2022資料分析: 電商天貓維生素類藥品銷售分析
前言
這篇資料分析記述了一次關於天貓維生素類的藥品(2020-2021)銷售資料的分析。

有些不足的地方,希望大家斧正。
題目
隨著國家政策的逐步開放,越來越多的藥品可以在網路上購買,醫藥電商平臺蒸蒸日上,受新冠疫情的影響,線下藥店購買困難,更讓醫藥電商進入了更多消費者的視野,各大藥企也紛紛加大力度佈局醫藥電商領域。但電商模式與線下零售有所不同,如何更好的經營醫藥電商成為藥企急需解決的問題。本題採集了天貓維生素類的藥品,請針對維生素藥品進行資料的清洗、分析與挖掘,並回答下列問題。
- 對店鋪進行分析,一共包含多少家店鋪,各店鋪的銷售額佔比如何?給出銷售額佔比最高的店鋪,並分析該店鋪的銷售情況。
- 對所有藥品進行分析,一共包含多少個藥品,各藥品的銷售額佔比如何?給出銷售額佔比最高的 10 個藥品,並繪製這 10 個藥品每月銷售額曲線圖。
- 對所有藥品品牌進行分析,一共包含多少個品牌,各品牌的銷售額佔比如何?給出銷售額佔比最高的 10 個品牌,並分析這 10 個品牌銷售較好的原因?
- 預測天貓維生素類藥品未來三個月的銷售總額並繪製擬合曲線,評估模型效能和誤差。
- 一家藥企計劃將新的維生素品牌進行網路銷售,聘請你當企業的顧問,請你設計一份不超過兩頁紙的電商經營策略。
摘 要
隨著國家政策的逐步開放,越來越多的藥品可以在網路上購買, 醫藥電商平臺蒸蒸日上,受新冠疫情的影響,線下藥店購買困難,更讓醫藥電商進入了更多消費者的視野,各大藥企也紛紛加大力度佈局醫藥電商領域。
我們對維生素售賣的藥店,維生素藥品,維生素藥品品牌進行了分析。
對於空值資料採用眾數填充,資訊的提取用到了正規表示式,藥品名稱的獲取用到了北大中文醫藥分詞的模形並適配自己的詞典進行提取。模形預測使用了時間序列的自相關模型並做了基於時間序列殘差的模型評估。
基於分析得到的資訊給出了銷售建議。
關鍵詞
眾數填充 銷售分析 暢銷藥品 北大中文醫藥分詞 時間序列自相關模型 平穩性 殘差
1 店鋪分析
1.1 店鋪數量
通過對資料shop_name欄的統計。
import pandas as pd
import matplotlib.pyplot as plt
import re
from matplotlib.pyplot import style
import statsmodels.api as sm
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller as ADF
from scipy import stats
#qq圖
from statsmodels.graphics.api import qqplot
# 載入北大分詞包
import pkuseg
data = pd.read_excel('./data.xlsx')
print(data.head())
# 統計商店數量
shop = data['shop_name'].value_counts()
print(shop.head())
print(shop.tail())
print(shop.size)
print(shop.index)
發現共有26家店鋪。分別是:
阿里健康大藥房, 天貓國際進口超市, 康愛多大藥房旗艦店, 天貓超市, ChemistWarehouse海外旗艦店, 焦作國控大藥房旗艦店, 阿里健康大藥房海外店, nyc美林健康海外專營店, thejamy保健海外專營店, 百康保健品專營店, 康恩貝官方旗艦店, hihealth海外專營店, 宜度海外專營店, 天貓國際妙顏社, NRC營養優選海外專營店, 蘇寧易購官方旗艦店, nrfs湖畔海外專營店, 進口/國產保健品精品店, 康壽營養品店,百秀大藥房旗艦店, LuckyVitamin海外旗艦店, skyshop海外專營店, 搬運健康館, 美加精品,SASA美國直郵, 同堂保健品專營店。
