Java集合 Map 集合 與 操作集合的工具類: Collections 的詳細說明
Java集合 Map 集合 與 操作集合的工具類: Collections 的詳細說明

每博一文案
別把人生,輸給心情
師父說:心情不是人生的全部,卻能左右人生的全部。
你有沒有體會到,當你心情好的時候,生活彷彿陽光燦爛,順風順水,
當你心情不好的時候,似乎周圍的一切都糟糕透了。
有時候,我們不是輸給了別人,而是敗給了壞心情的自己。
人活著就像一個陀螺,為了生活不停的轉動,永遠都有忙不完的事。
有時候又像沙漠中的駱駝,揹負著重擔努力地前行,卻不知道哪裡才是終點。
先現在情緒低落,只是因為陷進了自我糾纏的陷阱,等到熬過了這段苦難,
你會發現你所糾結的東西,真的只是無關痛癢的小事。
生活就像天氣,不會總是晴天,也不會一直陰雨,喜歡和討厭是次要的,關鍵是你要學會調整自己。
心靜了,才能聽見自己的心聲,心清了,才能照見萬物的本性。
假如任由壞情緒累積和蔓延,很多事只會變得越來越糟糕,
既然做不到讓所有人都滿意,為何不努力讓自己開心?
生活是你自己的,喜怒悲歡都由你自己決定,記得別被壞情緒束縛住,
不要讓你的人生,輸給了心情。
—————— 一禪心靈廟語
1. Map介面概述
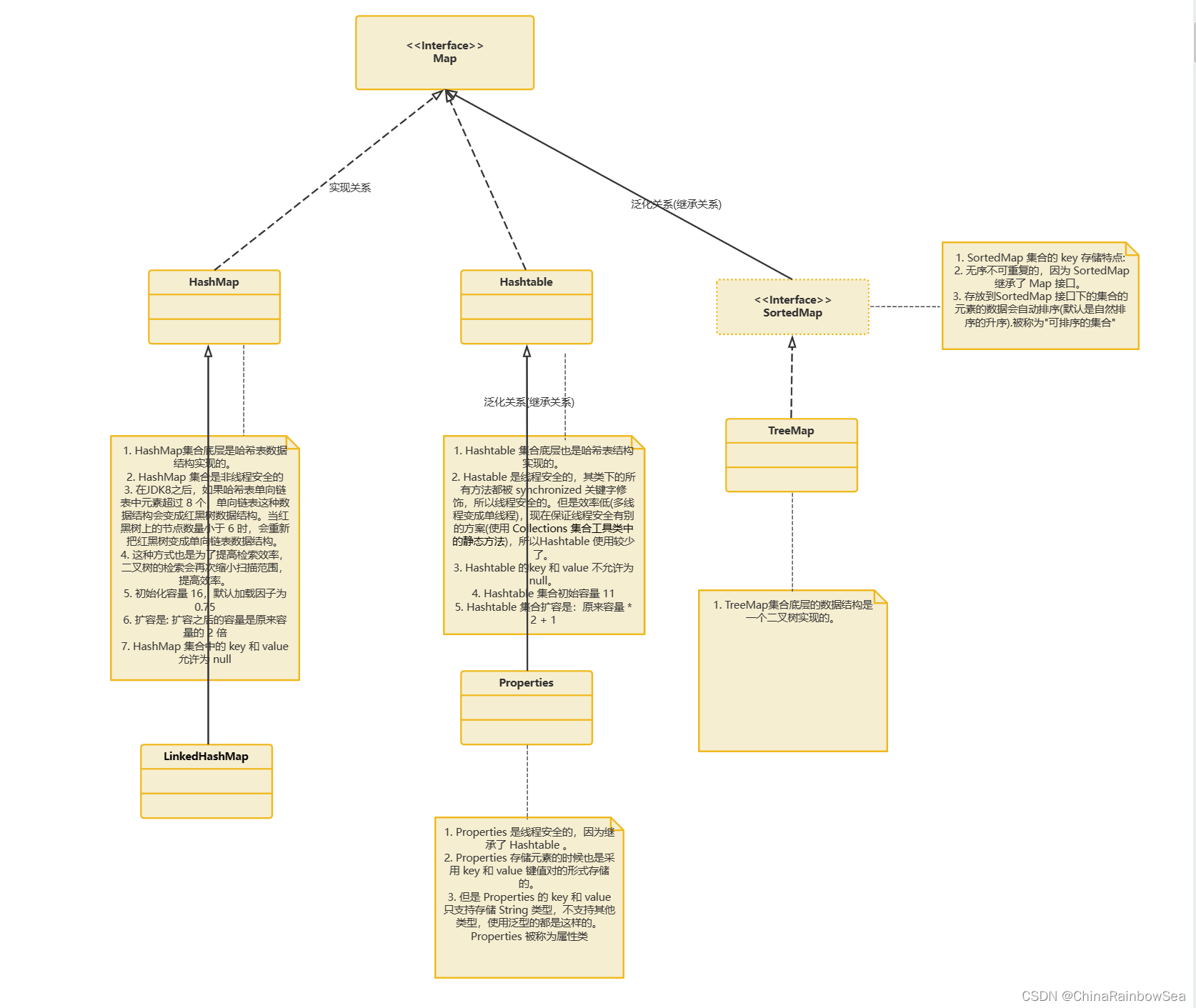
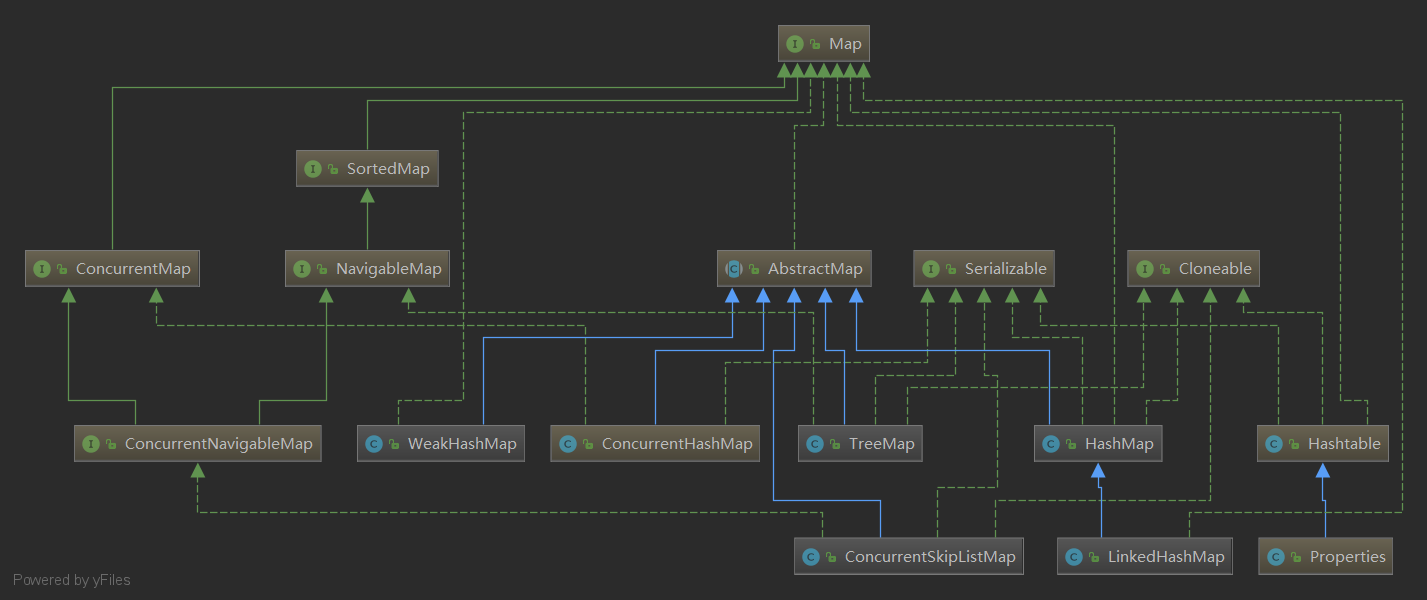
-
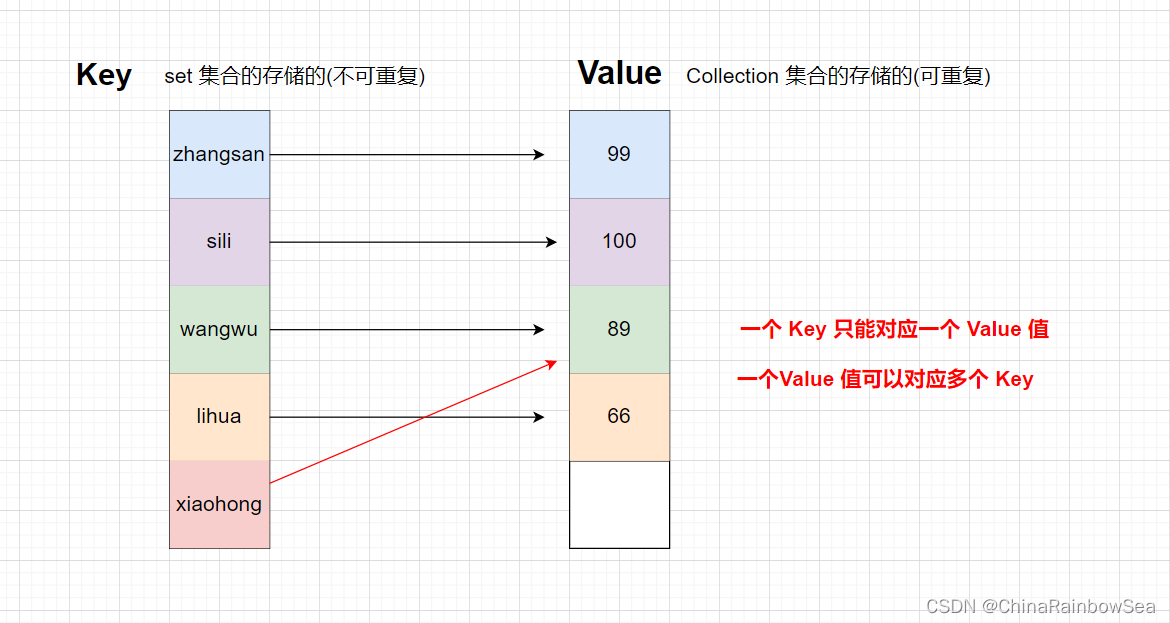
Map 介面與 Collection 並列存在的,用於儲存具有對映關係的資料:key-value 被稱為 鍵值對 。
-
Java集合可分為 Collection 和 Map 兩種體系。
- Collection 介面:單例資料,定義了存取一組物件的方法的集合。
- List : 元素有序,可重複的集合。
- Set :元素無序,不可重複的集合。
- Map 介面:雙列資料,儲存具有對映關係」key-value對「 的集合。
- Collection 介面:單例資料,定義了存取一組物件的方法的集合。
-
Map 中的 key 和 value 都可以是任何參照型別的資料。
- key 和 value 都是參照資料型別,都是儲存物件的記憶體地址的。不是基本資料型別。
- 其中 key 起到主導地位,value 是 key 的一個附屬品。
-
Map 中的 key 用 Set 集合儲存的,不允許重複。即同一個 Map 物件所對應的類,必須重寫hashCode() 和 equals() 方法。但是其中的 value 值是可以儲存重複的資料的。而 value 值則是被 Collection 介面集合儲存的。
-
常用 String 類作為 Map 的 」鍵「。
-
key 和 value 之間存在單向一對一關係,即通過指定的 key 總能找到唯一的,確定的 value 。
-
Map 介面的常用實現類:
- HashMap 作為Map的主要實現類,執行緒不安全的,效率高,可以儲存 null 的key 和 value。HashMap是 Map 介面使用頻率最高的實現類
- LinkedHashMap 保證再遍歷Map元素時,可以按照新增的順序實現遍歷,原因: 在原有的HashMap底層結構基礎上,新增了一對指標,指向前一個和後一個元素。對於頻繁的遍歷操作,此類執行效率高於HashMap
- TreeMap 保證按照新增的 key-value鍵值對進行排序,實現排序遍歷.此時考慮key的自然排序或客製化排序,底層使用紅黑樹:
- Hashtalbe 作為古老的實現類,執行緒安全的,效率低,不可以儲存 null
- Properties 主要用於組態檔的讀取。
-
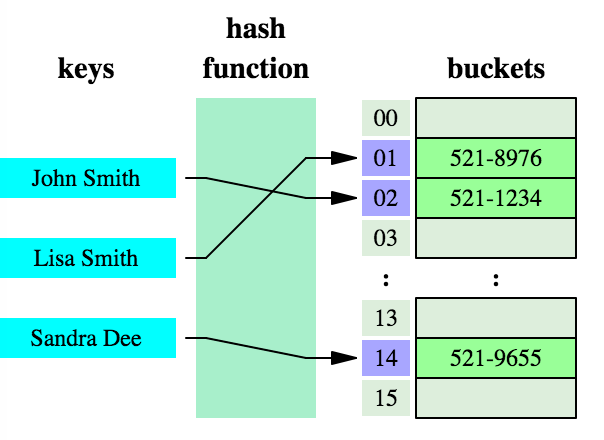
鍵值對的示圖:
2. Map介面:常用方法
新增、刪除、修改操作:
- put(K key, V value) : 將指定的 key 和 value 值新增/修改到該集合當中。
V put(K key,V value); // 將指定的 key 和 value 值新增/修改到該集合當中。
- putAll(Map m) : 將 m 中所有的key-value 值存放到當前 物件集合當中。
void putAll(Map<? extends K,? extends V> m); // 將m中的所有key-value對存放到當前map集合當中
- remove(Object key) : 移除指定key的key-value對,並返回value。
V remove(Object key); // 移除指定key的key-value對,並返回value
- clear() : 清空當前map中的所有資料。
void clear(); // 清空當前map中的所有資料
- size() : 返回此集合中儲存的元素資料(鍵值對)的數量。
int size(); // 返回此集合中儲存的元素資料(鍵值對)的數量。
舉例:
import java.util.HashMap;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
// Map 介面 , HashMap實現類,多型,<String,Integer> 泛型
Map<String,Integer> map = new HashMap<String,Integer>();
// 新增元素資料:
map.put("zhangsan",66);
map.put("lisi",89);
map.put("wangwu",97);
map.put("lihua",99);
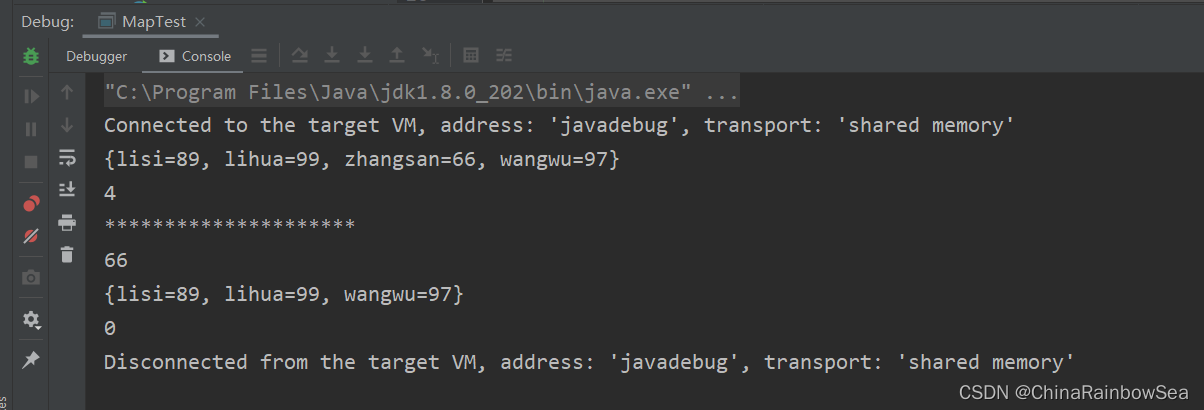
System.out.println(map);
int size = map.size(); // 返回該集合中儲存的鍵值對的數量。
