MySQL效能優化淺析及線上案例
作者:京東健康 孟飛
1、 資料庫效能優化的意義
業務發展初期,資料庫中量一般都不高,也不太容易出一些效能問題或者出的問題也不大,但是當資料庫的量級達到一定規模之後,如果缺失有效的預警、監控、處理等手段則會對使用者的使用體驗造成影響,嚴重的則會直接導致訂單、金額直接受損,因而就需要時刻關注資料庫的效能問題。
2、 效能優化的幾個常見措施
資料庫效能優化的常見手段有很多,比如新增索引、分庫分表、優化連線池等,具體如下:
| 序號 | 型別 | 措施 | 說明 |
|---|---|---|---|
| 1 | 物理級別 | 提升硬體效能 | 將資料庫安裝到更高設定的伺服器上會有立竿見影的效果,例如提高CPU設定、增加記憶體容量、採用固態硬碟等手段,在經費允許的範圍可以嘗試。 |
| 2 | 應用級別 | 連線池引數優化 | 我們大部分的應用都是使用連線池來託管資料庫的連線,但是大部分都是預設的設定,因而設定好超時時長、連線池容量等引數就顯得尤為重要。 1、 如果連結長時間被佔用,新的請求無法獲取到新的連線,就會影響到業務。 2、 如果連線數設定的過小,那麼即使硬體資源沒問題,也無法發揮其功效。之前公司做過一些壓測,但就是死活不達標,最後發現是由於連線數太小。 |
