巨量資料實時多維OLAP分析資料庫Apache Druid入門分享-下
@
架構
核心架構
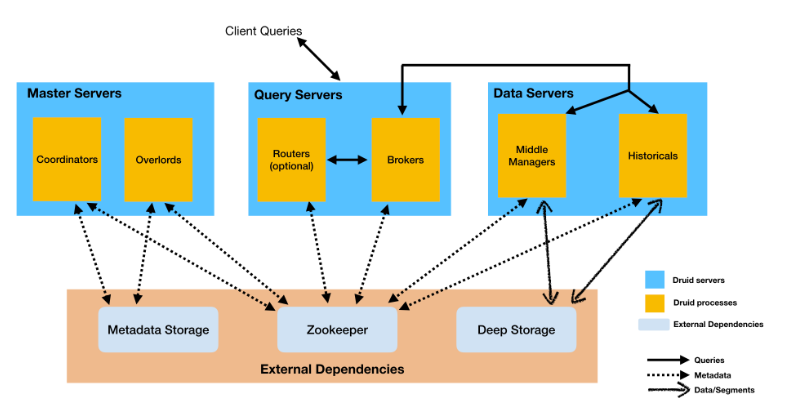
Druid servers建議將它們組織為三種伺服器型別:Master主伺服器、Query查詢伺服器和Data資料伺服器。
- Master:Master管理資料攝入和可用性,負責啟動新的攝入作業,並協調「資料伺服器」上的資料可用性。在主伺服器中功能劃分為Coordinator和Overlord兩個程序。
- Query:處理來自外部使用者端的查詢,查詢伺服器提供使用者和使用者端應用程式與之互動的端點,將查詢路由到資料伺服器或其他查詢伺服器(以及可選的代理主伺服器請求)。在查詢伺服器中功能被分為Broker和Router兩個程序。
- Data:執行攝取作業並儲存可查詢的資料,功能被分為Historical程序和MiddleManager兩個程序。
服務程序型別細分如下:
- Coordinator(協調器):服務管理叢集上的資料可用性。協調器程序監視資料伺服器上的歷史程序,負責將Segments分配到特定的伺服器,並確保Segments在各個歷史資料之間得到很好的平衡。
- Overlord:服務控制資料攝取工作負載的分配。Overlord程序監視Data伺服器上的MiddleManager程序,並且是資料攝取到Druid的控制器。負責將攝取任務分配給middlemanager並協調Segments釋出。
- Broker:代理處理來自外部使用者端的查詢。代理程序從外部使用者端接收查詢,並將這些查詢轉發給資料伺服器。當代理從這些子查詢接收到結果時,合併這些結果並將它們返回給呼叫者。使用者通常是查詢broker而不直接在資料伺服器上查詢Historicals或MiddleManagers程序。
- Router:Router服務是可選的;他們將請求路由到broker、coordinator和Overlords。路由器程序是可選程序,在Druid broker、Overlords和coordinator面前提供統一的API閘道器。也可以直接請求broker、coordinator和Overlords。Router還執行web控制檯、資料來源、分段、任務、資料流程(Historicals和MiddleManagers)的管理UI,以及協調器動態設定;還可以在控制檯中執行SQL和本地Druid查詢。
- Historical:處理儲存和查詢「歷史」資料(包括在系統中存在足夠長時間以提交的任何流資料)的主力。歷史程序從深層儲存中下載Segments並響應關於這些Segments的查詢,不接受寫操作。
- MiddleManager:服務攝取資料。負責將新資料匯入叢集,從外部資料來源讀取資料並行布新的Druid Segments。
- Indexer process:可選的,是MiddleManagers和Peons的替代方案。Indexer不是為每個任務派生單獨的JVM程序,而是在單個JVM程序中作為單獨的執行緒執行任務。與MiddleManager + Peon系統相比,Indexer的設計更容易設定和部署,並且更好地支援跨任務共用資源。Indexer是一個較新的特性,由於它的記憶體管理系統仍在開發中,所以目前還處於試驗階段,將在Druid的未來版本中逐漸成熟。通常情況下,可以部署MiddleManagers或Indexers,但不能同時部署兩者。
外部依賴
- 深度儲存:Druid使用深度儲存來儲存任何已經攝入到系統中的資料。深度儲存是每個Druid伺服器都可以存取的共用檔案儲存。在叢集部署中,這通常是一個分散式物件儲存,如S3、HDFS或一個網路掛載的檔案系統。在單伺服器部署中是本地磁碟。
- 後設資料儲存:儲存各種共用的系統後設資料,如段使用資訊和任務資訊。在叢集部署中,這通常是傳統的RDBMS,如PostgreSQL或MySQL。在單伺服器部署中,它通常是本地儲存的Apache Derby資料庫。
- ZooKeeper:用於內部服務發現、協調和領導者選舉。
核心內容
Druid能夠實現海量資料實時分析採取瞭如下特殊⼿段:
- 預聚合
- 列式儲存
- 多級分割區(Datasource和Segments)+點陣圖索引
roll-up預聚合
