1.5萬字長文:從 C# 入門 Kafka
作者:痴者工良
部落格園:https://www.cnblogs.com/whuanle/
本教學地址:https://kafka.whuanle.cn/
本教學是關於 Kafka 知識的教學,從 C# 中實踐編寫 Kafka 程式,一邊寫程式碼一邊瞭解 Kafka。
1, 搭建 Kafka 環境
本章的內容比較簡單,我們將使用 Docker 快速部署一個單節點的 Kafka 或 Kafka 叢集,在後面的章節中,將會使用已經部署好的 Kafka 範例做實驗,然後我們通過不斷地實驗,逐漸瞭解 Kafka 的知識點以及掌握使用者端的使用。
這裡筆者給出了單機和叢集兩種部署方式,但是為了便於學習後面的章節,請以叢集的方式部署 Kafka。
安裝 docker-compose
使用 docker-compose 部署 Kafka 可以減少很多沒必要的麻煩,一個指令碼即可完成部署,省下折騰時間。
安裝 docker-compose 也是挺簡單的,直接下載二進位制可執行檔案即可。
INSTALLPATH=/usr/local/bin
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o ${INSTALLPATH}/docker-compose
sudo chmod +x ${INSTALLPATH}/docker-compose
docker-compose --version
如果系統沒有對映
/usr/local/bin/路徑,執行命令完成後,如果發現找不到docker-compose命令,請將檔案下載到/usr/bin,即替換INSTALLPATH=/usr/local/bin為INSTALLPATH=/usr/bin。
單節點 Kafka 的部署
建立一個 docker-compose.yml 檔案,檔案內容如下:
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:7.3.0
container_name: broker
ports:
# To learn about configuring Kafka for access across networks see
# https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
- "9092:9092"
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_INTERNAL:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.156:9092,PLAINTEXT_INTERNAL://broker:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
volumes:
- /data/kafka/broker/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock
請替換
PLAINTEXT://192.168.3.156中的 IP 。
然後執行命令開始部署應用:
docker-compose up -d
接著,安裝 kafdrop,這是一個 Kafka 管理介面,可以很方便地檢視一些資訊。
docker run -d --rm -p 9000:9000 \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e KAFKA_BROKERCONNECT=192.168.3.156:9092 \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop
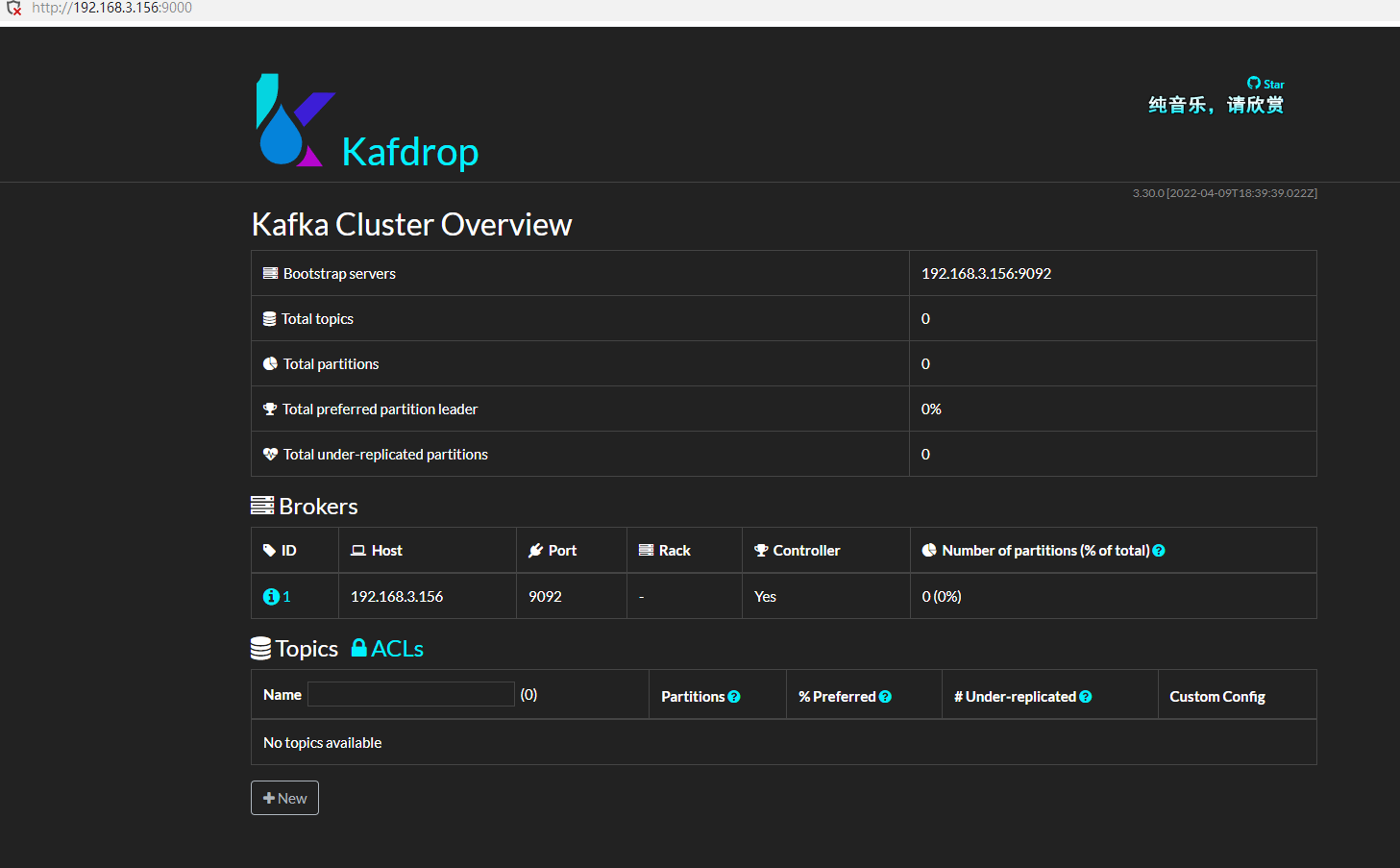
Kafka 叢集的部署
Kafka 叢集的部署方法有很多,方法不盡相同,其中使用的設定引數(環境變數)也很多,這裡筆者只給出自己在使用的快速部署引數,讀者可以參閱官方檔案,以便客製化設定。
筆者的部署指令碼中其中一些重要的環境變數說明如下:
KAFKA_BROKER_ID: 當前 Broker 範例的 id,Broker id 不能重複;KAFKA_NUM_PARTITIONS:預設 Topic 的分割區數量,預設為 1,如果設定了這個設定,自動建立的 Topic 會根據這個大小設定分割區數量。KAFKA_DEFAULT_REPLICATION_FACTOR:預設 Topic 分割區的副本數;KAFKA_ZOOKEEPER_CONNECT:Zookeeper 地址;KAFKA_LISTENERS:Kafka Broker 範例監聽的 ip;KAFKA_ADVERTISED_LISTENERS:外部如何存取當前範例,用於 Zookeeper 監控;
建立一個 docker-compose.yml 檔案,檔案內容如下:
---
version: '3'
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.3.0
container_name: zookeeper
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka1:
image: confluentinc/cp-kafka:7.3.0
container_name: broker1
ports:
- 19092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_NUM_PARTITIONS: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.158:19092
volumes:
- /data/kafka/broker1/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock
kafka2:
image: confluentinc/cp-kafka:7.3.0
container_name: broker2
ports:
- 29092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 2
KAFKA_NUM_PARTITIONS: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.158:29092
volumes:
- /data/kafka/broker2/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock
kafka3:
image: confluentinc/cp-kafka:7.3.0
container_name: broker3
ports:
- 39092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 3
KAFKA_NUM_PARTITIONS: 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 2
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://192.168.3.158:39092
volumes:
- /data/kafka/broker3/logs:/opt/kafka/logs
- /var/run/docker.sock:/var/run/docker.sock
由於三個 Broker 範例都在同一個虛擬機器器上面,因此這裡通過暴露不同的埠,避免 Broker 衝突。
然後執行命令開始部署應用:
docker-compose up -d
接著部署 kafdrop:
docker run -d --rm -p 9000:9000 \
-e JVM_OPTS="-Xms32M -Xmx64M" \
-e KAFKA_BROKERCONNECT=192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092 \
-e SERVER_SERVLET_CONTEXTPATH="/" \
obsidiandynamics/kafdrop
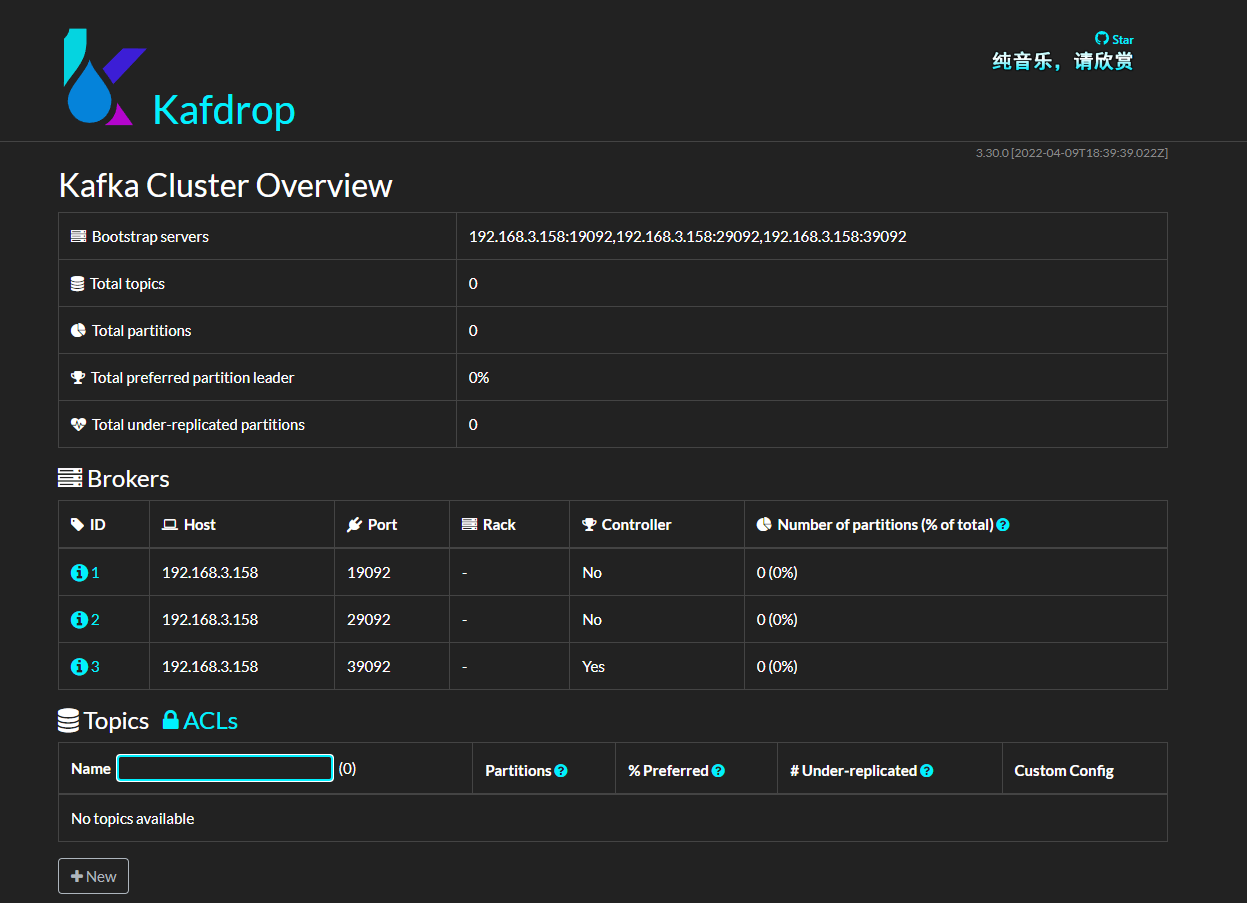
現在,已經部署好了 Kafka 環境以及管理面板。
2, Kafka 概念
在本章中,筆者會介紹 Kafka 的一些基本概念,文中的內容是筆者個人理解總結,可能會有錯誤或其它問題,如有疑問,歡迎指出。
基本概念
一個簡單的 生產訊息 -> 儲存到 Broker -> 消費訊息 的結構圖範例如下:
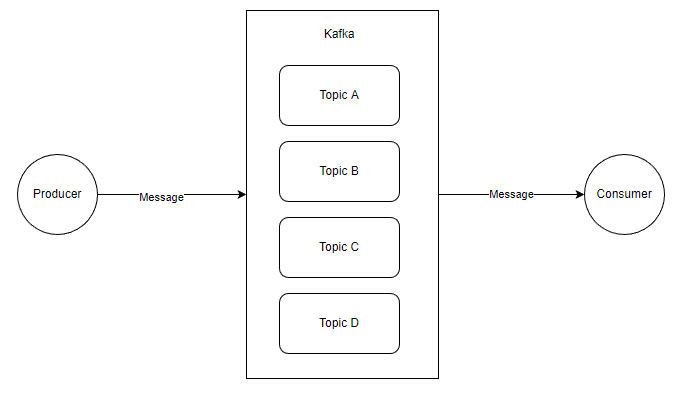
在這裡,出現了四個物件:
生產者 Producer:產生 Message 的使用者端;
消費者 Consumer :消費 Message 的使用者端;
主題 Topic:邏輯上的東西;
訊息 Message: 資料實體;
當然圖中每一個物件本身都是很複雜的,這裡為了便於學習,畫了個簡單的圖,現在我們先從最簡單的結構圖開始瞭解這些東西。
這裡的圖比較簡單,大概是這樣的, Kafka 中有多個 Topic,Producer 可以向指定的 Topic 生產一條訊息,而 Consumer 可以消費指定 Topic 的訊息。
Producer 和 Consumer 都是使用者端應用,只是在執行的功能上有所區分,理論上 Kafka 的使用者端庫都是將兩者的程式碼寫在同一個模組,例如 C# 的 confluent-kafka-dotnet,同時具有生產者和消費者的 API。
然後就是這個 Message 了,Message 主要結構是:
Key
Value
其它後設資料
其中 Value 是我們自定義訊息內容的地方。
關於 Message,我們這裡簡單瞭解即可,在後面的章節中會繼續深入介紹。
在 Kafka 中,每個 Kafka 範例稱為 Broker,每個 Broker 中可以儲存多個 Topic。每個 Topic 可以劃分為多個分割區,每個分割區儲存的資料是不一樣的,這些分割區可以在同一個 Broker 中,也可以在散佈在不同的 Broker 中。
一個 Broker 可以儲存不同 Topic 的不同分割區,也可以儲存同一個 Topic 的不同分割區。
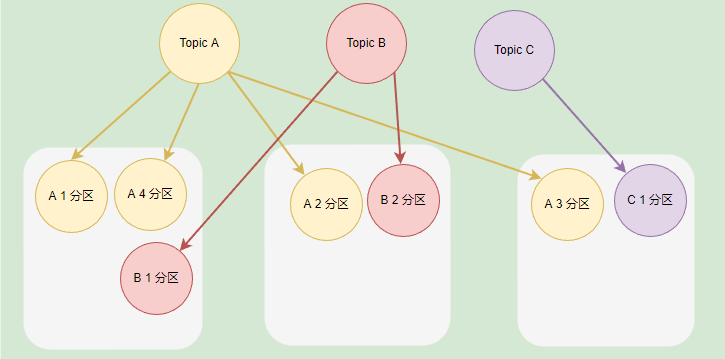
如果一個 Topic 有多個分割區,一般來說其並行量會有所提高,通過增加分割區數實現叢集的負載均衡,一般情況下,分割區均衡需要散佈在不同的 Broker 才能合理地負載均衡,不然分割區都在同一個 Broker 時,瓶頸在單個機器上。
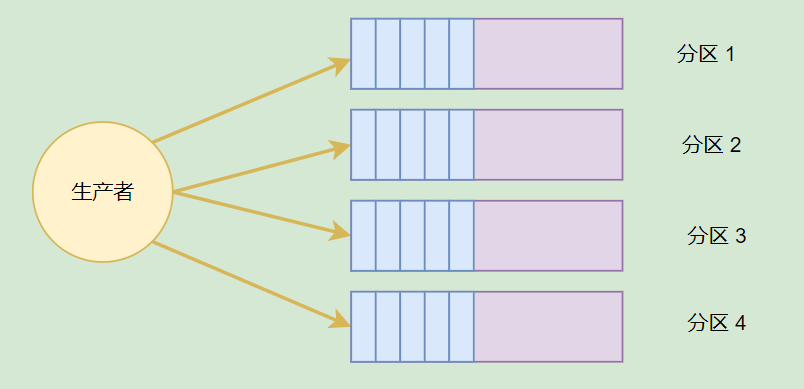
如果 Broker 的範例比較少,但是 Topic 劃分了多個分割區,那麼這些分割區會被部署到同一個 Broker 上。
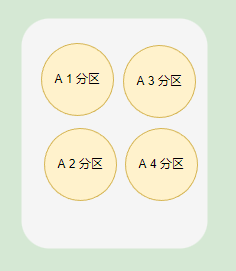
主題分割區可以有效提高生產者或消費者的並行量,因為將訊息分別儲存到不同的分割區中,可以同時往多個分割區推播訊息,會比只向一個分割區推播訊息的速度快。
前面提到,每個 Message 都有 Key 和 Value,Topic 可以根據 Message 的 Key 將一個 Message 儲存到不同的分割區。當然,我們也可以在生產訊息的時候,指定向一個分割區推播訊息。
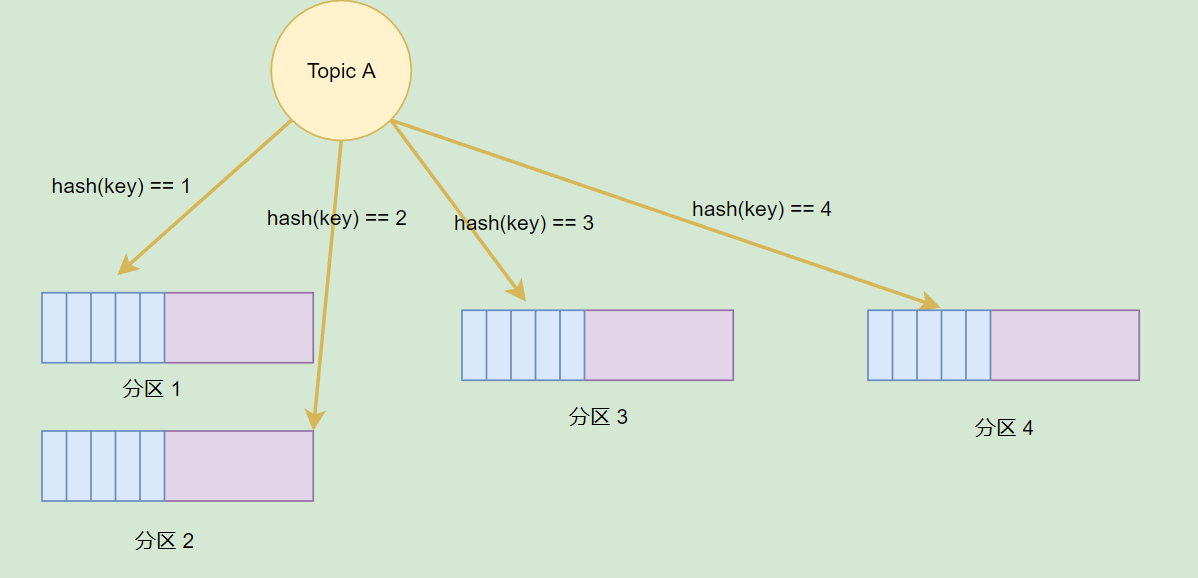
分割區可以提高並行,但是如果一個 Broker 掛了,資料便會丟失,怎麼辦?
