. 103 111.
[15] I. Rec, P.862.2: Wideband extension to recommendation p.862 for the assessment of wideband telephone networks and speech codecs, International Telecommunication Union,CH Geneva, 2005.
[16] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An algorithm for intelligibility prediction of time frequency weighted noisy speech, in IEEE/ACM Transactions on Acoustics, Speech, and Signal Processing, vol. 19, no. 7, 2011, pp. 2125 2136.
[17] C. Valentini-Botinhao, X. Wang, S. Takaki, and J. Yamagishi, Investigating rnn-based speech enhancement methods for noiserobust text-to-speech, in Proceedings of ISCA Speech Synthesis Workshop (SSW), 2016, pp. 146 152.
[18] https://github.com/orcan369/PercepNet-plus-samples.
[19] J. H. Chen, Gersho, and A., Adaptive postfiltering for quality enhancement of coded speech, in IEEE/ACM Transactions on Acoustics, Speech, and Signal Processing, vol. 3, no. 1, 1995, pp. 59 71.
[20] D. Talkin., A robust algorithm for pitch tracking (RAPT), in Speech Coding and Synthesis, 1995, pp. 495 518.
[21] K. Vos, K. V. Sorensen, S. S. Jensen, and J.-M. Valin., Voice coding with opus, in Proceedings of AES Convention, 2013.
[22] K. K. Paliwal, K. K. W ojcicki, and B. J. Shannon, The importance of phase in speech enhancement, Speech Communication, vol. 53, no. 4, pp. 465 494, 2011.
[23] C. Zheng, X. Peng, Y. Zhang, S. Srinivasan, and Y. Lu, Interactive speech and noise modeling for speech enhancement, in AAAI, 2021, pp. 14 549 14 557.
[24] A. Nicolson and K. K. Paliwal, Masked multi-head self-attention for causal speech enhancement, Speech Communication, vol. 125, no. 3, pp. 80 96, 2020.
[25] A. Li, W. Liu, X. Luo, C. Zheng, and X. Li, ICASSP 2021 deep noise suppression challenge: Decoupling magnitude and phase optimization with a two-stage deep network, in Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6628 6632.
[26] Y.-H. Tu, J. Du, L. Sun, and C.-H. Lee, Lstm-based iterative mask estimation and post-processing for multi-channel speech enhancement, in Proceedings of Asia-Pacific Signal and Information Processing Association (APSIPA), 2017, pp. 488 491.
[27] A. Li, W. Liu, X. Luo, G. Yu, C. Zheng, and X. Li, A Simultaneous Denoising and Dereverberation Framework with Target Decoupling, in Proceedings of INTERSPEECH, 2021, pp. 2801 2805.
[28] S. E. Eskimez, T. Yoshioka, H. Wang, X. Wang, Z. Chen, and X. Huang, Personalized speech enhancement: New models and comprehensive evaluation, arXiv preprint arXiv:2110.09625, 2021.
[29] Q. Wang, I. L. Moreno, M. Saglam, K. Wilson, A. Chiao, R. Liu, Y. He, W. Li, J. Pelecanos, M. Nika, and A. Gruenstein, VoiceFilter-Lite: Streaming Targeted Voice Separation for OnDevice Speech Recognition, in Proceedings of INTERSPEECH, 2020, pp. 2677 2681.
[30] J. Li, A. Mohamed, G. Zweig, and Y. Gong, Lstm time and frequency recurrence for automatic speech recognition, in Proceedings of Automatic Speech Recognition and Understanding (ASRU), 2015, pp. 187 191. [31] http://www-mmsp.ece.mcgill.ca/Documents/Data/.
[32] https://www.ntt-at.com/product/artificial/.
[33] T. Ko, V. Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, A study on data augmentation of reverberant speech for robust speech recognition, in Proceedings of International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5220 5224.
[34] D. B. Paul and J. M. Baker, The design for the wall street journalbased csr corpus, in Proceedings of Second International Conference on Spoken Language Processing (ICSLP), 1992, pp. 357 362. [35] https://jmvalin.ca/demo/rnnoise/.
[36] X. O. Foundation, Vorbis I specification, 2004. [37] D. P. Kingma and J. Ba, Adam: A method for stochastic optimization, in Proceedings of International Conference on Learning Representations (ICLR), 2015.