Java微服務隨機掉線排查思路
背景
- 我們的業務共使用11臺(阿里雲)伺服器,使用SpringcloudAlibaba構建微服務叢集,共計60個微服務,全部註冊在同一個Nacos叢集
- 流量轉發路徑: nginx->spring-gateway->業務微服務
- 使用的版本如下:
spring-boot.version:2.2.5.RELEASE
spring-cloud.version:Hoxton.SR3
spring-cloud-alibaba.version:2.2.1.RELEASE
java.version:1.8
案發
- 春節放假期間,收到反饋,網頁報錯服務未找到(gateway找不到服務的報錯提示).
- 檢視nacos叢集列表,發現個別服務丟失(下線).
- 這個問題每幾天出現一次,出現時間不固定,每次掉線的服務像是隨機選的幾個.
- 服務手動kill+restart後能穩定執行2-3天
排查和解決
懷疑物件一:伺服器記憶體爆了
1.進阿里雲控制檯檢視故障機器近期的各項指標,但是發現故障機器的指標有重要的幾項丟失,記憶體使用率,cpu使用率,系統負載均不顯示
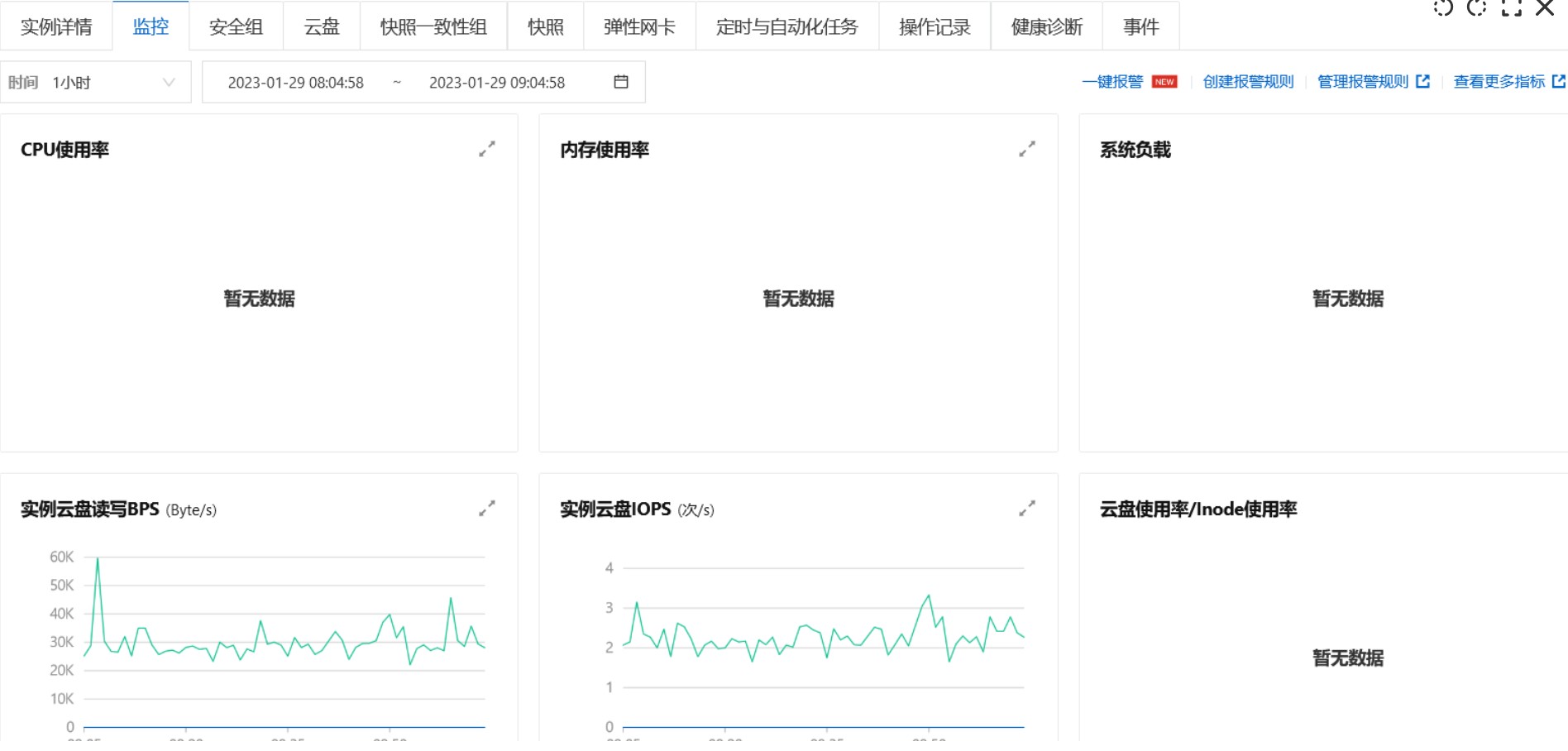
2.控制檯看不了只好進伺服器內檢視各指標
free -m 檢視記憶體,無異常
3.提交阿里工單,授權阿里工程師幫忙修復控制檯顯示問題,懷疑這個問題對業務有影響
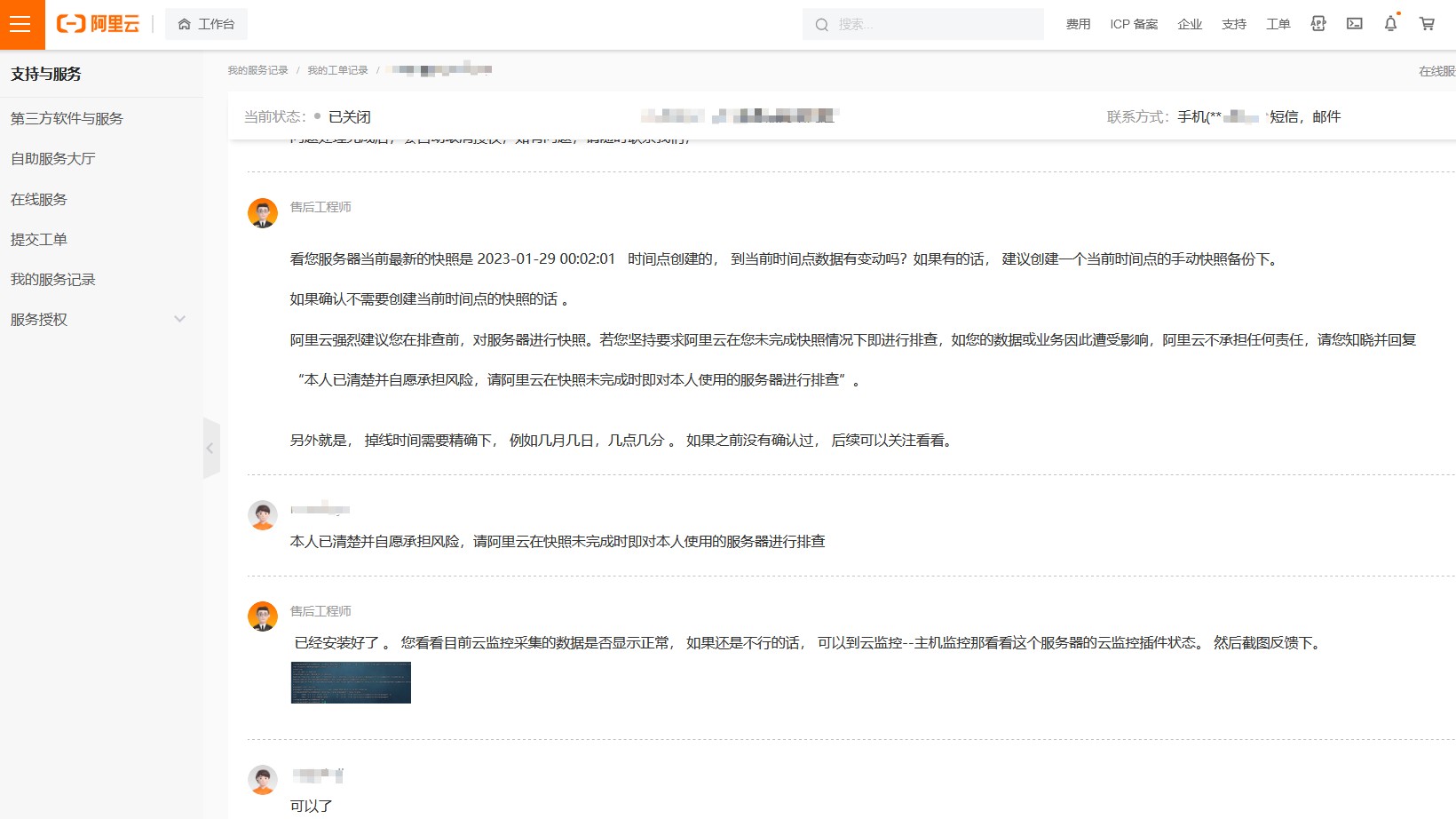
4.控制檯修復後掉線問題依然存在
懷疑物件二:CPU滿載
能感覺到執行命令很流暢,所以感覺不是這個原因, top檢視後很正常
懷疑物件三:磁碟滿了
雖然概率很小,但是看一下,du -sh *發現磁碟容量還能用到公司倒閉
懷疑物件四:網路有問題
- 伺服器那三個基本故障暫時排除後,最大懷疑物件就是網路,畢竟服務掉線肯定是伺服器端一段時間內接收不到使用者端心跳包,所以把使用者端踢下線了.
- 通過