在 Kafka 中,分割區可以設定多個分割區副本,這些副本跟分割區並不在同一個 Broker 上,這個當 Broker 掛了後,這些分割區可以利用副本在其它 Broker 上覆活。
[info] 提示
在 《Kafka權威指南(第2版)》 的 21 頁中,指導瞭如何合理設定分割區數量,以及分割區的優勢和缺點。
關於 Kafka 指令碼工具
前面介紹了 Kafka 的一些簡單概念,為了更加好地瞭解 Kafka,我們可以利用 Kafka 的指令碼做一些實驗。
開啟其中一個 Kafka 容器(docker exec 命令進入容器),然後執行命令檢視自帶的二進位制指令碼:
ls -lah /usr/bin/ | grep kafka
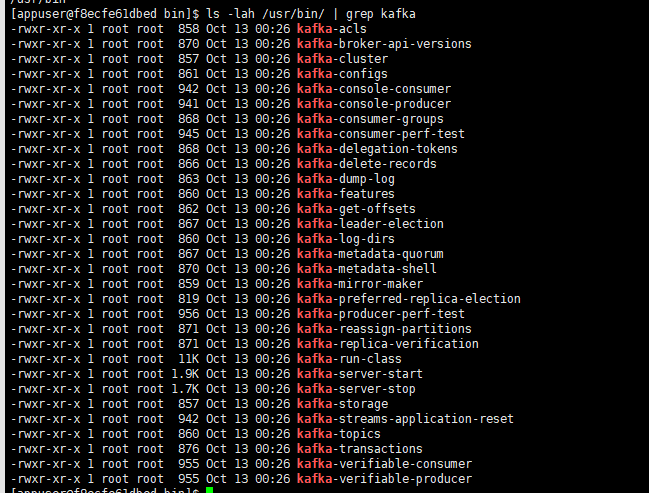
可以看到,裡面有很多 CLI 工具,每種 CLI 工具說明檔案可以到這裡檢視:
https://docs.cloudera.com/runtime/7.2.10/kafka-managing/topics/kafka-manage-basics.html
下面筆者介紹部分 CLI 工具的使用方法。
主題管理
kafka-topics 是用於主題管理的 CLI 工具,kafka-topics 提供基本操作如下所示:
- 操作:
--create:建立主題;--alter:變更這個主題,修改分割區數等;--config:修改主題相關的設定;--delete:刪除該主題;
在管理主題時,我們可以設定主題設定,主題設定儲存時,其格式範例為 default.replication.factor ,如果用 CLI 工具操作,那麼傳遞的引數範例為 --replication-factor,因此我們通過不同工具操作主題時,引數名稱可能不同一樣。
主題的所有設定引數可以檢視官方檔案:
kafka-topics 一些常用引數:
-
--partitions:分割區數量,該主題劃分成多少個分割區; -
--replication-factor:副本數量,表示每個分割區一共有多少個副本;副本數量需要小於或等於 Broker 的數量; -
--replica-assignment:指定副本分配方案,不能與--partitions或--replication-factor同時使用; -
--list: 列出有效的主題; -
--describe:查詢該主題的資訊資訊。
下面是使用 CLI 手工建立主題的命令,建立主題時設定分割區、分割區副本。
kafka-topics --create --bootstrap-server 192.168.3.158:19092 \
--replication-factor 3 \
--partitions 3 \
--topic hello-topic

使用 CLI 時,可以通過
--bootstrap-server設定連線到一個 Kafka 範例,或者通過--zookeeper連線到 Zookeeper,然後 CLI 自動找到 Kafka 範例執行命令。
檢視主題的詳細資訊:
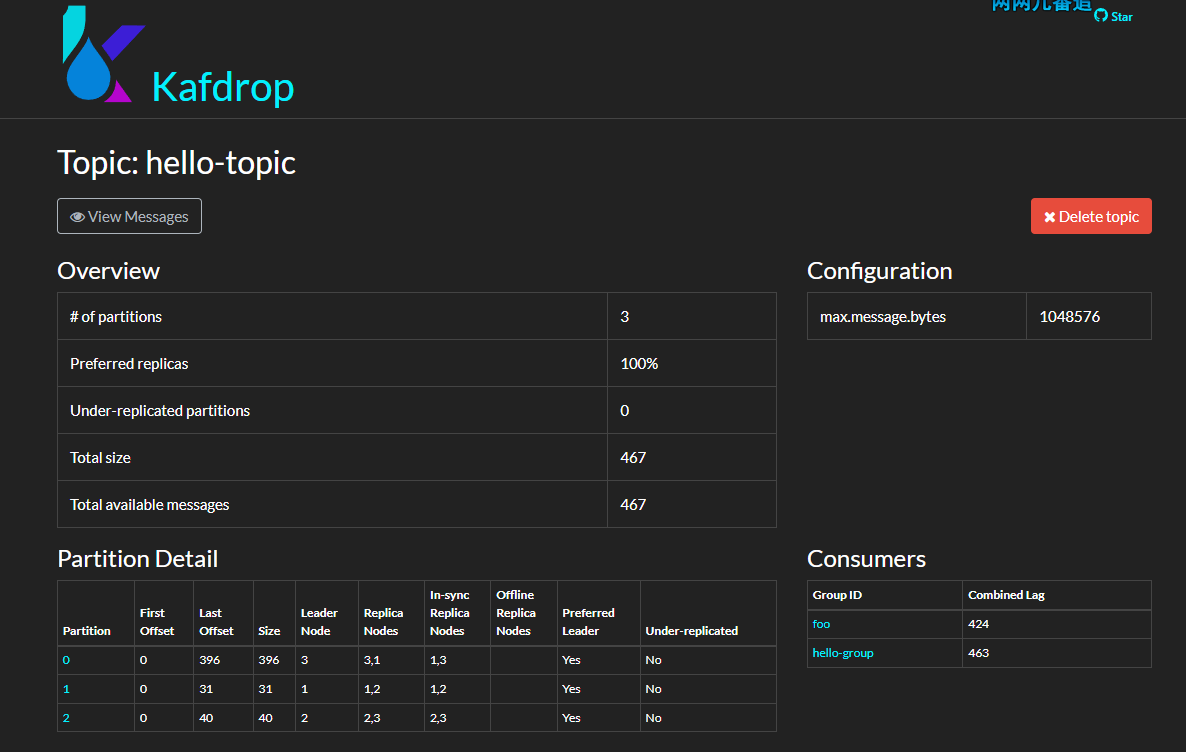
kafka-topics --describe --bootstrap-server 192.168.3.158:19092 --topic hello-topic
Topic: hello-topic TopicId: r3IlKv8BSMaaoaT4MYG8WA PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: hello-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: hello-topic Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: hello-topic Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
可以看到,建立的分割區會被均衡分佈到不同的 Broker 範例中;對於 Replicas 這些東西,我們後面的章節再討論。
也可以開啟 kafdrop 檢視主題的資訊。
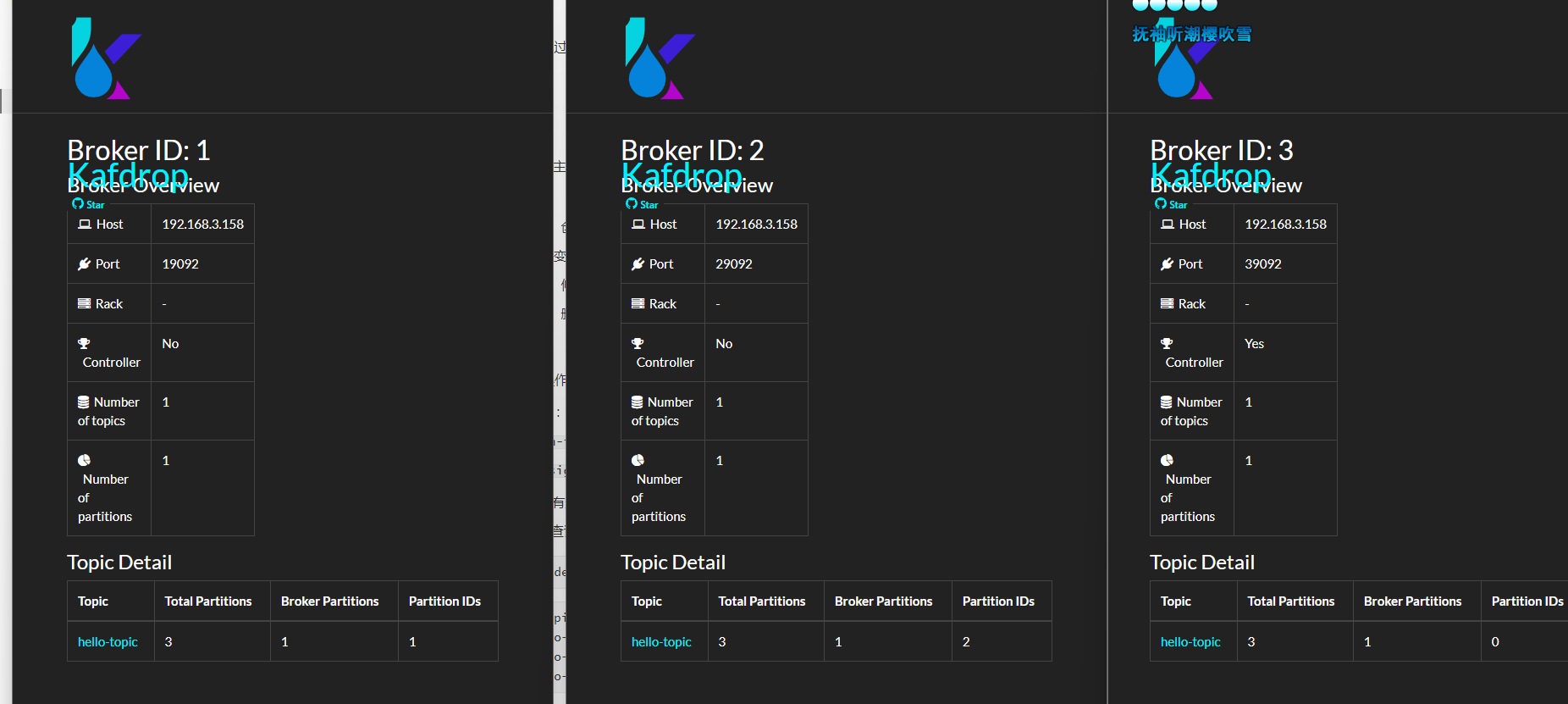
如果一個 Topic 的分割區數量大於 Broker 數量呢?前面筆者已經提到,如果分割區數量比較大時,部分 Broker 中會存在同一個主題的多個分割區。
下面我們來實驗驗證一下:
kafka-topics --create --bootstrap-server 192.168.3.158:19092 \
--replication-factor 2 \
--partitions 4 \
--topic hello-topic1
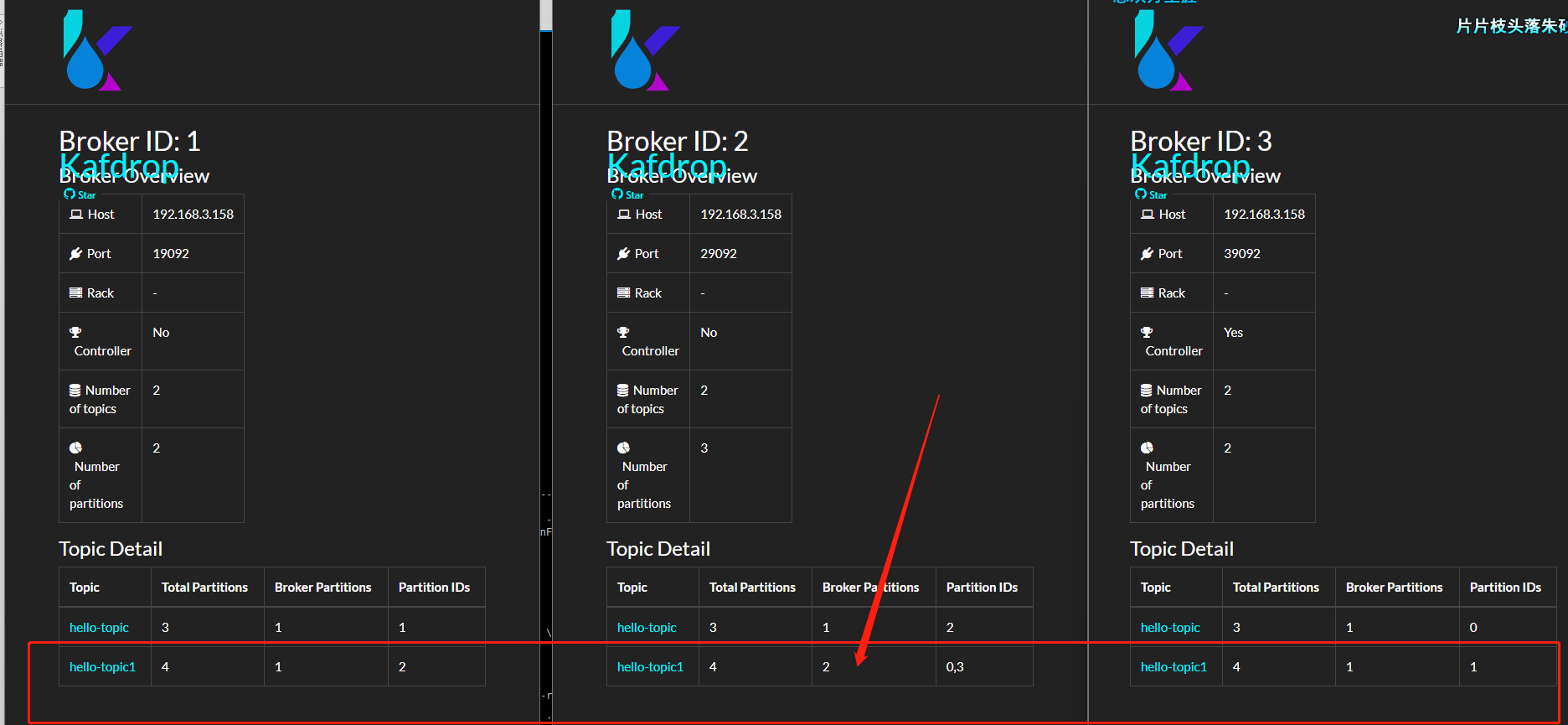
可以看到,Broker 2,分到了 hello-topic1 的兩個分割區。
使用 C# 建立分割區
使用者端庫中可以利用介面管理主題,如 C# 的 confluent-kafka-dotnet,使用 C# 程式碼建立 Topic 的範例如下:
static async Task Main()
{
var config = new AdminClientConfig
{
BootstrapServers = "192.168.3.158:19092"
};
using (var adminClient = new AdminClientBuilder(config).Build())
{
try
{
await adminClient.CreateTopicsAsync(new TopicSpecification[] {
new TopicSpecification { Name = "hello-topic2", ReplicationFactor = 3, NumPartitions = 2 } });
}
catch (CreateTopicsException e)
{
Console.WriteLine($"An error occured creating topic {e.Results[0].Topic}: {e.Results[0].Error.Reason}");
}
}
}
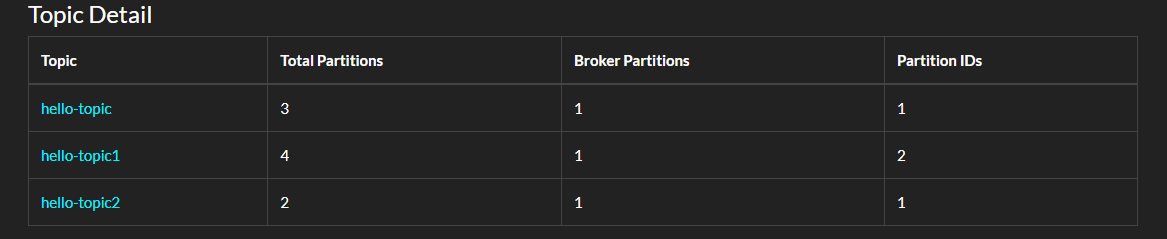
在 AdminClient 中還有很多方法可以探索。
分割區與複製
在前面,我們建立了一個名為 hello-topic 的主題,並且為其設定三個分割區,三個副本。
接著,使用 kafka-topics --describe 命令檢視一個 Topic 的資訊,可以看到:
Topic: hello-topic TopicId: r3IlKv8BSMaaoaT4MYG8WA PartitionCount: 3 ReplicationFactor: 3 Configs:
Topic: hello-topic Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: hello-topic Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: hello-topic Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2這些數位都是指 Broker ID,Broker ID 可以是數位也可以是有英文。
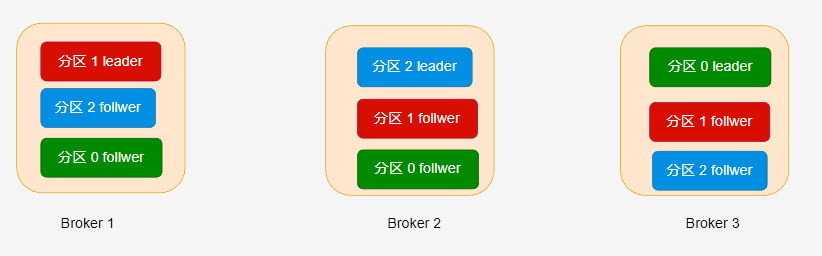
主題的每個分割區都有至少一個副本,也就是 --replication-factor 引數必須設定大於大於 1。副本分為 leader 和 follwer 兩種,每個副本都需要消耗一個儲存空間,leader 對外提供讀寫訊息,而 follwer 提供冗餘備份,leader 會及時將訊息增量同步到所有 follwer 中。
Partition: 0 Leader: 3 Replicas: 3,1,2 表示分割區 0 的副本分佈在 ID 為 3、1、2 的 Kafka broker 中。
在 hello-topic 主題中,當分割區只有一個副本時,或只關注 leader 副本時,leader 副本對應的 Broker 節點位置如下:
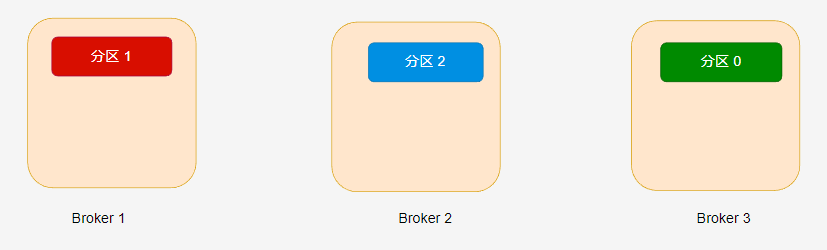
Kafka 分配分割區到不同的節點有一定的規律,感興趣的讀者可參考 《Kafka 權威指南》第二版或官方檔案。
如果設定了多個副本( --replication-factor=3 ) 時,leader 副本和 follwer 副本的位置如下所示:
分割區的副本數量不能大於 Broker 數量,每個 Broker 只能有此分割區的一個副本,副本數量範圍必須在
