[資料結構] 根據前中後序遍歷中的兩種構造二元樹
前中後序遍歷
前中後序遍歷的特點
前序遍歷
前序遍歷順序:根節點 -> 左子樹 -> 右子樹
前序遍歷結果:[根節點,[左子樹前序遍歷結果],[右子樹前序遍歷結果]]
假如把前序遍歷結果存到陣列中,陣列中的第一個元素就是二元樹根節點的資料,而且還可以知道第二個元素是根節點左孩子的資料,即左子樹根節點的資料。
中序遍歷
中序遍歷順序:左子樹 -> 根節點 -> 右子樹
中序遍歷結果:[[左子樹中序遍歷結果],根節點,[右子樹中序遍歷結果]]
將中序遍歷結果儲存到陣列中,如果我們知道了根節點的下標,可以判斷二元樹左子樹節點的個數和右子樹的個數。
後序遍歷
後序遍歷順序:左子樹 -> 右子樹 -> 根節點
後序遍歷結果:[[左子樹後序遍歷結果],[右子樹後序遍歷結果],根節點]
將後序遍歷結果儲存倒陣列中,可以發現陣列的最後一個元素是二元樹根節點的資料,而且也可以知道倒數第二個元素是根節點右孩子資料,即右子樹根節點的資料。
根據兩種遍歷方式構造二元樹的可行性
根據兩種遍歷的結果來構造二元樹,前提是這兩種遍歷結果一定是同一顆二元樹遍歷的結果,而且二元樹的每個節點值都是唯一的,也就是說不存在重複元素。
前序 + 中序構造二元樹
前序遍歷 + 中序遍歷思路
前序遍歷:[根節點,[左子樹前序遍歷結果],[右子樹前序遍歷結果]]
中序遍歷:[[左子樹中序遍歷結果],根節點,[右子樹中序遍歷結果]]
根據前序遍歷可以知道根節點的資料,然後在中序遍歷的結果中根據這個值定位到根節點位置。假設定位到中序遍歷根節點下標為 index_mid ,那麼就可以確定左子樹節點個數 left_num 為 index_mid - in_left ,右子樹節點個數 right_num 為 in_right - index_mid ,其中 in_left 為當前二元樹中序遍歷的左邊界, in_right 為當前二元樹中序遍歷的右邊界。(在實際運用過程中,其實只用到左子樹節點個數就可以了)
