論文翻譯:2022_2022_TEA-PSE 2.0:Sub-Band Network For Real-Time Personalized Speech Enhancement
論文地址:TEA-PSE 2.0:用於實時個性化語音增強的子帶網路
參照:
摘要
個性化語音增強(Personalized speech enhancement,PSE)利用額外的線索,如說話人embeddings來去除背景噪聲和干擾語音,並從目標說話人提取語音。此前,Tencent - Ethereal - Audio - Lab個性化語音增強(TEA-PSE)系統在ICASSP 2022深度噪聲抑制(DNS2022)挑戰賽中排名第一。在本文中,我們將TEA-PSE擴充套件到它的子帶版本TEA-PSE 2.0,以降低計算複雜度並進一步提高效能。具體來說,我們採用有限脈衝響應濾波器組和頻譜分割來降低計算複雜度。我們在系統中引入了時頻折積模組(TFCM),用小的折積核來增加感受野。此外,我們探索了幾種訓練策略來優化兩級網路,並研究PSE任務中的各種損失函數。在語音增強效能和計算複雜度方面,TEA-PSE 2.0明顯優於TEA-PSE。在DNS 2022盲測試集上的實驗結果表明,與之前的TEA-PSE相比,TEA-PSE 2.0提高了0.102 OVRL個性化DNS MOS,僅進行了21.9%的乘法-累積操作。
索引術語:個性化語音增強,子帶,實時,深度學習
1 引言
實時通訊(RTC)在我們的日常生活中變得不可或缺。然而,語音質量受到背景噪聲、混響、背景說話人的語音等影響。有效的語音增強在RTC系統中起著重要的作用。傳統的語音增強主要是去除背景噪聲和混響。它不能過濾掉干擾的說話人。為此,我們提出了個性化語音增強(PSE)[1 4],根據目標說話人錄入的語音片段,從所有其他說話人和背景噪聲中提取目標說話人的聲音。
最新的ICASSP 2022 DNS挑戰賽[5]旨在推廣全頻段實時個性化語音增強任務。TEA-PSE[6]通過專門設計的兩階段框架在ICASSP 2022 DNS個性化語音增強評估集上獲得優異的效能。但它具有27.84 G每秒的乘法累積運算(mac)的高計算複雜度,並直接對全頻段訊號執行,實時因子(RTF)為0.96。此外,TEA-PSE中使用的編碼器-解碼器結構不能有效地捕獲長程相關性,因為根據[7],折積的感受野受到限制。
為了降低計算複雜度,
- 第一種方法是特徵壓縮。例如,RNNoise[8]和Personalized PercepNet[9]分別使用Bark-scale和等效矩形頻寬(ERB) scale壓縮全頻帶輸入特徵。這種特徵壓縮方法不可避免地會丟失關鍵的頻段資訊,導致效能不佳。
- 第二種方法是頻譜分割,這在最近的語音增強(SE)研究中很常見。Lv et al.[10]和Li et al.[11]在短時傅立葉變換(STFT)後進行頻譜分裂,將堆疊的子帶作為批次處理,而不是直接對全帶特徵進行建模。與這些批次處理方法不同,DMF-Net[12]和SF-Net[13]採用級聯結構的頻譜分裂。在處理較高頻帶時,預處理過的較低頻帶會給出外部知識引導。
- 第三種方法是基於有限脈衝響應(FIR)的子帶分析與合成,該方法可以有效降低經典數位訊號處理[14]的頻寬。多頻帶WaveRNN[15]和多頻帶MelGAN[16]在文字到語音(TTS)任務的子帶處理中獲得了較高的MOS效果。這種用於音樂源分離(MSS)任務的子帶處理[17]明顯優於全帶處理。
另一方面,最近的多階段方法在直觀的假設下,將原來複雜的語音增強問題分解為多個更簡單的子問題,並在每個階段逐步得到更好的解的前提下,表現出了優異的效能。儘管有專門設計的模型體系結構,我們也注意到這些方法中採用的優化策略是非常不同的。具體來說,SDD-Net[18]和TEA-PSE[6]在訓練當前模組時凍結前一階段的模組。不同的是,CTS-Net[19]以較低的學習率對前面的模組進行微調。Wang et al.[20]在分階段訓練的基礎上,採用端到端的訓練方法,用一個損失函數同時優化不同的模組。多階段訓練方法的最佳訓練策略有待進一步的比較研究。
