分散式協定與演演算法-Paxos演演算法
1.Basic Paxos
假設我們要實現一個分散式叢集,這個叢集是由節點 A、B、C 組成,提供唯讀 KV 儲存服務。你應該知道,建立唯讀變數的時候,必須要對它進行賦值,而且這個值後續沒辦法修改。因此一個節點建立唯讀變數後就不能再修改它了,所以所有節點必須要先對唯讀變數的值達成共識,然後所有節點再一起建立這個唯讀變數。

1.1三種角色
在 Basic Paxos 中,有提議者(Proposer)、接受者(Acceptor)、學習者(Learner)
三種角色,他們之間的關係如下:

提議者(Proposer):提議一個值,用於投票表決。為了方便演示,你可以把圖 1 中的使用者端 1 和 2 看作是提議者。但在絕大多數場景中,叢集中收到使用者端請求的節點,才是提議者(圖 1 這個架構,是為了方便演示演演算法原理)。這樣做的好處是,對業務程式碼沒有入侵性,也就是說,我們不需要在業務程式碼中實現演演算法邏輯,就可以像使用資料庫一樣存取後端的資料。
接受者(Acceptor):對每個提議的值進行投票,並儲存接受的值,比如 A、B、C 三個節點。 一般來說,叢集中的所有節點都在扮演接受者的角色,參與共識協商,並接受和儲存資料。
學習者(Learner):被告知投票的結果,接受達成共識的值,儲儲存存,不參與投票的過程。一般來說,學習者是資料備份節點,比如「Master-Slave」模型中的 Slave,被動地接受資料,容災備份。
前面不是說接收使用者端請求的節點是提議者嗎?這裡怎麼又是接受者呢?
一個節點(或程序)可以身兼多個角色。想象一下,一個 3 節點的叢集,1 個節點收到了請求,那麼該節點將作為提議者發起二階段提交,然後這個節點和另外2 個節點一起作為接受者進行共識協商,如下圖:
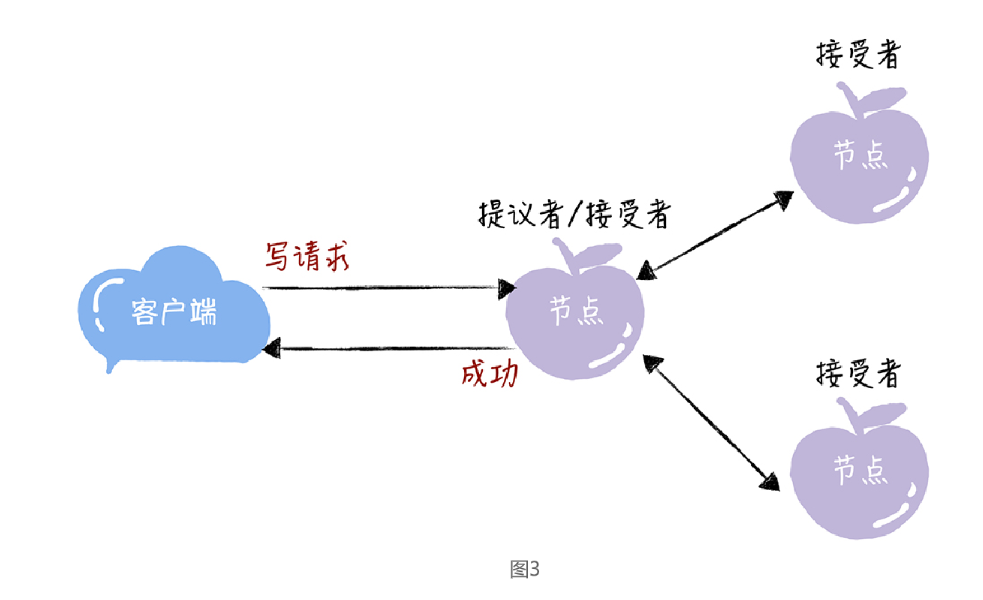
什麼是二階段提交?
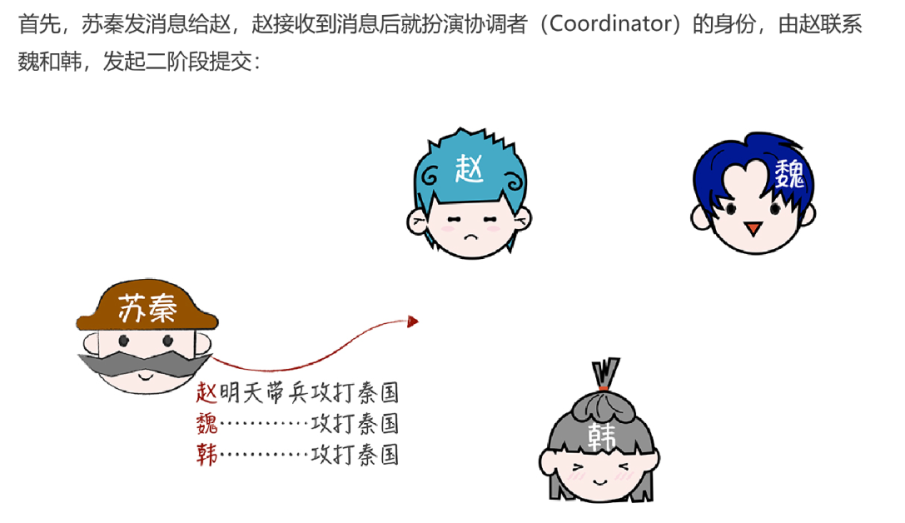
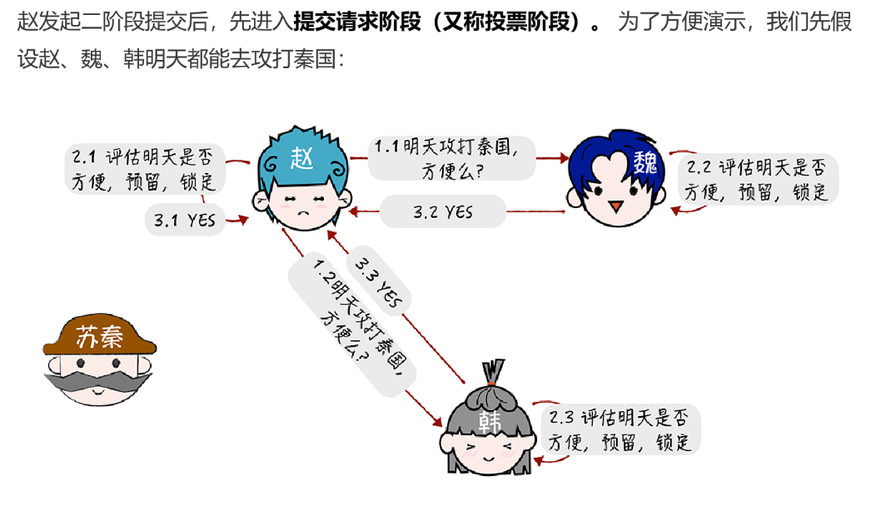
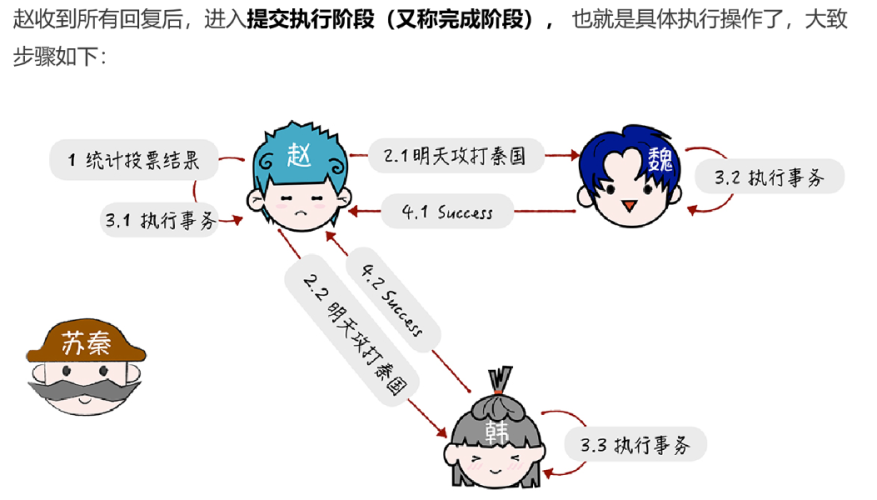
在兩階段提交過程中,主要分為了兩種角色協調者(coordinator)和參與者(participants),協調者主要就是起到協調參與者是否需要提交事務或者中止事務,參與者主要就是接受協調者的響應並回復協調者是否能夠參與事務提交,當接受到協調者提交事務的命令後提交事務等功能。
1.2如何達成共識
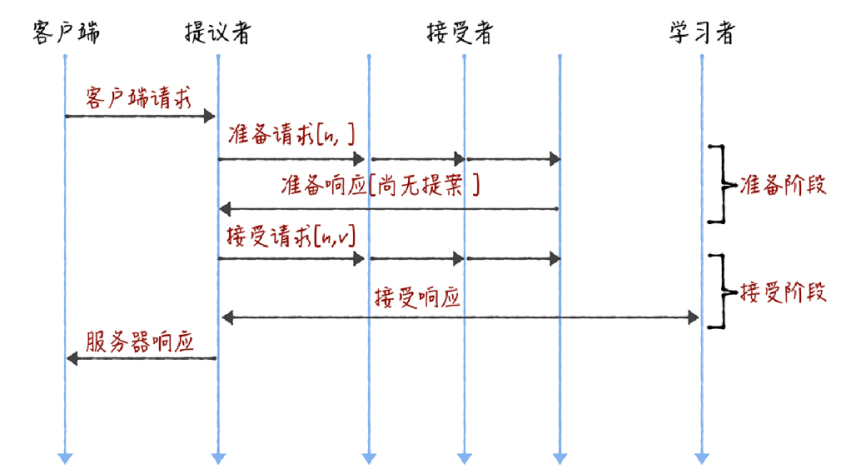
(1)準備階段
先來看第一個階段,首先使用者端 1、2 作為提議者,分別向所有接受者傳送包含提案編號的準備請求:
注意:在準備請求中是不需要指定提議的值的,只需要攜帶提案編號就可以了

當節點 A、B 收到提案編號為 1 的準備請求,節點 C 收到提案編號為 5 的準備請求後,將進行這樣的處理

由於之前沒有通過任何提案:
節點 A、B 將返回一個 「尚無提案」的響應。也就是說節點 A 和 B 在告訴提議者,我之前沒有通過任何提案呢,並承諾以後不再響應提案編號小於等於 1 的準備請求,不會通過編號小於 1 的提案。
節點 C 也是如此,它將返回一個 「尚無提案」的響應,並承諾以後不再響應提案編號小於等於 5 的準備請求,不會通過編號小於 5 的提案。
繼續:
另外,當節點 A、B 收到提案編號為 5 的準備請求,和節點 C 收到提案編號為 1 的準備請求的時候,將進行這樣的處理過程:

當節點 A、B收到提案編號為 5 的準備請求的時候,因為提案編號 5 大於它們之前響應的準備請求的提案編號 1,而且兩個節點都沒有通過任何提案,所以它將返回一個 「尚無提案」的響應,並承諾以後不再響應提案編號小於等於 5 的準備請求,不會通過編號小於 5 的提案。
當節點 C收到提案編號為 1 的準備請求的時候,由於提案編號 1 小於它之前響應的準備請求的提案編號 5,所以丟棄該準備請求,不做響應。
(2)接受請求
第二個階段也就是接受階段,首先使用者端 1、2 在收到大多數節點的準備響應之後,會分別傳送接受請求:
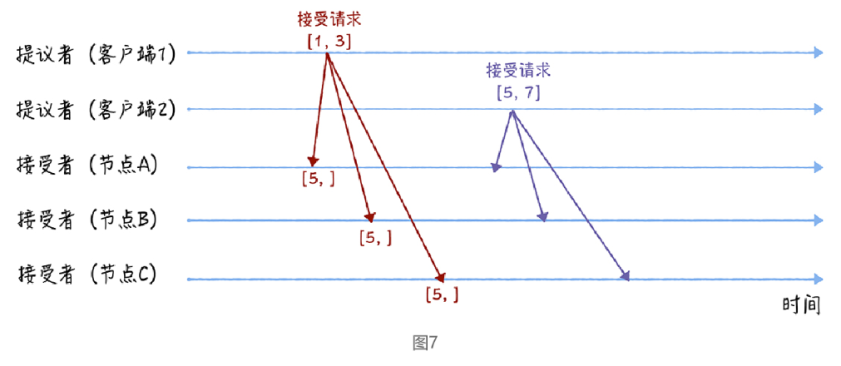
當使用者端 1 收到大多數的接受者(節點 A、B)的準備響應後,根據響應中提案編號最大的提案的值,設定接受請求中的值。因為該值在來自節點 A、B 的準備響應中都為空(也就是圖 5 中的「尚無提案」),所以就把自己的提議值 3 作為提案的值,傳送接受請求[1, 3]。
當**使用者端 2 **收到大多數的接受者的準備響應後(節點 A、B 和節點 C),根據響應中提案編號最大的提案的值,來設定接受請求中的值。因為該值在來自節點 A、B、C 的準備響應中都為空(也就是圖 5 和圖 6 中的「尚無提案」),所以就把自己的提議值 7 作為提案的值,傳送接受請求[5, 7]。
當三個節點收到 2 個使用者端的接受請求時,會進行這樣的處理:
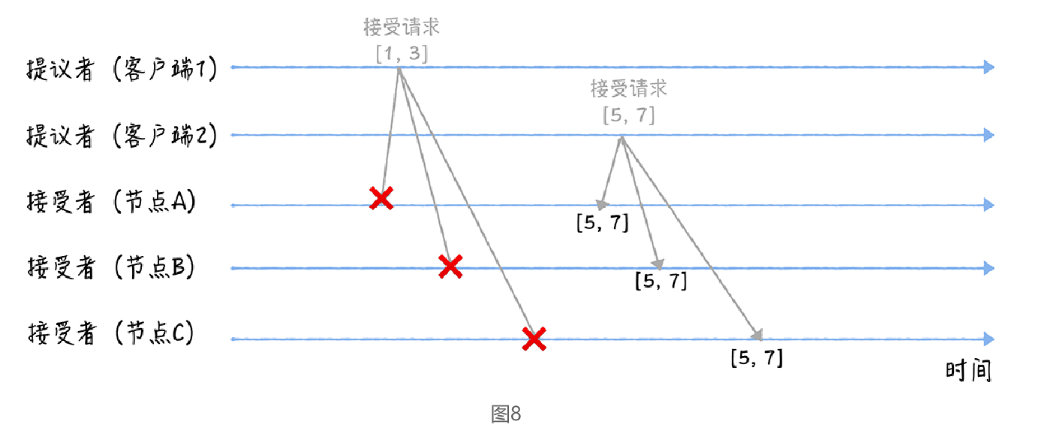
當節點 A、B、C 收到接受請求[1, 3]的時候,由於提案的提案編號 1 小於三個節點承諾能通過的提案的最小提案編號 5,所以提案[1, 3]將被拒絕。
當節點 A、B、C 收到接受請求[5, 7]的時候,由於提案的提案編號 5 不小於三個節點承諾能通過的提案的最小提案編號 5,所以就通過提案[5, 7],也就是接受了值 7,三個節點就 X 值為 7 達成了共識。
2.Multi-Paxos
蘭伯特提到的 Multi-Paxos 是一種思想,不是演演算法。而Multi-Paxos 演演算法是一個統稱,它是指基於 Multi-Paxos 思想,通過多個 Basic Paxos範例實現一系列值的共識的演演算法(比如 Chubby 的 Multi-Paxos 實現、Raft 演演算法等)
Basic Paxos 是通過二階段提交來達成共識的。在第一階段,也就是準備階段,接收到大多數準備響應的提議者,才能發起接受請求進入第二階段(也就是接受階段):
多次執行 Basic Paxos的侷限性:
而如果我們直接通過多次執行 Basic Paxos 範例,來實現一系列值的共識,就會存在這樣幾個問題:
一、如果多個提議者同時提交提案,可能出現因為提案衝突,在準備階段沒有提議者接收到大多數準備響應,協商失敗,需要重新協商。你想象一下,一個 5 節點的叢集,如果 3個節點作為提議者同時提案,就可能發生因為沒有提議者接收大多數響應(比如 1 個提議者接收到 1 個準備響應,另外 2 個提議者分別接收到 2 個準備響應)而準備失敗,需要重新協商。
二、2 輪 RPC 通訊(準備階段和接受階段)往返訊息多、耗效能、延遲大。你要知道,分散式系統的執行是建立在 RPC 通訊的基礎之上的,因此,延遲一直是分散式系統的痛點,是需要我們在開發分散式系統時認真考慮和優化的。
如何解決:
引入領導者和優化 Basic Paxos 執行來解決。
2.1Chubby 的 Multi-Paxos範例
首先,它通過引入主節點,實現了蘭伯特提到的領導者(Leader)節點的特性。也就是說,主節點作為唯一提議者,這樣就不存在多個提議者同時提交提案的情況,也就不存在提案衝突的情況了。
另外,在 Chubby 中,主節點是通過執行 Basic Paxos 演演算法,進行投票選舉產生的,並且在執行過程中,主節點會通過不斷續租的方式來延長租期(Lease)。比如在實際場景中,幾天內都是同一個節點作為主節點。如果主節點故障了,那麼其他的節點又會投票選舉出新的主節點,也就是說主節點是一直存在的,而且是唯一的。
其次,在 Chubby 中實現了蘭伯特提到的,「當領導者處於穩定狀態時,省掉準備階段,直接進入接受階段」這個優化機制。
最後,在 Chubby 中,實現了成員變更(Group membership),以此保證節點變更的時候叢集的平穩執行。
在 Chubby 中,為了實現了強一致性,讀操作也只能在主節點上執行。 也就是說,只要資料寫入成功,之後所有的使用者端讀到的資料都是一致的。具體的過程,就是下面的樣子:
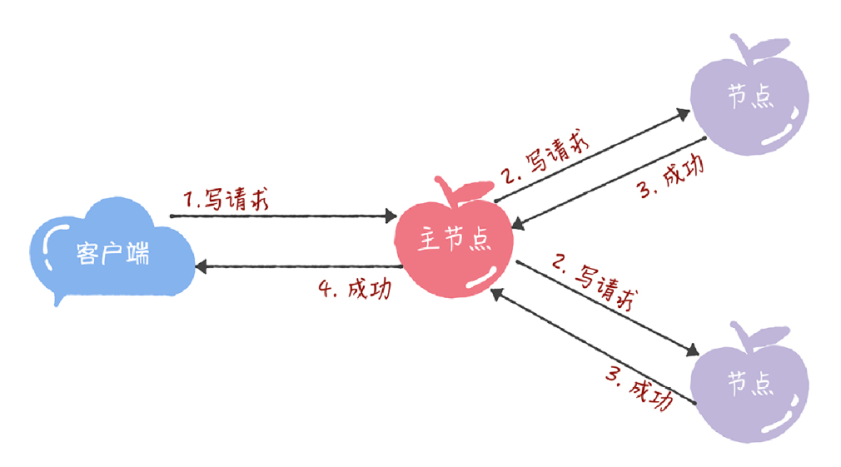
所有的讀請求和寫請求都由主節點來處理。當主節點從使用者端接收到寫請求後,作為提議者,執行 Basic Paxos 範例,將資料傳送給所有的節點,並且在大多數的伺服器接受了這個寫請求之後,再響應給使用者端成功:
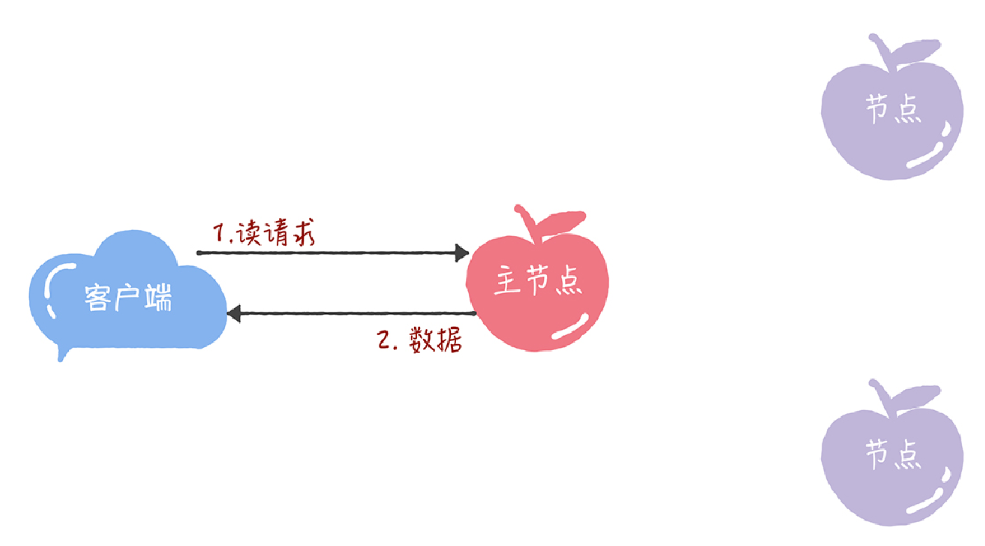
