MySQL 中一條 sql 的執行過程
一條 SQL 的執行過程
前言
在開始學習 MySQL 中知識點的時候,首先來看下 SQL 在 MySQL 中的執行過程。
查詢
查詢語句是我們經常用到的,那麼一個簡單的查詢 sql,在 MySQL 中的執行過程是怎麼樣的呢?
SELECT * FROM user WHERE id =1
慄如上面的這個簡單的查詢語句,來看下具體的查詢邏輯。
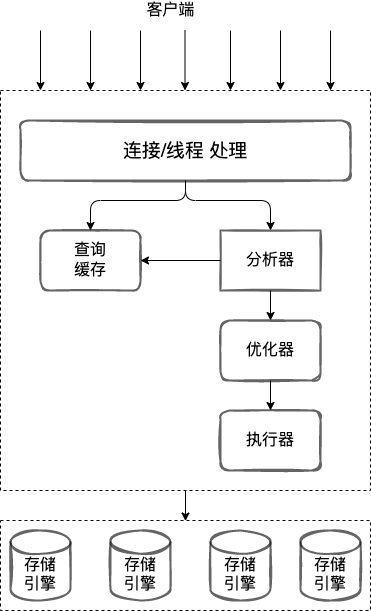
MySQL 主要分為 Server 層和儲存引擎層兩部分。
Server 層包括聯結器、查詢快取。分析器、執行器等。MySQL 中大多數的核心功能,所有的內建函數,所有跨儲存引擎的功能都在這一層實現。慄如:儲存過程,觸發器,檢視等。。。
儲存引擎層負責資料的儲存和提取。其架構是外掛式的,支援 InnoDB、MyISAM、Memory 等多個儲存引擎。MySQL 5.5.5 InnoDB 成為了預設的儲存引擎。
聯結器
大多數基於網路的使用者端/伺服器的工具或者服務都有類似的架構。
這裡主要的工作就是管理和使用者端的連線,同時進行連線的許可權認證。
-
如果使用者名稱密碼不對,就會有一個 "Access denied for user" 的錯誤提示。
-
如果使用者名稱密碼認證通過,聯結器中會在許可權表中查詢改賬號擁有的許可權,之後所有的許可權判斷邏輯,都依賴於此時讀到的許可權。
這就意味著,一旦一個使用者建立連線後,即使對這個賬號進行了許可權的修改,對已經建立的連線也不會產生影響。只有新建連線,才能使用新的許可權。
使用者端如何太長時間沒有動靜,聯結器會斷開連線,這個時間由引數 wait_timeout 控制預設 8 小時。
資料庫的連線分成兩種型別短連線和短連結:
長連線:長連線在連線成功之後,後面使用者端的請求,可以複用這個連線;
短連線:短連線每次執行完幾次查詢就斷開連線,每次使用者端的請求都會新建一個。
因為建立連線的過程是很複雜,並且是有一定開銷的,應該儘量減少連線的建立,長連線更加推薦使用。
為了避免執行緒被頻繁的建立和銷燬,影響效能,MySQL5.5 版本引入了執行緒池,會快取建立的執行緒,不需要為每一個新建的連線,建立或銷燬執行緒。可以使用執行緒池中少量的執行緒服務大量的連線。
查詢快取
MySQL 查詢快取,為了提高相同 Query 語句的響應速度,會快取特定 Query 的整個結果集資訊,當後面有相同的查詢語句,直接查詢快取,返回查詢的結果。當命中的時候不需要執行後面複雜的操作,就可以直接返回結果,查詢效率是很高的。
不過當一個表有更新的時候,和這個表有關的查詢快取都會被刪除,造成查詢快取的失效。所以更新較頻繁的資料庫不建議使用查詢快取,命中率會非常的低。所以,長時間不更新的靜態表,這種適合使用查詢快取。
在 MySQL 5.6 開始,就已經預設禁用查詢快取了。在 MySQL 8.0,就已經刪除查詢快取功能了。
分析器
當 SQL 需要執行時候,首先分析器會做一個詞法分析和語法分析,一條 SQL 語句由字串和空格組成,MySQL 需要識別出裡面的字串分別是什麼,代表什麼。根據詞法分析的結果,語法分析器會根據語法規則,判斷你輸入的這個SQL語句是否滿足MySQL語法。
優化器
優化執行:利用資料庫的統計資訊決定 SQL 語句的最佳執行方式,選擇合適的索引,找出最優的查詢方案,
優化器是在表裡面有多個索引的時候,決定使用哪個索引;或者在一個語句有多表關聯(join)的時候,決定各個表的連線順序。
執行器
開始執行的時候,要先判斷一下你對這個表T有沒有執行查詢的許可權,如果沒有,就會返回沒有許可權的錯誤。
有許可權,會根據優化後的 SQL,向儲存引擎發起查詢操作,並且返回查詢的結果。
執行與優化
總體來說就是