大致思路我們知道了,根據左子樹的前序遍歷和中序遍歷結果,以及右子樹的前序遍歷和中序遍歷結果,可以遞回來求解左子樹和右子樹,所以我們只需要再分別遞迴對左子樹對應範圍和右子樹對應範圍進行同樣的操作就可以了。
在中序遍歷中定位根節點,可以在中序遍歷中掃描一遍,當出現值相等時,記錄下標。但是這個方法比較低效,我們用更加高效的辦法來完成根節點在中序遍歷中的定位。我們構造一個雜湊對映,記錄節點值在中序遍歷中對應的下標位置,即鍵為節點值,值為中序遍歷中對應的下標。我們事先記錄節點在中序遍歷中的下標,當我們知道了根節點的數值時,就可以在 O(1) 的時間複雜度找到其在中序遍歷中的位置 index_mid。
大致步驟為:
得到根節點在中序遍歷中的位置 index_mid,pre_left 為前序遍歷左邊界,pre_right 為前序遍歷右邊界
(1)root = new TreeNode(root_val)
(2)root->left = func(pre_left + 1, pre_left + left_num, in_left, index_mid - 1)
(3)root->right = func(pre_left + left_num + 1, pre_right, index_mid + 1, in_right)
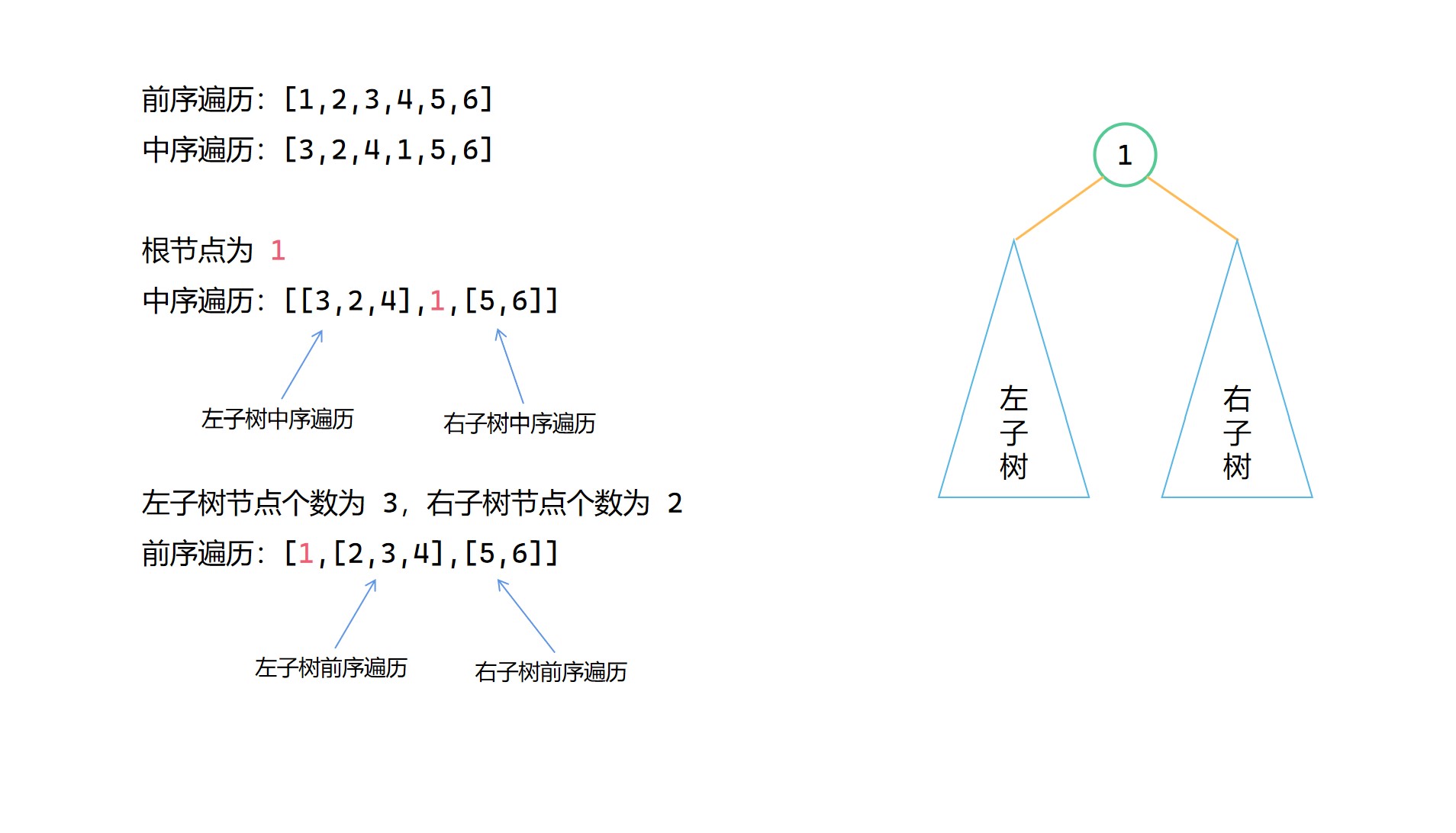
前序 + 中序構造二元樹圖解
(1)
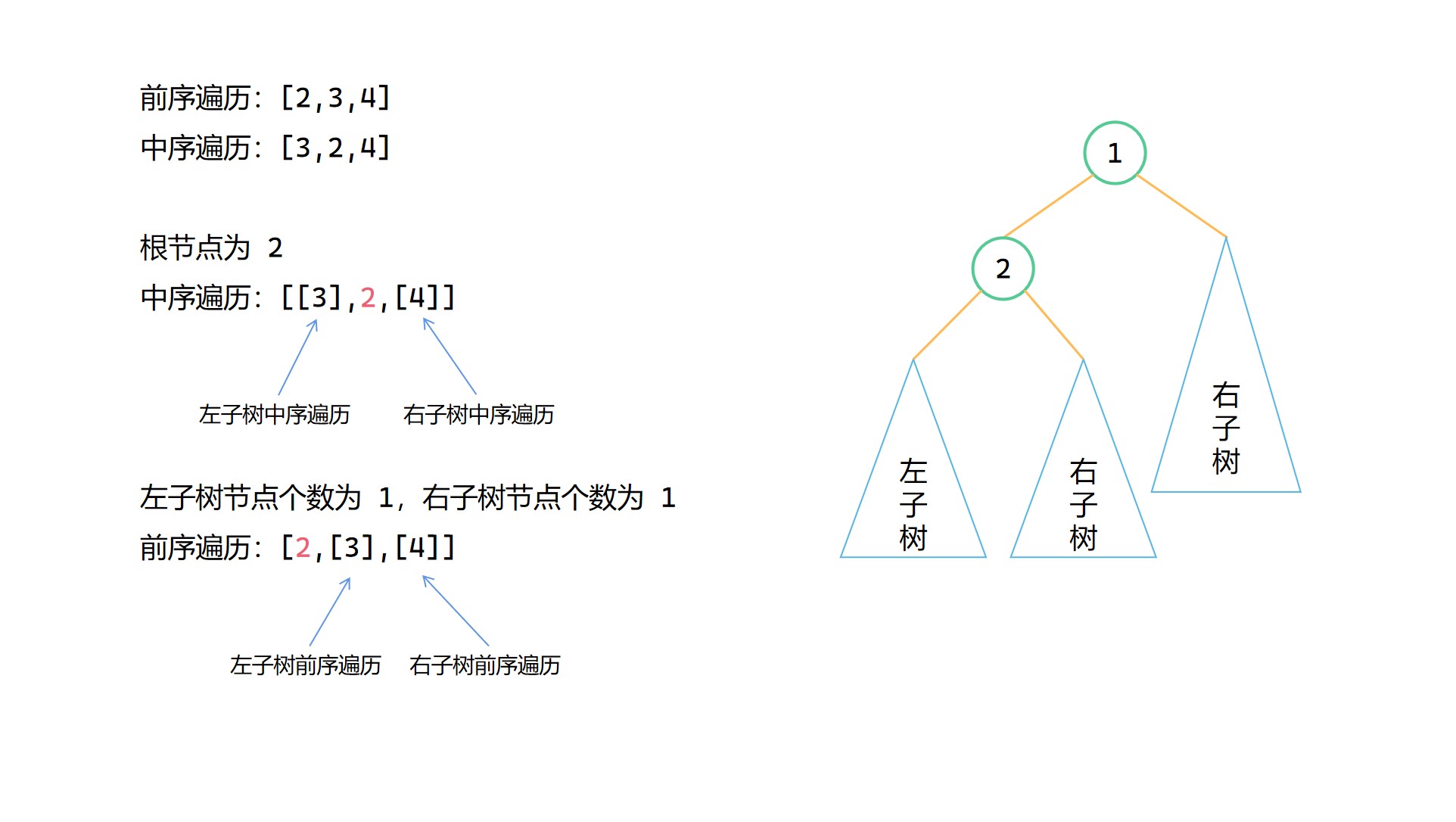
(2)
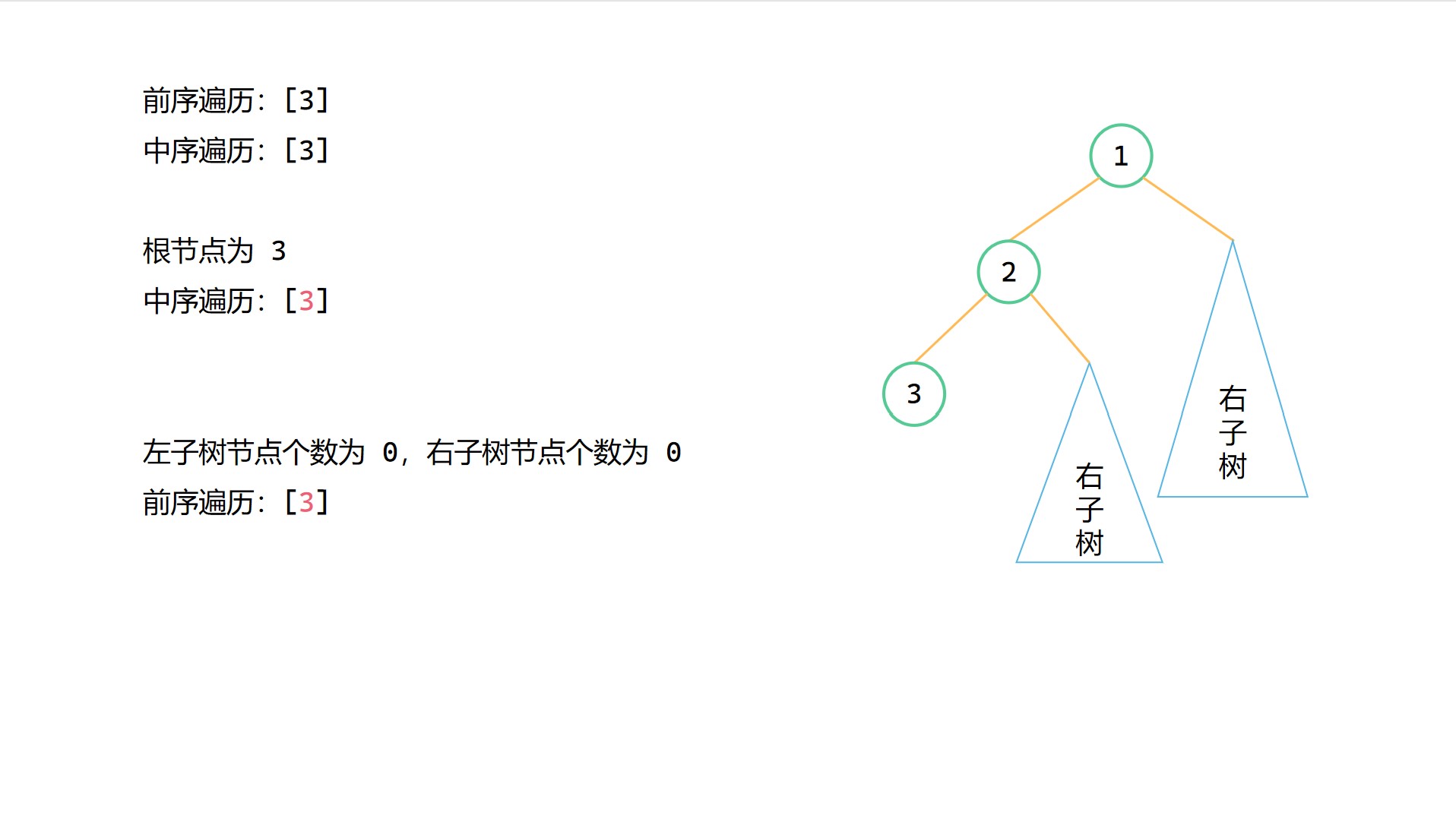
(3)
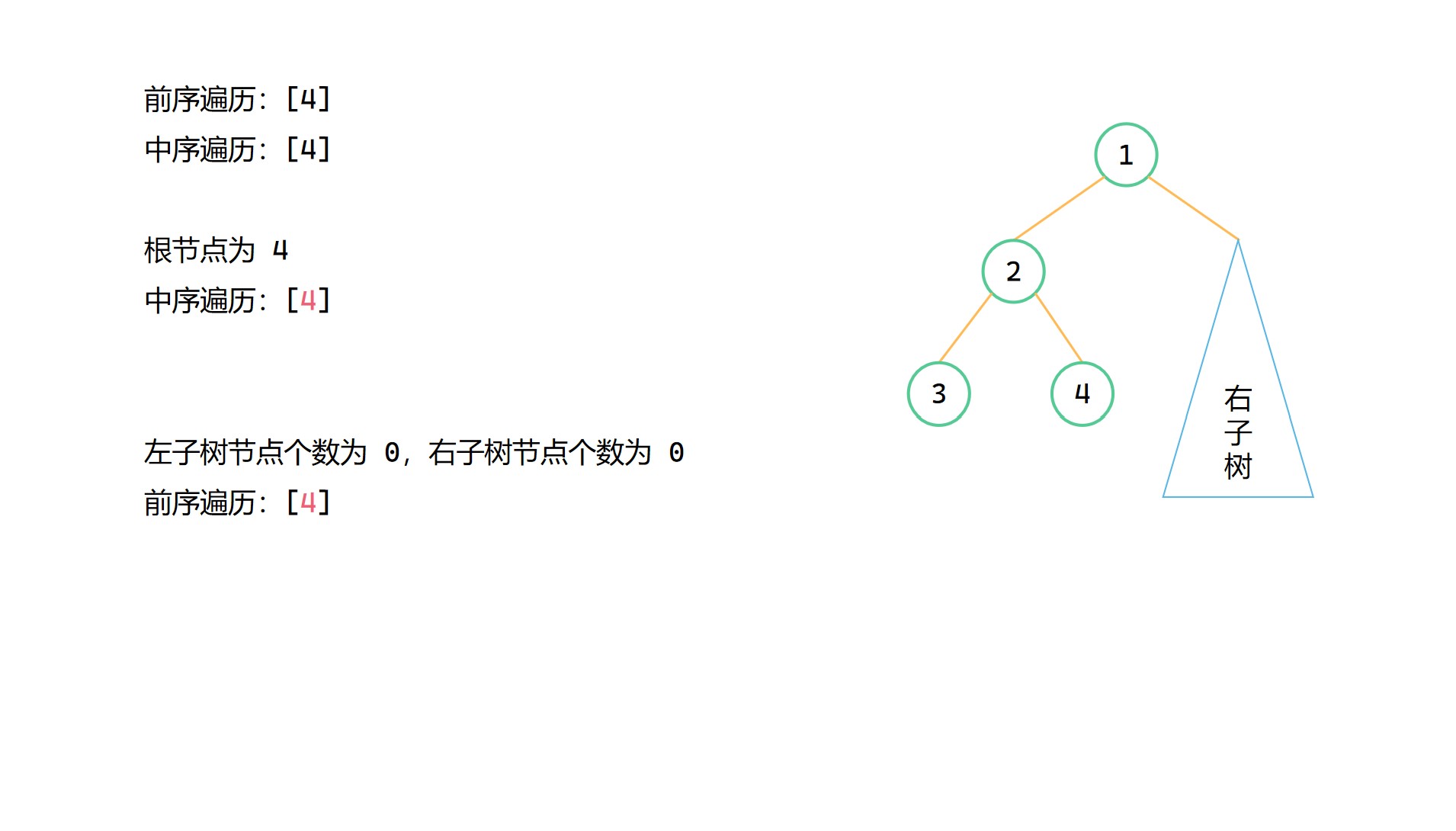
(4)
(5)
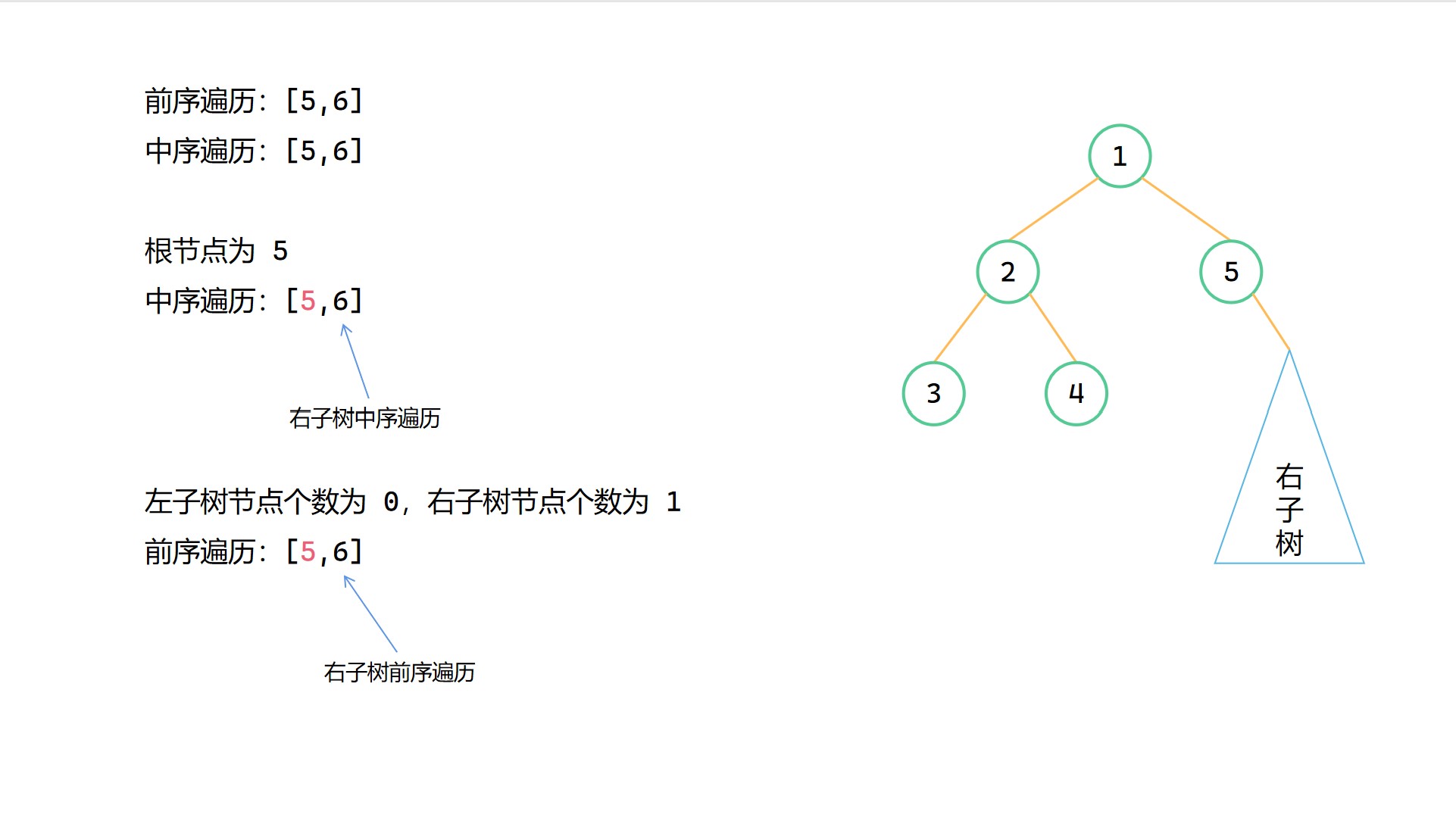
(6)
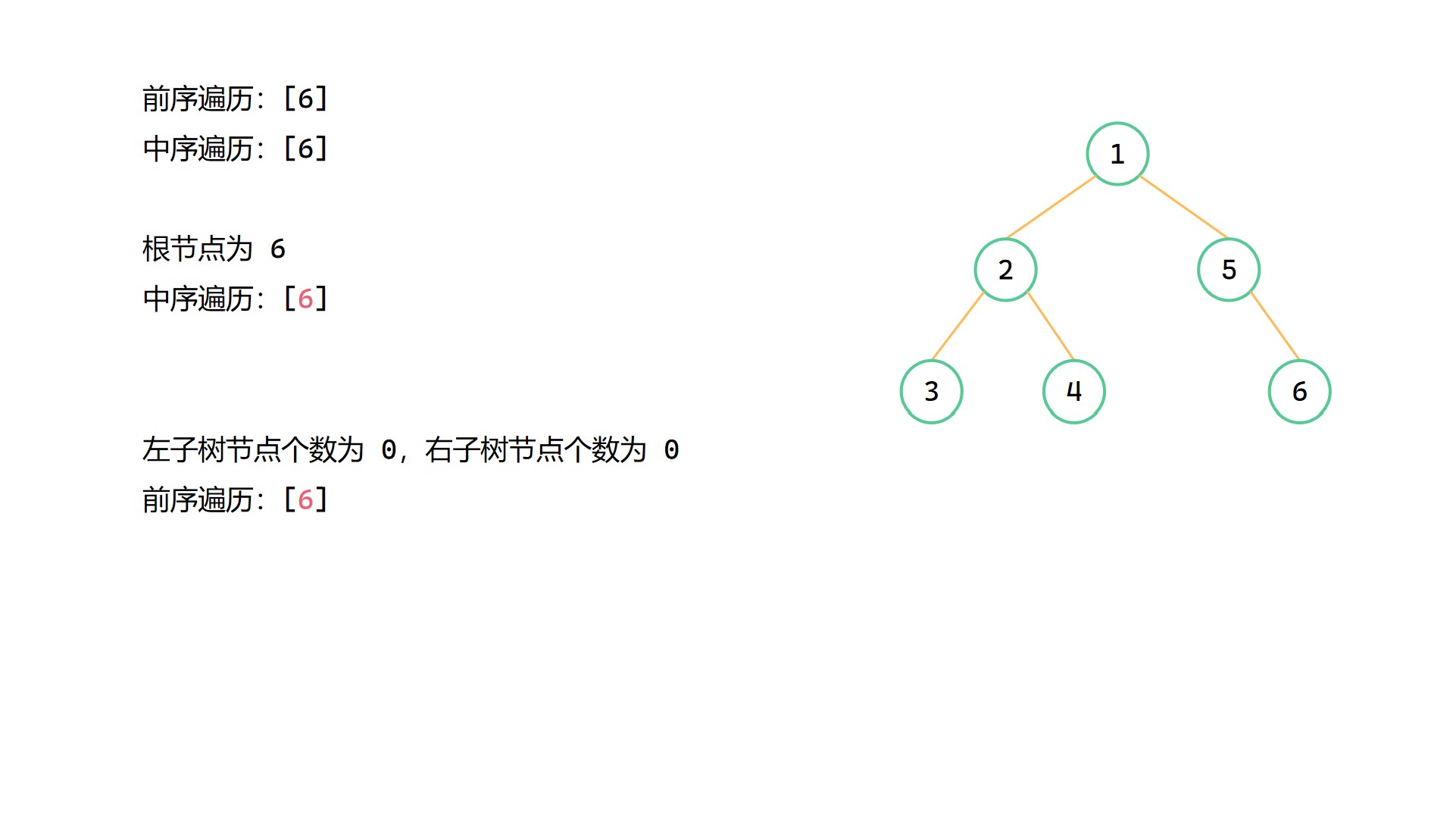