在本文中,我們提出了TEA-PSE 2.0,以進一步提高感知語音質量,同時顯著抑制噪聲和干擾,降低計算複雜度。我們的貢獻是三重的。首先,我們利用設計的FIR濾波器和直接頻譜分割擴充套件了原始TEA-PSE模型的子帶處理。子帶輸入比全帶輸入具有更好的語音增強效能,並顯著加快了模型推理速度。其次,利用時頻折積模組[21]對模型進行升級,利用小的折積核來增加模型的感受野;實驗結果表明,改進後的兩級網路具有顯著的效能提升。最後,我們比較了多階段方法的順序優化和聯合優化。本文還研究了PSE的單域和多域損失函數。結果表明,序列優化訓練策略和多域損失函數的優越性。最後,在ICASSP 2022 DNS挑戰盲測試集上,提出的TEA-PSE 2.0優於之前的TEA-PSE,具有0.102 OVRL個性化DNSMOS (PDNSMOS)[22]評分提高。令人印象深刻的是,它的計算複雜度只有TEA-PSE的21.9%
2 問題公式化
假設$y$是目標說話人、干擾說話人和背景噪聲的混合物,由一個麥克風在時域捕獲。
$$公式1:y(n)=s(n)*h_s(n)+z(n)*h_z(n)+v(n)$$
其中$n$表示波形取樣點索引,$s$表示目標說話人的訊號,$z$表示干擾說話人的訊號,$h_s$和$h_z$表示說話人和麥克風之間的房間脈衝響應(RIR), $v$表示附加噪聲。我們用$e$表示目標說話人的註冊語音。在頻域中,式(1)可表示為
$$公式2:Y(t, f)=S(t, f) \cdot H_s(t, f)+Z(t, f) \cdot H_z(t, f)+V(t, f)$$
其中$t$和$f$分別是幀索引和頻率索引。我們在論文中沒有明確地考慮到去混響。在實驗過程中,背景噪聲、干擾語音和混響可能同時存在。
3 TEA-PSE 2.0
3.1 子帶分解

圖1所示 TEA-PSE 2.0總體流程圖
在圖1中,我們展示了TEA-PSE 2.0的總體流程圖。我們設計了兩個流程來比較不同子帶處理策略的建模能力。第一個流程是紅線,它是基於FIR濾波器組在訊號級進行子帶分析和合成。第二個流程是綠線,這是頻譜分割與合併。其中$K$為取樣間隔,$F_M \in R^{M*M}$為STFT核,$F_M^{-1}$為iSTFT核,M為窗長。
FIR濾波器組分析與合成(FAS)。我們採用穩定高效的濾波器組 偽正交鏡濾波器組[14](pseudo quadrature mirror filter bank (PQMF))進行子帶分解和訊號重構。分析和合成都包含K個FIR濾波器組,其中K表示子帶數。
-
- 子帶編碼器有三個過程,包括FIR分析、下取樣和STFT。我們用$y_k$表示分析和下取樣的輸出,其中$k \in [1, K]$是子帶索引。$y_k$的取樣率為$\frac{1}{K}$,$Y_k \in C^{T*F'}$表示$y_k$對應的頻域。然後沿通道維度堆疊$Y_k$,形成特徵$Y_{fas} \in C^{T*F'*K}$,作為PSE模組的輸入。
- 子帶譯碼器有三個過程,分別是iSTFT、上取樣和FIR合成。我們沿著通道維度對PSE模組的輸出$\hat{S}_{fas} \in C^{T*F'*K}$進行切片,作為每個子帶輸出$\hat{S}_k \in C^{T*F'}$的預測。經過iSTFT和上取樣後,$\hat{S}_k$變為$\hat{s}_k$,且$\hat{s}_k$的取樣率與$y$相同。最後,我們將$\hat{s}_k$通過一組合成濾波器組重構源訊號$\hat{s}$。
頻譜分割與合併(SSM)。我們對每個子帶$Y_k \in C^{T*\frac{F}{K}}$沿頻率軸對全頻段頻譜$Y \in C^{T*F}$進行拆分,然後沿通道軸進行堆疊,形成輸入特徵$Y_{ssm} \in C^{T*\frac{F}{K}*K}$作為PSE模組的輸入。在訊號重構過程中,對網路輸出訊號$\hat{S}_{ssm} \in C^{T*\frac{F}{K}*K}$進行重構,恢復全頻段頻譜$\hat{S} \in C^{T*F}$。