telnet,mtr -n *.*.*.*,netstat -nat |grep "TIME_WAIT" | wc -l這些命令也只能看個大概. echo "1" > /proc/sys/net/ipv4/tcp_tw_reuse修改核心引數,開啟TIME_WAIT socket複用能力,提升範例的網路傳送請求效能.- 檢視nacos使用者端(微服務)的紀錄檔,在前面案發裡提到沒有紀錄檔記錄
懷疑物件五:Nacos叢集伺服器端故障
- 檢視nacos叢集部署的那幾臺伺服器,檢視伺服器基礎指標(記憶體,cpu,磁碟等),未發現異常(畢竟還有幾十個微服務都很正常工作)
- 檢視nacos伺服器端紀錄檔,發現確實有主動下線服務操作,那就奇怪了,這個機器上的有些服務還在正常工作,為什麼會隨機下線幾個服務呢?
懷疑物件六:微服務佔用資源太多
後來仔細想想,這個懷疑物件是不是有點離譜了?因為部署指令碼都是同一個,而且負載均衡也是一樣的,但其他機器的這個服務都好好的.
1.調大每個微服務的記憶體佔用
2.新增堆疊列印

3.等待一段時間後,異常依然存在,並且,沒有堆疊列印???因為程序好好的並沒退出!