| 3 | 單表級別 | 合理運用索引 | 如果資料量較大,但是又沒有合適的索引,就會拖垮整個效能,但是索引是把雙刃劍,並不是說索引越多越好,而是要根據業務的需要進行適當的新增和使用。 缺失索引、重複索引、冗餘索引、失控索引這幾類情況其實都是對系統很大的危害。 |
| 4 | 庫表級別 | 分庫分表 | 當資料量較大的時候,只使用索引就意義不大了,需要做好分庫分表的操作,合理的利用好分割區鍵,例如按照使用者ID、訂單ID、日期等維度進行分割區,可以減少掃描範圍。 |
| 5 | 監控級別 | 加強運維 | 針對線上的一些系統還需要進一步的加強監控,比如訂閱一些慢SQL紀錄檔,找到比較糟糕的一些SQL,也可以利用業務內一些通用的工具,例如druid元件等。 |
3、 MySQL底層架構
首先了解一下資料的底層架構,也有助於我們做更好優化。
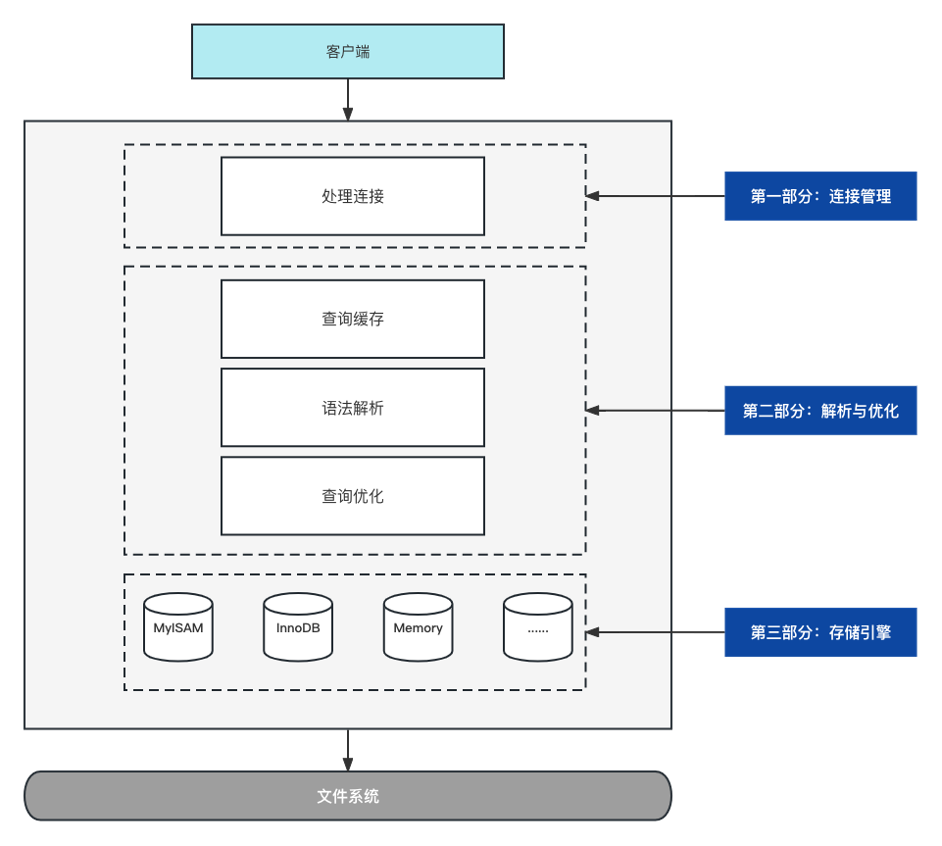
一次查詢請求的執行過程
我們重點關注第二部分和第三部分,第二部分其實就是Server層,這層主要就是負責查詢優化,制定出一些執行計劃,然後呼叫儲存引擎給我們提供的各種底層基礎API,最終將資料返回給使用者端。
4、MySQL索引構建過程
目前比較常用的是InnoDB儲存引擎,本文討論也是基於InnoDB引擎。我們一直說的加索引,那到底什麼是索引、索引又是如何形成的呢、索引又如何應用呢?這個話題其實很大也很小,說大是因為他底層確實很複雜,說小是因為在大部分場景下程式設計師只需要新增索引就好,不太需要了解太底層原理,但是如果瞭解不透徹就會引發線上問題,因而本文平衡了大家的理解成本和知識深度,有一定底層原理介紹,但是又不會太過深入導致難以理解。