3.2 兩階段PSE網路

圖2所示。(a) PSE模組的詳細資訊。(b) MAG-Net 的網路詳情
PSE模組的詳細資訊如圖2(a)所示。我們保留了與TEA-PSE[6]相同的兩階段框架,分別包含了MAG-Net和COM-Net來處理 幅度(magnitude)和複數(complex)特徵。圖2(b)顯示了PSE模組的MAG-Net的細節。我們用$E$表示由說話人編碼器網路提取的說話人embedding。對於MAG-Net,我們使用觀測訊號$Y$的幅值作為輸入,目標幅值作為訓練目標。MAG-Net 對噪聲成分和干擾語音有較強的抑制作用。然後,將$\hat{S}_1$與噪聲相位$e^{j\varphi (Y)}$耦合,得到實虛(RI)譜$(\hat{S}_r^1,\hat{S}_i^1)$作為COM-Net的輸入。我們還將觀測到的頻譜$(Y_r, Y_i)$作為COM-Net的輸入,進一步去除殘留噪聲和干擾語音成分。在COM-Net的輸入$(\hat{S}_r^1,\hat{S}_i^1)$和輸出之間進行殘差連線,形成最終的輸出$(\hat{S}_r^2,\hat{S}_i^2)$。COM-Net具有與MAGNet相似的網路拓撲結構,而其雙解碼器架構被設計用於單獨估計RI頻譜。
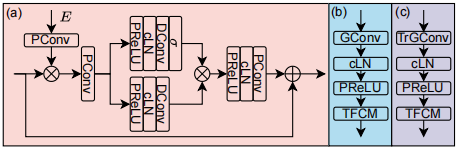
圖3。(a) GTCM的詳細資料。(b)編碼器FD層的詳細資訊。(c)解碼器中FU層的詳細資訊
編碼器和解碼器。編碼器由三個頻率下取樣(FD)層組成。圖3(b)顯示了FD層的詳細情況。其次是Gated Conv (GConv)[23,24],累積層範數(cLN) [25], PReLU和時頻折積模組(TFCM)[21]。我們使用TFCM用小的折積核來增加感受野,解決了原來的折積編解碼器結構[7]中感受野有限的問題。譯碼器有三層頻率上取樣(FU)層,其結構如圖3(c)所示。它採用鏡面結構作為FD層,用轉置門控Conv (TrGConv)代替GConv。
堆疊門控時序折積模組。我們的堆疊門控時序折積模組(S-GTCM)重複了一堆GTCM層,如圖3(a)所示,它保持了與TEA-PSE[6]相同的架構。GTCM包含兩個點折積(PConv)和一個擴張折積(DConv)。在相鄰折積之間,對PReLU和cLN進行插值。在輸入和輸出之間應用殘差連線,用於訓練更深層次的網路。在每個S-GTCM層中,第一個GTCM層接受混合語音的學習表示$X \in R^{T*F''}$以及說話人embedding 的$E \in R^D$,而其他GTCM層只接受混合語音特徵作為輸入。首先沿時間維重複說話人embedding,形成$E' \in R^{T*D}$,然後傳遞PConv以保持與學習表示相同的維數。然後將學習到的表示與嵌入在特徵維度中的說話者相乘。
3.3 損失函數
我們首先應用尺度不變訊雜比(SISNR)[25]損失
$$公式3:\mathcal{L}_{\mathrm{si}-\mathrm{snr}}=20 \log _{10} \frac{\left\|\left(\hat{s}^T s / s^T s\right) \cdot s\right\|}{\left\|\left(\hat{s}^T s / s^T s\right) \cdot s-\hat{s}\right\|},$$
其中$\hat{s}$表示估計的說話人。
然後使用冪律壓縮相位感知( power-law compressed phase-aware,PLCPA)損耗。PLCPA有利於ASR的準確性和感知質量[26,27]。它主要由以下兩部分組成:幅度損失$L_{mag}$和相位損失$L_{pha}$。
