Dijkstra演演算法詳解(樸素演演算法+堆優化)
定義
Dijkstra(讀音:/'daɪkstrə/)演演算法,是用來求解一個邊帶權圖中從某個頂點出發到達其餘各個頂點的最短距離的演演算法。(為表達簡便,下文中「起點(源點)到某個頂點的距離」簡稱為「某個頂點的距離」)
限制條件:各個邊的權不能為負。
原理
假設s,v1,v2,...,vn(以下簡稱P1)為從源點s到vn的最短路,則s,v1,v2,...,vi-1(以下簡稱P2)也為從源點s到vi-1的最短路。
這點可以用反證法證明,假如P2不是從源點s到vi-1的最短路,那必然存在某兩個m、n(1 <= m < n <= i-1),使得在vm和vn之間,存在著某條更短的路徑。由於P1只不過是在P2的基礎上加上了vi-1到vi的距離,那麼P1顯然就不是最短路了。如圖:
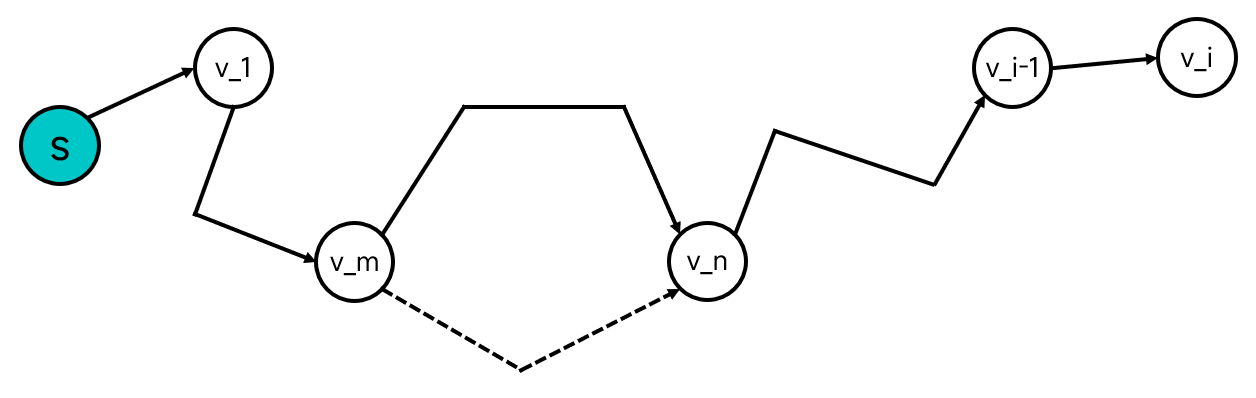
Dijkstra演演算法利用了這一點,從源點出發,不斷地利用已知的最短距離,依次求得剩餘頂點的最短距離。因此,這是一個貪婪演演算法。
演演算法步驟
引入兩個集合S和U,S為已求出最短距離的點的集合,U為尚未求出最短距離的點的集合。顯然S和U的交集為空,且S與U的併為整個圖的所有節點。初始時,S為空,而U包含圖的所有節點。初始時,除了起點的距離初始化為0之外,其餘所有節點的距離設為無窮大。(這樣才能保證能夠從起點開始)
不斷執行以下步驟,直到S已包含所有的頂點:
- 從U中找出距離最小的點,令其為v。
- 將v從U移到S。
- 對於v的每一個鄰接節點v',如果v'屬於U,且v的距離加上邊v-v'的長度之和小於v'的距離則更新v'的距離。(如果v'的距離為無窮大,那麼因為v的距離加上邊v-v'的長度之和一定是有限的,所以v'的距離一定會得到更新)