[1,{Broker數量}]中。也就是說,如果叢集只有三個 Broker,那麼建立的分割區,其副本數量必須在[1,3]範圍內。
在不同的副本中,只有 leader 副本能夠進行讀寫,follwer 接收從 leader 推播過來的資料,做好冗餘備份。
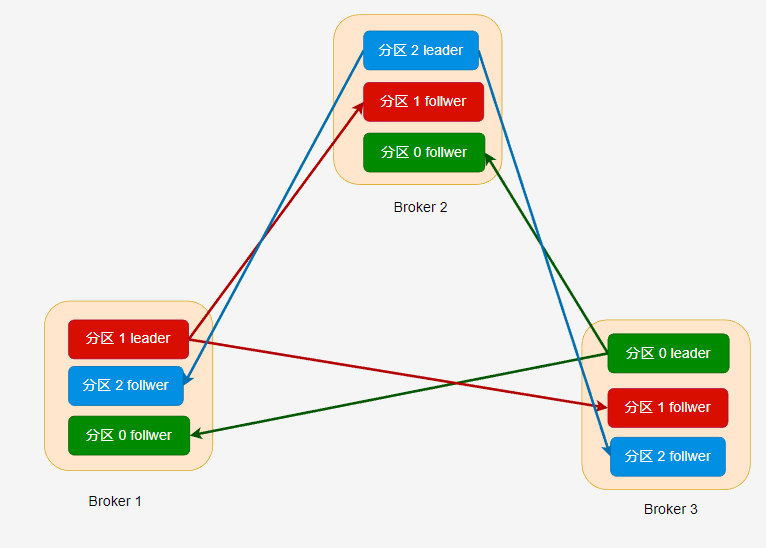
一個分割區的所有副本統稱為 AR(Assigned Repllicas),當 leader 接收到訊息時,需要推播到 follwer 中,理想情況下,分割區的所有副本的資料都是一致的。
但是 leader 同步到 follwer 的過程中可能會因為網路擁堵、故障等,導致 follwer 在一定時間內未能與 leader 中的資料一致(同步滯後),那麼這些副本稱為 OSR( Out-Sync Relipcas)。
如果副本中的資料為最新的資料,在給定的時間內同步沒有出現滯後,那麼這些副本稱為 ISR。
AR = ISR + OSR
如果 leader 故障,那麼剩下的 follwer 會重新選舉 一個 leader;但是如果 leader 接收到生產者的訊息後還沒有同步到 follwer 就故障了,那麼這些訊息就會丟失。為了避免這種情況,需要生產者設定合理的 ACK,在第四章中會討論這個問題。
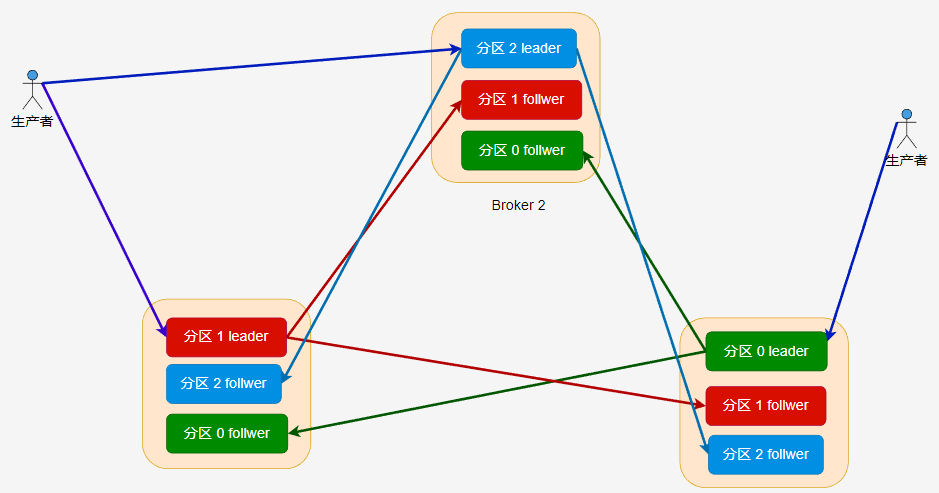
生產者消費者
kafka-console-producer 可以給指定的主題傳送訊息:
kafka-console-producer --bootstrap-server 192.168.3.158:19092 --topic hello-topic

kafka-console-consumer 則可以從指定主題接收訊息:
kafka-console-consumer --bootstrap-server 192.168.3.158:19092 --topic hello-topic \
--group hello-group \
--from-beginning

訂閱主題時,消費者需要指定消費者組。可以通過 --group 指定;如果不指定,指令碼會自動為我們建立一個消費者組。
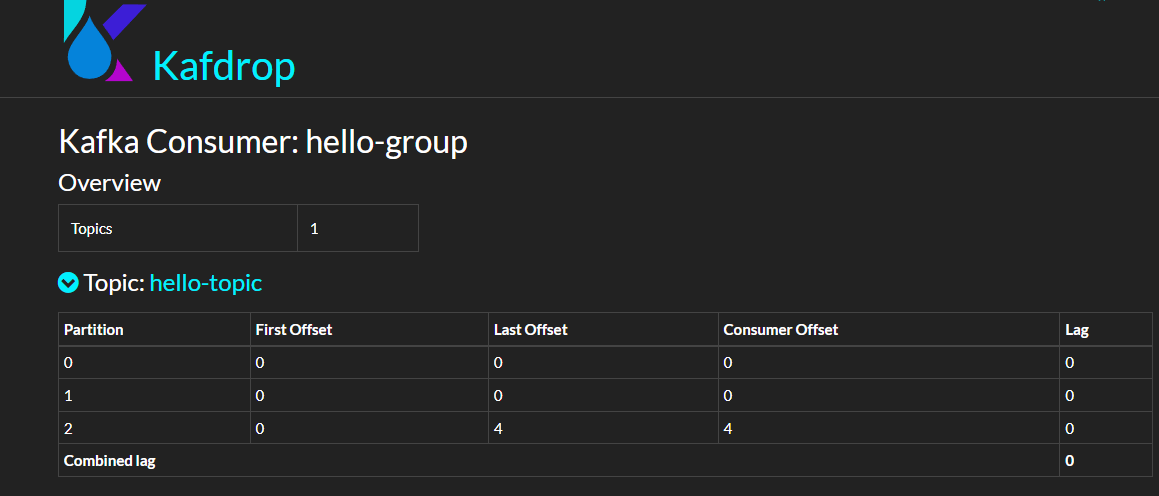
kafka-consumer-groups 則可以為我們管理消費者組,例如檢視所有的消費者組:
kafka-consumer-groups --bootstrap-server 192.168.3.158:19092 --list

檢視消費者組詳細資訊:
kafka-consumer-groups --bootstrap-server 192.168.3.158:19092 --describe --group hello-group

當然,也可以從 Kafdrop 介面中檢視消費者組的資訊。
這些引數我們現在可以先跳過。
C# 部分並沒有重要的內容要說,程式碼可以參考:
static async Task Main()
{
var config = new AdminClientConfig
{
BootstrapServers = "192.168.3.158:19092"
};
using (var adminClient = new AdminClientBuilder(config).Build())
{
var groups = adminClient.ListGroups(TimeSpan.FromSeconds(10));
foreach (var item in groups)
{
Console.WriteLine(item.Group);
}
}
}
對於消費者組來說,我們需要關注以下引數:
-
state:消費者組的狀態; -
members:消費者組成員; -
offsets: ACK 偏移量;
修改設定
可以使用 kafka-configs 工具設定、描述或刪除主題屬性。
檢視主題屬性描述:
kafka-configs --bootstrap-server [HOST:PORT] --entity-type topics --entity-name [TOPIC] --describe
kafka-configs --bootstrap-server 192.168.3.158:19092 --entity-type topics --entity-name hello-topic --describe

使用 --alter 引數後,可以新增、修改或刪除主題屬性,命令格式:
kafka-configs --bootstrap-server [HOST:PORT] --entity-type topics --entity-name [TOPIC] --alter --add-config [PROPERTY NAME]=[VALUE]
kafka-configs --bootstrap-server [HOST:PORT] --entity-type topics --entity-name [TOPIC] --alter --delete-config [PROPERTY_NAME]
例如 Kafka 預設限制傳送的訊息最大為 1MB,為了修改這個限制,可以使用以下命令:
kafka-configs --bootstrap-server 192.168.3.158:19092 --entity-type topics --entity-name hello-topic --alter --add-config 'max.message.bytes=1048576'

其中還有很多引數,請參考:
https://kafka.apache.org/10/documentation.html
此外,我們還可以通過 kafka-configs 檢視 Broker 的設定:
kafka-configs --bootstrap-server 192.168.3.158:19092 --describe --broker 1
3, Kafka .NET 基礎
在第一章中,筆者介紹瞭如何部署 Kafka;在第二章中,筆者介紹了 Kafka 的一些基礎知識;在本章中,筆者將介紹如何使用 C# 編寫程式連線 kafka,完成生產和消費過程。
在第二章的時候,我們已經使用到了 confluent-kafka-dotnet ,通過 confluent-kafka-dotnet 編寫程式碼呼叫 Kafka 的介面,去管理主題。
confluent-kafka-dotnet 其底層使用了一個 C 語言編寫的庫 librdkafka,其它語言編寫的 Kafka 使用者端庫也是基於 librdkafka 的,基於 librdkafka 開發使用者端庫,官方可以統一維護底層庫,不同的程式語言可以複用程式碼,還可以利用 C 語言編寫的庫提升效能。
此外,因為不同的語言都使用了相同的底層庫,也使用了相同的介面,因此其編寫的使用者端庫介面看起來也會十分接近。大多數情況下,Java 和 C# 使用 Kafka 的程式碼是比較相近的。
接著說一下 confluent-kafka-dotnet,Github 倉庫中對這個庫的其中一個特點介紹是:
- High performance : confluent-kafka-dotnet 是一個輕量級的程式包裝器,它包含了一個精心調優的 C 語言寫的 librdkafka 庫。
Library dkafka 是 Apache Kafka 協定的 C 庫實現,提供了 Producer、 Consumer 和 Admin 使用者端。它的設計考慮到資訊傳遞的可靠性和高效能,目前的效能超過 100萬條訊息/秒 的生產和 300萬條訊息/秒 的消費能力(原話是:current figures exceed 1 million msgs/second for the producer and 3 million msgs/second for the consumer)。
現在,這麼牛逼的東西,到 nuget 直接搜尋 Confluent.Kafka 即可使用。
迴歸正題,下面筆者將會介紹如果使用 C# 編寫生產者、消費者程式。在本章中,我們只需要學會怎麼用就行,大概瞭解過程,而不必深究引數設定,也不必細究程式碼的功能或作用,在後面的章節中,筆者會詳細介紹的。
生產者
編寫生產者程式大概可以分為兩步,第一步是定義 ProducerConfig 設定,裡面是關於生產者的各種設定,例如 Broker 地址、釋出訊息重試次數、緩衝區大小等;第二步是定義釋出訊息的過程。例如要釋出什麼內容、如何記錄錯誤訊息、如何攔截異常、自定義訊息分割區等。
下面是生產者程式碼的範例:
using Confluent.Kafka;
using System.Net;
public class Program
{
static void Main()
{
var config = new ProducerConfig
{
BootstrapServers = "host1:9092",
...
