NodeJS 實戰系列:如何設計 try catch
本文將通過一個 NodeJS 程式裡無效的錯誤捕獲範例,來講解錯誤捕獲裡常見的陷阱。錯誤捕獲不是憑感覺新增 try catch 語句,它的首要目的是提供有效的錯誤排查資訊,只有精心設計的錯誤捕獲才有可能完成這個使命。針對哪些方面去精心設計就是本篇文章裡想討論的內容
實戰系列來自於個人開發以及運維 site2share 網站過程中的經驗
設計陷阱,而非聽天由命
為什麼程式碼裡需要 try catch?是為了阻止 bug 的發生的?當然不是,bug 其實是程式碼的副產品,bug 的數量取決於程式碼的質量而非 try catch 的數量。
說到底 try catch 只是用來查漏補缺的工具,如果你把 try catch 只是當作萬能的膏藥在程式碼裡想貼就貼,那你可能多半貼不中真正的要害,也得不到期望的結果
在 site2share 中我需要整合 Redis 用於儲存使用者的 session 資訊,自然需要在程式碼中使用第三方類庫使用 Redis,無論是 node-redis (還是 ioredis),它們都提供事件機制用於反饋與 Redis Server 連線的當前狀態。比如我們可以監聽 error 事件:
redis.on('error', function () { });
為什麼不監聽看看呢。並且上線之後如償所願,在發現網站無法存取之後在紀錄檔中確實找到了
- 如題圖所示大量的報錯資訊
- 每一個錯誤的呼叫棧
但它們統統都僅是 node-redis 類庫內部的函數呼叫棧,我發現這些資訊對我來說毫無用處,因為它們無法向我提供最關鍵的一類資訊:上下文。所以這些資訊都只是在告訴我在存取 /api/folder/:id 時 redis 出現了報錯,然而下列這些問題的答案才更有助於我排查問題:
- 是否只在指定 id 的情況下才會發生錯誤?
- 請求 API 時使用者是否處於登入的狀態?
- 連線狀態是存在一定概率成功,還是穩定失敗?
- Azure Redis Server 的服務是否穩定?錯誤是否是由服務自身造成的
對於這些問題的答案我一無所知,更艱難的是我無法在本地開發環境中復現該錯誤。這個時候我才發現並非你收集的資訊越多,你把問題解決的概率就越大,如果你始終缺失某條關鍵資訊,再多的額外資訊也於事無補。
這又回到了我之前所說的資訊應該是雙向的,即我收集的資訊務必讓我有采取行動和回溯的能力
所以捕獲錯誤同樣需要設計。或者退一步說,即使我不太確定錯誤會在哪裡發生而需要在大範圍內對錯誤進行捕獲,也需要保證錯誤要提供有效資訊:
- 除了看到錯誤訊息,我還希望得到呼叫棧資訊
- 如果我有了呼叫棧,那麼我還希望得到具體的資料 id;
- 如果有了資料 id,那麼我還希望能夠得到 ORM 背後生成的 SQL 語句
再退一步說,如果無法得到直接有效資訊,間接的有效資訊也是可以接受的,例如你可以利用服務供應商或者基礎設施的自帶紀錄檔來協助排查問題;再不濟如果只能硬著頭皮閱讀程式碼的話,被精心設計的函數名也非常重要。
那麼如何設計好的 try catch呢?看起來你需要懂你的函數,你需要知道它可能的輸入和期待的輸出是什麼,你需要知道它在執行過程中會和哪些服務打交道,你需要知道它的風險在哪。很有意思的是,我們從函數出發,想盡可能完美地捕獲報錯,但完美的答案又在函數本身當中。
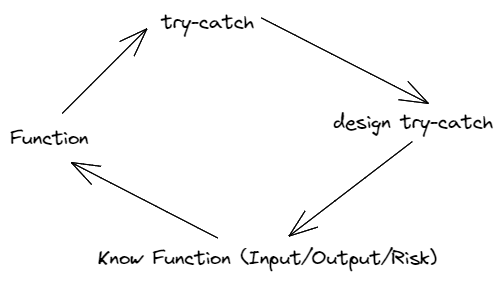
最後,如果程式在意料之外掛掉或者拋錯,順其自然好了。千萬不要想法設法當作什麼事情都沒有發生然後繼續執行下去。因為我們無法得知錯誤究竟帶來的影響是什麼,會帶來怎樣的連鎖反應。抱有僥倖心理不如就此止損——請快速失敗,快速恢復
說實話我很難找到關於 handle error 設計方面的書籍或者文章,很驚訝這塊領域內的空白(我都能找到好幾本聊依賴注入的圖書)。當你在讀技術教學比如《.NET Core in Action》或者《ASP.NET MVC 4 in Action》 時,它們只會告訴你在框架中存在這樣或者那樣的 error handling 機制,至於如何使用才是最佳實踐,並不在它們的範疇內。
"接住"錯誤
為什麼用「接住」而非「抓住」,是因為前者是被動後者是主動的,大部分情況下你都不太可能主動的、預測性的識別到某個bug。但我們不能因為如此就任由它們發生,我們需要:
- 抹去錯誤中的敏感資訊
- 讓錯誤資訊變得更加友好
- 記錄錯誤
在處理這些事物方面,我們需要集中化處理錯誤,目前絕大部分框架都支援這類操作。比如對於 .NET CORE 來說,我們可以通過在最外層新增 middleware 來解決這個問題
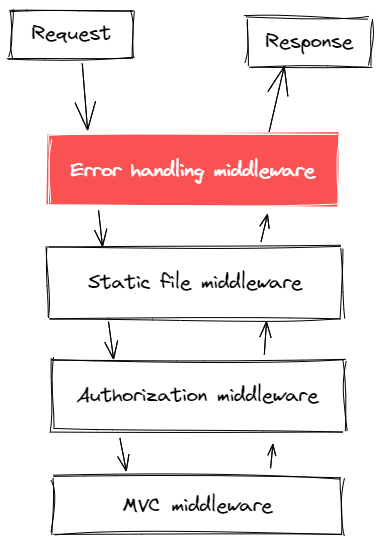
error handing middleare 只能作為程式處理錯誤的最後一道防線,對於不可知的錯誤尤其有效。然而對於一些可以前置,可以提前捕獲的錯誤來說,我們又應該如何處理呢?
