order by 語句怎麼優化?
說明 當前演示的資料庫版本5.7
一、一個簡單使用範例
先建立一張訂單表
CREATE TABLE `order_info` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`order_no` int NOT NULL COMMENT '訂單號',
`goods_id` int NOT NULL DEFAULT '0' COMMENT '商品id',
`name` varchar(50) NOT NULL COMMENT '商品名稱',
`status` int NOT NULL DEFAULT '0' COMMENT '訂單狀態:1待支付,2成功支付,3支付失敗,4已關閉',
`pay_type` int NOT NULL DEFAULT '0' COMMENT '支付方式:1微信支付,2支付寶支付',
`price` decimal(11,2) DEFAULT NULL COMMENT '訂單金額',
`pay_time` datetime DEFAULT NULL COMMENT '支付時間',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='訂單資訊表';
同時也在表裡插了一些資料
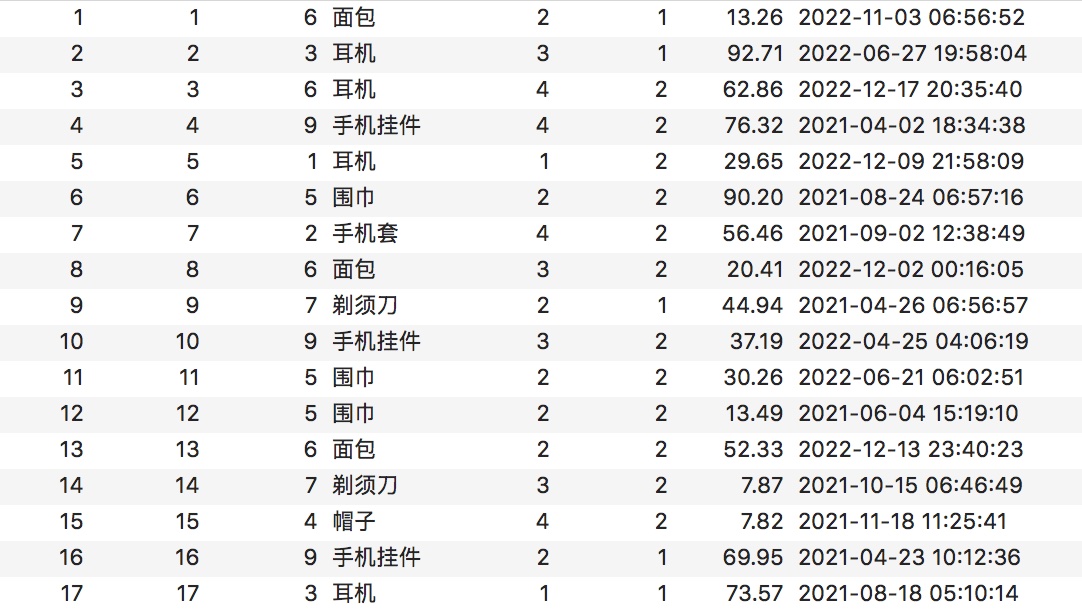
現在有一個需求: 查詢商品名稱是耳機,訂單號按照從小到大排序的前10個,查詢結果只需訂單號,商品名稱,訂單狀態。
現在我們這裡執行SQL語句
select order_no, name, status from order_info where name = '耳機' order by order_no limit 10
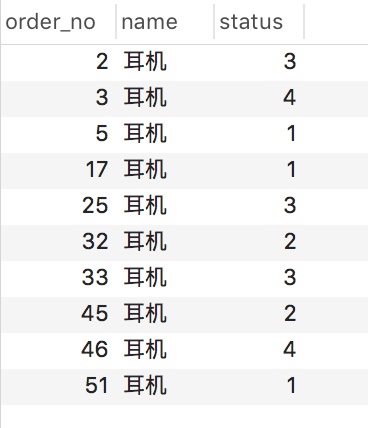
這條語句我們都會寫,但我們知道它的執行的流程是怎麼樣的嗎?