$$公式4:\mathcal{L}_{\mathrm{mag}}=\frac{1}{T} \sum_t^T \sum_f^F \|\left. S(t, f)\right|^p-\left.|\hat{S}(t, f)|^p\right|^2$$
$$公式5:\mathcal{L}_{\text {pha }}=\frac{1}{T} \sum_t^T \sum_f^F \|\left. S(t, f)\right|^p e^{j \varphi(S(t, f))}-\left.|\hat{S}(t, f)|^p e^{j \varphi(\hat{S}(t, f))}\right|^2$$
我們利用非對稱損耗來懲罰目標說話人的估計頻譜,這有利於緩解過度抑制[28]。
$$公式6:\mathcal{L}_{\text {asym }}=\frac{1}{T} \sum_t^T \sum_f^F\left|\operatorname{ReLU}\left(|S(t, f)|^p-|\hat{S}(t, f)|^p\right)\right|^2$$
兩級網路使用以下損失進行訓練。我們最初只用$L1$訓練MAG-Net。
$$公式7:L_1=L_{si-snr}+L_{mag}+L_{asym}$$
在此基礎上,將預先訓練好的magg - net引數凍結,只對COM-Net進行優化
$$公式8:L_2=L_{si-snr}+L_{mag}+L_{pha}+L_{asym}$$
$\hat{S}$和$S$分別為估計光譜和clean 光譜。譜壓縮因子$p$設定為 0.5。運算元$\varphi $計算一個複數的相位。
4 實驗
4.1 資料集
我們使用ICASSP 2022 DNS-challenge全頻段資料集[5]進行實驗。大約750小時的純淨語音和181小時的噪音剪輯組成了個性化DNS (PDNS)訓練集。總共有3230個說話人。噪聲資料來自DEMAND[31]、Freesound和AudioSet[32]資料庫。
我們使用了700小時的純淨語音資料和150小時的噪聲資料,它們都來自PDNS資料集,以生成訓練集。選取50小時的純淨語音資料和15小時的噪聲資料生成開發集。我們基於RT60 $\in$ [0.1, 0.6]s的image method [33]生成100,000個房間脈衝響應(RIRs)。房間的大小可以用$W*d*h$表示,其中w $\in$ [3, 8]m, d $\in$ [3, 8]m, h $\in$ [3, 4]m。麥克風分散在空間中,$h_{mic}$範圍為[0,1.2]m。語音聲源可以在房間的任何地方找到,$h_{speech}$範圍為[0.6,1.8]m。聲源與麥克風之間的距離範圍為[0.3,6.0]m。在訓練集和開發集中分別有80,000和10,000個RIR。
評價資料可分為兩部分。模擬集旨在評估模型在不可見說話人上的效能。我們使用KING-ASR-215資料集作為源語音,PDNS噪聲集中剩餘的16小時資料作為源噪聲,剩餘的10,000個RIR建立了201個說話人的2010個noise-clean配對的模擬集。在每對noise-clean對中加入一個SIR範圍為[5,20]dB的隨機干擾說話人和一個訊雜比範圍為[5,20]dB的隨機噪聲。第二部分是DNS2022盲測試集,由859個真實測試片段組成,其中121個片段存在干擾語音,其餘738個片段不存在干擾語音。應該注意的是,在訓練、開發和模擬評估集之間的源資料沒有重疊。
4.2 訓練步驟
訓練資料是動態生成的,每batch分割為10秒的塊,訊雜比和SIR範圍分別為[5,20]dB和[5,20]dB。混合物的刻度調整為[35,15] dBFS。此外,在訓練過程中,將源語音資料的50%與RIR進行折積,以模擬混響場景。此外,20%的訓練資料只包含一個干擾說話人,30%包含一個干擾說話人和一種型別的噪聲,30%只包含一種型別的噪聲,剩下的20%包含兩種型別的噪聲。