MySQL 會解析查詢,並建立內部的資料結構(解析樹),然後對其進行各種優化,包括重寫查詢,決定表的讀取順序,以及選擇合適的索引。
資料更新
在瞭解資料的更新,需要先來了解下,MySQL 中幾種常用的紀錄檔。
紀錄檔模組
先來看下 InnoDB 中的儲存
InnoDB 儲存引擎是基於磁碟儲存的,並將其中的記錄按照頁的方式進行管理。因此可以將其視為基於磁碟的資料庫系統,由於 CPU 速度與磁碟速度之間的鴻溝,基於
磁碟的資料庫系統通常使用快取池技術來提供資料庫整體效能。
快取池簡單來說就是一塊記憶體區域,通過記憶體速度來彌補磁碟速度較慢對資料庫效能的影響。
-
資料庫讀取頁的操作,會將從磁碟讀出的頁存放到快取池中,下次讀相同的頁就可以在快取池中查詢了,查詢不到還是會從磁碟中讀取。
-
資料庫中頁的修改操作,首先修改快取池中的頁,然後一定頻率重新整理到新的磁碟上。頁從快取池中重新整理到磁碟中的操作並不是在每次頁發生更新時觸發,而是通過一種稱為 Checkpoint 的機制重新整理回磁碟。
如果每一個頁發生變化,就將新頁的版本重新整理到磁碟,那麼這個開銷是很大的,如果資料都集中在某幾個頁,那麼資料庫的效能將變的很差。
同時,如果在從快取中將頁的新版本重新整理到磁碟時發生了宕機,那麼資料就不能恢復了,為了避免發生資料丟失的問題,當前事務資料系統都採用了 Write Ahead Log 策略,當事務提交的時候,先寫重做紀錄檔,再修改頁。通過重做紀錄檔來處理宕機時候的資料丟失問題。
redo log (重做紀錄檔)
InnoDB 中的重做紀錄檔,由兩部分組成,redo log 和 undo log。
-
redo log用來從保證事務的永續性; -
undo log用來實現事務回滾以及 MVCC 的功能。
redo log 簡單點講就是 MySQL 異常宕機後,將沒來得及提交的事物資料重做出來。
redo log 包括兩部分:一個是記憶體中的紀錄檔緩衝( redo log buffer ),另一個是磁碟上的紀錄檔檔案( redo log file )。
MySQL 每執行一條 DML 語句,先將記錄寫入 redo log buffer,後續某個時間點再一次性將多個操作記錄寫到 redo log file 。這種 先寫紀錄檔,再寫磁碟 的技術就是 MySQL 裡經常說到的 WAL(Write-Ahead Logging) 技術。
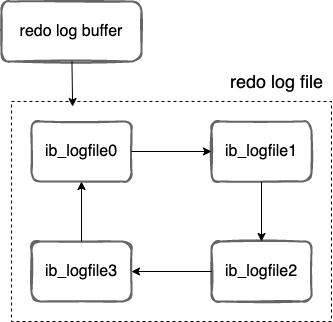
MySQL 支援三種將 redo log buffer 寫入 redo log file 的時機,可以通過 innodb_flush_log_at_trx_commit 引數設定,各引數值含義如下:
| 引數值 | 含義 |
|---|---|
| 0(延遲寫) | 事務提交時不會將 redo log buffer 中紀錄檔寫入到 os buffer ,而是每秒寫入 os buffer 並呼叫 fsync() 寫入到 redo log file 中。也就是說設定為0時是(大約)每秒重新整理寫入到磁碟中的,當系統崩潰,會丟失1秒鐘的資料。 |
| 1(實時寫,實時刷) | 事務每次提交都會將 redo log buffer 中的紀錄檔寫入 os buffer 並呼叫 fsync() 刷到 redo log file 中。這種方式即使系統崩潰也不會丟失任何資料,但是因為每次提交都寫入磁碟,IO的效能較差。 |
| 2(實時寫,延遲刷) | 2(實時寫,延遲刷) 每次提交都僅寫入到 os buffer ,然後是每秒呼叫 fsync() 將 os buffer 中的紀錄檔寫入到 redo log file 。 |
引數 innodb_flush_log_at_trx_commit 建議設定成 1 ,這樣可以保證MySQL異常重啟之後資料不丟失。
redo log 的紀錄檔檔案會一直追加嗎?