System.out.println(size);
System.out.println("*********************");
Integer zhangsan = map.remove("zhangsan"); // 移除key = zhangsan的元素資料,並返回該移除的value值。
System.out.println(zhangsan);
System.out.println(map);
map.clear(); // 清空該Map 集合當中的儲存的元素資料
System.out.println(map.size());
}
}
舉例
import java.util.HashMap;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
// Map 介面 , HashMap實現類,多型,<String,Integer> 泛型
Map<String,Integer> map = new HashMap<String,Integer>();
// 新增元素資料:
map.put("zhangsan",66);
map.put("lisi",89);
Map<String,Integer> map2 = new HashMap<String,Integer>();
map2.put("wangwu",97);
map2.put("lihua",99);
map.putAll(map2); // 將 map2 集合中所有的key-value鍵值對新增到此 map集合當中去
// 注意:兩者集合儲存的元素資料型別必須是一致的才可以新增成功。
System.out.println(map);
}
}
元素查詢的操作:
- get(Object key) : 獲取指定key對應的value。
V get(Object key); // 獲取指定key對應的value
- containsKey(Object key) : 判斷該集合當中是否包含指定的 key值。
boolean containsKey(Object key); // 判斷該集合當中是否包含指定的 key 值。
- containsValue(Object key) : 判斷該集合當中是否包含指定的 value 值。
boolean containsValue(Object value); // 判斷判斷該集合當中是否包含指定的 value 值。
- isEmpty() : 判斷此集合是否為 空,是返回 true,不是返回 false。
boolean isEmpty(); // 判斷此集合是否為 空,是返回 true,不是返回 false;
- equals(Object o) : 判斷當前map和引數物件 o 是否相等。
boolean equals(Object o); // 判斷當前map和引數物件 o 是否相等
舉例:
import java.util.HashMap;
import java.util.Map;
public class MapTest {
public static void main(String[] args) {
// Map 介面 , HashMap實現類,多型,<String,Integer> 泛型
Map<String,Integer> map = new HashMap<String,Integer>();
// 新增元素資料:
map.put("zhangsan",66);
map.put("lisi",89);
map.put("wangwu",97);
map.put("lihua",99);
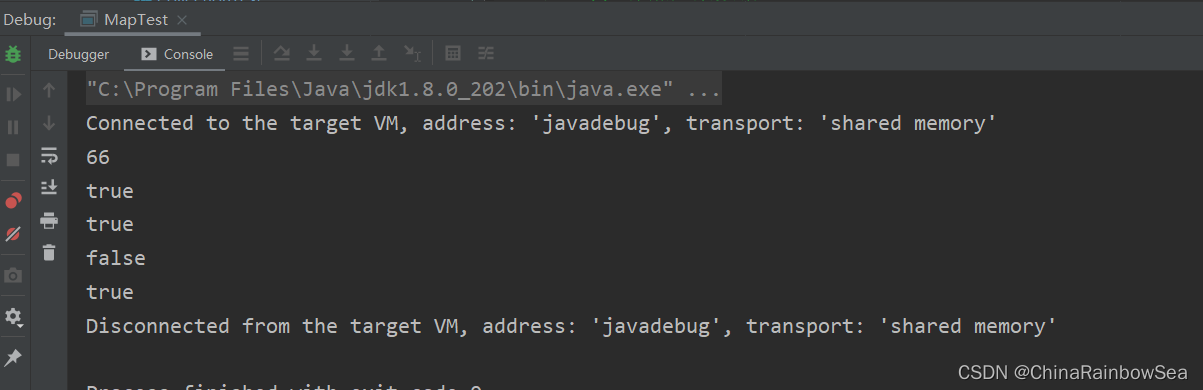
System.out.println(map.get("zhangsan")); // 獲取到對應 key上的 value值
System.out.println(map.containsKey("zhangsan")); // 判斷該集合當中是否存在 key = zhangsan的鍵值對
System.out.println(map.containsValue(99)); // 判斷該集合當中是否存在 value = 99的鍵值對
System.out.println(map.isEmpty()); // 判斷該集合是否為空
System.out.println(map.equals(map)); // 判斷當前map和引數物件 o 是否相等
}
}
元檢視操作的方法:
- keySet() : 返回所有key構成的Set集合。從該方法中可以看出 Map 介面下的集合中的 key 值是儲存在 Set 介面集合當中的。
Set<K> keySet(); // 返回所有key構成的Set集合
- values() : 返回所有value構成的Collection集合。從該方法中可以看出 Map 介面下的集合中的 value 值是儲存在 Collection 介面集合當中的。
Collection<V> values(); // 返回所有value構成的Collection集合
舉例:
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTest {
public static void main(String[] args) {
// Map 介面 , HashMap實現類,多型,<String,Integer> 泛型
Map<String,Integer> map = new HashMap<String,Integer>();
// 新增元素資料:
map.put("zhangsan",66);
map.put("lisi",89);
map.put("wangwu",97);
map.put("lihua",99);