舉個例子:
給定下面這張圖,以0為起點求出剩餘頂點的最短距離。
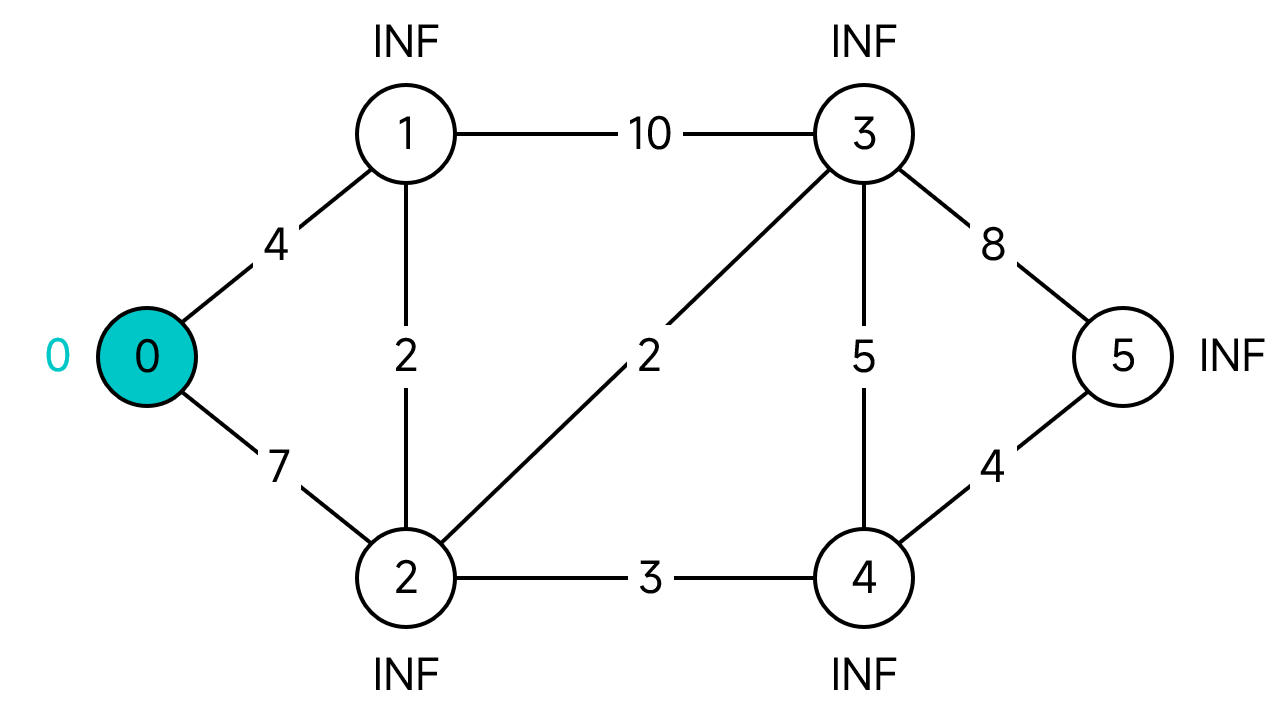
(PS:黑色空心節點表示U中的節點,綠色空心節點表示S中的節點,綠色實心節點表示當前選中的節點)
首先,S為空,而U包含了所有的節點。在U中的所有節點中,節點0的距離最短,為0。將0移到S,並更新其所有鄰接節點的距離。
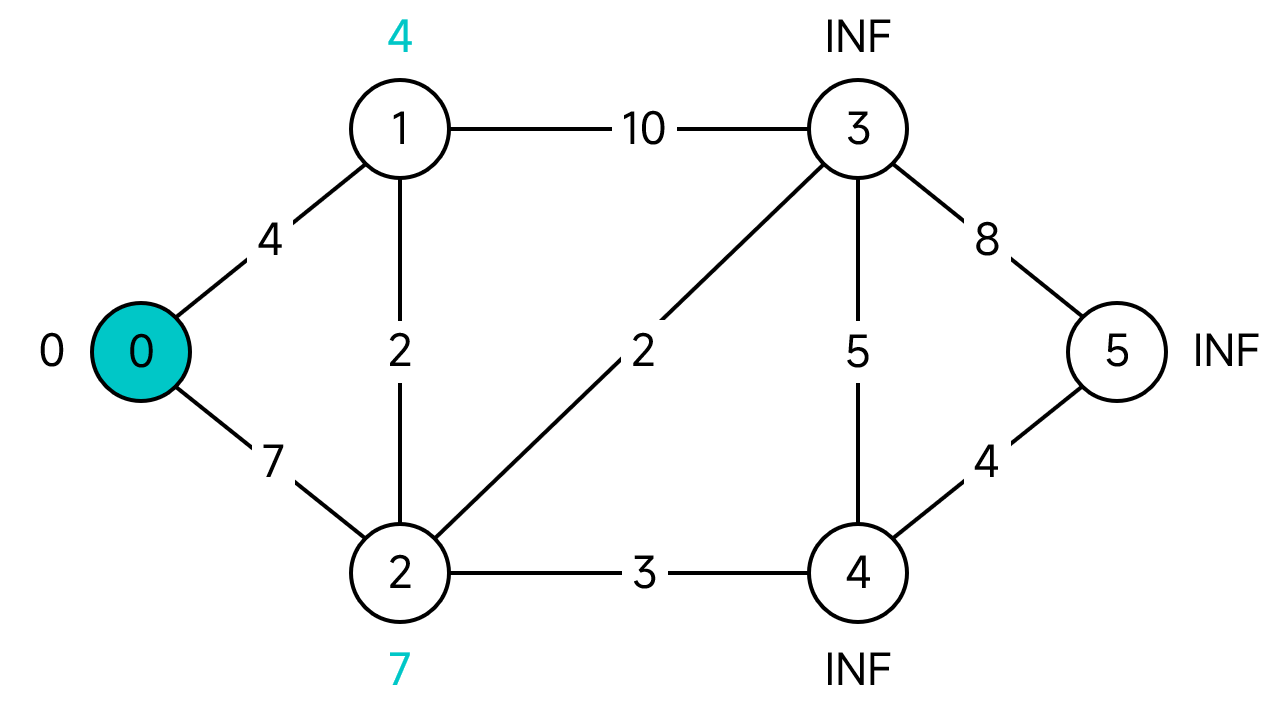
此時,U包含的節點為1、2、3、4、5、6,其中距離最短的節點為1。1的鄰接節點為0、2、3,其中:
- 節點0已屬於S,不做任何處理。
- 節點1的距離4加上1到2這條邊的距離2為6,小於節點2的距離7,因此更新2的距離為6。
- 節點1的距離4加上1到3這條邊的距離10為14,小於節點3的距離無窮大,因此更新3的距離為14。
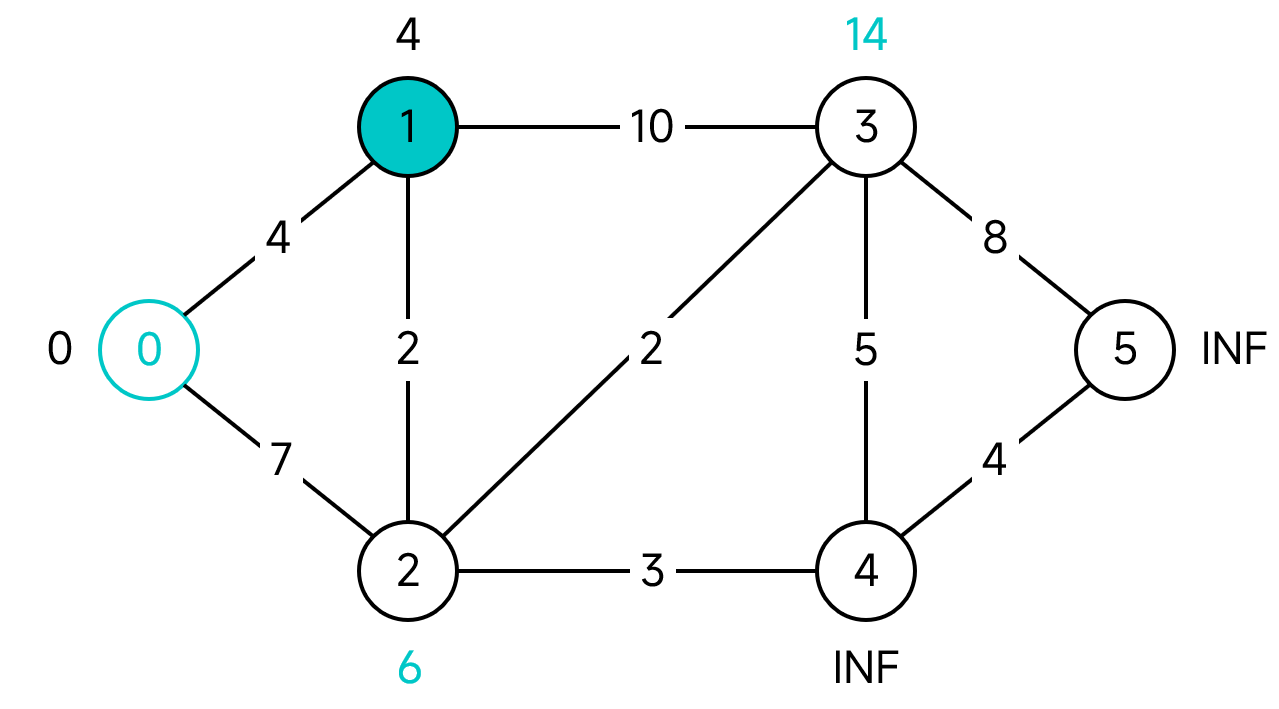
此時,U中距離最小的頂點為2,同樣的方法,更新其鄰接節點的距離。
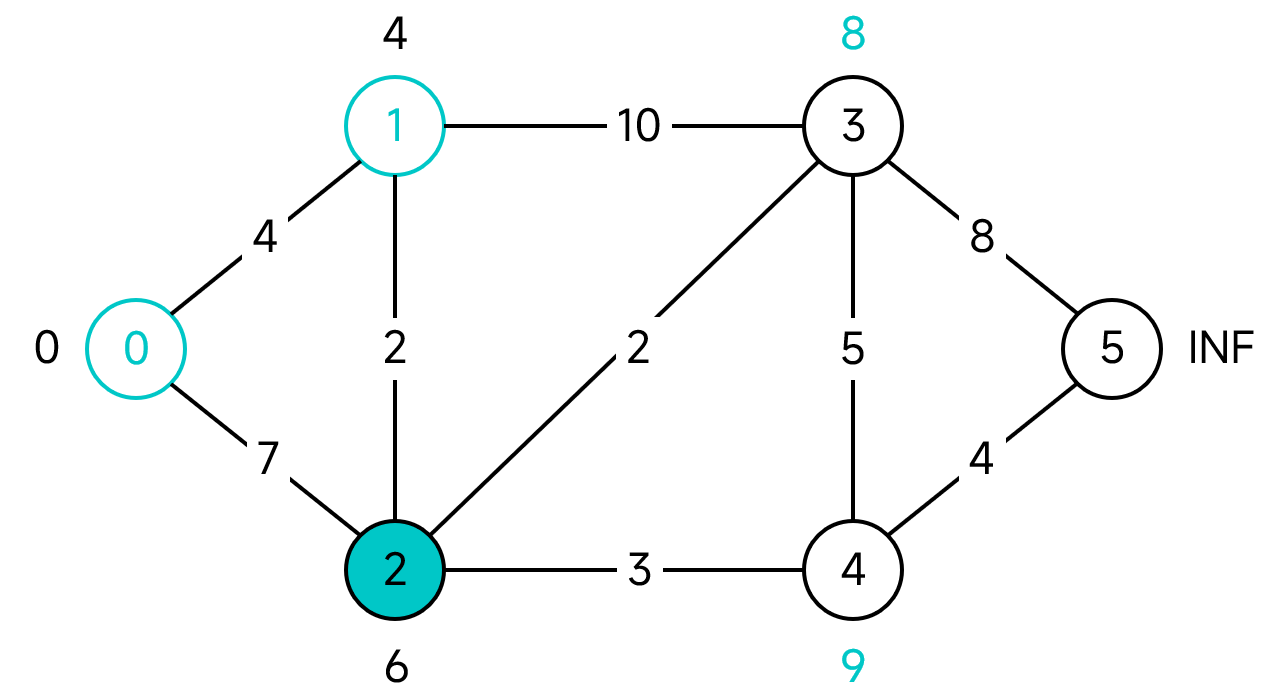
按照上面的步驟一直進行下去,就可以得到所有節點的最小距離:

程式碼實現
傳統實現
類定義
因為每條邊攜帶了權值資訊,所以這裡使用鄰接矩陣來表示圖。非鄰接節點之間的權值規定為無窮大。出於效率考慮,這裡使用一維陣列儲存鄰接矩陣,假設整個圖的節點數為n,則節點i和 節點j的邊的權值為陣列中下標為i*n+j的值。