前序 + 中序構造二元樹程式碼
在leetcode上有相關題目,程式碼也是此題目對應的解答。從前序與中序遍歷序列構造二元樹
class Solution {
unordered_map<int, int> hash;
public:
TreeNode* build(vector<int>& pre, vector<int> &in, int pre_left, int pre_right, int in_left, int in_right){
if(in_left > in_right || pre_left > pre_right) return NULL;
int root_val = pre[pre_left]; //前序遍歷第一個為根節點
int index_mid = hash[root_val]; //根節點在中序遍歷中對應的下標
int left_num = index_mid - in_left; //左子樹節點個數
TreeNode *root = new TreeNode(root_val);
root->left = build(pre, in, pre_left + 1, pre_left + left_num, in_left, index_mid - 1);
root->right = build(pre, in, pre_left + left_num + 1, pre_right, index_mid + 1, in_right);
return root;
}
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
int n = inorder.size();
for(int i = 0; i < n; i++) hash[inorder[i]] = i;
return build(preorder, inorder, 0, n - 1, 0, n - 1);
}
};
中序 + 後序構造二元樹
中序遍歷 + 後序遍歷思路
中序遍歷結果:[[左子樹中序遍歷結果],根節點,[右子樹中序遍歷結果]]
後序遍歷結果:[[左子樹後序遍歷結果],[右子樹後序遍歷結果],根節點]
和前序遍歷 + 中序遍歷構造二元樹的思路有些類似,我們可以根據後序遍歷最後一個元素知道二元樹根節點的數值,然後在中序遍歷結果中定位。假設定位下標位置為 index_mid,可以確定左子樹節點個數 left_num 為 index_mid - in_left ,右子樹節點個數 right_num 為 in_right - index_mid ,其中 in_left 為當前二元樹中序遍歷的左邊界, in_right 為當前二元樹中序遍歷的右邊界。
根據左子樹的中序遍歷和後序遍歷結果,以及右子樹的中序遍歷和後序遍歷結果,遞回來求解左子樹和右子樹。
記錄下標同樣是構造雜湊對映來記錄中序遍歷結果的鍵值對。
大致步驟為:
得到根節點在中序遍歷中的位置 index_mid,post_left 為後序遍歷左邊界,post_right 為後序遍歷右邊界。
(1)root = new TreeNode(root_val)
(2)root->left = func(in_left, index_mid - 1, post_left + 1, post_left + left_num - 1)
(3)root->right = func(index_mid + 1, in_right, post_left + left_num, post_right - 1)
中序 + 後序構造二元樹圖解
(1)
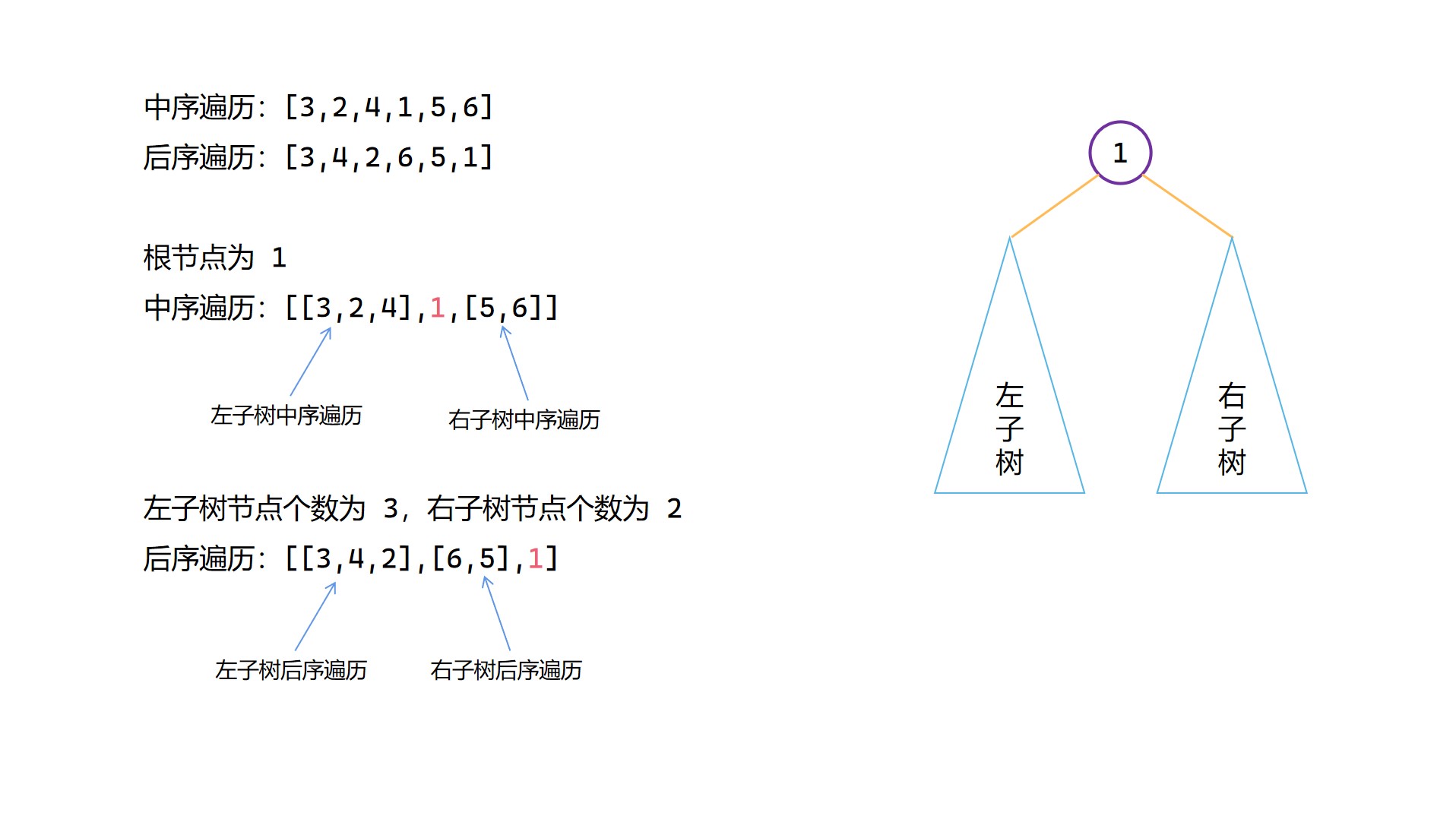
(2)
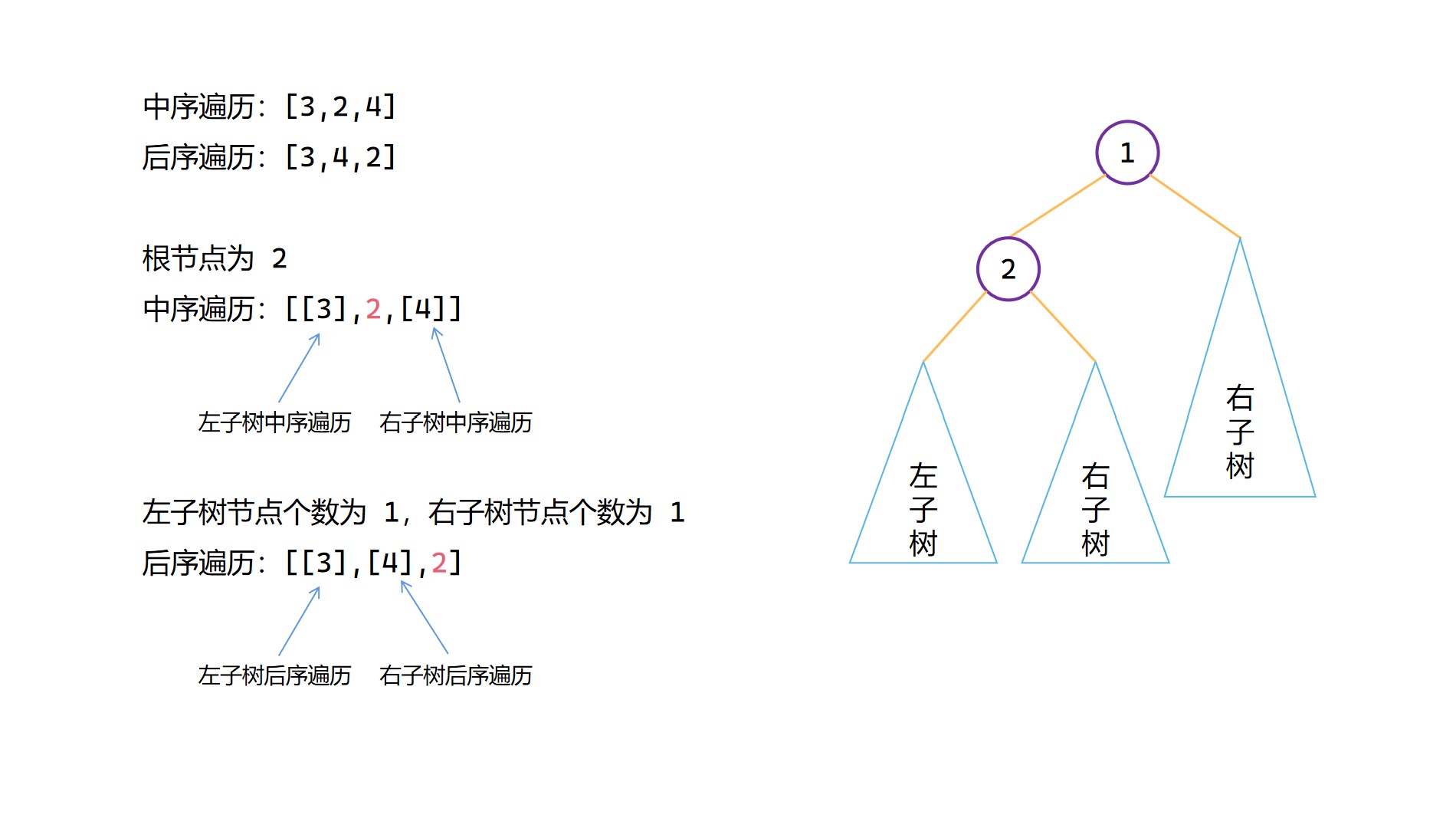
(3)
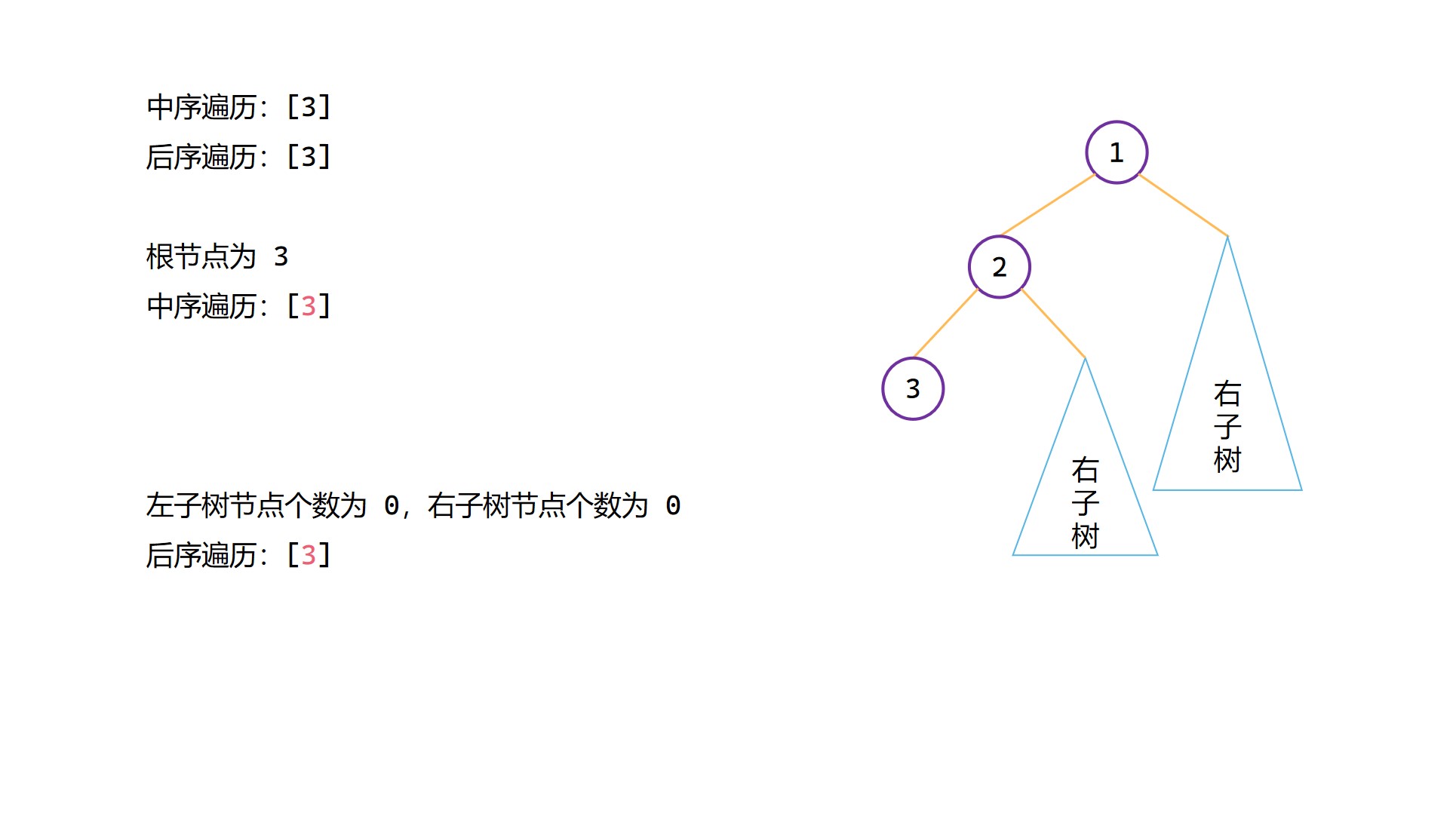
(4)
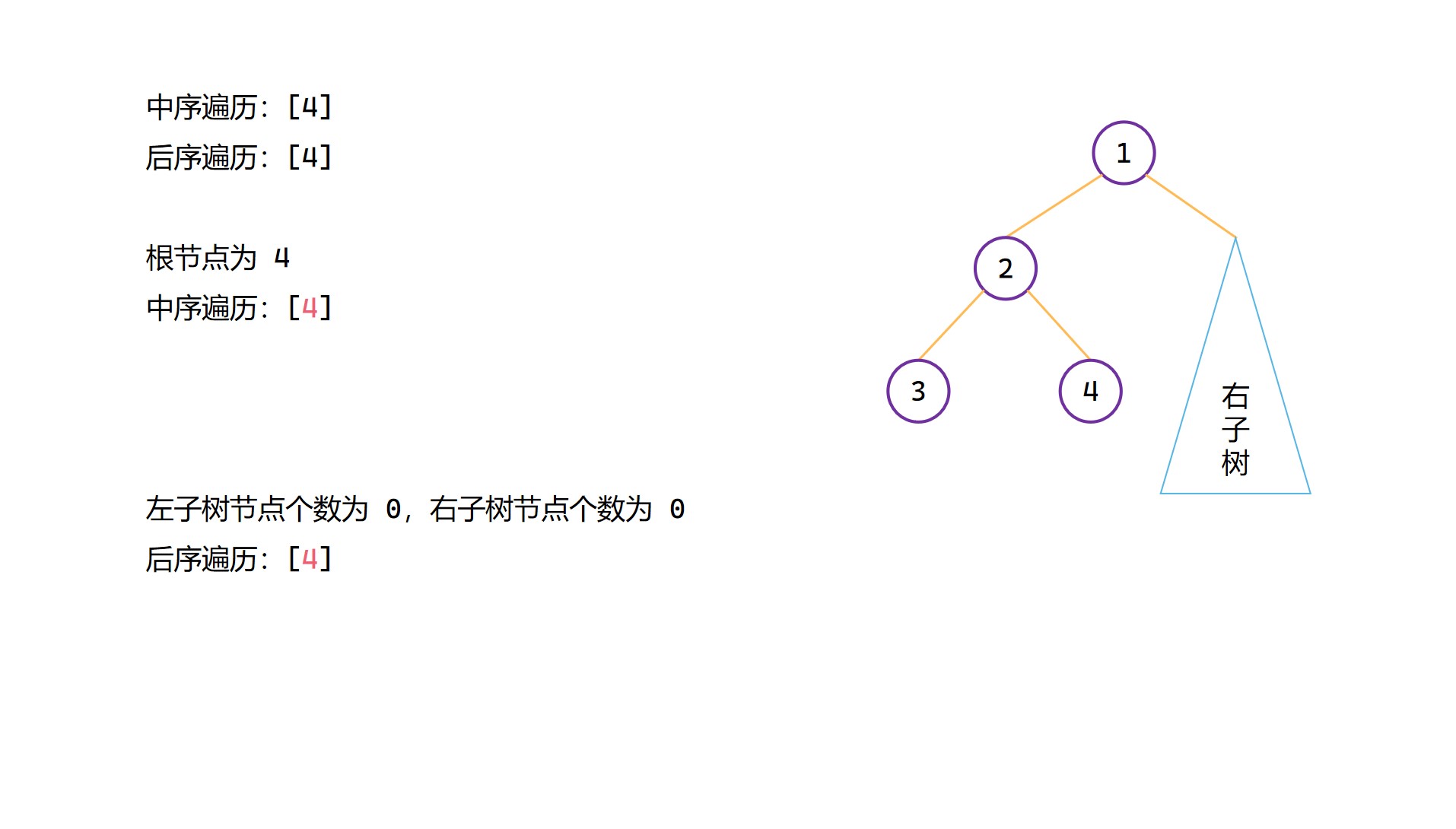
