隨機高並行查詢結果一致性設計實踐
作者:京東物流 趙帥 姚再毅 王旭東 孟偉傑 孔祥東
1 前言
物流合約中心是京東物流合同管理的唯一入口。為商家提供合同的建立,蓋章等能力,為不同業務條線提供合同的客製化,歸檔,查詢等功能。由於各個業務條線眾多,為各個業務條線提供高可用查詢能力是物流合約中心重中之重。同時計費系統在每個物流單結算時,都需要查詢合約中心,確保商家簽署的合同內容來保證計費的準確性。
2 業務場景
1.查詢維度分析
從業務呼叫的來源來看,合同的大部分是計費系統在每個物流單計費的時候,需要呼叫合約中心來判斷,該商家是否簽署合同。

從業務呼叫的入參來看,絕大部分是多個條件來查詢合同,但基本都是查詢某個商家,或通過商家的某個屬性(例如業務賬號)來查詢合同。
從呼叫的結果來看,40%的查詢是沒有結果的,其中絕大部分是因為商家沒有簽署過合同,導致查詢為空。其餘的查詢結果,每次返回的數量較少,一般一個商家只有3到5個合同。
2.呼叫量分析
呼叫量
目前合同的呼叫量,大概是在每天2000W次。
一天的呼叫量統計:

呼叫時間
每天高峰期為上班時間,最高峰為4W/min。
一個月的呼叫量統計:

由上可以看出,合同每日的呼叫量比較平均,主要集中在9點到12點和13點到18點,也就是上班時間,整體呼叫量較高,基本不存在呼叫暴增的情況。
總體分析來看,合約中心的查詢,呼叫量較高,且較平均,基本都是隨機查詢,也並不存在熱點資料,其中無效查詢佔比較多,每次查詢條件較多,返回資料量比不大。
3 方案設計
從整體業務場景分析來看,我們決定做三層防護來保證呼叫量的支撐,同時需要對資料一致性做好處理。第一層是布隆過濾器,來攔截絕大部分無效的請求。第二層是redis快取資料,來保證各種查詢條件的查詢儘量命中redis。第三層是直接查詢資料庫的兜底方案。同時再保證資料一致性的問題,我們藉助於廣播mq來實現。
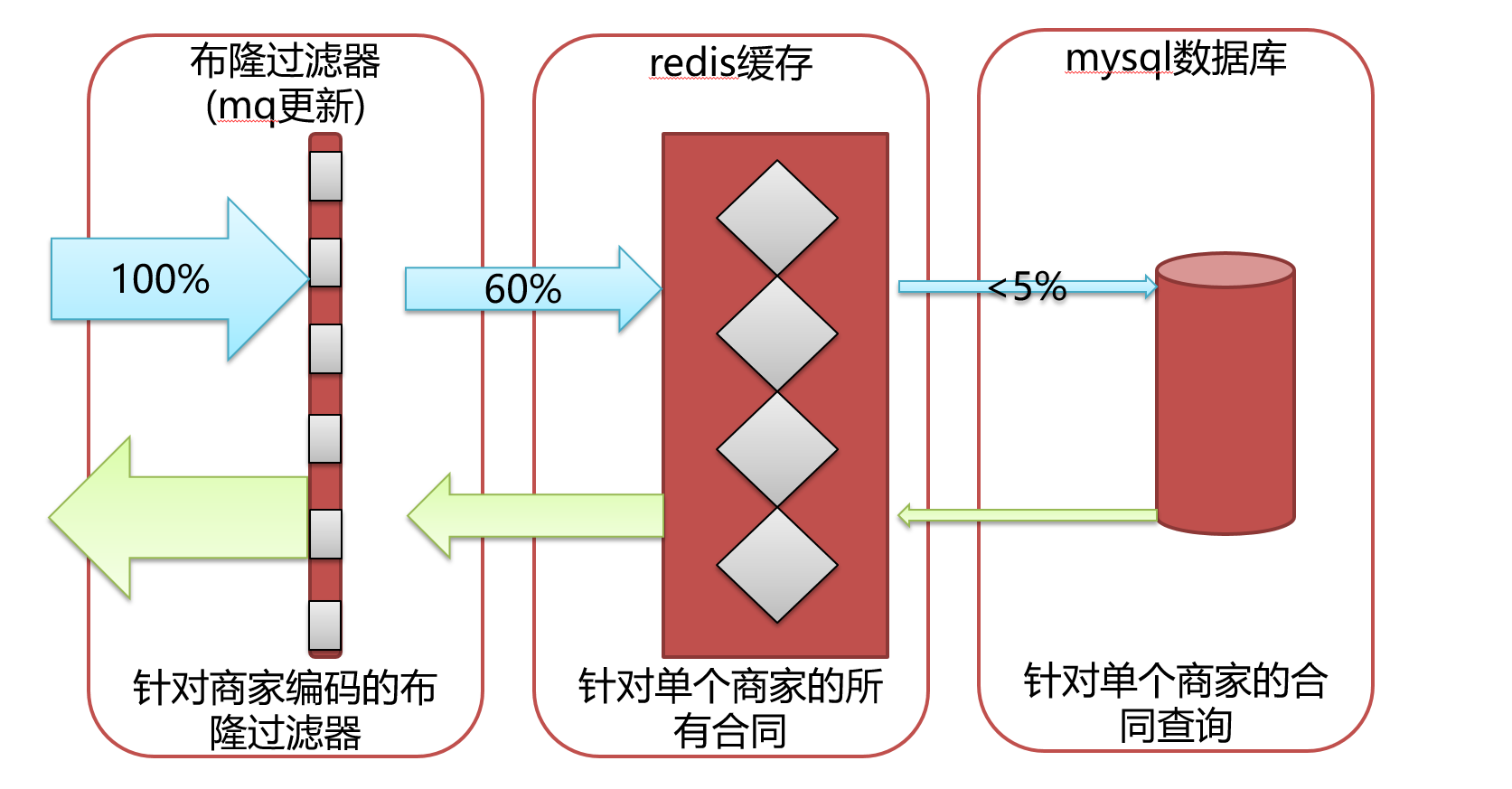
1.第一層防護
由於近一半的查詢都是空,我們首先這是快取穿透的現象。
快取穿透問題
快取穿透(cache penetration)是使用者存取的資料既不在快取當中,也不在資料庫中。出於容錯的考慮,如果從底層資料庫查詢不到資料,則不寫入快取。這就導致每次請求都會到底層資料庫進行查詢,快取也失去了意義。當高並行或有人利用不存在的Key頻繁攻擊時,資料庫的壓力驟增,甚至崩潰,這就是快取穿透問題。