首先來做個實驗:
建立一個表,目前是隻有一個主鍵索引
CREATE TABLE t1(
a int NOT NULL,
b int DEFAULT NULL,
c int DEFAULT NULL,
d int DEFAULT NULL,
e varchar(20) DEFAULT NULL,
PRIMARYKEY(a)
)ENGINE=InnoDB
插入一些資料:
insert into test.t1 values(4,3,1,1,'d');
insert into test.t1 values(1,1,1,1,'a');
insert into test.t1 values(8,8,8,8,'h');
insert into test.t1 values(2,2,2,2,'b');
insert into test.t1 values(5,2,3,5,'e');
insert into test.t1 values(3,3,2,2,'c');
insert into test.t1 values(7,4,5,5,'g');
insert into test.t1 values(6,6,4,4,'f');
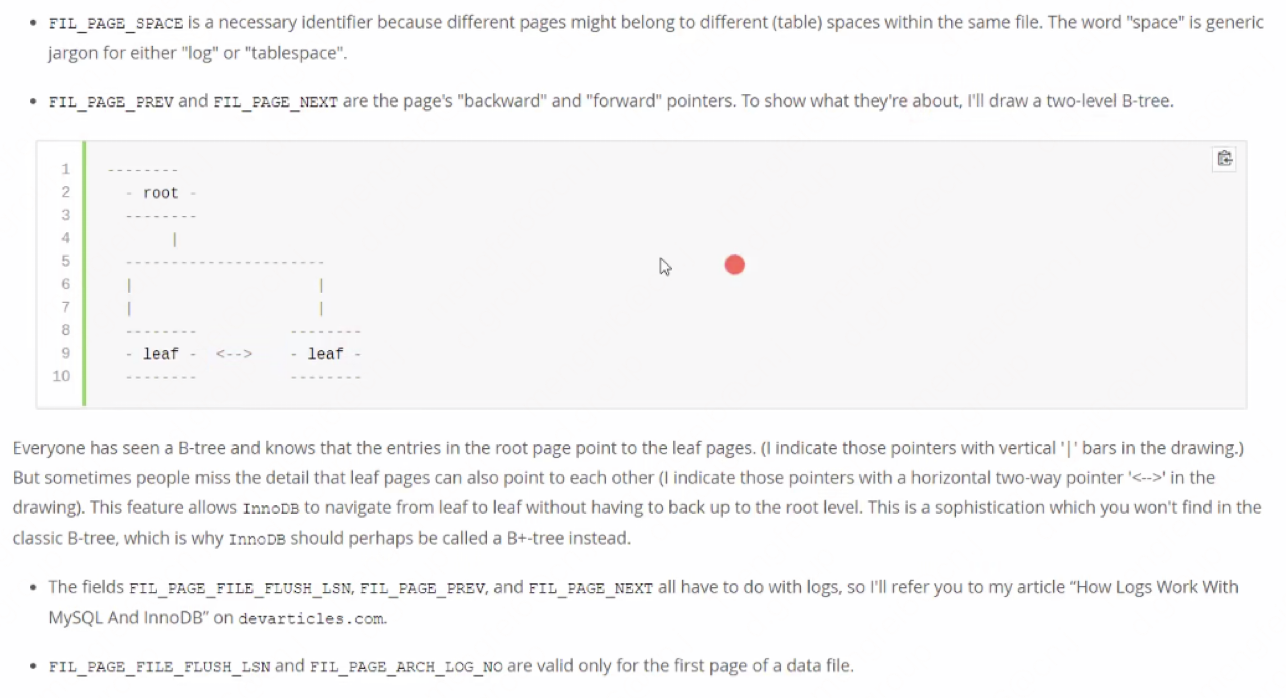