Set<String> keys = map.keySet(); // 返回此集合當中所有的 key 值儲存到 Set 集合當中
for (String s : keys) {
System.out.println(s);
}
System.out.println("****************");
Collection<Integer> values = map.values(); // 返回此集合當中所有的 value 值儲存到 Collection 集合當中
// Collection 介面集合可以使用迭代器
Iterator<Integer> iterator = values.iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
}
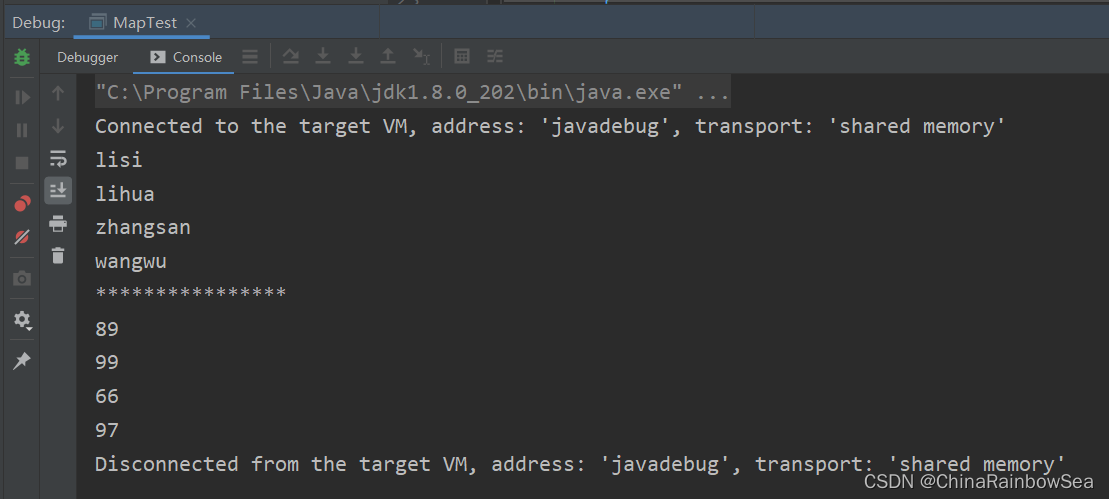
- entrySet() : 返回該集合當中的所有 key-value鍵值對,並儲存到 Set 集合當中後,再返回一個 Set 集合物件(該集合儲存了所有的key-value) 值。
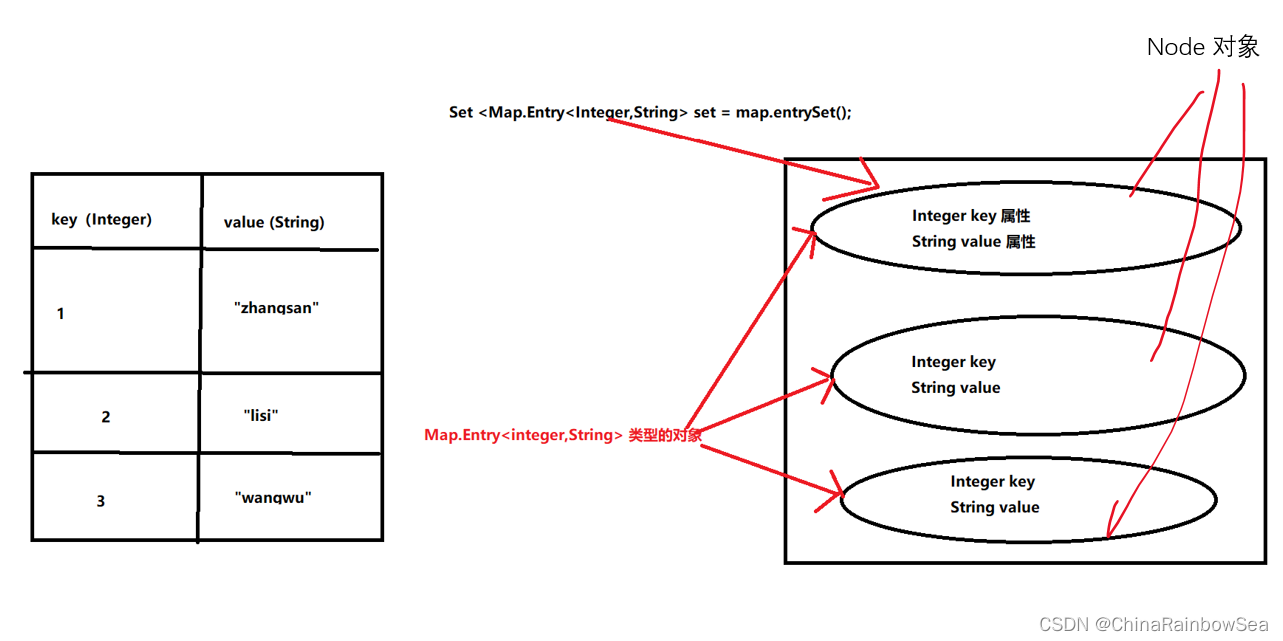
Set<Map.Entry<K,V>> entrySet(); // 返回所有key-value對構成的Set集合
其中的 Map.Entry 表示的是一個介面,也可以理解為是一個類。
* Set<Map.Entry<K,V>> entrySet() 將 Map集合轉換成 Set集合
* 假設現在有一個 Map集合 ,如下所示:
* map1 集合物件
* key value
* 1 zhangsan
* 2 lisi
* 3 wangwu
* 4 zhaoliu
*
* Set set = mop1.entrySet();
* set 集合物件
* 1=zhangsan
* 2=lisi
* 3=wangwu
* 4=zhaoliu
Map.Entry<K,V> 的圖示:
舉例:
import java.util.Collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class MapTest {
public static void main(String[] args) {
// Map 介面 , HashMap實現類,多型,<String,Integer> 泛型
Map<String,Integer> map = new HashMap<String,Integer>();
// 新增元素資料:
map.put("zhangsan",66);
map.put("lisi",89);
map.put("wangwu",97);
map.put("lihua",99);
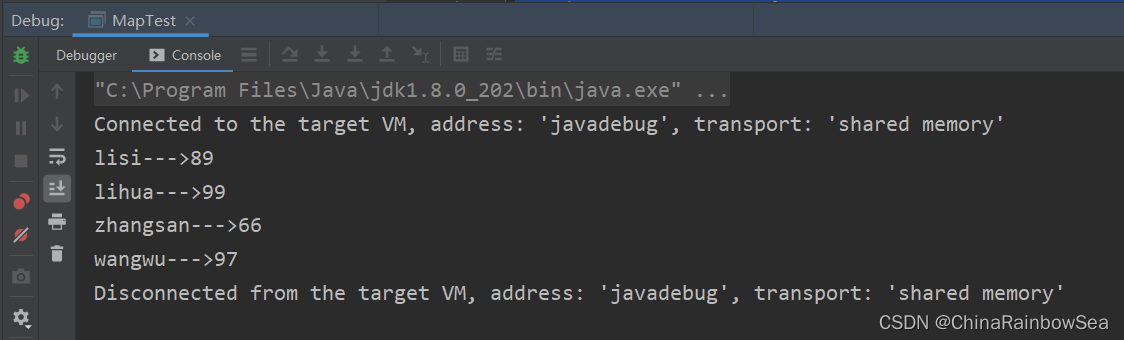
Set<Map.Entry<String, Integer>> entries = map.entrySet();
Iterator<Map.Entry<String, Integer>> iterator = entries.iterator();
while(iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
// getKey()獲取 key 值,getValue()獲取value值
System.out.println(entry.getKey() + "--->" + entry.getValue());
}
}
}
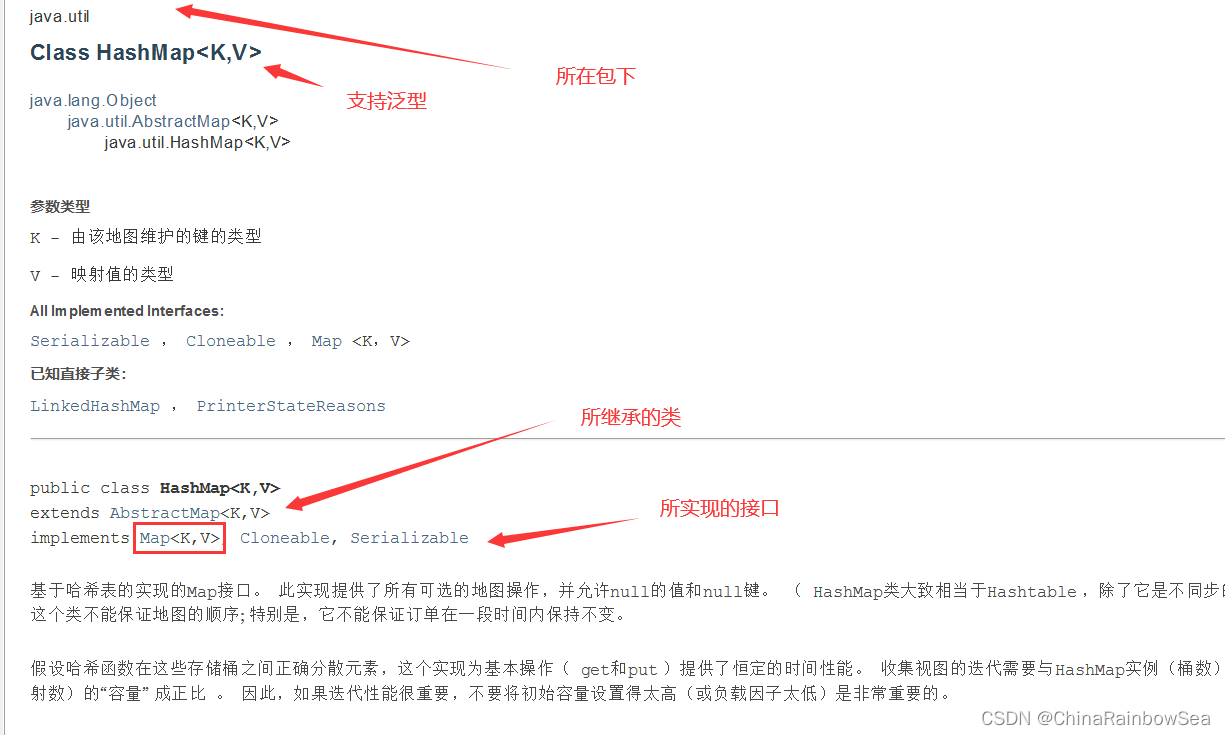
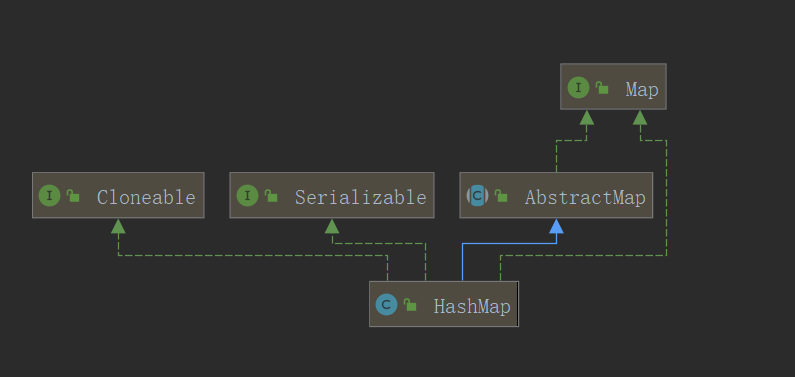
3. Map實現類之一:HashMap

-
HashMap 是 Map 介面使用頻率最高的實現類。
-
HashMap 允許儲存 null 值,key 可以為 null ,但僅僅只能有一個,因為不可重複,value 可以為 null 。無序
-
HashMap 中所有的 key 構成的集合是儲存在 Set 當中的,無序的,不可重複的,所以:key 所在類和 Set 集合是一樣的必須重寫 euqlas() 和 hashCode() 方法。其中 Java當中的包裝類和String 類都重寫了 equals() 和 hashCode()方法。基本上只有我們自定的類需要重寫。
-
一個key-value 構成一個
Map.Entry。 -
所有的 Map.Entry 構成的集合是 Set 無序的,不可重複的。
-
HashMap
判斷兩個 key 相等的標準是: 兩個key 通過 equals() 方法返回 true , hashCode 值也相等。 -
HashMap
判斷兩個 value 相等的標準是: 兩個 value 通過 equals() 方法返回 true。 -
HashMap 集合底層是雜湊表的資料結構
- 雜湊表是一個陣列 + 單向連結串列 的結合體。
- 陣列:在查詢方面效率很高,隨機增刪方面很低。
- 連結串列:在隨機增刪方面效率較高,在查詢方面效率低。
- 而雜湊表:將以上兩種資料結構融合在一起,充分發揮它們各自的優點。
-
對於 HashMap 中的方法基本上都是繼承了對應的 Map 介面的方法,上面已經說明了,這裡就不多介紹了。
舉例:
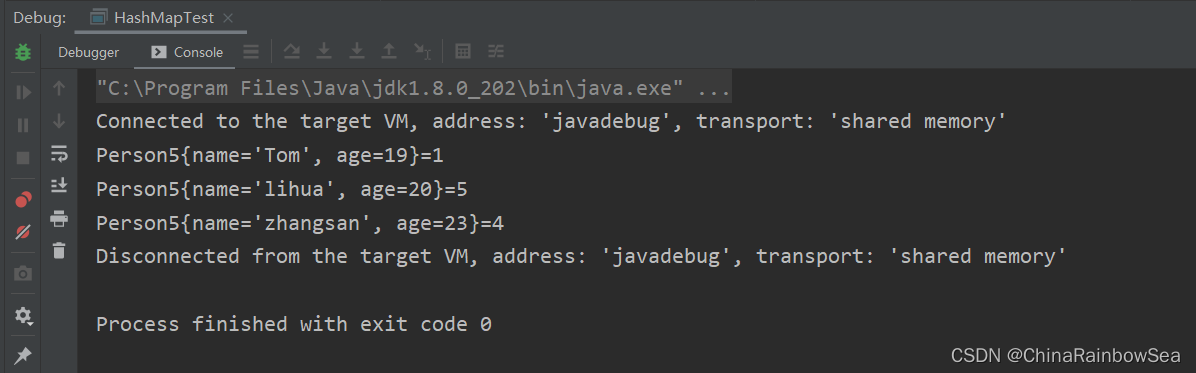
如下是 Set 中的 Key 儲存自定義類 Person5 ,其中並沒有重寫Object 中的 equals() 方法和 hashCode()方法。會出現 Key 儲存到重複的資料。
package blogs.blogs7;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