二、order by 原理分析
2.1、explain 分析
為了避免全表掃描,這裡我們在name加上一個普通索引
alter table order_info add index idx_name(name)
我們再看下執行計劃
explain select order_no, name, status from order_info where name = '耳機' order by order_no limit 10

-
Extra 這個欄位的
Using index condition表示該查詢走了索引,但需要回表查詢 -
Extra 這個欄位的
Using filesort表示使用了內部排序
一般出現Using filesort 也是我們需要考慮優化的點。
Using filesort: 表示沒有走索引排序,而是走了內部排序,這時MySQL會給每個執行緒分配一塊記憶體用於排序,稱為sort_buffer。
2.2 全欄位排序
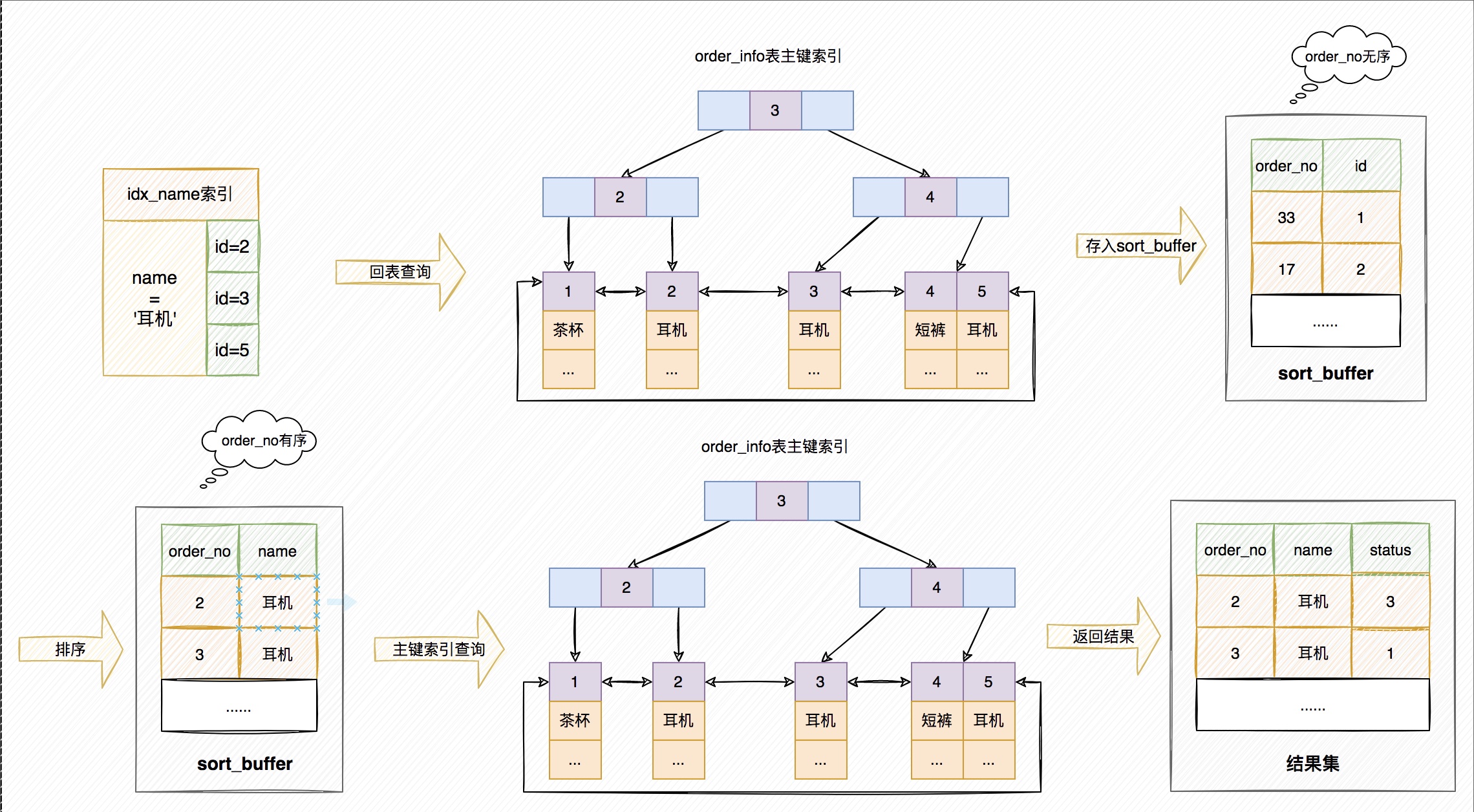
為了說明上面這條SQL查詢語句的執行過程,我們先來看一下idx_name這個索引的示意圖。
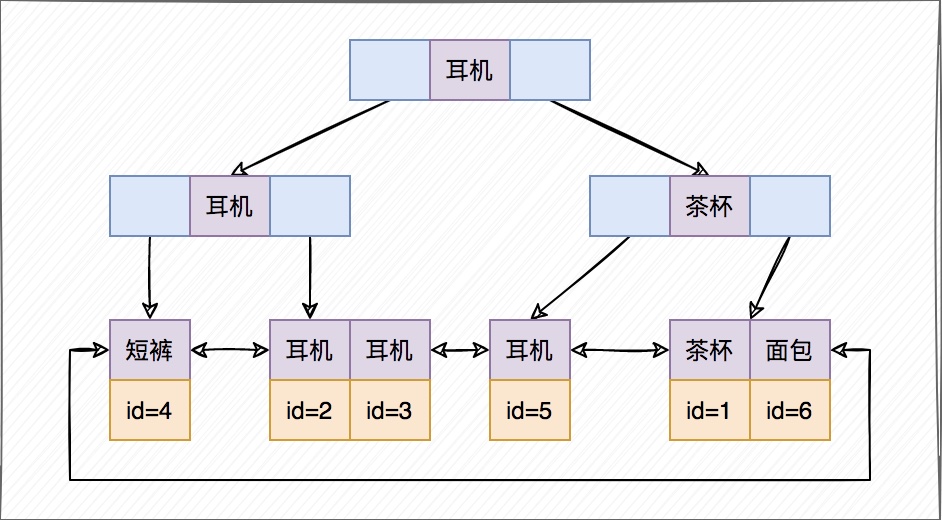
從圖中可以看到,滿足name='耳機'條件的行,是id = (2,3,5) 的這些記錄。
整個完整流程如下圖所示:

這裡的執行流程:
1)、初始化sort_buffer,確定放入order_no、name、status這三個欄位;
2)、從索引idx_name找到第一個滿足name='耳機'條件的主鍵id,也就是圖中的id=2;
3)、到主鍵索引取出整行,取order_no、name、status三個欄位的值,存入sort_buffer中;
4)、從索引idx_name取下一個滿足name='耳機'條件的主鍵id;
5)、重複步驟3、4直到name的值不滿足查詢條件為止;
6)、對sort_buffer中的資料按照欄位name做快速排序;
7)、按照排序結果取前10行返回給使用者端。
因為需要查詢的欄位不能夠在idx_name索引中全部找到,所以才需要拿著idx_name索引中獲取的主鍵,再到主鍵索引中獲取其它屬性。這個過程也叫回表。
回表: 就是指拿到主鍵再回到主鍵索引查詢的過程。
全欄位排序,就是把查詢所需要的欄位全部讀取到sort_buffer中。
但如果查詢的欄位資料量很大呢,大到當前的sort_buffer放不下了,那怎麼辦呢?
