百萬級資料excel匯出功能如何實現?
前言
最近我做過一個MySQL百萬級別資料的excel匯出功能,已經正常上線使用了。
這個功能挺有意思的,裡面需要注意的細節還真不少,現在拿出來跟大家分享一下,希望對你會有所幫助。
原始需求:使用者在UI介面上點選全部匯出按鈕,就能匯出所有商品資料。
咋一看,這個需求挺簡單的。
但如果我告訴你,匯出的記錄條數,可能有一百多萬,甚至兩百萬呢?
這時你可能會倒吸一口氣。
因為你可能會面臨如下問題:
- 如果同步導資料,介面很容易超時。
- 如果把所有資料一次性裝載到記憶體,很容易引起OOM。
- 資料量太大sql語句必定很慢。
- 相同商品編號的資料要放到一起。
- 如果走非同步,如何通知使用者匯出結果?
- 如果excel檔案太大,目標使用者打不開怎麼辦?
我們要如何才能解決這些問題,實現一個百萬級別的excel資料快速匯出功能呢?
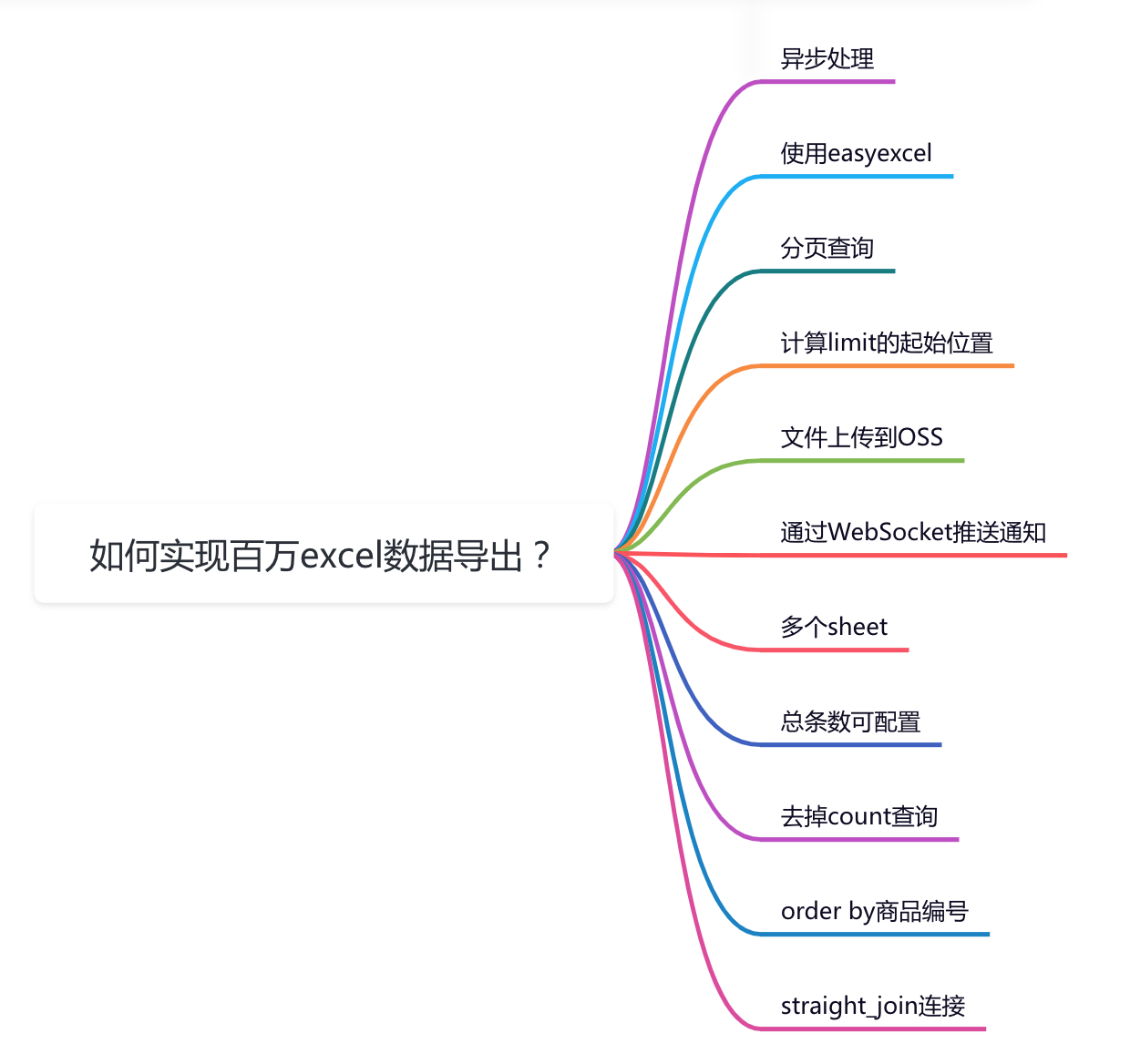
1.非同步處理
做一個MySQL百萬資料級別的excel匯出功能,如果走介面同步匯出,該介面肯定會非常容易超時。
因此,我們在做系統設計的時候,第一選擇應該是介面走非同步處理。
說起非同步處理,其實有很多種,比如:使用開啟一個執行緒,或者使用執行緒池,或者使用job,或者使用mq等。
為了防止服務重啟時資料的丟失問題,我們大多數情況下,會使用job或者mq來實現非同步功能。
1.1 使用job
如果使用job的話,需要增加一張執行任務表,記錄每次的匯出任務。
使用者點選全部匯出按鈕,會呼叫一個後端介面,該介面會向表中寫入一條記錄,該記錄的狀態為:待執行。
有個job,每隔一段時間(比如:5分鐘),掃描一次執行任務表,查出所有狀態是待執行的記錄。
然後遍歷這些記錄,挨個執行。
需要注意的是:如果用job的話,要避免重複執行的情況。比如job每隔5分鐘執行一次,但如果資料匯出的功能所花費的時間超過了5分鐘,在一個job週期內執行不完,就會被下一個job執行週期執行。
所以使用job時可能會出現重複執行的情況。
為了防止job重複執行的情況,該執行任務需要增加一個執行中的狀態。
具體的狀態變化如下:
- 執行任務被剛記錄到執行任務表,是
待執行狀態。 - 當job第一次執行該執行任務時,該記錄再資料庫中的狀態改為:
執行中。 - 當job跑完了,該記錄的狀態變成:
完成或失敗。
這樣匯出資料的功能,在第一個job週期內執行不完,在第二次job執行時,查詢待處理狀態,並不會查詢出執行中狀態的資料,也就是說不會重複執行。