HashMap<Person5,Integer> hashMap = new HashMap<Person5, Integer>();
hashMap.put(new Person5("Tom",19),1);
hashMap.put(new Person5("Tom",19),1);
hashMap.put(new Person5("Tom",19),1);
hashMap.put(new Person5("zhangsan",23),4);
hashMap.put(new Person5("lihua",20),5);
// 遍歷HashMap 集合
Set<Map.Entry<Person5,Integer>> entries = hashMap.entrySet();
for (Map.Entry<Person5,Integer> entry : entries) {
System.out.println(entry);
}
}
}
class Person5 {
String name;
int age;
public Person5() {
}
public Person5(String name, int age) {
this.name = name;
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person5{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}

修改: 重寫其中的 Key 值的 Set 集合中儲存的 類中的 equals() 和 hashCode() 方法。
package blogs.blogs7;
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
HashMap<Person5,Integer> hashMap = new HashMap<Person5, Integer>();
hashMap.put(new Person5("Tom",19),1);
hashMap.put(new Person5("Tom",19),1);
hashMap.put(new Person5("Tom",19),1);
hashMap.put(new Person5("zhangsan",23),4);
hashMap.put(new Person5("lihua",20),5);
// 遍歷HashMap 集合
Set<Map.Entry<Person5,Integer>> entries = hashMap.entrySet();
for (Map.Entry<Person5,Integer> entry : entries) {
System.out.println(entry);
}
}
}
class Person5 {
String name;
int age;
public Person5() {
}
public Person5(String name, int age) {
this.name = name;
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Person5)) return false;
Person5 person5 = (Person5) o;
return age == person5.age &&
Objects.equals(name, person5.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Person5{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
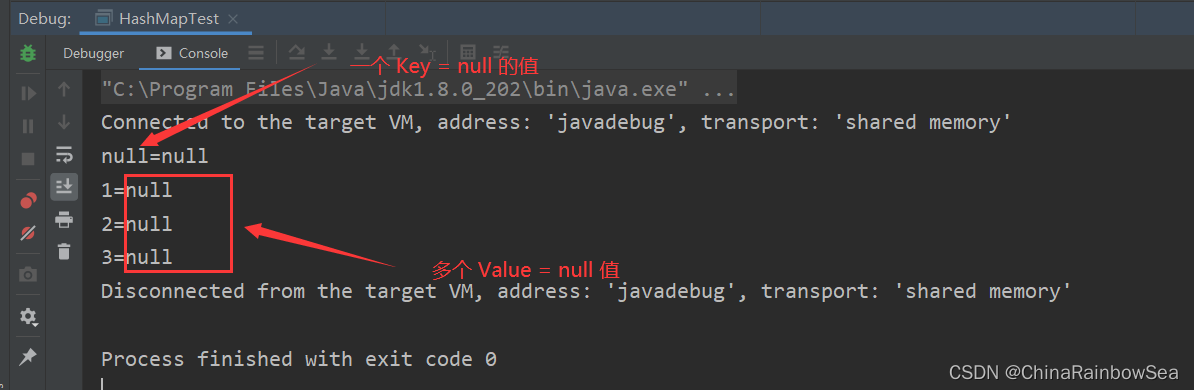
HashMap中的 Key值可以儲存新增 null 值,但是僅僅只能新增一個 null ,因為 Key 中的資料儲存在 Set集合當中的,不可重複,而 Value 值也可以儲存 null值,而且可以儲存多個 null 值,因為 Value 值資料底層是儲存在Collection集合當中的。
舉例:
import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.Set;
public class HashMapTest {
public static void main(String[] args) {
HashMap<String,Integer> hashMap = new HashMap<String, Integer>();
hashMap.put(null,null);
hashMap.put(null,null);
hashMap.put(null,null);
hashMap.put("1",null);
hashMap.put("2",null);
hashMap.put("3",null);
// 遍歷HashMap 集合
Set<Map.Entry<String,Integer>> entries = hashMap.entrySet();
for (Map.Entry<String,Integer> entry : entries) {
System.out.println(entry);
}
}
}
常用方法總結:
- 新增: put(Object key,Object value)
- 刪除: remove(object key)
- **修改: **put(Object key,Object value)
- 查詢: get(Object key)
- 長度: size();
- 遍歷: keySet()/values()/entrySet()
3.1 HashMap的儲存結構
JDK 7及以前版本:HashMap是陣列+連結串列結構(即為鏈地址法)
JDK 8版本釋出以後:HashMap是陣列+連結串列+紅黑樹實現