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
...
}
}
}
如果要將訊息推播到 Kafka,那麼程式碼是這樣寫的:
var result = await producer.ProduceAsync("weblog", new Message<Null, string> { Value="a log message" });
Value就是訊息的內容。其實一條訊息的結構比較複雜的,除了 Value ,還有 Key 和各種後設資料,這個在後面的章節中我們再討論。
下面是釋出一條訊息的實際程式碼範例:
using Confluent.Kafka;
using System.Net;
public class Program
{
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
var result = await producer.ProduceAsync("weblog", new Message<Null, string> { Value = "a log message" });
}
}
}
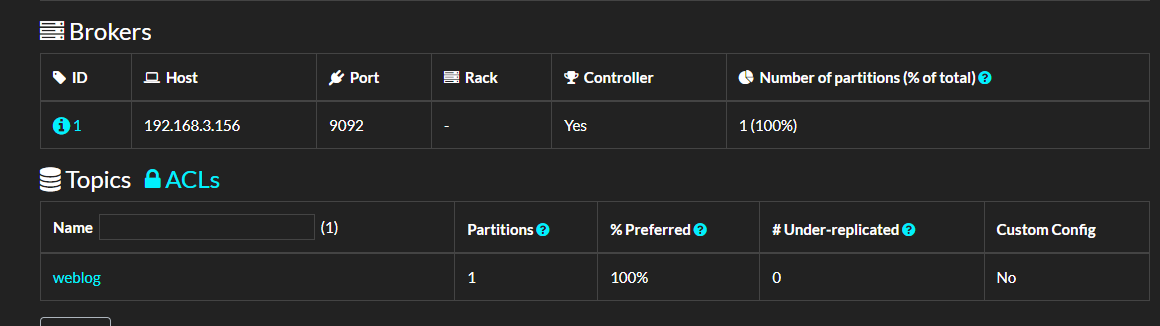
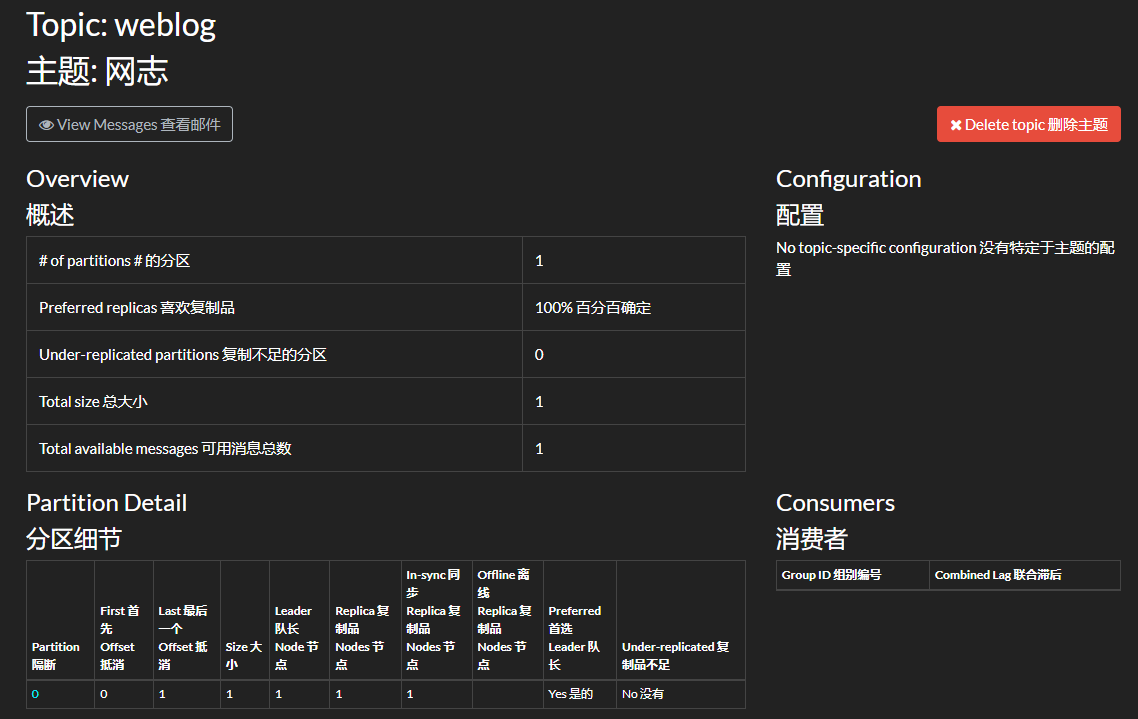
執行這段程式碼後,可以開啟 kafdrop 面板檢視主題資訊。
如果我們斷點偵錯 ProduceAsync 後的內容,可以看到有比較多的資訊,例如:
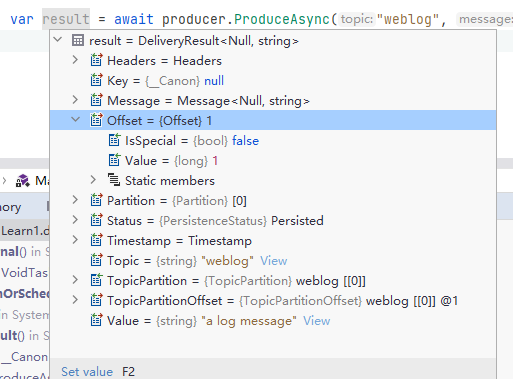
這些資訊記錄了當前訊息是否被 Broker 接收並確認(ACK),該條訊息被推播到哪個 Broker 的哪個分割區中,訊息偏移量數值又是什麼。
當然,這裡暫時不需要關注這個。
批次生產
這一節中,我們來了解如何通過程式碼批次推播訊息到 Broker。
下面是程式碼範例:
using Confluent.Kafka;
using System.Net;
public class Program
{
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int i = 0; i < 10; ++i)
{
producer.Produce("my-topic", new Message<Null, string> { Value = i.ToString() }, handler);
}
}
// 幫忙程式自動退出
Console.ReadKey();
}
public static void handler(DeliveryReport<Null, string> r)
{
Console.WriteLine(!r.Error.IsError
? $"Delivered message to {r.TopicPartitionOffset}"
: $"Delivery Error: {r.Error.Reason}");
}
}
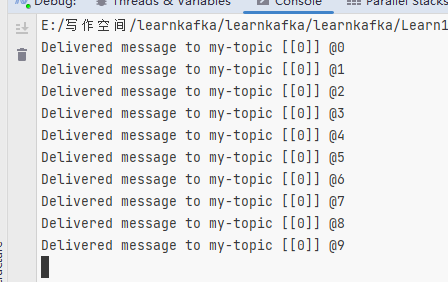
可以看到,這裡批次推播訊息使用了 Produce,而之前我們使用的非同步程式碼用了 ProduceAsync。
其實兩者都是非同步的,但是 Product 方法更直接地對映到底層的 librdkafka API,能夠利用 librdkafka 中高效能的介面批次推播訊息。而 ProduceAsync 則是 C# 實現的非同步,相對來說Product 的開銷小一些,但是 ProduceAsync 仍然非常高效能——在典型的硬體上每秒能夠產生數十萬條訊息
如果說最最直觀的差異,那麼就是兩者的返回結果。
從定義來看:
Task<DeliveryResult<TKey, TValue>> ProduceAsync(string topic, Message<TKey, TValue> message, ...);
void Produce(string topic, Message<TKey, TValue> message, Action<DeliveryReport<TKey, TValue>> deliveryHandler = null);
ProduceAsync 可以直接獲得 Task,然後通過等待 Task 獲取響應結果。
而 Produce 並不能直接獲得結果,而是通過回撥方式獲取推播結果,由 librdkafka 執行回撥。
由於 Produce 是框架底層非同步的,但是沒有 Task,所以不能 await ,為了避免在批次訊息處理完成之前,producer 生命週期結束了,所以需要使用 producer.Flush(TimeSpan.FromSeconds(10)) 這樣的程式碼等待批次訊息完成推播。
呼叫 Flush 方法可使所有緩衝記錄立即可用於傳送,並在與這些記錄關聯的請求完成時發生阻塞。
Flush 有兩個過載:
int Flush(TimeSpan timeout);
void Flush(CancellationToken cancellationToken = default(CancellationToken));
int Flush() 會等待指定的時間,如果時間到了,佇列中的訊息只傳送一部分,那麼會返回沒成功傳送的訊息數量。
範例程式碼如下:
using Confluent.Kafka;
using System.Net;
public class Program
{
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
for (int i = 0; i < 10; ++i)
{
producer.Produce("my-topic", new Message<Null, string> { Value = i.ToString() }, handler);
}
// 只等待 10s
var count = producer.Flush(TimeSpan.FromSeconds(10));
// 或者使用
// void Flush(CancellationToken cancellationToken = default(CancellationToken));
}
// 不讓程式自動退出
Console.ReadKey();
}
public static void handler(DeliveryReport<Null, string> r)
{
Console.WriteLine(!r.Error.IsError
? $"Delivered message to {r.TopicPartitionOffset}"
: $"Delivery Error: {r.Error.Reason}");
}
}
如果將 Kafka 服務停止,使用者端肯定是不能推播訊息的,那麼我們在使用批次推播程式碼時會有什麼現象呢?
這裡可以停止所有 Broker 或者給 BootstrapServers 引數設定一個錯誤的地址,然後啟動程式,會發現 producer.Flush(TimeSpan.FromSeconds(10)); 會等待 10s,但是此時 handler 不會起效。
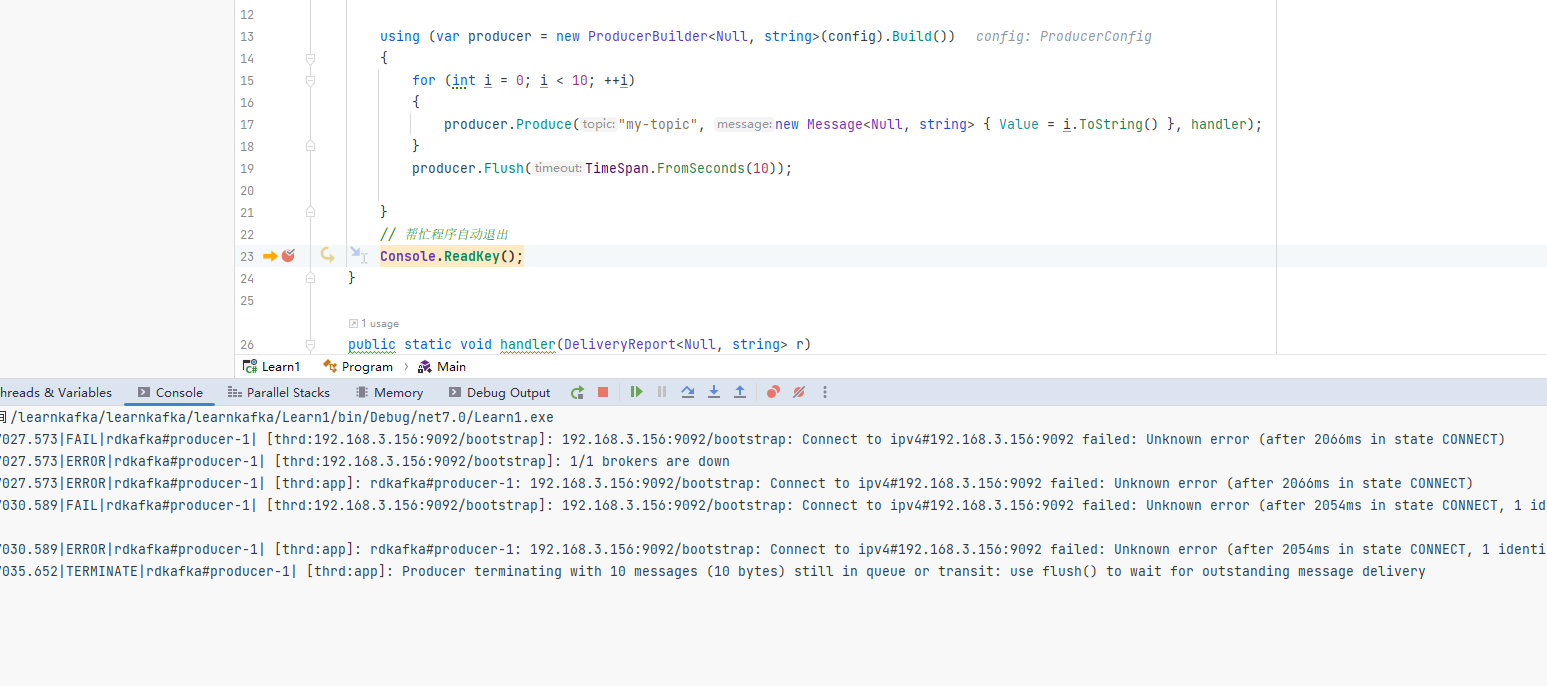
可以看到,如果使用批次訊息,需要注意使用 Flush,即使連線不上 Broker,程式也不會報錯。
所以我們使用批次訊息時,一定要注意與 Broker 的連線狀態,以及處理 Flush 返回的失敗數量。
var result = producer.Flush(TimeSpan.FromSeconds(10));
Console.WriteLine(result);

使用 Tasks.WhenAll
前面提到了使用 Produce 方法來批次推播訊息,除了框架本身的批次提交,我們也可以利用 Tasks.WhenAll 來實現批次提交獲取返回結果,不過效能並沒有 produce - Flush 好。
範例程式碼如下:
using (var producer = new ProducerBuilder<Null, string>(config).Build())
{
List<Task> tasks = new();
for (int i = 0; i < 10; ++i)
{
var task = producer.ProduceAsync("my-topic", new Message<Null, string> { Value = i.ToString() });
tasks.Add(task);
}
await Task.WhenAll(tasks.ToArray());
}
如何進行效能測試
produce - Flush 的效能到底有多好呢?