那就不得不利用磁碟臨時檔案輔助排序。
實際上,sort_buffer的大小是由一個引數控制的:sort_buffer_size。
如果要排序的資料小於sort_buffer_size,排序在sort_buffer 記憶體中完成,如果要排序的資料大於sort_buffer_size,則藉助磁碟檔案來進行排序
我們可以通過下面的方法來確定一個排序語句是否使用了臨時檔案。
/* 開啟optimizer_trace,只對本執行緒有效 */
SET optimizer_trace='enabled=on';
/* 執行語句 */
select order_no, name, status from order_info where name = '耳機' order by order_no limit 10;
/* 檢視 OPTIMIZER_TRACE 輸出 */
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`;
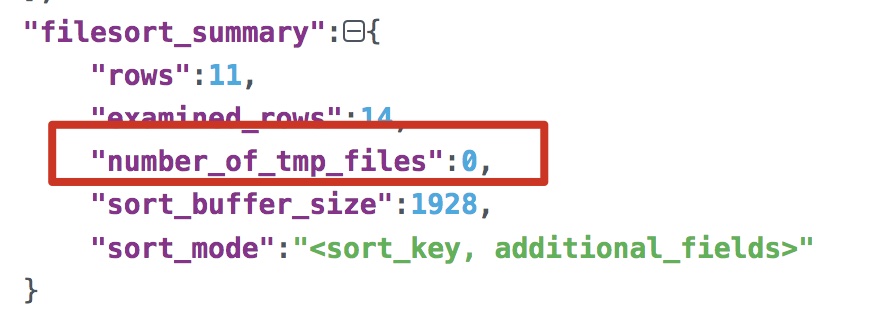
number_of_tmp_files 表示使用來排序的磁碟臨時檔案數。
如果number_of_tmp_files>0,則表示使用了磁碟檔案來進行排序。
使用了磁碟臨時檔案,整個排序過程又是怎樣的呢?
1)、從主鍵索引樹,拿到需要的資料,並放到sort_buffer記憶體塊中。當sort_buffer快要滿時,就對sort_buffer中的資料排序,排完後,把資料臨時放到磁碟一個小檔案中。
2)、繼續回到主鍵索引樹取資料,繼續放到sort_buffer記憶體中,排序後,也把這些資料寫入到磁碟臨時小檔案中。
3)、繼續迴圈,直到取出所有滿足條件的資料。
4)、 最後把磁碟的臨時排好序的小檔案,合併成一個有序的大檔案。
2、rowid排序
既然查詢的欄位資料量很大,大到當前的sort_buffer放不下了,就會使用磁碟臨時檔案,排序的效能會很差。
那是不是可以不把所有查詢欄位都放入sort_buffer中,而僅僅是放排序欄位和該記錄主鍵到sort_buffer中呢,這其實就是rowid 排序。
這裡我們思考兩個問題?
什麼是rowid排序?
就是隻把查詢SQL需要用於排序的欄位和主鍵id,放到sort_buffer中。
什麼情況走全欄位排序,什麼情況下走rowid排序?
它們的切換通過一個引數控制的這個引數就是max_length_for_sort_data 它表示MySQL用於排序行資料的長度的一個引數,如果單行的長度超過這個值,MySQL 就認為