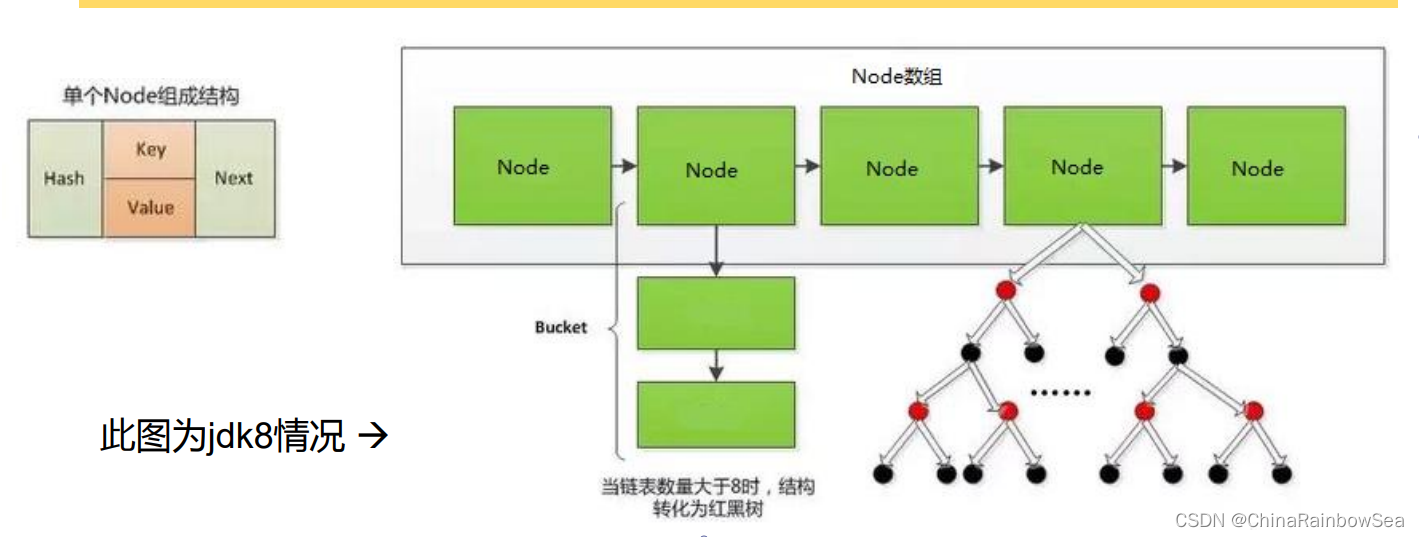
如下是 JDK8 的HashMap 結構圖
3.2 HashMap原始碼中的重要常數
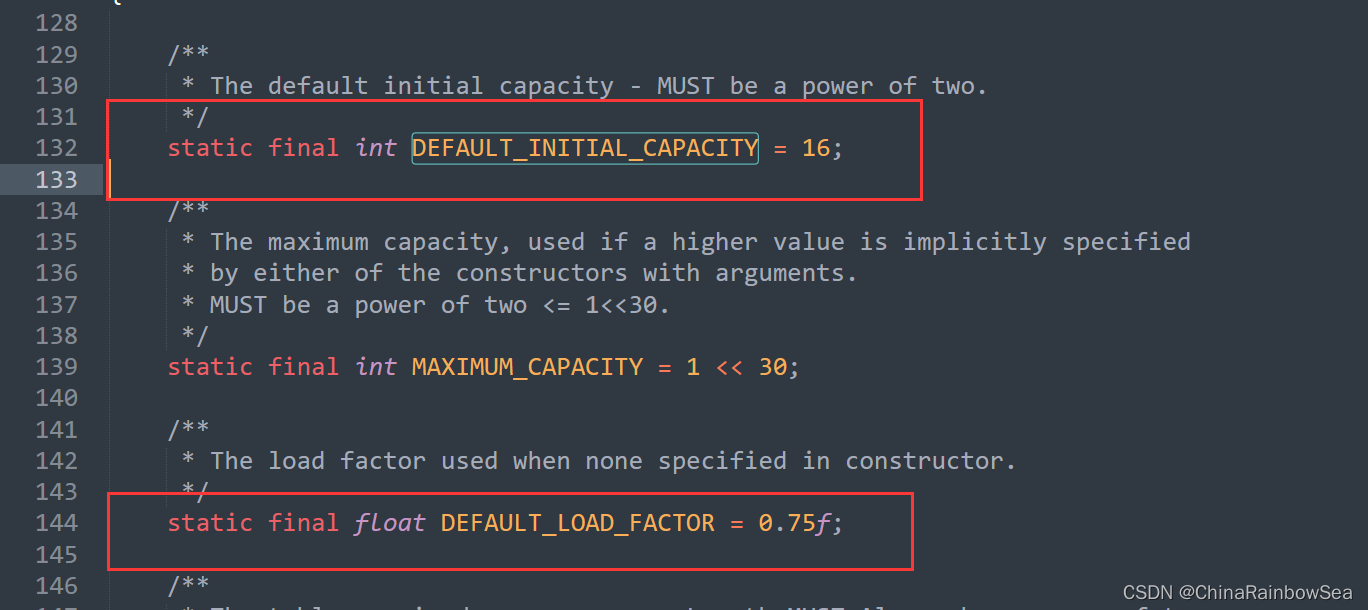
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 HashMap的預設容量是 16
-----------------------------------------------------------------------------------
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30; // HashMap的最大支援容量,2^30
-----------------------------------------------------------------------------------
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f; // HashMap的預設載入因子
-----------------------------------------------------------------------------------
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8; // Bucket中連結串列長度大於該預設值,轉化為紅黑樹
-----------------------------------------------------------------------------------
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6; // Bucket中紅黑樹儲存的Node小於該預設值,轉化為連結串列
-----------------------------------------------------------------------------------
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64; // 桶中的Node被樹化時最小的hash表容量。(當桶中Node的數量大到需要變紅黑樹時,若hash表容量小於MIN_TREEIFY_CAPACITY時,此時應執行resize擴容操作這個MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。)
-----------------------------------------------------------------------------------
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table; // 儲存元素的陣列,總是2的n次冪
-----------------------------------------------------------------------------------
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set<Map.Entry<K,V>> entrySet; // 儲存具體元素的集合
-----------------------------------------------------------------------------------
/**
* The number of key-value mappings contained in this map.
*/
transient int size; // HashMap中實際儲存的鍵值對的數量
-----------------------------------------------------------------------------------
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount; // HashMap擴容和結構改變的次數。
-----------------------------------------------------------------------------------
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold; // 擴容的臨界值,=容量 * 填充因子
-----------------------------------------------------------------------------------
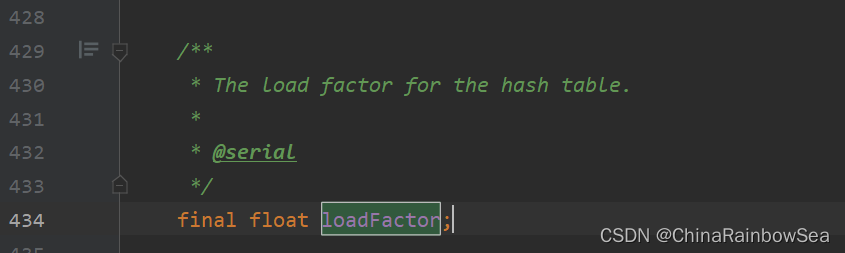
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor; // 填充因子
3.3 HashMap的儲存結構:JDK 1.8之前 / JDK 1.8之後
3.3.1 JDk 1.8 之前
-
HashMap 內部儲存結構其實是
陣列 + 連結串列的結合。當範例化一個 new HashMap() 時,實際上會建立一個長度為 Capacity 的 Entry 陣列。這個長度在 雜湊表中稱為 容量(Capacity) ,在這個陣列中可以存放元素的位置,我們稱之為 」桶「 (bucket) ,每個 bucket 都有自己的索引,系統可以根據索引快速的查詢 bucket 中的元素。 -
每個bucket 中儲存一個元素,即 一個 Entry 物件內部類 ,但每一個 Entry 物件可以帶 一個參照變數,用於指向下一個元素,因此,在一個桶 (bucket) 中,就有可能生成一個 Entry 鏈。而且新新增的元素作為連結串列的 head 。
