Scrapy爬蟲框架快速入門
安裝scrapy
pip install scrapy -i https://pypi.douban.com/simple/
安裝過程可能遇到的問題
- 版本問題導致一些輔助庫沒有安裝好,需要手動下載並安裝一個輔助庫Twisted
- 執行時候:ModuleNotFoundError: No module named 'attrs'
pip install attrs --upgrade - 執行時候:Loading "scrapy.core.downloader.handlers.http.HTTPDownload Handler" for scheme "https"
pip install pywin32
建立專案
CMD進入需要建立專案的目錄下,輸入命令
scrapy startproject ×××

命令基本不需要死記硬背,正如下圖所示,會告訴你接下來需要輸入的命令

設定實體檔案(建立要獲取的欄位)
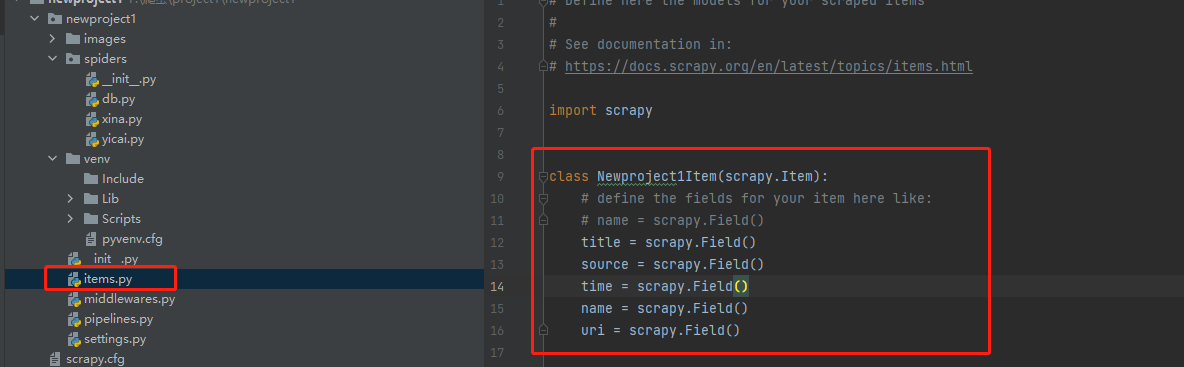
這個檔案內會寫入後續需要爬取的欄位,scrapy.Field()就是變數儲存區域,通過「spiders」裡的爬蟲檔案獲取的內容都會儲存在此處設定的區域裡。
然後以實體檔案作為中轉站,將這些變數傳輸到其他檔案中,例如,傳輸到管道檔案中進行資料儲存等處理。設定完實體檔案,就可以在實戰中應用剛才建立的變數了。
修改設定檔案(設定Robots協定和User-Agent,啟用管道檔案)
執行爬取檔案可能會遇到DEBUG:Forbidden by robots txt 說明百度的Robots協定禁止Scrapy框架直接爬取。
解決這個問題可以通過設定檔案20行左右的位置把OBEY置為False