InnoDB 中的 redo log 是固定大小的,比如可以設定為一組 4 個檔案,每個檔案的大小為 1GB 那麼 redo log 中就可以記錄 4GB 的資料操作。redo log 中紀錄檔的寫入是迴圈寫入的,當寫到結尾時,會回到開頭回圈寫紀錄檔。
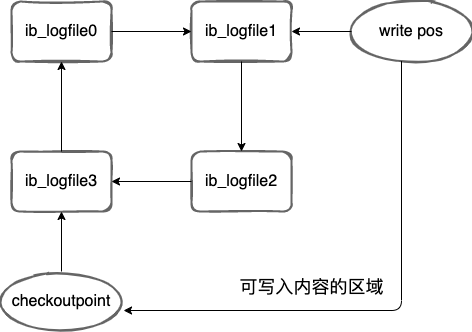
write pos 表示當前記錄的位置,一邊寫一邊後移,checkpoint 表示當前要擦除的位置,checkpoint 之前的頁被會重新整理到磁碟中。
write pos 和 checkpoint 之間的區域就是還能寫入到 redo log 中的紀錄檔檔案。
有了 redo log,InnoDB 就可以保證即使資料庫發生異常重啟,之前提交的記錄都不會丟失,這個能力稱為 crash-safe。
binlog (歸檔紀錄檔)
binlog 記錄了 MySQL 資料執行更改的所有操作,以二進位制的形式儲存在磁碟中,binlog 是 MySQL 中的邏輯紀錄檔,由 server 層進行記錄,使用任何引擎的 MySQL 都會記錄 binlog 紀錄檔。
binlog 是通過追加的方式進行寫入的,可以通過 max_binlog_size 引數設定每個 binlog 檔案的大小,當檔案大小達到給定值之後,會生成新的檔案來儲存紀錄檔。
使用場景
binlog 主要有下面幾種作用:
-
主從複製:在主從複製中,從庫利用主庫上的binlog進行重播,實現主從同步;
-
資料恢復:使用者資料庫基於時間點的資料還原;
-
審計:使用者通過二進位制紀錄檔中的資訊來進行審計,判斷是否有對資料庫進行注入的攻擊。
binlog 刷盤時機
在預設情況下,二進位制檔案並不是每次寫的時候同步到磁碟,因此當資料庫所在的作業系統宕機的時候,可能會存在一部分資料沒有寫入到二進位制檔案中。
具體的刷盤時機可以通過 sync_binlog 引數來控制
| 引數值 | 含義 |
|---|---|
| 0 | 不去強制要求,由系統自行判斷何時寫入到磁碟中 |
| 1 | 每次 commit 的時候都要將 binlog 寫入磁碟 |
| N | 每N個事務,才會將 binlog 寫入磁碟 |
在 MySQL 5.7.7 之後的版本 sync_binlog 的預設值都是1。
undo log (回滾紀錄檔)
是 InnoDB 儲存引擎層生成的紀錄檔,實現了事務中的原子性,主要用於事務回滾和 MVCC。
在對資料庫進行修改的時候,就會記錄 undo log ,這樣當事務執行失敗的時候,就能使用這些 undo log 恢復到修改之前的樣子。
不過需要注意的是 undo log 記錄的是邏輯紀錄檔,只是將資料庫邏輯的恢復到之前的樣子,所有的修改邏輯都被取消了,但是資料結構和頁本身在回滾之後可能會不一樣。聽起來有點難理解,下面舉個栗子分析下。
比如使用者執行了一個 INSERT 10W 條記錄的事務,這個事務會導致分配一個新的段,表空間會增大。事務執行失敗,回滾的時候,只是將插入的資料進行了回滾,表的空間大小並不會進行收縮。所以說,undo log 記錄的是邏輯紀錄檔,只是將資料庫邏輯的恢復到之前的樣子。
InnoDB 通過 undo log 進行事務的回滾,實際上做的是和之前相反的工作,對於每個 INSERT ,InnoDB 會生成一個 DELETE ;對於 DELETE 操作,InnoDB 會生成一個 INSERT。。。通過反向的操作來實現事務資料的回滾操作。
除了回滾操作,還有一個作用就是 MVCC,InnoDB 中對 MVCC 的實現需要藉助於 undo log。
InnoDB 通過 undo log 儲存每條資料的多個版本,並且能夠找回資料歷史版本提供給使用者讀,每個事務讀到的資料版本可能是不一樣的。
當用戶讀取一行記錄的時候,若該記錄已經被其他的事務佔用,當前事務可以從 undo log 中讀取之前的行版本資訊,以此實現非鎖定讀取。
兩階段提交
這裡來看下一條 Update 語句的執行過程