由於每條邊的權值規定不能為負,因此這裡用std::size_t(計算機能夠表示的最大的無符號整數型別)儲存權值。
另外,用16進位制的0x3f3f3f3f表示無窮大。這個數在10進位制下是109數量級的,這樣既可以保證路徑長度在一般情況下遠遠不會達到這麼大,也可以確保在進行加法運算的時候不會溢位。
#define INF 0x3f3f3f3f
為了使語意更加明確,使用型別別名表示節點下標,以和其他的整數資訊(如權值等)區分開。
using node_t = std::size_t;
因此,整個圖類定義如下:
class Graph {
std::size_t n; // 節點個數
std::vector<std::size_t> adjMatrix; // 鄰接矩陣
public:
using node_t = std::size_t; // 型別別名,表示節點下標
Graph(std::size_t n, std::initializer_list<std::size_t> il) : n(n), adjMatrix(il) {} // 建構函式
std::vector<std::size_t> dijkstra(node_t start); // Dijkstra演演算法,起點通過入參start指定
};
演演算法程式碼
由於一個節點要麼屬於S,要麼屬於V,因此我們使用一個bool陣列,true表示該節點屬於S,false表示該節點屬於V。初始時,陣列元素全為false。
std::vector<bool> shortest(n, false);
因此,整個演演算法程式碼的實現如下:
std::vector<std::size_t> Graph::dijkstra(Graph::node_t start) {