Apache Druid可以在攝入原始資料時使用稱為「roll-up」的過程進行彙總。roll-up是針對選定列集的一級聚合操作,可減小儲存資料的大小。分析查詢逃不開聚合操作,Druid在資料⼊庫時就提前進⾏了聚合,這就是所謂的預聚合(roll-up)。Druid把資料按照選定維度的相同的值進⾏分組聚合,可以⼤⼤降低儲存⼤⼩。資料查詢的時候只需要預聚合的資料基礎上進⾏輕量的⼆次過濾和聚合即可快速拿到分析結果。要做預聚合,Druid要求資料能夠分為三個部分:
- Timestamp列:Druid所有分析查詢均涉及時間(思考:時間實際上是⼀個特殊的維度,它可以衍⽣出⼀堆維度,Druid把它單列出來了)
- Dimension列(維度):Dimension列指⽤於分析資料⻆度的列,例如從地域、產品、⽤戶的⻆度來分析訂單資料,⼀般⽤於過濾、分組等等。
- Metric列(度量):Metric列指的是⽤於做聚合和其他計算的列;⼀般來說是數位。
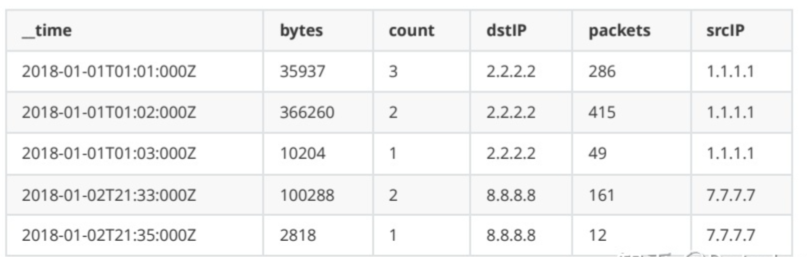
使用網路流事件資料的一個小樣本,表示在特定秒內發生的從源到目的IP地址的流量的包和位元組計數,資料如下:
{"timestamp":"2018-01-01T01:01:35Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":20,"bytes":9024}
{"timestamp":"2018-01-01T01:01:51Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":255,"bytes":21133}
{"timestamp":"2018-01-01T01:01:59Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":11,"bytes":5780}
{"timestamp":"2018-01-01T01:02:14Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":38,"bytes":6289}
{"timestamp":"2018-01-01T01:02:29Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":377,"bytes":359971}
{"timestamp":"2018-01-01T01:03:29Z","srcIP":"1.1.1.1","dstIP":"2.2.2.2","packets":49,"bytes":10204}
{"timestamp":"2018-01-02T21:33:14Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":38,"bytes":6289}
{"timestamp":"2018-01-02T21:33:45Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":123,"bytes":93999}
{"timestamp":"2018-01-02T21:35:45Z","srcIP":"7.7.7.7","dstIP":"8.8.8.8","packets":12,"bytes":2818}
timestamp是Timestamp列,srcIP和dstIP是Dimension列(維度),packets和bytes是Metric列。資料⼊庫到Druid時如果開啟預聚合功能(可以不開啟聚合,資料量大建議開啟),要求對packets和bytes進⾏累加(sum),並且要求按條計數(count *),聚合之後的資料如下,可以看出聚合是以犧牲明細資料分析查詢為代價。
列式儲存
列式儲存的概念已經非常耳熟,但凡在⼤資料領域想要解決快速儲存和分析海量資料基本都會採⽤列式儲存,一般來說OLTP資料庫使用行式儲存,OLAP資料使用列式儲存。
- 對於分析查詢,⼀般只需要⽤到少量的列,在列式儲存中,只需要讀取所需的資料列即可。 例如,如果您需要100列中的5列,則I / O減少20倍。
- 按列分開儲存,按封包讀取時因此更易於壓縮。 列中的資料具有相同特徵也更易於壓縮, 這樣可以進⼀步減少I / O量。
- 由於減少了I / O,因此更多資料可以容納在系統快取中,進⼀步提⾼分析效能。
Datasource和Segments