MYSQL從磁碟讀取資料到記憶體是按照一頁讀取的,一頁預設是16K,而一頁的格式大概如下。
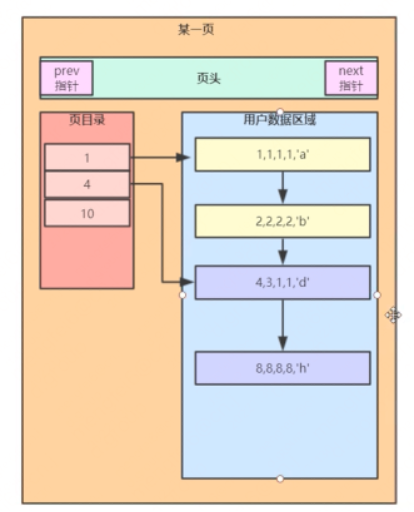
每一頁都包括了這麼幾個內容,首先是頁頭、其次是頁目錄、還有使用者資料區域。
1)剛才插入的幾條資料就是放到這個使用者資料區域的,這個是按照主鍵依次遞增的單向連結串列。
2)頁目錄這個是用來指向具體的使用者資料區域,因為當用戶資料區域的資料變多的時候也就會形成分組,而頁目錄就會指向不同的分組,利用二分查詢可以快速的定位資料。
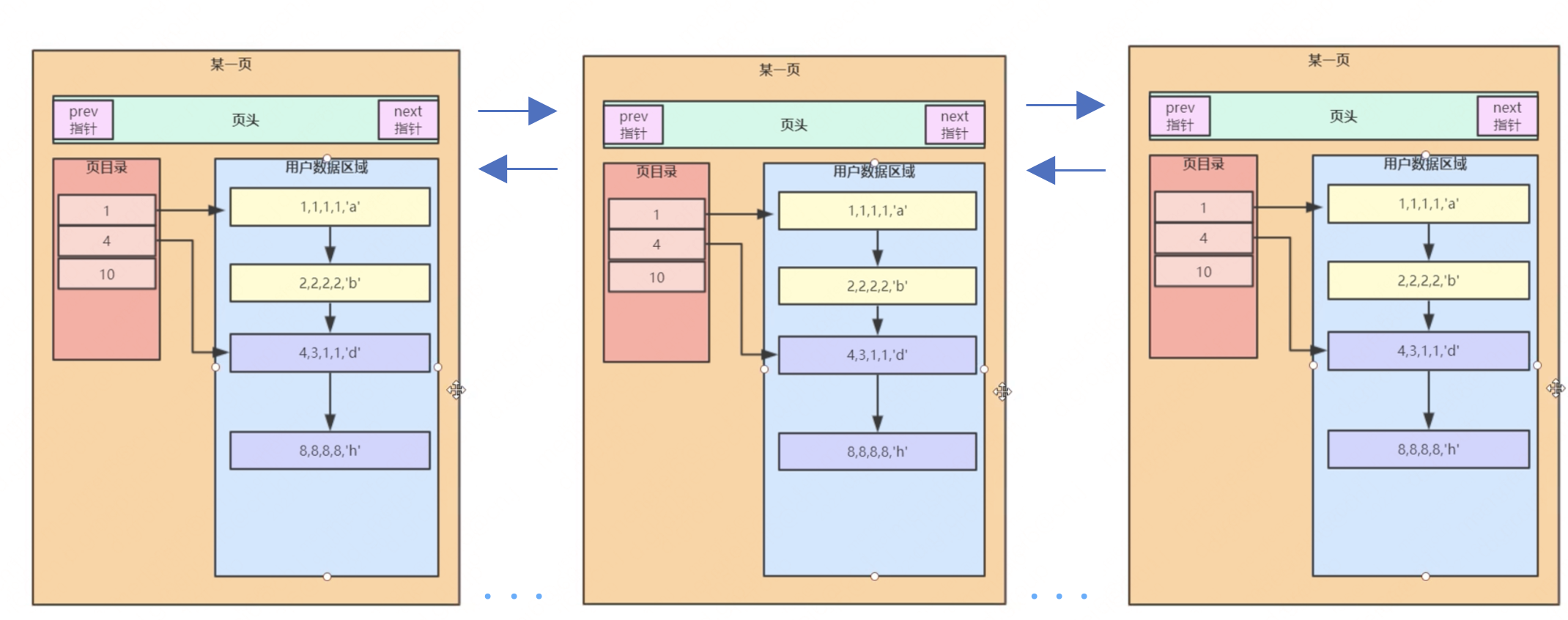
當資料量變多的時候,那麼這一頁就裝不下這麼多資料,就要分裂頁,而每頁之間都會雙向連結,最終形成一個雙向連結串列。
頁內的單向連結串列是為了查詢快捷,而頁間的雙向連結串列是為了在做範圍查詢的時候提效,下圖為示意圖,其中其二頁和第三頁是複製的第一頁,並不真實。
而如果資料還繼續累加,光這幾個頁也不夠了,那就逐步的形成了一棵樹,也就是說索引B-Tree是隨著資料的積累逐步構建出來的。
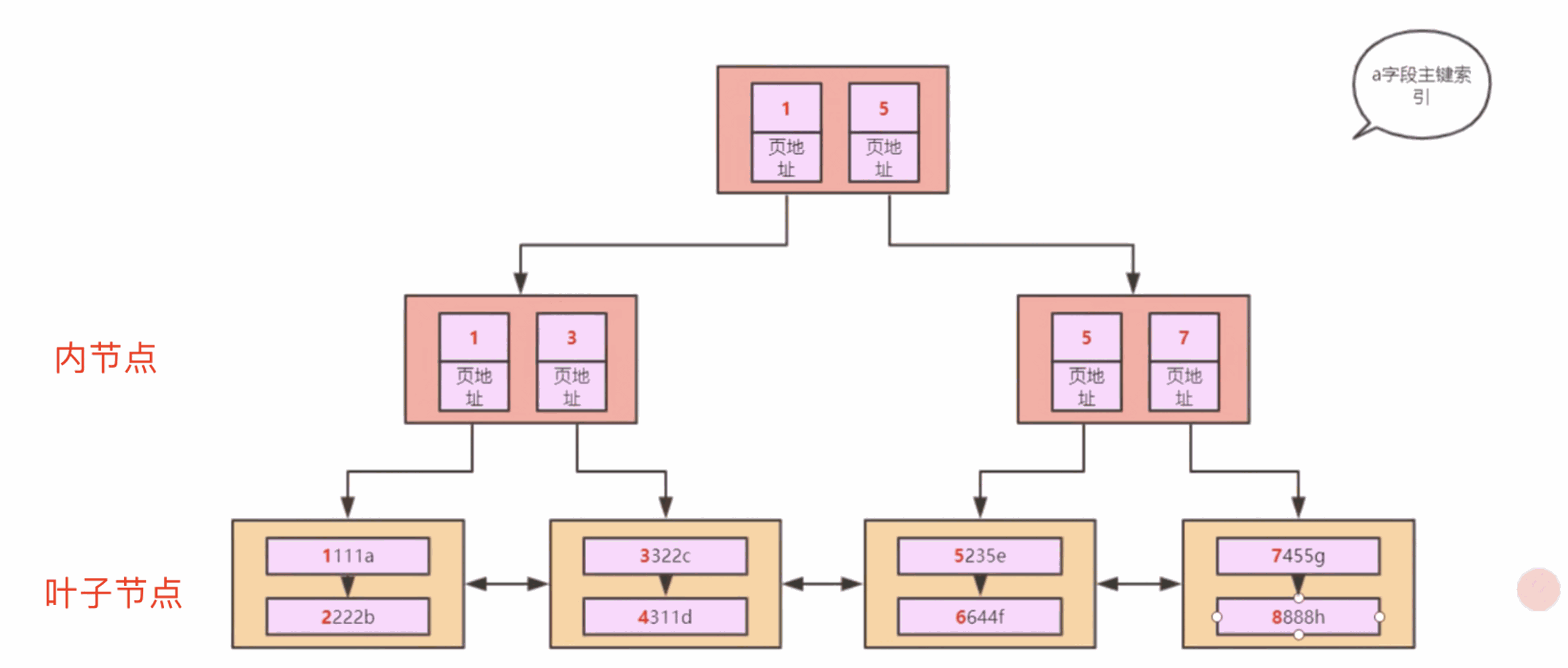
最下邊的一層叫做葉子節點,上邊的叫做內節點,而葉子節點中儲存的是全量資料,這樣的樹就是聚簇索引。一直有同學的理解是說索引是單獨一份而資料是一份,其實MySQL中有一個原則就是資料即索引、索引即資料,真實的資料本身就是儲存在聚簇索引中的,所謂的回表就是回的聚簇索引。