1.2 店鋪銷售額佔比
1.2.1 資料預處理
由於資料中並沒有銷售額一欄,需要我們自行計算。
採用:銷售額 = 折扣 * 售價 * 銷售數量 得到一行資料的銷售額。
但是資料的折扣欄存在2884個空值。為了充分利用資料,所以我們使用折扣的眾數(95折)進行填充。之後為資料新增一列銷售額sales。
# 空值數量
data['discount'].isnull().sum()
# 空值處理 用眾數填充
discount_mode = data['discount'].mode()
data['discount'].fillna(discount_mode[0], inplace=True)
data['discount'].isnull().sum()
# 將 9折等轉化為 float 0.90
data['discount'] = data['discount'].apply(
lambda x: float(re.findall('[0-9\.]+', x)[0])/10 if len(re.findall('[0-9\.]+', x))!=0 else None)
# 處理過後的空值數量 == 0
data['discount'].isnull().sum()
# 建立銷售額資料列
data['sales'] = data['price'] * data['sold'] * data['discount']
data['sales'].head()
經過分析發現天貓維生素品類,26家商店,兩年的銷售總額達到了1498551953元,即14.98億元。
1.2.2 銷售額佔比柱狀圖
對資料以藥店名稱shop_name進行聚類,並對銷售額sales進行逐項加和,求出每個商店兩年內的銷售總額,並繪製柱狀圖。
# 獲取總的銷售額
all_sales = data['sales'].sum()
# 對資料進行商店名稱聚類
shop_group = data.groupby('shop_name')
# 以藥店為組,進行銷售額彙總
shop_sales = shop_group['sales'].agg('sum')
# 以藥店銷售額降序排列26個藥店
shop_sales.sort_values(ascending=False)
# 獲取銷售額佔比
shop_sales_percent = (shop_sales / all_sales).sort_values(ascending=False)
plt.figure(figsize=(8, 5))
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.bar(range(len(shop_sales_percent[:10])), shop_sales_percent[:10])
plt.xticks(range(len(shop_sales_percent[:10])), shop_sales_percent[:10].index, rotation=45, ha='right')
plt.title('銷售額佔比最多的10家商店')
plt.gcf().subplots_adjust(bottom = 0.3)
plt.grid()
plt.show()
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.bar(range(len(shop_sales_percent[-10:])), shop_sales_percent[-10:])
