委派模式——從SLF4J說起
作者:vivo 網際網路伺服器團隊- Xiong yangxin
將某個通用解決方案包裝成成熟的工具包,是每一個技術建設工作者必須思考且必須解決的問題。本文從業內流行的既有工具包入手,解析實現思路,沉澱一般方法。為技術建設的初學者提供一些實踐思路的參考。尤其是文中提倡的「去中心化」的共同作業模式,和「關鍵鏈路+開發介面」的開發模式,具有一定的實際落地意義。當然本文在行文中,不可避免存在一定主觀偏見性,讀者可酌情閱讀。
一、前言
熟悉JAVA伺服器開發的同學應該都使用過紀錄檔模組,並且大概率使用過"log4j-over-slf4j"和「slf4j-log4j」這兩個包。那麼這兩個包的區別是什麼?為什麼會互相參照包含呢?這篇文章會解釋下這幾個概念的區別。
首先說一下SLF4J。
二、從SLF4J開始
SLF4J全稱"Simple Logging Facade for Java (SLF4J) ", 它誕生之初的目的,是為了針對不同的log解決方案,提供一套統一的介面適配標準,從而讓業務程式碼無須關心使用到的第三方模組都使用了哪些log方案。
舉個例子, Apache Dubbo和RabbitMQ使用到的紀錄檔模組便不相同。從某種意義上而言,SLF4J只是一個facade,類似於當年的ODBC(針對不同的資料庫廠商而制定的統一介面標準, 下文會涉及到)。而這個facade對應的包名,是 「slf4j-api-xxx.xxx.xxx.jar」。所以,當你應用了"slf4j-api-xxx.jar"的包時,其實只是引入了一個紀錄檔介面標準,而並沒有引入紀錄檔具體實現。
2.1、業內實現
SLF4J標準在應用層的核心類,就是兩個: org.slf4j.Logger 和 org.slf4j.LoggerFactory。其中,自版本1.6.0後,如果並沒有具體的實現,slf4j-api會預設提供一個啥也不幹的Logger實現(org.slf4j.helpers.NOPLogger)。
在當前(本稿件於2022-03-01擬製)的市面上,既有的實現SLF4J的方案有以下幾種:
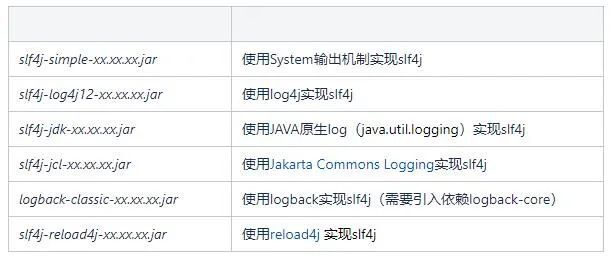
整體層次如下圖:
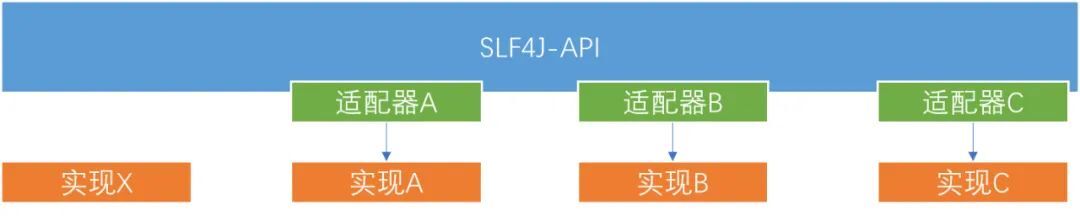
綜上而言:以SLF4J-開頭的jar包,一般指的是採用某種第三方框架實現的slf4j解決方案。
2.2 工作機制
那麼整個SLF4J的工作機制是如何運作的呢,換句話說,系統是如何知道應該使用哪個實現方案的呢?