- Apache Druid將其資料和索引儲存在按時間劃分的段檔案中。Druid為每個包含資料的段間隔建立一個段。如果間隔為空(即不包含行),則該時間間隔不存在段。
- 如果你在同一段時間內通過不同的攝入作業攝入資料,Druid可能會在同一段時間內建立多個分段。壓縮是Druid過程,它試圖將這些段組合成每個間隔的單個段,以獲得最佳效能。為了讓Druid在過載查詢負載下執行良好,段檔案大小在300-700 MB的推薦範圍內是很重要的。如果您的段檔案大於此範圍,則考慮更改段時間間隔的粒度或對資料進行分割區和/或調整partitionsSpec中的targetRowsPerSegment。這個引數的一個起點是500萬行。
- 段檔案是柱狀的,每一列的資料在單獨的資料結構中進行佈局。通過分別儲存每個列,Druid通過只掃描查詢實際需要的列來減少查詢延遲。有三種基本的列型別:時間戳、維度和度量,例如
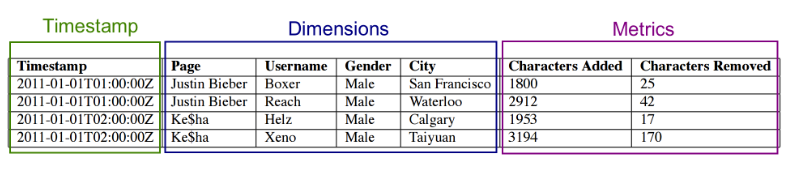
- 時間戳和度量型別列是用LZ4壓縮的整數或浮點值陣列。一旦查詢確定了要選擇的行,就會對它們進行解壓,取出相關行,並應用所需的聚合操作符。如果查詢不需要列,Druid會跳過該列的資料。
- 維度列是不同的,因為它們支援篩選和分組操作,所以每個維度都需要以下三種資料結構:
- Dictionary(字典):將值(總是被視為字串)對映為整數id,允許列表和點陣圖值的緊湊表示。
- List(列表):列的值,使用字典進行編碼。GroupBy和TopN查詢必選。這些操作符允許在不存取值列表的情況下執行僅基於過濾器聚合指標的查詢。
- Bitmap(點陣圖):列中每個不同值的點陣圖,用於指示哪些行包含該值。點陣圖允許快速過濾操作,因為它們便於快速應用AND和OR操作符。也稱為倒排指數。
Druid的資料在儲存層⾯是按照Datasource和Segments實現多級分割區儲存的,並建⽴了點陣圖索引。
- Datasource相當於關係型資料庫中的表。
- Datasource會按照時間來分⽚(類似於HBase⾥的Region和Kudu⾥的tablet),每⼀個時間分⽚被稱為chunk。
- chunk並不是直接儲存單元,在chunk內部資料還會被切分為⼀個或者多個segment。
- 所有的segment獨⽴儲存,通常包含數百萬⾏,segment與chunk的關係如下圖:
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-xkKQdpk9-1675265402036)(http://www.itxiaoshen.com:3001/assets/1675159187424CTMTr68s.png)]
Segment跟Chunk
- Segment是Druid資料儲存的最小單元,內部採用列式儲存,建立了點陣圖索引,對資料進行了編碼跟壓縮,
Druid資料儲存的攝取方式、聚合方式、每列資料儲存的位元組起始位都有儲存。
點陣圖索引
例如有一份資料如下
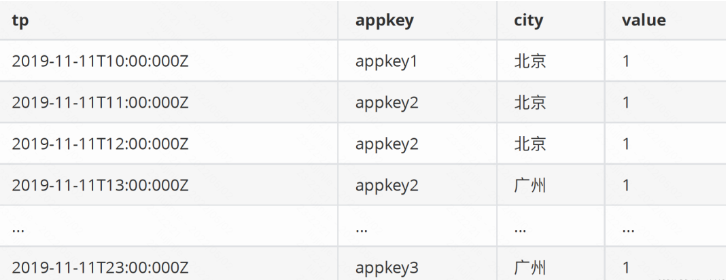
以tp為時間列,appkey和city為維度,以value為度量值,導⼊Druid後按天聚合,最終結果如下
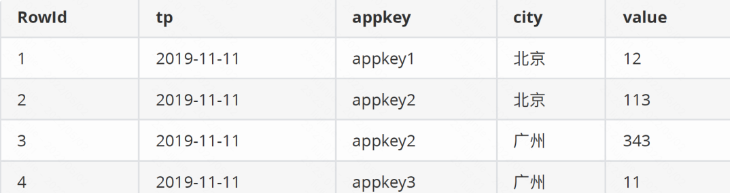
聚合後資料經過聚合之後查詢本身就很快了,為了進⼀步加速對聚合之後資料的查詢,Druid會建立點陣圖索引如下
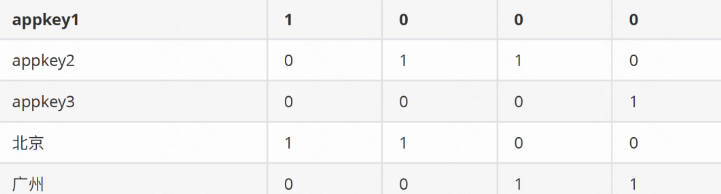
上⾯的點陣圖索引不是針對列⽽是針對列的值,記錄了列的值在資料的哪⼀行出現過,第一列是具體列的值,後續列標識該列的值在某⼀⾏是否出現過,依次是第1列到第n列。例如appkey1在第⼀⾏出現過,在其他⾏沒出現,那就是1000(例子中只有四個列)。
Select sum(value)
from xxx
where time='2019-11-11' and appkey in('appkey1','appkey2') and area='北京'
當我們有如上查詢時,⾸先根據時間段定位到segment,然後根據appkey in (‘appkey1’,’appkey2’) and area=’北京’ 查到各⾃的bitmap:(appkey1(1000) or appkey2(0110)) and 北京(1100) = (1100) 也就是說,符合條件的列是第⼀行和第⼆行,這兩⾏的metric的和為125.