plt.xticks(range(len(shop_sales_percent[-10:])), shop_sales_percent[-10:].index, rotation=45, ha='right')
plt.title('銷售額佔比最少的10家商店')
plt.gcf().subplots_adjust(bottom = 0.3)
plt.grid()
plt.show()
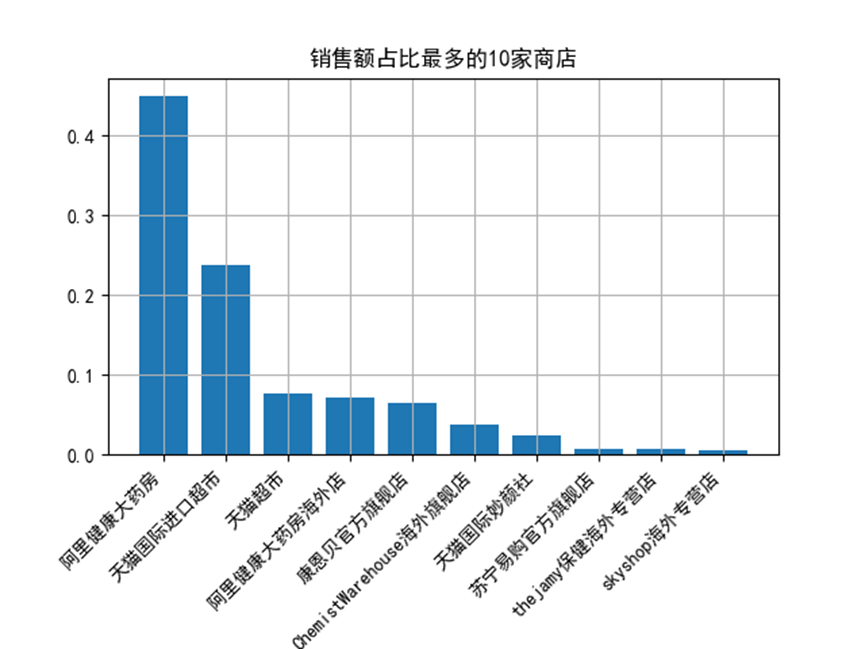
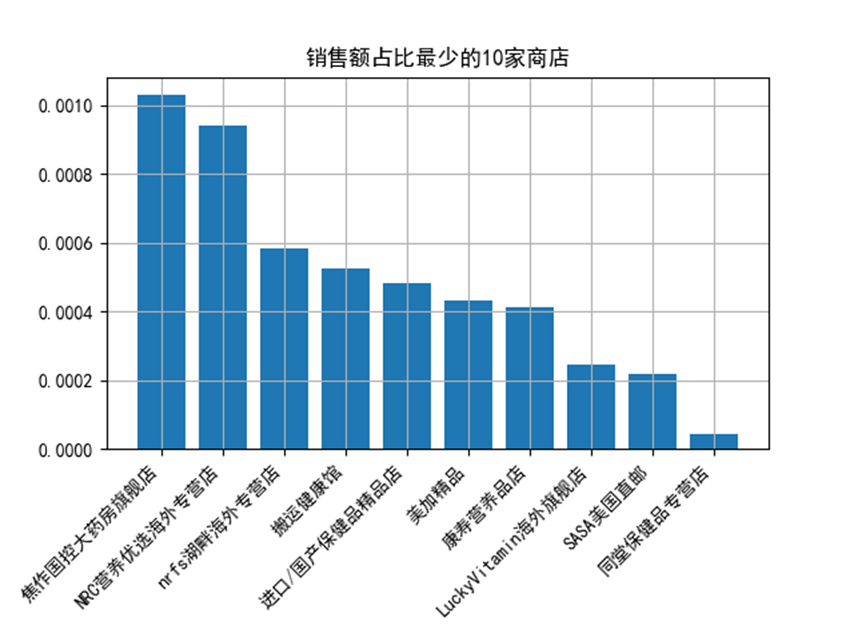
其中阿里健康大藥房的銷售總額以674820879元,即6.74億,佔比45.03%,位列第一。
天貓國際進口超市的銷售總額以355597052元,即3.55億,佔比23.73%,位列第二。
天貓超市的銷售總額以114308114元,即1.14億,佔比7.63%,位列第三。
後十家的藥店銷售總額加起來為7362907元,即736萬元,十家的總佔比為0.49%。
經過分析得知電商天貓維生素類藥品銷量最好的是阿里系的藥店,其他藥店的銷售份額佔比非常小。
1.3 阿里健康大藥房
由上述分析可得,阿里健康大藥房的銷售佔比最高。所以對於16958條阿里健康大藥房的資料進行銷售分析。
1.3.1 年度分析
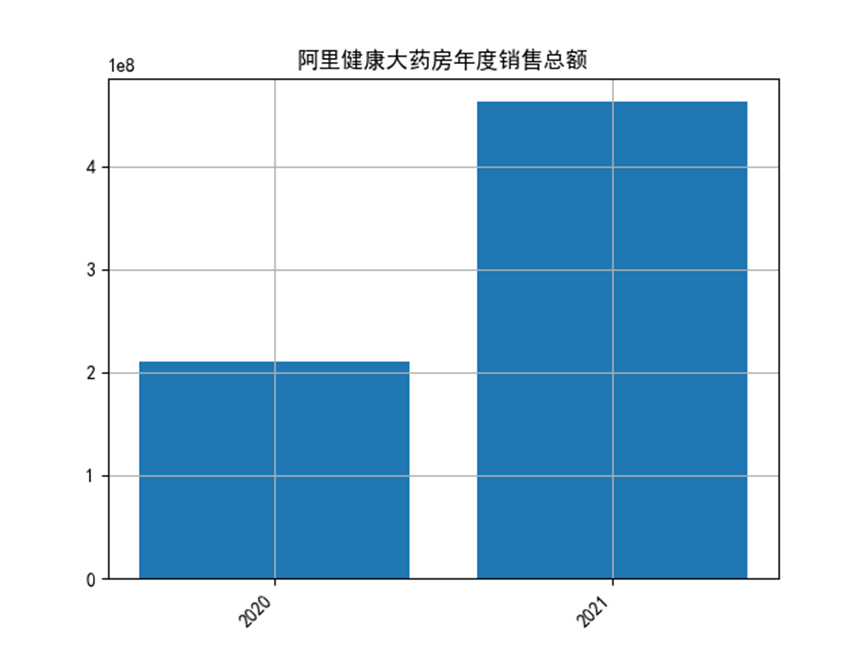
阿里健康大藥房2020年有5998條資料,2021年有10960條資料。
經過分析發現,阿里健康大藥房2021年銷售總額同比增長119.23%。增長幅度較大。
# 阿里健康大藥房
Ali = shop_group.get_group('阿里健康大藥房').copy()
# 年度分析對比
Ali_year = Ali.groupby(data.date_time.dt.year)
Ali_year_sum = Ali_year['sales'].sum()
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.bar(range(len(Ali_year_sum)), Ali_year_sum)
plt.xticks(range(len(Ali_year_sum)), Ali_year_sum.index, rotation=45, ha='right')
plt.title('阿里健康大藥房年度銷售總額')
plt.grid()
plt.show()
growth_rate = (Ali_year_sum[2021] - Ali_year_sum[2020]) / Ali_year_sum[2020]*100
1.3.2 季度分析
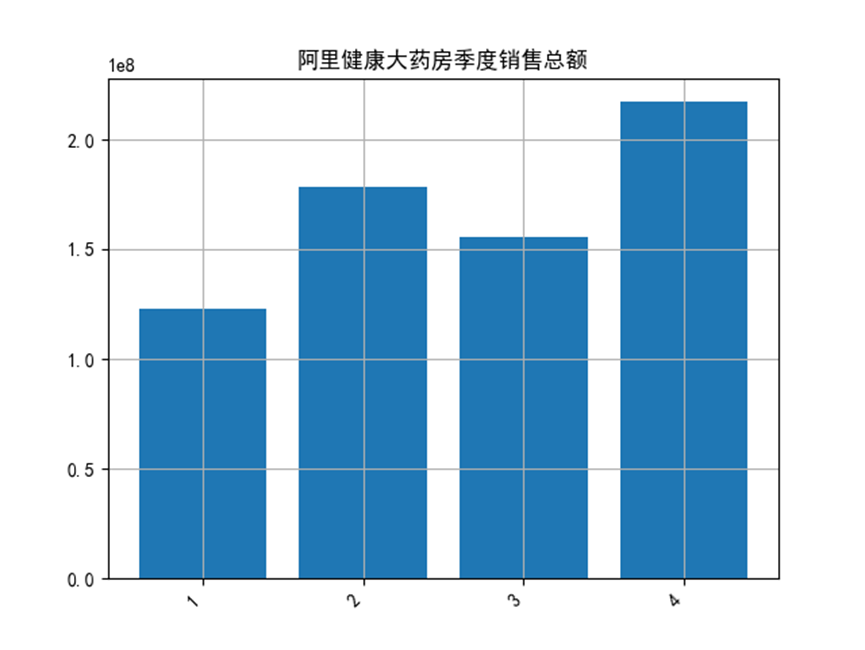
通過季度分析發現,第四季度購買次數最多,第一季度購買次數最少.
# 季度分析對比
Ali_qua = Ali.groupby(data.date_time.dt.quarter)
Ali_qua_sum = Ali_qua['sales'].sum()
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.bar(range(len(Ali_qua_sum)), Ali_qua_sum)
plt.xticks(range(len(Ali_qua_sum)), Ali_qua_sum.index, rotation=45, ha='right')
plt.title('阿里健康大藥房季度銷售總額')
plt.grid()
plt.show()
1.3.3 月度分析
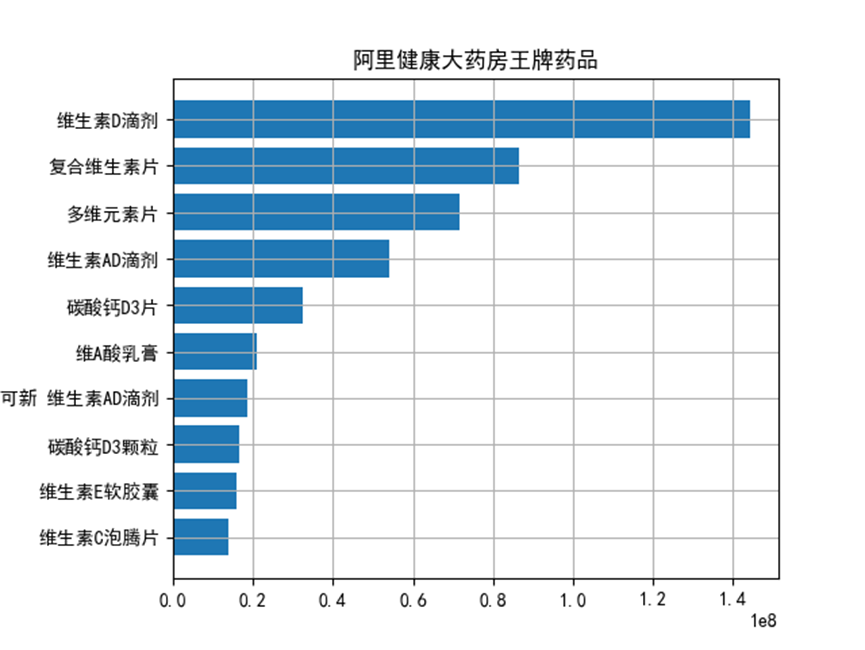
