【Django drf】 序列化類常用欄位類和欄位引數 客製化序列化欄位的兩種方式 關係表外來鍵欄位的反序列化儲存 序列化類繼承ModelSerializer 反序列化資料校驗原始碼分析
序列化類常用欄位類和欄位引數
常用欄位類
# BooleanField
BooleanField()
# NullBooleanField
NullBooleanField()
# CharField
CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True)
# EmailField
EmailField(max_length=None, min_length=None, allow_blank=False)
# RegexField
RegexField(regex, max_length=None, min_length=None, allow_blank=False)
# SlugField
SlugField(maxlength=50, min_length=None, allow_blank=False)
正則欄位,驗證正則模式 [a-zA-Z0-9-]+
# URLField
URLField(max_length=200, min_length=None, allow_blank=False)
# UUIDField
UUIDField(format=’hex_verbose’)
format:
1)'hex_verbose' 如 "5ce0e9a5-5ffa-654b-cee0-1238041fb31a"
2)'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a"
3)'int' 如 "123456789012312313134124512351145145114"
4)'urn' 如 "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a"
# IPAddressField
IPAddressField(protocol=’both’, unpack_ipv4=False, **options)
# IntegerField
IntegerField(max_value=None, min_value=None)
# FloatField
FloatField(max_value=None, min_value=None)
# DecimalField
DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None)
max_digits: 最多位數 decimal_palces: 小數點位置
# DateTimeField
DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None)
# DateField
DateField(format=api_settings.DATE_FORMAT, input_formats=None)
# TimeField
TimeField(format=api_settings.TIME_FORMAT, input_formats=None)
# DurationField
DurationField()
# ChoiceField
ChoiceField(choices) choices與Django的用法相同
# MultipleChoiceField
MultipleChoiceField(choices)
# FileField
FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
# ImageField
ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL)
---------記住以下幾個-----------
CharField
BooleanField
IntegerField
DecimalField
'''序列化類的額外欄位'''
# ListField
ListField(child=,min_length=None,max_length=None)
當hobby下有多個資料時,序列化之後返回的資料格式hobby的部分用列表 ---> ['籃球','足球'] 儲存。
{name:'lqz',age:19,hobby:['籃球','足球']}
# DictField
DictField(child=)
序列化之後,使用字典 ---> {'name':'劉亦菲','age':33}。
{name:'lqz',age:19,wife:{'name':'劉亦菲','age':33}}
常用欄位引數
選項引數
# 選項引數
給某一些指定的欄位使用的引數(不是每個欄位都能使用這些引數)
# 給CharField欄位類使用的引數
引數名稱 作用
max_length 最大長度
min_lenght 最小長度
allow_blank 是否允許為空
trim_whitespace 是否截斷空白字元
# 給IntegerField欄位類使用的引數
max_value 最小值
min_value 最大值
通用引數
# 通用引數:放在哪個欄位類上都可以的
引數名稱 作用
required 表明該欄位在反序列化時必須輸入,預設True
default 反序列化時使用的預設值(欄位如果沒傳,就是預設值)
allow_null 表明該欄位是否允許傳入None,預設False
validators 該欄位使用的驗證器【不需要了解】
error_messages 包含錯誤編號與錯誤資訊的字典
label 用於HTML展示API頁面時,顯示的欄位名稱
help_text 用於HTML展示API頁面時,顯示的欄位幫助提示資訊
# 重點
read_only 表明該欄位僅用於序列化輸出,預設False
(從資料庫拿出來,給前端)
write_only 表明該欄位僅用於反序列化輸入,預設False
(前端往後端傳入資料)
# 如何理解這裡的read\write
站在程式的角度:
從資料庫拿資料(序列化) ---> 讀
從前端獲取資料,寫入資料庫(反序列化) ---> 寫
上述引數用於反序列化校驗資料(類似form元件):