對於那種不需要介面卡的原生實現方式,直接引入對應的包即可。
對於那種需要介面卡的委託式實現方式,則需要通過另外的一個渠道來告知SLF4J應該使用哪個實現類: SPI機制。
舉個例子,我們看一下slf4j-log4j的包結構:
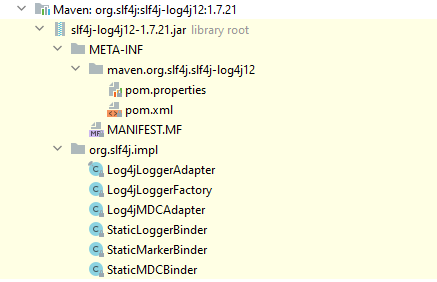
我們先看pom檔案,就包含兩個依賴:
<dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> </dependency>
slf4j-log4j同時引入了slf4j-api和log4j。那麼slf4j-log4j本身的作用不言而喻:使用LOG4j的功能,實現SLF4J的介面標準。
整體的介面/類關係路徑如下圖:
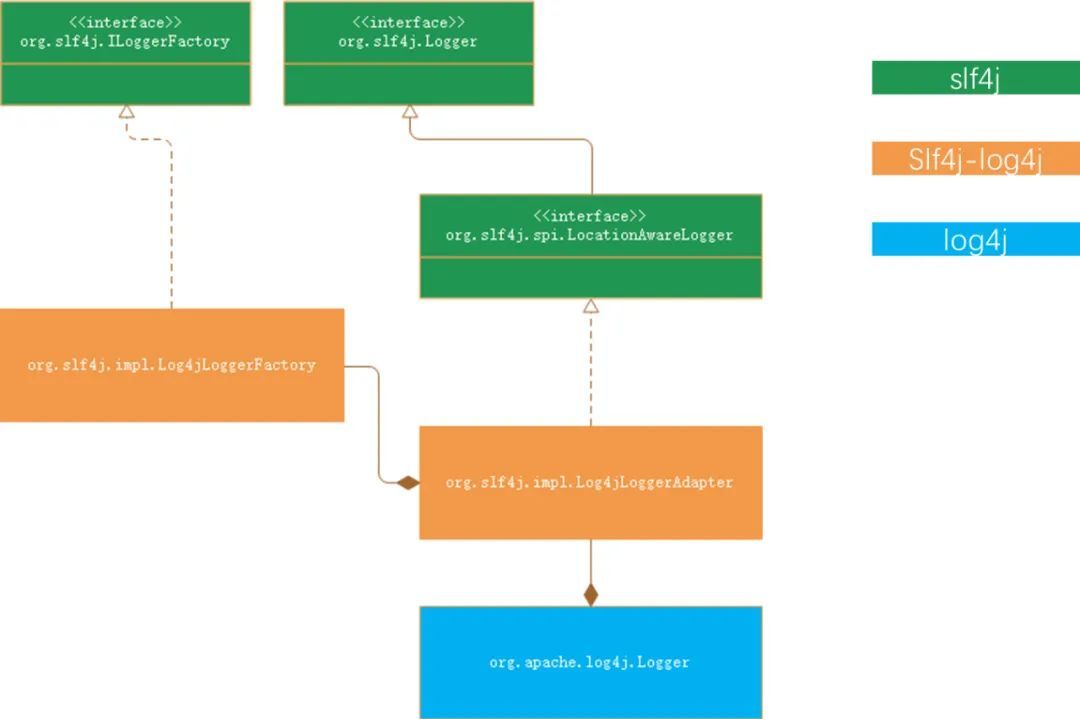
但是這仍然沒有解決本章節開始提出的問題(程式怎麼知道應該用哪個Logger)。
可以從原始碼入手:(slf4j/slf4j-log4j12 at master · qos-ch/slf4j · GitHub),我們看到了以下關鍵的檔案:

也就是說:slf4j-log4j使用了java的SPI機制告知JVM在執行時呼叫具體哪一個實現類。由於SPI機制暫不屬於本文章討論範圍,讀者可以去官網獲取資訊。
讀者可以去GitHub - qos-ch/slf4j: Simple Logging Facade for Java看其他的實現方式的介面卡是如何工作的。
那麼本章開始的問題答案便是:
-
SLF4J制定一套紀錄檔列印流程,然後把核心類抽象出介面給外部去實現;
-
介面卡使用第三方紀錄檔元件實現了這些核心類介面,並採用SPI機制,讓JAVA執行時意識到核心介面的具體實現類。
而上述兩點,構成了本文接下來要講述的知識點:委派模式。
三、委派模式
從上文中,我們從SLF4J的案例,引出了"委派模式"這個概念,下面我們就重點討論委派模式(delegation)。
接下來我們按照認知流程,依次從三個問題,解釋委派模式:
-
為什麼使用委派模式
-
什麼是委派模式
-
如何使用委派模式
然後會在下一章,用業內的典型案例,分析委派模式的使用情況。
3.1 為什麼採用委派模式?