我們對阿里健康大藥房的暢銷商品進行了分析,其中維生素D滴劑,複合維生素片,多元維生素片,維生素AD滴劑,碳酸鈣D3片為五大暢銷產品。
# 月度分析
Ali['medicine'] = Ali['parameter'].apply(find_medi)
Ali_medi = Ali.groupby('medicine')
Ali_medi_sum = Ali_medi['sales'].sum().sort_values(ascending=False)
Ali_keyMedi = Ali_medi_sum.index[:5]
print(Ali_medi_sum)
Ali_medi_sum = Ali_medi['sales'].sum().sort_values()
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.barh(range(len(Ali_medi_sum[-10:])), Ali_medi_sum[-10:])
plt.yticks(range(len(Ali_medi_sum[-10:])), Ali_medi_sum[-10:].index)
plt.title('阿里健康大藥房王牌藥品')
plt.gcf().subplots_adjust(left = 0.2)
plt.grid()
plt.show()
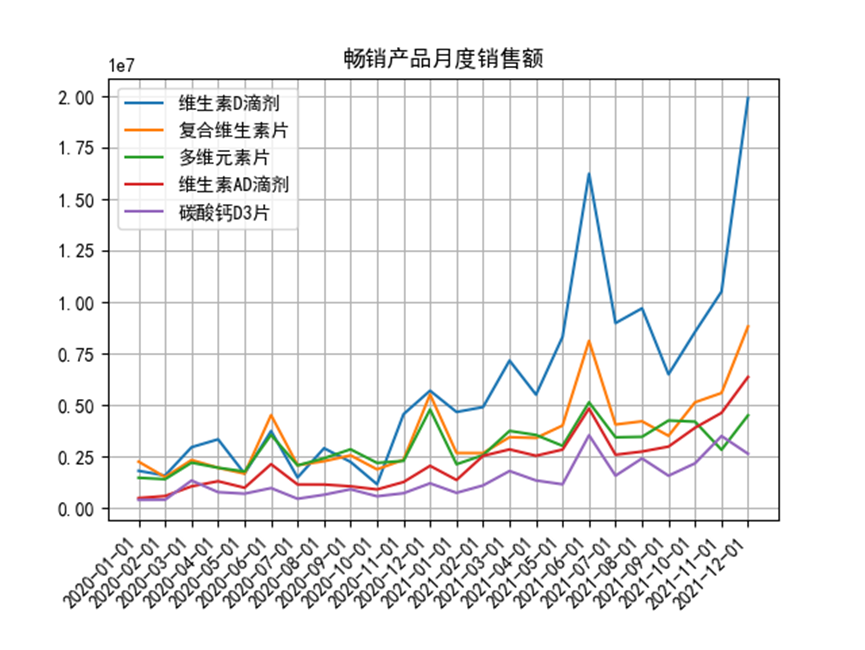
Ali_month_medi = Ali.groupby(['date_time','medicine'])
num = Ali_month_medi['sales'].sum()
for i in range(5):
num1 = num[num.index.get_level_values(1) == Ali_keyMedi[i]]
plt.plot(range(len(num1)), num1)
plt.legend(Ali_keyMedi)
plt.xticks(range(len(num1)), num1.index.get_level_values(0).date, rotation=45, ha='right')
plt.gcf().subplots_adjust(bottom = 0.2)
plt.title('暢銷產品月度銷售額')
plt.show()
通過月度銷售額分析,發現所有的暢銷產品都有高頻波動的跡象,存在明顯的季節變動,每年6-7月,12-1月為銷售量會大幅增加。
2 藥品分析
2.1 資料預處理
經過對於資料的分析,藥品名稱在parameter裡,並且有不同的形式。
藥品通用名稱,系列,藥品名稱。
對於藥品名稱來說,資料中並沒有顯式的給出,比較有說服力的是parameter中的藥品通用名稱,其他屬性存在著許多問題,資料雜亂。
系列屬性存在無關資訊列如,第14550行‘特價優惠’,第14628行‘其他’。
產品名稱屬性廣泛存在品牌名稱,例如第45行‘康恩貝牌維生素C咀嚼片(香橙味)’,第14663行‘湯臣倍健?鈣維生素D維生素K軟膠囊’。
所以我們首先將阿里健康大藥房的藥品通用名稱提取出來,製作成字典(72個品類的dict.txt)。接著採用北大的Python分詞包pkuseg,設定自己的字典(dict.txt),進行醫學分詞。
利用分詞包從資料的title裡進行醫學分詞來獲取藥品資料,獲得29085條資料。
對parameter裡的藥品通用名稱使用正規表示式提取出來,獲得資料15345條。
將兩者合併獲得30418條資料。
def find_medi(x):
if type(x) is str:
pattern = r"藥品通用名:([\u4E00-\u9FD5 0-9 a-z A-Z ‘ \. /]+)"