此外,使用job還有一個硬傷即:它不是立馬執行的,有一定的延遲。
如果對時間不太敏感的業務場景,可以考慮使用該方案。
1.2 使用mq
使用者點選全部匯出按鈕,會呼叫一個後端介面,該介面會向mq伺服器端,傳送一條mq訊息。
有個專門的mq消費者,消費該訊息,然後就可以實現excel的資料匯出了。
相較於job方案,使用mq方案的話,實時性更好一些。
對於mq消費者處理失敗的情況,可以增加補償機制,自動發起重試。
RocketMQ自帶了失敗重試功能,如果失敗次數超過了一定的閥值,則會將該訊息自動放入死信佇列。
2.使用easyexcel
我們知道在Java中解析和生成Excel,比較有名的框架有Apache POI和jxl。
但它們都存在一個嚴重的問題就是:非常耗記憶體,POI有一套SAX模式的API可以一定程度的解決一些記憶體溢位的問題,但POI還是有一些缺陷,比如07版Excel解壓縮以及解壓後儲存都是在記憶體中完成的,記憶體消耗依然很大。
百萬級別的excel資料匯出功能,如果使用傳統的Apache POI框架去處理,可能會消耗很大的記憶體,容易引發OOM問題。
而easyexcel重寫了POI對07版Excel的解析,之前一個3M的excel用POI sax解析,需要100M左右記憶體,如果改用easyexcel可以降低到幾M,並且再大的Excel也不會出現記憶體溢位;03版依賴POI的sax模式,在上層做了模型轉換的封裝,讓使用者更加簡單方便。
需要在maven的pom.xml檔案中引入easyexcel的jar包:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.0.2</version>
</dependency>
之後,使用起來非常方便。
讀excel資料非常方便:
@Test
public void simpleRead() {
String fileName = TestFileUtil.getPath() + "demo" + File.separator + "demo.xlsx";
// 這裡 需要指定讀用哪個class去讀,然後讀取第一個sheet 檔案流會自動關閉
EasyExcel.read(fileName, DemoData.class, new DemoDataListener()).sheet().doRead();
}
