05安裝一個Hadoop分散式叢集
安裝一個Hadoop分散式叢集
最小化的Hadoop已經可以滿足學習過程中大部分需求,但是為了研究Hadoop叢集執行機制,部署一個類生產的環境還是有必要的。因為叢集機器比較少,筆者沒有設定ssh,所以就需要在每一臺機器上手動啟動服務。啟動上相對繁瑣一些,優點是可以高度自定義叢集中的任務節點數量,從而更好的理解叢集中各個程序的作用。
一、環境準備
筆者認為一個Hadoop叢集管理著兩種資源,計算資源(CPU和記憶體)與儲存資源(資料儲存)。所以就對應了兩類服務,yarn和HDFS:
-
yarn resourcemanager:資源管理器,負責管理nodemanager、排程叢集資源
-
yarn nodemanager:節點管理器,管理物理機器上的CPU和記憶體,一個叢集可以有多個節點
-
HDFS namenode:HDFS namenode節點,管理檔案系統後設資料
-
HDFS datanode:HDFS datanode節點,儲存檔案資料塊
-
historyserver:歷史作業查詢服務,用於查詢已經結束的任務執行期間資料
yarn之後會進行介紹,這裡只需要知道它和HDFS一樣,有兩種服務:resourcemanager和nodemanager,resourcemanager類似HDFS的namenode節點,nodemanager類似HDFS的datanode節點。
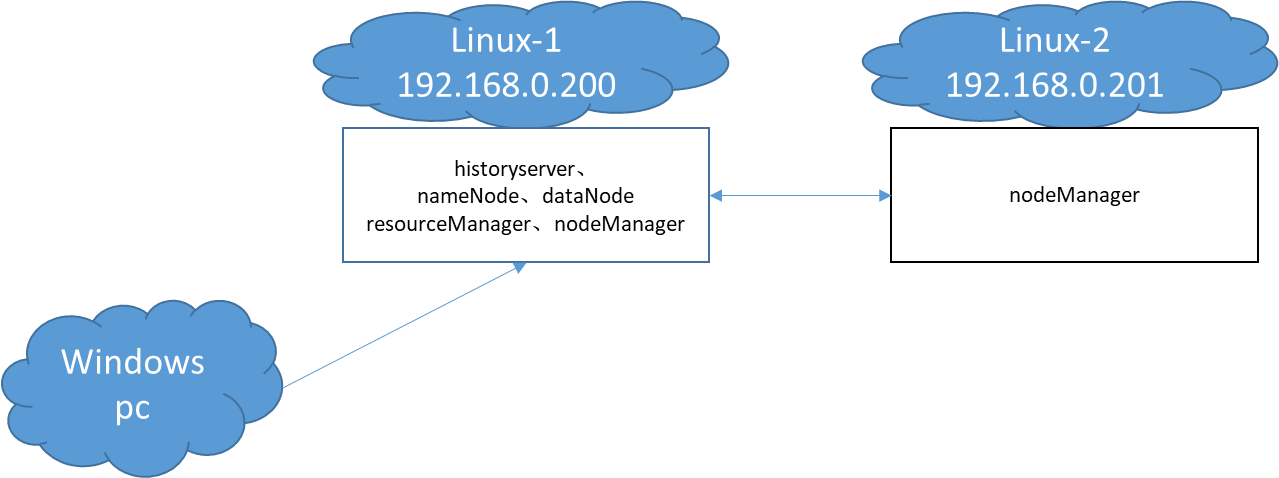
我的叢集使用了2個虛擬機器器,debian系統,8G記憶體,並且安裝了JDK1.8。這樣我就有3臺機器,分別是客戶機Windows,Linux-1和Linux-2。Linux-1執行了叢集全套的服務,Linux-2負責執行一個nodemanager節點,模擬被resourcemanager排程。
Linux-1和Linux-2的完整情況如下:
| Linux-1 | Linux-2 | |
|---|---|---|
| IP地址 | 192.168.0.200 | 192.168.0.201 |
| resourcemanager | 執行 | |
| nodemanager | 執行 | 執行 |
| namenode | 執行 | |
| datanode | 執行 | |
| historyserver | 執行 |
整個叢集的網路需要能夠互相存取,其他無特殊要求,系統拓撲如下:
二、組態檔結構
1、組態檔結構簡介
一個組態檔結構如下:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property>
<name>my.host</name>
<value>192.168.0.200</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://${my.host}:8082/</value>
</property>
</configuration>
一個組態檔的根節點是configuration,一般包含多個property節點,而一個property節點就是一個設定引數。property節點有name和value兩個屬性,分別是設定名稱和值。
如果存在多個同名的property節點,後一個property節點會覆蓋前一個。property節點的value支援${}預留位置,執行的時候預留位置會被解析為實際的值。
2、Hadoop設定
Hadoop有上百個設定,分為預設設定和自定義設定兩類。如果某個引數在自定義設定沒有,則會載入預設設定,所以我們只需要在自定義設定中加入少量的引數就可以執行叢集。
可以在以下網址查詢到Hadoop的預設設定:
自定義設定位於Hadoop安裝目錄下的etc/hadoop下,對應的4個自定義組態檔,名稱分別為core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml
三、安裝和設定叢集
1、修改組態檔
從https://hadoop.apache.org/releases.html下載Hadoop程式。這裡我下載的是2.10.2。分別解壓到Linux-1和Linux-2上,解壓後程式目錄如下:
drwxr-xr-x 2 debian debian 4096 5月 25 2022 bin