-
JDK7 原始碼分析如下:

3.3.2 JDk 1.8 及之後
JDK8: HashMap 的內部儲存結構其實是:陣列+連結串列+樹 的結合。當範例化一個 new HashMap 時,會初始化 initilCapacity 和 loadFactor ,在 put() 第一對對映關係(鍵值對)新增時,系統會建立一個長度為 initilCapacity 的 Node 陣列 ,這個長度在雜湊表中被稱為 」容量" (Capacity),在這個陣列中可以存放元素的位置,我們稱之為 「桶」(bucket) ,每個 bucket 都有自己的索引,系統可以根據索引快速的查詢 bucket 中的元素。
每個bucket 中儲存一個元素資料,既 一個 Node 物件,但每一個 Node 物件可以帶一個參照變數 next ,用於指向下一個元素,因此,在一個桶中,就有可能生成一個 Node 連結串列。也可能是一個一個TreeNode 物件,每一個TreeNode 物件可以有兩個葉子節點 left 和 right ,因此,在一個桶中,就有可能生成一個 TreeNode 樹。而新新增的元素作為連結串列的 last ,或樹的葉子節點。
JDK1.8 原始碼分析:



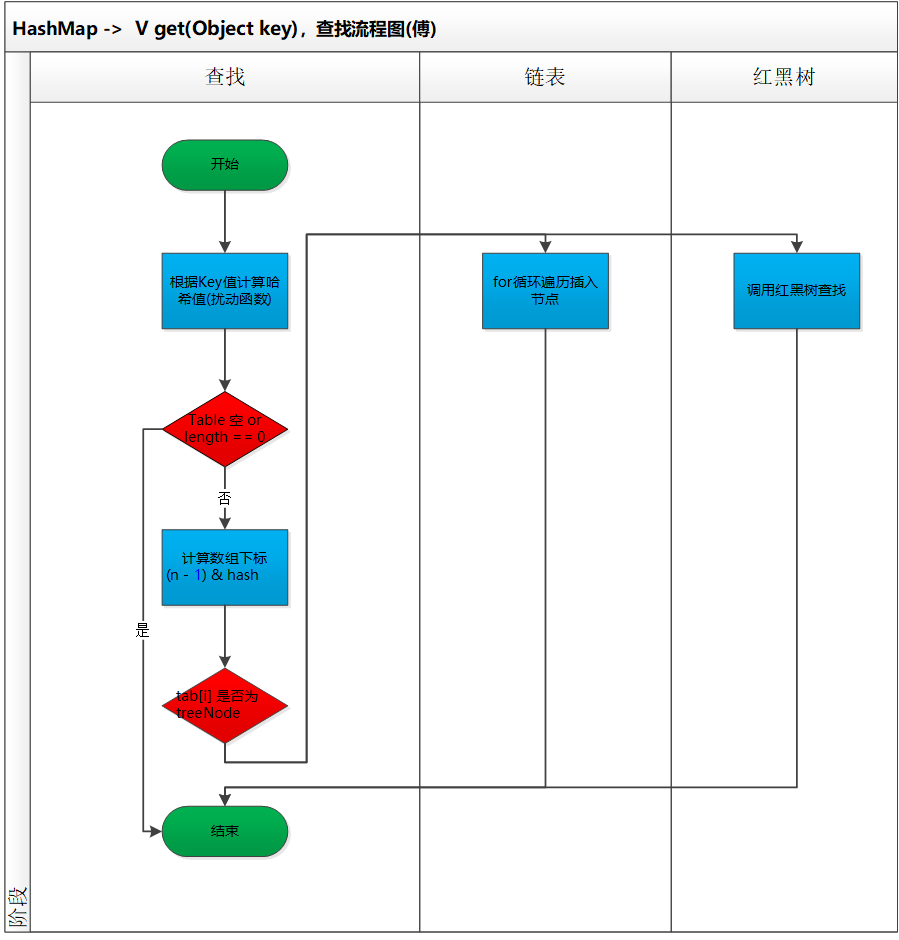
3.3.3 JDK8 HashMap 集合新增元素的過程
向 HashMap 集合中新增 put(key1,value1) 鍵值對, 首先呼叫 元素 key1 所在類的 hashCode() 方法,來得到該 key1物件的 hashCode(雜湊) 值。
然後再根據得到的 hashCode (雜湊)值,通過某種雜湊函數 計算除該物件在 HashSet 集合中底層Node[] 陣列的儲存位置(即為:索引下標位置),(這個雜湊函數會與底層陣列的長度相計算得到在陣列中的下標,並且這種雜湊函數計算還儘可能保證能均勻儲存元素,越是雜湊分佈,該雜湊函數設計的越好)。
-
判斷此計算處理得到的陣列下標位置上是否已經有元素儲存了 :
- 如果沒有其他元素資料儲存,則 元素 key1-value1新增到該位置上。 —— 情況1
- 如果有其它元素資料儲存(或以連結串列形式儲存的多個元素) : 則比較key1和已經存在的一個或多個資料的雜湊值):
-
如果 key1的hashCode() 雜湊值與已經存在的資料的雜湊值都 不相等, 則元素 key1-value1新增到該陣列連結串列上。—— 情況2
-
如果 key1 的hashCode() 雜湊值 與 已經存在的資料的雜湊值都 相等, 則呼叫 key1 元素所在類的 equals() 方法,, 判斷比較所儲存的內容是否和集合中儲存的相等。
- 如果 不相等 也就是 equals() 方法,返回 false ,則此時 key1-value1新增成功。—— 情況3
- 如果 相等 也就是 equals()方法,返回 true,不新增,替換掉其中存放的 value 值為 value1 ,因為 key1 是唯一的不可重複的,但是其 對應的 value 值是可以重複的。
-
-
對應上述 新增成功的 情況2 和 情況3 而言,關於情況2和情況3:此時key1-value1和原來的資料以連結串列的方式儲存
-
如下是 新增鍵值對的過程的圖示:

如下是查詢圖示:
假設將所有的hashCode()方法返回設定為不一樣的值,可以嗎?,有什麼問題:
不行,因為這樣的話,就導致 HashMap 集合底層的雜湊表就成為了一維陣列了,沒有連結串列的概念了,更沒有雜湊表的概念了。
假設將所有的hashCode()方法返回設返回值固定為某個值,可以嗎?,有什麼問題:
答:不可以,設將所有的hashCode()方法,返回值固定為某個值,那麼會導致底層雜湊表變成了純單向連結串列。這種情況下我們稱為:雜湊分別不均勻。
什麼時雜湊分佈不均勻
假設我們有 100 個元素,10個單向連結串列,那麼每個單向連結串列上有10個節點,這是最好的,是雜湊分佈均勻的
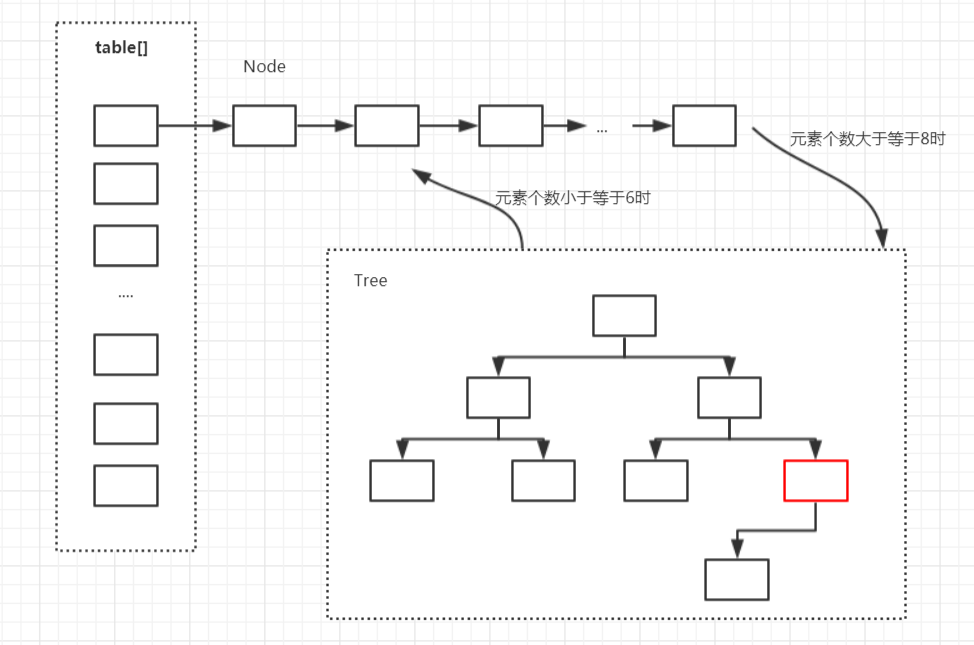
3.3.4 JDK8 HashMap 進行 "擴容"和 "樹形化"
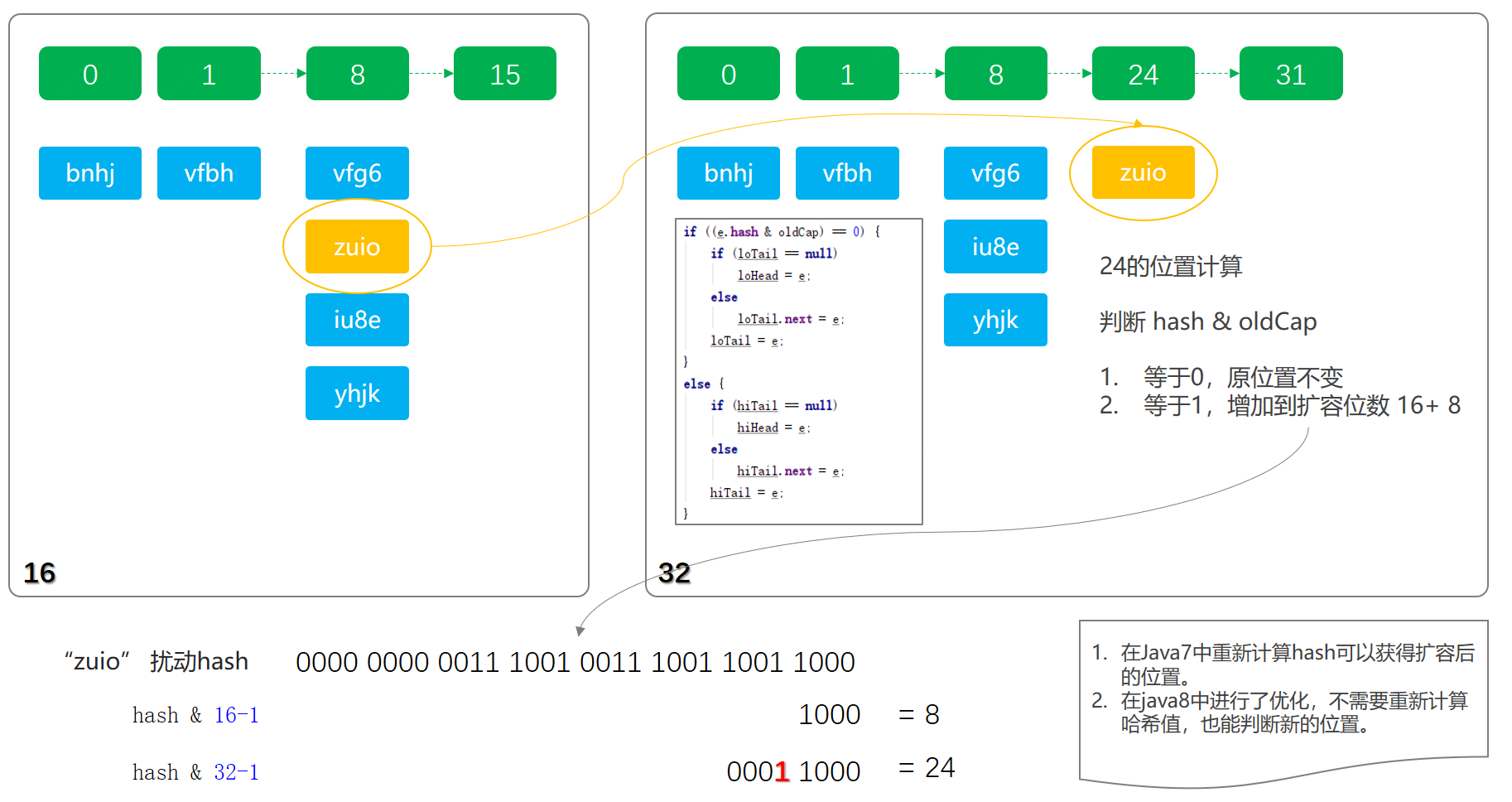
擴容
當 put(Key1,value1) 新增鍵值對個數超過 陣列大小(陣列總大小 length ,不是陣列中實際存放的鍵值對個數 size),時,就會進行陣列擴容。loadFactor 的預設值:DEFAULT_LOAD_FACTOR)為0.75,這是一個折中的取值,也就是說,預設情況下,陣列大小(DEFAULT_INITIAL_CAPACITY)為16 ,那麼當 HashMap 中元素個數超過 16 * 0.75 = 12 (這個值就是程式碼中的 threshold值,也叫臨界值)的時候,就把陣列的大小擴充套件為 2 * 16 = 32 ,即擴大 1倍 ,然後重新計算每個元素在陣列中的位置,而這是一個非常消耗效能的操作。所以在開發中如果我們可以預估計其儲存的資料量,也就是 HashMap中儲存元素的個數,那麼就呼叫其HashMap(int num) 設定儲存容量的大小,減少擴容次數,提高 HashMap的效能 。
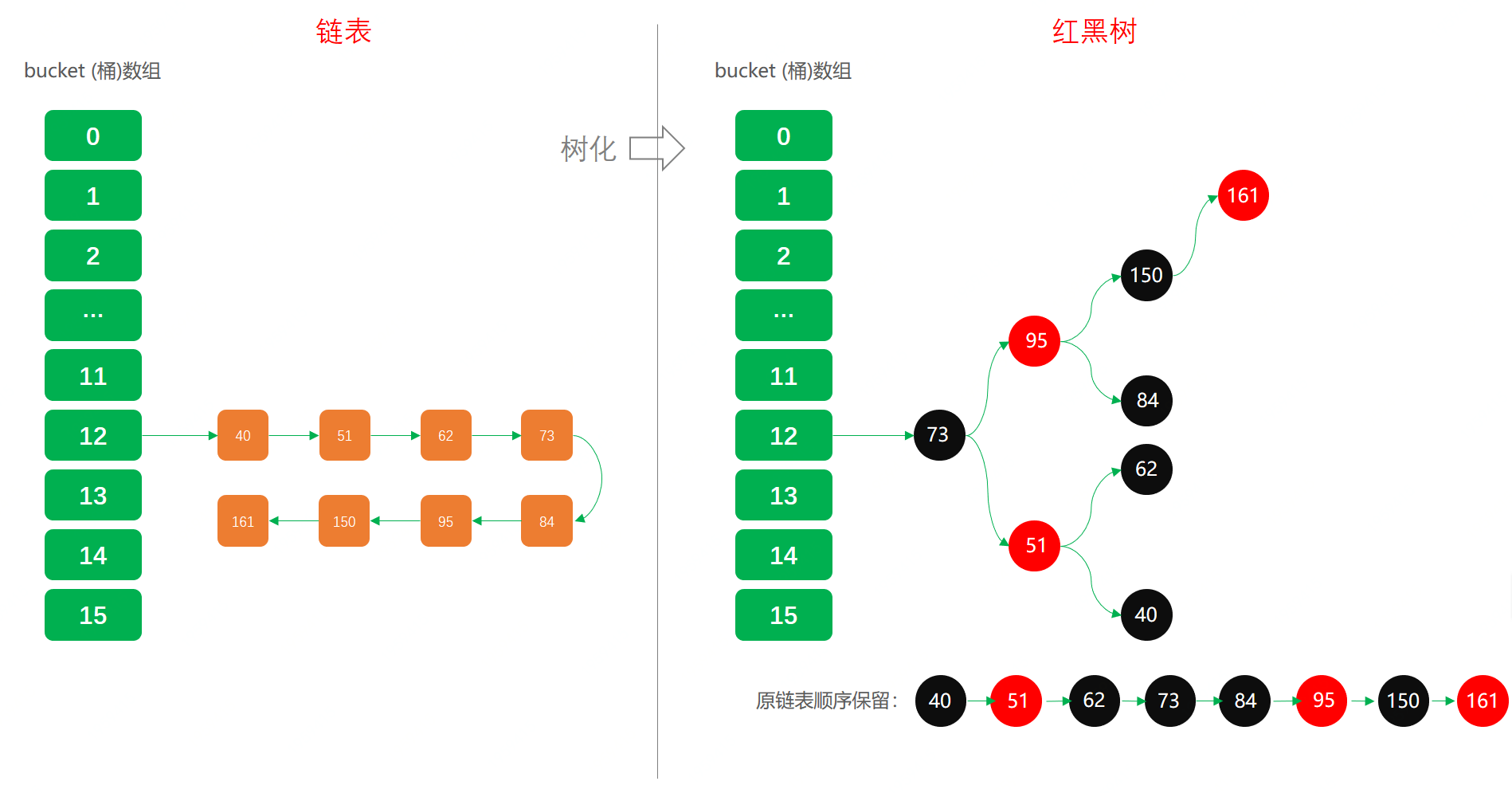
樹形化
當HashMap中的其中一個鏈的物件個數如果達到了8個,此時如果capacity沒有達到64,那麼HashMap會先擴容解決,如果已經達到了64,那麼這個鏈會變成樹,結點型別由Node變成TreeNode型別。當然,如果當對映關係被移除後,下次resize方法時判斷樹的結點個數低於6個,也會把樹再轉為連結串列。
補充:
關於對映關係的key是否可以修改 ???
