自從學習了MongoDB高可用,慢慢的喜歡上了它,之前確實冷落了
大家好,我是哪吒,最近專案在使用MongoDB作為圖片和檔案的儲存資料庫,為啥不直接存MySQL裡,還要搭個MongoDB叢集,麻不麻煩?
讓我們一起,一探究竟,繼續學習MongoDB高可用和片鍵策略,實現快速入門,豐富個人簡歷,提高面試level,給自己增加一點談資,秒變面試小達人,BAT不是夢。

一、複製
在MongoDB中,建立副本集後就可以使用複製功能了,副本集是一組伺服器,其中一個用於處理寫操作的主節點primary,還有多個用於儲存主節點資料副本的從節點secondary。如果主節點崩潰了,則從節點會選取出一個新的主節點。
如果使用複製功能時有一臺伺服器停止執行了,那麼仍然可以從副本集中的其它伺服器存取資料。如果伺服器上的資料已損壞或無法存取,則可以從副本集中的其它成員中建立一個新的資料副本。
副本集中的每個成員都必須能夠連線到其它成員,如果收到有關成員無法存取到其它成員,則可能需要更改網路設定以允許它們之間的連線。

二、如何進行選舉
當一個從節點無法與主節點連通時,它就會聯絡並請求其它的副本整合員將自己選舉為主節點。
其它成員會做幾項健全性檢查:
- 它們能否連線到主節點,而這個主節點是發起選舉的節點無法連線到的?
- 這個發起選舉的從節點是否有最新資料?
- 有沒有其它更高優先順序的成員可以被選舉為主節點?
MongoDB在3.2版本中引入了第1版複製協定。這是一個類PAFT的協定,並且包含了一些特定於MongoDB的副本集概念,比如仲裁節點、優先順序、非選舉成員、寫入關注點等。還提出了很多新概念,比如更短的故障轉移時間,大大減少了檢測主節點失效的時間,它還通過使用term ID來防止重複投票。
RAFT是一種共識演演算法,它被分解成了相對獨立的子問題。共識是指多臺伺服器或程序在一些值上達成一致的過程。RAFT確保了一致性,使得同一序列的命令產生相同序列的結果,並在所部署的各個成員中達到相同序列的狀態。
副本整合員相互間每隔兩秒傳送一次心跳。如果某個成員在10秒內沒有反饋心跳,則其它成員會將不良成員標記為無法存取。選舉演演算法將盡最大努力嘗試讓具有最高優先權的從節點發起選舉。成員優先權會影響選舉的時機和結果。優先順序高的從節點要比優先順序低的從節點更快發起選舉,而且也更有可能成為主節點。然而,低優先順序的從節點也是有可能被短暫的選舉為主節點的,副本整合員會繼續發起選舉直到可用的最高優先順序成員被選舉為主節點。被選舉為主節點的從節點必須擁有最新的複製資料。
三、優先順序
優先順序用於表示一個成員稱為主節點的優先程度,取值範圍是0 ~ 100。數值越大,優先順序越高。預設為1,如果將priority設定為0,表示此節點永遠無法成為主節點,這樣的成員還有一個名字~被動成員。
四、選舉仲裁者