資料攝取
-
在Druid中載入資料稱為攝取或索引。當攝取資料到Druid時,Druid從源系統讀取資料並將其儲存在稱為段的資料檔案中;通常,每個段檔案包含幾百萬行。
-
對於大多數攝取方法,Druid MiddleManager程序或Indexer程序載入源資料。唯一的例外是基於Hadoop的攝取,它在YARN上使用Hadoop MapReduce作業。
-
在攝入過程中,Druid建立片段並將它們儲存在深層儲存中。歷史節點將段載入到記憶體中以響應查詢。對於流輸入,中層管理人員和索引人員可以使用到達的資料實時響應查詢。
-
Druid包含流式和批次攝取方法,以下描述了適用於所有攝入方法的攝入概念和資訊。
- Druid資料模型介紹了資料來源、主時間戳、維度和度量的概念。
- 資料預聚合將預聚合描述為一個概念,並提供了最大化預聚合好處的建議。
- 分割區描述了Druid中的時間塊和二級分割區。
-
流攝取:有兩個可用的選項;流攝取由一個持續執行的管理器控制。
-
批次攝取:有三種可供批次攝入的選擇。批次攝取作業與在作業期間執行的控制器任務相關聯。

查詢
Apache Druid支援兩種查詢語言:Druid SQL和本機查詢;可以使用Druid SQL查詢Druid資料來源中的資料。Druid將SQL查詢翻譯成其本地查詢語言。Druid SQL計劃發生在Broker上。設定Broker執行時屬性以設定查詢計劃和JDBC查詢。
- Data types:Druid列支援的資料型別列表的資料型別。
- Aggregation functions:聚合函數用於Druid SQL SELECT語句可用的聚合函數列表。
- Scalar functions:用於Druid SQL標量函數的標量函數,包括數位和字串函數、IP地址函數、Sketch函數等。
- SQL multi-value string functions:SQL多值字串函數,用於在包含多個值的字串維度上執行操作。
- Query translation:查詢翻譯,瞭解Druid如何在執行SQL查詢之前將其翻譯為本機查詢。
Apache Druid 包含的API如下:
- Druid SQL API:關於HTTP API的資訊的Druid SQL API。
- SQL JDBC driver API:SQL JDBC驅動程式API獲取有關JDBC驅動程式API的資訊。
- SQL query context:SQL查詢上下文,獲取有關影響SQL規劃的查詢上下文引數的資訊。
Apache Druid的本地查詢型別和本地查詢元件內容如下:
- 本地查詢型別
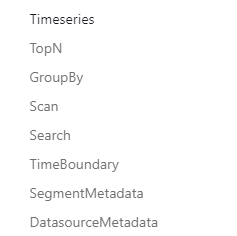
- 本地查詢元件

叢集部署
部署規劃
使用hadoop1、hadoop2、hadoop3共3臺搭建druid的叢集,如果有更多伺服器可以隨時啟動相應元件即可,叢集規模不大Master Server3臺和Query Server2臺即可,更多的是根據處理資料規模增加Data Server節點。