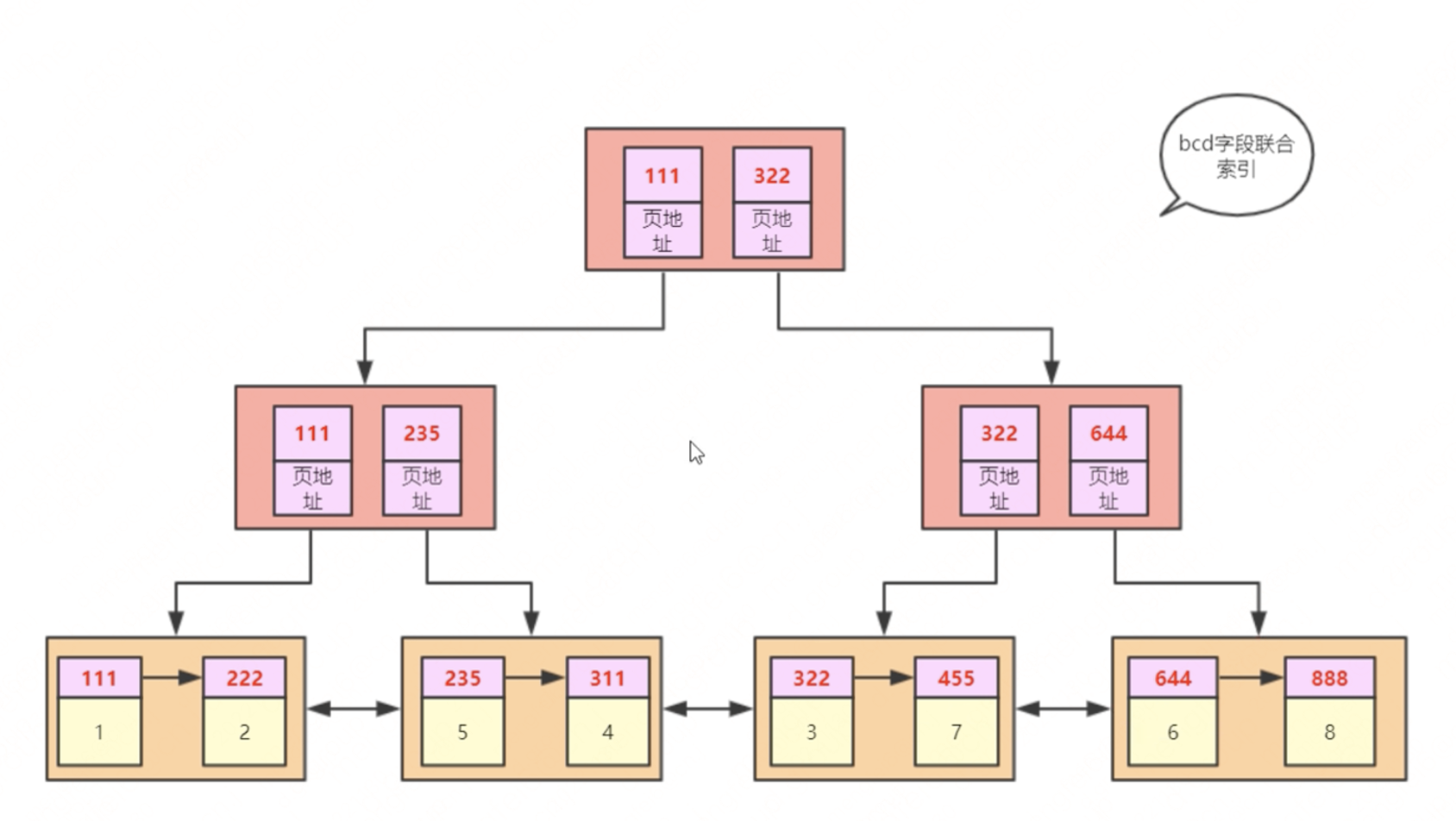
但是我們也不一定每次都按照主鍵來執行SQL語句,大部分情況下都是按照一些業務欄位來,那就會形成別的索引樹,例如,如果按照b,c,d來建立的索引就會長這樣。
推薦1個網站,可以視覺化的檢視一些演演算法原型:
目錄:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B+樹
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
而在MySQL官網上介紹的索引的葉子節點是雙向連結串列。
關於索引結構的小結:
對於B-Tree而言,葉子節點是沒有連結的,而B+Tree索引是單向連結串列,但是MySQL在B+Tree的基礎之上加以改進,形成了雙向連結串列,雙向的好處是在處理> <,between and等'範圍查詢'語法時可以得心應手。
5、MySQL索引的一些使用規範
1、 只為用於搜尋、排序或分組的列建立索引。
重點關注where語句後邊的情況
2、 當列中不重複值的個數在總記錄條數中的佔比很大時,才為列建立索引。
例如手機號、使用者ID、班級等,但是比如一張全校學生表,每條記錄是一名學生,where語句是查詢所有’某學校‘的學生,那麼其實也不會提高效能。