(5)
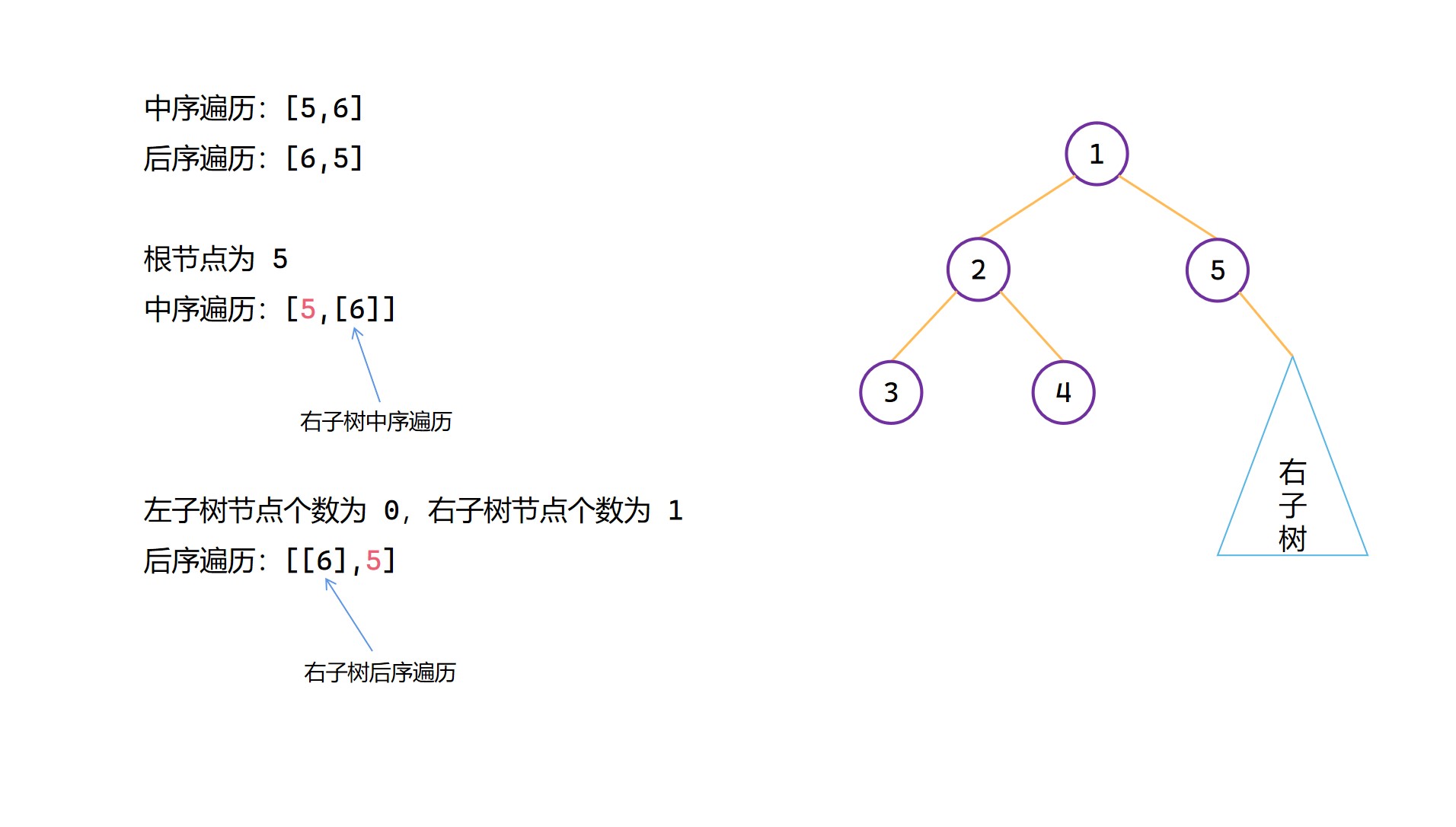
(6)
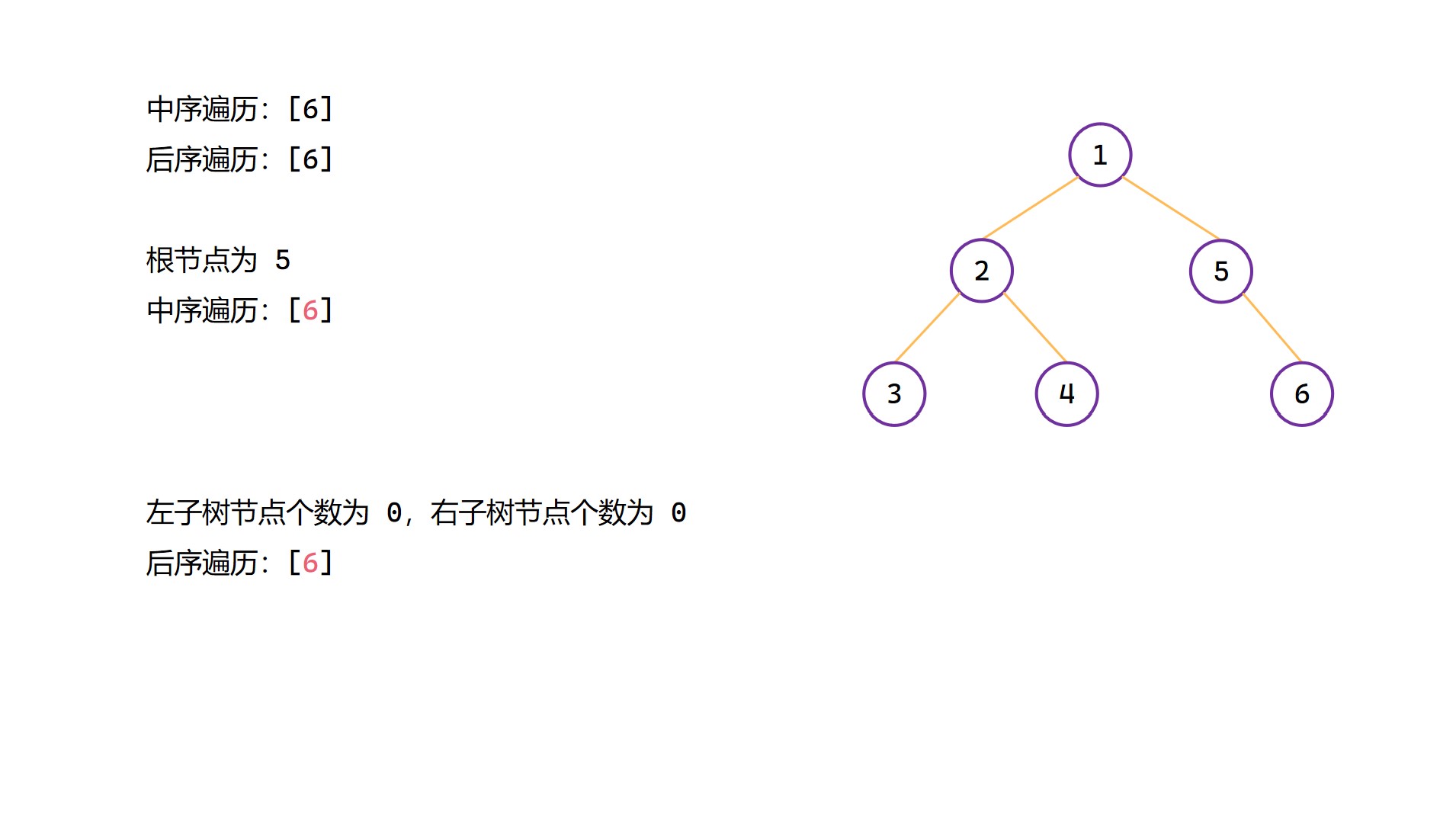
中序 + 後序構造二元樹程式碼
在leetcode上有相關題目,程式碼也是此題目對應的解答。從中序與後序遍歷序列構造二元樹
class Solution {
unordered_map<int, int> hash;
public:
TreeNode* build(vector<int>& in, vector<int>& post, int in_left, int in_right, int post_left, int post_right){
if(in_left > in_right || post_left > post_right) return NULL;
int root_val = post[post_right]; //後序遍歷的最後一個為根節點
int index_mid = hash[root_val]; //根節點在中序遍歷中對應下標
int left_num = index_mid - in_left; //左子樹節點個數
TreeNode *root = new TreeNode(root_val);
root->left = build(in, post, in_left, index_mid - 1, post_left, post_left + left_num - 1);
root->right = build(in, post, index_mid + 1, in_right, post_left + left_num, post_right - 1);
return root;
}
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
int n = inorder.size();