4.google搜尋nacos服務掉線,找到一篇看起來極其靠譜的文章!
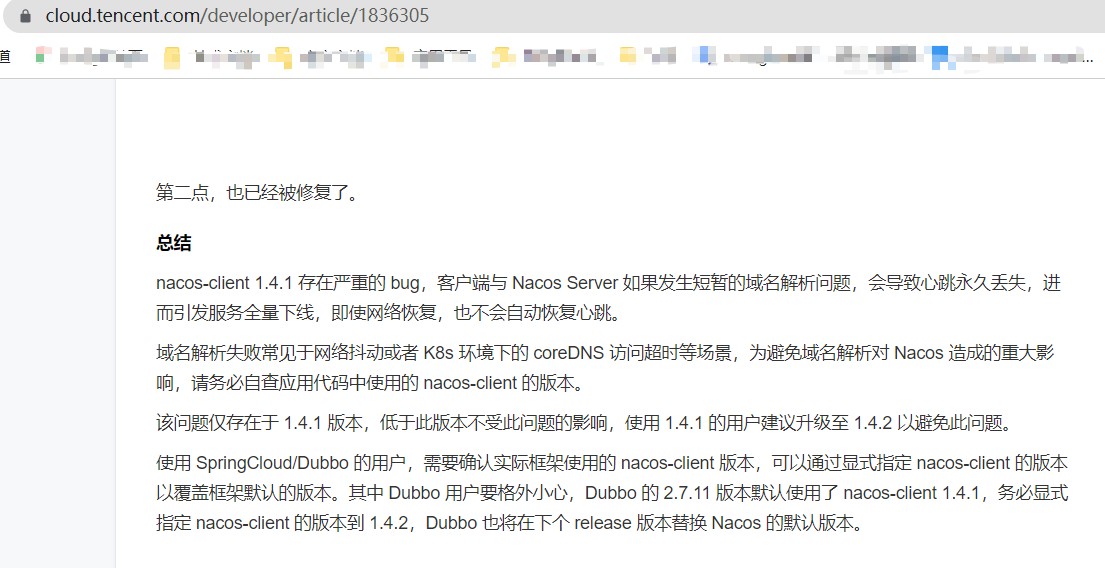
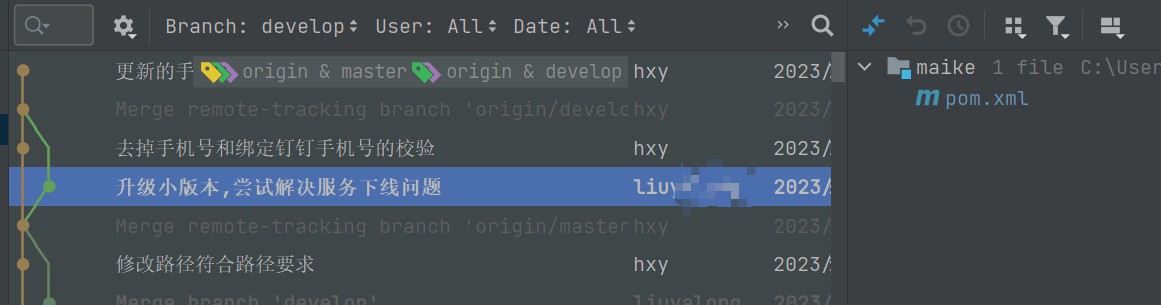
5.上文提到我使用的springcloud版本,恰好這個版本的nacos-client版本就是1.4.1,於是立馬測試升級
6.觀察幾天後,發現問題依舊,只能將探查方向繼續轉回微服務本身.
7.使用arthas進行勘測各項指標,發現所有正常的服務各指標均正常.
8.想到服務掉線大概率是因為心跳包丟失,懷疑是心跳執行緒因為某些原因被殺死了.
9.翻看nacos-client原始碼,找到心跳函數(nacos2.x不是這個),使用arthas監聽心跳包,嘗試能找到心跳丟失的證據,貼上當時的記錄

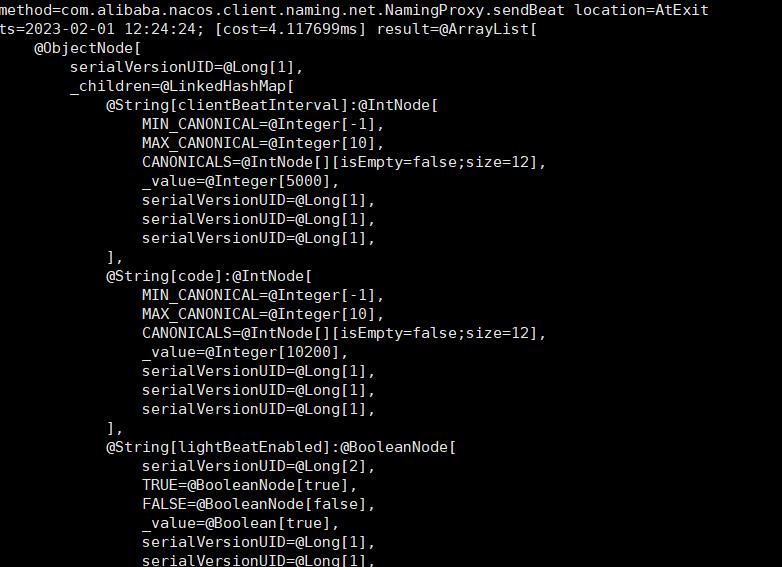
10.當異常再次發生......arthas監聽卡死,無任何記錄和響應........