單行太大,就換rowid 排序。
我們可以通過命令看下這個引數取值。
show variables like 'max_length_for_sort_data';
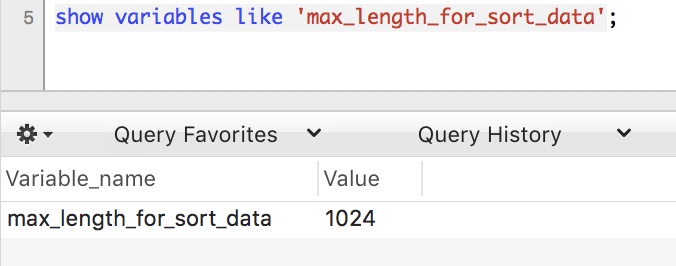
預設是1024,。
因為本文範例中name,order_no,status長度=50+4+4 =58 < 1024, 所以走的是全欄位排序。
接下來,我來修改一個引數,讓MySQL採用另外一種演演算法。
SET max_length_for_sort_data = 16;
新的演演算法放入sort_buffer的欄位,只有要排序的列(即order_no欄位)和主鍵id。
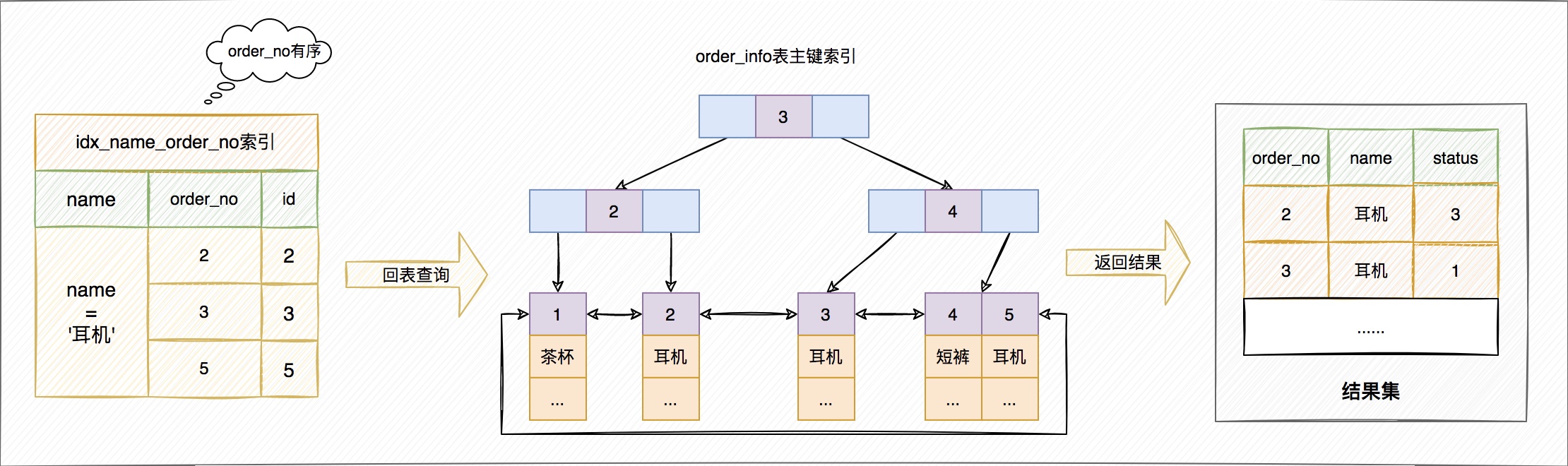
但這時,排序的結果就因為少了name和status欄位的值,不能直接返回了,整個執行流程就變成如下所示的樣子:
1)、初始化sort_buffer,確定放入兩個欄位,即order_no和id;
2)、從索引idx_name找到第一個滿足name='耳機’條件的主鍵id,也就是圖中的id=2;
3)、到主鍵索引取出整行,取order_no、id這兩個欄位,存入sort_buffer中;
4)、從索引idx_name取下一個滿足name='耳機’條件的主鍵id;
5)、重複步驟3、4直到不滿足name='耳機’條件為止;
6)、對sort_buffer中的資料按照欄位order_no進行排序;
7)、 遍歷排序結果,取前10行,並按照id的值回到主鍵索引中取出order_no、name和status三個欄位返回給使用者端。
這個執行流程的示意圖如下,我把它稱為rowid排序。
3、全欄位排序 VS rowid排序
全欄位排序:如果sort_buffer記憶體足夠,那效率是最高的,但如果sort_buffer記憶體不夠的話,就需要用到磁碟臨時檔案,排序的效能會很差。rowid排序:雖然sort_buffer可以放更多資料了,相對於全欄位排序而言,rowid排序會多一次回表查詢。
如果MySQL認為記憶體足夠大,會優先選擇全欄位排序,把需要的欄位都放到sort_buffer中,這樣排序後就會直接從記憶體裡面返回查詢結果了,不用再回到原表去取資料。
這也就體現了MySQL的一個設計思想:如果記憶體夠,就要多利用記憶體,儘量減少磁碟存取。
三、排序欄位新增索引
上面的案例中,我們僅僅是在查詢欄位新增索引,那如果我們在查詢條件和排序欄位新增組合索引呢,那整個排序的流程又是怎麼樣的?
