【Java應用服務體系】「序章入門」全方位盤點和總結調優技術專題指南
專題⽬標
本系列專題的目標是希望可以幫助讀者們系統和全存取掌握應⽤系統調優的思路與方案以及相關的調優工具的使用,雖然未必會覆蓋目前的所有的問題場景,但是還是提供了較為豐富的案例和調優理論,會幫助大家開啟思維去⽀撐系統服務體系優化能力。
適合人員
Java相關的開發人員、系統架構師、資料庫DB人員以及運維人員等。
什麼是調優
調優手段就是讓計算機的硬體或軟體在正常地⼯作基礎上,非常出色的發揮其應有的效能,並且將所承擔的負擔降低到最低的技術手段。在Java應用服務體系中有大致可以分為5個維度的調優方向。
調優技術的五個維度
- 應⽤⾃身的調優
- 運⾏環境的調優(JVM的調優)
- 儲存上的調優(資料庫的調優)
- 作業系統的調優
- 架構上的調優
如下圖所示。
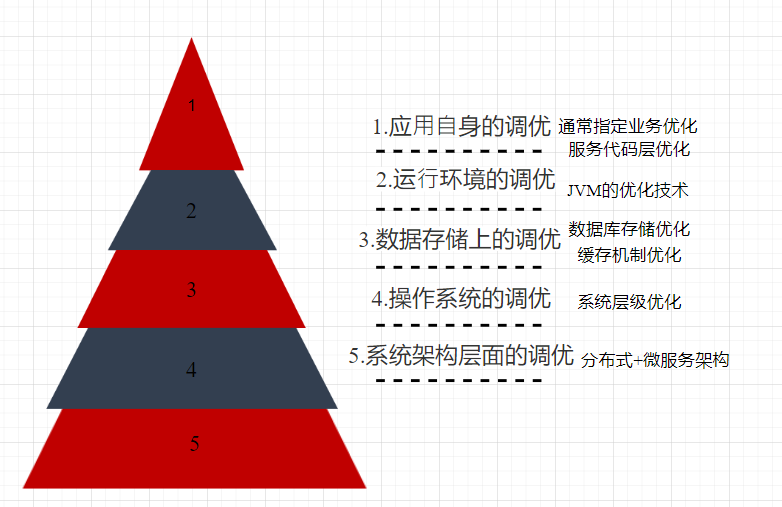
一般從上到下系統優化的層面成本越來越高,而從下到上系統優化層面的成本越來月底,而且難度也適當下降,建議自下而上的去進行調優規劃。
調優技術的四條準則
藉助監控預防問題、發現問題,監控 + 告警
採用監控和預防的手段去實現提前發現問題:zabbix、promethus等等
藉助⼯具定位問題
問題排查工具使用機制
定期覆盤,防⽌同類問題再現
定期進行排查和覆盤相關的程式碼問題,加深我們對問題的印象以及防止問題再次發生
定好規範,⼀定程度上規避問題
制定標準規範,約束問題的發生。
調優的原則
有問題,解決問題。not broken, don't fix.
應⽤調優
應⽤調優-⼯具篇
-
⼯具旨在幫助我們快速找到應⽤的效能瓶頸。
-
⽇志分析⼯具⽐較與分析
-
ELK、GrayLog、SLSLog...
-
ELK搭建與使⽤
-
現場演示
-
調⽤鏈跟蹤⼯具與對⽐
-
Skywalking、Sleuth + Zipkin、Jaeger...