我們對觀測到的訊號採用漢寧窗,幀長為20 ms,幀移為10 ms。STFT包含1024個觀測訊號輸入點,取樣率為48 kHz,導致513-dim特徵。Adam優化器[34]用於優化每個神經模型,使用$1e-3$的初始學習速率。如果驗證損失連續兩個週期沒有下降,則學習率減半。每個階段訓練60個epoch。我們應用最大l2範數5進行梯度裁剪。
編碼器有3個FD層,解碼器有3個FU層。GConv和TrGConv在時間軸和頻率軸上的核大小和步長分別設為(1, 7)和(1, 4)。在4個子帶和8個子帶的實驗中,沿頻率軸的步幅分別為3和2。對於所有GConv和TrGConv,通道數量保持在80。一個TFCM包含6個折積層,膨脹率為$\{2^0, 2^1, 2^2, 2^3, 2^4, 2^5\}$。每個TFCM中深度DConv的核大小為(3,3),每個TFCM中所有Conv的通道數為80。GTCM中所有子模組的通道數設定為80,最後一個PConv除外。一個S-GTCM包含4個對應的GTCM層,對於DConv,核心大小為5,膨脹率分別為{1,2,5,9}。我們堆疊了4個S-GTCM塊,在連續幀之間建立長期關係,並結合說話人嵌入。
為了從目標說話人的註冊語音中提取說話人embedding,我們使用了預先訓練好的開源ECAPA-TDNN[35]網路。
4.3 評價指標
使用了幾個客觀指標,包括寬頻感知評估語音質量(PESQ)[36]用於語音質量,短時客觀可理解性(STOI)[37]及其擴充套件版本ESTOI[38]用於可理解性,SISNR[39]用於語音失真。我們採用基於ITU-T P.835[40]的非侵入式主觀評價指標PDNSMOS P.835[22]來評價主觀語音效能。PDNSMOS P.835是專門為PSE任務設計的,更多細節可以在[22]中找到。對於所有的度量,高值表示更好的效能。
5 結果與分析
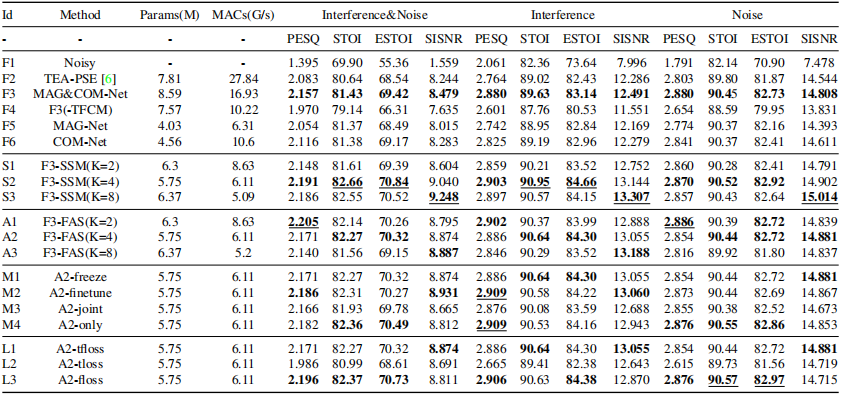
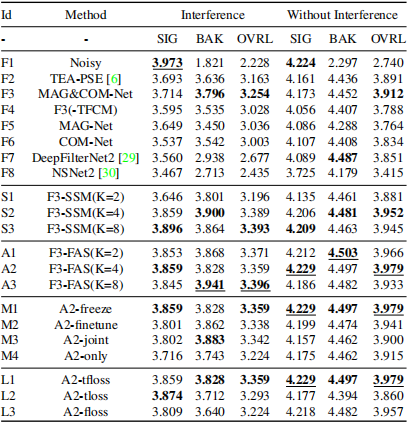
我們設計了幾組實驗來驗證效能的不同方面,包括a)全帶輸入(F1-F6), b)基於SSM的子帶處理(S1-S3), c)基於FAS的子帶處理(A1-A3), d)訓練策略(M1- M4), e)損失函數(L1-L3)。MAG-Net (F5)用L1優化,COM-Net (F6)用L2優化。我們使用用於盲測試集的開源預訓練模型評估NSNet2 [30] (F7)和DeepFilterNet2 [29] (F8)的結果。粗體結果表示每列中的最佳結果,最佳結果畫了下劃線。
5.1 全帶消融
從表1中可以看出,兩級MAG&COM-Net (F3)在所有指標上都優於其他方法。比較F3和F2 (TEA-PSE), MAG&COM-Net的效能優於TEA-PSE, MACs只有TEA-PSE的60%。對比F3和F4(不含TFCM的MAG&COM-Net), TFCM模組可以有效地擴充套件感受野,學習編碼器和解碼器的時間相關性。在表2中,TFCM帶來了0.116 SIG、0.081 BAK和0.136 OVRL效能提升。將F5 (MAG-Net)和F6 (COM-Net)與F3進行比較,我們使用兩級網路來進一步抑制噪聲成分和不需要的干擾說話人聲音,這對於PSE任務是有效的。對於表2中的DNS盲測試集,MAG&COM-Net優於其他基線系統。
表1 以PESQ, STOI (%), ESTOI(%)和SISNR (dB)來表示模擬集上的效能
5.2 子帶消融
基於FAS和SSM的子帶處理優於全帶特徵,同時大大降低了計算複雜度。這是因為子帶輸入使模型能夠將不同的能力分配給不同的子帶[17],而全帶輸入的模型往往會由於高低頻能量[41]的差異而出現高頻損失。對於基於SSM的子帶處理,S2 (SSM, K=4)和S3 (SSM, K=8)的效能相似,且優於S1 (SSM, K=2)。這是因為,隨著步幅的減小,模型的頻率建模能力有可能提高。對於基於FAS的子帶處理,隨著子帶數的增加,訊號重構誤差會變大。所以在表1中,A3 (FAS, K=8)的效果不如A1 (FAS, K=2)和A2 (FAS, K=4)。總的來說,4子帶輸入在子帶輸入實驗中表現最好。