result = re.findall(pattern, x)
if len(result) >= 1:
return result[0]
else:
return None
else:
return None
def title_split(x):
x.upper()
result = segcut.cut(x)
if len(result) >= 1:
for i in result:
if i in dict:
return i
return None
else:
return None
dict = list(Ali_medi_sum.index)
f = open("dict.txt", "w", encoding='utf-8')
for line in dict:
f.write(line + '\n')
f.close()
segcut = pkuseg.pkuseg(model_name = "medicine", user_dict = 'dict.txt', postag = False)
data['medicine'] = data['title'].apply(title_split)
data['medicine1'] = data['parameter'].apply(find_medi)
# 以medicine1 的資料填充 medicine 的空值
data["medicine"].fillna(data["medicine1"], inplace=True)
2.2 藥品數量分析
通過對資料的藥品通用名稱統計,有112種藥品。
medi_group = data.groupby('medicine')
medi_group.size()
2.3 藥品銷售額佔比
# 以藥品為組,進行銷售額彙總
medi_sales = medi_group['sales'].agg('sum')
# 以藥品銷售額降序排列 獲得銷售佔比
num = medi_sales.sort_values(ascending=False)
num_rate = num / num.sum()
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.bar(range(len(num_rate[:10])), num_rate[:10])
plt.xticks(range(len(num_rate[:10])), num_rate[:10].index, rotation=45, ha='right')
plt.title('銷售額佔比最多的10個品類')
plt.gcf().subplots_adjust(bottom = 0.2)
plt.grid()
plt.show()

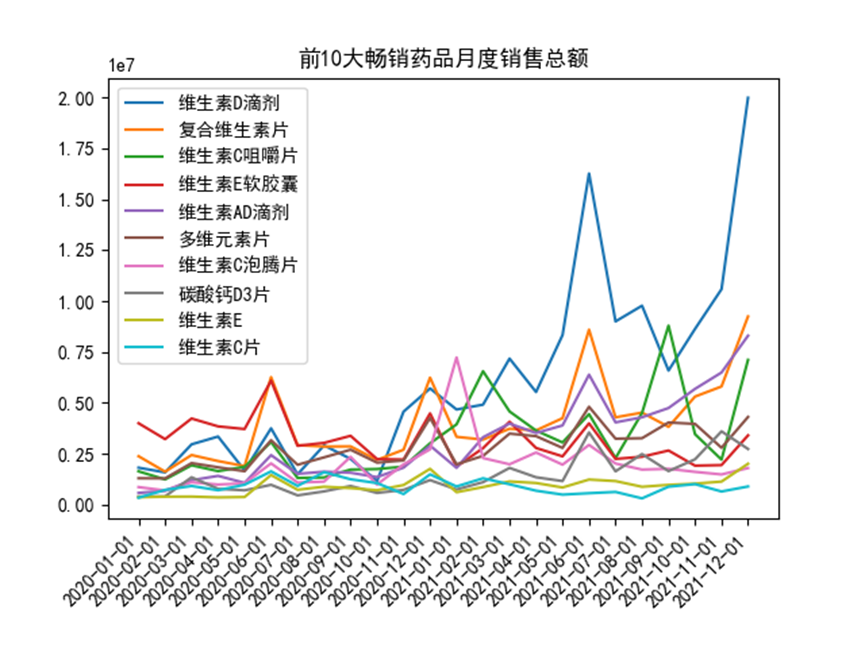
2.4 10個藥品每月銷售額曲線圖
keyMedi = list(medi_sales.sort_values(ascending=False).index)[:10]
month_medi = data.groupby(['date_time','medicine'])
num = month_medi['sales'].sum()
for i in range(10):
num1 = num[num.index.get_level_values(1) == keyMedi[i]]
plt.plot(range(len(num1)), num1)
plt.show()
plt.legend(keyMedi)
plt.xticks(range(len(num1)), num1.index.get_level_values(0).date, rotation=45, ha='right')