我們回到SLF4J。為什麼它會用委派模式呢?因為紀錄檔列印功能存在各種不同的實現方式。對於應用開發者而言,最好需要一個標準的列印流程,其他第三方元件可以在某些地方有些不同,但是核心流程是最好不要變。對於標準制定者 而言,他無法控制每一個第三方元件的所有細節,所以只能暴露出有限的自客製化能力。
而我們放大到軟體領域,或者在網際網路開發領域,不同的開發者的共同作業模式,主要靠jar包應用:第三方開發一個工具包,放在中心倉庫中(maven, gradle), 使用者從其他資訊渠道(csdn, stackoverflow等等)根據問題定位到這個jar包,然後在程式碼工程中參照。理論上,如果這個第三方jar包很穩定(例如c3p0),那麼該jar包的維護者就很少甚至幾乎不會和使用者建立聯絡。如果某些中介軟體開發者覺得不滿足自己公司/部門的需求,會根據該jar包再做一次自定義封裝。
縱觀上述整個過程,不難發現兩點:
-
工具包開發者和使用者沒有建立穩定的協同渠道
-
工具包開發者對自己成品的發展掌控很薄弱
那麼如果有人想要建立一套標準呢?比如log標準,比如資料庫連線標準,那麼只能有幾個大公司聯盟,或者著名的開發團隊聯盟,制定一個標準,並實現其中核心鏈路部分。至於為什麼不實現全部鏈路,原因也很簡單:軟體領域的協同本身就是弱中心化的 ,否則你不帶別人玩,別人也不會採用你的標準(參考當年IBM推廣的COBOL)。
綜上而言:委派模式是基於當前軟體領域的共同作業特性,採取的較好的軟體結構模式。
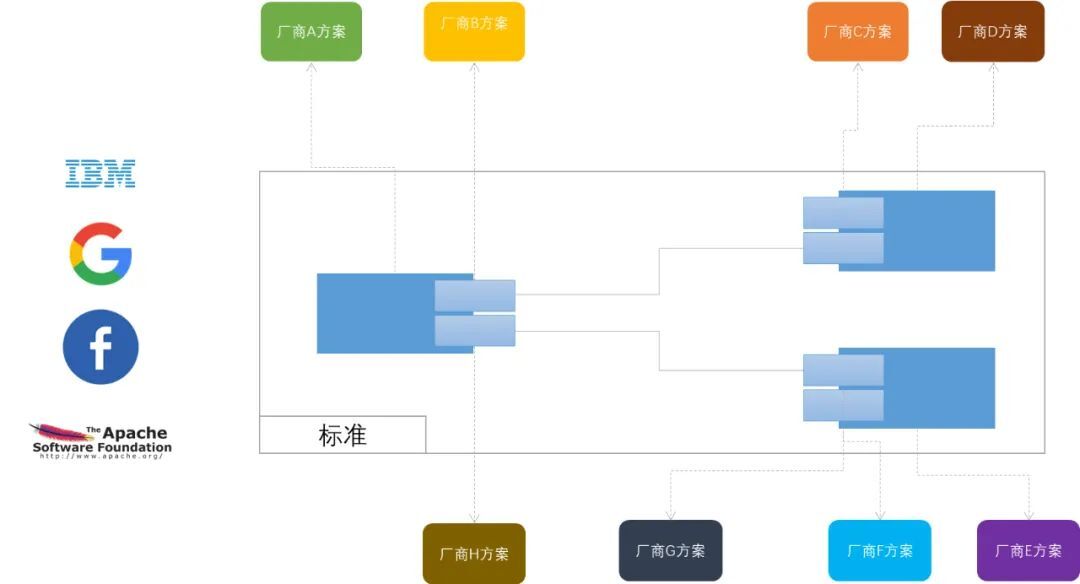
所以啥時候採用委派模式呢?
-
存在設定某個標準並由中心化團隊負責的必要
-
使用者有強烈的需求自客製化某些區域性實現
這裡就舉一個硬體領域的反例:快充標準。在2018年甚至更早,消費者就需要一個快充的功能。但是快充需要客製化很多硬體才能實現,所以此時就具備了條件一,但是當時並沒有任何一個團隊或者公司能夠掌控安卓手機硬體整個生態,無法共同推出一箇中心化團隊去負責,從而導致各個手機廠商的快充功能百花齊放:A公司的快充線,無法給B公司的手機快充。
3.2 什麼是委派模式?