當主節點接收到讀請求後,處理就比較簡單了,主節點只需要查詢本地資料,然後返回給使用者端就可以了:
3.內容小結
1.蘭伯特提到的 Multi-Paxos 是一種思想,不是演演算法,而且還缺少演演算法過程的細節和程式設計所必須的細節,比如如何選舉領導者等,這也就導致了每個人實現的 Multi-Paxos 都不一樣。而 Multi-Paxos 演演算法是一個統稱,它是指基於 Multi-Paxos 思想,通過多個Basic Paxos 範例實現一系列資料的共識的演演算法(比如 Chubby 的 Multi-Paxos 實現、Raft 演演算法等)。
2.Chubby 實現了主節點(也就是蘭伯特提到的領導者),也實現了蘭伯特提到的「當領導者處於穩定狀態時,省掉準備階段,直接進入接受階段」 這個優化機制,省掉 Basic Paxos 的準備階段,提升了資料的提交效率,但是所有寫請求都在主節點處理,限制了叢集處理寫請求的並行能力,約等於單機。
3.因為Chubby 的 Multi-Paxos 實現中,也約定了「大多數原則」,也就是說,只要大多數節點正常執行時,叢集就能正常工作,所以 Chubby 能容錯(n - 1)/2 個節點的故障。
4.本質上而言,「當領導者處於穩定狀態時,省掉準備階段,直接進入接受階段」這個優化機制,是通過減少非必須的協商步驟來提升效能的。這種方法非常常用,也很有效。比如,Google 設計的 QUIC 協定,是通過減少 TCP、TLS 的協商步驟,優化 HTTPS 效能。我希望你能掌握這種效能優化思路,後續在需要時,可以通過減少非必須的步驟,優化系統效能。