answer:不要修改,對映關係儲存到 HashMap 中會儲存 key 的 雜湊值 ,這樣就不用每次查詢時,重新計算每一個 Entry 或 Node (TreeNode)的 雜湊值了,因此如果已經 put 到 Map 中的對映關係,再修改 key 的屬性,而這個屬性有參與 hashCode值的計算,那麼會導致匹配不上。
為什麼HashMap擴容時,不是陣列滿了的時候擴容而是達到一個的 0.75 的額度才擴容 ???
因為HashMap 集合的底層時由 連結串列 + 陣列 + 樹 構成的。由於連結串列的存在,HashMap 當中的陣列不一定會儲存滿了。
以及涉及到 HashMap 集合效能最優的效果,雜湊均勻分佈,所以是到達一定額度 0.75 是最好的情況了.
負載因子值的大小,對HashMap有什麼影響 ???
/** * The load factor used when none specified in constructor. */ static final float DEFAULT_LOAD_FACTOR = 0.75f; // HashMap的預設載入因子負載因子的大小決定了HashMap的資料密度。
負載因子越大密度越大,發生碰撞的機率越高,陣列中的連結串列越容易長,
造成查詢或插入時的比較次數增多,效能會下降。
負載因子越小,就越容易觸發擴容,資料密度也越小,意味著發生碰撞的
機率越小,陣列中的連結串列也就越短,查詢和插入時比較的次數也越小,效能會更高。但是會浪費一定的內容空間。而且經常擴容也會影響效能,建議初始化預設大一點的空間。
按照其他語言的參考及研究經驗,會考慮將負載因子設定為0.7~0.75,此時平均檢索長度接近於常數。
3.3.5 總結:JDK1.8 相較於之前的變化:
-
JDK8 :HashMap map = new HashMap() ,預設情況下,是不會先建立長度為 16 的 陣列的,而是首先呼叫 map.put() 新增鍵值對的時候建立 長度為 16的陣列(類比:單例模式中的餓漢式)。 JDK7 則是預設先建立了一個長度為 16的陣列(類比:單例模式中的懶漢式)。
-
JDK8 底層的陣列是 Node[ ] ,JDK7 底層的陣列是 Entry[ ] 。
-
put(Key1,Value1) 新增鍵值對時,JDK7 是新增到連結串列上的頭部(陣列上),JDK8 是新增到連結串列的尾部(不在陣列上),簡稱:七上八下。
-
jdk7 底層結構只有:陣列 + 連結串列,jdk8 中底層結構: 陣列 + 連結串列 + 紅黑樹
當陣列的某一個索引位置上的元素以連結串列形式存在的資料個數 > 8 且當前陣列的長度 > 64時,此時此索引位置上的所有資料改為使用「紅黑樹」儲存。當小於 8 時,有會變成連結串列的形式儲存。
4. Map實現類之二:LinkedHashMap

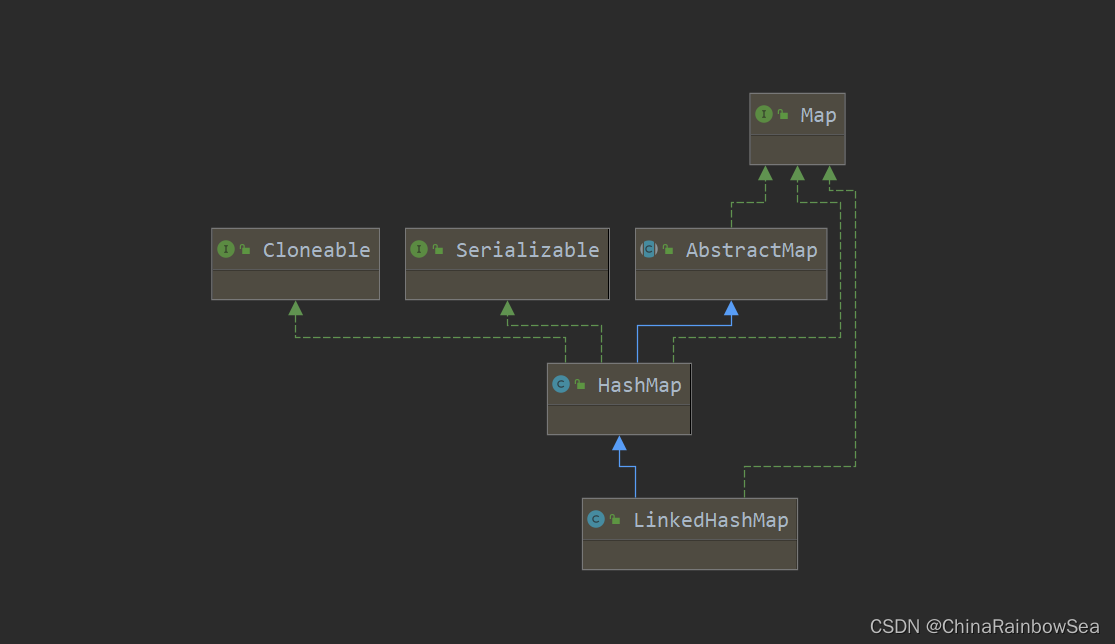
- LinkedHashMap 是 HashMap 的子類,所以 LinkedHashMap 繼承了 HashMap 的特點:其中的 key 是無序,不可重複的,其 Key 儲存的元素類必須重寫 eqauls() 和 hashCode() 方法。同樣的 Key 值是儲存在 Set 集合當中的,而Value 則是儲存在 Collection 集合當中的。
- LinkedHashMap 是在 HashMap 儲存結構的基礎上,使用了一對雙向連結串列來記錄新增元素的順序的,所以你新增元素資料的順序是怎樣的,取元素資料的順序就是怎樣的。
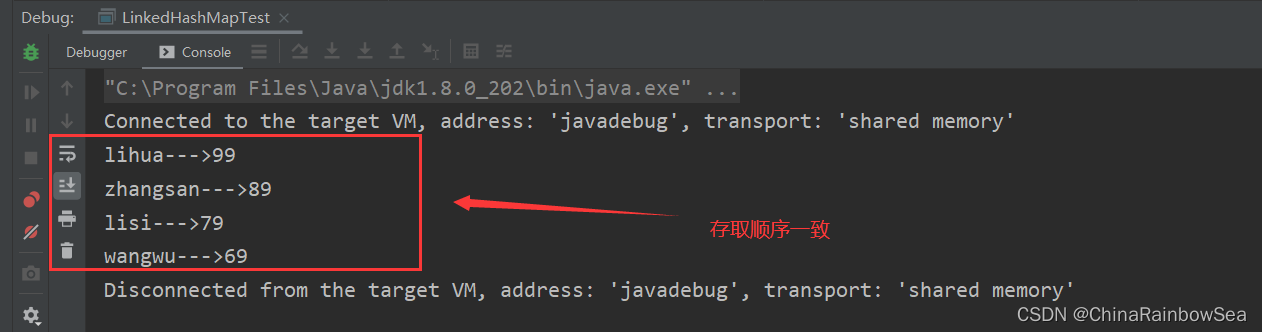
- 與 LinkedHashSet 類似, LinkedHashMap 可以維護 Map 的迭代順序:迭代順序與 Key-Value 鍵值對的插入順序一致,簡單的說就是:存取順序一樣。
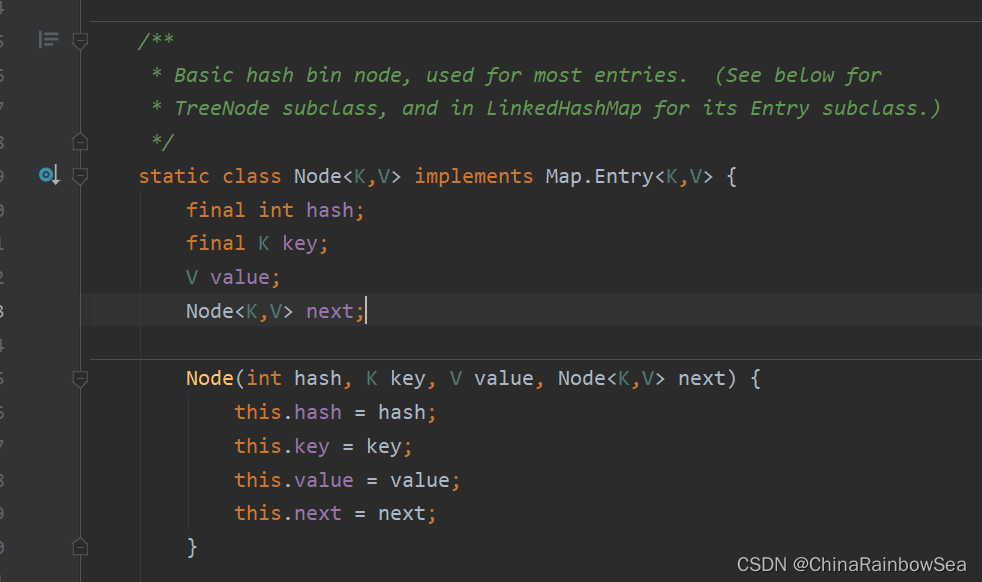
- LinkedHashMap 是繼承了 HashMap 其常用的方法是一樣的,這裡就不多說明了。不同的是HashMap 底層的內部類是 Node ,而LinkedHashMap 底層的內部類是Entry ,該內部類繼承了 HashMap.Node<K,V>