我們可以使用 BenchmarkDotNet 做效能測試,來評估推播不同訊息數量時,消耗的時間和記憶體。由於不同伺服器的 CPU、記憶體、磁碟速度,以及使用者端與伺服器之間的網路頻寬、時延都是影響訊息吞吐量的重要因素,因此有必要編寫程式碼來進行效能測試,來評估使用者端以及伺服器需要多高的效能來執行程式。
範例程式碼如下:
using Confluent.Kafka;
using System.Net;
using System.Security.Cryptography;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Running;
using BenchmarkDotNet.Jobs;
public class Program
{
static void Main()
{
var summary = BenchmarkRunner.Run<KafkaProduce>();
}
}
[SimpleJob(RuntimeMoniker.Net70)]
[SimpleJob(RuntimeMoniker.NativeAot70)]
[RPlotExporter]
public class KafkaProduce
{
// 每批訊息數量
[Params(1000, 10000,100000)]
public int N;
private ProducerConfig _config;
[GlobalSetup]
public void Setup()
{
_config = new ProducerConfig
{
BootstrapServers = "192.168.3.156:9092"
};
}
[Benchmark]
public async Task UseAsync()
{
using (var producer = new ProducerBuilder<Null, string>(_config).Build())
{
List<Task> tasks = new();
for (int i = 0; i < N; ++i)
{
var task = producer.ProduceAsync("ben1-topic", new Message<Null, string> { Value = i.ToString() });
tasks.Add(task);
}
await Task.WhenAll(tasks);
}
}
[Benchmark]
public void UseLibrd()
{
using (var producer = new ProducerBuilder<Null, string>(_config).Build())
{
for (int i = 0; i < N; ++i)
{
producer.Produce("ben2-topic", new Message<Null, string> { Value = i.ToString() }, null);
}
producer.Flush(TimeSpan.FromSeconds(60));
}
}
}
在範例程式碼中,筆者除了記錄時間速度外,也開啟了 GC 記錄。
Ping 伺服器的結果以及 BenchmarkDotNet 效能測試結果如下:
正在 Ping 192.168.3.156 具有 32 位元組的資料:
來自 192.168.3.156 的回覆: 位元組=32 時間=1ms TTL=64
來自 192.168.3.156 的回覆: 位元組=32 時間=2ms TTL=64
來自 192.168.3.156 的回覆: 位元組=32 時間=2ms TTL=64
來自 192.168.3.156 的回覆: 位元組=32 時間=1ms TTL=64
| Method | Job | Runtime | N | Mean | Error | StdDev | Gen0 | Gen1 | Gen2 | Allocated |
|---|---|---|---|---|---|---|---|---|---|---|
| UseAsync | .NET 7.0 | .NET 7.0 | 1000 | 125.1 ms | 2.21 ms | 2.17 ms | - | - | - | 1055.43 KB |
| UseLibrd | .NET 7.0 | .NET 7.0 | 1000 | 124.7 ms | 2.26 ms | 2.12 ms | - | - | - | 359.18 KB |
| UseAsync | NativeAOT 7.0 | NativeAOT 7.0 | 1000 | 124.8 ms | 1.83 ms | 1.62 ms | - | - | - | 1055.43 KB |
| UseLibrd | NativeAOT 7.0 | NativeAOT 7.0 | 1000 | 125.1 ms | 1.76 ms | 1.64 ms | - | - | - | 359.18 KB |
| UseAsync | .NET 7.0 | .NET 7.0 | 10000 | 143.9 ms | 3.70 ms | 10.86 ms | 1250.0000 | 750.0000 | 250.0000 | 10577.22 KB |
| UseLibrd | .NET 7.0 | .NET 7.0 | 10000 | 140.6 ms | 2.74 ms | 4.80 ms | 250.0000 | - | - | 3523.29 KB |
| UseAsync | NativeAOT 7.0 | NativeAOT 7.0 | 10000 | 145.7 ms | 3.25 ms | 9.59 ms | 1250.0000 | 750.0000 | 250.0000 | 10577.22 KB |
| UseLibrd | NativeAOT 7.0 | NativeAOT 7.0 | 10000 | 140.6 ms | 2.78 ms | 5.56 ms | 250.0000 | - | - | 3523.29 KB |
| UseAsync | .NET 7.0 | .NET 7.0 | 100000 | 407.3 ms | 7.17 ms | 9.58 ms | 13000.0000 | 7000.0000 | 2000.0000 | 105185.91 KB |
| UseLibrd | .NET 7.0 | .NET 7.0 | 100000 | 259.7 ms | 5.72 ms | 16.78 ms | 4000.0000 | - | - | 35164.82 KB |
| UseAsync | NativeAOT 7.0 | NativeAOT 7.0 | 100000 | 419.8 ms | 8.31 ms | 13.19 ms | 14000.0000 | 8000.0000 | 2000.0000 | 105194.3 KB |
| UseLibrd | NativeAOT 7.0 | NativeAOT 7.0 | 100000 | 255.3 ms | 6.31 ms | 18.62 ms | 4000.0000 | - | - | 35164.72 KB |
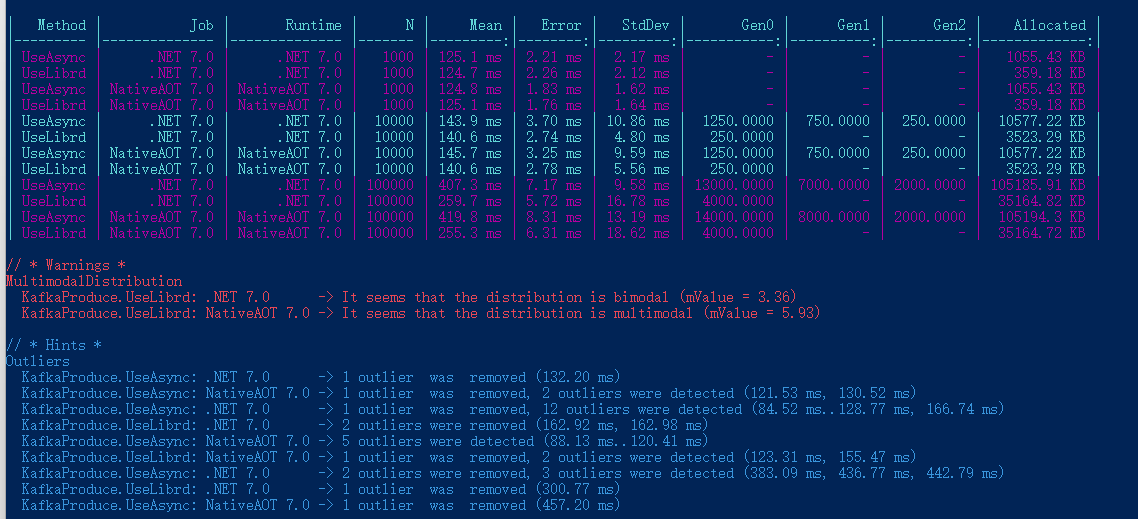
可以看到使用了 librdkafka 批次推播,比使用 Task.WhenAll 效能要好一些,特別是訊息數量比較大的情況下。
不過這個效能測試的結果意義也不大,主要是讓讀者瞭解如何使用 BenchmarkDotNet 進行效能測試,使用者端推播訊息到 Broker,能夠實現每秒多大的負載,以此評估在當前環境下可以承載多大的流量。
消費
生產訊息後,接著編寫消費者程式處理訊息,消費的程式碼分為 ConsumerConfig 設定和消費兩步,其範例程式碼如下:
using System.Collections.Generic;
using Confluent.Kafka;
...
var config = new ConsumerConfig
{
// 這些設定後面的章節中筆者會介紹,這裡跳過。
BootstrapServers = "host1:9092,host2:9092",
GroupId = "foo",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
...
}
消費者設定預設會自動提交確認(ACK),所以消費後不需要編寫程式碼確認訊息,所以筆者編寫的消費者範例程式碼如下:
using Confluent.Kafka;
using System.Net;
public class Program
{
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.156:9092",
GroupId = "test1",
AutoOffsetReset = AutoOffsetReset.Earliest
};
CancellationTokenSource source = new CancellationTokenSource();
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
// 訂閱主題
consumer.Subscribe("my-topic");
// 迴圈消費
while (!source.IsCancellationRequested)
{
var consumeResult = consumer.Consume(source.Token);
Console.WriteLine(consumeResult.Message.Value);
}
consumer.Close();
}
}
}
在本章中,關於 Kafka .NET 的基礎就到這裡,接下來筆者會詳細講解生產者和消費者的程式碼編寫方法以及各種引數設定的使用方法。
4,生產者
在第三章中,我們學習到了 Kafka C# 使用者端的一些使用方法,學習瞭如何編寫生產者程式。
在本章中,筆者將會詳細介紹生產者程式的引數設定、介面使用方法,以便在專案中更加好地應用 Kafka,以及應對可能發生的故障。
下圖是一個生產者推播訊息的流程:
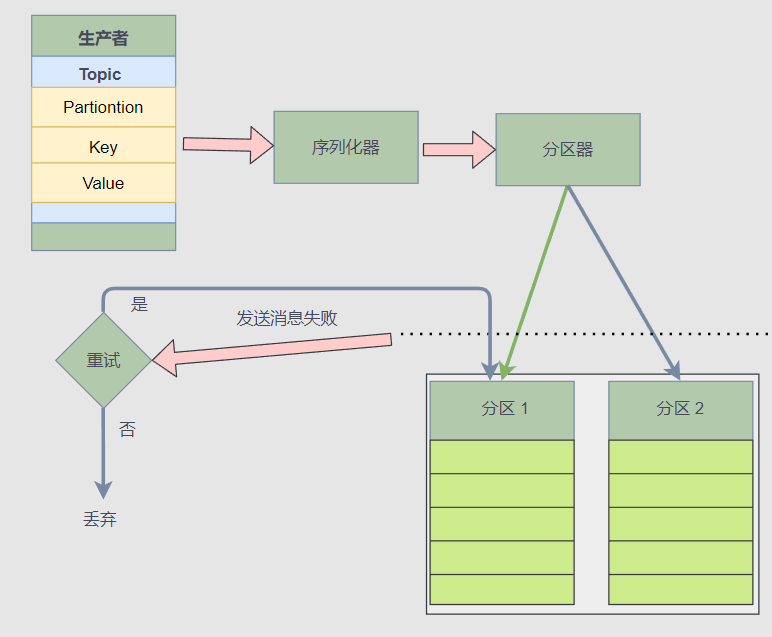
使用使用者端庫編寫生產者是比較簡單的,但是訊息推播過程是比較複雜的,從上圖中可以看到生產者推播訊息時,使用者端庫會先用序列化器將訊息序列化為二進位制,然後通過分割區器算出 Topic 的訊息需要推播到哪個 Broker 、哪個分割區中 。
接著,如果推播訊息失敗,那麼使用者端庫還要確認是否重試,重試次數、時間間隔等。
所以說,推播訊息雖然很簡單,但是怎麼處理故障,確保訊息不會丟失,還有生產者的設定,這些都需要開發者根據場景考慮,設計合理的生產者程式邏輯。
就 「避免訊息丟失」 這個話題來說,除了生產者需要關注訊息是否已經推播到 Broker,還要關注 leader 副本是否及時與 follwer 副本同步。否則即使使用者端已經將訊息推播到 Broker,Broker 的 leader 還沒有同步最新的訊息到 follwer 副本就掛了,那麼此條訊息還是會丟失的,所以使用者端還需要設定合理的 ACK。
說明了訊息會不會丟失,不僅跟生產者的狀態有關,還跟 Broker 狀態有關。
下面筆者將詳細介紹生產者推播訊息時,一些日常開發中會遇到的設定以及細節。
連線 Broker
生產者連線 Broker,需要定義 ProducerConfig ,首先是 BootstrapServers 屬性,填寫所有 Broker 的伺服器地址,格式如下:
host1:9092,host2:9092,...
using Confluent.Kafka;
using System.Net;
public class Program
{
static void Main()
{
var config = new ProducerConfig
{
BootstrapServers = "host1:9092",
...
};
... ...