11.無奈更換思路,寫一個監聽服務掉線的程式,期望可以在工作時間內及時獲取到異常
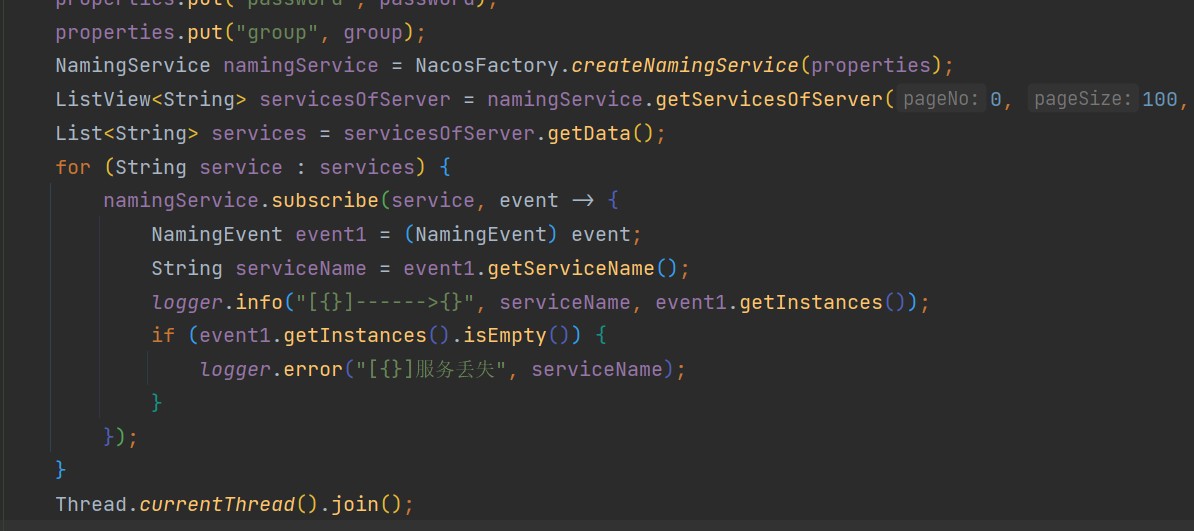
12.終於在工作時間捕獲到異常,第一時間進入伺服器內檢視情況,

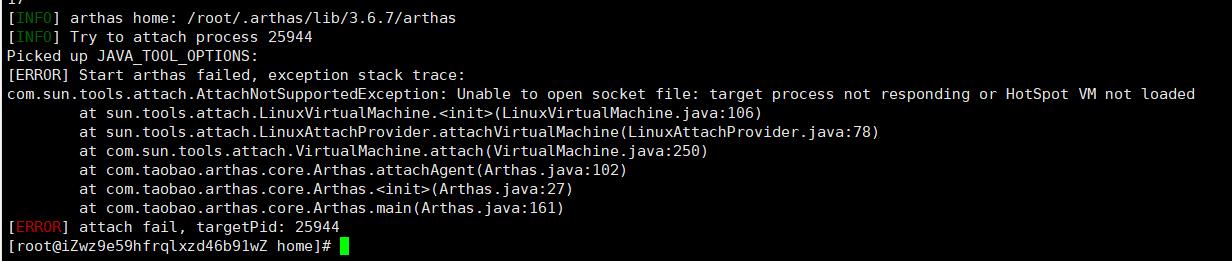
13.確認伺服器基礎項沒問題後,使用arthas檢視服務程序堆疊情況,但是arthas無法進入程序!!!
14.用jstat檢視GC情況,顯示很正常

15.用jmap/jstack輸出堆疊jstack -l 25944 >heap.txt,但是提示無法進入程序,無奈使用新增-F(這個引數的堆疊少了很多資訊),jstack -F -l 25944 >heap.txt
16.檢視堆疊檔案,上萬行記錄,眼都看花了,但是沒有死鎖也沒有發現異常
17.此時發現監聽程式提示服務上線了???!!!檢查後發現確實掉線的幾個微服務自動恢復了,心想這就難排查了.