HashMap中的內部類:Node
LinkedHashMap中的內部類:Entry

舉例:
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LinkedHashMapTest {
public static void main(String[] args) {
// 建立 LinkedHashMap 集合物件
LinkedHashMap<String,Integer> linkedHashMap = new LinkedHashMap<String, Integer>();
// 新增元素資料(鍵值對)
linkedHashMap.put("lihua",99);
linkedHashMap.put("zhangsan",89);
linkedHashMap.put("lisi",79);
linkedHashMap.put("wangwu",69);
// 遍歷 LinkedHashMap 集合
// 獲取到key-value 儲存的 Set Entry 內部類集合物件
Set<Map.Entry<String, Integer>> entries = linkedHashMap.entrySet();
// 獲取到該 Set Entry 內部類集合的迭代器
Iterator<Map.Entry<String, Integer>> iterator = entries.iterator();
while(iterator.hasNext()) {
Map.Entry<String, Integer> entry = iterator.next();
System.out.println(entry.getKey() + "--->" + entry.getValue());
}
}
}
5. Map實現類之三:TreeMap

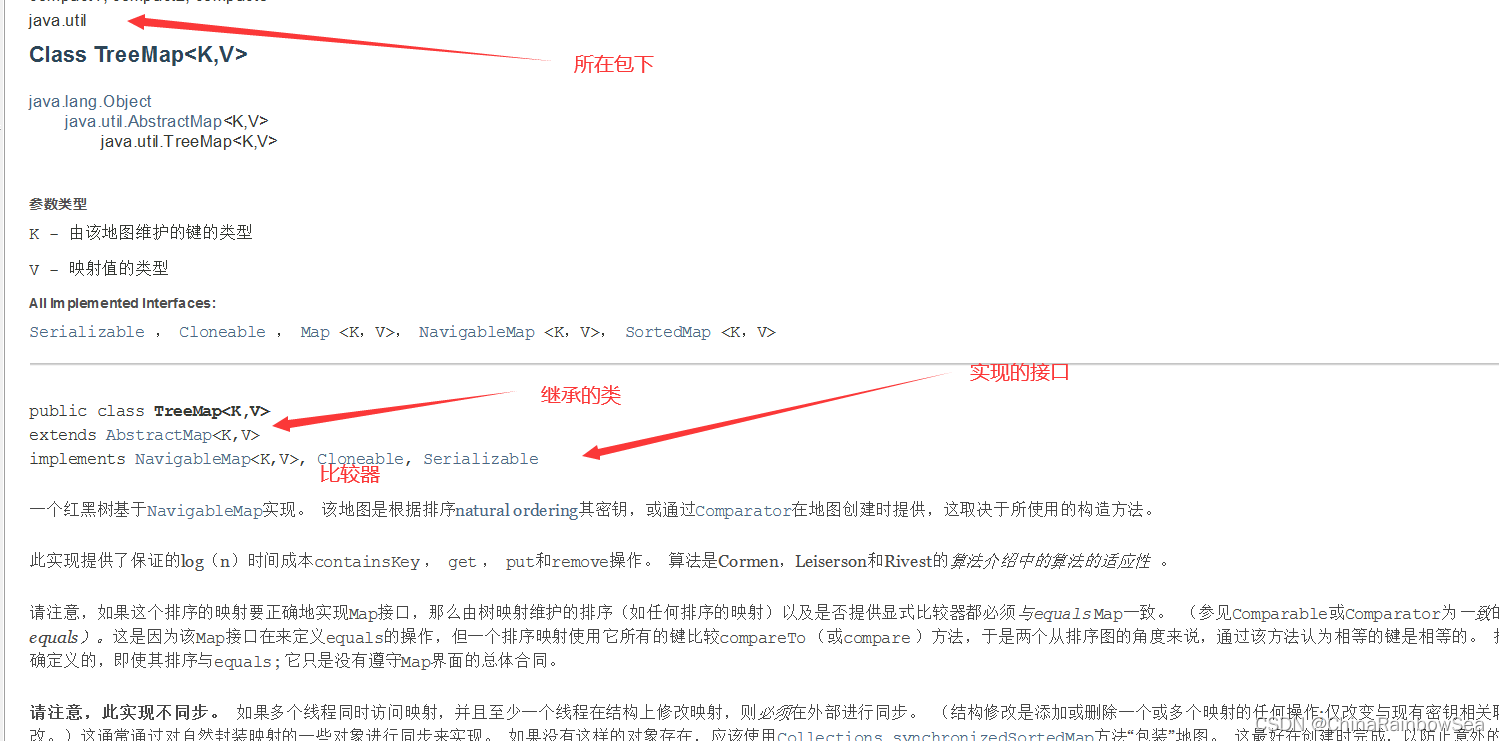
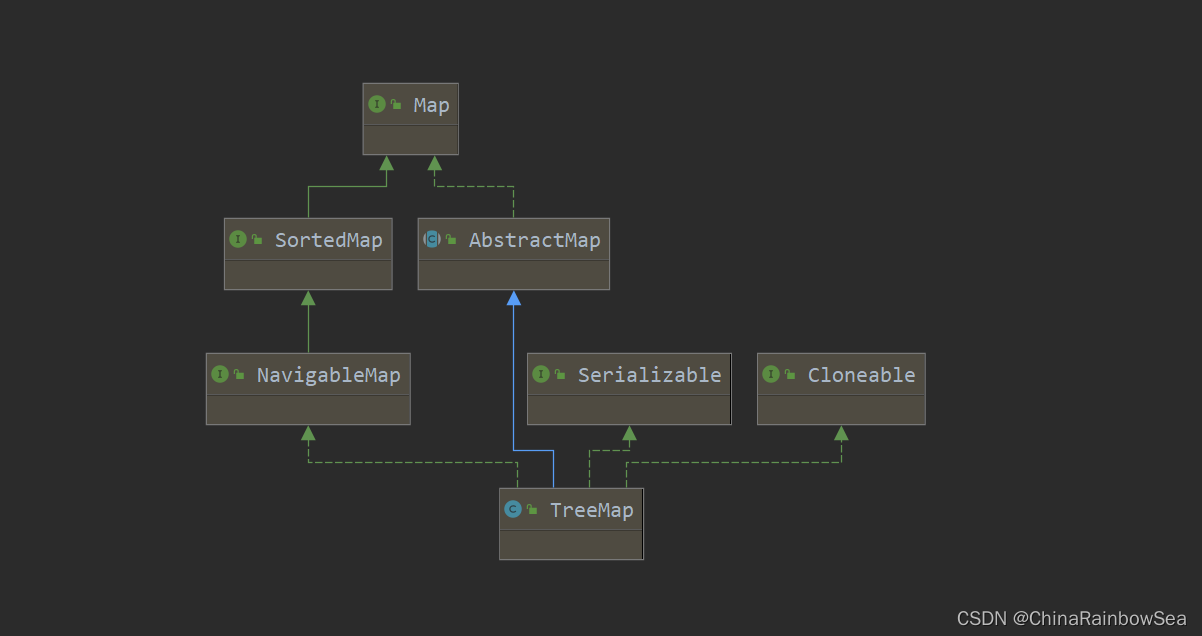
-
TreeMap 儲存 Key-Value 鍵值對時,需要根據 key-value 鍵值對進行排序,TreeMap 可以保證所有的 key-value 鍵值對處於有序狀態。
-
TreeSet 底層 就是由 TreeMap 構成的,new TreeSet 底層實際上說就是 new TreeMap 集合儲存資料,向 TreeSet 中新增資料就是向 TreeMap 集合中新增資料。
-
TreeMap 中的 key 儲存的資料型別必須是一致的,不然無法比較判斷,從而排序。
-
TreeMap 的 排序是對 Key 的內容進行排序的,其中的 Key 值內部是由 Set 集合儲存的,無序,不可重複性,所儲存類必須重寫 equals() 和 hashCode() 方法。因為會自動排序,所以還需要實現排序:兩種方式一種是:
- 自然排序: TreeMap 的所有的 Key 必須實現(實現
java.lang.Comparable的介面,而且所有 的 Key 應該是同一個類的物件(因為不是同一型別無法比較判斷),否則將會丟擲ClasssCastException自然排序,重寫其中的compareTo()抽象方法) 。在Java當中所有的包裝類和String都實現了該java.lang.Comparable介面。所以一般要實現該介面的都是自定的類。 - 客製化排序: 建立 TreeMap 時,傳入一個 Comparator 物件,該物件負責對 TreeMap 中的所有 key 進行排序。此時不需要 Map 的 Key 實現 Comparable 介面
public TreeMap(Comparator<? super K> comparator)v // 構造一個新的,空的樹圖,按照給定的比較器排序。- 關於自然排序與 客製化排序 的詳解內容大家可以移步至:
- 自然排序: TreeMap 的所有的 Key 必須實現(實現