| 主機 | 元件 |
|---|---|
| hadoop1 | Master Server(Coordinator和Overlords) |
| hadoop2 | Data Server(Historical和MiddleManager) |
| hadoop3 | Query Server(Broker和Router) |
前置條件
- Java 8 or 11(使用現有)
- Python2 or Python3(使用現有Python3)
- MySQL(後設資料儲存,使用現有MySQL 8.0.28)
- HDFS(深度儲存,使用現有hadoop 3.3.4)
- ZooKeeper(使用現有)
MySQL設定
- 建立資料庫
-- 建立一個druid資料庫,確保使用utf8mb4作為編碼
CREATE DATABASE druid DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin;
-- 建立一個druid使用者
CREATE USER 'druid'@'%' IDENTIFIED BY 'diurd';
-- 向用戶授予剛剛建立的資料庫的所有許可權
GRANT ALL PRIVILEGES ON druid.* TO druid@'%' WITH GRANT OPTION;
ALTER USER 'druid'@'%' IDENTIFIED WITH mysql_native_password BY 'druid';
FLUSH PRIVILEGES;
- 將MySQL驅動(mysql-connector-java-8.0.28.jar)上傳到druid根目錄下的extensions/mysql-metadata-storage目錄下

- 修改叢集組態檔。vi conf/druid/cluster/_common/common.runtime.properties
druid.host=hadoop1
# 在擴充套件載入列表中包含mysql-metadata-storage和下面使用的druid-hdfs-storage
druid.extensions.loadList=["druid-hdfs-storage", "druid-kafka-indexing-service", "druid-datasketches", "druid-multi-stage-query","mysql-metadata-storage"]
#druid.metadata.storage.type=derby
#druid.metadata.storage.connector.connectURI=jdbc:derby://localhost:1527/var/druid/metadata.db;create=true
