FalseSharing-偽共用
1.CPU快取
要了解什麼是偽共用,首先得了解CPU快取架構與快取行的知識
(1)<CPU快取架構>
主記憶體RAM是資料存在的地方,CPU和主記憶體之間有好幾級快取,因為即使直接存取主記憶體相對來說也是非常慢的。如果對一塊資料做相同的運算多次,那麼在執行運算的時候把它載入到離CPU很近的地方就有意義了,避免每次都到主記憶體中去取這個資料。
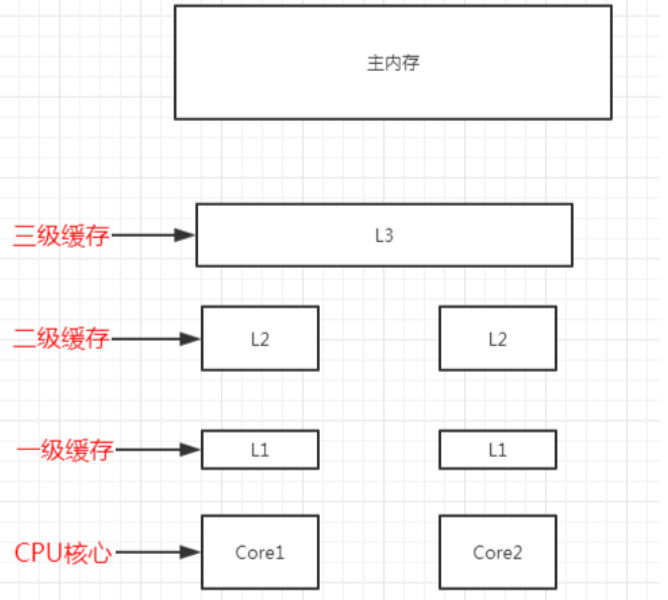
越靠近CPU的快取越快也越小,所以L1快取很小但很快,並且緊靠著在使用它的CPU核心。
L2大一些,但也慢一些,並且仍然只能被一個單獨的CPU核使用。
L3在現代多核機器中更普遍,仍然更大,更慢,並且被單個插槽上的所有CPU核共用。
最後,主記憶體儲存著程式執行的所有資料,它更大,更慢,由全部插槽上的所有CPU核共用。
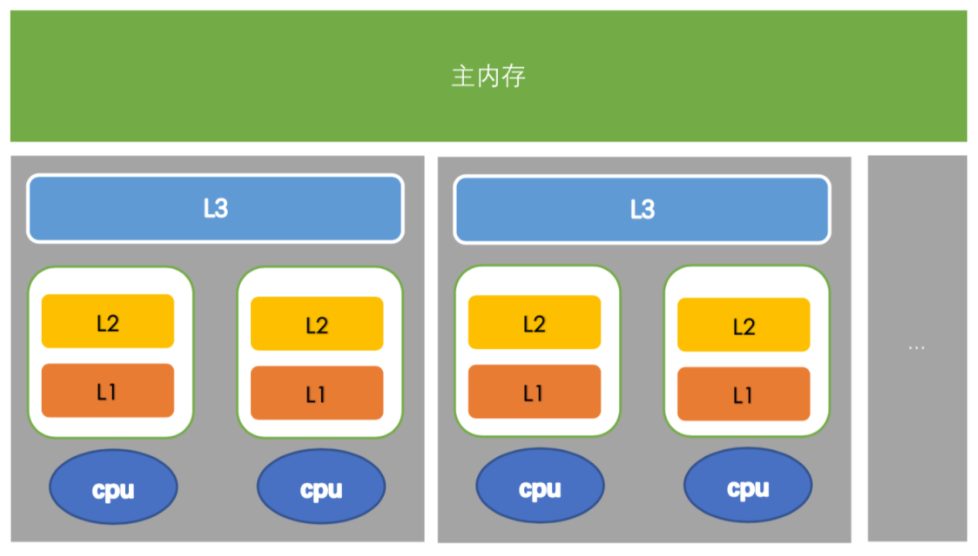
當CPU執行運算的時候,它先去L1查詢所需的資料,再去L2,然後L3,最後如果這些快取中都沒有,所需的資料就要去主記憶體拿。
走得越遠,運算耗費的時間就越長。所以如果進行一些很頻繁的運算,要確保資料在L1快取中。
(2)<CPU快取行>
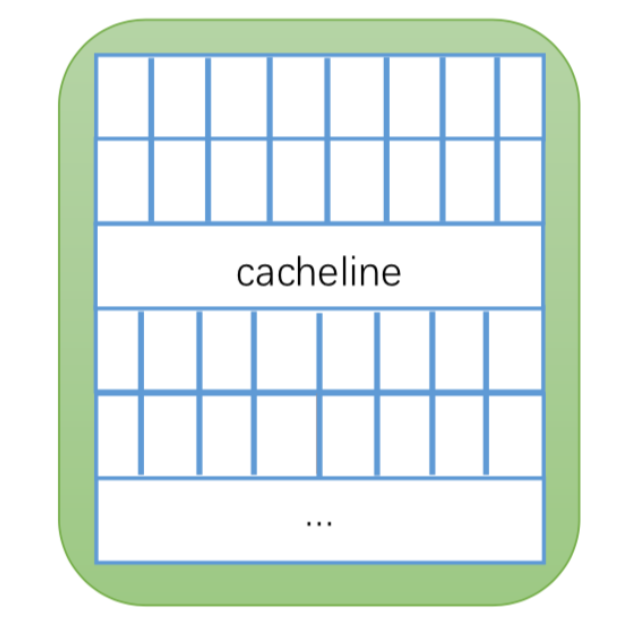
快取失效其實指快取行失效,Cache是由很多個Cache line 組成的,每個快取行大小是32~128位元組(通常是64位元組)。我們這裡假設快取行是64位元組,而java的一個Long型別是8位元組,這樣的話一個快取行就可以存8個Long型別的變數,如下圖所示。