-
Skywalking快速發現效能瓶頸
應⽤調優常⽤技巧-池化技術-物件池
通過復⽤物件,減少物件建立、垃圾回收的開銷
適⽤場景
維護⼀些很⼤、建立很慢的物件,提升效能
缺點:有學習成本、增加了程式碼的複雜度
物件池框架
Apache Commons-Pool2
Commons-Pool2詳解
兩⼤類物件池:ObjectPool & KeyedObjectPool
ObjectPool
實現類如下,其中,最重要、功能最強、使⽤最⼴泛的GenericObjectPool,這個物件池⾮常的強⼤,它⽐較的通⽤,⽽且封裝得也⾮常完備。
- BaseObjectPool:抽象類,⽤來擴充套件⾃⼰的物件池
- ErodingObjectPool:「腐蝕」物件池,代理⼀個物件池,並基於factor引數,為其新增「腐蝕」⾏為。歸還的物件被腐蝕後,將會丟棄,⽽不是新增到空閒容量中。
- GenericObjectPool:⼀個可設定的通⽤物件池實現。
- ProxiedObjectPool:代理⼀個其他的物件池,並基於動態代理(⽀持JDK代理和CGLib代理),返回⼀個代理後的物件。該物件池主要⽤來增強對池化物件的控制,⽐如防⽌在歸還該物件後,還繼續使⽤該物件等。
- SoftReferenceObjectPool:基於軟引⽤的物件池
- SynchronizedObjectPool:代理⼀個其他物件池,併為其提供執行緒安全的能⼒。
核⼼API如下
- borrowObject() 從物件池中借物件
- returnObject() 將物件歸還到物件池
- invalidateObject() 失效⼀個物件
- addObject() 增加⼀個空閒物件,該⽅法適⽤於使⽤空閒物件預載入物件池
- clear() 清空空閒的所有物件,並釋放相關資源
- close() 關閉物件池,並釋放相關資源
- getNumIdle() 獲得空閒的物件數量
- getNumActive() 獲得被借出物件數量
KeyedObjectPool
這種物件池和ObjectPool的區別在於,它是通過key找物件的,從設計上來看和ObjectPool沒什麼區別。實現類如下,使⽤最⼴的是GenericKeyedObjectPool。
- ErodingKeyedObjectPool 類似ErodingObjectPool
- GenericKeyedObjectPool 類似GenericObjectPool
- ProxiedKeyedObjectPool 類似ProxiedObjectPool
- SynchronizedKeyedObjectPool 類似SynchronizedObjectPool
使⽤
new GenericObjectPool(PooledObjectFactory<T> factory)
new GenericObjectPool(PooledObjectFactory<T> factory, GenericObjectPoolConfig<T> config)
new GenericObjectPool(PooledObjectFactory<T> factory, GenericObjectPoolConfig<T> config, AbandonedConfig abando
nedConfig)
最重要的引數是PooledObjectFactory,⼀般來說,⼯⼚是需要我們⾃⼰根據業務需求去實現的。它是⽤來建立物件的,這其實就是設計模式⾥⾯的⼯⼚模式。
⽬前PooledObjectFactory有兩個實現類。
- BasePooledObjectFactory:抽象類,⽤於擴充套件⾃⼰的PooledObjectFactory
- PoolUtils.SynchronizedPooledObjectFactory:內部類,代理⼀個其他的PooledObjectFactory,實現執行緒同步,⽤ PoolUtils.synchronizedPooledFactory() 建立
Factory核⼼⽅法:
- makeObject 建立⼀個物件範例,並將其包裝成⼀個PooledObject
- destroyObject 銷燬物件
- validateObject 校驗物件,確保物件池返回的物件是OK的
- activateObject 重新初始化物件
- passivateObject 取消初始化物件。GenericObjectPool的addIdleObject、returnObject、evict調⽤該⽅法。
Commons-Pool2總體分析
- ObjectPool:物件池,最核⼼:GenericObjectPool、 GenericKeyedObjectPool。
- Factory:建立&管理PooledObject,⼀般要⾃⼰擴充套件
- PooledObject:包裝原有的物件,從⽽讓物件池管理,⼀般⽤DefaultPooledObject即可
Factory範例
class MyPooledObjectFactory implements PooledObjectFactory<Model> {
public static final Logger LOGGER = LoggerFactory.getLogger(MyPooledObjectFactory.class);
@Override
public PooledObject<Model> makeObject() throws Exception {
DefaultPooledObject<Model> object = new DefaultPooledObject<>(new Model(1, "S"));
LOGGER.info("makeObject..state = {}", object.getState());
return object;
}
@Override
public void destroyObject(PooledObject p) throws Exception{
LOGGER.info("destroyObject..state = {}", object.getState());
}
@Override
public boolean validateObject(PooledObject p) {
LOGGER.info("validateObject..state = {}", object.getState());
return true;
}
@Override
public void activateObject(PooledObject p) throws Exception{
LOGGER.info("activateObject..state = {}", p.getState());
}
@Override
public void passivateObject(PooledObject p) {
LOGGER.info("passivateObject..state = {}", object.getState());
return true;
}
所有操作面向的都是PooledObject這個引數,makeObject返回的是PooledObject,其他API為什麼操作的也是 PooledObject,⽽不是直接操作我們建立的物件呢?