drwxr-xr-x 3 debian debian 4096 5月 25 2022 etc
drwxr-xr-x 2 debian debian 4096 5月 25 2022 include
drwxr-xr-x 3 debian debian 4096 5月 25 2022 lib
drwxr-xr-x 2 debian debian 4096 5月 25 2022 libexec
-rw-r--r-- 1 debian debian 106210 5月 25 2022 LICENSE.txt
drwxr-xr-x 3 debian debian 4096 2月 4 17:05 logs
-rw-r--r-- 1 debian debian 15830 5月 25 2022 NOTICE.txt
-rw-r--r-- 1 debian debian 1366 5月 25 2022 README.txt
drwxr-xr-x 3 debian debian 4096 5月 25 2022 sbin
drwxr-xr-x 4 debian debian 4096 5月 25 2022 share
etc/hadoop為程式組態檔存放設定,我們需要在每一個節點建立4個檔案core-site.xml、yarn-site.xml、mapred-site.xml、hdfs-site.xml。
筆者的設定完整內容如下:
core-site.xml
my.host需要設定成當前主機實際的地址。my.namenode.host、my.resourcemanager.host、my.jobhistory.host分別設定為:HDFS namenode執行地址、yarn資源管理器執行地址、歷史作業查詢服務jobhistory執行地址。這裡提一下fs.defaultFS,它的含義是HDFS的namenode地址,HDFS的datanode通過這個地址來發現namenode,同時這個地址也是預設檔案系統地址,用於解析相對的檔案路徑。
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 當前主機地址,修改成Linux-1或Linux-2實際的IP地址 -->
<property>
<name>my.host</name>
<value>192.168.0.200</value>
</property>
<!-- dfs namenode所在地址 -->
<property>
<name>my.namenode.host</name>
<value>192.168.0.200</value>
</property>
<!-- yarn 資源管理器所在地址 -->
<property>
<name>my.resourcemanager.host</name>
<value>192.168.0.200</value>
</property>
<!-- 作業歷史所在地址 -->
<property>
<name>my.jobhistory.host</name>
<value>192.168.0.200</value>
</property>
<!-- 檔案系統地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://${my.namenode.host}:8082/</value>
</property>
</configuration>
yarn-site.xml
yarn中機器ip的設定大多數繼承於core-site.xml,所以可以直接分發這個檔案到各個機器上,唯一需要注意的是yarn.nodemanager.local-dirs引數,這個目錄用於存放任務執行過程中的臨時檔案,通常需要大一點。
<?xml version="1.0"?>
<configuration>
<!-- 資源管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>${my.resourcemanager.host}</value>
</property>
<!-- 資源管理器繫結地址 -->
<property>
<name>yarn.resourcemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 節點管理器地址 -->