#druid.metadata.storage.connector.host=localhost
#druid.metadata.storage.connector.port=1527
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://mysqlserver:3306/druid
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=diurd
HDFS設定
- 註釋掉「深度儲存」和「索引服務紀錄檔」下的本地儲存設定。vi conf/druid/cluster/_common/common.runtime.properties
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
- 將Hadoop設定xml (core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml)放在Druid程序的類路徑中。把它們複製到conf/druid/cluster/_common/。
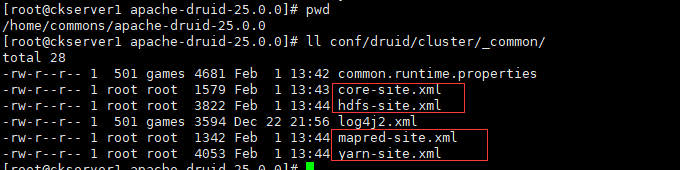
- 連線Hadoop的設定(可選),如果需要從Hadoop叢集中載入資料則需要設定,並將Hadoop設定xml (core-site.xml, hdfs-site.xml,)放在Druid程序的類路徑中。把它們複製到conf/druid/cluster/_common/。vi conf/druid/cluster/data/middleManager/runtime.properties
druid.indexer.task.baseTaskDir=/var/druid/task
# Hadoop indexing
druid.indexer.task.hadoopWorkingPath=/var/druid/hadoop-tmp
Zookeeper設定
vi conf/druid/cluster/_common/common.runtime.properties
druid.zk.service.host=zk1:2181,zk2:2181,zk3:2181
啟動叢集
# 將apache-druid分別到另外兩臺伺服器上,並修改druid.host
rsync -az apache-druid-25.0.0/ hadoop2:/home/commons/apache-druid-25.0.0/
rsync -az apache-druid-25.0.0/ hadoop3:/home/commons/apache-druid-25.0.0/
# hadoop1上啟動Master Serve
bin/start-cluster-master-no-zk-server
# hadoop2上啟動Data Server
bin/start-cluster-data-server
# hadoop3上啟動Query Server
bin/start-cluster-query-server
# 如果叢集規模較大需要分離程序模組,也可以單獨啟動
bin/coordinator.sh start
bin/overlord.sh start
bin/historical.sh start
bin/middleManager.sh start
bin/broker.sh start
bin/jconsole.sh start
# 單獨關閉
bin/coordinator.sh stop
bin/overlord.sh stop
bin/historical.sh stop
bin/middleManager.sh stop
bin/broker.sh stop
bin/jconsole.sh stop
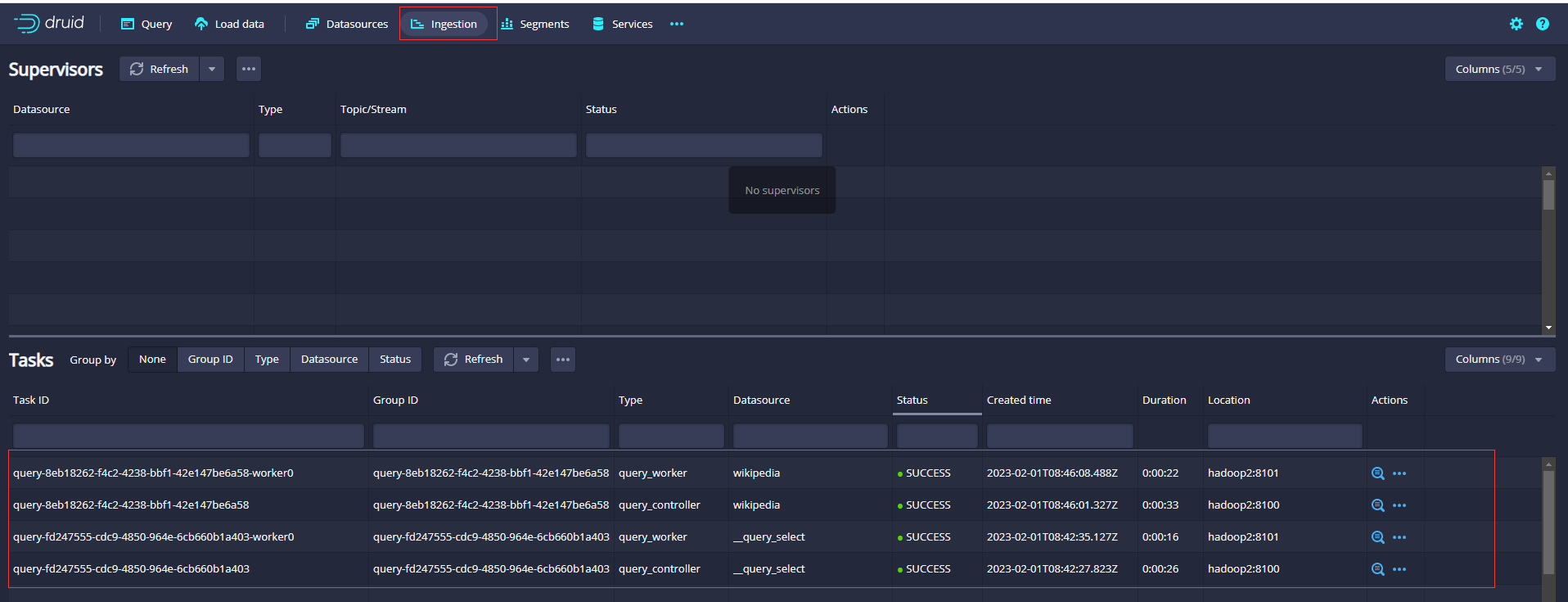
啟動完畢後存取查詢節點的Druid的控制檯UI,http://hadoop3:8888/,點選Services欄目可以看到所有程序服務詳細資訊

匯入HDFS範例
# 先將官方提供的範例資料上傳到hdfs
hdfs dfs -put wikiticker-2015-09-12-sampled.json.gz /tmp/my-druid
然後和前面單機版匯入操作流程相似,只是選擇輸入型別為HDFS,填寫Paths為上面上傳的路徑/tmp/my-druid/wikiticker-2015-09-12-sampled.json.gz
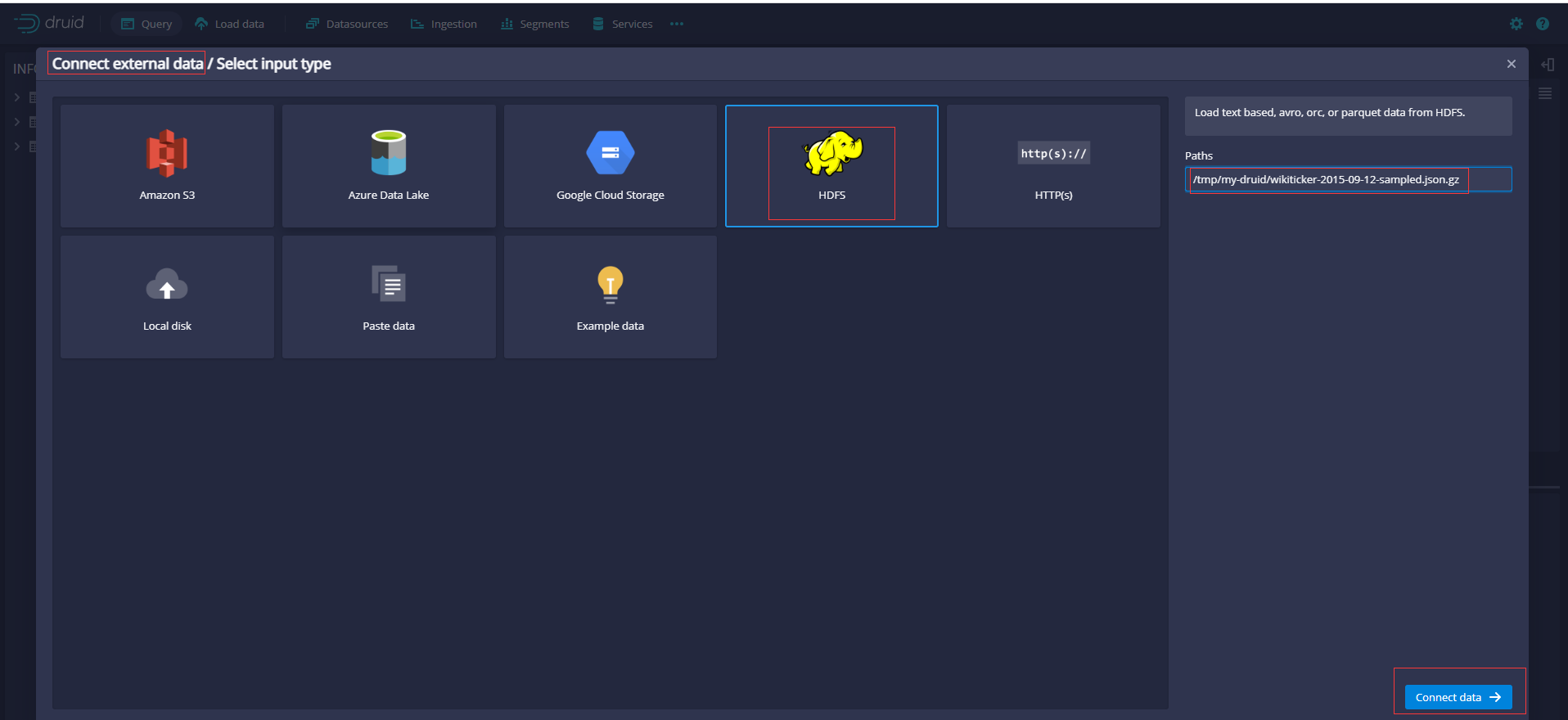
生成SQL如下,修改表名為wikipedia(原來為data)
REPLACE INTO "wikipedia" OVERWRITE ALL
WITH "ext" AS (SELECT *
FROM TABLE(
EXTERN(
'{"type":"hdfs","paths":"/tmp/my-druid/wikiticker-2015-09-12-sampled.json.gz"}',
'{"type":"json"}',
'[{"name":"time","type":"string"},{"name":"channel","type":"string"},{"name":"cityName","type":"string"},{"name":"comment","type":"string"},{"name":"countryIsoCode","type":"string"},{"name":"countryName","type":"string"},{"name":"isAnonymous","type":"string"},{"name":"isMinor","type":"string"},{"name":"isNew","type":"string"},{"name":"isRobot","type":"string"},{"name":"isUnpatrolled","type":"string"},{"name":"metroCode","type":"long"},{"name":"namespace","type":"string"},{"name":"page","type":"string"},{"name":"regionIsoCode","type":"string"},{"name":"regionName","type":"string"},{"name":"user","type":"string"},{"name":"delta","type":"long"},{"name":"added","type":"long"},{"name":"deleted","type":"long"}]'
)
))
SELECT
TIME_PARSE("time") AS "__time",
"channel",
"cityName",
"comment",
"countryIsoCode",
"countryName",
"isAnonymous",
"isMinor",
"isNew",
"isRobot",
"isUnpatrolled",
"metroCode",
"namespace",
"page",
"regionIsoCode",
"regionName",
"user",
"delta",
"added",
"deleted"
FROM "ext"
PARTITIONED BY DAY
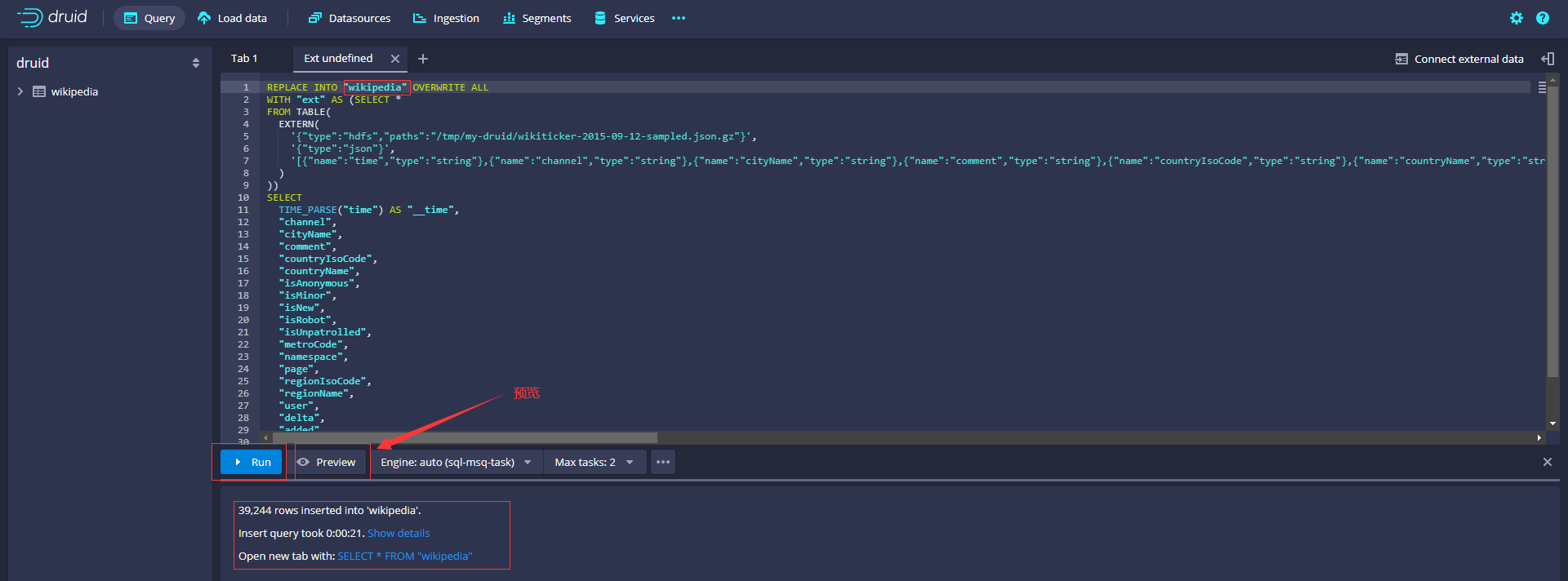
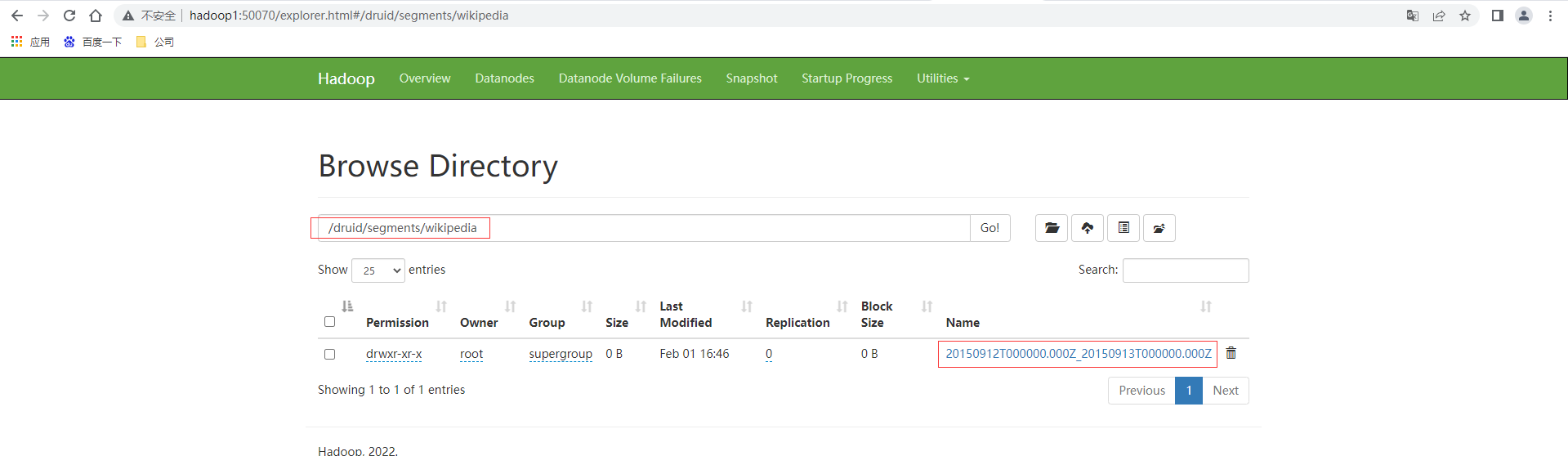
檢視資料來源可以看到wikipedia表資訊

檢視HDFS上也有相應的段資料
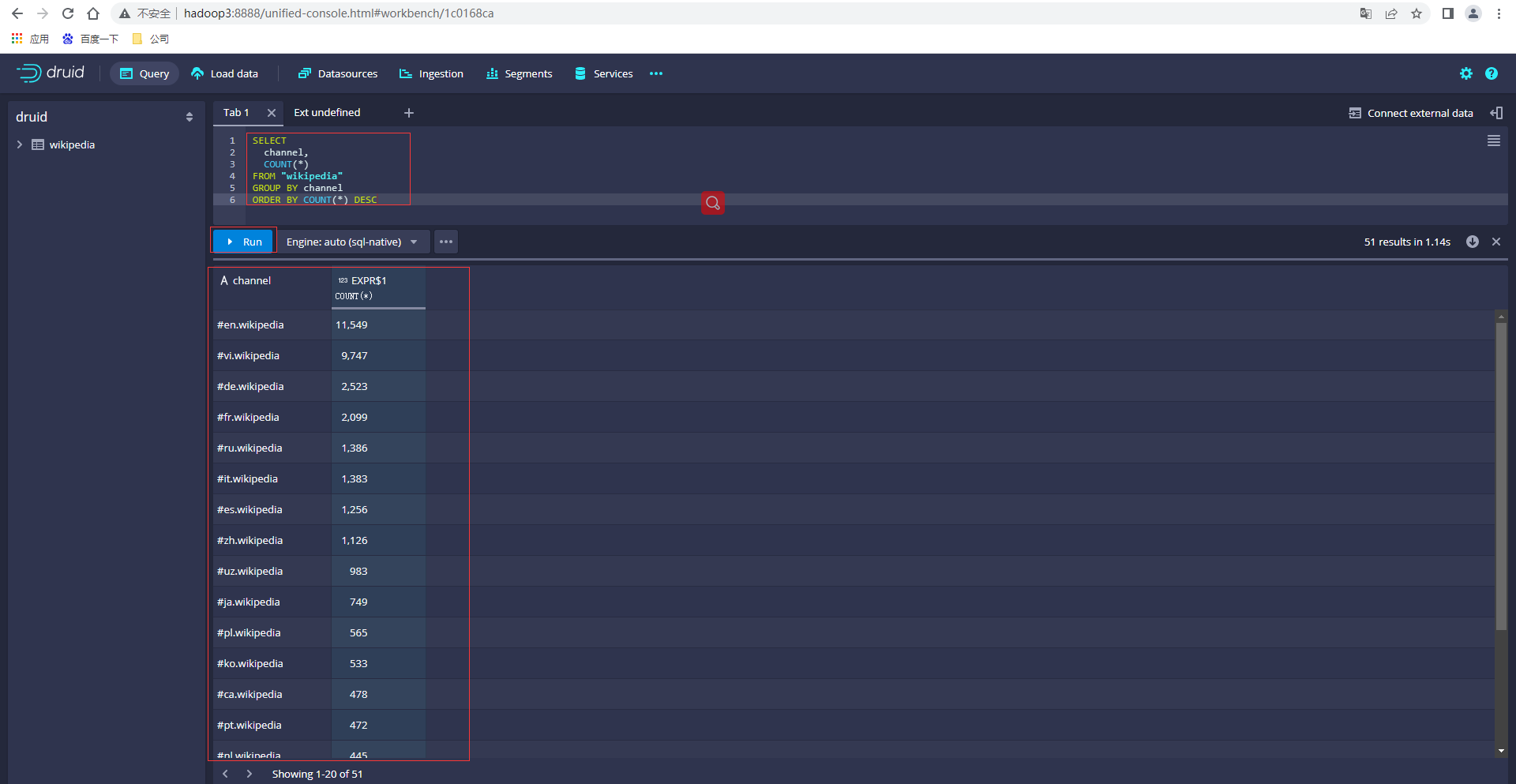
輸入SQL,點選執行查詢資料
SELECT
channel,
COUNT(*)
FROM "wikipedia"
GROUP BY channel
ORDER BY COUNT(*) DESC
可以通過http請求查詢,這裡以官方範例TopN查詢為例
curl -X POST 'http://hadoop3:8888/druid/v2/?pretty' -H 'Content-Type:application/json' -d @wikipedia-top-pages.json
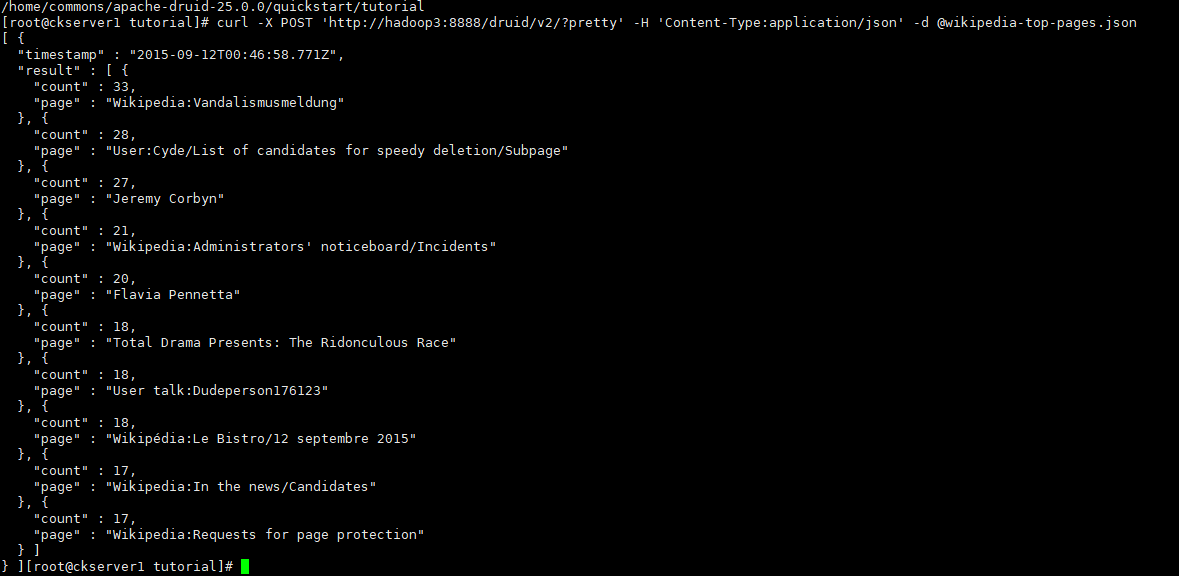
檢視資料攝取的任務資訊
檢視段資訊

- 本人部落格網站IT小神 www.itxiaoshen.com