基於上述的討論,委派模式的核心構成就顯而易見了:核心鏈路, 開放介面。
核心鏈路指的是:為了達到某個目的,特定的一組構件,按照特定的順序,特定的協同標準,共同執行計算的邏輯。
開放介面指的是:給定特定的輸入和輸出,將實現細節交給外部的功能介面。
舉個比較現實的例子:傳統汽車。
幾乎每一輛傳統汽車,都按照三大件進行整合和共同作業:發動機,變速器,底盤。發動機做功, 通過變速器將動力傳輸給底盤(這麼說並不標準,甚至在汽車工業的工人眼中,這種描述幾乎是謬論,但是大致是這樣)。也基於此,發動機的介面, 變速箱的介面,底盤的介面都已經固定,剩下的就各個廠商去實現了:三菱的發動機, 日產的發動機,愛信的變速箱,採埃孚的變速箱,倫福德的底盤,天合的底盤等等。甚至連輪胎的介面都制定好了:大陸的輪胎,普利司通的輪胎,固特異的輪胎。
不同的汽車廠商,選擇不同公司的元件,整合出某個汽車型號。當然也有公司自己去實現某個標準:比如大眾自己生產EA888發動機,PSA自己生產並調教的底盤並引以為傲。
如果大家覺得不夠熟悉,那麼可以舉一個tomcat的例子。
經歷過00年代的軟體開發者,應該知道當時開發一個web應用是多麼的困難:如何監聽socket, 如何編碼解碼,如何處理並行,如何管理程序等等。但是有一點是共通的:每一個Web開發者都想要一個框架去管理整個http服務的協定層和核心層。於是出現了JBoss, WebSphere, Tomcat(笑到了最後)。
這些產品,都是指定了核心的鏈路:監聽socket → 讀封包→ 封裝成http報文 → 派發給處理池子 → 處理池的執行緒呼叫處理邏輯去處理 → 編碼返回的報文 → 編組成tcp包 → 呼叫核心函數→ 發出資料。
基於這個核心鏈路,制定標準:業務處理邏輯的輸入是什麼,輸出是什麼,如何讓web框架識別到業務處理模組。
Tomcat的方案就是web.xml。開發者只要遵從web.xml標準去實現servlet即可。也就是說,在整個http伺服器鏈路中,Tomcat將特定的幾個流程處理構件(listener, filter, interceptor, servlet)委派給了業務開發者去實現。
3.3 如何使用委派模式
在使用委派模式之前,先根據上文的模式匹配條件進行自我判斷:
-
存在設定某個標準並由中心化團隊負責的必要
-
使用者有強烈的需求自客製化某些區域性實現
如果並不符合條件一,那麼就不需要考慮使用委派模式;如果符合條件一但是不符合條件二,那就先預留好介面,採用依賴注入的方式,自己開發介面實現類並注入到主流程中。這個做法在很多的第三方依賴包中能夠看到,比如spring的BeanFactory, BeanAware等等,還有各個公司開發SSO時預留的一些hook和filter等等。
在確定使用委派模式後,第一件事就是「確定核心鏈路」,這一步最難,因為往往使用者都有某種期望,但是讓他們具體描述出來,卻又經常不夠精準,甚至有時候後主次顛倒。筆者的建議是:直接讓他們說出原始的需求/痛點,然後自己嘗試給出方案,再對比他們的方案,進行溝通,並逐漸將兩個方案統一。統一的過程也就是不斷試探和確定的過程。
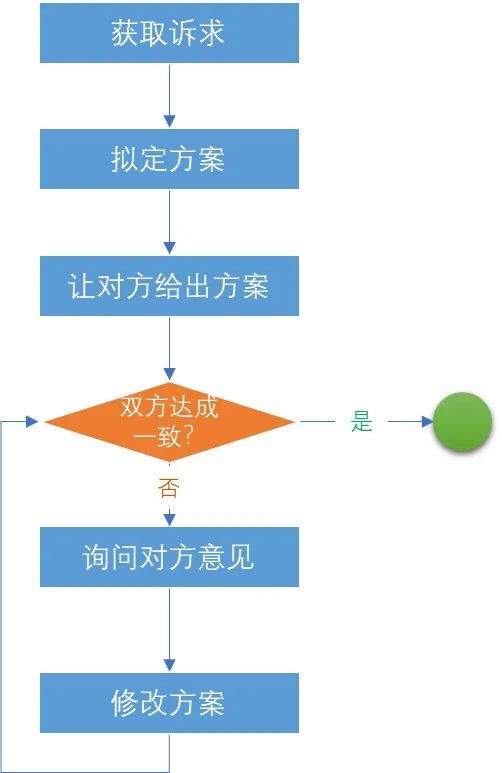
上述的過程是筆者自己的經驗,僅當借鑑。
在確定核心流程後,再將流程中的一些需要自客製化的功能抽象成介面暴露出去。介面的定義中,儘量減少對整個流程中其他類的呼叫依賴。
所以整體的流程分為三步:確認使用該模式;提取核心流程;抽象開放介面。
至於是採用SPI機制還是像TOMCAT一樣使用XML設定識別,需要看具體情況,在此不做涉及。
四、 業內案例
4.1 JDBC
