記一次使用gdb診斷gc問題全過程
2023-02-04 21:00:50
原創:扣釘日記(微信公眾號ID:codelogs),歡迎分享,轉載請保留出處。
簡介
上次解決了GC長耗時問題後,系統果然平穩了許多,這是之前的文章《GC耗時高,原因竟是服務流量小?》
然而,過了一段時間,我檢查GC紀錄檔時,又發現了一個GC問題,如下:
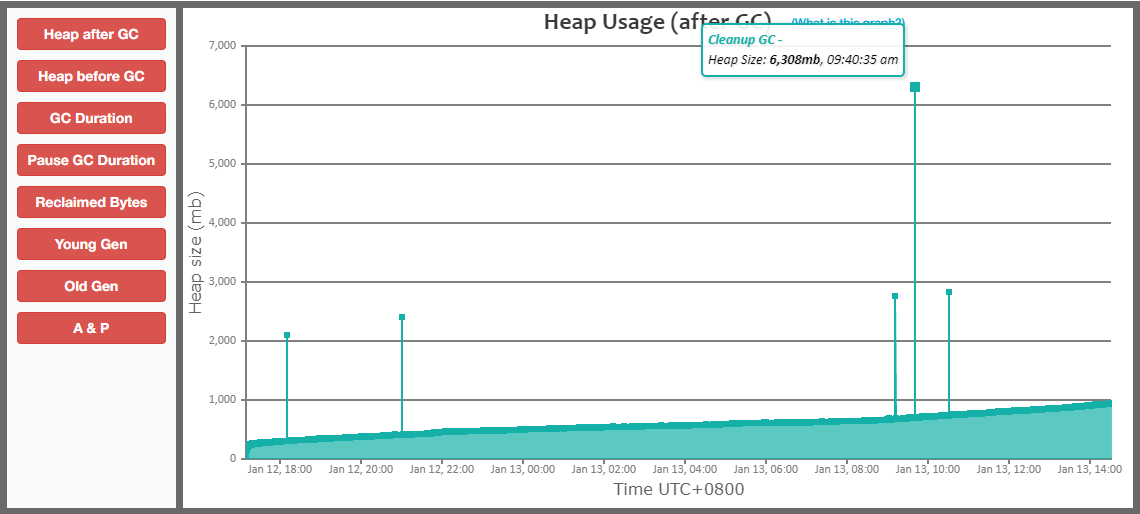
從這個圖中可以發現,我們GC有一些尖峰,有時會突然有大量的記憶體分配。
檢視GC紀錄檔,發現有大物件分配的記錄,如下:
$ grep 'concurrent humongous allocation' gc.log | awk 'match($0,/allocation request: (\w+) bytes/,a){print a[1]}' |sort -nr
1941835784
1889656848

可以看到,一次大物件分配,分配大小竟然有1.9G,這誰能抗得住啊!
async-profiler定位大物件分配
上面提到的文章介紹過,使用async-profiler可以很容易的定位大物件分配的呼叫棧,方法如下:
./profiler.sh start --all-user -e G1CollectedHeap::humongous_obj_allocate -f ./humongous.jfr jps
然後使用jmc開啟humongous.jfr檔案,呼叫棧如下:
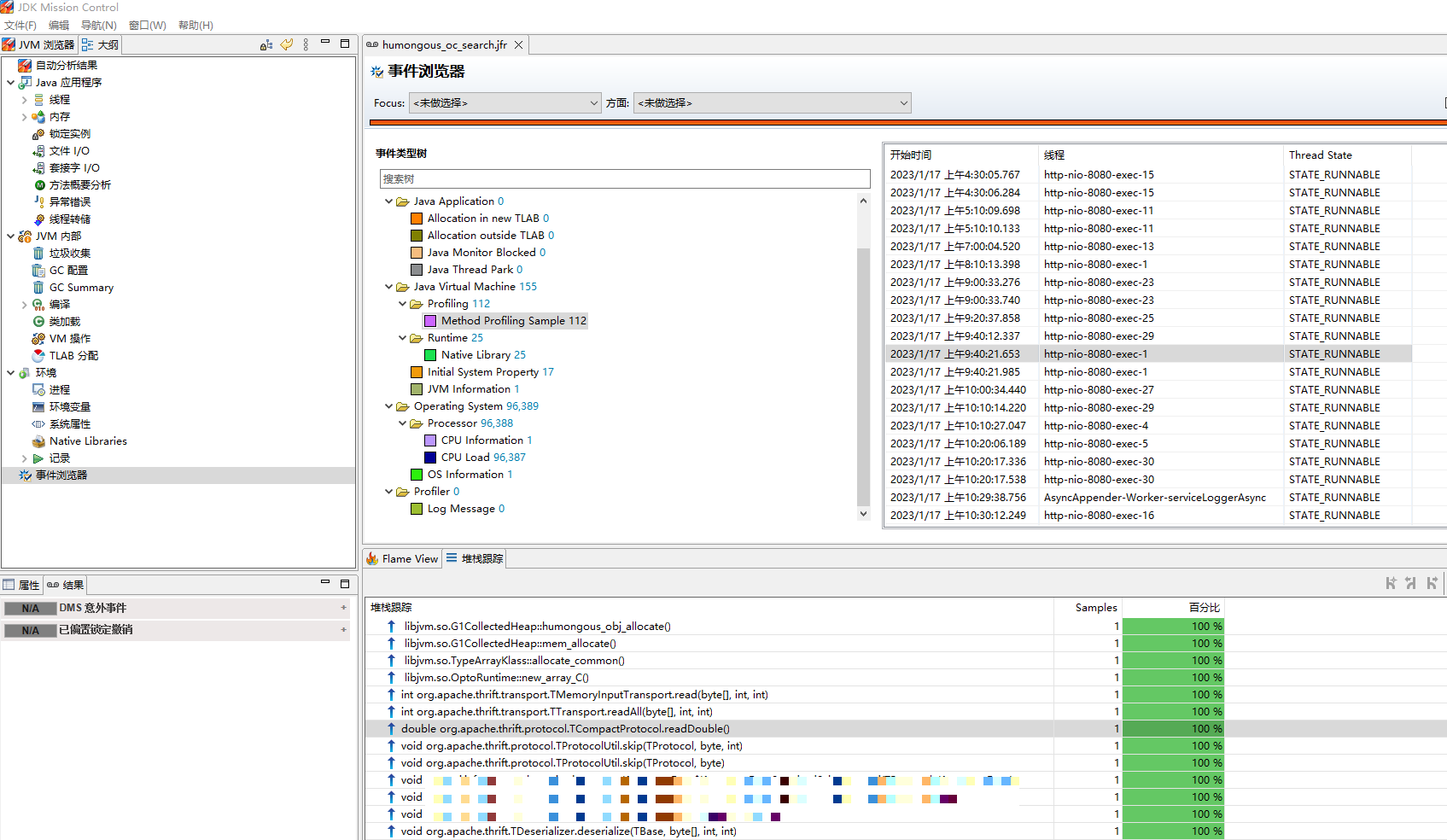
這是在做thrift反序列化操作,呼叫了TCompactProtocol.readDouble方法,方法程式碼如下:
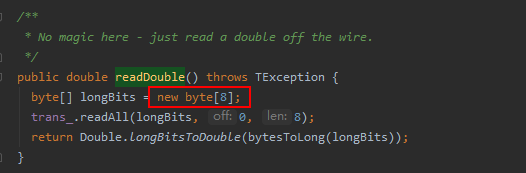
可是,這裡只建立了8位元組的陣列,怎麼也不可能需要分配1.9G記憶體吧,真是奇了怪了!
經過一番瞭解,這是因為async-profiler是通過AsyncGetCallTrace來獲取呼叫棧的,而AsyncGetCallTrace獲取的棧有時是不準的,Java社群有反饋過這個問題,至今未解決。

問題連結:https://bugs.openjdk.org/browse/JDK-8178287
尋找其它tracer
linux上有很多核心態的tracer,如perf、bcc、systemtap,但它們都需要root許可權,而我是不可能申請到這個許可權的