for(int i = 0; i < n; i++) hash[inorder[i]] = i;
return build(inorder, postorder, 0, n - 1, 0, n - 1);
}
};
前序 + 後序構造二元樹 *
前序遍歷 + 後序遍歷思路 *
前序遍歷結果:[根節點,[左子樹前序遍歷結果],[右子樹前序遍歷結果]]
後序遍歷結果:[[左子樹後序遍歷結果],[右子樹後序遍歷結果],根節點]
前序遍歷 + 後序遍歷相比前兩種要特殊一些,這個組合可以構造二元樹,但是根據前序遍歷和後序遍歷是無法確定唯一的二元樹的。
我們知道前序遍歷第一個是根節點,後序遍歷最後一個是根節點,光靠這兩個資訊無法構造二元樹。但是我們可以知道一般前序遍歷的第二個元素是左子樹根節點的值,後序遍歷的倒數第二個元素一般是右子樹根節點的值,我們可以由此來確定左右子樹的節點個數。(注意是一般情況下是這樣,當沒有左子樹時,前序遍歷的第二個應當為右子樹根節點數值,後續便利同樣也存在這樣的問題,這也是後面為什麼寫了無法確定唯一二元樹的一個原因)實際上,我們只需要用其中一個子樹根節點就可以了,以已知左子樹根節點為例,假如我們知道了左子樹根節點元素在後序遍歷中對應的下標為 index_mid,那麼可以得到左子樹節點個數 left_num 為 index_mid - post_left,右子樹節點個數 right_num 為 post_right - 1 - index_mid。對於左子樹根節點的定位,我們只需要構造對二元樹後序遍歷的雜湊對映就可以了。根據後序遍歷已知右子樹根節點同理。
根據左子樹的前序遍歷和後序遍歷結果,以及右子樹的前序遍歷和後序遍歷結果,遞回來求解左子樹和右子樹。
大致步驟為:
(1)root = new TreeNode(root_val)
(2)root->left = func(pre_left + 1, pre_left + left_num, post_left, index_mid)