3、 索引列的型別儘量小。
無論是主鍵還是索引列都儘量選擇小的,如果很大則會佔據很大的索引空間。
4、 可以只為索引列字首建立索引,減少索引佔用的儲存空間。
alter table single_table add index idx_key1(key1(10))
5、 儘量使用覆蓋索引進行查詢,以避免回表操作帶來的效能損耗。
select key1 from single_table order by key1
6、 為了儘可能的少的讓聚簇索引發生頁面分裂的情況,建議讓主鍵自增。
7、 定位並刪除表中的冗餘和重複索引。
冗餘索引:
單列索引:(欄位1)
聯合索引:(欄位1 欄位2)
重複索引:
在一個欄位上新增了普通索引、唯一索引、主鍵等多個索引
6、 執行計劃

其中常用的是:
possible_keys: 可能用到的索引
key: 實際使用的索引
rows:預估的需要讀取的記錄條數
7、 線上案例
案例1:
在建設網際網路醫院系統中,問診單表當時量級23萬左右,其中有一個business_id字串欄位,這個欄位用來記錄外部訂單的ID,並且在該欄位上也加了索引,但是'根據該ID查詢詳情'的SQL語句卻總是時好時壞,效能不穩定,快則10ms,慢則2秒左右,SQL大體如下:
select 欄位1、欄位2、欄位3 from nethp_diag where business_Id = ?