}
}
如果需要通過加密連線,ProducerConfig 可以參考下面的程式碼:
var config = new ProducerConfig
{
BootstrapServers = "<your-IP-port-pairs>",
SslCaLocation = "/Path-to/cluster-ca-certificate.pem",
SecurityProtocol = SecurityProtocol.SaslSsl,
SaslMechanism = SaslMechanism.ScramSha256,
SaslUsername = "ickafka",
SaslPassword = "yourpassword",
};
使用者端並不需要填寫所有 Broker 的地址,因為生產者在建立連線之後,便可以從已連線的 Broker 中查詢叢集資訊,獲取到所有 Broker 地址。但是建議至少填寫兩個 Broker 地址,因為如果第一個 Broker 地址不可用,使用者端還可以從其它 Broker 中獲取當前叢集的資訊,不至於完全連不上伺服器。
例如伺服器有三個 Broker,使用者端只填寫了一個 BootstrapServers 地址,然後使用者端推播訊息,這些訊息還是會被自動推播到對應的分割區中的。
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092"
};
using (var producer = new ProducerBuilder<string, string>(config).Build())
{
var r1 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "a", Value = "a log message" });
var r2 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "b", Value = "a log message" });
var r3 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "c", Value = "a log message" });
var r4 = await producer.ProduceAsync("hello-topic", new Message<string, string> { Key = "d", Value = "a log message" });
Console.WriteLine($"""
r1 Status:{r1.Status},Partition:{r1.Partition}
r2 Status:{r2.Status},Partition:{r2.Partition}
r3 Status:{r3.Status},Partition:{r3.Partition}
r4 Status:{r4.Status},Partition:{r4.Partition}
""");
}
}
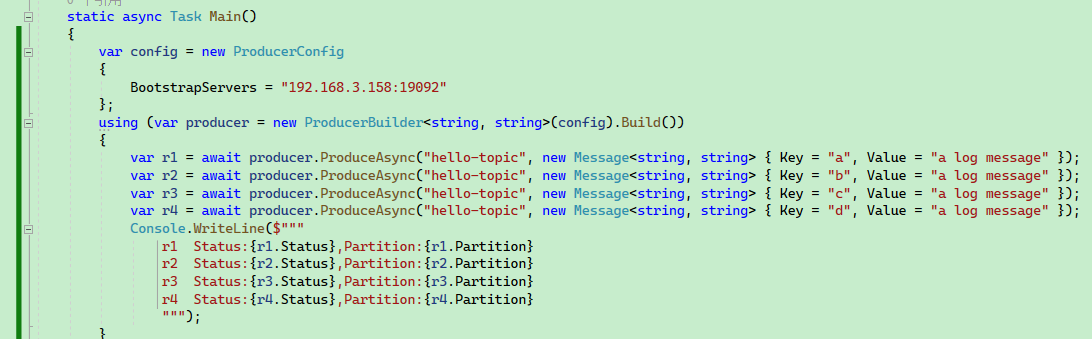
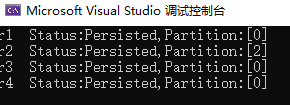
可以看到,即使只填寫一個 Broker,訊息依然可以被正確分割區。
Key 分割區
本節會介紹 Key 的使用方法。
提前建立了一個 hello-topic 主題,並設定了 3 個分割區,3 個副本,其建立命令如下所示:
kafka-topics --create --bootstrap-server 192.168.3.158:19092 \
--replication-factor 23 \
--partitions 3 \
--topic hello-topic
在前面的章節中,筆者介紹瞭如何編寫生產者以及推播訊息,但是程式碼比較簡單,只設定了 Value。
new Message<Null, string> { Value = "a log message" }
然後是關於分割區的問題。
首先是分割區器,分割區器決定將當前訊息推播到哪個分割區,而分割區器位於使用者端。
推播訊息時,我們可以在使用者端顯示指定將訊息推播到哪個分割區,如果沒有顯式指定分割區位置,那麼就會由分割區器基於 Key 決定將訊息推播到哪個分割區中。
如果一個訊息沒有設定 Key,即 Key 是 null,那麼這些沒有 Key 的訊息,會被均衡分佈到各個分割區上,按照 p0 => p1 => p2 => p0 這樣的順序推播訊息。
接下來,筆者介紹 Key 使用。
建立主題後,我們來看一下 C# 程式碼中的生產者構造器以及 Message<TKey, TValue> 的定義。
ProducerBuilder<TKey, TValue> 和 Message<TKey, TValue> 兩者都具有相同的泛型引數。
public class ProducerBuilder<TKey, TValue>
public class Message<TKey, TValue> : MessageMetadata
{
//
// 摘要:
// Gets the message key value (possibly null).
public TKey Key { get; set; }
//
// 摘要:
// Gets the message value (possibly null).
public TValue Value { get; set; }
}
然後,在編寫程式碼時,我們需要為 Key 和 Value 設定對應的型別。
生產者的程式碼範例如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092"
};
using (var producer = new ProducerBuilder<int, string>(config).Build())
{
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 1, Value = "a log message" });
var r2 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 2, Value = "a log message" });
var r3 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 3, Value = "a log message" });
var r4 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = 4, Value = "a log message" });
Console.WriteLine($"""
r1 Status:{r1.Status},Partition:{r1.Partition}
r2 Status:{r2.Status},Partition:{r2.Partition}
r3 Status:{r3.Status},Partition:{r3.Partition}
r4 Status:{r4.Status},Partition:{r4.Partition}
""");
}
}
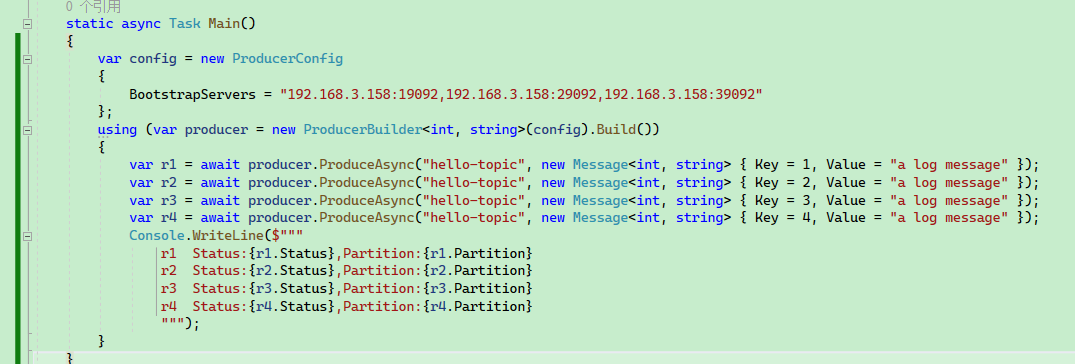
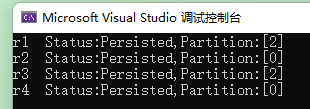
響應結果中可以看到訊息被推播到哪個分割區中。
接下來還有一個疑問,如果向 Broker 推播具有相同值的 Key,那麼會覆蓋之前的訊息?
正常情況下應該不會。
主題有個
cleanup.policy引數,設定紀錄檔保留策略,如果保留策略是compact(壓實),那麼只為每個 key 保留最新的值。
下面我們可以來做使用,首先向 Broker 推播 20 條訊息,一共有 10 個 Key,兩兩重複。
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
};
using (var producer = new ProducerBuilder<string, string>(config)
.Build())
{
int i = 1;
while (i <= 10)
{
var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "1" });
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
i++;
}
i = 1;
while (i <= 10)
{
var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "2" });
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
i++;
}
}
}
或者:
int i = 1; while (i <= 10) { var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "1" }); Console.WriteLine($"id:{r1.Key},status:{r1.Status}"); var r2 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = i.ToString(), Value = "2" }); Console.WriteLine($"id:{r1.Key},status:{r2.Status}"); i++; }
然後開啟 kafdrop,檢視每個分割區的訊息數量,。
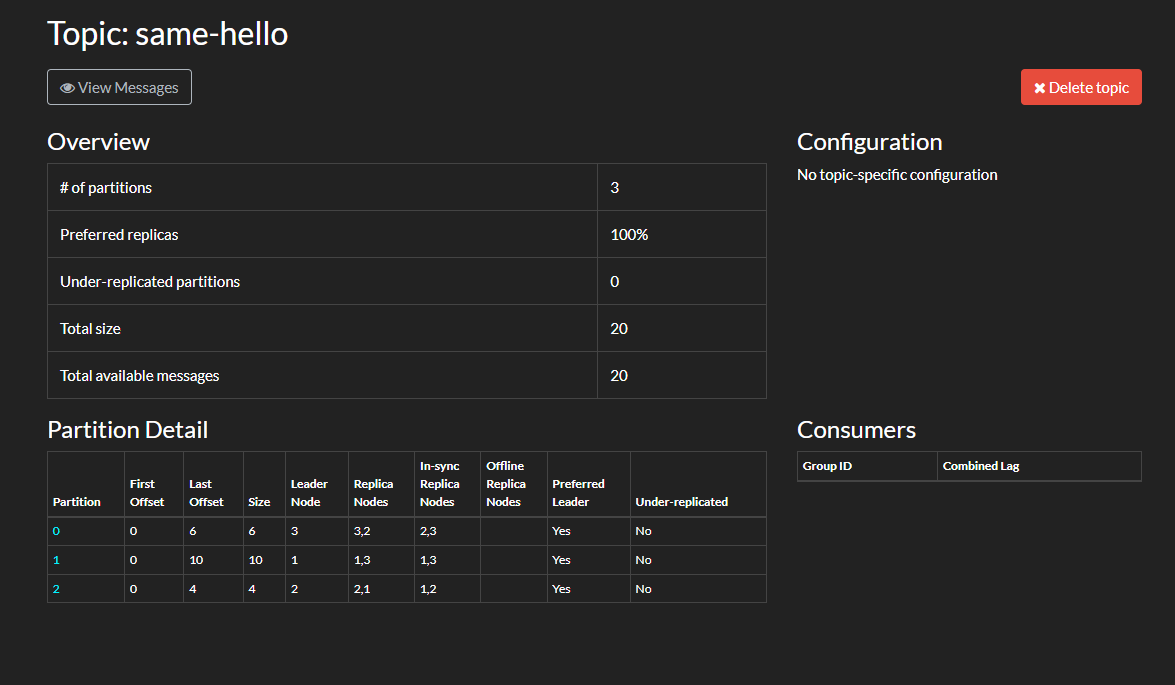
可以看到,訊息數量總數為 20 條,雖然部分 key 重複,但是訊息還在,不會丟失。
接著開啟其中一個分割區,會發現分割區器依然是正常工作,相同的 key 依然會被劃分到同一個分割區中。

所以我們並不需要擔心 Key 為空,以及相同的 Key 覆蓋訊息。
評估訊息傳送時間
下面是推播一條訊息的步驟。
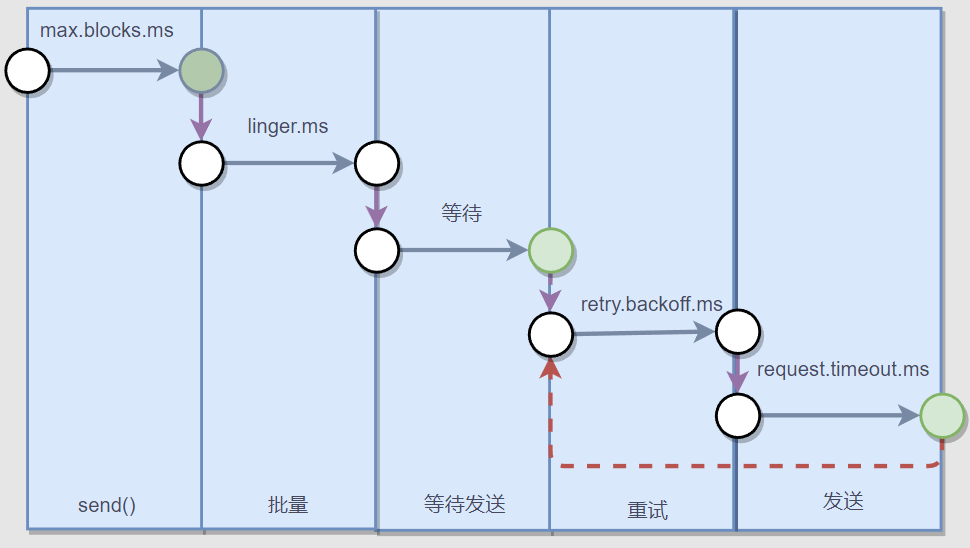
這裡的批次指的是緩衝區。
使用者端庫裡面設計到了好幾個時間設定,在《Kafka權威指南(第2版)》,給出了一個時間公式:
delivery.timeout.ms >= linger.ms + retry.backoff.ms + request.timeout.ms
delivery.timeout.ms 設定將訊息放到緩衝區、推播訊息到 Broker、獲得 Ack、以及重試的總時間不能超過這個範圍,否則視為超時。
在 C# 中沒有這麼詳細的時間設定,然後這些時間的設定驗證比較麻煩,因此這裡筆者只給出簡單的說明,詳細每個時間設定,讀者可以參考 《Kafka權威指南(第2版)》 的 41 頁。
生產者設定
本節主要參考文章:
https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f
部分圖片來源於此文章。
參考資料還包括 《Kafka權威指南(第2版)》。
本節介紹生產者的以下設定:
acksbootstrap.serversretriesenable.idempotencemax.in.flight.requests.per.connectionbuffer.memorymax.block.mslinger.msbatch.sizecompression.type
檢視 ProducerConfig 的原始碼可以發現,每個屬性欄位都對應了一個 Kafka 設定項。
完整的生產者設定檔案:https://docs.confluent.io/platform/current/installation/configuration/producer-configs.html
接下來筆者對日常開發中比較容易用到的設定項進行一一說明。
acks
C# 中對應的列舉如下:
public enum Acks
{
None = 0,
Leader = 1,
All = -1
}
使用範例:
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:9092",
Acks = Acks.Leader
};
預設值是
Acks.Leader。
acks 指定了生產者推播訊息時,需要多少個分割區副本全部收到訊息的情況下,才會認為訊息寫入成功。
在預設情況下,在首領副本收到訊息後,即可向使用者端迴應訊息已寫入成功,這有助於控制傳送的訊息的永續性。
下面是 akcs 設定的說明:
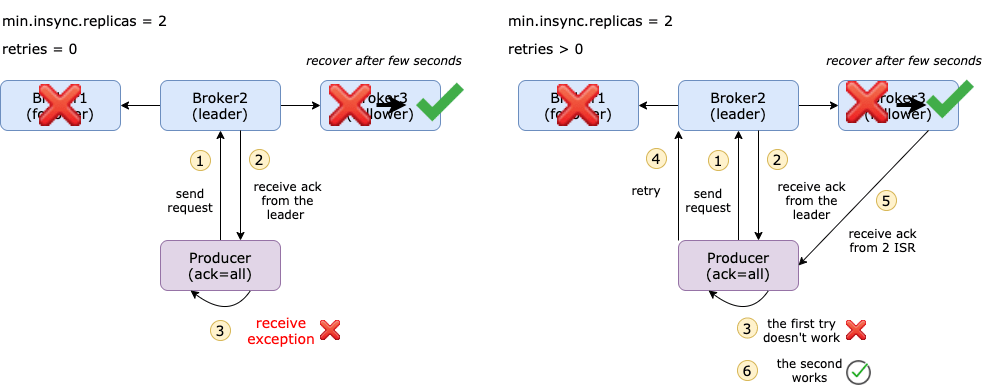
acks=0: 這意味著該記錄將立即新增到通訊端緩衝區並被視為已傳送,如果網路故障或其它原因訊息沒有推播到 Broker,那麼抱歉,這個訊息就會被丟棄;acks=1: 只要生產者收到 Leader 副本的確認,它就會將其視為成功的提交。不過在 Leader 副本發生崩潰的情況下,訊息還是有可能丟失的;acks=all: 訊息提交後必須等待來自該主題的所有副本的確認,它提供了最強大的可用訊息永續性,但是耗時會增加。
在第二章和第三章都提到過這個 leader 和 follwer 的情況。
acks 的預設值為 1,這意味著只要生產者從該主題的 Leader 副本收到 ack,它就會將其視為成功的提交併繼續下一條訊息。
acks= all 將確保生產者從該主題的所有同步副本中獲得 acks 才會認為訊息已經提交,它提供了最強的訊息永續性,但是它也需要較長的時間,從而導致較高的延遲。
下圖是 acks=1 和 acks=all 的區別。
acks=all也可以寫成acks=-1。
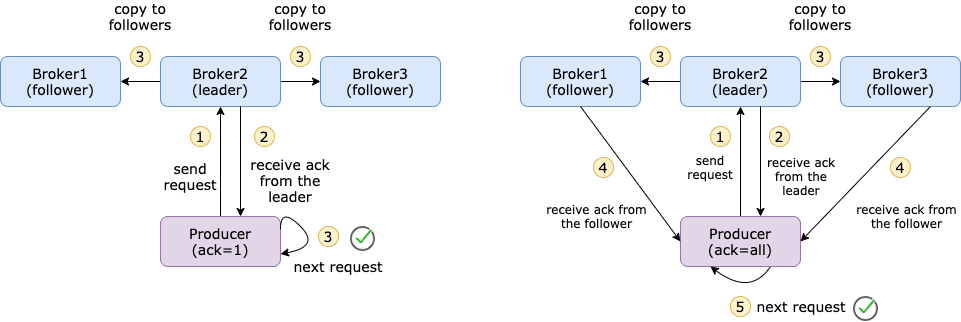
【圖源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
bootstrap.servers
前面提到過,這裡不再贅述。
retries
預設情況下,如果訊息提交失敗,生產者不會重新傳送記錄,即不會重試,即預設重試次數為 0。
可以通過可以設定 retries = n 讓傳送失敗的訊息重試 n 次。
在 C# 中,可以通過 ProducerConfig 的 MessageSendMaxRetries 設定最大重試次數。
public int? MessageSendMaxRetries
{
get
{
return GetInt("message.send.max.retries");
}
set
{
SetObject("message.send.max.retries", value);
}
}
【圖源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
另外,還可以設定重試的間隔時間,預設為 100ms。
public int? RetryBackoffMs
{
get
{
return GetInt("retry.backoff.ms");
}
set
{
SetObject("retry.backoff.ms", value);
}
}
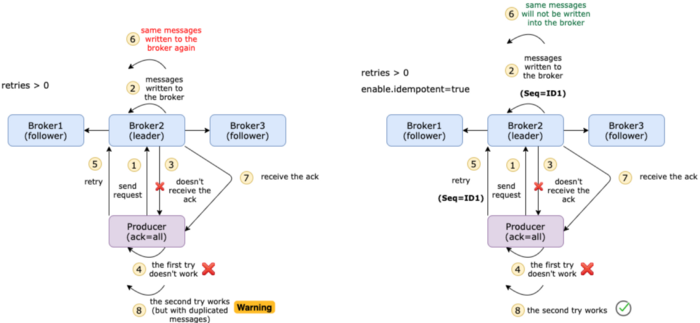
enable.idempotence
簡單地說,冪等性是某些操作在不改變結果的情況下多次應用的性質。當開啟時,生產者將確保只有一個記錄副本被髮布到流。預設值為 false,這意味著生產者可以將訊息的副本寫入流。要開啟冪等函數,請使用下面的命令
enable.idempotent=true
冪等生產者被啟用時,生產者將給傳送的每一條訊息都加上一個序列號。
在某些情況下,訊息實際上已經提交給所有同步副本,但由於網路問題,代理無法傳送回一個 ack (例如,只允許單向通訊)。同時,我們設定 retry = 3,然後生成器將重新傳送訊息3次。這可能導致主題中出現重複訊息。
最理想的情況是精確一次語意,即使生產者重新傳送訊息,使用者也應該只收到相同的訊息一次。
它是怎麼工作的?訊息以批次處理方式傳送,每個批次處理都有一個序號。在代理端,它跟蹤每個分割區的最大序列號。如果進入一個序列號較小或相等的批次處理,代理將不會將該批次處理寫入主題。通過這種方式,它還可以確保批次的順序。
【圖源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
max.in.flight.requests.per.connection
Connection Kafka Producer Config 表示客戶機在阻塞之前在單個連線上傳送的未確認請求的最大數量。預設值為5。
如果啟用了重試,並且 max.in.flight.requests.per.connect 設定為大於1,則存在訊息重新排序的風險。
確保順序的另一個重要設定是 max.in.flight.requests.per.connect,預設值為5。這表示可以在生產者端緩衝的未確認請求的數量。如果重試次數大於1,第一個請求失敗,但第二個請求成功,那麼第一個請求將被重試,訊息的順序將錯誤。
請注意,如果此設定大於1,並且傳送失敗,則由於重試(即,如果啟用了重試) ,存在訊息重新排序的風險。
如果沒有設定 enable.idempotent=true,但仍希望保持訊息的順序,則應將此設定設定為1。