這裡新增一條組合索引
drop index idx_name on order_info;
alter table order_info add index idx_name_order_no(name,order_no);
我們再來看下執行計劃
explain select order_no, name, status from order_info where name = '耳機' order by order_no limit 10

- Extra 這個欄位的
Using index condition表示該查詢走了索引
我們發現已經沒有上面的Using filesort,說明這個查詢過程不需要內部排序。
那我們再看下它的執行流程是怎麼樣的?
我們發現這裡流程裡已經不需要排序,但還需要走一次回表,那是因為我們查詢欄位有個status,在idx_name_order_no索引中並沒有。
所以需要回表查詢這個值。
那如果我們將所以改成如下呢?
-- 刪除索引
drop index idx_name_order_no on order_info;
-- 新增索引
alter table order_info add index idx_name_order_no_status(name,order_no,status);
我們再來看下執行計劃
explain select order_no, name, status from order_info where name = '耳機' order by order_no limit 10

- Extra 這個欄位的
Using index表示走了索引覆蓋,也就是說都不需要回表查詢主鍵索引了。
索引覆蓋: 只需要在一棵索引樹上就能獲取SQL所需的所有列資料,無需回表,速度更快。
我們再來看下當前的執行流程
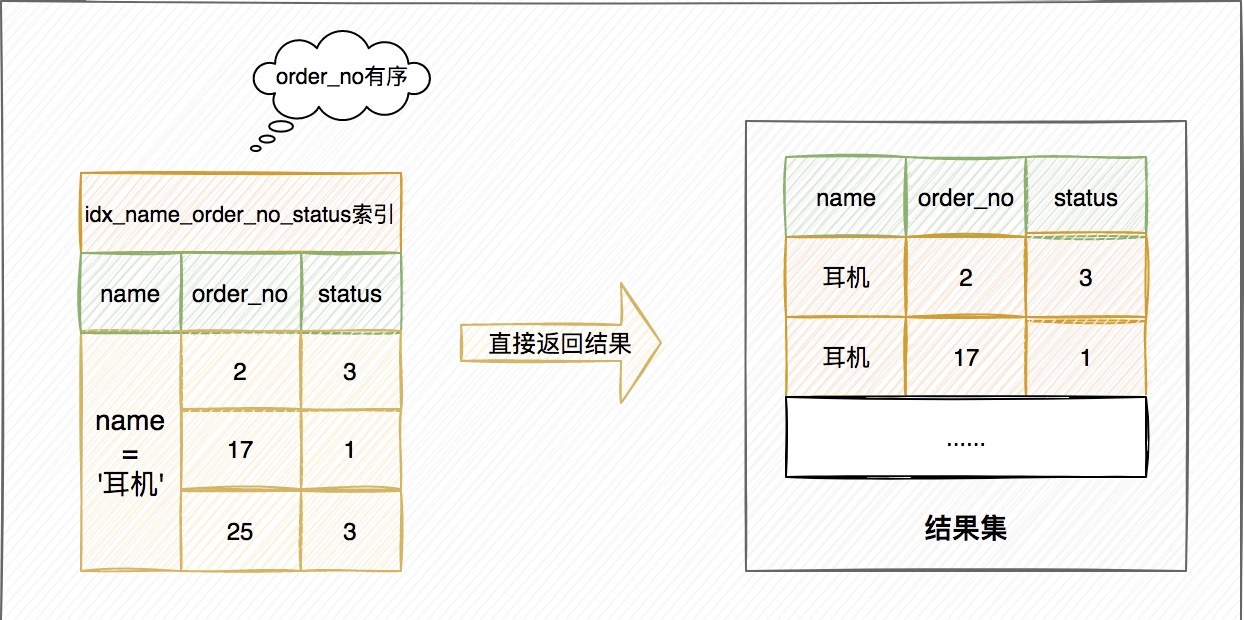
這樣整個查詢語句的執行流程就變成了:
-
從索引(name,order_no,status)找到第一個滿足
name='耳機'條件的記錄,取出其中的ame,order_no,status這三個欄位的值,作為結果集的一部分直接返回; -
從
索引(name,order_no,status)取下一個記錄,同樣取出這三個欄位的值,作為結果集的一部分直接返回; -
重複執行步驟2,直到查到第10條記錄,或者是不滿足name='耳機'條件時迴圈結束。
使用了覆蓋索引,效能上會快很多。
當然,這裡並不是說要為了每個查詢能用上覆蓋索引,就要把語句中涉及的欄位都建上聯合索引,畢竟索引還是有維護代價的。這是一個需要權衡的決定。
四、order by如何優化?