這其實也是commons-pool設計巧妙之處。Pooledobject可以對原始物件進⾏包裝,從⽽被物件池管理。⽬前 pooledobject有兩個實現類:
- DefaultPooledObject:包裝原始物件,實現監控(例如建立時間、使⽤時間等)、狀態跟蹤等
- PooledSoftReference:封裝了DefaultPooledObject,⽤來和SoftReferenceObjectPool配合使⽤。
DefaultPooledObject定義了物件的若⼲種狀態
- IDLE 物件在佇列中,並空閒。
- ALLOCATED 使⽤中(即出借中)
- EVICTION 物件當在佇列中,正在進⾏驅逐測試
- EVICTION_RETURN_TO_HEAD 物件驅逐測試通過後,放回到佇列頭部
- VALIDATION 物件當前在佇列中,空閒校驗中
- VALIDATION_PREALLOCATED 物件當前不在佇列中,出借前校驗中 VALIDATION_RETURN_TO_HEAD 物件當前不在佇列中,校驗通過後放回頭部 INVALID 物件失效,驅逐測試失敗、校驗失敗、物件銷燬,都會將物件置為 INVALID。
- ABANDONED 放逐中,如果物件上次使⽤時間超過removeAbandonedTimeout的設定,則將其標記為ABANDONED。標記為ABANDONED的物件即將變成 INVALID。
- RETURNING 物件歸還池中。
JVM調優
本系列專題將針對於Oracle Java HotSpot虛擬機器器為為開發者們提供不同的Java Heap記憶體空間的較為深入的分析介紹。對於任何接觸的開發者都是非常重要的理論依據。頻繁遇到的記憶體問題,提供生產環境的優化調整。那麼適當的實戰層級的Java虛擬機器器的記憶體空間分析能力是至關重要的。
前提概述
- Java虛擬機器器是你的Java程式執行的基礎,它為你提供動態的分配記憶體服務、垃圾收集、執行緒排程和切換、IO處理和本機操作等
- Java堆空間是執行時Java程式的記憶體「容器」,它提供給您的Java應用程式所需的適當記憶體空間(Java堆、本機堆),並由JVM本身去管理。
JVM HotSpot記憶體被劃分2類和5空間:
- Heap堆記憶體空間:屬於執行緒共用區域,也是我們JVM的記憶體管理範疇的最大的一部分執行時記憶體區域。