(3)root->right = func(pre_left + left_num + 1, pre_right, index_mid + 1, post_right - 1)
但是這無法確定唯一二元樹,我們可以舉個例子來看一下。
假如某個二元樹的前序遍歷結果為 [1, 2, 4, 3],後序遍歷結果為 [4, 2, 3, 1]。
根據上面的方式可以得到根節點數值是1,左子樹根節點數值是2,在後序遍歷中定位後可以得到左子樹後續遍歷結果為 [4, 2] ,再對其進行遞迴操作,預設得到的是4為2的左孩子。但是實際上4為2的右孩子的話,也是滿足上面前序遍歷和後序遍歷的結果的。
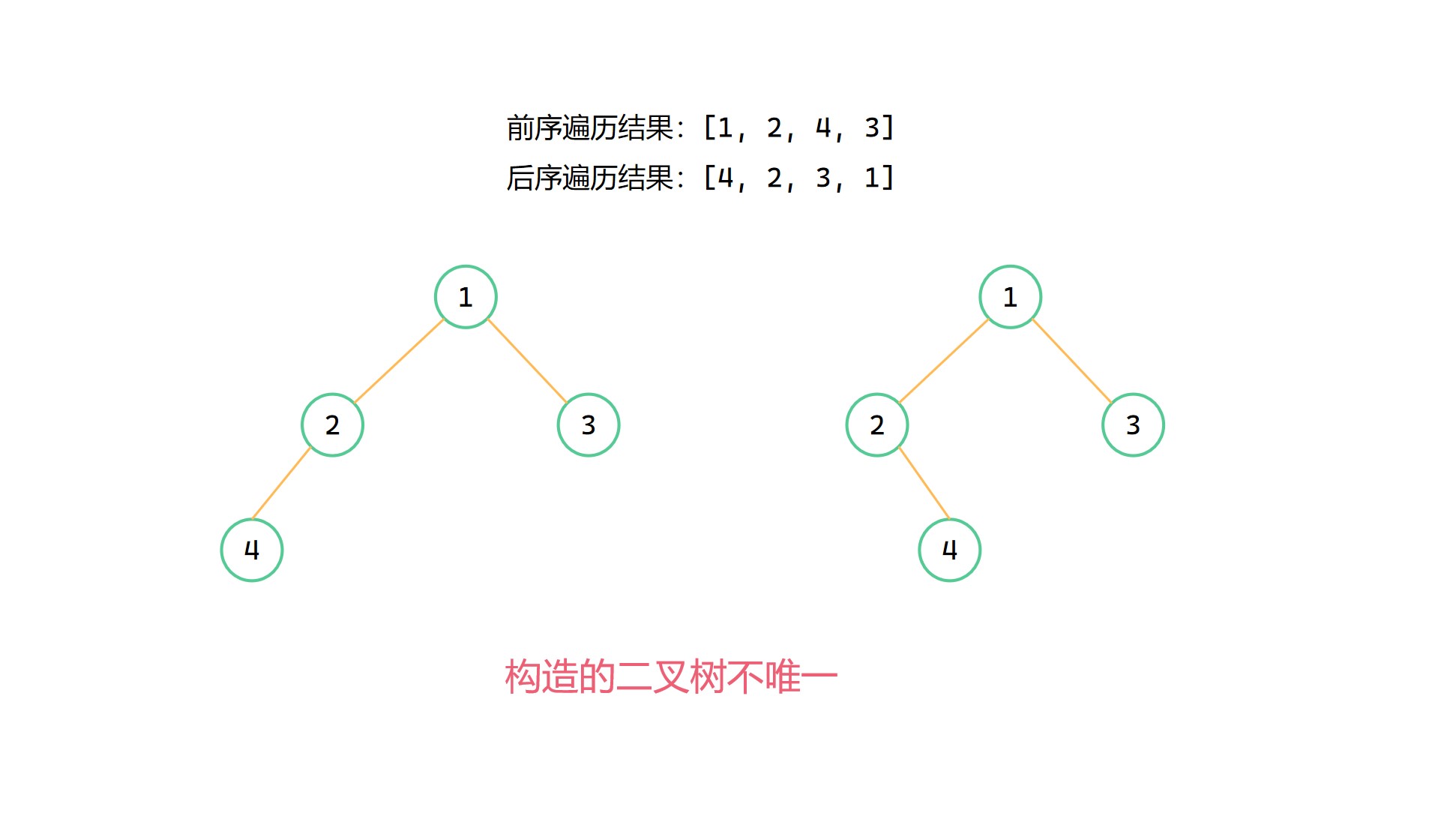
不過當二元樹不存在度數為 1 的節點時,前序遍歷 + 後序遍歷是可以確定唯一的二元樹的。
前序 + 後序構造二元樹圖解
(1)
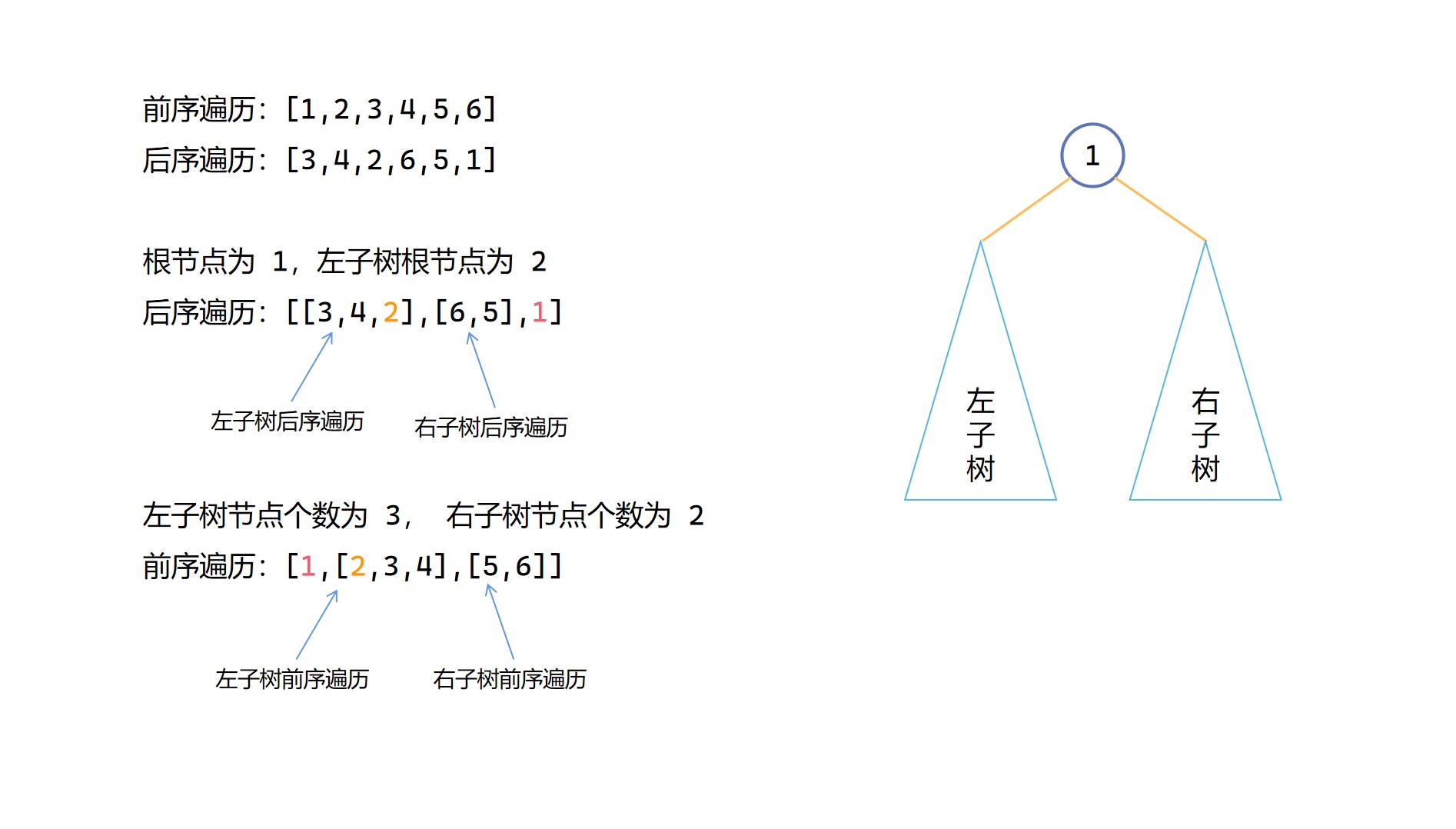
(2)
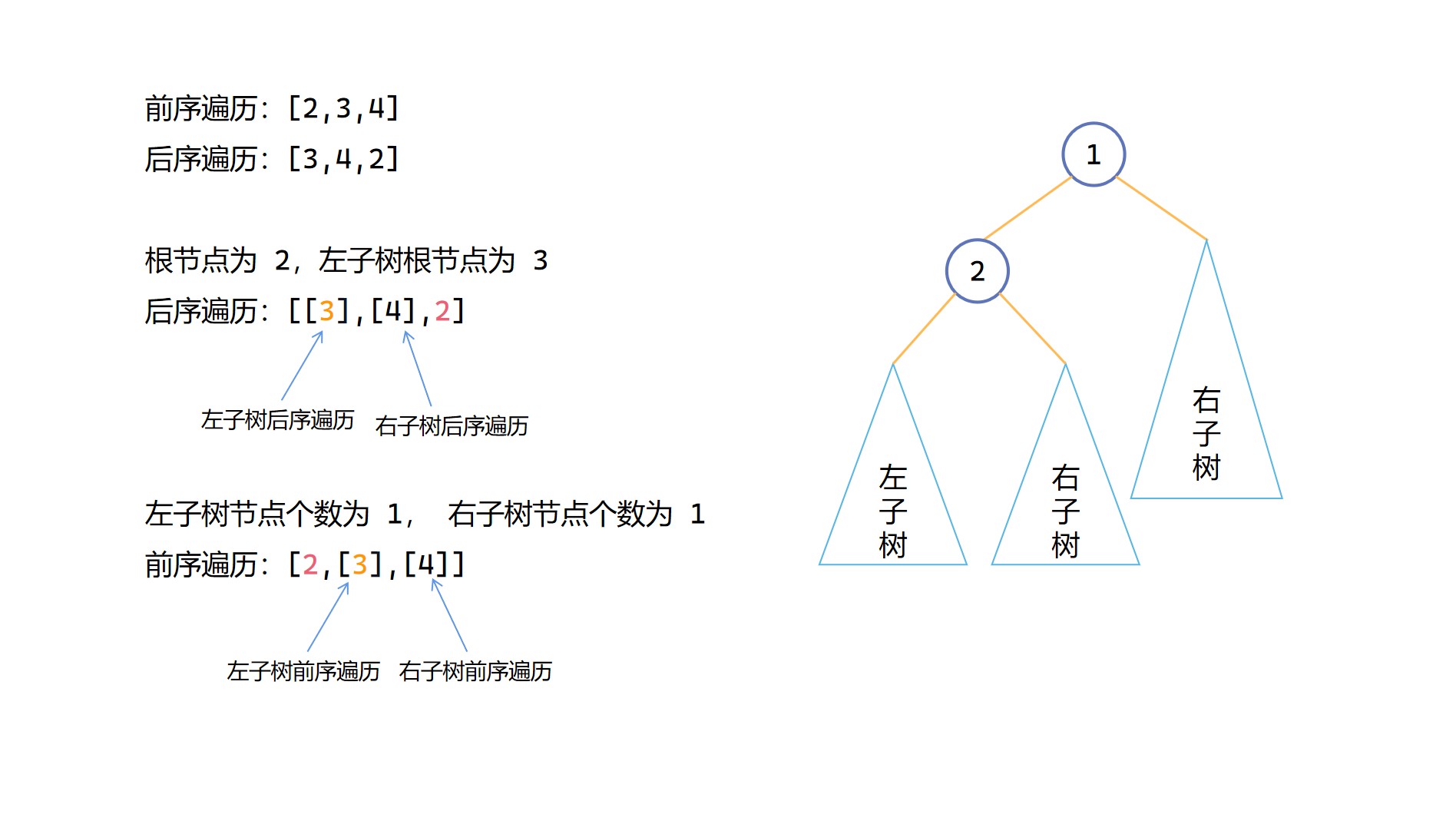
(3)
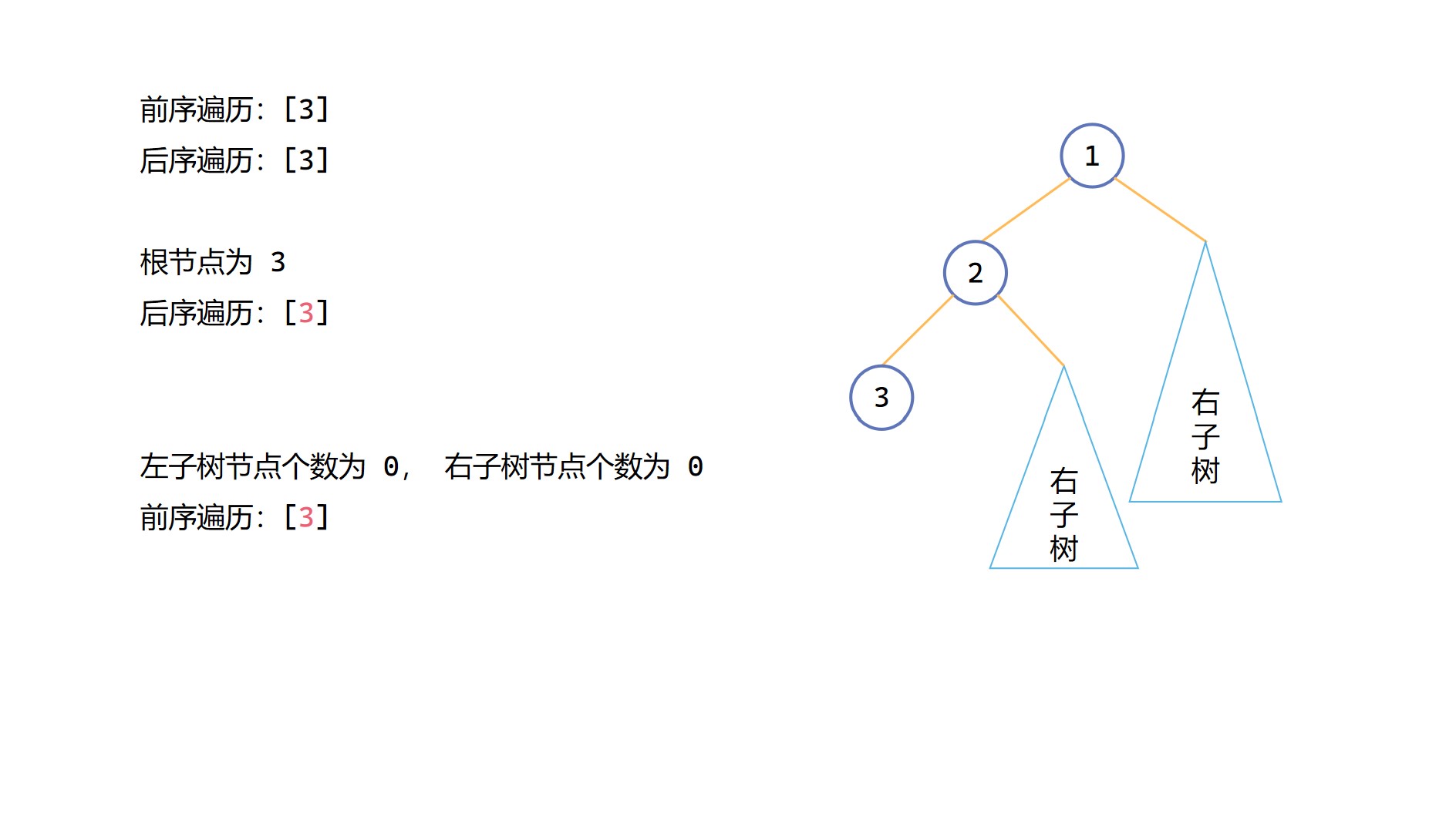
(4)
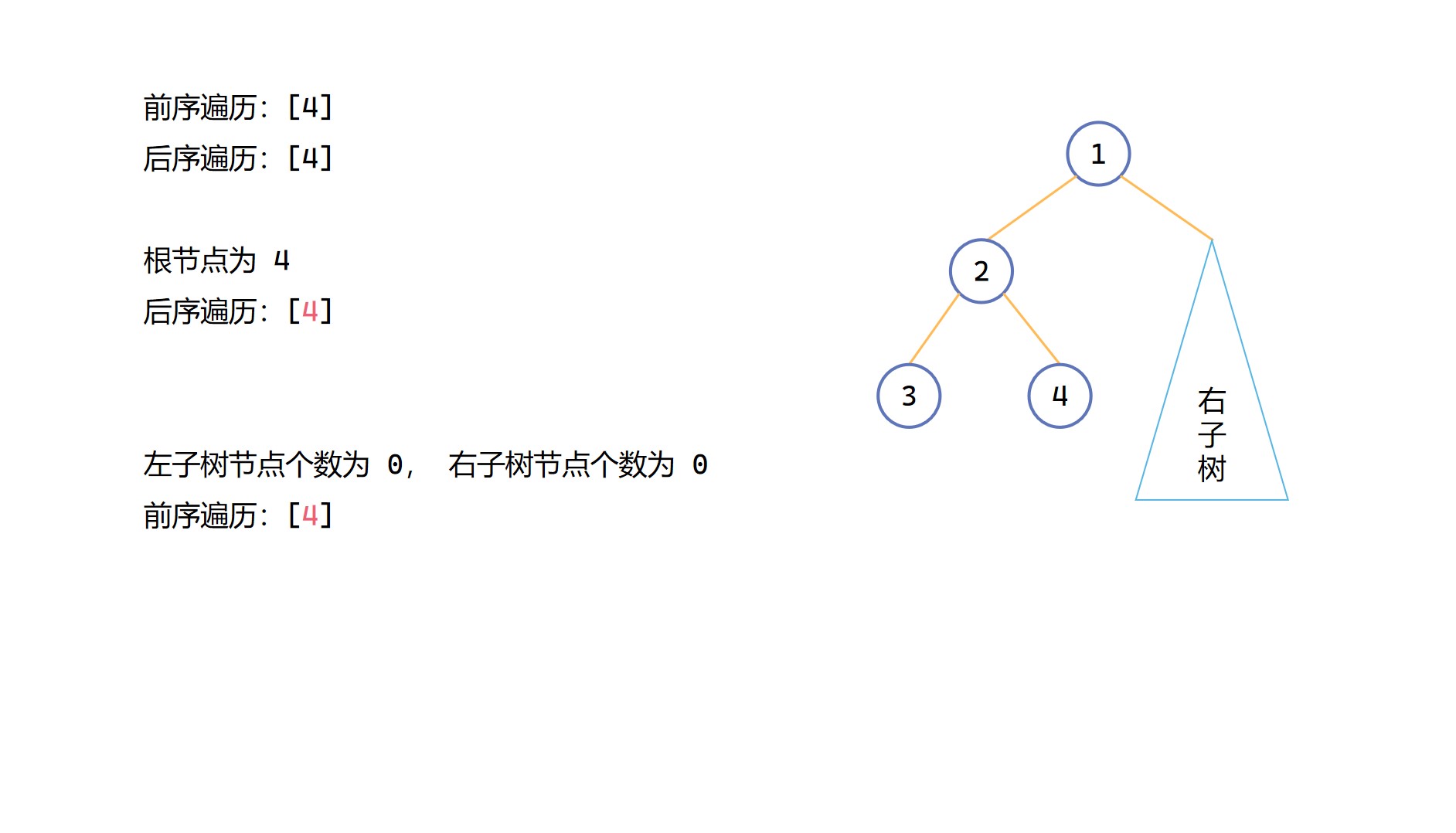
(5)
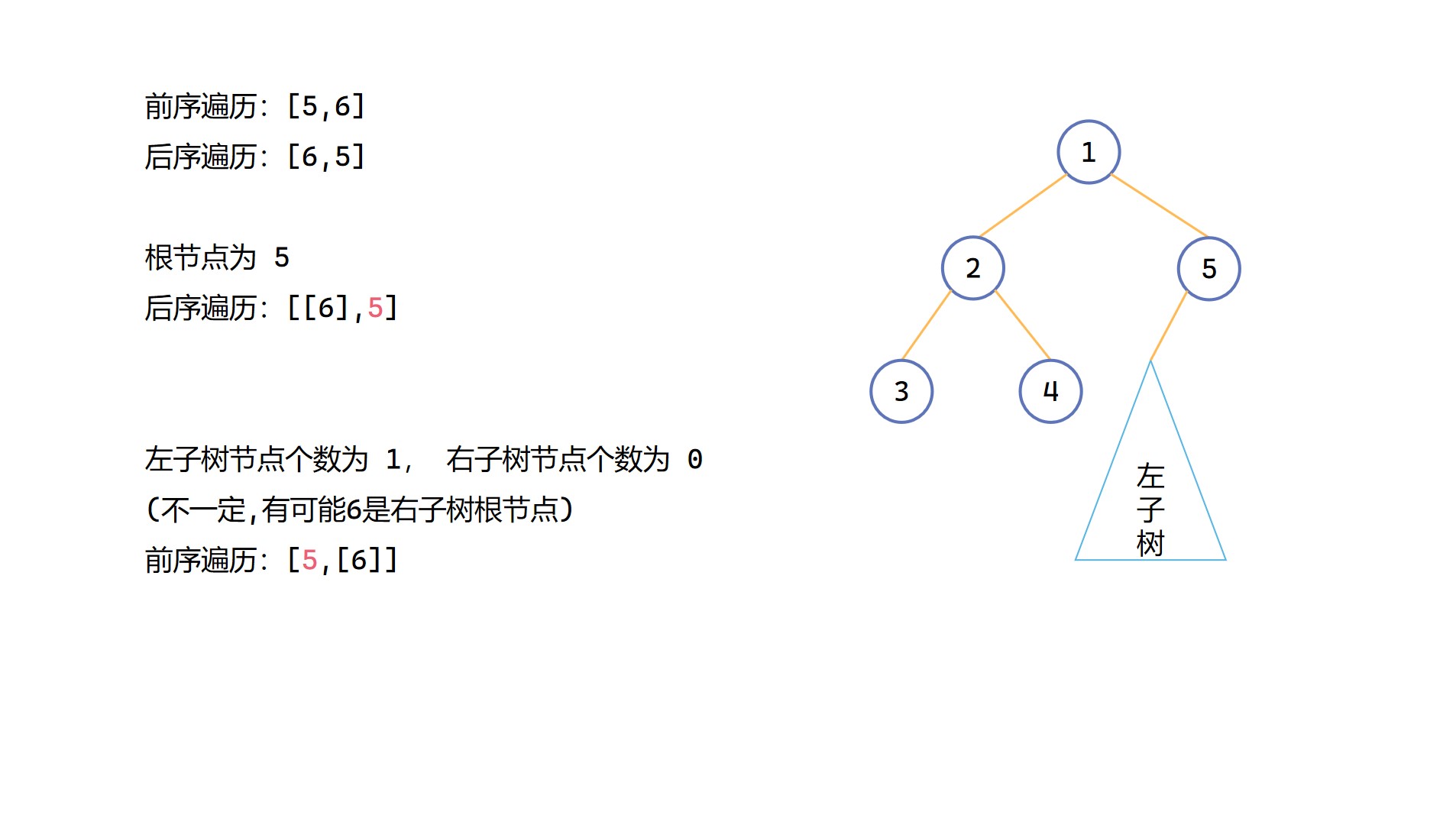
(6)
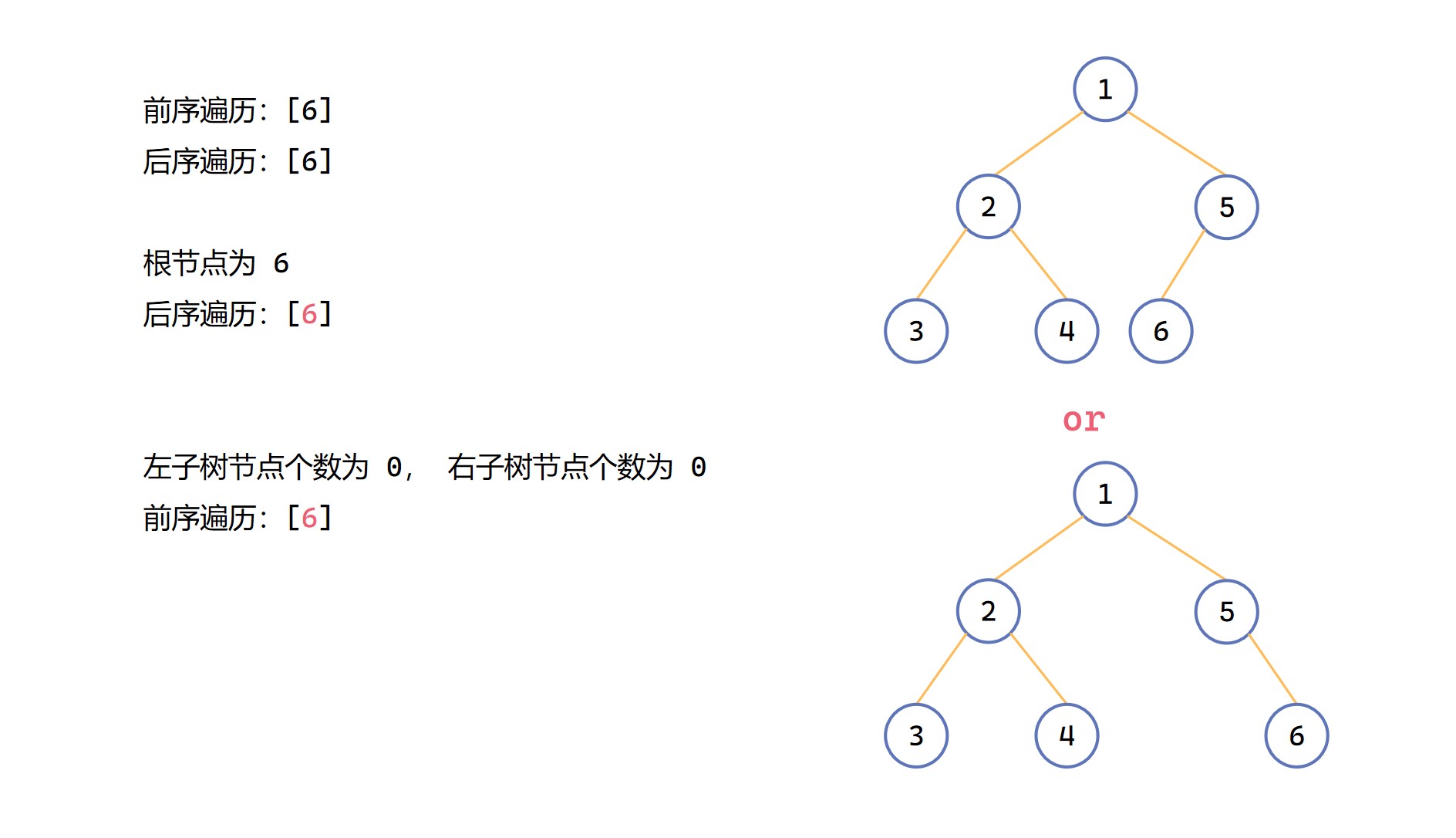
前序 + 後序構造二元樹程式碼
在leetcode上有相關題目,程式碼也是此題目對應的解答。根據前序和後序遍歷構造二元樹
class Solution {
unordered_map<int, int> hash;
public:
TreeNode* build(vector<int>& pre, vector<int>& post, int pre_left, int pre_right, int post_left, int post_right){
if(pre_left > pre_right || post_left > post_right) return NULL;
if(pre_left == pre_right) return new TreeNode(pre[pre_left]);
int root_val = pre[pre_left], left_root = pre[pre_left + 1];
//根節點 左子樹根節點
int index_mid = hash[left_root];
int left_num = index_mid - post_left + 1;
TreeNode *root = new TreeNode(root_val);
root->left = build(pre, post, pre_left + 1, pre_left + left_num, post_left, index_mid);
root->right = build(pre, post, pre_left + left_num + 1, pre_right, index_mid + 1, post_right - 1);
return root;
}
TreeNode* constructFromPrePost(vector<int>& preorder, vector<int>& postorder) {
int n = preorder.size();
for(int i = 0; i < n; i++) hash[postorder[i]] = i;
return build(preorder, postorder, 0, n - 1, 0, n - 1);
}
};
一切都是命運石之門的選擇,本文章來源於部落格園,作者:Amαdeus,出處:https://www.cnblogs.com/MAKISE004/p/17080153.html,未經允許嚴禁轉載