UPDATE user SET username = '小張-001' WHERE id = 2;
1、執行器先找引擎取 id = 2 這一行;
-
如果
id = 2這一行的資料頁、本來就在buffer pool中,就直接返回給執行器更新; -
如果記錄不在
buffer pool中,將資料從磁碟讀入到buffer pool,返回記錄給執行器。
2、執行器得到資料之後嗎,首先看下更新前的記錄和更新後的記錄時候一樣;
-
如果一樣,不執行後面的更新流程;
-
如果不一樣,就把更新前的資料和更新後的資料都傳給 InnoDB 引擎,讓 InnoDB 來執行更新操作;
3、引擎將資料更新到記憶體中,同時將更新操作記錄到 redo log 中,此時的 redo log 處於 prepare 狀態,然後告知執行器執行完成了,隨時可以提交事務;
4、執行器生成這個操作的 binlog,並把 binlog 寫入到磁碟中;
5、執行器呼叫引擎的提交事務介面,引擎把剛剛寫入的 redo log 改成提交(commit)狀態,更新完成。

其中在寫 binlog 和 redo log 的過程中,為了保證兩個檔案寫入的原子性,這裡使用了內部 XA 事務的兩階段提交。
Prepare 階段:
將(內部事務的id) xid 寫入到 redo log 中,InnoDB 將事務狀態設定為 prepare 狀態,將 redolog 寫檔案並刷盤;
Commit 階段:
將 xid 寫入到 binlog, binlog 寫入檔案,binlog 刷盤,然後 InnoDB 提交事務。
兩階段提交保證了事務在多個引擎和 binlog 之間的原子性,binlog 承擔內部 XA 事務的協調者,以 binlog 寫入成功作為事務提交的標誌。
在崩潰恢復中,是以 binlog 中的 xid 和 redo log 中的 xid 進行比較,xid 在 binlog 裡存在則提交,不存在則回滾。我們來看崩潰恢復時具體的情況:
在 prepare 階段崩潰,即已經寫入 redolog,在寫入 binlog 之前崩潰,則會回滾;
在 commit 階段,當沒有成功寫入 binlog 時崩潰,也會回滾;
如果已經寫入 binlog,在寫入 InnoDB commit 標誌時崩潰,則重新寫入 commit 標誌,完成提交。
為什麼需要兩階段提交
如果不使用"兩階段提交",資料庫的狀態就有可能和它的紀錄檔回覆出來的庫的狀態不一致。
不使用"兩階段提交" binlog 和 redo log 先後寫,在實際的情況都會出現其中一個寫不成功的情況
如果 redo log 沒有寫成功,那麼主庫中在宕機之後,通過 redo log 實現事務的一致性,就會損失宕機時候沒有寫成功的幾條資料,而從庫通過 binlog 進行同步,資料是沒有丟失的,這樣和主庫就出現了資料不一致的情況。
如果 binlog 沒有寫成功,這樣就更容易理解了,從庫通過 binlog 進行同步,就會丟失資料庫宕機時候丟失的資料,和主庫的主句就不一致了。
所以 binlog 和 redo log 出現半成功的情況,就有可能出現主從環境資料不一致的情況。
邏輯紀錄檔和物理紀錄檔
邏輯紀錄檔:可以簡單理解為記錄的就是sql語句。
物理紀錄檔:因為 MySQL 資料最終是儲存在資料頁中的,物理紀錄檔記錄的就是資料頁變更。
參考
【高效能MySQL(第3版)】https://book.douban.com/subject/23008813/
【MySQL 實戰 45 講】https://time.geekbang.org/column/100020801
【MySQL技術內幕】https://book.douban.com/subject/24708143/
【MySQL · 原始碼分析 · 內部 XA 和組提交】http://mysql.taobao.org/monthly/2020/05/07/
【MySQL學習筆記】https://github.com/boilingfrog/Go-POINT/tree/master/mysql