<property>
<name>yarn.nodemanager.hostname</name>
<value>${my.host}</value>
</property>
<!-- 節點管理器繫結地址 -->
<property>
<name>yarn.nodemanager.bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 節點管理器臨時檔案存放路徑 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data1/debian/hadoop-data/nodemanager-local-data</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 節點管理器執行容器最大記憶體 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4000</value>
</property>
<!-- 節點管理器單個容器分配最大記憶體 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3000</value>
</property>
</configuration>
mapred-site.xml
mapred-site.xml設定只需要設定歷史作業查詢服務jobhistory執行地址,筆者的這個組態檔引數也來源於core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 歷史任務IPC地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>${my.jobhistory.host}:10020</value>
</property>
<!-- 歷史任務web服務地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>${my.jobhistory.host}:19888</value>
</property>
</configuration>
hdfs-site.xml
這個組態檔用於控制HDFS的namenode和datanode節點資料存放路徑,dfs.namenode.checkpoint.dir控制namenode資料持久化目錄,之前提到的HDFS檔案系統中的檔案後設資料就儲存在這裡。dfs.datanode.data.dir為資料塊存放路徑,HDFS中的資料塊就存放在這裡。
這裡並沒有設定namenode所在地址,datanode是通過core-site.xml的fs.defaultFS中設定的地址尋找namenode的
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- 設定namenode資料儲存目錄 多個逗號分割-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data1/debian/hadoop-data/namenode-data</value>
</property>
<!-- 設定輔助namenode資料儲存目錄 多個逗號分割-->
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/data1/debian/hadoop-data/namenode-checkpoint-data</value>
</property>
<!-- namenode rpc繫結主機地址 -->
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<!-- 設定datanode資料儲存目錄 多個逗號分割 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data1/debian/hadoop-data/datanode-data</value>
</property>
<!-- 資料副本數 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
2、初始化HDFS nameserver資料目錄