// shortest陣列定義
std::vector<bool> shortest(n, false);
// 儲存各個頂點距離的陣列
std::vector<node_t> distance(n, INF); // 其餘元素初始化為無窮大
distance[start] = 0; // 起點距離初始化為0
// 集合U中還剩餘多少個節點
std::size_t left = n;
// 迴圈執行以下步驟,直到U中沒有節點了
while (left) {
// 從U中選出距離最小的節點
node_t cur = 0;
std::size_t minDistance = INF;
for (node_t v = 0; v < n; ++v) {
if (shortest[v]) continue; // 排除掉已經在S中的節點
if (distance[v] < minDistance) {
cur = v;
minDistance = distance[cur];
}
}
// 將該節點從U移到S
shortest[cur] = true;
left--; // 剩餘節點數相應減一
// 更新該節點所有在U中的鄰接節點的距離
for (node_t neighbor = 0; neighbor < n; neighbor++) {
if (shortest[neighbor]) continue; // 排除S中的節點
auto dis = adjMatrix[cur * n + neighbor]; // 該節點與鄰接節點之間的權值
if (dis == INF) continue; // 排除不與該節點鄰接的節點
distance[neighbor] = std::min(distance[cur] + dis, distance[neighbor]); // 更新鄰接節點的距離
}
}
return distance;
}
測試:
int main() {
Graph::node_t n = 6;
Graph::node_t start = 0;
Graph graph(n, {0, 4, 7, INF, INF, INF,
4, 0, 2, 10, INF, INF,
7, 2, 0, 2, 3, INF,
INF, 10, 2, 0, 5, 8,
INF, INF, 3, 5, 0, 4,
INF, INF, INF, 8, 4, 0});
auto distance = graph.dijkstra(start);
for (Graph::node_t node = 0; node < n; ++node) {
std::cout << start << "->" << node << ": " << distance[node] << std::endl;
}
return 0;
}
輸出:
0->0: 0
0->1: 4
0->2: 6
0->3: 8
0->4: 9
0->5: 13
時間複雜度分析
時間複雜度:可以看出,演演算法程式碼裡面有while迴圈巢狀著for迴圈,其中while迴圈的執行次數為n(left初始化為n,每次迴圈減一,直到減到0退出迴圈),for迴圈的執行次數也為n,因此時間複雜度為O(n2)。
這樣的時間複雜度好像不太能令人滿意,那麼是否可以減少時間成本呢?
答案是可以的。
堆優化
我們發現,每次選出距離最小的點,都需要遍歷圖中所有的頂點,時間成本為O(n),顯然過大。利用優先佇列這個資料結構,我們可以將時間成本減少為O(1)。(C++的STL中的優先佇列的底層實現預設為完全二元堆積)
要實現這一點,我們首先需要定義一個struct,包含節點下標和距離。同時,我們也需要定義一個operator>過載運運算元用來定義比較大小的規則(按照距離值排序)。
struct Node {
std::size_t index;
std::size_t distance;
Node(std::size_t index, std::size_t distance) : index(index), distance(distance) {}
inline bool operator>(Node another) const {
return distance > another.distance;
}
};
類定義
為節省空間和時間,我們改用鄰接列表的方式儲存圖。
class Graph2 {
struct Node {
std::size_t index;
std::size_t distance;
Node(std::size_t index, std::size_t distance) : index(index), distance(distance) {}
inline bool operator>(Node another) const {
return distance > another.distance;
}
};
std::size_t n;
std::vector<std::list<Node>> adj;
public:
Graph2(std::initializer_list<std::initializer_list<Node>> ll);
std::vector<std::size_t> dijkstra(std::size_t start);
};
演演算法程式碼
定義一個儲存節點的小根堆:
std::priority_queue<Node, std::vector<Node>, std::greater<>> heap;
每次遍歷某個節點的鄰接節點的時候,更新完其距離就將其扔到堆裡,以供下次取距離最小的節點的時候取出。你可能會問,萬一同一個節點多次入隊怎麼辦呢?這點不用擔心,即便佇列裡面有多個相同下標的節點,取出的也一定是其中距離最小的那個。而取出之後就在S裡面了,因此相同下標的其他節點取出後就可以直接丟棄。所以取出一個節點的時候先要判斷其是否處於S中,如果是的話就丟棄。否則就是V中距離最小的節點。
auto cur = heap.top();
heap.pop();
if (shortest[cur.index]) continue;
其餘部分相應的更改就是了。
std::vector<std::size_t> Graph2::dijkstra(std::size_t start) {
std::vector<bool> shortest(n, false);
std::vector<std::size_t> distance(n, INF);
distance[start] = 0;
std::priority_queue<Node, std::vector<Node>, std::greater<>> heap;
heap.emplace(start, 0); // 初始化
while (!heap.empty()) {
// 取出距離最小的頂點
auto cur = heap.top();
heap.pop();
if (shortest[cur.index]) continue; // 如果當前頂點處於S中,就丟棄
// 將其移入S中
shortest[cur.index] = true;
// 更新其鄰接節點的距離
for (auto &neighbor: adj[cur.index]) {
if (shortest[neighbor.index]) continue;
if (distance[cur.index] + neighbor.distance < distance[neighbor.index]) {
distance[neighbor.index] = distance[cur.index] + neighbor.distance;
heap.emplace(neighbor.index, distance[neighbor.index]);
}
}
}
return distance;
}
測試:
int main() {
std::size_t n = 6;
std::size_t start = 0;
Graph2 graph({
{{1, 4}, {2, 7}},
{{0, 4}, {2, 2}, {3, 10}},
{{0, 7}, {1, 2}, {3, 2}, {4, 3}},
{{1, 10}, {2, 2}, {4, 5}, {5, 8}},
{{2, 3}, {3, 5}, {5, 4}},
{{3, 8}, {4, 4}}
});
auto distance = graph.dijkstra(start);
for (std::size_t node = 0; node < n; node++) {
std::cout << start << "->" << node << ": " << distance[node] << std::endl;
}
return 0;
}
輸出:
0->0: 0
0->1: 4
0->2: 6
0->3: 8
0->4: 9
0->5: 13
時間複雜度分析
時間複雜度:O((n + m) * log(n))。(n為點數,m為邊數)
證明:
設每個節點平均擁有的邊數為k,即k=m/n。
每一次while迴圈,執行上述3個步驟,其中:
- 取出距離最小節點的時間複雜度為O(log(n)),這是因為取出後還要花O(log(n))的時間恢復二元堆積的堆序性。
- 移動到S中的時間複雜度為O(1)。
- 更新其鄰接節點的距離的時間複雜度為k * O(log(n)) = O(k * log(n)),這是因為放入堆中後還要花O(log(n))的時間恢復二元堆積的堆序性。
而while迴圈的次數有多少次呢,因為初始時S中有一個節點,每次while迴圈往S中增加一個節點,當S中有n個節點時停止迴圈。因此while迴圈的次數為n-1次,為O(n)量級。
所以,堆優化的Dijkstra演演算法的時間複雜度為:
O(n) * (O(log(n)) + O(1) + O(k * log(n)))
= O(n) * (k + 1) * O(log(n))
= O(n * k + n) * O(log(n))
= O(m + n) * O(log(n))
= O((n + m) * log(n))
本文來自部落格園,作者:YVVT_Real,轉載請註明原文連結:https://www.cnblogs.com/YWT-Real/p/17092649.html