- 方法區(永久代/元空間):屬於執行緒共用區域,往往我們會忽略了這個區域的記憶體回收能力。
- 本地堆 (C-Heap):本地方法的呼叫棧。
- 虛擬機器器棧:Java方法的呼叫棧。
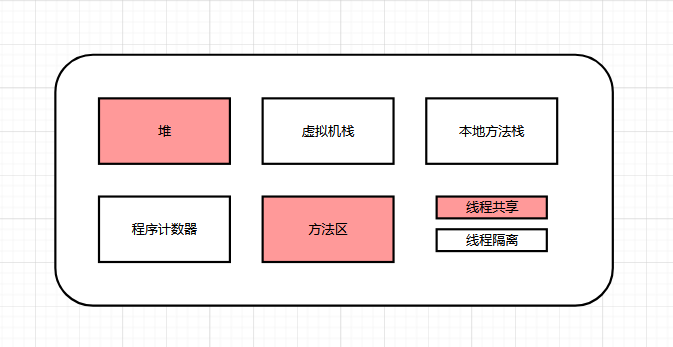
Heap堆記憶體空間
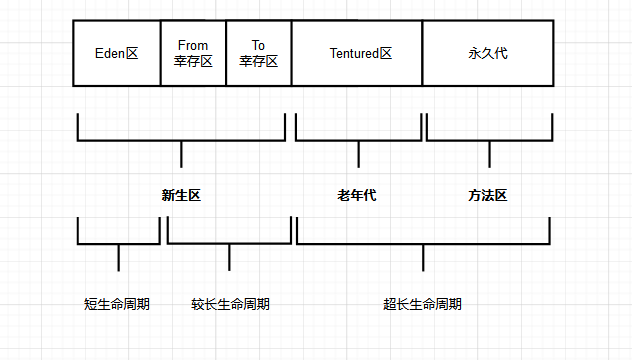
JVM的堆空間的變化在<18的版本之內,主要有一個分水嶺,主要集中在8之前和8之後。
JDK8之前的對空間
JDK8之前的Heap空間如下圖所示:
JDK8之後的Heap空間如下圖所示:
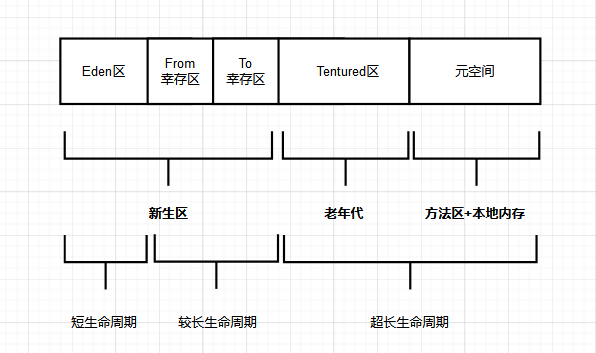
主要時針對於方法區的實現機制:永久代 -> 元空間結構模型,接下來我們看看後設資料空間在方法區中的分佈結構模型。
後續版本中的-元空間和方法去的記憶體才能出分配關係
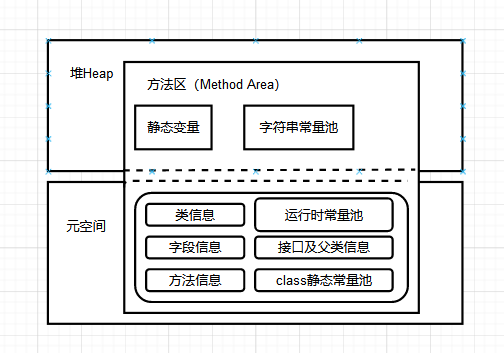
可以看到JDK8之後,方法去的實現有元空間和一部分堆記憶體組成。之前主要只有單純的永久代去實現的。
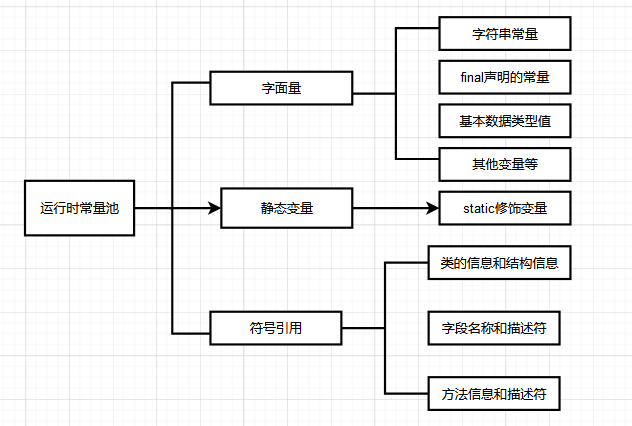
常數池
常數池主要有靜態常數池和執行時常數池組成。
- 類資訊
- 類的版本
- 欄位描述資訊
- 方法描述資訊
- 介面和父類別等描述資訊
- class檔案常數池(靜態常數池)
靜態常數池,也叫class⽂件常數池,主要存放:
- 字⾯量:例如⽂本字串、 final修飾的常數。
- 符號引⽤:例如類和接⼝的全限定名、欄位的名稱和描述符、⽅法的名稱和描述符。
運⾏時常數池
當類載入到記憶體中後,JVM就會將靜態常數池中的內容存放到運⾏時的常數池中;運⾏時常數池⾥⾯儲存的主要是編譯期間⽣成的字⾯量、符號引⽤等等。如下圖對應的字串常數在字串常數池中的儲存模式。
字串常數池
字串常數池,也可以理解成運⾏時常數池分出來的⼀部分,類載入到記憶體的時候,字串,會存到字串常數池⾥⾯。
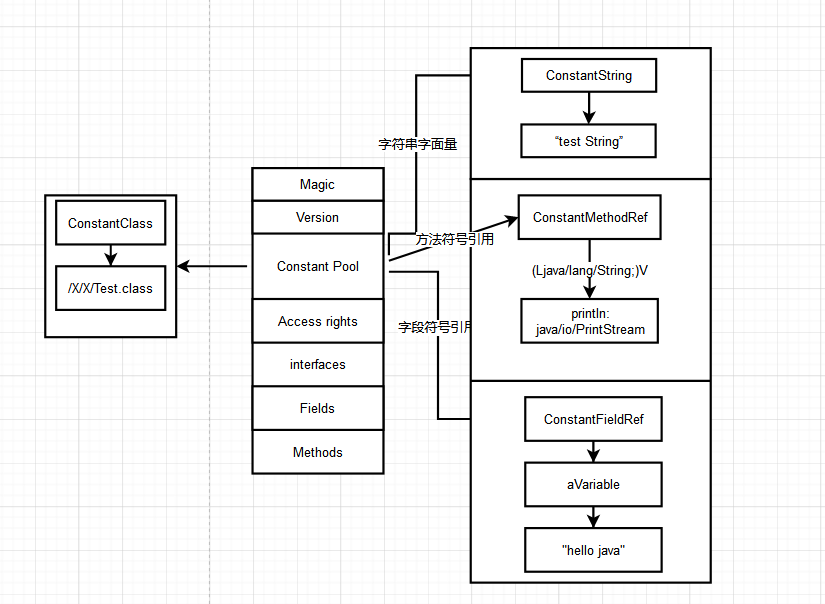
物件和類在記憶體分佈
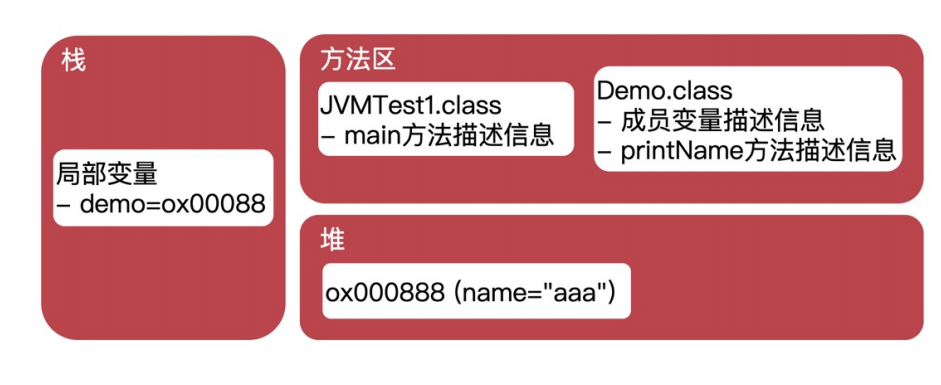
針對於程式碼的執行和儲存在JVM的分佈,主要集中在棧空間和堆空間、方法區。它們各個的職能不同,對應的能力也是不同的。我們針對於一段程式碼塊進行分析和介紹
虛擬機器器棧的基本結構模型