常規解決方案
快取特定值
一般對於快取穿透我們比較常規的做法就是,將不存在的key 設定一個固定值,比如說NULL,&&等等,在查詢返回這個值的時候,我們應用就可以認為這是一個不存在的key,那我們應用就可以決定是否繼續等待,還是繼續存取,還是直接放棄,如果繼續等待存取的話,設定一個輪詢時間,再次請求,如果取到的值不再是我們預設的,那就代表已經有值了,從而避免了透傳到資料庫,從而把大量的類似請求擋在了快取之中。
快取特定值並同步更新
特定值做了快取,那就意味著需要更多的記憶體儲存空間。當儲存層資料變化了,快取層與儲存層的資料會不一致。有人會說,這個問題,給key 加上一個過期時間不就可以了,確實,這樣是最簡單的,也能在一定程度上解決這兩個問題,但是當並行比較高的時候(快取並行),其實我是不建議使用快取過期這個策略的,我更希望快取一直存在;通過後臺系統來更新快取中的資料一致性的目的。
布隆過濾器
布隆過濾器的核心思想是這樣的,它不儲存實際的資料,而是在記憶體中建立一個定長的點陣圖用0,1來標記對應資料是否存在系統;過程是將資料經過多個雜湊函數計算出不同的雜湊值,然後用雜湊值對點陣圖的長度進行取模,最後得到點陣圖的下標位,然後在對應的下標位上進行標記;找數的時候也是一樣,先通過多個雜湊函數得到雜湊值,然後雜湊值與點陣圖的長度進行取模得到多個下標。如果多個下標都被標記成1了,那麼說明資料存在於系統,不過只要有一個下標為0那麼就說明該資料肯定不存在於系統中。
在這裡先通過一個範例介紹一下布隆過濾器的場景:
以ID查詢文章為例,如果我們要知道資料庫是否存在對應的文章,那麼最簡單的方式就是我們把所有資料庫存在的ID都儲存到快取去,這個時候當請求過進入系統,先從這個快取資料裡判斷系統是否存在對應的資料ID,如果不存在的話直接返回出去,避免請求進入到資料庫層,存在的話再從獲取文章的資訊。但是這個不是最好的方式,因為當文章的數量很多很多的時候,那快取中就需要存大量的檔案id而且只能持續增長,所以我們得想一種方式來節省記憶體資源當又能是請求都能命中快取,這個就是布隆過濾器要做的。
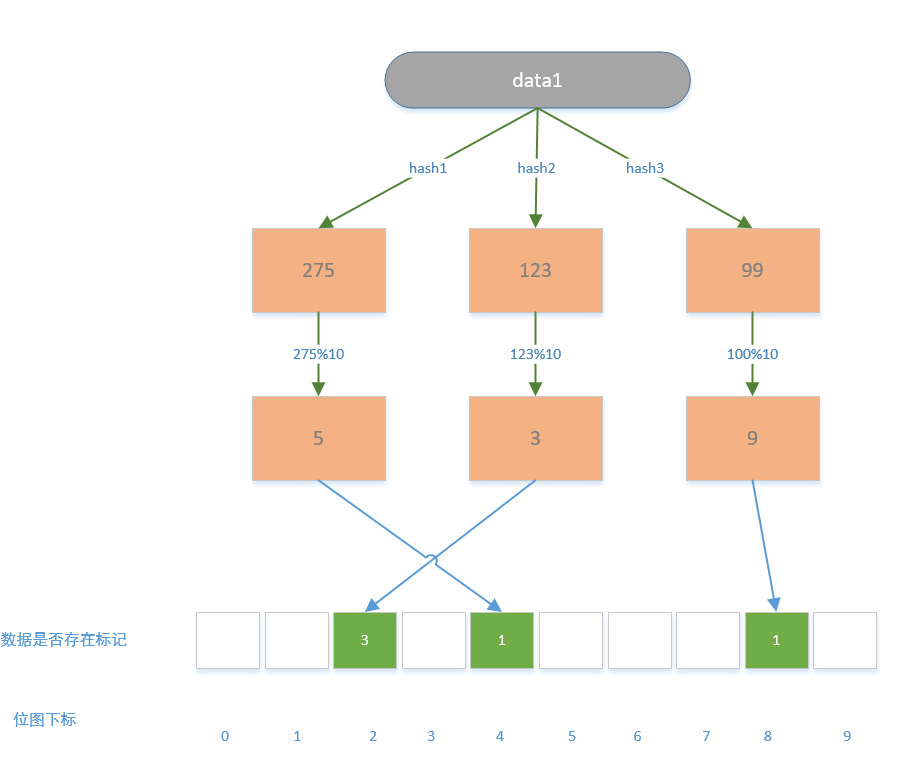
我們分析布隆過濾器的優缺點
優點
1.不需要儲存資料,只用位元表示,因此在空間佔用率上有巨大的優勢