validators引數(瞭解):
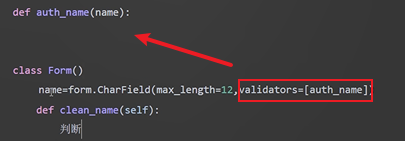
給validators傳入一個列表,列表中存放函數的記憶體地址。用這些函數來進行資料校驗。
總結:
# 校驗流程:
欄位引數限制(max_length) ---> validators函數校驗 ---> 區域性勾點 ---> 全域性勾點
# 有勾點函數,為什麼要使用validators?
勾點函數只能在當前類生效,而validators的校驗函數,可以在多個類生效,無需寫重複的程式碼
序列化類高階用法之source
source用於修改序列化欄位的名字。
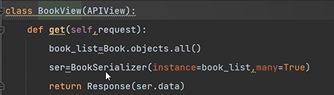
# 獲取所有圖書介面 使用APIView+Response+序列化類
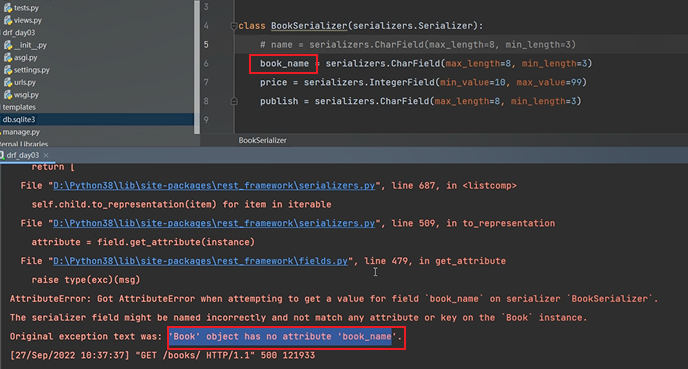
# 需求:name欄位在前端顯示的時候叫book_name
-使用source,欄位引數,可以指定序列化表中得哪個欄位
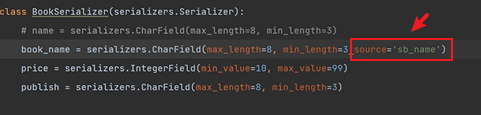
book_name = serializers.CharField(max_length=8, min_length=3,source='name')
-source指定的可以是欄位,也可以是方法,用於重新命名
-source可以做跨表查詢
source引數可以填寫三個東西。
source填寫類中欄位
檢視類:
序列化類:

序列化類中欄位和model類中的欄位需要一一對應:
可以使用source指向模型類中的方法,方法的返回值會被序列化。
序列化某個方法。
source支援跨表查詢
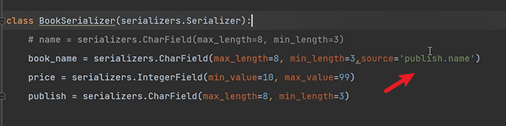
如果這裡的publish是一對多外來鍵欄位,該外來鍵在圖書類。可以通過publish.name跳轉到出版社,序列化出版社的名字。
程式碼:
class BookSerializer(serializers.Serializer):
name_detail = serializers.CharField(max_length=8, min_length=3,source='name')
# 或
publish_name = serializers.CharField(max_length=8, min_length=3,source='publish.name')
# 或
xx = serializers.CharField(max_length=8, min_length=3,source='xx') #source的xx表示表模型中得方法
客製化序列化欄位的兩種方式
準備工作
表建立:
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField(null=True)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
def __str__(self):
return self.name
# 寫了個方法,可以包裝成資料屬性,也可以不包
def publish_de(self):
return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email}
def author_li(self):
res_list = []
for author in self.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
class Author(models.Model):
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
def __str__(self):
return self.name
class AuthorDetail(models.Model):
telephone = models.BigIntegerField()
birthday = models.DateField()
addr = models.CharField(max_length=64)
class Publish(models.Model):
name = models.CharField(max_length=32)
city = models.CharField(max_length=32)
email = models.EmailField()
# def __str__(self):
# return self.name
publish是外來鍵欄位。
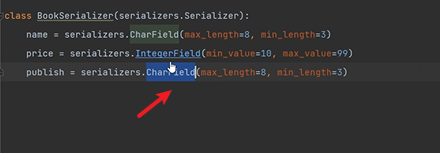
如果這裡寫CharField,那麼前端得到的序列化結果是什麼?
可見結果是字串:

這是因為我們寫了__str__:
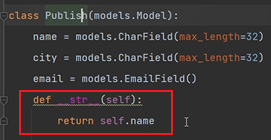
如果我們將__str__註釋掉,前端將會得到:

如果我們不在模型類中寫__str__,則需要使用source跨表查詢:
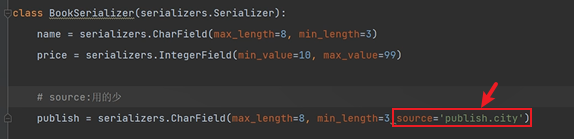
無論是__str__,還是source引數,都只能給前端返回出版社的某一個屬性(名稱|城市|郵箱)。
而我們希望返回一個字典物件,可以包含出版社的所有資訊,如下:
# 前端顯示形式
{
"name": "西遊記",
"price": 33,
"publish": {name:xx,city:xxx,email:sss}
}
實現該需求(客製化序列化)有以下兩種方法。
方法一:使用SerializerMethodField
# 第一種:在【序列化類】中寫SerializerMethodField
publish = serializers.SerializerMethodField()
def get_publish(self, obj):
# obj 是當前序列化的物件
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
這裡我們不使用CharField,因為CharField是用於序列化字串形式,而我們是想要序列化物件形式的資料。
使用SerializerMethodField:
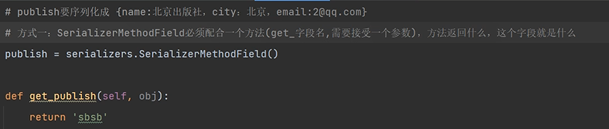
需要配合一個方法使用,這個方法的返回值是什麼,前端接收的publish就是什麼。

get_publish方法需要傳入一個引數obj,這個obj是當前序列化的物件:
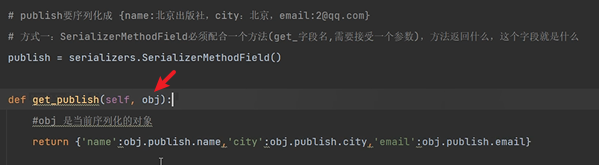
通過book物件進行跨表查詢,獲取出版社的各個欄位資料。

由於一本書可以有多個作者,所以我們返回一個列表,列表中是一個個作者物件。

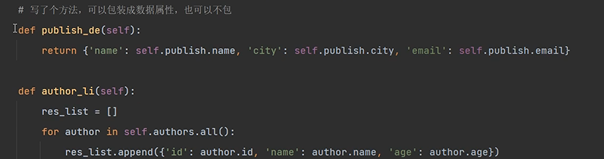
方法二:在模型類中寫方法
# 第二種:在【表模型】中寫方法(又多一些)
def publish_detail(self):
return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email}
在序列化中取
publish_detail=serializers.DictField()
# 在模型類中寫邏輯程式碼,稱之為ddd,領域驅動模型
也就是在表模型中寫一個方法,與序列化類中的欄位重名:

總結:序列化類不僅僅能序列化模型類中某個欄位,還能序列化模型類中的方法。這種方法和上面方法的實際區別就是,將同一段程式碼寫在不同的位置,寫在序列化類或者寫在模型表。
這裡如果我們序列化類使用charfield欄位,會造成postman無法美化顯示Json字典:

這裡是因為,我們模型類中方法返回的是一個字典,而CharField是用於序列化字串,所以會直接將字典強行轉化成字串(如上圖所示,該字典是用單引號引起來的,不是JSON格式)。
所以這裡應該使用DictField:

實現顯示所有作者:

在模型類中寫函數,返回作者列表。
方式一程式碼演示:使用SerializerMethodField
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8, min_length=3)
price = serializers.IntegerField(min_value=10, max_value=99)
publish_date = serializers.DateField()
# publish要序列化成 {name:北京出版社,city:北京,email:[email protected]}
# 方式一:SerializerMethodField必須配合一個方法(get_欄位名,需要接受一個引數),方法返回什麼,這個欄位就是什麼
publish = serializers.SerializerMethodField()
def get_publish(self, obj):
# obj 是當前序列化的物件
return {'name': obj.publish.name, 'city': obj.publish.city, 'email': obj.publish.email}
# 練習,用方式一,顯示所有作者物件 []
authors = serializers.SerializerMethodField()
def get_authors(self, obj):
res_list = []
for author in obj.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
方式二程式碼演示:在表模型中寫(用的最多)
# 表模型中
class Book(models.Model):
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=5, decimal_places=2)
publish_date = models.DateField(null=True)
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
authors = models.ManyToManyField(to='Author')
# 寫了個方法,可以包裝成資料屬性,也可以不包
def publish_detail(self):
return {'name': self.publish.name, 'city': self.publish.city, 'email': self.publish.email}
def author_list(self):
res_list = []
for author in self.authors.all():
res_list.append({'id': author.id, 'name': author.name, 'age': author.age})
return res_list
# 序列化類中
class BookSerializer(serializers.Serializer):
name = serializers.CharField(max_length=8, min_length=3)
price = serializers.IntegerField(min_value=10, max_value=99)
publish_date = serializers.DateField()
# 方式二:在表模型中寫方法
publish_detail = serializers.DictField(read_only=True)
# 練習,使用方式二實現,顯示所有作者
author_list = serializers.ListField(read_only=True)
在模型類中寫邏輯程式碼的行為(邏輯不寫在檢視類中),稱之為ddd(領域驅動模型)。
相關文章:
https://cloud.tencent.com/developer/article/1371115
關係表外來鍵欄位的反序列化儲存
多表關聯情況下的新增圖書介面:(request.data接收前端傳送的資料)
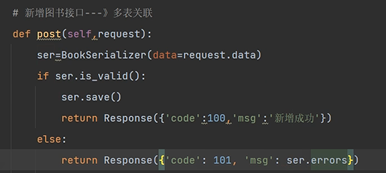
我們要新增圖書,除了上傳普通欄位,還要上傳外來鍵欄位。
需要在前端上傳出版社主鍵和作者列表(列表中是作者主鍵)。
注意:需要在序列化類中重寫create方法。
前端提交的資料
前端提交常見問題:

無法在新增圖書的時候新增出版社,publish欄位只能寫出版社的主鍵。而作者和作者詳情表可以一同新增。
前端的提交資料應該是這樣的:
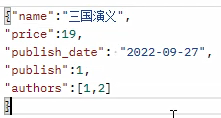
前端範例:
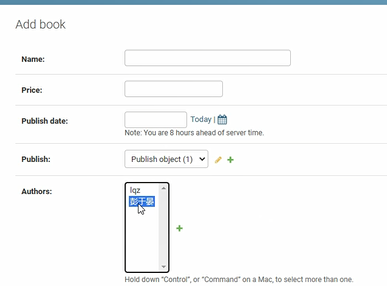
序列化類新增欄位
實現反序列化需要在序列化類中新增新欄位:

這兩個反序列化的欄位,對應著模型類中的外來鍵欄位:
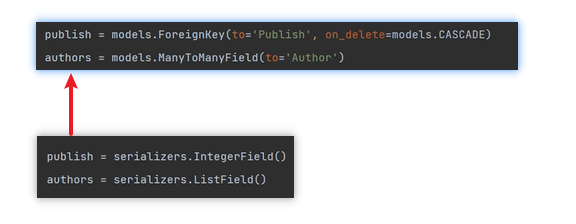
如果不新增這些引數,則可能會出現一個欄位既參與序列化,又參與反序列化的情況:
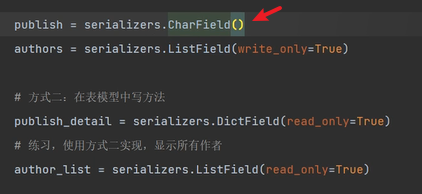
檢視前端接收到的序列化結果:

這裡是自動把序列化類中的欄位全部都序列化了。
publish在資料庫中沒有對應的欄位,所以這裡展現給前端的是一個物件。
重寫create方法
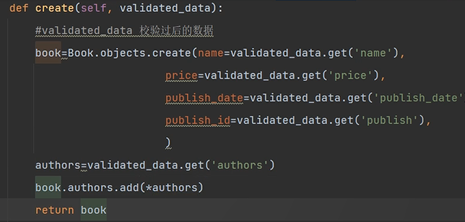
當前我們實現反序列化還需要重寫序列化類的create、updata的方法。
# 缺點
1 在序列化中每個欄位都要寫,無論是序列化還是反序列化
2 如果新增或者修改,在序列化類中都需要重寫create或update
# 解決這個缺點,使用ModelSerializer來做
程式碼:
# 1 序列化欄位和反序列化欄位不一樣 【序列化類中】
# 反序列化用的
publish = serializers.CharField(write_only=True)
authors = serializers.ListField(write_only=True)
#序列化用的
publish_detail = serializers.DictField(read_only=True)
author_list = serializers.ListField(read_only=True)
# 2 一定要重寫create 【序列化類中】
def create(self, validated_data):
# validated_data 校驗過後的資料
{"name":"三國1演義",
"price":19,
"publish_date": "2022-09-27",
"publish":1,
"authors":[1,2]
}
book = Book.objects.create(name=validated_data.get('name'),
price=validated_data.get('price'),
publish_date=validated_data.get('publish_date'),
publish_id=validated_data.get('publish'),
)
authors = validated_data.get('authors')
book.authors.add(*authors)
return book
序列化類繼承ModelSerializer
繼承ModelSerializer:

modelserializer是跟表有關聯的。
Meta類
在BookmodelSerializer中寫一個Meta類:
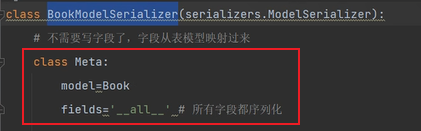
model=Book: 指定序列化的是哪個模型類
fields='__all__': 指定序列化哪些欄位,雙下all表示序列化模型類所有欄位。
修改檢視層,使用ModelSerializer:
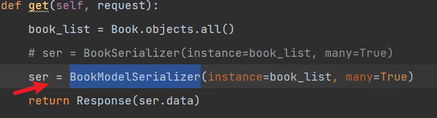
檢視結果:

可以發現把publish、authors的序列化結果是主鍵值,而我們希望能獲取出版社物件和作者物件,所以需要自己客製化如何序列化。
自定義序列化欄位
方法一:使用serializerMethodField
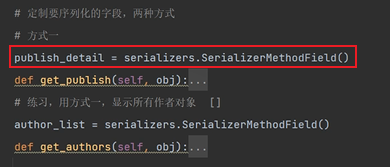
修改Meta類的fields:
在fields列表裡填寫,我們serializermethodfield產生的欄位
新增read_only:

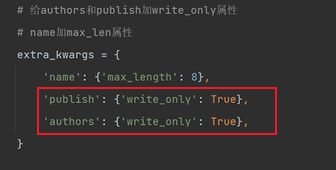
給authors和publish新增write_only屬性:
在Meta類寫extra_kwargs。你在字典裡寫的鍵值對,會當做欄位引數傳入欄位類。
程式碼:
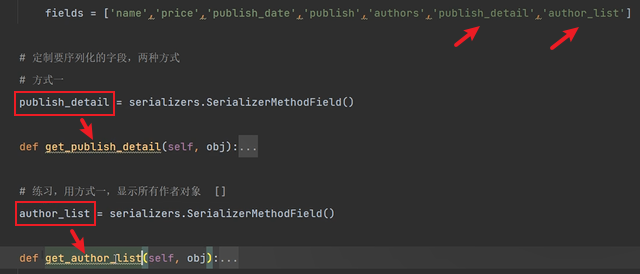
class BookModelSerializer(serializers.ModelSerializer): #ModelSerializer繼承Serializer
# 不需要寫欄位了,欄位從表模型對映過來
class Meta:
model = Book # 要序列化的表模型
# fields='__all__' # 所有欄位都序列化
fields = ['name', 'price', 'publish_date', 'publish', 'authors', 'publish_detail',
'author_list'] # 列表中有什麼,就是序列化哪個欄位
# 給authors和publish加write_only屬性
# name加max_len屬性
extra_kwargs = {
'name': {'max_length': 8},
'publish': {'write_only': True},
'authors': {'write_only': True},
}
publish_detail = serializers.SerializerMethodField(read_only=True)
...
author_list = serializers.SerializerMethodField(read_only=True)
...
剛剛我們是使用了自定義序列化的第一種方式:在序列化類中使用SerializerMethodField。
方法二:在模型類中寫方法
Meta類中的fields列表支援寫入以下幾種:
- 模型類中的欄位
- 模型類中的方法
- 序列化類中的欄位(SerializerMethodField)
在表模型內寫方法:
在field欄位註冊:
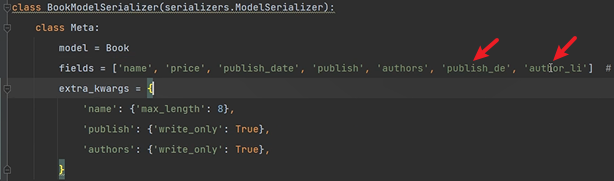
在field欄位註冊模型類中的方法時,就不存在新增引數read_only了,因為這兩個方法沒有對應的欄位。如果是方法一,則可以給SerializerMethodField欄位新增引數。
ModelSerializer使用總結
# 如何使用
1 定義一個類繼承ModelSerializer
2 類內部寫內部內 class Meta:
3 在內部類中指定model
填寫要序列化的表
4 在內部類中指定fields
寫要序列化的欄位,寫__all__表示所有,__all__不包含方法,如果要包含方法必須要在列表中寫一個個欄位。
範例:['欄位1','欄位2'...]
5 在內部類中指定extra_kwargs,給欄位新增欄位引數的
因為有些欄位是從模型類對映過來的,在序列化類中沒有這個欄位,所以需要使用extra_kwargs新增欄位引數。
6 在序列化類中,可以重寫某個欄位,優先使用你重寫的
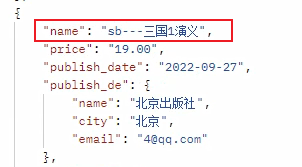