JDBC的誕生很大程度上是借鑑了ODBC的思想,為JAVA設計了專用的資料庫連線規範JDBC(JAVA Database Connectivity)。JDBC期望的目標是讓Java開發人員在編寫資料庫應用程式時,可以有統一的介面,無須依賴特定資料庫API,達到「 一次開發,適用所有資料庫」。雖然實際開發中,經常會因為使用了資料庫特定的語法、資料型別或函數等而無法達到目標,但JDBC的標準還是大大簡化了開發工作。
整體而言,JDBC的接入結構大致如下圖:
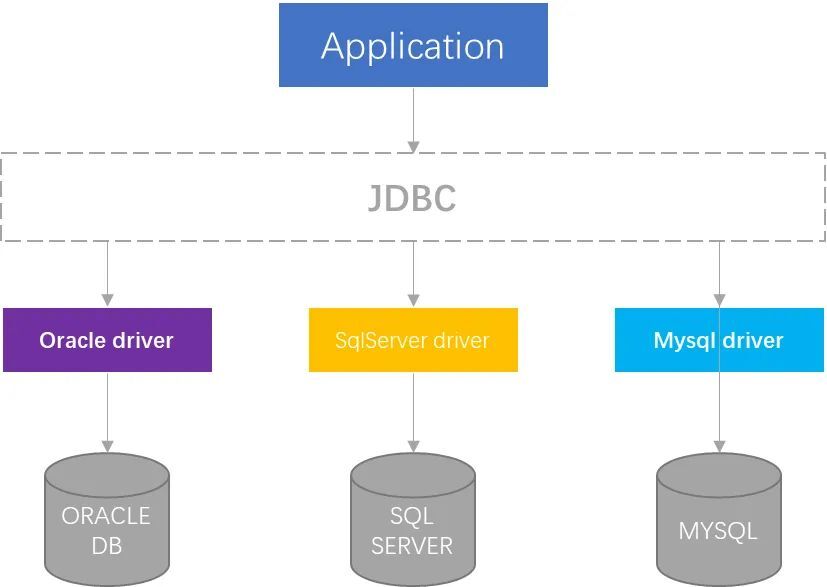
但是實際上,在JDBC誕生之初,市面上並未有很多的廠家響應SUN公司(那時候SUN還並未被ORACLE收購), 於是SUN公司就使用了本文介紹的橋接模式,如下圖:
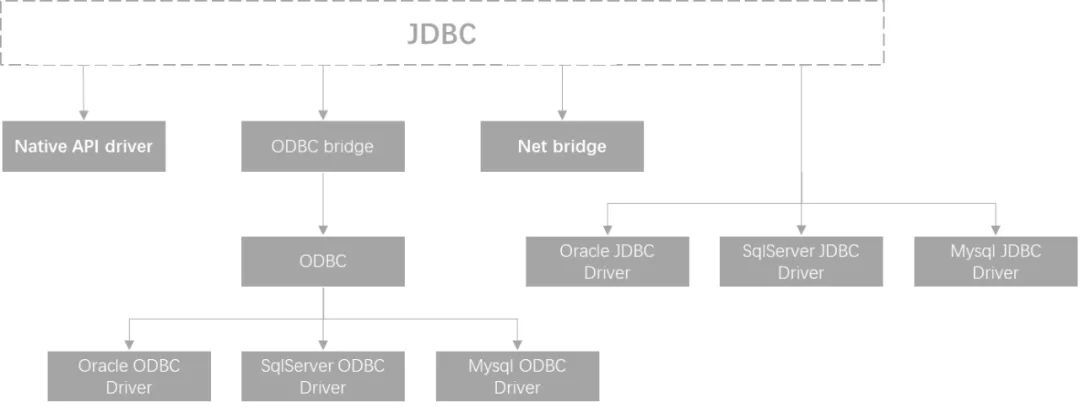
也是說,形式上,出現了初步委派的結構形式。
下文會只針對單次委託的JDBC層級做分析。
按照上文所言,每一個委派結構,必然存在兩個要素:核心路徑和開放介面。我們從這兩個維度開始分析JDBC。
JDBC的核心路徑分為六步, 包含委託機制需要的兩步(引入包,宣告委託承接人),總共八步,如下:
-
引入JDBC實現包
-
註冊JDBC Driver
-
和資料庫建立連線
-
發起transaction(必要的話),建立statement
-
執行statement並讀取返回,塞入ResultSet
-
處理ResultSet
-
關閉ResultSet, 關閉Statement
-
關閉Connection
縱觀整個過程,核心的參與者為:Driver, Connection, Statement, ResultSet。transaction實際上是基於Connection的三個方法(setAutoCommit, commit, rollback)包裝而成的對談層,理論上不屬於標準層。
以mysql-connector-java為例,具體實現JDBC介面的情況如下:

通過Java自帶的overriding機制,只要使用com.mysql.jdbc.Driver,那麼其他元件的實現類便直接被應用實現。具體細節不做討論。那麼mysql-connector-java是如何告知JVM應該使用com.mysql.jdbc.Driver呢?
兩種模式
-
明文模式——在業務程式碼中明文使用Class.forName("com.mysql.jdbc.Driver")
-
SPA機制
其實上述的兩種方法,核心就是初始化com.mysql.jdbc.Driver,執行以下類初始化邏輯。
try {
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
也就是說,JDBC通過DriveManager維護委託承接者的資訊。讀者如果有興趣檢視DriverManager的原始碼,會發現JDBC的另一種實現類發現方式。不過考慮行文長度,筆者在此不表。
4.2 Apach Dubbo
Dubbo的核心路徑大致如下(不考慮服務管理那一套):
consumer呼叫 → 引數序列化 → 網路請求 → 接收請求 → 引數反序列化 → provider計算並返回 → 結果序列化 → 網路返回 → consumer方接收 → 結果反序列化
(斜體代表consumer方的dubbo職責,下劃線代表provider方的dubbo職責)
Dubbo的可客製化介面有很多,整體大量採用了「類SPI」機制,為整個RPC流程的很多環節,提供了自客製化的注入機制。相較於傳統的Java SPI, Dubbo SPI在封裝性和實現類發現性上做了很多的擴充套件和自客製化。