5.3 訓練策略消融
A2是我們在訓練策略和損失函數的消融研究中後續實驗的backbone。我們探索了4種不同的兩階段網路訓練策略,包括M1): 預先訓練MAG-Net,然後在訓練COM-Net時凍結它,M2):預先訓練MAG-Net,然後在訓練COM-Net時以較小的學習率對其進行微調,M3):同時使用L1 + L2訓練MAG-Net和COM-Net, M4):只使用L2訓練整個網路。一般來說,M1(凍結)提供了最好的整體效能,如表2所示,M2 (finetune)也產生了出色的效能。對於M4(僅),僅優化L2會對效能產生負面影響,這表明在所有模組上設定優化限制的重要性。對於M3(joint),joint訓練策略在表1中總體表現最差。根據上面的實驗結果,我們得出結論,序列訓練,即逐個優化網路模組,是PSE任務中兩階段模型的首選策略,儘管它將花費更多的訓練時間。
表2 DNS2022盲測試機上的效能。PDNSMOS P.835指標包括語音質量(SIG)、背景噪聲質量(BAK)和總體質量(OVRL)
5.4 損失函數消融
時域損失函數常用於語音分離任務,而頻域損失函數常用於語音增強任務。為了在PSE任務中找到最優的損失策略,我們對不同域的損失函數進行了實驗,包括L1):將時域損失函數$L_{si-snr}$與頻域損失函數$L_{mag}$, $L_{pha}$, $L_{asym}$結合,L2):時域損失函數,L3):頻域損失函數。在表2中,L1 (tfloss)總體表現最好。這說明了從時域和頻域對模型進行優化的價值。在表1中,L3(floss)的PESQ、STOI和ESTOI得分最高。
6 結論
本文提出了一種新的子帶兩級個性化語音增強網路TEA-PSE 2.0,它是TEA-PSE的升級版。得益於基於fas的子帶處理和TFCM模組,TEA-PSE 2.0(表2中的A2)在計算複雜度上僅為TEA-PSE的21.9% MACs,在ICASSP 2022 PDNS盲測試集中實現了最先進的PDNSMOS效能。並證明了按順序優化MAG-Net和COM-Net是最好的訓練策略。此外,利用時域和頻域相結合的損失函數對模型進行優化是有價值的。在未來,我們將特別考慮PSE中的語音去混音,以進一步提高語音質量。
7 致謝
作者感謝西北工業大學的S. Lv和J. Sun在子帶處理方面的有益討論,以及網易公司的Y. Fu在$MTFA-Net$實現方面的有益討論。
8 參考文獻
[1] Q. Wang, H. Muckenhirn, K. Wilson, P. Sridhar, Z. Wu, J. R. Hershey, R. A. Saurous, R. Weiss, Y. Jia, and I. L. Moreno, VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking, in Interspeech, 2019, pp. 2728 2732.
[2] K. Zmol ıkov a, M. Delcroix, K. Kinoshita, T. Ochiai, T. Nakatani, L. Burget, and J. Cernock`y, Speakerbeam: Speaker aware neural network for target speaker extraction in speech mixtures, IEEE J. Sel. Topics Signal Process. , vol. 13, no. 4, pp. 800 814, 2019.
[3] C. Xu, W. Rao, E. S. Chng, and H. Li, Spex: Multi-scale time domain speaker extraction network, IEEE/ACM Trans. Audio, Speech, Language Process. , vol. 28, pp. 1370 1384, 2020.