大多數小型專案,MongoDB只有兩個副本集,為了參與選舉,MongoDB支援一種特殊型別的成員,稱為仲裁者,其唯一作用就是參與仲裁。仲裁者不參與儲存資料,也不會為程式提供服務,它只是為了幫助只有兩個副本集的叢集選舉主節點(為了滿足大多數),需要注意的是,只能有一個仲裁者。
仲裁者的缺點:
假設有一個主節點,兩個從節點,一個仲裁者。如果一個從節點停止執行了,那麼就需要一個新的從節點,並且將主節點的資料複製到新的從節點,複製資料會父伺服器造成很大的壓力,降低程式執行速度。所以,儘可能使用奇數的從節點,而不是使用仲裁者。
五、同步
MongoDB通過儲存操作紀錄檔oplog使多臺伺服器間保持相同的資料,oplog中儲存著主節點執行的每一次寫操作。oplog存在於主節點local資料庫中的一個固定集合中,從節點通過查詢此集合以獲取需要複製的操作。
每個從節點同樣維護著自己的oplog,用來記錄它從主節點複製的每個操作。這使得每個成員都可以被用作其他成員的同步源。如果應用某個操作失敗,則從節點會停止從當前資料來源複製資料。
如果一個從節點由於某種原因停止工作了,它重新啟動後,會從oplog中的最後一個操作開始同步。由於這些操作是先應用到資料上然後再寫入oplog,因此從節點可能會重複已經應用到資料上的操作。MongoDB在設計時考慮了這點,oplog中的操作執行一次和多次,效果都是一樣的,oplog中的每個操作都是冪等的。
六、處理過時資料
如果某個從節點的資料遠遠落後於同步源當前的操作,那麼這個從節點就是過時的。過時的從節點無法趕上同步源,如果繼續同步,從節點就需要跳過一些操作。此時,需要從其它節點進行復制,看看其它成員是否有更長的oplog以繼續同步。如果都沒有,該節點當前的複製操作將停止,需要進行完全同步或從最近的備份中恢復。
為了避免出現不同步的節點,讓主節點擁有比較大的oplog以儲存足夠多的操作紀錄檔。
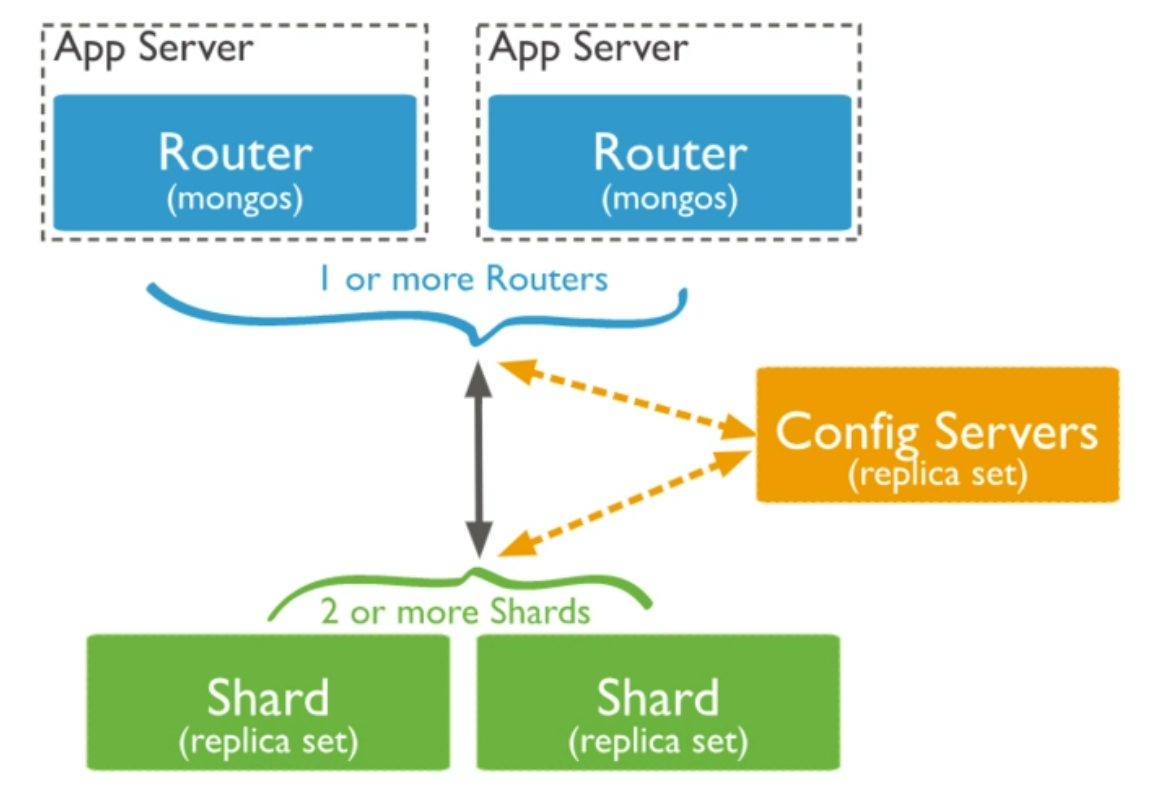
七、雜湊片鍵
為了儘可能快地載入資料,雜湊片鍵是最好的選擇。雜湊片鍵可以使任何欄位隨機分發。如果打算在大量查詢中使用升序鍵,但又想在寫操作時隨機分發,雜湊片鍵是不錯的選擇,不過需要注意的是,雜湊片鍵無法執行指定目標的範圍查詢。
建立雜湊片鍵:
db.users.createIndex({"name":"hashed"})
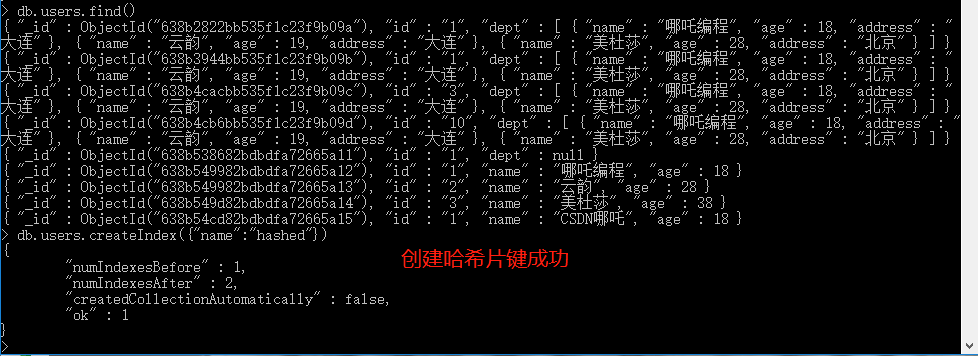
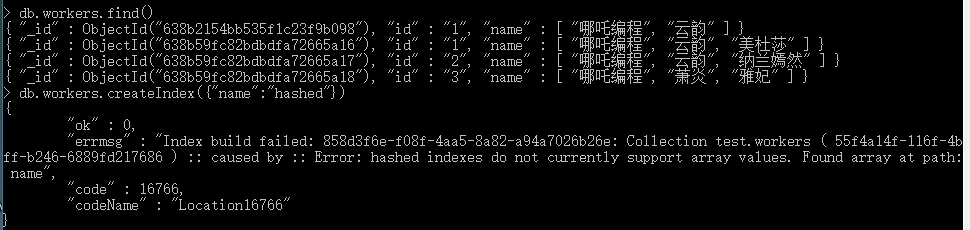
有一點需要注意,雜湊片鍵的欄位,不能是陣列。
Error: hashed indexes do not currently support array values.
八、多熱點