寫excel資料也非常方便:
@Test
public void simpleWrite() {
String fileName = TestFileUtil.getPath() + "write" + System.currentTimeMillis() + ".xlsx";
// 這裡 需要指定寫用哪個class去讀,然後寫到第一個sheet,名字為模板 然後檔案流會自動關閉
// 如果這裡想使用03 則 傳入excelType引數即可
EasyExcel.write(fileName, DemoData.class).sheet("模板").doWrite(data());
}
easyexcel能大大減少佔用記憶體的主要原因是:在解析Excel時沒有將檔案資料一次性全部載入到記憶體中,而是從磁碟上一行行讀取資料,逐個解析。
3.分頁查詢
百萬級別的資料,從資料庫一次性查詢出來,是一件非常耗時的工作。
即使我們可以從資料庫中一次性查詢出所有資料,沒出現連線超時問題,這麼多的資料全部載入到應用服務的記憶體中,也有可能會導致應用服務出現OOM問題。
因此,我們從資料庫中查詢資料時,有必要使用分頁查詢。比如:每頁5000條記錄,分為200頁查詢。
public Page<User> searchUser(SearchModel searchModel) {
List<User> userList = userMapper.searchUser(searchModel);
Page<User> pageResponse = Page.create(userList, searchModel);
pageResponse.setTotal(userMapper.searchUserCount(searchModel));
return pageResponse;
}
每頁大小pageSize和頁碼pageNo,是SearchModel類中的成員變數,在建立searchModel物件時,可以設定設定這兩個引數。
然後在Mybatis的sql檔案中,通過limit語句實現分頁功能:
limit #{pageStart}, #{pageSize}
其中的pagetStart引數,是通過pageNo和pageSize動態計算出來的,比如:
pageStart = (pageNo - 1) * pageSize;
4.多個sheet
我們知道,excel對一個sheet存放的最巨量資料量,是有做限制的,一個sheet最多可以儲存1048576行資料。否則在儲存資料時會直接報錯:
invalid row number (1048576) outside allowable range (0..1048575)
如果你想匯出一百萬以上的資料,excel的一個sheet肯定是存放不下的。
因此我們需要把資料儲存到多個sheet中。
5.計算limit的起始位置
我之前說過,我們一般是通過limit語句來實現分頁查詢功能的:
limit #{pageStart}, #{pageSize}
其中的pagetStart引數,是通過pageNo和pageSize動態計算出來的,比如:
pageStart = (pageNo - 1) * pageSize;
如果只有一個sheet可以這麼玩,但如果有多個sheet就會有問題。因此,我們需要重新計算limit的起始位置。
例如:
ExcelWriter excelWriter = EasyExcelFactory.write(out).build();
int totalPage = searchUserTotalPage(searchModel);
if(totalPage > 0) {
Page<User> page = Page.create(searchModel);
int sheet = (totalPage % maxSheetCount == 0) ? totalPage / maxSheetCount: (totalPage / maxSheetCount) + 1;
for(int i=0;i<sheet;i++) {
WriterSheet writeSheet = buildSheet(i,"sheet"+i);
int startPageNo = i*(maxSheetCount/pageSize)+1;
int endPageNo = (i+1)*(maxSheetCount/pageSize);
while(page.getPageNo()>=startPageNo && page.getPageNo()<=endPageNo) {
page = searchUser(searchModel);
if(CollectionUtils.isEmpty(page.getList())) {
break;
}
excelWriter.write(page.getList(),writeSheet);
page.setPageNo(page.getPageNo()+1);