這裡總結4點優化經驗
1)、排序欄位加索引
2)、只select需要的欄位
3)、嘗試提高 sort_buffer_size
4)、嘗試提高 max_length_for_sort_data
4.1 排序欄位加索引
儘量使用索引排序,如果這裡使用ID排序的話,因為ID是索引欄位,天生就具備有序的特性,所以這種情況都不需要放到sort buffer中去額外進行排序操作。
4.2 只select需要的欄位
避免非必要的欄位查詢,只select需要的欄位, 這點非常重要。
在這裡的影響是:
1)、因為查詢的欄位較多可能導致資料會超出sort_buffer的容量,超出之後就需要用到磁碟臨時檔案,排序的效能會很差。
2)、 當select的欄位大小總和>max_length_for_sort_data,排序演演算法會將 全欄位排序 改為 rowid排序 增加一次回表查詢。
4.3 嘗試提高 sort_buffer_size
不管用哪種演演算法,提高這個引數都會提高效率,當然,要根據系統的能力去提高,因為這個引數是針對每個程序的。
4.4 嘗試提高 max_length_for_sort_data
提高這個引數, 會增加用改進演演算法的概率。但是如果設的太高,資料總容量超出sort_buffer_size的概率就增大,超出之後就需要用到磁碟臨時檔案,排序的效能會很差。
五、一個有意思的思考題
在上面範例中如果我們在新增 idx_name_order_no 索引,同時執行下面sql
select order_no, name, status from order_info where name = '耳機' order by order_no limit 10
在分析explain的時候,是不會產生 Using filesort 的,因為會走idx_name_order_no索引排序。
那如果這裡sql改成
select order_no, name, status from order_info where name in ('耳機', '短褲') order by order_no limit 10
1)那麼這個語句執行的時候會走內部排序嗎,為什麼?
雖然有(name,order_no)聯合索引,對於單個name內部,order_no是遞增的。
但這條SQL語句不是要單獨地查一個name的值,而是同時查了耳機和短褲 兩個名稱,因此所有滿足條件的order_no就不是遞增的了。也就是說,這條SQL語句需要排序。
所以答案是依然會產生 Using filesort。
2)針對上面的sql有沒有什麼方式來實現走idx_name_order_no索引排序?
這裡,我們要用到(name,order_no)聯合索引的特性,把這一條語句拆成兩條語句,執行流程如下:
-- 這個語句是不需要排序的,使用者端用一個長度為10的記憶體陣列A儲存結果。
select order_no, name, status from order_info where name = '耳機' order by order_no limit 10
-- 用相同的方法,假設結果被存進了記憶體陣列B。
select order_no, name, status from order_info where name = '短褲' order by order_no limit 10
現在A和B是兩個有序陣列,然後你可以用歸併排序的思想,得到order_no最小的前10值,就是我們需要的結果了。
宣告: 公眾號如需轉載該篇文章,發表文章的頭部一定要 告知是轉至公眾號: 後端元宇宙。同時也可以問本人要markdown原稿和原圖片。其它情況一律禁止轉載!