2.檢索效率高,插入和查詢的時間複雜度都為 O(K)(K 表示雜湊函數的個數)
3.雜湊函數之間相互獨立,可以在硬體指令層次平行計算,因此效率較高。
缺點
1.存在不確定的因素,無法判斷一個元素是否一定存在,所以不適合要求 100% 準確率的場景
2.只能插入和查詢元素,不能刪除元素。
布隆過濾器分析:面對優點,完全符合我們的訴求,針對缺點1,會有極少的資料穿透對系統來說並無壓力。針對缺點2,合同的資料,本來就是不可刪除的。如果合同過期,我們可以查出單個商家的所有合同,從合同的結束時間來判斷合同是否有效,並不需要取刪除布隆過濾器裡的元素。
考慮到呼叫redis布隆過濾器,會走一次網路,而我們的查詢近一半都是無效查詢,我們決定使用本地布隆過濾器,這樣就可以減少一次網路請求。但是如果是本地布隆過濾器,在更新時,就需要對所有機器的本地布隆過濾器更新,我們監聽合同的狀態來更新,通過mq的廣播模式,來對布隆過濾器插入元素,這樣就做到了所有機器上的布隆過濾器統一元素插入。
2.第二層防護
面對高並行,我們首先想到的是快取。
引入快取,我們就要考慮快取穿透,快取擊穿,快取雪崩的三大問題。
其中快取穿透,我們已再第一層防護中處理,這裡只解決快取擊穿,快取雪崩的問題。
快取擊穿(Cache Breakdown)快取雪崩是指只大量熱點key同時失效的情況,如果是單個熱點key,在不停的扛著大並行,在這個key失效的瞬間,持續的大並行請求就會擊破快取,直接請求到資料庫,好像蠻力擊穿一樣。這種情況就是快取擊穿。
常規解決方案
快取失效分散
這個問題其實比較好解決,就是在設定快取的時效時間的時候增加一個隨機值,例如增加一個1-3分鐘的隨機,將失效時間分散開,降低集體失效的概率;把過期時間控制在系統低流量的時間段,比如凌晨三四點,避過流量的高峰期。
加鎖
加鎖,就是在查詢請求未命中快取時,查詢資料庫操作前進行加鎖,加鎖後後面的請求就會阻塞,避免了大量的請求集中進入到資料庫查詢資料了。
永久不失效
我們可以不設定過期時間來保證快取永遠不會失效,然後通過後臺的執行緒來定時把最新的資料同步到快取裡去
解決方案:使用分散式鎖,針對同一個商家,只讓一個執行緒構建快取,其他執行緒等待構建快取執行完畢,重新從快取中獲取資料。