但是如果已經啟用了 enable.idempotent=true,那麼就不需要顯式定義這個設定。卡夫卡將選擇適當的值,正如這裡所述。
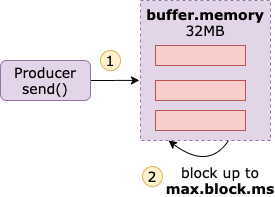
buffer.memory
``buffer.memory` 表示生產者可以用來緩衝等待傳送到伺服器的訊息的總記憶體位元組數。
預設值是 32 MB,如果生產者傳送記錄的速度快於它們傳送到伺服器的速度,那麼緩衝區被耗盡之後,在緩衝區裡面的訊息減少之前,其它訊息需要等待加入緩衝區,此時生產者傳送訊息就會被阻塞。
另外,有個 max.block.ms 引數可以設定訊息等待進入緩衝區的最大時間,預設是 60s,如果訊息一直不能進入緩衝區,那麼就會丟擲異常。
【圖源:https://towardsdatascience.com/10-configs-to-make-your-kafka-producer-more-resilient-ec6903c63e3f】
另外兩個可以使用的設定是 linger.ms 和 batch.size。 linger.ms 是緩衝區批次傳送之前的延遲時間,預設值為 0,這意味著即使批次訊息中只有 1 條訊息,也會立即傳送批次處理。
可以將 linger.ms 設定大一些,以減少請求數量,一次性將多個訊息批次推播,提高吞吐量,但這將導致更多的訊息堆積在記憶體中。
有一個與 linger.ms 等價的設定,即 batch.size,這是單個批次處理的最大訊息數量。
當滿足這兩個要求中的任何一個時,批次訊息將被傳送。
batch.size
Whenever multiple records are sent to the same partition, the producer attempts to batch the records together. This way, the performance of both the client and the server can be improved. batch.size represents the maximum size (in bytes) of a single batch.
每當多條記錄被傳送到同一個分割區時,生產者就會嘗試將這些記錄批次處理在一起。通過這種方式,可以提高客戶機和伺服器的效能。Size 表示單個批次處理的最大大小(以位元組為單位)。
Small batch size will make batching irrelevant and will reduce throughput, and a very large batch size will lead to memory wastage as a buffer is usually allocated in anticipation of extra records.
小批次將使批次處理無關緊要,並將降低吞吐量,而且非常大的批次處理大小將導致記憶體浪費,因為緩衝區通常是在預期額外記錄的情況下分配的。
compression.type
在預設情況下,生產者傳送的訊息是未經壓縮的。這個引數可以被設定為snappy、gzip、lz4或zstd,這指定了訊息被傳送給broker之前使用哪一種壓縮演演算法。snappy壓縮演演算法由谷歌發明,雖然佔用較少的CPU時間,但能提供較好的效能和相當可觀的壓縮比。如果同時有效能和網路頻寬方面的考慮,那麼可以使用這種演演算法。gzip壓縮演演算法通常會佔用較多的CPU時間,但提供了更高的壓縮比。如果網路頻寬比較有限,則可以使用這種演演算法。使用壓縮可以降低網路傳輸和儲存開銷,而這些往往是向Kafka傳送訊息的瓶頸所在。
生產者攔截器
Library dkafka 有一個攔截器 API,但是您需要用 C 編寫它們,並且不能輕鬆地從 C # 程式碼中共用狀態。
https://github.com/confluentinc/confluent-kafka-dotnet/issues/1454
序列化器
有 Key 和 Value 兩種序列化器。
.SetKeySerializer(...)
.SetValueSerializer(...)
基本上,ApacheKafka 提供了我們可以輕鬆釋出和訂閱記錄流的能力。因此,我們可以靈活地建立自己的客製化序列化程式和反序列化程式,這有助於使用它傳輸不同的資料型別。
但是,將物件轉換為位元組流以進行傳輸的過程稱為序列化(Serialization)。儘管如此,ApacheKafka 在其佇列中儲存並傳輸這些位元組陣列。
然而,序列化的對立面是反序列化。在這裡,我們將陣列的位元組轉換為所需的資料型別。但是,確保 Kafka 只為少數幾種資料型別提供序列化器和反序列化器,例如
- String 繩子
- Long 很長
- Double 雙倍
- Integer 整數
- Bytes 位元組
換句話說,在將整個訊息傳輸給代理之前,讓生產者知道如何使用序列化器將訊息轉換為位元組陣列。類似地,要將位元組陣列轉換回物件,使用者使用反序列化器。
在 C# 中,Serializers 定義了幾個預設的序列化器。
Utf8
Null
Int64
Int32
Single
Double
ByteArray
由於 byte[] 轉對應的型別並不複雜,因此這裡將部分序列化器的原始碼顯示出來:
private class Utf8Serializer : ISerializer<string>
{
public byte[] Serialize(string data, SerializationContext context)
{
if (data == null)
{
return null;
}
return Encoding.UTF8.GetBytes(data);
}
}
private class NullSerializer : ISerializer<Null>
{
public byte[] Serialize(Null data, SerializationContext context)
{
return null;
}
}
private class Int32Serializer : ISerializer<int>
{
public byte[] Serialize(int data, SerializationContext context)
{
return new byte[4]
{
(byte)(data >> 24),
(byte)(data >> 16),
(byte)(data >> 8),
(byte)data
};
}
}
如果需要支援更多型別,則可以繼承 ISerializer<T> 來實現。
由於 C# 有泛型,因此在使用 new ProducerBuilder<TKey, TValue> 的時候,會自動從預設的幾種序列化器中找到合適的 ISerializer<T> ,如果不是預設的這幾種型別,則需要自行實現序列化器。
生產者設定了對應的序列化器,使用者端同樣可以設定對應的反序列化器,以便能夠正確從 Message 中還原對應的結構。
同樣,有這幾種預設的反序列化器,在 Deserializers 中可以找到,因為生產者、消費者這部分設定是關聯相通的,因此後面講解消費者的時候,就不提及了。
using (var consumer = new ConsumerBuilder<Ignore, string>(config)
.SetKeyDeserializer(Deserializers.Ignore)
.Build())
{
}
檔頭
檔頭是訊息中的後設資料,主要目的在於向訊息中加入一些資料,例如來源、追蹤資訊等。
在 C# 中,一個訊息的定義如下:
public class MessageMetadata
{
public Timestamp Timestamp { get; set; }
public Headers Headers { get; set; }
}
public class Message<TKey, TValue> : MessageMetadata
{
public TKey Key { get; set; }
public TValue Value { get; set; }
}
我們可以通過在訊息的 Headers 中加入自定義的訊息,其範例如下:
var message = new Message<Null, string>
{
Value = "666",
Headers = new Headers()
{
{ "Level",Encoding.ASCII.GetBytes("Info")},
{ "IP",Encoding.ASCII.GetBytes("192.168.3.66")}
}
};
var result = await producer.ProduceAsync("my-topic", message);
生產者處理器
SetStatisticsHandler
SetKeySerializer
SetValueSerializer
SetPartitioner
SetDefaultPartitioner
SetErrorHandler
SetLogHandler
Statistics 統計資料
通過將 statistics.interval.ms 設定屬性設定一個固定值,library dkafka 可以設定為以固定的時間間隔發出內部指標,也就是說可以定期獲取到 Kafka 叢集的所有資訊。
首先修改生產者設定中的 StatisticsIntervalMs 屬性
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
StatisticsIntervalMs = 1000,
};
然後使用 SetStatisticsHandler 設定處理器,其委託定義為:Action<IProducer<TKey, TValue>, string> statisticsHandler。
委託中一共有兩個引數變數,前者 IProducer<TKey, TValue> 就是當前生產者範例,後者 string 是 Json 文字,記錄了當前所有 Broker 的所有詳細資訊。
由於表示的內容很多,讀者可以參考:
https://github.com/confluentinc/librdkafka/blob/master/STATISTICS.md
使用範例如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
StatisticsIntervalMs = 1000,
};
using (var producer = new ProducerBuilder<int, string>(config)
.SetStatisticsHandler((producer, json) =>
{
Console.WriteLine(producer.Name);
Console.WriteLine(json);
})
.Build())
{
int i = 100;
while (true)
{
Thread.Sleep(1000);
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = i, Value = "a log message" });
i++;
}
}
}
SetPartitioner、SetDefaultPartitioner
由於指定生產者在向 Broker 推播訊息時,訊息向指定分割區寫入。
SetPartitioner 的定義如下:
SetPartitioner:
SetPartitioner(string topic, PartitionerDelegate partitioner)
-- PartitionerDelegate:
Partition PartitionerDelegate(string topic, int partitionCount, ReadOnlySpan<byte> keyData, bool keyIsNull);
SetDefaultPartitioner 的定義如下:
SetDefaultPartitioner(PartitionerDelegate partitioner)
SetPartitioner、SetDefaultPartitioner 的區別在於 SetPartitioner 可以對指定的 topic 有效,SetDefaultPartitioner 則對當前生產者中的所有 topic 有效。
程式碼範例如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
StatisticsIntervalMs = 1000,
};
using (var producer = new ProducerBuilder<int, string>(config)
.SetPartitioner("hello-topic", (topic, partitionCount, keyData, keyIsNull) =>
{
return new Partition(0);
})
.SetDefaultPartitioner((topic, partitionCount, keyData, keyIsNull) =>
{
return new Partition(0);
})
.Build())
{
int i = 100;
while (true)
{
Thread.Sleep(1000);
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = i, Value = "a log message" });
i++;
}
}
}
可以看到,現在所有 topic 都向指定的分割區 0 寫入:
剩下的兩個 SetErrorHandler、SetLogHandler,用於記錄錯誤紀錄檔、普通紀錄檔,讀者可根據其它資料自行實驗,這裡筆者就不再贅述了。
using (var producer = new ProducerBuilder<int, string>(config)
.SetErrorHandler((p, err) =>
{
Console.WriteLine($"Producer Name:{p.Name},error:{err}");
})
.SetLogHandler((p, log) =>
{
Console.WriteLine($"Producer Name:{p.Name},log messagge:{JsonSerializer.Serialize(log)}");
})
.Build())
{
}
例外處理和重試
生產者推播訊息有三種傳送方式:
-
傳送並忘記
-
同步傳送
-
非同步傳送
傳送訊息時,一般有兩種異常情況,一種是可重試異常,例如網路故障、Broker 故障等;另一種是不可重試故障,例如伺服器端限制了單條訊息的最大位元組數,但是使用者端的訊息超過了這個限制,此時會直接丟擲異常,而不能重試。
using (var producer = new ProducerBuilder<string, string>(config)
.Build())
{
try
{
var r1 = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = "1", Value = "1" });
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
}
catch (ProduceException<string, string> ex)
{
Console.WriteLine($"Produce error,key:[{ex.DeliveryResult.Key}],errot message:[{ex.Error}],trace:[{ex.StackTrace}]");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
訊息傳送後會返回 DeliveryResult<TKey, TValue>,其 Status 欄位表示了訊息的狀態,有三種狀態。
// 訊息持久狀態的列舉。
public enum PersistenceStatus
{
// 訊息從未傳輸到 Broker,或者失敗,並出現錯誤,指示未將訊息寫入日;應用程式重試可能導致排序風險,但不會造成複製風險。
NotPersisted,
// 訊息被傳輸到代理,但是沒有收到確認;應用程式重試有排序和複製的風險。
PossiblyPersisted,
// 訊息被寫入紀錄檔並由 Broker 確認。在發生代理故障轉移的情況下,應使用 `acks='all'` 選項使其完全受信任。
Persisted
}
在訊息傳送失敗時,使用者端可以進行重試,可以設定重試次數和重試間隔,還可以設定是否重新排序。
是否重新排序可能會對業務產生極大的影響。
例如傳送順序為
[A,B,C,D],當用戶端傳送 A 失敗時,如果不允許重新排序,那麼使用者端會重試 A,A 成功後繼續傳送[B,C,D],這一過程是阻塞的。如果允許重新排序,那麼使用者端會在稍候對 A 進行重試,而現在先傳送
[B,C,D];這樣可能會導致 Broker 收到的訊息順序是[B,C,D,A]。
範例程式碼如下:
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
