hashmap的一些效能測試
0.前言
本文主要討論雜湊衝突下的一些效能測試。
為什麼要寫這篇文章,不是為了KPI不是為了水字數。
hashmap是廣大JAVA程式設計師最為耳熟能詳,使用最廣泛的集合框架。它是大廠面試必問,著名八股經必備。在小公司呢?這些年也面過不少人,對於3,5年以上的程式設計師,問到hashmap也僅限於要求知道底層是陣列+連結串列,知道怎麼放進去,知道有雜湊衝突這麼一回事即可,可依然免不了裝備的嫌疑。
可hashmap背後的思想,在快取,在資料傾斜,在負載均衡等分散式巨量資料領域都能廣泛看到其身影。瞭解其背後的思想不僅僅只是為了一個hashmap.
更重要的是,hashmap不像jvm底層原理那麼遙遠,不像並行程式設計那麼宏大,它只需要通勤路上十分鐘就可搞定基本原理,有什麼理由不呢?
所以本文試著從相對少見的一個微小角度來重新審視一下hashmap.
1.準備工作。
1.1模擬雜湊衝突
新建兩個class,一個正常重寫equals和hashcode方法,一個故意在hashcode方法裡返回一定範圍內的亂數,模擬雜湊衝突,以及控制雜湊衝突的程式。
不衝突的類
@Setter
public class KeyTest2 {
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyTest2 keyTest = (KeyTest2) o;
return name != null ? name.equals(keyTest.name) : keyTest.name == null;
}
@Override
public int hashCode() {
return name != null ? name.hashCode() : 0;
}
}
衝突的類
@Setter
@NoArgsConstructor
public class KeyTest {
private String name;
private Random random;
public KeyTest(Random random){
this.random = random;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyTest keyTest = (KeyTest) o;
return name != null ? name.equals(keyTest.name) : keyTest.name == null;
}
@Override
public int hashCode() {
// return name != null ? name.hashCode() : 0;
return random.nextInt(1000);
}
}
眾所周知,hashmap在做put的時候,先根據key求hashcode,找到陣列下標位置,如果該位置有元素,再比較equals,如果返回true,則替換該元素並返回被替換的元素;否則就是雜湊衝突了,即hashcode相同但equals返回false。
雜湊衝突的時候在衝突的陣列處形成陣列,長度達到8以後變成紅黑樹。
1.2 java的基準測試。