一個新的HDFS的namenode類似新硬碟,使用前需要先格式化(初始化資料檔案),datanode節點不需要這個操作。一個HDFS的容量大小取決於datanode節點數量,所以也不需要設定HDFS的容量。
在namenode執行的節點,使用如下命令初始化HDFS的資料目錄:
bin/hdfs namenode -format
執行完成後在dfs.namenode.name.dir設定的目錄會生成namenode所需要的資料檔案,裡面有一個資料夾current,由於筆者HDFS節點已經執行過一段時間了,所以current中的內容如下:
debian@debian:/data1/debian/hadoop-data/namenode-data$ pwd
/data1/debian/hadoop-data/namenode-data
debian@debian:/data1/debian/hadoop-data/namenode-data$ ll
總用量 8
drwxr-xr-x 2 debian debian 4096 2月 4 15:27 current
-rw-r--r-- 1 debian debian 10 2月 4 15:27 in_use.lock
debian@debian:/data1/debian/hadoop-data/namenode-data$ ll current/
總用量 15396
-rw-r--r-- 1 debian debian 1048576 1月 22 14:20 edits_0000000000000000001-0000000000000000001
-rw-r--r-- 1 debian debian 1048576 1月 22 14:21 edits_0000000000000000002-0000000000000000002
-rw-r--r-- 1 debian debian 1048576 1月 22 14:21 edits_0000000000000000003-0000000000000000003
-rw-r--r-- 1 debian debian 1048576 1月 22 14:29 edits_0000000000000000004-0000000000000000004
-rw-r--r-- 1 debian debian 1048576 1月 24 17:47 edits_0000000000000000005-0000000000000000048
-rw-r--r-- 1 debian debian 1048576 1月 24 18:03 edits_0000000000000000049-0000000000000000061
-rw-r--r-- 1 debian debian 1048576 1月 28 10:01 edits_0000000000000000062-0000000000000000170
-rw-r--r-- 1 debian debian 1048576 2月 2 17:01 edits_0000000000000000171-0000000000000000171
-rw-r--r-- 1 debian debian 1048576 2月 2 21:18 edits_0000000000000000172-0000000000000000482
-rw-r--r-- 1 debian debian 1048576 2月 2 22:32 edits_0000000000000000483-0000000000000000866
-rw-r--r-- 1 debian debian 1048576 2月 2 22:45 edits_0000000000000000867-0000000000000000867
-rw-r--r-- 1 debian debian 1048576 2月 2 23:09 edits_0000000000000000868-0000000000000001143
-rw-r--r-- 1 debian debian 1048576 2月 3 10:50 edits_0000000000000001144-0000000000000001382
-rw-r--r-- 1 debian debian 1048576 2月 4 00:39 edits_0000000000000001383-0000000000000001620