單獨的mongod伺服器在執行升序寫操作時效率最高,這與分片相沖突,當寫操作分發在叢集中時分片效率最高。每個分片上都有幾個熱點,便於寫操作在叢集中均勻分發。
可以使用複合片鍵實現均勻分發,複合片鍵的第一個值可以是一個基數較小的值,片鍵的第二部分是一個升序值,這意味著在塊的內部,值總是在增加的。
九、分片規則
1、分片的限制
比如上圖的異常,片鍵不能是陣列,大多數特殊型別的索引不能用作片鍵。特別是,不能在地理空間索引上進行分片。
2、片鍵的基數
片鍵與索引類似,在基數高的欄位上進行分片,效能會更好。如果有一個status鍵,只有「正常」、"異常"、「錯誤」幾個值,MongoDB是無法將資料拆分成3個以上的塊(因為目前只有三個值),如果想將一個取值較小的鍵作為片鍵,那麼可以將其與另一個擁有多值的鍵組成複合片鍵,比如createTime欄位。這樣複合片鍵就擁有了較高的基數。
十、控制資料分發
1、自動分片
MongoDB將集合均勻分發在叢集中的每個分片上,如果儲存的是同構資料,那麼這種方式非常高效。如果有一個紀錄檔集合,價值不是很大,你可能不希望它儲存在效能最好的伺服器上,效能最好的伺服器一般會儲存重要的實時資料,而不允許其它集合使用它。
可以通過sh.addShardToZone("shard0","hign")、sh.addShardToZone("shard1","low")、sh.addShardToZone("shard2","low")實現它。
可以將不同的集合分配給不同的分片,比如,對及其重要的實時集合執行:
sh.updateZoneKeyRange("super.important",{"<shardKey>":MinKey},...{"<shardKey>":MaxKey},"high")
這條命令指的是:
對於這個集合super.important,將片鍵從負無窮到正無窮的資料儲存在標記為「high」的分片上。這不會影響其它集合的均勻分發。
同樣可以通過low,將不重要的紀錄檔集合存放在效能較差的伺服器上。
sh.updateZoneKeyRange("super.logs",{"<shardKey>":MinKey},...{"<shardKey>":MaxKey},"low")
此時,紀錄檔集合就會均勻的分發到shard1和shard2上。
同樣,可以通過removeShardFromZone()從區域中刪除分片。
sh.removeShardFromZone("super.logs",{"<shardKey>":MinKey},...{"<shardKey>":MaxKey})
2、手動分發
可以通過關閉均衡器 sh.stopBalancer()啟動手動分發。
如果當前正在進行遷移,則此設定在遷移完成之前不會生效。一旦正在執行的遷移完成,均衡器就會停止行動資料。
除非遇到特殊情況,否則,MongoDB應該使用自動分片,而不是手動分片。