}
}
}
這樣就能實現分頁查詢,將資料匯出到不同的excel的sheet當中。
6.檔案上傳到OSS
由於現在我們匯出excel資料的方案改成了非同步,所以沒法直接將excel檔案,同步返回給使用者。
因此我們需要先將excel檔案存放到一個地方,當用戶有需要時,可以存取到。
這時,我們可以直接將檔案上傳到OSS檔案伺服器上。
通過OSS提供的上傳介面,將excel上傳成功後,會返回檔名稱和存取路徑。
我們可以將excel名稱和存取路徑儲存到表中,這樣的話,後面就可以直接通過瀏覽器,存取遠端excel檔案了。
而如果將excel檔案儲存到應用伺服器,可能會佔用比較多的磁碟空間。
一般建議將應用伺服器和檔案伺服器分開,應用伺服器需要更多的記憶體資源或者CPU資源,而檔案伺服器需要更多的磁碟資源。
7.通過WebSocket推播通知
通過上面的功能已經匯出了excel檔案,並且上傳到了OSS檔案伺服器上。
接下來的任務是要本次excel匯出結果,成功還是失敗,通知目標使用者。
有種做法是在頁面上提示:正在匯出excel資料,請耐心等待。
然後使用者可以主動重新整理當前頁面,獲取本地匯出excel的結果。
但這種使用者互動功能,不太友好。
還有一種方式是通過webSocket建立長連線,進行實時通知推播。
如果你使用了SpringBoot框架,可以直接引入webSocket的相關jar包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
使用起來挺方便的。
我們可以加一張專門的通知表,記錄通過webSocket推播的通知的標題、使用者、附件地址、閱讀狀態、型別等資訊。
能更好的追溯通知記錄。
webSocket給使用者端推播一個通知之後,使用者的右上角的收件箱上,實時出現了一個小視窗,提示本次匯出excel功能是成功還是失敗,並且有檔案下載連結。
當前通知的閱讀狀態是未讀。
使用者點選該視窗,可以看到通知的詳細內容,然後通知狀態變成已讀。
8.總條數可設定
我們在做導百萬級資料這個需求時,是給使用者用的,也有可能是給運營同學用的。
其實我們應該站在實際使用者的角度出發,去思考一下,這個需求是否合理。
使用者拿到這個百萬級別的excel檔案,到底有什麼用途,在他們的電腦上能否開啟該excel檔案,電腦是否會出現太大的卡頓了,導致檔案使用不了。
如果該功能上線之後,真的發生發生這些情況,那麼匯出excel也沒有啥意義了。