plt.gcf().subplots_adjust(bottom = 0.2)
plt.title('前10大暢銷藥品月度銷售總額')
plt.show()
3 藥品品牌分析
我們發現藥品的品牌在Parameter裡所以利用正規表示式進行提取。
3.1 資料預處理
# 品牌分析
pattern = "品牌:([\u4E00-\u9FD5 0-9 a-z A-Z ‘ \. \+ - /]+)"
def find_brand(x):
if type(x) is str:
pattern = "品牌:([\u4E00-\u9FD5 0-9 a-z A-Z ‘ \. \+ - /]+)"
result = re.findall(pattern, x);
if len(result) > 0:
return result[0]
else:
return None
else:
return None
data['brand'] = data['parameter'].apply(find_brand)
3.2 品牌數目
分析發現總共有512個品牌。
# 對資料進行品牌名稱聚類
brand_group = data.groupby('brand')
brand_group.size()
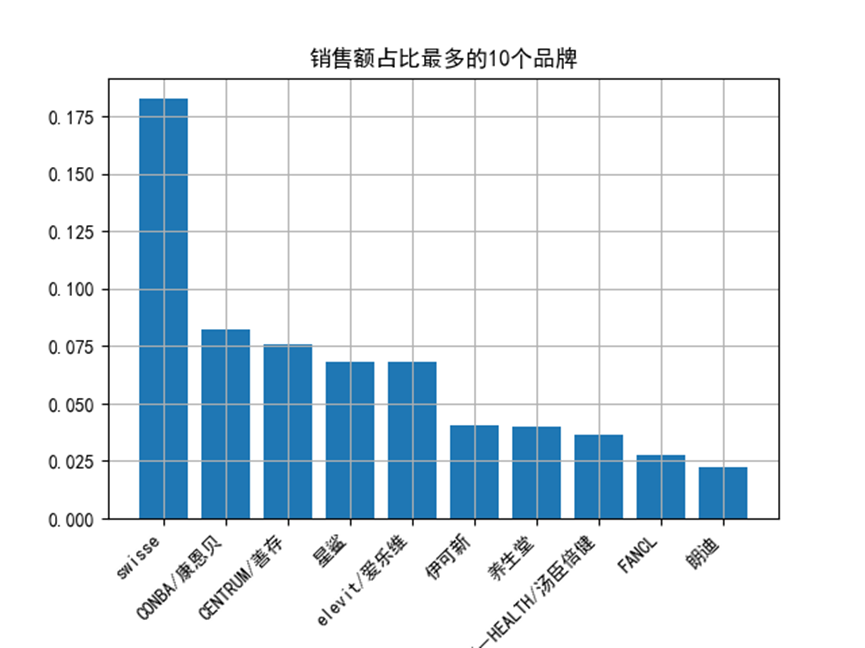
3.3 品牌銷售額佔比
# 以品牌為組,進行銷售額彙總
brand_sales = brand_group['sales'].agg('sum')
# 以品牌銷售額降序排列
num = brand_sales.sort_values(ascending=False)
brand_top = list(num.index)[:10]
num_rate = num / num.sum()
plt.rcParams['font.sans-serif'] = 'Simhei'
plt.bar(range(len(num_rate[:10])), num_rate[:10])
plt.xticks(range(len(num_rate[:10])), num_rate[:10].index, rotation=45, ha='right')
plt.title('銷售額佔比最多的10個品牌')
plt.gcf().subplots_adjust(bottom = 0.2)
plt.grid()
plt.show()
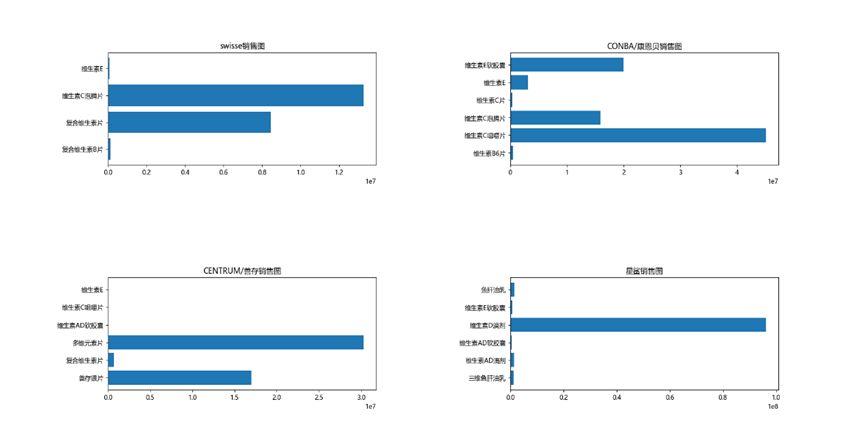
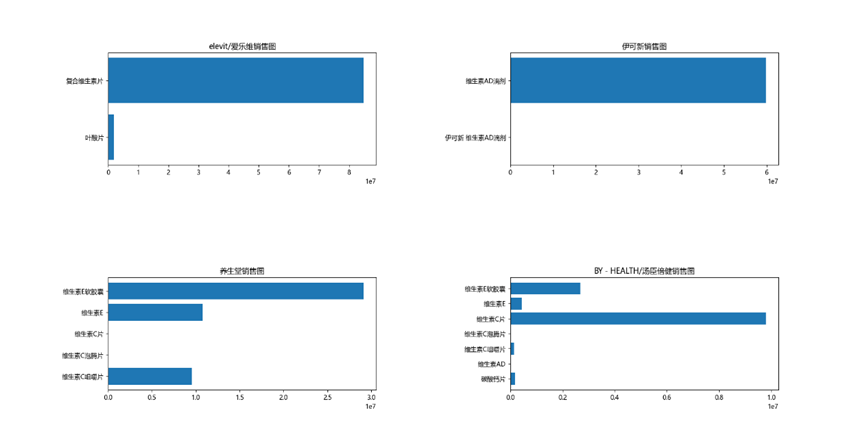
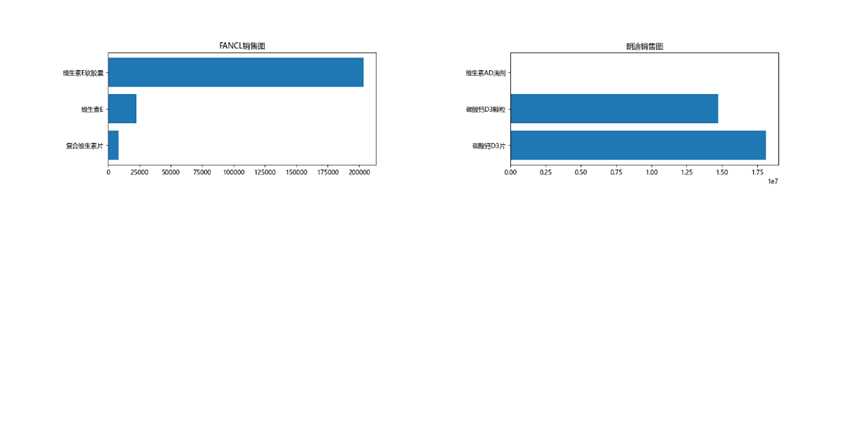
3.4 品牌銷售好的原因分析
我們對十大品牌的藥品銷售情況做了分析,這些品牌之所以銷量好,首先是藥物銷售品類與10大暢銷品類高度重合,其次可能是品牌自身在這些品類的行銷好,消費者認可。
# 品牌銷售分析
band_medicine = data.groupby(['brand','medicine'])
b_m_sum = band_medicine['sales'].sum()
num = b_m_sum
num1 = num[num.index.get_level_values(0) == brand_top[0]]
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
plt.subplots_adjust(left=None,bottom=None,right=None,top=None,wspace=0.5,hspace=1)
for i in range(1,11):