name = serializers.SerializerMethodField()
def get_name(self, obj):
return 'sb---' + obj.name
7 以後不需要重寫create和update了
-ModelSerializer寫好了,相容性更好,任意表都可以直接存(考慮了外來鍵關聯)
-當有特殊需求的情況下,也可以重寫
在序列化類中,可以重寫某個欄位,優先使用你重寫的:
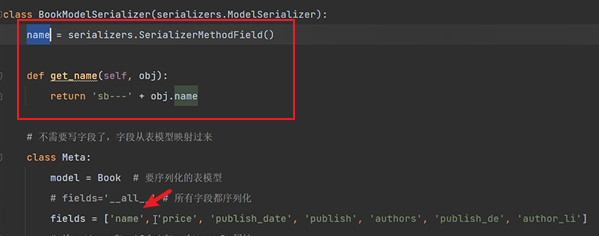
這裡我們在序列化類中,將name欄位寫了兩次,此時會優先用上面的。
正常情況下會直接輸出書名,我們進行重寫,可以給查詢到的結果做一些操作再輸出給前端。
也就是說:即可以在fields裡面註冊某個欄位,也可以手動重寫欄位。
檢視效果:
反序列化之資料校驗
反序列化的資料校驗和forms元件很像。既有欄位自己的校驗規則,也有區域性勾點、全域性勾點。
欄位自己的校驗規則
# 欄位自己的校驗規則
-如果繼承的是Serializer
因為序列化類中有欄位,所以可以直接新增欄位引數。
name=serializers.CharField(max_length=8,min_length=3,error_messages={'min_length': "太短了"})
-如果繼承的是ModelSerializer,有兩種方式:
1. 在Meta類上面重寫欄位
2. 使用Meta類extra_kwargs給欄位新增欄位引數
extra_kwargs = {
'name': {'max_length': 8, 'min_length': 3}, 'error_messages': {'min_length': "太短了"},
}
注意:只能新增模型類欄位包含的欄位引數。
勾點函數
# 區域性勾點
-如果繼承的是Serializer,寫法一樣
-如果繼承的是ModelSerializer,寫法一樣
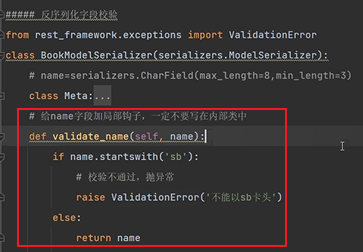
def validate_name(self, name):
if name.startswith('sb'):
# 校驗不通過,拋異常
raise ValidationError('不能以sb卡頭')
else:
return name
注意:區域性勾點不要寫在Meta類中。
# 全域性勾點
-如果繼承的是Serializer,寫法一樣
-如果繼承的是ModelSerializer,寫法一樣
def validate(self, attrs):
if attrs.get('name') == attrs.get('publish_date'):
raise ValidationError('名字不能等於日期')
else:
return attrs
'''當以上校驗全部通過,序列化類的is_valid才會通過'''
區域性勾點:
form元件區域性勾點函數範例: clean_name
反序列化校驗區域性勾點範例:validate_name
二者只是有名字上的區別。
反序列化資料校驗原始碼分析(瞭解)
# 校驗順序
先校驗欄位自己的規則(最大,最小),走區域性勾點校驗,走全域性勾點
# 疑問
區域性勾點:validate_name,全域性勾點:validate
為什麼勾點函數必須這樣命名?
# 入口
從哪開始看原始碼,哪個操作執行了欄位校驗 ---> ser.is_valid()
# 序列化類的繼承順序
你自己寫的序列化類 ---> 繼承了ModelSerializer ---> 繼承了Serializer ---> BaseSerializer ---> Field
'''一直往上查詢is_valid,發現在BaseSerializer裡有,如下只挑選is_valid最關鍵的程式碼'''
1. BaseSerializer內的is_valid()方法
def is_valid(self, *, raise_exception=False):
'''省略'''
# 如果沒有進行校驗,物件中就沒有_validated_data
if not hasattr(self, '_validated_data'):
try:
# 真正進行校驗的程式碼,如果校驗成功,返回校驗過後的資料
self._validated_data = self.run_validation(self.initial_data)