[4] M. Ge, C. Xu, L. Wang, E. S. Chng, J. Dang, and H. Li, SpEx+: A Complete Time Domain Speaker Extraction Network, in Interspeech, 2020, pp. 1406 1410.
[5] H. Dubey, V. Gopal, R. Cutler, A. Aazami, S. Matusevych, S. Braun, S. E. Eskimez, M. Thakker, T. Yoshioka, H. Gamper, et al., ICASSP 2022 deep noise suppression challenge, in ICASSP. IEEE, 2022, pp. 9271 9275.
[6] Y. Ju, W. Rao, X. Yan, Y. Fu, S. Lv, L. Cheng, Y. Wang, L. Xie, and S. Shang, TEA-PSE: Tencent-etherealaudio-lab Personalized Speech Enhancement System for ICASSP 2022 DNS CHALLENGE, in ICASSP. IEEE, 2022, pp. 9291 9295.
[7] S. Zhao, B. Ma, K. N. Watcharasupat, and W. Gan, FRCRN: Boosting feature representation using frequency recurrence for monaural speech enhancement, in ICASSP. IEEE, 2022, pp. 9281 9285.
[8] J. Valin, A hybrid dsp/deep learning approach to realtime full-band speech enhancement, in MMSP. IEEE, 2018, pp. 1 5.
[9] R. Giri, S. Venkataramani, J. Valin, U. Isik, and A. Krishnaswamy, Personalized PercepNet: Real-Time, Low-Complexity Target Voice Separation and Enhancement, in Interspeech, 2021, pp. 1124 1128.
[10] S. Lv, Y. Hu, S. Zhang, and L. Xie, DCCRN+: Channel-Wise Subband DCCRN with SNR Estimation for Speech Enhancement, in Interspeech, 2021, pp. 2816 2820.
[11] J. Li, D. Luo, Y. Liu, Y. Zhu, Z. Li, G. Cui, W. Tang, and W. Chen, Densely connected multi-stage model with channel wise subband feature for real-time speech enhancement, in ICASSP. IEEE, 2021, pp. 6638 6642.
[12] G. Yu, Y. Guan, W. Meng, C. Zheng, and H. Wang, DMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement, arXiv preprint arXiv:2203.00472, 2022.