這裡使用JMH進行基準測試.
JMH是Java Microbenchmark Harness的簡稱,一般用於程式碼的效能調優,精度甚至可以達到納秒級別,適用於 java 以及其他基於 JVM 的語言。和 Apache JMeter 不同,JMH 測試的物件可以是任一方法,顆粒度更小,而不僅限於rest api.
jdk9以上的版本自帶了JMH,如果是jdk8可以使用maven引入依賴。
點選檢視JMH依賴
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>${jmh.version}</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>${jmh.version}</version>
</dependency>
2.測試初始化長度
點選檢視初始化長度基本測試程式碼
/使用模式 預設是Mode.Throughput
@BenchmarkMode(Mode.AverageTime)
// 設定預熱次數,預設是每次執行1秒,執行10次,這裡設定為3次
@Warmup(iterations = 3, time = 1)
// 本例是一次執行4秒,總共執行3次,在效能對比時候,採用預設1秒即可
@Measurement(iterations = 3, time = 4)
// 設定同時起多少個執行緒執行
@Threads(1)
//代表啟動多個單獨的程序分別測試每個方法,這裡指定為每個方法啟動一個程序
@Fork(1)
// 定義類範例的生命週期,Scope.Benchmark:所有測試執行緒共用一個範例,用於測試有狀態範例在多執行緒共用下的效能
@State(value = Scope.Benchmark)
// 統計結果的時間單元
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class HashMapPutResizeBenchmark {
@Param(value = {"1000000"})
int value;
/**
* 初始化長度
*/
@Benchmark
public void testInitLen(){
HashMap map = new HashMap(1000000);
Random random = new Random();
for (int i = 0; i < value; i++) {
KeyTestConflict test = new KeyTestConflict(random, 10000);
test.setName(i+"");
map.put(test, test);
}
}
/**
* 不初始化長度
*/
@Benchmark
public void testNoInitLen(){
HashMap map = new HashMap();
for (int i = 0; i < value; i++) {
Random random = new Random();
KeyTestConflict test = new KeyTestConflict(random, 10000);