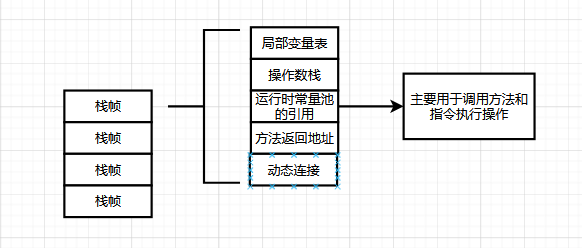
程式碼在堆疊中的儲存結構資訊
記憶體漏失怎麼排查[java記憶體溢位排查]
top 等檢視系統記憶體概況
top:顯示所有程序執行情況,按M鍵按照記憶體大小排序。
使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
引數說明
- d:指定每兩次螢幕資訊重新整理之間的時間間隔,當然使用者可以使用s互動命令來改變之。
- p:通過指定監控程序ID來僅僅監控某個程序的狀態。
- q:該選項將使top沒有任何延遲的進行重新整理。如果呼叫程式有超級使用者許可權,那麼top將以儘可能高的優先順序執行。
- S:指定累計模式。
- s:使top命令在安全模式中執行。這將去除互動命令所帶來的潛在危險。
- i:使top不顯示任何閒置或者僵死程序。
- c:顯示整個命令列而不只是顯示命令名。
命令說明
- jmx 快速發現jvm中的記憶體異常項
【實戰階段】JVM排查問題優化引數
jps [-q] [-mlvV] [<hostid>]
引數如下:
- -q 只顯示程序號
- -m 顯示傳遞給main⽅法的引數
- -l 顯示應⽤main class的完整包名應⽤的jar⽂件完整路徑名
- -v 顯示傳遞給JVM的引數
- -V 禁⽌輸出類名、JAR⽂件名和傳遞給main⽅法的引數,僅顯示本地JVM識別符號的列表
hostid的引數格式
- hostid:想要檢視的主機的識別符號,格式為: [protocol:][[//]hostname][:port][/servername] ,其中:
- protocol:通訊協定,預設rmi
- hostname:⽬標主機的主機名或IP地址
- port:通訊端⼝,對於預設 rmi 協定,該引數⽤來指定 rmiregistry 遠端主機上的端⼝號。如省略該引數,並且該
- protocol指示rmi,則使⽤預設使⽤1099端⼝。
- servicename:服務名稱,取值取決於實現⽅式,對於rmi協定,此引數代表遠端主機上RMI遠端物件的名稱
今天就寫到這裡,未完待續,等待下一部分的內容。
本文來自部落格園,作者:洛神灬殤,轉載請註明原文連結:https://www.cnblogs.com/liboware/p/17063422.html,任何足夠先進的科技,都與魔法無異。