因為business_id是記錄第三方系統的訂單ID,為了相容不同的第三方系統,因而設計成了字串型別,但如果傳入的是一個數位型別是無法使用索引的,因為MySQL只能將字串轉數位,而不能將數位轉字串,由於外部的ID有的是數位有的是字串,因而導致索引一會可以走到,一會走不到,最終導致了效能的不穩定。
案例2:
在某次大促的當天,突然接到DBA運維的報警,說資料庫突然流量激增,CPU也打到100%了,影響了部分線上功能和體驗,遇到這種情況當時大部分人都比較緊張,下圖為當時的資料庫流量情況:
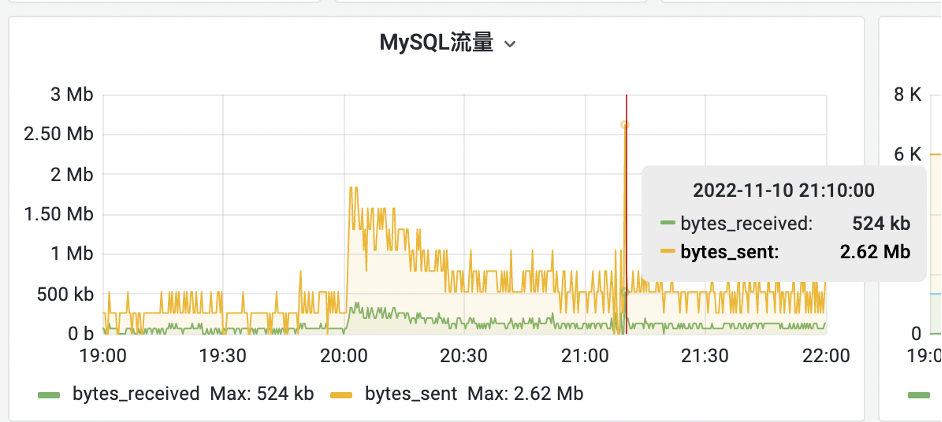

相關SQL語句:
當時的索引情況

當時的執行計劃

其實在patientId和doctor_pin兩個欄位上是有索引的,但是由於線上情況的改變,導致test判斷沒有進入,這樣的通用查詢導致這兩個欄位沒有設定上,進而導致了資料庫掃描的量激增,對資料庫產生了很大壓力。
案例3:
2020年某日上午收到資料庫CPU異常報警,對線上有一定的影響,後續檢查資料庫CPU情況如下,從7點51分開始,CPU從8%瞬間達到99.92%,絲毫沒有給程式設計師留任何情面。
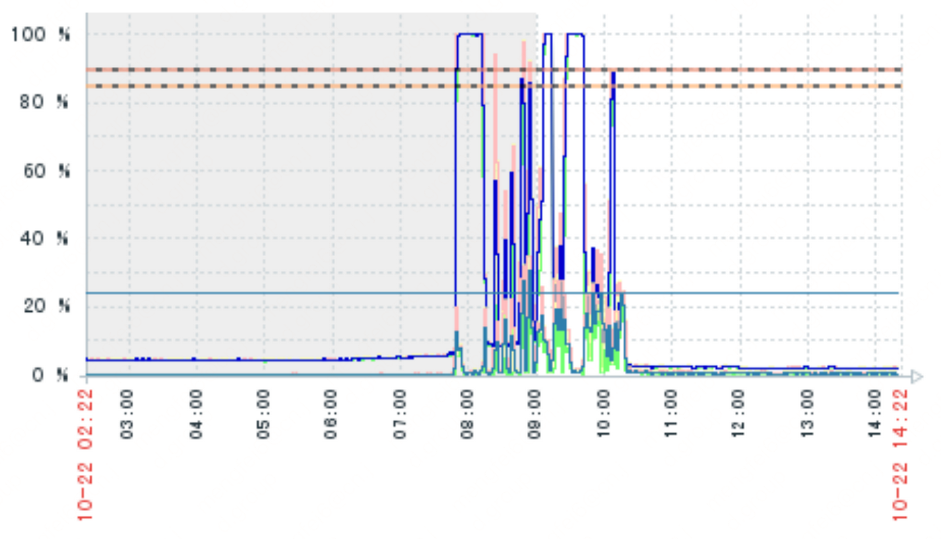
當時的SQL語句:
select rx_id, rx_create_time from nethp_rx_info where rx_status = 5 and status = 1 and rx_product_type = 0 and (parent_rx_id = 0 or parent_rx_id is null) and business_type != 7 and vender_id = 8888 order by rx_create_time asc limit 1;
當時的索引情況:
PRIMARY KEY (id), UNIQUE KEY uniq_rx_id (rx_id), KEY idx_diag_id (diag_id), KEY idx_doctor_pin (doctor_pin) USING BTREE, KEY idx_rx_storeId (store_id), KEY idx_parent_rx_id (parent_rx_id) USING BTREE, KEY idx_rx_status (rx_status) USING BTREE, KEY idx_doctor_status_type (doctor_pin, rx_status, rx_type), KEY idx_business_store (business_type, store_id), KEY idx_doctor_pin_patientid (patient_id, doctor_pin) USING BTREE, KEY idx_rx_create_time (rx_create_time)