// 接收來自所有同步副本的確認
Acks = Acks.All,
// 最大重試次數
MessageSendMaxRetries = 3,
// 重試時間間隔
RetryBackoffMs = 1000,
// 如果不想在重試時對訊息重新排序,則設定為 true
EnableIdempotence = true
};
using (var producer = new ProducerBuilder<string, string>(config)
.SetLogHandler((_, message) =>
{
Console.WriteLine($"Facility: {message.Facility}-{message.Level} Message: {message.Message}");
})
.SetErrorHandler((_, e) =>
{
Console.WriteLine($"Error: {e.Reason}. Is Fatal: {e.IsFatal}");
})
.Build())
{
try
{
var result = await producer.ProduceAsync("same-hello", new Message<string, string> { Key = "1", Value = "1" });
Console.WriteLine($"[{result.Key}] 傳送狀態; {result.Status}");
// 訊息沒有收到 Broker 的 ACK
if (result.Status != PersistenceStatus.Persisted)
{
// 自動重試失敗後,此訊息需要手動處理。
}
}
catch (ProduceException<string, string> ex)
{
Console.WriteLine($"Produce error,key:[{ex.DeliveryResult.Key}],errot message:[{ex.Error}],trace:[{ex.StackTrace}]");
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
}
Broker 限制速率
在 Kafka 中,生產者、消費者都是使用者端,兩者都有一個 client.id,消費者還有一個消費者組的概念,但生產者只有 client.id,沒有其它標識了。
一般來說,並不需要設定 生產者的 client.id,框架會自動設定,如:
rdkafka#producer-1
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092",
StatisticsIntervalMs = 1000,
ClientId = "abcdef"
};
新的 client.id:
abcdef#producer-1
迴歸正題,在 Kafka 中,可以根據 client.id ,對生產者或消費者進行限制流量,多個使用者端(消費者或生產者)可以用同一個 client.id。或者通過其它認證機制標識使用者端身份。
可以通過以下方式表示使用者端。
-
user
-
client id
-
user + client id
筆者選擇使用最簡單的 client.id 做實驗。
kafka-configs --alter --bootstrap-server 192.168.3.158:19092 --add-config 'producer_byte_rate=1024,consumer_byte_rate=1024' --entity-type clients --entity-name 'abcdef'
限制 1kb/s。
然後編寫使用下面的程式碼測試,會發現推播訊息速度變得很慢。
static async Task Main()
{
var config = new ProducerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
StatisticsIntervalMs = 1000,
ClientId = "abcdef"
};
using (var producer = new ProducerBuilder<int, string>(config)
.Build())
{
int i = 1000;
var str = string.Join(",", Enumerable.Range(0, 1024).Select(x => x.ToString("X16")));
while (true)
{
var r1 = await producer.ProduceAsync("hello-topic", new Message<int, string> { Key = i, Value = str });
i++;
Console.WriteLine($"id:{r1.Key},status:{r1.Status}");
}
}
}
5.消費者
在第四章中的生產者中,介紹了比較多的生產者特性,而消費者很多特性跟生產者是一樣的,因此本章簡單介紹消費者程式的編寫方式和一些問題的解決方法,不再過多介紹消費者的引數。
消費者和消費者組
建立一個消費者時,可以指定這個消費者所屬的組(GroupId),如果不指定,Kafka 預設會給其分配一個。
給消費者指定一個消費者組 C 的方式如下:
var config = new ConsumerConfig
{
BootstrapServers = "host1:9092,host2:9092",
GroupId = "C",
AutoOffsetReset = AutoOffsetReset.Earliest
};
消費者組是一個很重要的設定。
如果一個主題只有一個分割區,並且只有一個消費者組,只有一個消費者,那麼消費過程如圖。
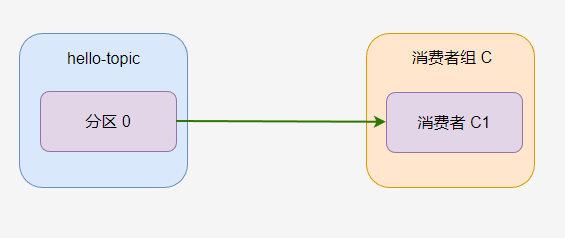
hello-topic 中的所有訊息都會被
C-C1消費。
一個分割區只能被消費者組中的一個消費者消費!消費者組 C 中,無論有多少個消費者,分割區 0 只有一個消費者可以消費。
如果 C1 消費者程式掛了,C2 消費者開始消費,那麼預設是從 C1 消費者上次消費的位置開始消費。
如果一個主題有多個消費者組,那麼每個消費者組都可以消費這個分割區的所有訊息。
每個消費者組都有自己的消費標記。

如果一個消費者組中有多個消費者,那麼一個分割區只會分配給其中一個消費者。
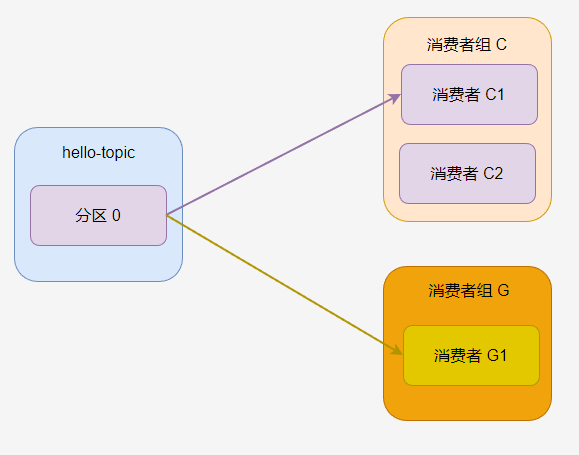
此時 C2 一直沒有活幹。
如果主題有多個分割區,那麼分割區會被一定規則分配給消費者組的消費者,例如下圖中,消費者 C1 被分配到 分割區 0 和分割區 2,消費者 C2 分到 分割區 1。
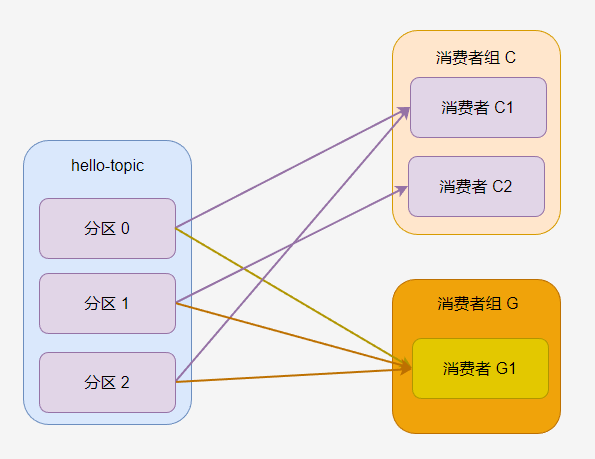
消費者組 G 中只有一個消費者,因此 G1 被分配了所有分割區。
一般來說,一個消費者組的消費者數量跟分割區數量一致最好,這樣每個消費者可以消費一個分割區。過多的消費者會導致部分消費者不能消費訊息,過少的消費者會導致單個消費者需要處理多個分割區的訊息。
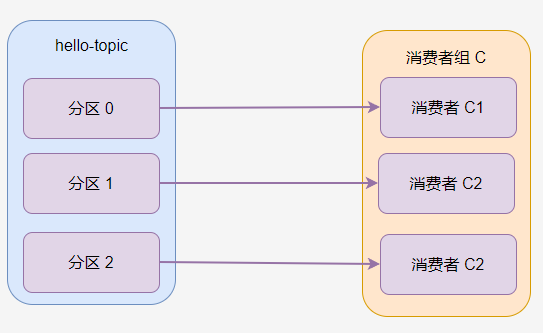
在消費者連線到 Broker 之後,Broker 便會給消費者分配主題分割區。
在預設情況下,消費者的群組成員身份標識是臨時的。當一個消費者離開群組時,分配給它的分割區所有權將被複原;當該消費者重新加入時,將通過再均衡協定為其分配一個新的成員 ID 和新分割區。可以給消費者分配一個唯一的 group.instance.id,讓它成為群組的固定成員。
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092",
GroupId = "C",
GroupInstanceId = "C1",
AutoOffsetReset = AutoOffsetReset.Earliest,
};
如果兩個消費者使用相同的 group.instance.id 加入同一個群組,則第二個消費者會收到錯誤,告訴它具有相同 ID 的消費者已存在。
消費位置
預設情況下,消費者的 AutoOffsetReset 引數是 AutoOffsetReset.Earliest,會自動從消費者組最近消費到的位置開始消費。
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092",
GroupId = "foo",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var consumer = new ConsumerBuilder<int, string>(config).Build())
{
consumer.Subscribe("hello-topic");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine(consumeResult.Message.Value);
}
}
}
AutoOffsetReset 的定義如下:
public enum AutoOffsetReset
{
Latest,
Earliest,
Error
}
public AutoOffsetReset? AutoOffsetReset
{
get
{
return (AutoOffsetReset?)GetEnum(typeof(AutoOffsetReset), "auto.offset.reset");
}
set
{
SetObject("auto.offset.reset", value);
}
}
下面是三個列舉的使用說明:
-
latest(default) which means consumers will read messages from the tail of the partition最新(預設) ,這意味著使用者將從分割區的尾部讀取訊息,只消費最新的資訊,即自從消費者上線後才開始推播來的訊息。那麼會導致忽略掉之前沒有處理的訊息。
-
earliestwhich means reading from the oldest offset in the partition這意味著從分割區中最早的偏移量讀取;自動從消費者上次開始消費的位置開始,進行消費。
-
nonethrow exception to the consumer if no previous offset is found for the consumer's group如果沒有為使用者的組找到以前的偏移量,則不會向使用者丟擲異常。
可以在 Kafdrop 中看到消費的偏移量。
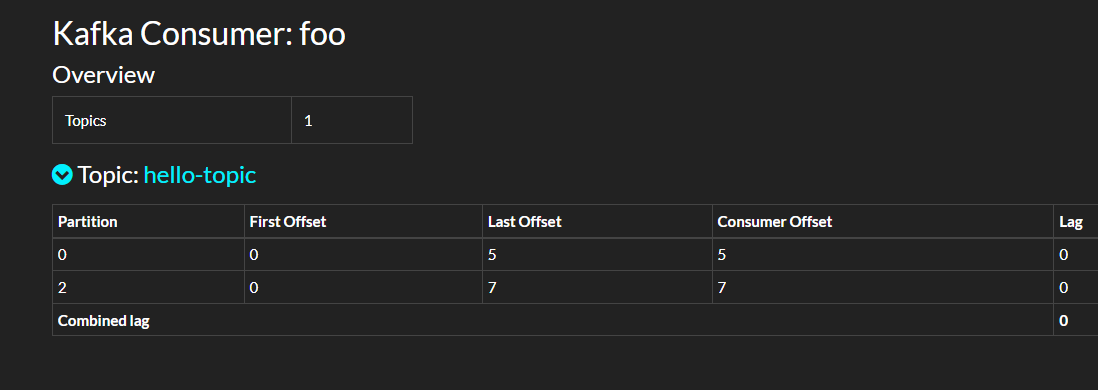
手動提交
使用者端可以設定手動活自動確認訊息。
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
GroupId = "foo",
// 是否自動提交,對自行定位消費位置無影響
EnableAutoCommit = false
};
var consumeResult = consumer.Consume();
consumer.Commit();
消費定位
消費者可以自行設定要消費哪個分割區的訊息以及設定偏移量。
範例程式如下:
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
GroupId = "foo",
// 是否自動提交,對自行定位消費位置無影響
EnableAutoCommit = true
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
// 重新設定此消費組在某個分割區的偏移量
consumer.Assign(new TopicPartitionOffset(new TopicPartition("hello-topic", new Partition(0)), new Offset(0)));
consumer.Assign(new TopicPartitionOffset(new TopicPartition("hello-topic", new Partition(1)), new Offset(0)));
consumer.Assign(new TopicPartitionOffset(new TopicPartition("hello-topic", new Partition(2)), new Offset(0)));
consumer.Subscribe("hello-topic");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine(consumeResult.Message.Value);
}
}
}
如果要從指定時間開始消費,範例如下:
static void Main()
{
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092,192.168.3.158:29092,192.168.3.158:39092",
GroupId = "foo",
// 是否自動提交,對自行定位消費位置無影響
EnableAutoCommit = true
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build())
{
var timestamp = new Timestamp(DateTime.Now.AddDays(-1));
// 重新設定此消費組在某個分割區的偏移量
consumer.Assign(consumer.OffsetsForTimes(new List<TopicPartitionTimestamp>
{
new TopicPartitionTimestamp(new TopicPartition("hello-topic", new Partition(0)),timestamp),
new TopicPartitionTimestamp(new TopicPartition("hello-topic", new Partition(1)),timestamp),
new TopicPartitionTimestamp(new TopicPartition("hello-topic", new Partition(2)),timestamp)
}, timeout: TimeSpan.FromSeconds(100)));
consumer.Subscribe("hello-topic");
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine(consumeResult.Message.Value);
}
}
}

條件訂閱
RabbitMQ 中有模糊訂閱,但是 Kafka 中沒有,所以如果想訂閱符合條件的 Topic,需要先拿到叢集中的所有 Topic,篩選後,訂閱這些 Topic。
範例程式碼如下:
static async Task Main()
{
var adminConfig = new AdminClientConfig
{
BootstrapServers = "192.168.3.158:19092"
};
var config = new ConsumerConfig
{
BootstrapServers = "192.168.3.158:19092",
GroupId = "C",
GroupInstanceId = "C1",
AutoOffsetReset = AutoOffsetReset.Earliest,
};
List<string> topics = new List<string>();
using (var adminClient = new AdminClientBuilder(adminConfig).Build())
{
// 獲取叢集所有 topic
var metadata = adminClient.GetMetadata(TimeSpan.FromSeconds(10));
var topicsMetadata = metadata.Topics;
var topicNames = metadata.Topics.Select(a => a.Topic).ToList();
topics.AddRange(topicNames.Where(x => x.StartsWith("hello-")));
}
using (var consumer = new ConsumerBuilder<string, string>(config)
.Build())
{
consumer.Subscribe(topics);
while (true)
{
var consumeResult = consumer.Consume();
Console.WriteLine($"key:{consumeResult.Message.Key},value:{consumeResult.Message.Value},partition:{consumeResult.Partition}");
}
}
}
消費者中的反序列化器、攔截器、處理器,可以參考第四章中的生產者,這裡不在贅述。