CPU 每次從主記憶體中獲取資料的時候都會將相鄰的資料存入到同一個快取行中。假設我們存取一個Long記憶體對應的陣列的時候,如果其中一個被載入到記憶體中,那麼對應的後面的7個資料也會被載入到對應的快取行中,這樣就會非常快的存取資料。
2.偽共用
根據MESI協定(快取一致性協定),我們知道在一個快取中的資料變化的時候會將其他所有儲存該快取的快取(其實是快取行)都失效。
(1)<範例概述>
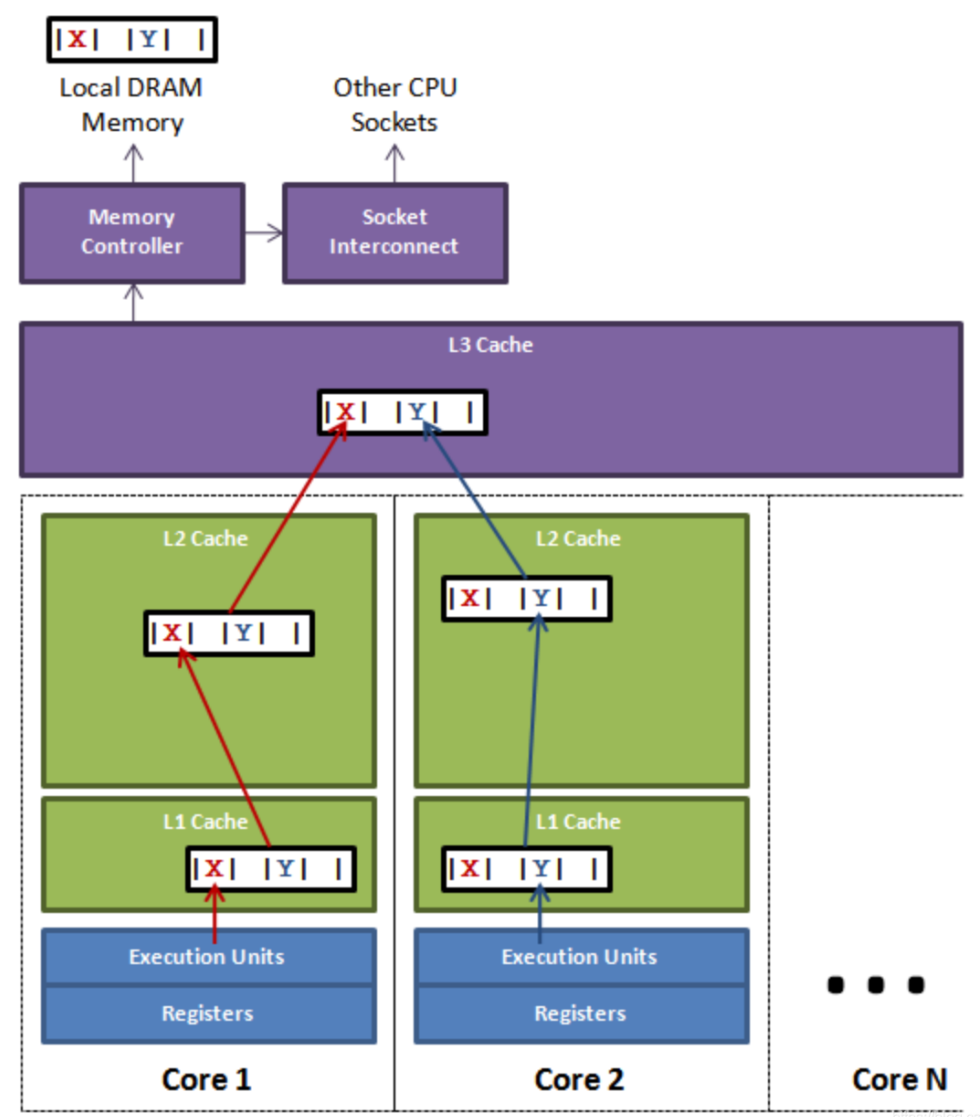
下圖中顯示的是一個槽的情況:裡面是多個CPU, 如果CPU1上面的執行緒更新了變數X,根據MESI協定,那麼變數X對應的所有快取行都會失效(由於X和Y被放到了一個快取行,所以一起失效了),這個時候如果cpu2中的執行緒進行讀取變數Y,發現快取行失效,想獲取Y就會按照快取查詢策略,往上查詢。如果期間cpu1對應的執行緒更新X後沒有存取X(也就是沒有重新整理快取行),cpu2的執行緒就只能從主記憶體中獲取資料,對效能就會造成很大的影響,這就是偽共用。
表面上 X 和 Y 都是被獨立執行緒操作的,而且兩操作之間也沒有任何關係。只不過它們共用了一個快取行,但所有競爭衝突都是來源於共用。
(2)<解決方法>
這個問題的解決辦法有兩個:
1.使用對齊填充,因為一個快取行大小是64個位元組,如果讀取的目標資料小於64個位元組,可以增加一些無意義的成員變數來填充。
2.在Java8裡面,提供了@Contented註解,它也是通過快取行填充來解決偽共用問題的,被@Contented註解宣告的類或者欄位,會被載入到獨立的快取行上。