設定User-Agent同樣在設定檔案40行左右位置,新增一行User-Agent

要進行資料的爬後處理,即將資料寫入資料庫或檔案等後續操作。所以先要啟用管道
後面的數位只是排序的順序,越小越靠前
如果管道檔案有新增類名,就需要在這裡新增

在資料夾「spiders」中編寫爬蟲邏輯(核心爬蟲程式碼)
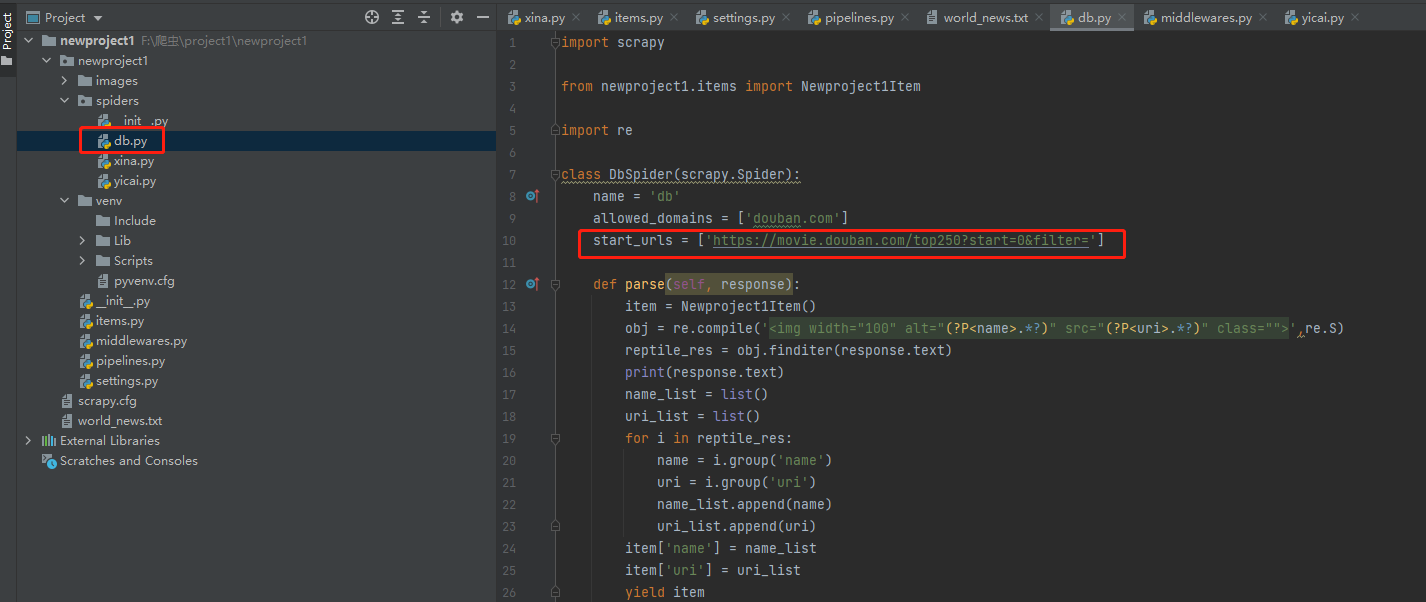
第10 行start_urls是一個列表存放需要爬取的url,如果需要爬取多個地址(例如存在ajex動態頁面爬取),可以往這個start_urls列表中append多個地址
爬蟲程式碼基本都在parse中
第13行範例化items,就是範例化需要提取的欄位
後面幾行都是基本的爬蟲程式碼這裡就解釋了,需要說一下的是response.text才是網頁原始碼
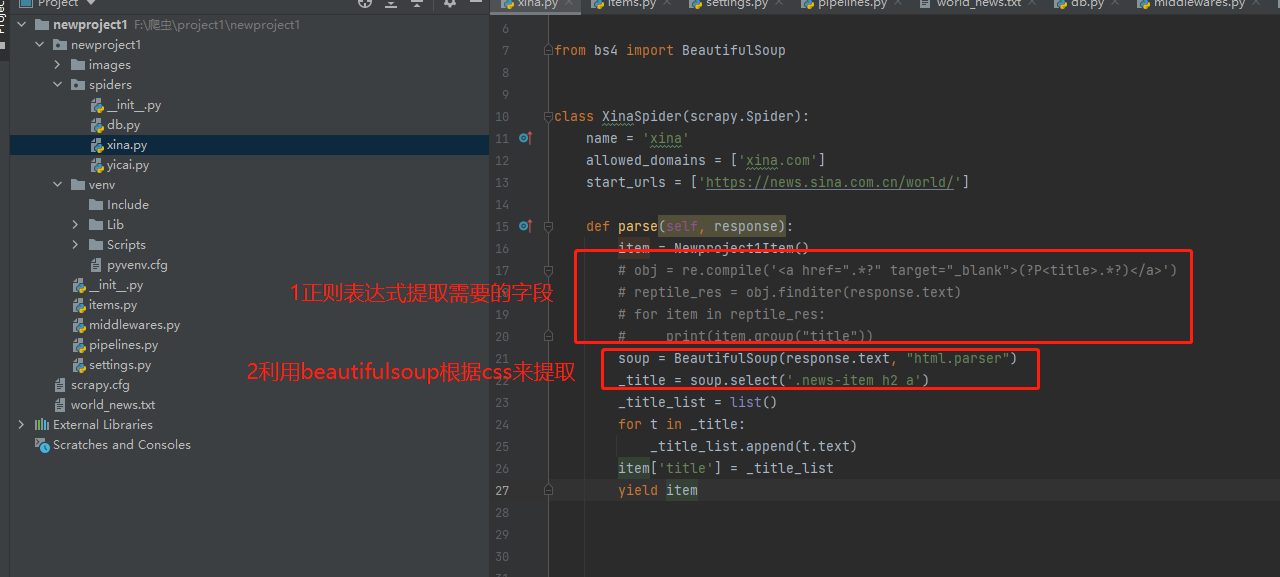
注:除了常見的用正規表示式提取,還有一個庫比較常見就是Beautifulsoup
設定管道檔案(爬後處理)
爬取後需要存入檔案或者下載檔案
這裡需要說一下,第15行和第24行去判斷spider.name是為了在執行的時候進行區分。
當然寫管道的時候,可以把所有處理方式寫在一個類中,通過spider.name去進行區分,也可以像下圖一樣用不同的類去寫。但如果是不同的類就需要到設定檔案中把新增類新增到設定中去。
第26行urlretrieve()函數是用來下載圖片

最後執行
最後在命令列輸入
scrapy crawl ****
作者: yetangjian
出處: https://www.cnblogs.com/yetangjian/p/17057552.html
關於作者: yetangjian
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出, 原文連結 如有問題, 可郵件([email protected])諮詢.