test.setName(i+"");
map.put(test, test);
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(HashMapPutResizeBenchmark.class.getSimpleName())
.mode(Mode.All)
// 指定結果以json結尾,生成後複製可去:http://deepoove.com/jmh-visual-chart/ 或https://jmh.morethan.io/ 得到視覺化介面
.result("hashmap_result_put_resize.json")
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
}
測試結果圖
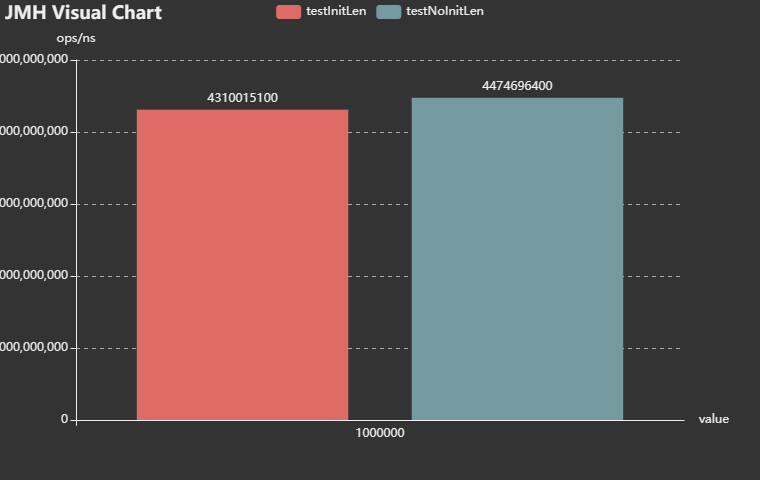
對測試結果圖例做一個簡單的說明:
以上基準測試,會得到一個json格式的結果。然後將該結果上傳到官方網站,會得到一個上述圖片的結果。
橫座標,紅色駐圖代表有衝突,淺藍色駐圖無衝突。
眾座標,ops/ns代表平均每次操作花費的時間,單位為納秒,1秒=1000000000納秒,這樣更精準。
下同。
簡單說,駐圖越高代表效能越低。
我測了兩次,分別是無雜湊衝突和有雜湊衝突的,這裡只貼一種結果。
測試結果表明,hashmap定義時有初始化對比無初始化,有大約4%到12%的效能損耗。
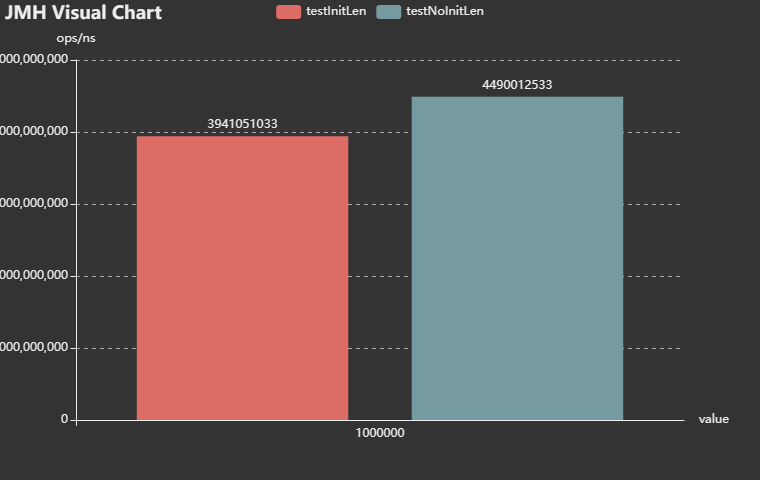
足夠的初始化長度下,有雜湊衝突的測試結果:
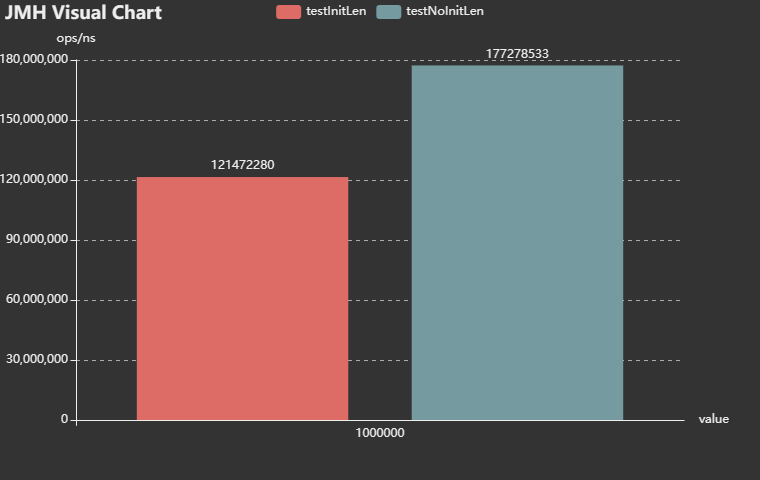
足夠的初始化長度下,沒有雜湊衝突的測試結果:
3.模擬一百萬個元素put,get的差異。
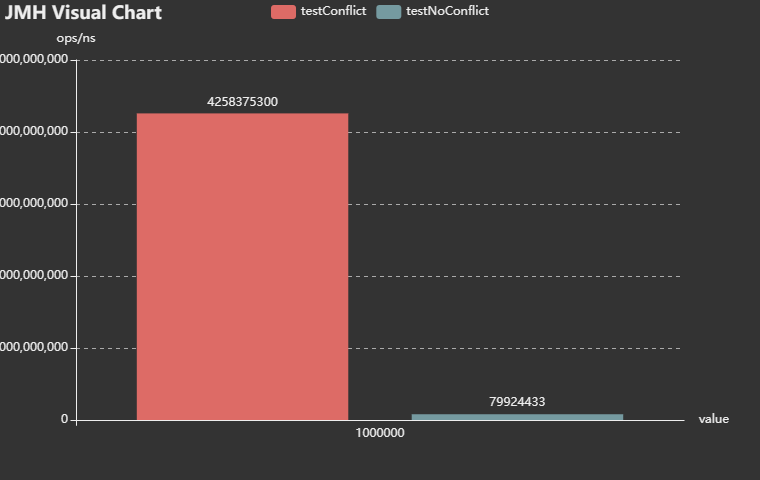
眾所周知,hashmap在頻繁做resize時,效能損耗非常嚴重。以上是沒初始化長度,無衝突和有衝突的情況下,前者效能是後者效能的53倍。
那麼在初始化長度的情況下呢?
HashMap map = new HashMap(1000000);
同樣的程式碼下,得到的測試結果
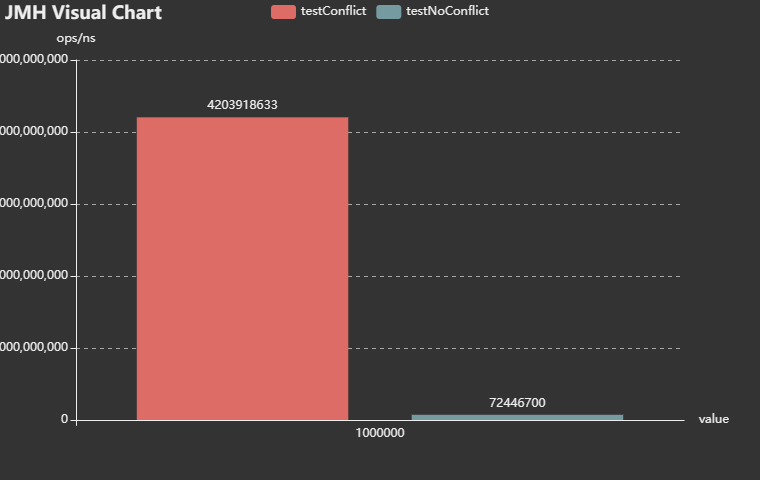
以上是有初始化長度,無衝突和有衝突的情況下,前者效能是後者效能的58倍。
大差不差,不管有無初始化長度,無衝突的效率都是有衝突效率的50倍以上。說明,這是雜湊衝突帶來的效能損耗。
4.模擬無紅黑樹情況下get效率
4.1 將random擴大,雜湊衝突嚴重性大大減小,模擬大多數雜湊衝突導致的雜湊鏈長度均小於8,無法擴充套件為紅黑樹,只能遍歷陣列。
將KeyTest的hashcode方法改為:
@Override
public int hashCode() {
// return name != null ? name.hashCode() : 0;
return random.nextInt(130000);
}
這樣1000000/130000 < 8,這樣大多數的雜湊鏈將不會擴充套件為紅黑樹。
測試結果為:
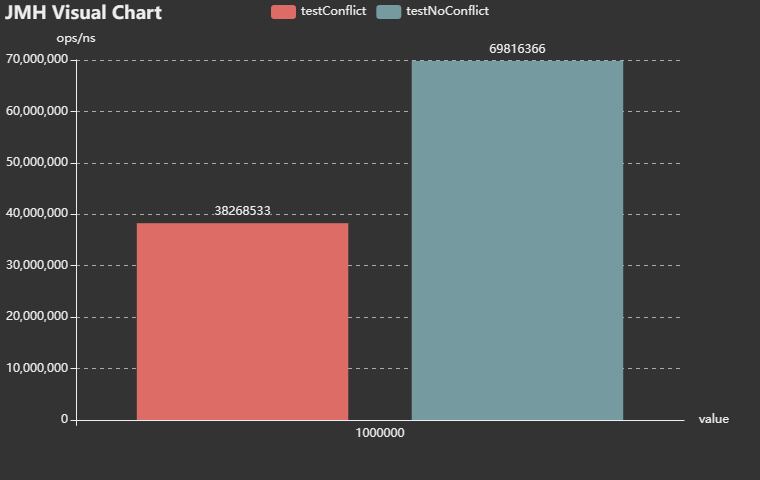
測試結果說明,**有衝突的效率反而比無衝突的效率要高**,差不多高出80%左右。
這其實有點違反常識,我們通常講,hashmap要儘量避免雜湊衝突,雜湊衝突的情況下寫入和讀取效能都會受到很大的影響。
但是上面的測試結果表明,巨量資料量相對比較大的時候,適當的雜湊衝突(<8)反而讀取效率更高。
個人猜測是,適當的雜湊衝突,陣列長度大為減少。
為了證明以上猜想,直接對ArrayList進行基準測試。
4.1.1 ArrayList不同長度下get效率的基準測試
模擬一個雜湊衝突非常嚴重下,底層陣列長度較小的list,和雜湊衝突不嚴重情況下,底層陣列較大的list,再隨機測試Get的效率如何。
點選檢視測試程式碼
//使用模式 預設是Mode.Throughput
@BenchmarkMode(Mode.AverageTime)
// 設定預熱次數,預設是每次執行1秒,執行10次,這裡設定為3次
@Warmup(iterations = 3, time = 1)
// 本例是一次執行4秒,總共執行3次,在效能對比時候,採用預設1秒即可
@Measurement(iterations = 3, time = 4)
// 設定同時起多少個執行緒執行
@Threads(1)
//代表啟動多個單獨的程序分別測試每個方法,這裡指定為每個方法啟動一個程序
@Fork(1)
// 定義類範例的生命週期,Scope.Benchmark:所有測試執行緒共用一個範例,用於測試有狀態範例在多執行緒共用下的效能
@State(value = Scope.Benchmark)
// 統計結果的時間單元
@OutputTimeUnit(TimeUnit.NANOSECONDS)
public class ArrayListGetBenchmark {
// @Param(value = {"1000","100000","1000000"})
@Param(value = {"1000000"})
int value;
@Benchmark
public void testConflict(){
int len = 10000;
Random random = new Random(len);
for (int i = 0; i < 100; i++) {
int index = random.nextInt(len);
System.out.println("有衝突,index = " + index);
ConflictHashMapOfList.list.get(index);
}
}
@Benchmark
public void testNoConflict(){
int len = 1000000;
Random random = new Random(len);
for (int i = 0; i < 100; i++) {
int index = random.nextInt(len);
System.out.println("無衝突,index = " + index);
NoConflictHashMapOfList.list.get(index);