因此,非常有必要把記錄的總條數,做成可設定的,可以根據使用者的實際情況調整這個設定。
比如:使用者發現excel中有50萬的資料,可以正常存取和操作excel,這時候我們可以將總條數調整成500000,把多餘的資料擷取掉。
其實,在使用者的操作介面,增加更多的查詢條件,使用者通過修改查詢條件,多次導資料,可以實現將所有資料都匯出的功能,這樣可能更合理一些。
此外,分頁查詢時,每頁的大小,也建議做成可設定的。
通過總條數和每頁大小,可以動態調整記錄數量和分頁查詢次數,有助於更好滿足使用者的需求。
9.order by商品編號
之前的需求是要將相同商品編號的資料放到一起。
例如:
| 編號 | 商品名稱 | 倉庫名稱 | 價格 |
|---|---|---|---|
| 1 | 筆電 | 北京倉 | 7234 |
| 1 | 筆電 | 上海倉 | 7235 |
| 1 | 筆電 | 武漢倉 | 7236 |
| 2 | 平板電腦 | 成都倉 | 7236 |
| 2 | 平板電腦 | 大連倉 | 3339 |
但我們做了分頁查詢的功能,沒法將資料一次性查詢出來,直接在Java記憶體中分組或者排序。
因此,我們需要考慮在sql語句中使用order by 商品編號,先把資料排好順序,再查詢出資料,這樣就能將相同商品編號,倉庫不同的資料放到一起。
此外,還有一種情況需要考慮一下,通過設定的總記錄數將全部資料做了擷取。
但如果最後一個商品編號在最後一頁中沒有查詢完,可能會導致匯出的最後一個商品的資料不完整。
因此,我們需要在程式中處理一下,將最後一個商品刪除。
但加了order by關鍵字進行排序之後,如果查詢sql中join了很多張表,可能會導致查詢效能變差。
那麼,該怎麼辦呢?
總結
最後用兩張圖,總結一下excel非同步導資料的流程。
如果是使用mq導資料:
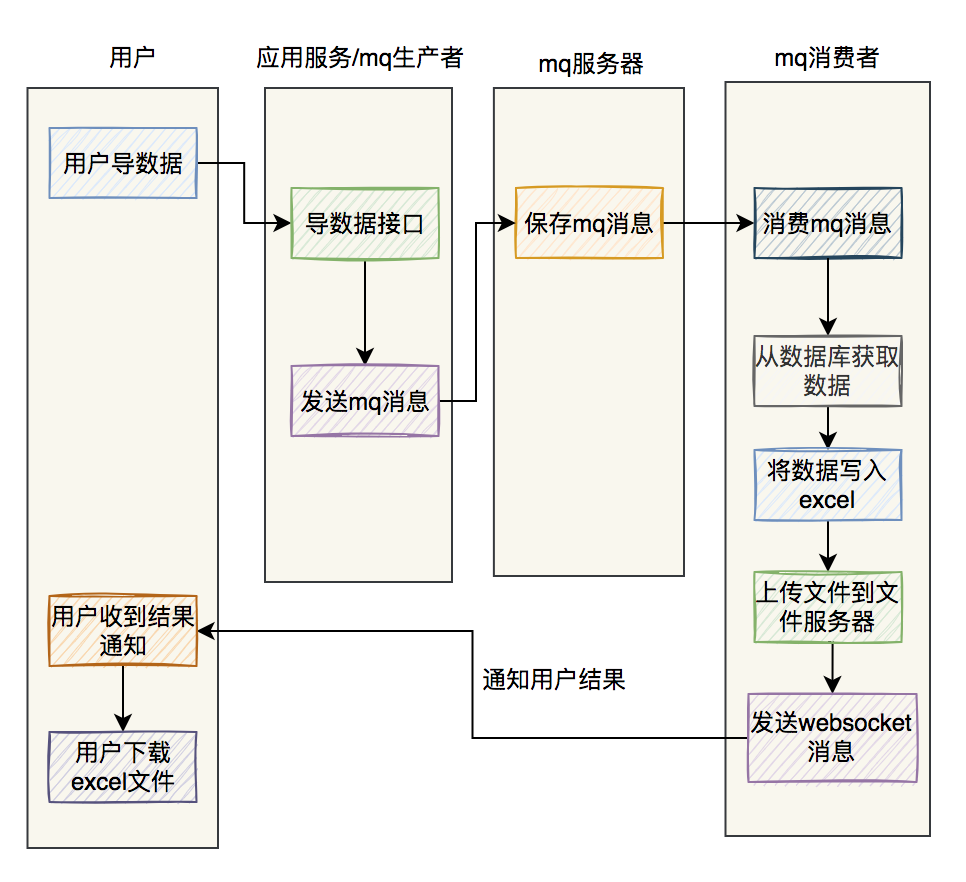
如果是使用job導資料:
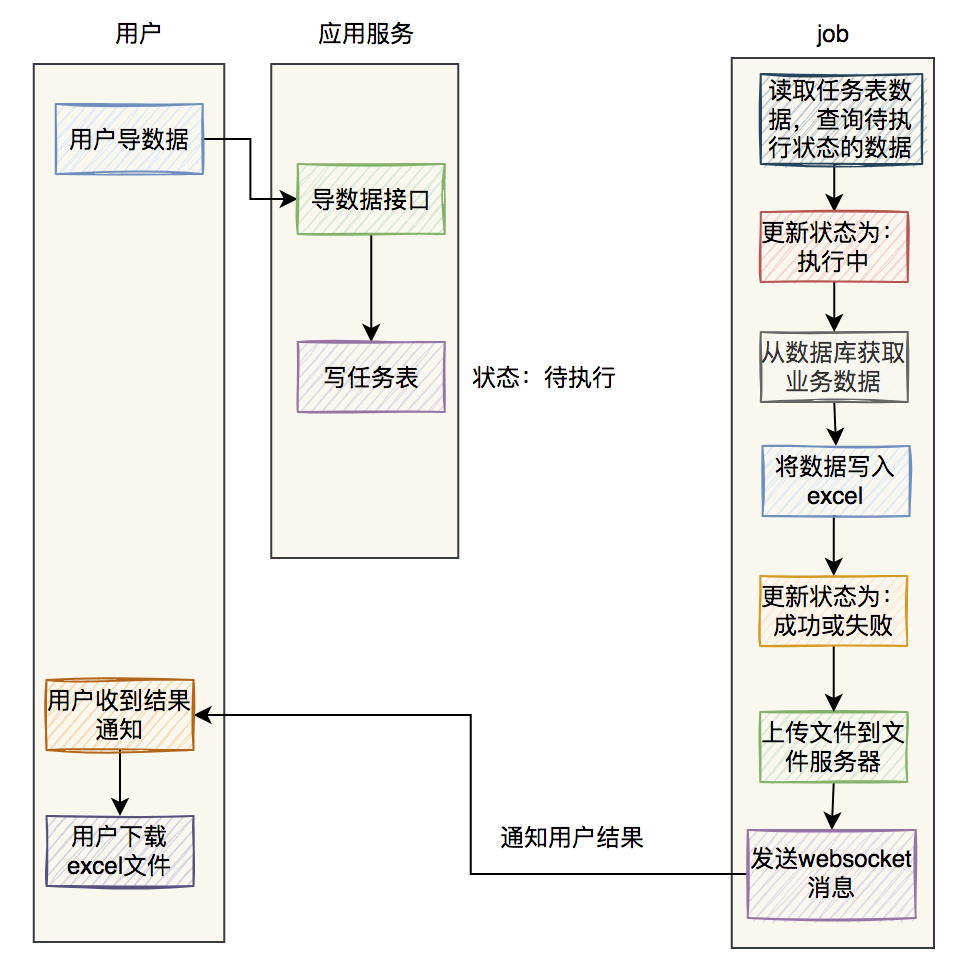
這兩種方式都可以,可以根據實際情況選擇使用。
最後說一句(求關注,別白嫖我)
如果這篇文章對您有所幫助,或者有所啟發的話,幫忙掃描下發二維條碼關注一下,您的支援是我堅持寫作最大的動力。
求一鍵三連:點贊、轉發、在看。
關注公眾號:【蘇三說技術】,在公眾號中回覆:面試、程式碼神器、開發手冊、時間管理有超讚的粉絲福利,另外回覆:加群,可以跟很多BAT大廠的前輩交流和學習。