# 這裡的self.run_validation執行的是Serializer類的,而不是Field類的。
except ValidationError as exc:
return not bool(self._errors)
說明:self.run_validation(self.initial_data)這行程式碼執行的是Serializer的run_validation
-補充說明:如果你按住ctrl鍵,滑鼠點選,會從當前類中找run_validation,找不到會去父類別找
-這不是程式碼的執行,程式碼執行要從頭開始找,從自己身上再往上找(物件方法的查詢順序)
2.檢視Serializer中的run_validation:
def run_validation(self, data=empty):
# 區域性勾點的執行
value = self.to_internal_value(data)
try:
# 全域性勾點的執行,從根上開始找著執行,優先執行自己定義的序列化類中得全域性勾點
value = self.validate(value)
except (ValidationError, DjangoValidationError) as exc: # 注意這裡還能捕獲django丟擲的異常
raise ValidationError(detail=as_serializer_error(exc))
return value
-全域性勾點看完了,區域性勾點---》 self.to_internal_value---》從根上找----》本質執行的Serializer的
3.檢視Serializer中的to_internal_value
def to_internal_value(self, data):
for field in fields: # fields:序列化類中所有的欄位,for迴圈每次取一個欄位物件
# 反射:去self:序列化類的物件中,反射 validate_欄位名 的方法
validate_method = getattr(self, 'validate_' + field.field_name, None)
# field.field_name 獲取欄位物件的欄位名稱(字串)
try:
# 這句話是欄位自己的校驗規則(最大最小長度),執行的是field的run_validation
validated_value = field.run_validation(primitive_value)
# 區域性勾點
if validate_method is not None:
validated_value = validate_method(validated_value) # 區域性勾點執行
except ValidationError as exc:
errors[field.field_name] = exc.detail
return ret
欄位物件是什麼: name=serializers.CharField(max_length=8,min_length=3,error_messages={'min_length': "太短了"})
這裡的name就是一個欄位物件。具體可以研究OMR怎麼實現關係表對映。
檢視原始碼的設定
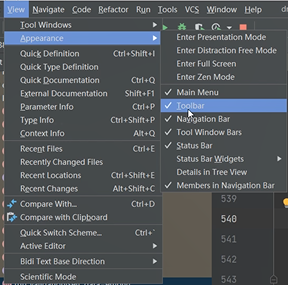
新增這個設定可以進行前進、回退等操作。
斷言assert
# 框架的原始碼中,大量使用斷言
# assert :斷言,作用的判斷,斷定一個變數必須是xx,如果不是就報錯
# 土鱉寫法
# name = 'lqz1'
# if not name == 'lqz':
# raise Exception('name不等於lqz')
#
# print('程式執行完了')
# assert的斷言寫法
name = 'lqz1'
assert name == 'lqz', 'name不等於lqz'
print('程式執行完了')
練習
#1 寫出book表(帶關聯關係)5 個介面
Serializer
ModelSerializer(簡單,不用重寫create和update)
name最大8,最小3,名字中不能帶sb
price最小9,最大199,不能為66
#2 出版社,作者,作者詳情 5個介面寫完(ModelSerializer好些一些)