}
}
public static void main(String[] args) throws RunnerException {
Options opt = new OptionsBuilder()
.include(HashMapGetBenchmark.class.getSimpleName())
.mode(Mode.All)
// 指定結果以json結尾,生成後複製可去:http://deepoove.com/jmh-visual-chart/ 或https://jmh.morethan.io/ 得到視覺化介面
.result("arraylist_result_get_all.json")
.resultFormat(ResultFormatType.JSON).build();
new Runner(opt).run();
}
@State(Scope.Thread)
public static class ConflictHashMapOfList {
volatile static ArrayList list = new ArrayList();
static int randomMax = 10000;
static {
// 模擬雜湊衝突嚴重,陣列長度較小
for (int i = 0; i < randomMax; i++) {
list.add(i);
}
}
}
@State(Scope.Thread)
public static class NoConflictHashMapOfList {
volatile static ArrayList list = new ArrayList();
static int randomMax = 1000000;
static {
// 模擬沒有雜湊衝突,陣列長度較大
for (int i = 0; i < randomMax; i++) {
list.add(i);
}
}
}
}
測試結果如下:
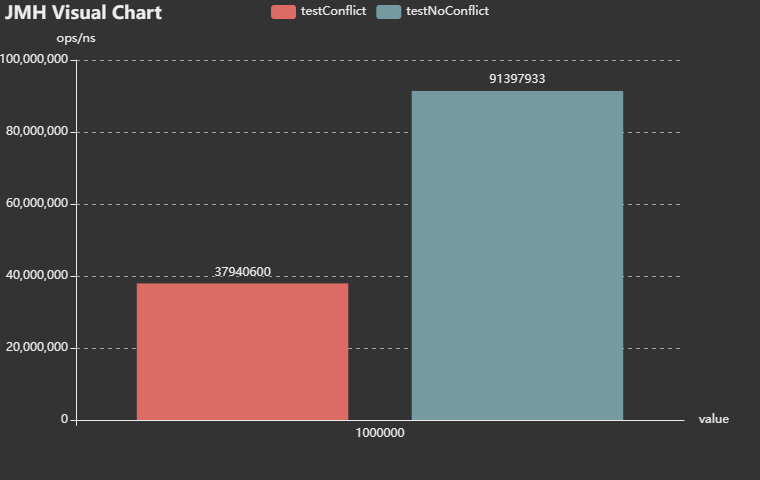
可以看到,間接證實了以上的猜想。
當然這裡的程式碼可能並不嚴謹,也歡迎大家一起討論。
4.2 jdk1.8版本,雜湊衝突嚴重下的get效率測試
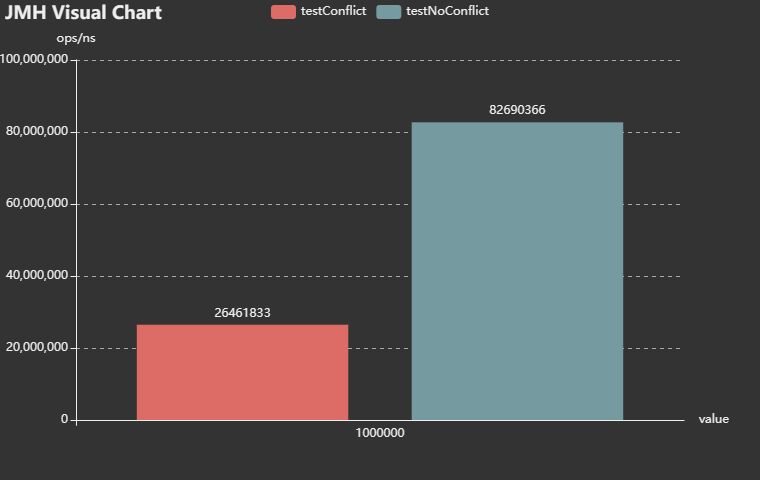
測試結果說明:在jdk8,無衝突效率是有有衝突的3倍左右。
4.3 將jdk版本降為1.7,在雜湊衝突依然嚴重的情況下,get效率如何?
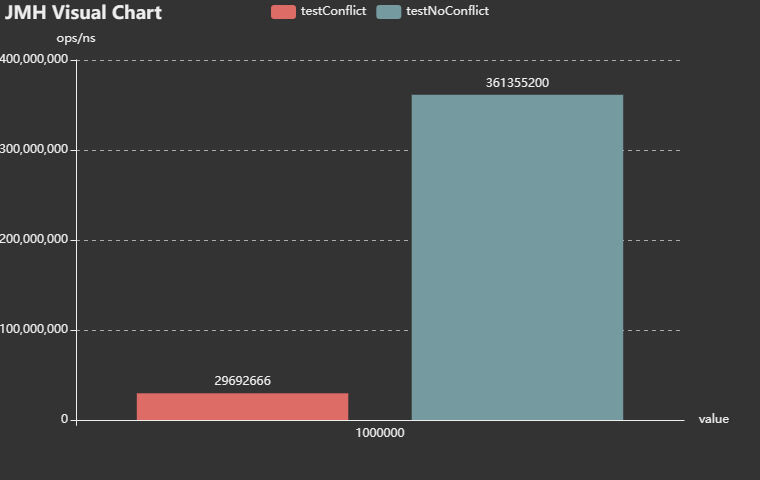
測試結果說明:在jdk7,無衝突效率是有有衝突的12倍左右。
結合4.1和4.2的測試對比,說明jdk1.8紅黑樹的優化效率確實提升很大。
5.總結
1.初始化的時候指定長度,長度要考慮到負載因子0.75.初始化的影響受到雜湊衝突的影響,沒有那麼大(相對於倍數而言),但也不小。
2.雜湊衝突嚴重時,put效能急劇下降。(幾十倍級)
3.相同元素個數的前提下,在雜湊衝突時,get效率反而更高。
4.相比之前的版本,雜湊衝突嚴重時,jdk8紅黑樹對get效率有非常大的提升。
測試程式碼和測試結果在 這裡