[13] G. Yu, A. Li, W. Liu, C. Zheng, Y. Wang, and H. Wang, Optimizing shoulder to shoulder: A coordinated subband fusion model for real-time full-band speech enhancement, arXiv preprint arXiv:2203.16033, 2022.
[14] T. Q. Nguyen, Near-perfect-reconstruction pseudo-qmf banks, IEEE Trans. Signal Process. , vol. 42, no. 1, pp. 65 76, 1994.
[15] C. Yu, H. Lu, N. Hu, M. Yu, C. Weng, K. Xu, P. Liu, D. Tuo, S. Kang, G. Lei, D. Su, and D. Yu, DurIAN: Duration Informed Attention Network for Speech Synthesis, in Interspeech, 2020, pp. 2027 2031.
[16] G. Yang, S. Yang, K. Liu, P. Fang, W. Chen, and L. Xie, Multi-band MelGAN: Faster waveform generation for high-quality text-to-speech, in SLT. IEEE, 2021, pp. 492 498.
[17] H. Liu, L. Xie, J. Wu, and G. Yang, Channel-Wise Subband Input for Better Voice and Accompaniment Separation on High Resolution Music, in Interspeech, 2020, pp. 1241 1245.
[18] A. Li, W. Liu, X. Luo, G. Yu, C. Zheng, and X. Li, A Simultaneous Denoising and Dereverberation Framework with Target Decoupling, in Interspeech, 2021, pp. 2801 2805.
[19] A. Li, W. Liu, C. Zheng, C. Fan, and X. Li, Two heads are better than one: A two-stage complex spectral mapping approach for monaural speech enhancement, IEEE/ACM Trans. Audio, Speech, Language Process. , vol. 29, pp. 1829 1843, 2021.
[20] H. Wang and D. Wang, Cross-domain speech enhancement with a neural cascade architecture, in ICASSP. IEEE, 2022, pp. 7862 7866.
[21] G. Zhang, L. Yu, C. Wang, and J. Wei, Multi-scale temporal frequency convolutional network with axial attention for speech enhancement, in ICASSP. IEEE, 2022, pp. 9122 9126.
[22] C. K. Reddy, V. Gopal, and R. Cutler, DNSMOS P. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise suppressors, in ICASSP. IEEE, 2022, pp. 886 890.
[23] Y. N. Dauphin, A. Fan, M. Auli, and D. Grangier, Language modeling with gated convolutional networks, in International conference on machine learning. PMLR, 2017, pp. 933 941.
[24] S. Zhang, Z. Wang, Y. Ju, Y. Fu, Y. Na, Q. Fu, and L. Xie, Personalized Acoustic Echo Cancellation for Full-duplex Communications, arXiv preprint arXiv:2205.15195, 2022.
[25] Y. Luo and N. Mesgarani, Conv-tasnet: Surpassing ideal time frequency magnitude masking for speech separation, IEEE/ACM Trans. Audio, Speech, Language Process. , vol. 27, no. 8, pp. 1256 1266, 2019.
[26] S. E. Eskimez, X. Wang, M. Tang, H. Yang, Z.n Zhu, Z. Chen, H. Wang, and T. Yoshioka, Human Listening and Live Captioning: Multi-Task Training for Speech Enhancement, in Interspeech, 2021, pp. 2686 2690.
[27] S. Zhang, Z. Wang, J. Sun, Y. Fu, B. Tian, Q. Fu, and L. Xie, Multi-task deep residual echo suppression with echo-aware loss, in ICASSP. IEEE, 2022, pp. 9127 9131.
[28] Q. Wang, I. L. Moreno, M. Saglam, K. Wilson, A. Chiao, R. Liu, Y. He, W. Li, J. Pelecanos, M. Nika, and A. Gruenstein, VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition, in Interspeech, 2020, pp. 2677 2681.
[29] H. Schr oter, T. Rosenkranz, A. Maier, et al., Deepfilternet2: Towards real-time speech enhancement on embedded devices for full-band audio, arXiv preprint arXiv:2205.05474, 2022.