快取雪崩(Cache Avalanche)當快取中大量熱點快取採用了相同的實效時間,就會導致快取在某一個時刻同時實效,請求全部轉發到資料庫,從而導致資料庫壓力驟增,甚至宕機。從而形成一系列的連鎖反應,造成系統崩潰等情況,這就是快取雪崩。
解決方案:快取雪崩的解決方案是將key的過期設定為固定時間範圍內的一個亂數,讓key均勻的失效即可。
我們考慮使用redis快取,因為每次查詢的條件都不一樣,返回的結果資料又比較少,我們考慮限制查詢都必須有一個固定的查詢條件,商家編碼。如果查詢條件中沒有查商家編碼,我們可以通過商家名稱,商家業務賬號這些條件來反查查商家編碼。
這樣我們就可以快取單個商家編碼的所有合同,然後再通過程式碼使用filter對其他查詢條件做支援,避免不同的查詢條件都去快取資料而引發的快取資料更新,快取資料淘汰已經快取資料一致等問題。
同時只快取單個商家編碼的所有合同,快取的資料量也是可控,每個快取的大小也可控,基本不會出現redis大key的問題。
引入快取,我們就要考慮快取資料一致性的問題。
有關快取一致性問題,可自行百度,這個就不在敘述。
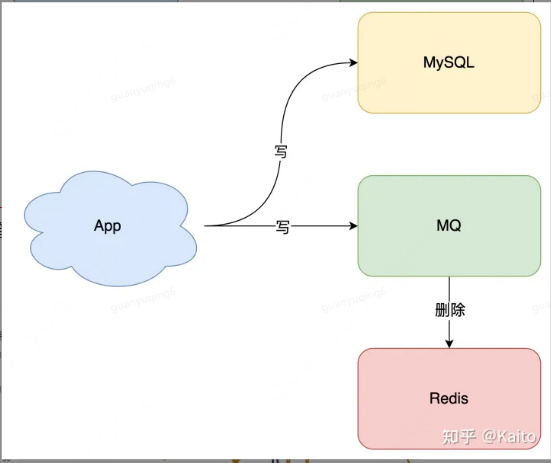
如圖所示 對於商家編碼維度的快取資料,我們通過監聽合同的狀態,使用mq廣播來刪除對應商家的快取,從而避免出現快取和資料一致性的相關問題。
3.第三層防護
第三層防護,自然是資料庫,如果有查詢經過了第一層和第二層,那我們需要直接查詢資料庫來返回結果,同時,我們對直接呼叫到資料庫的執行緒進行監控。
為避免一些未知的查詢大量查詢湧入,導致資料庫呼叫保證的問題,尤其是大促時,我們可以提前對資料庫裡的所有商家合同進行提前快取。在快取時,為避免快取雪崩問題,我們對將key的過期設定為固定時間範圍內的一個亂數,讓key均勻的失效。
同時,為避免依然存在意外的情況,有大量查詢湧入。我們通過ducc開關控制資料庫的查詢,如呼叫量太高導致無法支撐,則直接關閉資料庫的呼叫,保證資料庫不會直接宕機導致整個業務不可用。
4 總結
本文主要分析了面對高並行呼叫的呼叫場景設計及的技術方案,在引入快取的同時,也要考慮實際的呼叫入參及結果,面對增加的網路請求,是否可以進一步減少。面對redis快取,是否可以通過一些手段避免所有查詢條件都需要快取,帶來的快取爆炸,快取淘汰策略等問題,以及解決快取與資料一致等一系列問題。
本方案是根據具體的查詢業務場景設計具體的技術方案,針對不同的業務場景,對應的技術方案也是不一樣的。