當時這張表量級2000多萬,而當這條慢SQL執行較少的時候,資料庫的CPU也就下來了,恢復到了49.91%,基本可以恢復線上業務,從而表象就是線上間歇性的一會可以開方一會不可以,這條SQL當時總共執行了230次,當時的CPU情況也是忽高忽低,伴隨這條SQL語句的執行情況,從而最終證明CPU的飆升是由於這條慢SQL。當線上業務邏輯複雜的時候,你很難第一時間知道到底是由於那條SQL引起的,這個就需要對業務非常熟悉,對SQL很熟悉,否則就會白白浪費大量的排查時間。
最後的排查結果:
在頭天晚上的時候新增了一條索引rx_create_time,當時沒事,但是第二天卻出了事故。
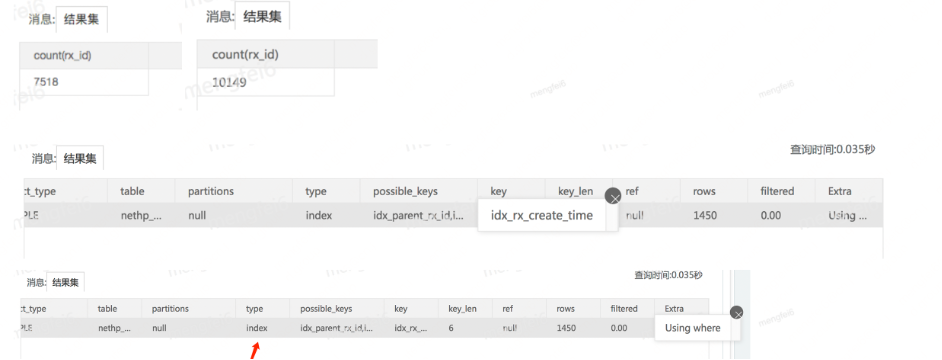
加索引前後走的索引不同,一個是走的rx_status(處方稽核狀態)單列索引,一個是走的rx_create_time(處方提交事件)單列索引,這個就要回到業務,因為處方狀態是個列舉,且列舉範圍不到10個,也就說線上29,000,000的資料量也就是被分成了不到10份,rx_status=5的值是其中一份,因而通過這個索引就可以命中很多行,這是業務規則,再套用MySQL的特性,主要是以下幾條:
1、沒加新索引rx_create_time的時候,由於order by後邊沒有索引,就看where條件中是否有合適的索引,查詢選擇器選定rx_status這個單列索引,而rx_status=5這個條件下限制的資料行在索引中是連續,即使需要的rx_id不在索引中,再回主鍵聚簇索引也來得及,由於order by後邊沒有索引,所以走磁碟級別的排序filesort,高峰積壓的時候處方就1萬到2萬,跑到了100ms,白天低谷的時候幾百單也就20ms。
2、新加索引之後,就分兩種情況:
2.1、加索引是在晚上,當前命中的行數比較少,由於當天晚上的時候待稽核的處方確實很少,也就是rx_status=5的確實很少,查詢優化器感覺反正沒多少行,排序不重要,因而就還是選擇rx_status索引。
2.2、第二天白天,待稽核的處方數量很多了(rx_status=5的資料量多了),當時可以命中幾萬資料,如果當前命中的行數比較多,查詢優化器就開始算成本,感覺排序的成本會更高,那就優先保排序吧,所以就選擇rx_create_time這個欄位,但是這個索引樹上沒有別的索引欄位的資訊,沒辦法,幾乎每條資料都要回表,進而引發了災難。
8、 推薦用書
這本書以一種詼諧幽默的風格寫了MySQL的一些執行機制,非常適合閱讀,理解成本大幅降低。
https://item.jd.com/13009316.html
https://item.jd.com/10066181997303.html
9、一些感悟
關於資料庫的效能優化其實是一個很複雜的大課題,很難通過一篇貼文講的很全面和深刻,這也就是為什麼我的標題是‘淺析’,程式設計師的成長一定是要付出代價和成本,因為只有真的在一線切身體會到當時的緊張和壓力,對於一件事情才能印象深刻,但反之也不能太過於強調代價,如果可以通過一些別人的分享就可以規避一些自己業務的問題和錯誤的代價也是好的。