-rw-r--r-- 1 debian debian 1048576 2月 4 17:07 edits_inprogress_0000000000000001621
-rw-r--r-- 1 debian debian 8109 2月 4 00:01 fsimage_0000000000000001382
-rw-r--r-- 1 debian debian 62 2月 4 00:01 fsimage_0000000000000001382.md5
-rw-r--r-- 1 debian debian 10696 2月 4 15:27 fsimage_0000000000000001620
-rw-r--r-- 1 debian debian 62 2月 4 15:27 fsimage_0000000000000001620.md5
-rw-r--r-- 1 debian debian 5 2月 4 15:27 seen_txid
-rw-r--r-- 1 debian debian 214 2月 4 15:27 VERSION
四、啟動服務
1、啟停指令碼說明
進入Hadoop安裝目錄下的sbin資料夾,主要有3個指令碼檔案,用於啟停叢集中各種守護行程,它們分別是
-
hadoop-daemon.sh
啟停HDFS的namenode和datanode,它還有多主機的啟停版本hadoop-daemons.sh
-
yarn-daemon.sh
啟停yarn的資源管理器和節點管理器,它還有多主機的啟停版本yarn-daemons.sh
-
mr-jobhistory-daemon.sh
啟停歷史任務管理服務historyserver
2、啟動HDFS
在Linux-1機器上執行如下命令
-- 啟動namenode
sbin/hadoop-daemon.sh start namenode
-- 啟動datanode
sbin/hadoop-daemon.sh start datanode
使用jps命令可以看到兩個程序
debian@debian:~/program/hadoop-2.10.2$ jps
676 NameNode
7846 Jps
733 DataNode
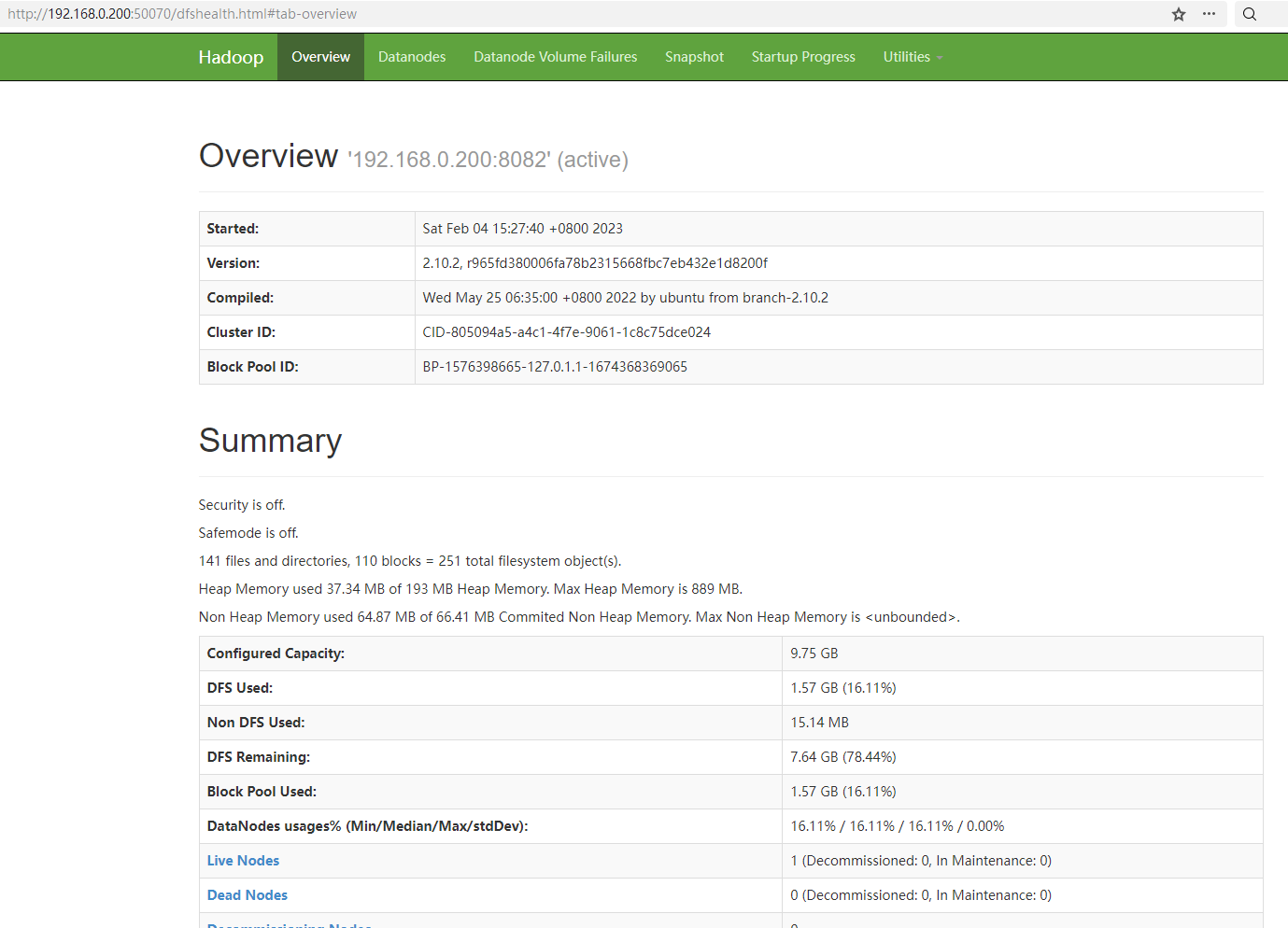
在windows物理機的瀏覽器輸入http://192.168.0.200:50070/可存取HDFS的web管理頁面,筆者的顯示如下:
五、在叢集執行一個MapReduce作業
本文所有的程式碼放在我的github上,地址是:https://github.com/xunpengliu/hello-hadoop 。本節需要用到的模組是maxSaleMapReduce。任務用到的資料檔案可以用common模組中的SaleDataGenerator可以生成。
1、編寫任務設定
為了讓任務執行在Hadoop叢集上,我們需要編寫一個組態檔cluster-config.xml。需要注意的是yarn.resourcemanager.hostname設定,很多書籍或其他資料設定的是yarn.resourcemanager.address,因為筆者提交作業是在windows上提交的,作業使用的設定是Hadoop預設設定,如果不設定yarn.resourcemanager.hostname,那麼yarn.resourcemanager.resource-tracker.address的值就是0.0.0.0:8031(預設${yarn.resourcemanager.hostname}:8031),導致ApplicationMasters程序無法連上yarn resourcemanager。
如果需要跨平臺,也就是提交作業的系統和叢集執行的系統不一樣,需要把mapreduce.app-submission.cross-platform設定成true
其他的設定就沒什麼特別的了,fs.defaultFS設定成HDFS的namenode的地址。mapreduce執行框架設定成yarn
完整內容如下:
<configuration>
<!-- 跨平臺提交 -->
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>