我的經驗是,需要在系統內建立一套機制或者說通道,讓 exception 按照指定的方向高效的流動起來才是首要任務。舉個例子
try {
await getUserInfo()
} catch(e) {
throw new LoadUserInfoException()
}
第一個問題是,我們是否真的需要 try catch?不一定,理想情況下即使錯誤在當前程式碼塊沒有被捕獲,它發生的意外錯誤也應該掉落進最後一道防線中,然後翻譯為能夠暴露給外部的資訊,隨後程式立即中斷,快速重啟。
退一步說,即使你按照以上程式碼有意進行 catch,你要如何處理這個新 throw 出來的錯誤呢?最好的辦法是我們無需關心。LoadUserInfoException 中可以事先定義這個錯誤的狀態嗎的 message,上面所說的程式中提前建立好的機制,會自動將這個錯誤按照狀態碼和message進行翻譯,返回給使用者端。並非所有場景都需要有意遮蔽錯誤資訊,有時候將恰當的錯誤資訊返回給使用者端能夠讓使用者自主的排查問題更好。
上面涉及的自動捕獲、對錯誤進行翻譯、直達使用者端,以及你能夠想到的跨功能需求,比如收集錯誤紀錄檔,都應該是程式中的基礎設施,具體的開發人員無需關心,無需對於每一個錯誤都手動執行這一系列步驟。
正如下圖所示,無論你的 controller、service、SDK 之間的呼叫層次如何,各個模組中被丟擲的異常都一視同仁的被處理。然而開發人員只需要關心下圖左上方的部分,至於錯誤資訊如何向右流向使用者端,則無需關心
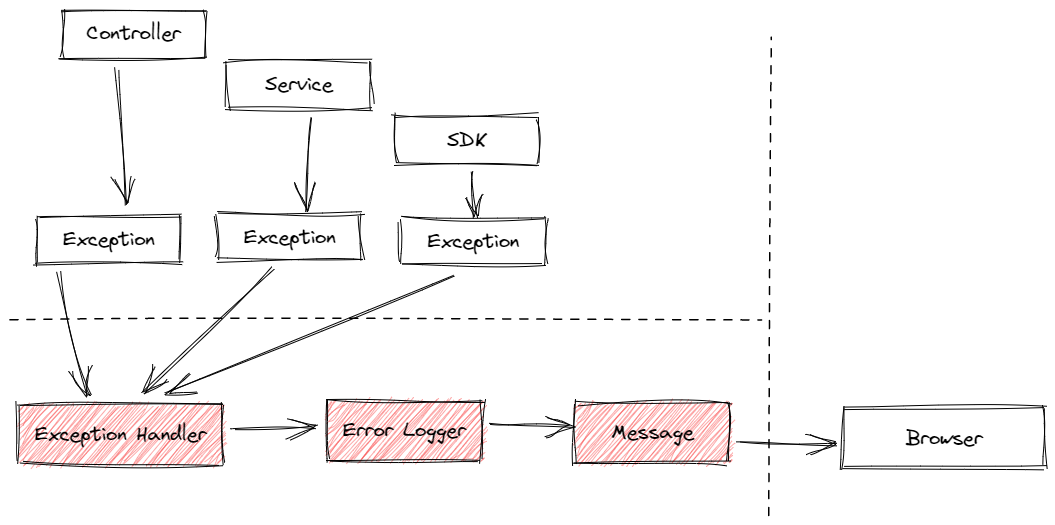
.NET Core 裡的 middleware 和 NodeJS 裡的 error handler 都能可以達到這個效果