Dubbo SPI整體實現機制及工作機制不在本文範圍,但為了行文方便,在此做一些必要說明。整體的Dubbo SPI機制可以分為三部分:
-
@SPI註解——宣告當前介面類為可延伸介面。
-
@Adaptive註解——宣告當前介面類(或者當前介面類的當前方法)能根據特定條件(註解中的value),動態呼叫具體實現類實現方法。
-
@Activate註解——宣告當前類/方法實現了某個可延伸介面(或者可延伸介面的某個具體方法的實現),並註明被啟用的條件,以及所有的被啟用實現類中的排序資訊。
我們以Dubbo-Auth(dubbo/dubbo-plugin/dubbo-auth at 3.0 · apache/dubbo · GitHub)為例,從核心路徑和開放介面兩個維度進行分析。
Dubbo-Auth的實現邏輯,是基於Dubbo-filter的原理,也就是說:Dubbo-Auth本身就是Dubbo整體流程中的某一個環節的委派實現方。
Dubbo-Auth的核心入口(也就是核心路徑的起始點), 是ProviderAuthFilter,
是org.apache.dubbo.auth.filter的具體實現, 也就是說:
-
org.apache.dubbo.auth.filter是dubbo核心鏈路中對外暴露的一個開發介面(類定義上標註了@SPI)。
-
ProviderAuthFilter是實現了dubbo核心鏈路中對外暴露的開發介面Filter(ProviderAuthFilter實現類定義上標註了@Activate)。
ProviderAuthFilter的核心路徑比較簡單:獲取Authenticator物件,使用Authenticator物件進行auth驗證。
具體程式碼如下:
@Activate(group = CommonConstants.PROVIDER, order = -10000)
public class ProviderAuthFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
URL url = invoker.getUrl();
boolean shouldAuth = url.getParameter(Constants.SERVICE_AUTH, false);
if (shouldAuth) {
Authenticator authenticator = ExtensionLoader.getExtensionLoader(Authenticator.class)
.getExtension(url.getParameter(Constants.AUTHENTICATOR, Constants.DEFAULT_AUTHENTICATOR));
try {
authenticator.authenticate(invocation, url);
} catch (Exception e) {
return AsyncRpcResult.newDefaultAsyncResult(e, invocation);
}
}
return invoker.invoke(invocation);
}
}
注意,上文程式碼中url.getParameter(Constants.AUTHENTICATOR, Constants.DEFAULT_AUTHENTICATOR)是dubbo spi 的Adaptive機制中的選擇條件,讀者可以深究,本文在此略過。
由於核心路徑包含了Authenticator ,那麼Authenticator 自然就很可能是對外暴露的開發介面了。也就是說,Authenticator 的宣告類中,必然是註解了@SPI。
@SPI("accessKey")