<!-- 檔案系統地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.200:8082/</value>
</property>
<!-- 資源管理器地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.200</value>
</property>
<!-- 執行框架 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- map任務數量 -->
<property>
<name>mapreduce.job.maps</name>
<value>5</value>
</property>
</configuration>
2、準備作業資料檔案
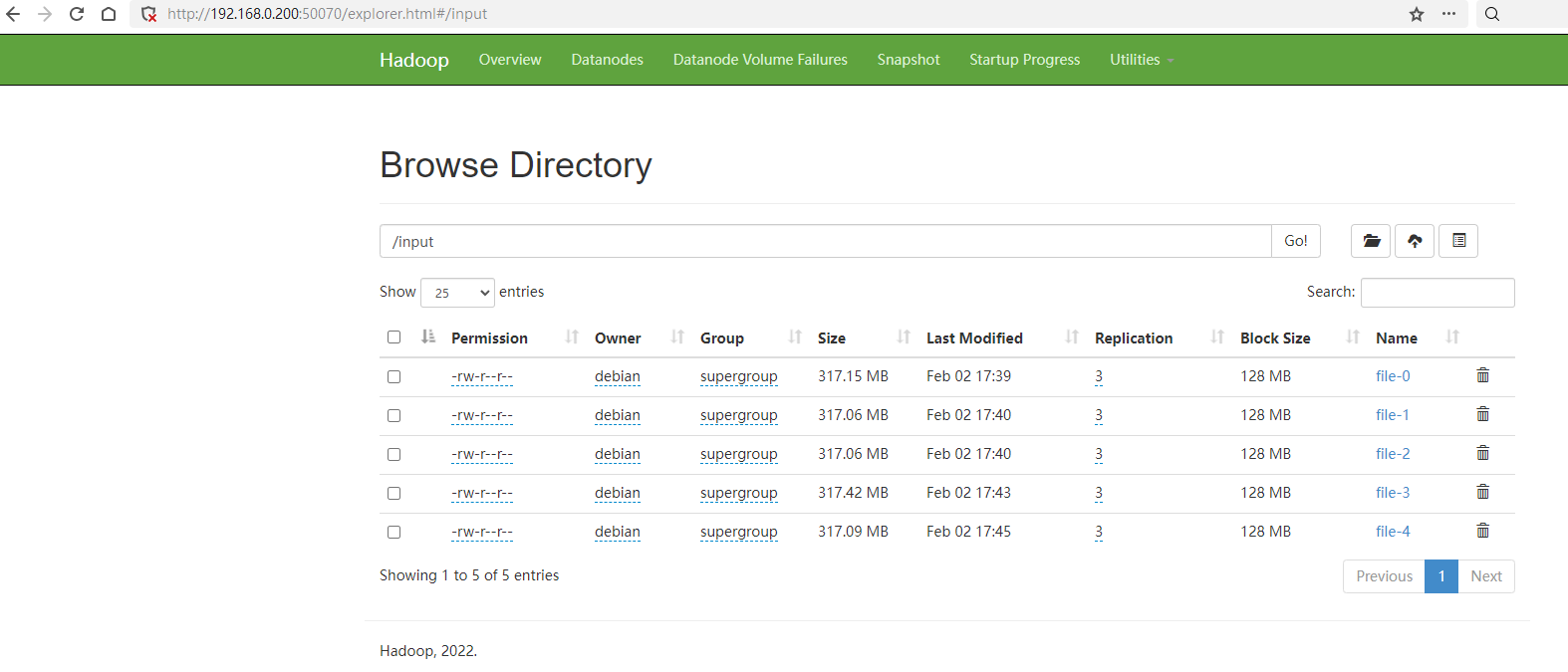
任務用到的資料檔案可以用common包中的SaleDataGenerator生成,把生成資料檔案傳到HDFS上的/input目錄上,可以用Hadoop的fs命令上傳。
hadoop fs -copyFromLocal file-0 hdfs://192.168.0.200:8082/input/file-0
hadoop fs -copyFromLocal file-1 hdfs://192.168.0.200:8082/input/file-1
hadoop fs -copyFromLocal file-2 hdfs://192.168.0.200:8082/input/file-2
hadoop fs -copyFromLocal file-3 hdfs://192.168.0.200:8082/input/file-3
hadoop fs -copyFromLocal file-4 hdfs://192.168.0.200:8082/input/file-4
上傳完成後可以在HDFS的管理頁面中看到檔案:
六、常見問題
-
上傳檔案到HDFS提示copyFromLocal: Permission denied
這個是因為hadoop命令獲取到使用者與HDFS上的許可權不符,修改環境變數更改執行使用者,然後重新執行命令:
-- windows set HADOOP_USER_NAME=debian -- linux export HADOOP_USER_NAME=debian -
執行MapReduce作業提示無讀寫許可權
23/02/04 21:34:34 INFO client.RMProxy: Connecting to ResourceManager at /192.168.0.200:8032 Exception in thread "main" org.apache.hadoop.security.AccessControlException: Permission denied: user=test, access=EXECUTE, inode="/tmp":debian:supergroup:drwx------ at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:350) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:311)/tmp存放任務執行的歷史結果,供historyserver使用。執行任務的使用者無寫入許可權,把這個目錄設定成所有人可寫,或者修改執行使用者為/tmp目錄的使用者
修改環境變數更改執行使用者,然後重新執行命令:
-- windows set HADOOP_USER_NAME=debian -- linux export HADOOP_USER_NAME=debian -
執行任務狀態一直卡在,任務紀錄檔報org.apache.hadoop.ipc.Client: Retrying connect to server: 0.0.0.0/0.0.0.0:8031
這個問題卡了我好久,MapReduce任務的ApplicationMasters程序無法連上yarn resourcemanager。根本原因是提交任務的機器使用的yarn.resourcemanager.resource-tracker.address設定是預設的,需要在任務的組態檔中加入yarn.resourcemanager.address設定