18.嘗試復現BUG,此時離第一次案發已經過去一週多,必須儘快處理好這個BUG,否則可能得被迫離職了...
19.當第二次發生異常的時候,使用同樣的方式,arthas無法進入->...->jstack輸出堆疊,奇蹟發生了,服務又恢復正常了
20.思考/猜測:因為jvm死了(假死),所以導致程序中的一切內容,包括心跳執行緒,紀錄檔等,都hold住.
20.Google搜尋關鍵詞jvm停止(假死)排查,終於找到一個極其靠譜的回答
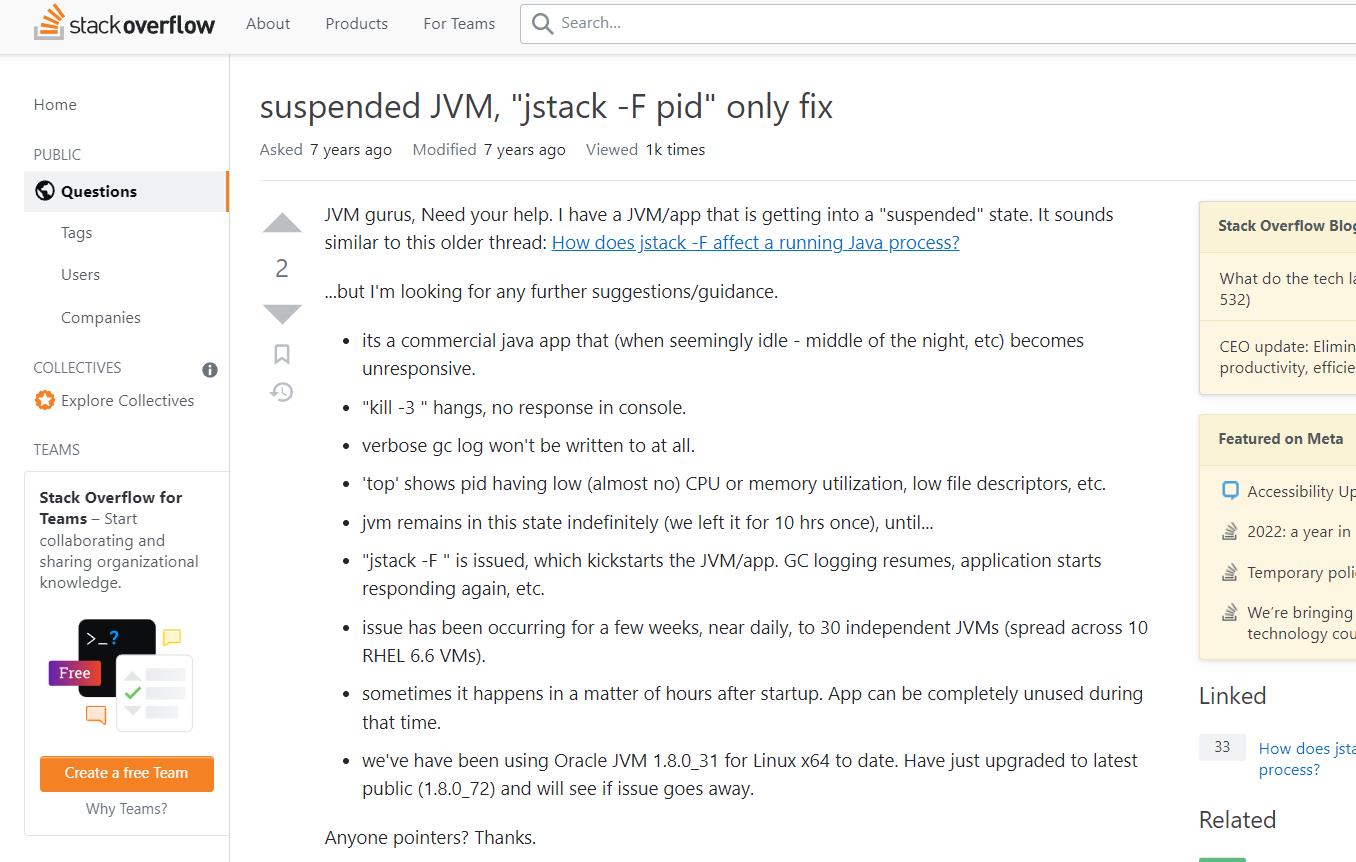
21.連忙檢視對比使用的幾個機器核心版本號uname -r


22.那個低版本的就是故障機器,確認相關資訊後,聯絡阿里雲提交工單
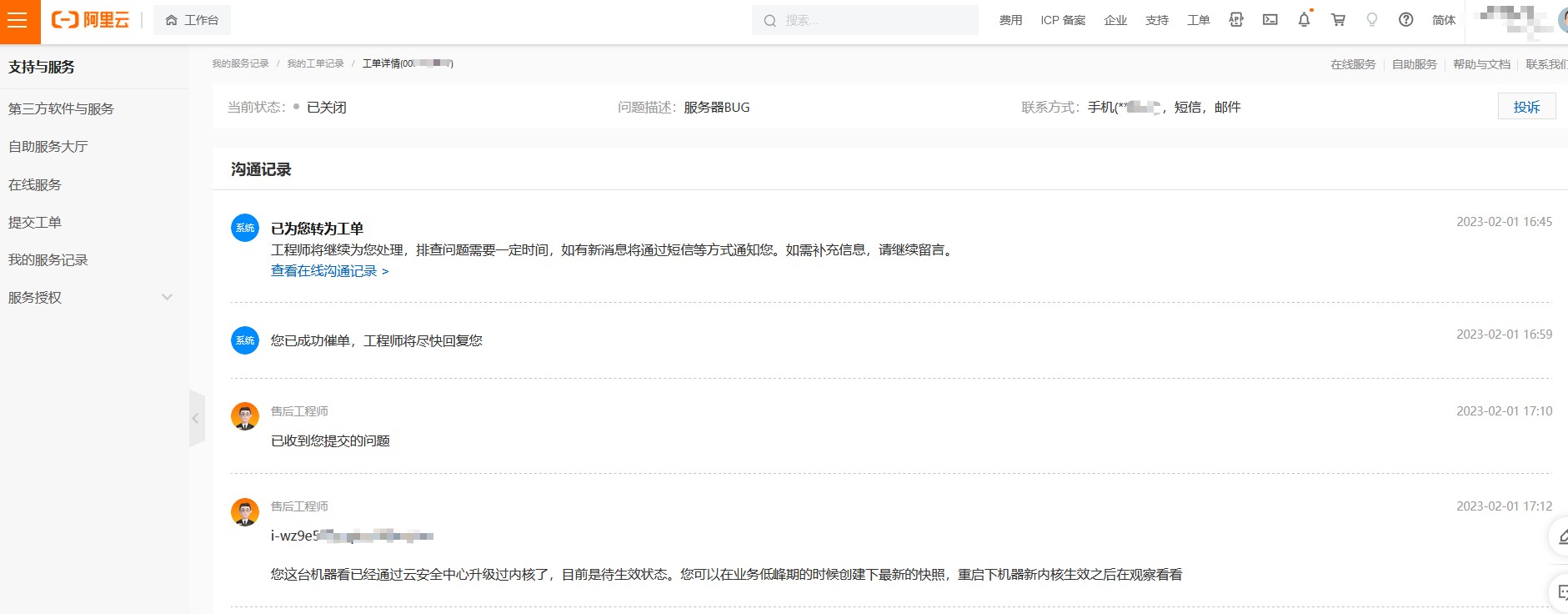
23.升級完核心並重啟後機器後,觀察兩天至今,這個問題不存在了,誰能想到這個問題居然是因為Linux核心的BUG引起的,不得不佩服第一個發現這個BUG的大佬
完結感言
這個問題折磨了一週多,每日如鯁在喉!偵錯過程也是苦樂參半,樂的是突然有了偵錯思路,苦的是思路是一條死衚衕,還好最終結果是滿意的.
作為一名程式設計師,還是要時刻保持一顆探索的心,學海無涯!
2023-02-03 記於深圳