# 往畫布上新增子圖:按五行二列,新增到下標為plt_index的位置(由於這個顯示不太好,很擠,所以最後用 兩行兩列4個 生成3次 獲得了最後的圖)
plt.subplot(5, 2, i)
# 繪圖
num1 = num[num.index.get_level_values(0) == brand_top[i-1]]
plt.barh(range(len(num1)), num1)
plt.yticks(range(len(num1)), num1.index.get_level_values(1))
plt.title(brand_top[i-1] + '銷售圖')
# 顯示畫布
plt.show()
4 預測銷售總額
這裡的預測我們採取時間序列的差分整合移動平均自迴歸模型(ARIMA)。
4.1 源資料
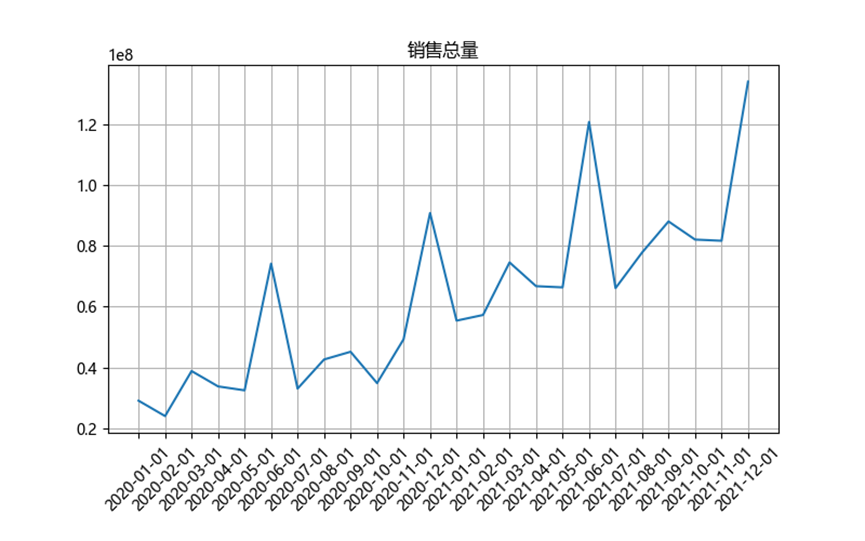
date = data.groupby('date_time')
date_sales = date['sales'].agg('sum')
plt.figure(figsize=(8,5))
plt.plot(range(24), date_sales)
plt.xticks(range(24), date_sales.index.date, rotation=45)
plt.gcf().subplots_adjust(bottom = 0.2)
plt.title('銷售總量')
plt.grid()
plt.show()

4.2 引數選擇
平穩性檢驗:
採用單位根檢驗,對時間序列單位根的檢驗就是對時間序列平穩性的檢驗,非平穩時間序列如果存在單位根,則一般可以通過差分的方法來消除單位根,得到平穩序列。
style.use('ggplot' )
plt. rcParams['font.sans-serif'] = ['SimHei']
plt. rcParams['axes.unicode_minus'] = False
sales_train = date_sales
sales_diff1 = sales_train.diff().dropna()
for i in range(1,3):
plt.subplot(1, 2, i)
if(i==1):
plt.plot(sales_train)
plt.title("源資料")
else:
plt.plot(sales_diff1)
plt.title("一階差分")
print(u'原始序列的ADF檢驗結果為:', ADF(sales_train))
print(u'一階差分的ADF檢驗結果為:', ADF(sales_diff1))

原始序列的ADF檢驗結果為: (-0.25294595330495406, 0.9319092621668796, 7, 16, {'1%': -3.9240193847656246, '5%': -3.0684982031250003, '10%': -2.67389265625}, 484.53439721589336)
一階差分的ADF檢驗結果為: (-9.322072363056753, 9.831298270974292e-16, 4, 18, {'1%': -3.859073285322359, '5%': -3.0420456927297668, '10%': -2.6609064197530863}, 455.9637318833934)
一階差分單位根檢驗p值<0.05,原始序列p值>0.05,於是ARIMA中的引數d定為1。
相關係數:
- 自相關係數(ACF):自相關係數度量的是同一事件在兩個不同時期之間的相關程度,形象的講就是度量自己過去的行為對自己現在的影響。
- 偏自相關係數(PACF):計算某一個要素對另一個要素的影響或相關程度時,把其他要素的影響視為常數,即暫不考慮其他要素的影響,而單獨研究那兩個要素之間的相互關係的密切程度時,稱為偏相關。
acf = plot_acf(sales_diff1, lags=10)
plt.title("ACF" )
acf.show()
pacf = plot_pacf(sales_diff1, lags=10)
plt.title("PACF" )
pacf.show()
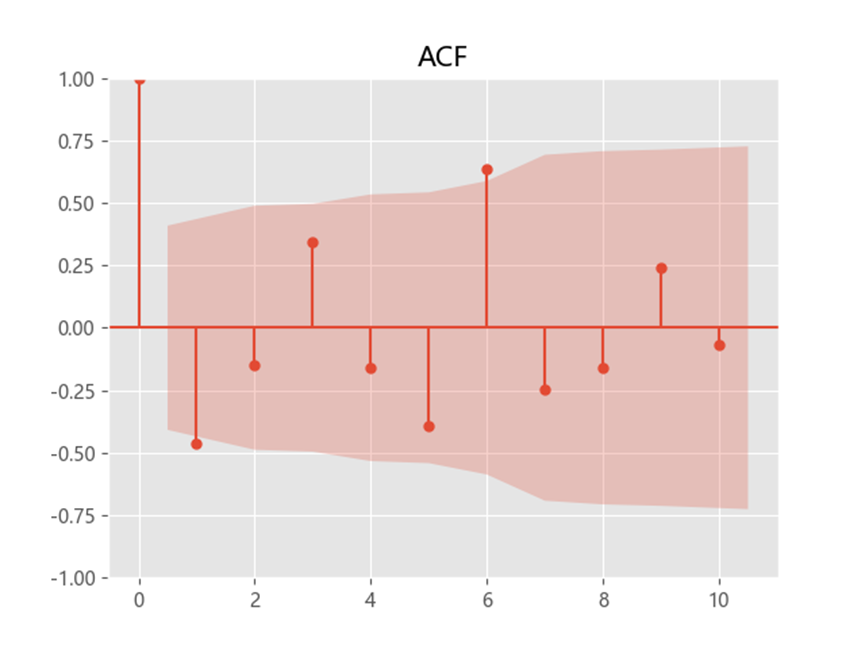
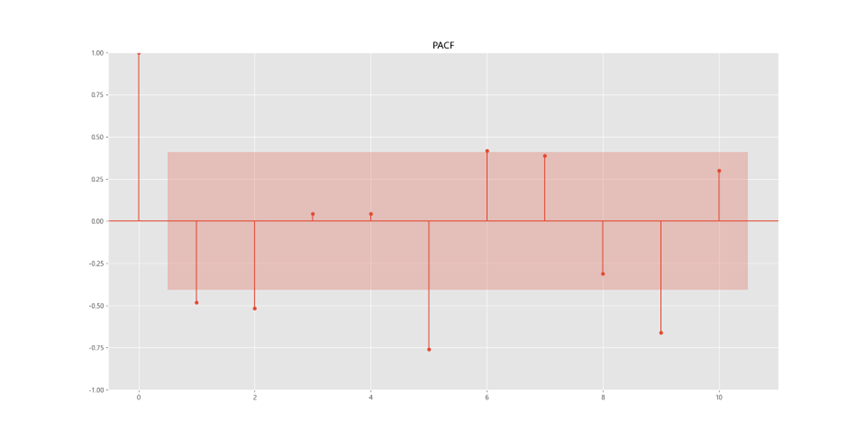
趨勢序列 ACF 有 1 階截尾,PACF 有 1 階截尾尾。因此可以選 p=1, q=1。
4.3模形擬合預測
model = sm.tsa.arima.ARIMA(sales_train, order=(1, 1, 1))
result = model.fit()
#print (result. sumary()
pred = result.predict( '20220101','20220301' ,dynamic=True, typ='levels' )
print(pred)
plt.figure(figsize=(12,8))
plt.xticks(rotation=45)
plt.plot(pred)
plt.plot(sales_train)
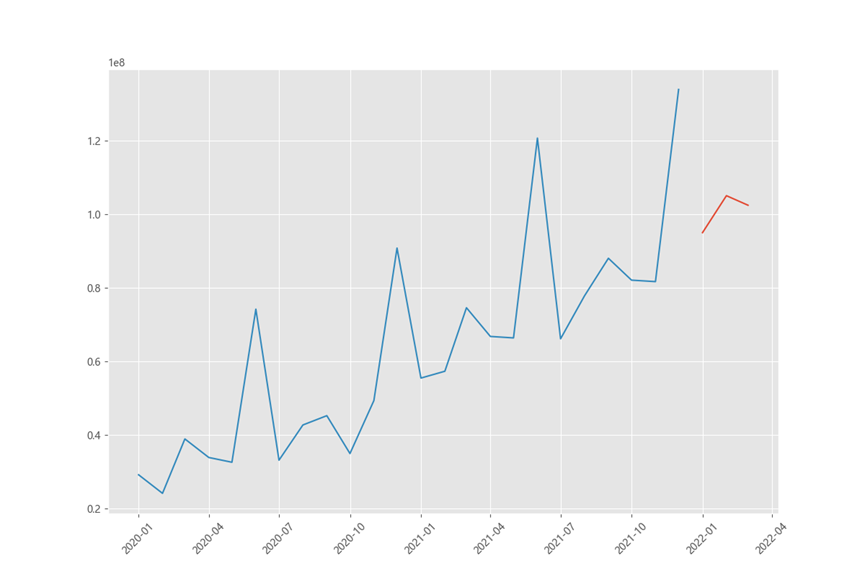
預測結果:
2022-01-01 9.497130e+07 94971300.0
2022-02-01 1.050360e+08 105036000.0
2022-03-01 1.024374e+08 102437400.0
4.4 模形評價
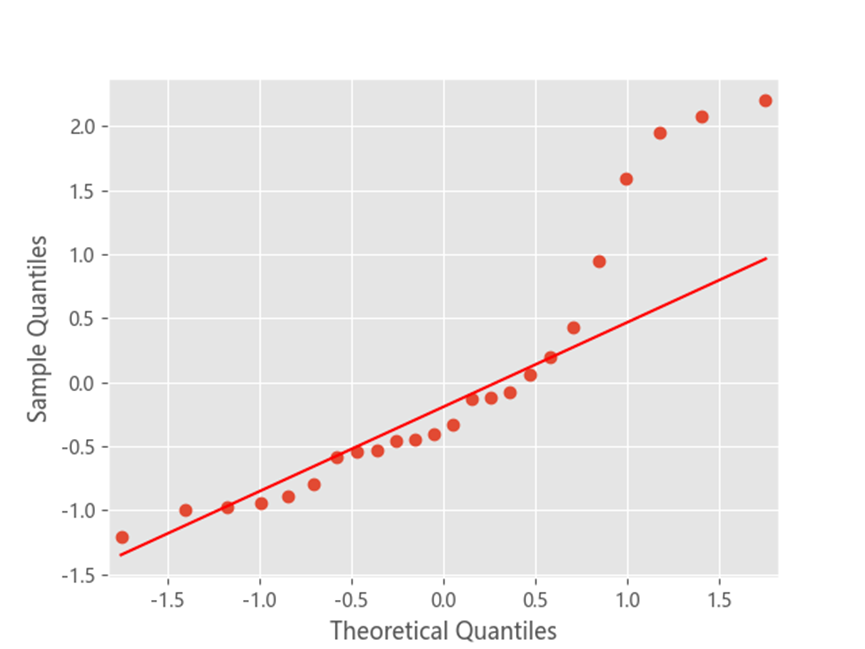
使用QQ圖檢驗殘差是否滿足正態分佈。p值在0.05附近可以看作是成正態分佈。
resid = result.resid # 求解模型殘差
plt.figure(figsize=(12, 8))
qqplot(resid, line='q', fit=True)
stats.normaltest(resid)#檢驗序列殘差是否為正態分佈
5 電商經營策略
商品經營無外乎更便宜,更豐富,更方便,提高商品週轉率。
關於銷售的貨品,主要以暢銷的10大藥品為主。
‘維生素D滴劑', '複合維生素片', '多維元素片', '維生素AD滴劑', '碳酸鈣D3片', ‘維生素C咀嚼片', ‘維生素E軟膠囊', ‘維生素E', ‘維生素C泡騰片', ‘維生素C片'。
藥品品牌的選擇以暢銷品牌的主打藥品(銷量好)為主。
'swisse':維生素C泡騰片。
'CONBA/康恩貝':維生素C咀嚼片。
'CENTRUM/善存':善存銀片,多維元素片。
'星鯊':維生素D滴劑
'elevit/愛樂維':複合維生素片。
'伊可新':維生素AD滴劑,。
'養生堂':維生素E軟膠囊, 維生素C咀嚼片。
'BY-HEALTH/湯臣倍健':維生素E軟膠囊, 維生素C片。
'FANCL':維生素E軟膠囊。
'朗迪':碳酸鈣D3片。
多樣化的暢銷貨品銷售能提高商品週轉率,也能為消費者提供更豐富的選擇。
鑑於銷售旺季在每年6-7月,12-1月。所以應該提前一個月進行銷售的預熱。同時儘量用折扣給消費者一個便宜的低價,來拉動銷量。
儘量完善好售後客服機制,用心服務好客戶,方便客戶。
作者:Dba_sys
轉載以及參照請註明原文連結:https://www.cnblogs.com/asmurmur/p/17088572.html
本部落格所有文章除特別宣告外,均採用CC 署名-非商業使用-相同方式共用 許可協定。