public interface Authenticator {
/**
* give a sign to request
*
* @param invocation
* @param url
*/
void sign(Invocation invocation, URL url);
/**
* verify the signature of the request is valid or not
* @param invocation
* @param url
* @throws RpcAuthenticationException when failed to authenticate current invocation
*/
void authenticate(Invocation invocation, URL url) throws RpcAuthenticationException;
}
上述程式碼證明了筆者的猜想。
在Dubbo-Auth中,提供了一個預設的Authenticator :AccessKeyAuthenticator。在這個實現類中,核心路徑被再次具體化:
-
獲取accessKeyPai;
-
使用accessKeyPair, 計算簽名;
-
對比請求中的簽名和計算的簽名是否相同。
在此核心路徑中,由於引入了accessKeyPair概念,於是就引出一個環節:如何獲取accessKeyPair, 針對此, dubbo-auth又定義了一個開放介面:AccessKeyStorage。
@SPI
public interface AccessKeyStorage {
/**
* get AccessKeyPair of this request
*
* @param url
* @param invocation
* @return
*/
AccessKeyPair getAccessKey(URL url, Invocation invocation);
}
4.3 LOG4J
最後一個案例,我們又回到了紀錄檔元件,而之所以介紹LOG4J, 是由於它使用了非常規的「反向委派」機制。
LOG4J借鑑了SLF4J的思想(或者LOG4J在前?SLF4J借鑑的LOG4J ?), 也採用了 介面標準+ 介面卡+第三方方案的思路來實現委派。
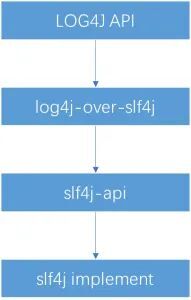
那麼顯然,這裡就有個問題:SLF4J確認了自己的核心路徑,然後暴露出待實現介面,SLF4J-LOG4J在嘗試實現SLF4J的待實現介面時,又使用了委託機制,把相關的路徑細節外包了出去,從而形成了一個環。

所以說,如果我同時引入了"log4j-over-slf4j"和"slf4j-log4j",會造成stackoverflow。
這個問題非常典型, google一下就可能看到很多的案例,比如Analysis of stack overflow exception of log4j-over-slf4j and slf4j-log4j12 coexistence - actorsfit等等, 官方也給出了警告(SLF4J Error Codes)。
由於此文的關注點在委派模式,所以關於此問題並不詳細討論。而此案例的重點,是說明了一件事:委派模式的缺點,就是對於開放介面的實現邏輯不可控。如果第三方實現存在重大機制性隱患,會導致整體核心流程出現問題。
五、總結
綜上所述,
委派模式的使用場景是:
-
存在設定某個標準並由中心化團隊負責的必要;
-
使用者有強烈的需求自客製化某些區域性實現。
委派模式的核心點: 核心路徑, 開放介面。
委派模式的隱藏機制:實現方式的註冊/發現。
參考資料: