特定領域知識圖譜(Domain-specific KnowledgeGraph:DKG)融合方案:技術知識前置【一】-文字匹配演演算法、知識融合學術界方案、知識融合業界落地方案、演演算法測評KG生產質
特定領域知識圖譜(Domain-specific KnowledgeGraph:DKG)融合方案:技術知識前置【一】-文字匹配演演算法、知識融合學術界方案、知識融合業界落地方案、演演算法測評KG生產質量保障
0.前言
本專案主要圍繞著特定領域知識圖譜(Domain-specific KnowledgeGraph:DKG)融合方案:技術知識前置【一】-文字匹配演演算法、知識融合學術界方案、知識融合業界落地方案、演演算法測評KG生產質量保障講解了文字匹配演演算法的綜述,從經典的傳統模型到孿生神經網路「雙塔模型」再到預訓練模型以及有監督無監督聯合模型,期間也涉及了近幾年前沿的對比學習模型,之後提出了文字匹配技巧提升方案,最終給出了DKG的落地方案。這邊主要以原理講解和技術方案闡述為主,之後會慢慢把專案開源出來,一起共建KG,從知識抽取到知識融合、知識推理、質量評估等爭取走通完整的流程。
1.文字匹配演演算法綜述(短文字匹配)
文字匹配任務在自然語言處理中是非常重要的基礎任務之一,一般研究兩段文字之間的關係。有很多應用場景;如資訊檢索、問答系統、智慧對話、文字鑑別、智慧推薦、文字資料去重、文字相似度計算、自然語言推理、問答系統、資訊檢索等,但文字匹配或者說自然語言處理仍然存在很多難點。這些自然語言處理任務在很大程度上都可以抽象成文字匹配問題,比如資訊檢索可以歸結為搜尋詞和檔案資源的匹配,問答系統可以歸結為問題和候選答案的匹配,複述問題可以歸結為兩個同義句的匹配。
- 如語言不規範,同一句話可以有多種表達方式;如「股市跳水、股市大跌、股市一片綠」
- 歧義,同一個詞語或句子在不同語境可能表達不同意思;如「割韭菜」,「領盒飯」,「蘋果」「小米」等在不同語境下語意完全不同
- 不規範或錯誤的輸入;如 「 yyds」,「絕絕子」「奪筍」「耗子尾汁」
- 需要知識依賴;如奧運冠軍張怡寧綽號「乒乓大魔王」等。
短文字匹配即計算兩個短文字的相似度,通常分成無監督方式、有監督方式、有監督+無監督方式
常見的文字匹配演演算法如下表(簡單羅列),按傳統模型和深度模型簡單的分為兩類:
| 演演算法 | 型別 |
|---|---|
| Jaccord | 傳統模型 |
| BM25 | 傳統模型 |
| VSM | 傳統模型 |
| SimHash | 傳統模型 |
| Levenshtein | 傳統模型 |
| cdssm | 深度模型 |
| arc-ii | 深度模型 |
| match_pyramid | 深度模型 |
| mvlstm | 深度模型 |
| bimpm | 深度模型 |
| drcn | 深度模型 |
| esim | 深度模型 |
| textmatching | 深度模型 |
| bert-base | 深度模型 |
| albert-base | 深度模型 |
| albert-large | 深度模型 |
| raberta | 深度模型 |
| sbert | 深度模型 |
| DiffCSE | 深度模型 |
| ERNIE-Gram | 深度模型 |
1.1 文字匹配傳統模型(無監督方式)
文字表徵:詞袋模型(one-hot 、TF)、詞向量預訓練(word2vector、fasttext、glove)
相似度計算:餘弦相似度、曼哈頓距離、歐氏距離、jaccard距離等
1.1.1 Jaccord 傑卡德相似係數
jaccard相似度是一種非常直觀的相似度計算方式,即兩句子分詞後詞語的交集中詞語數與並集中詞語數之比。

$\text { jaccard }=\frac{A \bigcap B}{A \bigcup B}$
def jaccard(list1, list2):
"""
jaccard相似係數
:param list1:第一句話的詞列表
:param list2: 第二句話的詞列表
:return:相似度,float值
"""
list1, list2 = set(list1), set(list2) #去重
intersection = list1.intersection(list2) # 交集
union = list1.union(list2) # 並集
Similarity = 1.0 * len(intersection) / len(union) #交集比並集
return Similarity
a.分詞
內蒙古 錫林郭勒盟 多倫縣 縣醫院 / 多倫縣 醫院
綿陽市 四 零 四 醫院 / 四川 綿陽 404 醫院
鄧州市 人民 醫院 / 南召縣 人民 醫院
b.去重求交集--並集
多倫縣(交集) -- 內蒙古、錫林郭勒盟、多倫縣、縣醫院、醫院(並集)
醫院(交集) -- 綿陽市、四、零、醫院、四川、綿陽、404(並集)
人民、醫院(交集) -- 鄧州市、人民、醫院、南召縣(並集)
c.相似度
| 文字對 | 相似度 | 真實標籤 |
|---|---|---|
| 內蒙古 錫林郭勒盟 多倫縣 縣醫院 / 多倫縣 醫院 | 1/5=0.2 | 1 |
| 綿陽市 四零四醫院/四川 綿陽 404 醫院 | 1/7 = 0.14 | 1 |
| 鄧州市 人民 醫院 / 南召縣 人民 醫院 | 2/4 = 0.5 | 0 |
1.1.2.Levenshtein編輯距離
一個句子轉換為另一個句子需要的編輯次數,編輯包括刪除、替換、新增,然後使用最長句子的長度歸一化得相似度。
def Levenshtein(text1, text2):
"""
Levenshtein編輯距離
:param text1:字串1
:param text2:字串2
:return:相似度,float值
"""
import Levenshtein
distance = Levenshtein.distance(text1, text2)
Similarity = 1 - distance * 1.0 / max(len(text1), len(text2))
return Similarity
a.分詞-計字數
內 蒙 古 錫 林 郭 勒 盟 多 倫 縣 縣 醫 院 (14) / 多 倫 縣 醫 院(5)
綿 陽 市 四 零 四 醫 院(8) / 四 川 綿 陽 4 0 4 醫 院(9)
鄧 州 市 人 民 醫 院 (7) / 南 召 縣 人 民 醫 院(7)
b.計算編輯距離
內 蒙 古 錫 林 郭 勒 盟 多 倫 縣 縣 醫 院 ------->刪除內、蒙、古、錫、林、郭、勒、盟、縣
綿 陽 市 四 零 四 醫 院 ------->加 四、川
------->刪除 市
------->替換 四(4)、零(0)、四(4)
鄧 州 市 人 民 醫 院 ------->替換鄧(南)、 州(召)、 市(縣)
| 文字對 | 距離 | 真實標籤 |
|---|---|---|
| 內蒙古 錫林郭勒盟 多倫縣 縣醫院 / 多倫縣 醫院 | 0.357 | 1 |
| 綿陽市 四零四醫院/四川 綿陽 404 醫院 | 0.333 | 1 |
| 鄧州市 人民 醫院 / 南召縣 人民 醫院 | 0.571 | 0 |
1.1.3 simhash相似度
先計算兩句子的simhash二進位制編碼,然後使用海明距離計算,最後使用兩句的最大simhash值歸一化得相似度。
def simhash_(text1, text2):
"""
simhash相似度
:param s1: 字串1
:param s2: 字串2
:return: 相似度,float值
"""
from simhash import Simhash
text1_simhash = Simhash(text1, f=64) #計算simhash向量
text2_simhash = Simhash(text2, f=64) #計算simhash向量
distance = text1_simhash.distance(text2_simhash) #漢明距離
Similarity = 1 - distance / max(len(bin(text1_simhash.value)), len(bin(text2_simhash.value))) #相似度
return Similarity
a.分詞
內蒙古 錫林郭勒盟 多倫縣 縣醫院 / 多倫縣 醫院
綿陽市 四 零 四 醫院 / 四川 綿陽 404 醫院
鄧州市 人民 醫院 / 南召縣 人民 醫院
b.計算詞權重(此處用tfidf計算,其他方法也可以)
| Text | Text | Text |
| 內蒙古5 | 錫林郭勒盟5 | 多倫縣2 | 縣醫院5 | 多倫縣7 | 醫院1 | |||
|---|---|---|---|---|---|---|---|---|
| 綿陽市3 | 四6 | 零3 | 四6 | 醫院1 | 四川5 | 綿陽5 | 4045 | 醫院1 |
| 鄧州市7 | 人民4 | 醫院1 | 南召縣7 | 人民4 | 醫院1 |
c.hash函數對映詞向量
- 先將詞對映到二進位制編碼,
- 然後用b步驟中的權重值替換1,
- b步驟中權重值的負數替換0

d.合併(將一段文字內的詞向量進行累加)

e海明距離判斷相似度
海明距離可以理解為:兩個二進位制串之間相同位置不同的個數。舉個例子,[1,1,1,0,0,0]和[1,1,1,1,1,1]的海明距離就是3。

1.1.4 Bm25相似度
一句話概況其主要思想:對Query(待查詢語句)進行語素解析,生成語素qi;然後,對於每個搜尋結果D,計算每個語素qi與D的相關性得分,最後,將qi相對於D的相關性得分進行加權求和,從而得到Query與D的相關性得分。公式如下:
$\operatorname{Score}(Q, d)=\sum_i^n W_i \cdot R\left(q_i, d\right)$
Q表示Query,qi即Q分詞後的每一個解析語素(對中文而言,我們可以把對Query的分詞作為語素分析,每個詞看成語素qi)。d表示一個搜尋結果檔案,Wi表示語素qi的權重,R(qi,d)表示語素qi與檔案d的相關性得分。
判斷一個詞與一個檔案的相關性的權重定義Wi方法有多種,較常用的是IDF。公式如下:
$\operatorname{IDF}\left(q_i\right)=\log \frac{N-n\left(q_i\right)+0.5}{n\left(q_i\right)+0.5}$
- N為索引中的全部檔案數,
- n(qi)為包含了qi的檔案數。
根據IDF的定義可以看出當很多檔案都包含了qi時,qi的區分度就不高,因此使用qi來判斷相關性時的重要度就較低。
$\operatorname{Score}(Q, d)=\sum_i^n I D F\left(q_i\right) \cdot \frac{f_i \cdot\left(k_1+1\right)}{f_i+k_1 \cdot\left(1-b+b \cdot \frac{d l}{a v g d l}\right)}$
求Score(qi,d)具體的公式可以參考文字相似度-BM25演演算法
其中
- f(qi, D)為單詞在當前候選檔案中的詞頻
- k1、b為調節因子,通常設為k1=2,b=0.75
- |D|為當前候選文字數(與目標文字匹配的總條數)
- avgdl為語料庫中所有檔案的平均長度。
在做文字匹配的時候(如重複問題檢測)可以嘗試BM25的方法,但在搜尋領域中,有時候搜尋query和候選檔案的長度是不一樣甚至差距很大,所以BM25在計算相似性的時候需要對檔案長度做一定的處理。
#Bm25
import math
import jieba
class BM25(object):
def __init__(self, docs):#docs是一個包含所有文字的列表,每個元素是一個文字
self.D = len(docs) #總文字數
self.avgdl = sum([len(doc)+0.0 for doc in docs]) / self.D #平均文字長度
self.docs = docs #文字型檔列表
self.f = [] # 列表的每一個元素是一個dict,dict儲存著一個檔案中每個詞的出現次數
self.df = {} # 儲存每個詞及出現了該詞的檔案數量
self.idf = {} # 儲存每個詞的idf值
self.k1 = 1.5
self.b = 0.75
self.init()
def init(self):
for doc in self.docs: #對每個文字
tmp = {} #定義一個字典儲存詞出現頻次
for word in doc:
tmp[word] = tmp.get(word, 0) + 1 # 儲存每個檔案中每個詞的出現次數
self.f.append(tmp)
for k in tmp.keys():
self.df[k] = self.df.get(k, 0) + 1
for k, v in self.df.items():
self.idf[k] = math.log(self.D-v+0.5)-math.log(v+0.5) #計算idf
def sim(self, doc, index):
score = 0
for word in doc:
if word not in self.f[index]:
continue
d = len(self.docs[index])
score += (self.idf[word]*self.f[index][word]*(self.k1+1)
/ (self.f[index][word]+self.k1*(1-self.b+self.b*d
/ self.avgdl)))
return score
def simall(self, doc):
scores = []
for index in range(self.D):
score = self.sim(doc, index)
scores.append(score)
return scores
if __name__ == '__main__':
sents1 = ["多倫縣醫院", #資料庫
"四川綿陽404醫院",
"南召縣人民醫院"]
sents2 = ["內蒙古錫林郭勒盟多倫縣縣醫院","綿陽市四零四醫院","鄧州市人民醫院"]#待匹配文字
doc = []
for sent in sents1:
words = list(jieba.cut(sent))
doc.append(words)
print(doc)
s = BM25(doc)
print(s.f)
print(s.idf)
for k in sents2:
print(s.simall(jieba.lcut(k))) #列印相似度匹配結果

1.1.5 VSM(向量空間模型)演演算法
VSM演演算法的思路主要分為兩步:
(1) 用向量表示句子,用向量表示句子的方法很多,簡單的有onehot,詞頻法,基於語意的有word2vec/fastText/glove/bert/elmo等,本例中使用基於簡單的詞頻的向量化方式。
(2)計算兩向量的餘弦距離(曼哈頓距離、歐幾里得距離、明式距離、切比雪夫距離)得相似度。
#tfidf_餘弦
def sim_vecidf(self, s1, s2):
"""詞向量通過idf加權平均後計算餘弦距離"""
v1, v2 = [], []
# 1. 詞向量idf加權平均
for s in jieba.cut(s1):
idf_v = idf.get(s, 1)
if s in voc:
v1.append(1.0 * idf_v * voc[s])
v1 = np.array(v1).mean(axis=0)
for s in jieba.lcut(s2):
idf_v = idf.get(s, 1)
if s in voc:
v2.append(1.0 * idf_v * voc[s])
v2 = np.array(v2).mean(axis=0)
# 2. 計算cosine
sim = self.cosine(v1, v2)
return sim
a.句子向量化
a1.取句子對的唯一詞元組
set(內蒙古 錫林郭勒盟 多倫縣 縣醫院 / 多倫縣 醫院) = (內蒙古 錫林郭勒盟 多倫縣 縣醫院 醫院)
set(綿陽市 四 零 四 醫院 / 四川 綿陽 404 醫院) = (綿陽市 四 零 醫院 四川 綿陽 404 )
set(鄧州市 人民 醫院 / 南召縣 人民 醫院) = (鄧州市 人民 醫院 南召縣)
a2.根據每個句子在元組中的詞頻建立向量表示

b.計算餘弦距離
$\operatorname{Cos}(x 1, x 2)=\frac{x 1 \cdot x 2}{|x 1||x 2|}$
| 句子 | 距離 |
|---|---|
| 內蒙古 錫林郭勒盟 多倫縣 縣醫院 / 多倫縣 醫院 | 0.3535 |
| 綿陽市 四零四醫院/四川 綿陽 404 醫院 | 0.1889 |
| 鄧州市 人民 醫院 / 南召縣 人民 醫院 | 0.6666 |
1.1.6 word2vector + 相似度計算(BERT模型+餘弦相似度為例)
常用做法是通過word2vec等預訓練模型得到詞向量,然後對文字做分詞,通過embedding_lookup得到每個token對應的詞向量,然後得到短文字的句向量。對兩個文字的句子向量採用相似度計算方法如餘弦相似度、曼哈頓距離、歐氏距離等。無監督方式取得的結果取決於預訓練詞向量的效果。
BERT是谷歌在2018年推出的深度語言表示模型,是關於語言理解的深度雙向transformers的預訓練模型,開啟了預訓練模型的新篇章。它可以學習文字的語意資訊,通過向量形式的輸出可以用於下游任務。也就說,它自己已經在大規模預料上訓練好的引數,我們在用的時候只需要在這個基礎上訓練更新引數。bert模型可以解決多種自然語言處理問題,如單文字分類、語句對分類、序列標註等。在解決文字匹配任務時,有兩種思路,第一種直接把文字匹配任務作為語句對分類任務,模型輸入語句對,輸出是否匹配的標籤;第二種利用bert模型預訓練文字對的上下文嵌入向量,再通過餘弦相似度等相似度計算方法驗證文字對是否匹配,在此基礎上還有很多基於bert模型的變種,篇幅有限不做一一講述。接下來簡單介紹一下bert預訓練文字嵌入+餘弦相似度的演演算法框架。
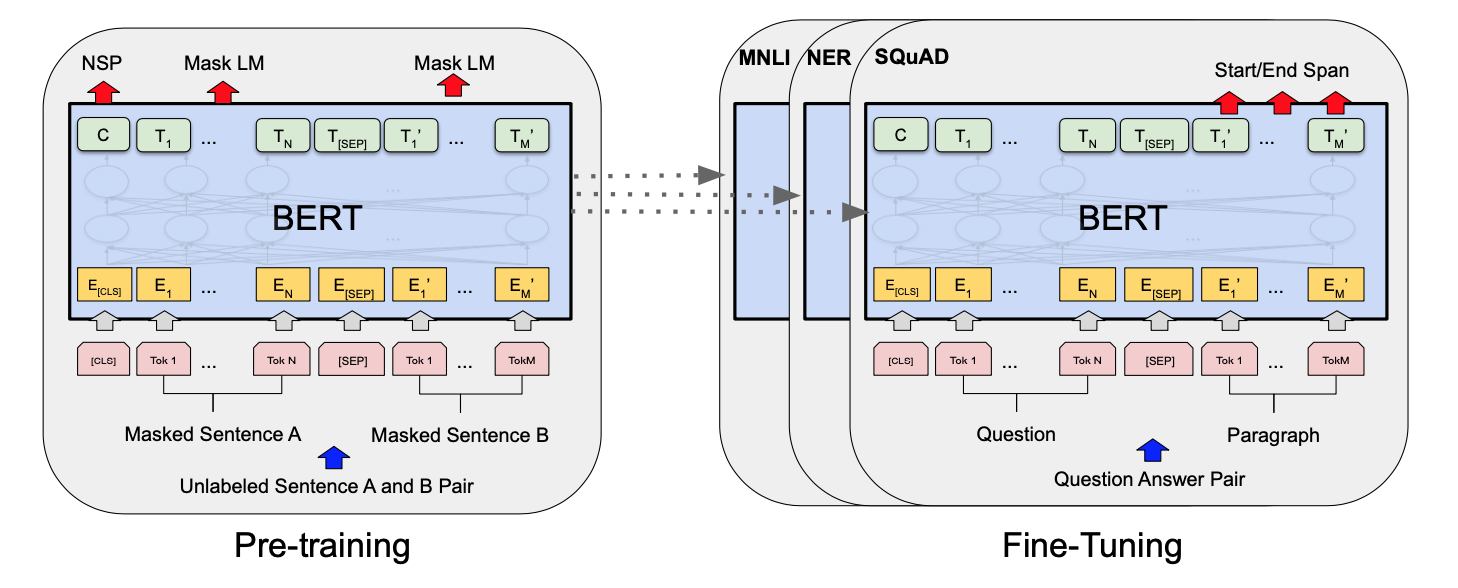
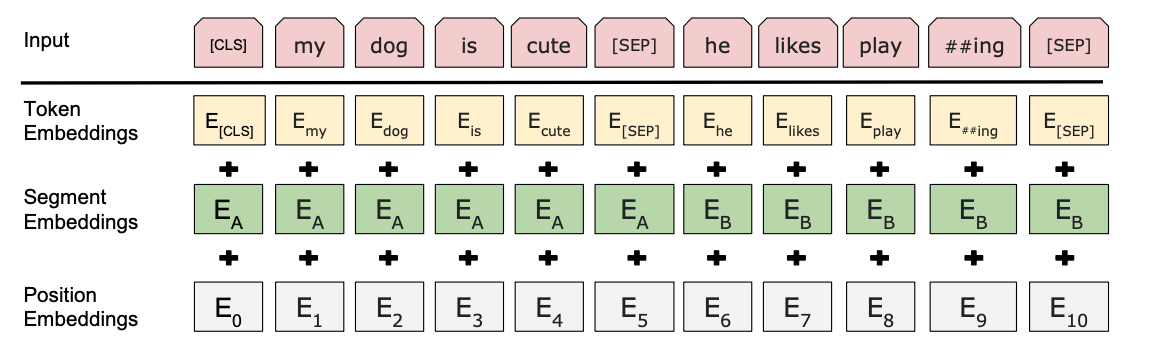
a.首先使用大量公域文字資料對BERT模型進行預訓練(或直接用谷歌預訓練好的模型)
b.將文字直接輸入模型
c.對模型輸出的語意向量C,或中間隱層向量,計算餘弦相似度,得到匹配結果。
基於深度學習的匹配演演算法種類繁多,如基於CNN網路、RNN網路、LSTM網路等及各種變種層出不窮,在此不一一列舉實現。
傳統的文字匹配方法主要關注文字間字與字,詞與詞的匹配關係,無法準確識別不同表達方式下不同文字的同一指向關係,即語意關係。因此在這一背景下,要對多源異構的海量地址資料進行匹配,傳統的文字匹配方法已不再適用,深度學習方法大行其道。但深度學習方法也有自身的侷限性,比如對海量文字和算力的高要求等,都使得深度學習方法的普適性大打折扣,因此沒有最好的文字匹配演演算法,只有當前條件下最適合的文字匹配演演算法。
2.有監督方式
2.1 孿生神經網路(Siamese Network)
原文:《Learning a Similarity Metric Discriminatively, with Application to Face Verification》
-
要解決什麼問題?
- 用於解決類別很多(或者說不確定),然而訓練樣本的類別數較少的分類任務(比如臉部辨識、人臉認證)
- 通常的分類任務中,類別數目固定,且每類下的樣本數也較多(比如ImageNet)
-
用了什麼方法解決?
提出了一種思路:將輸入對映為一個特徵向量,使用兩個向量之間的「距離」(L1 Norm)來表示輸入之間的差異(影象語意上的差距)。
基於上述思路設計了Siamese Network。每次需要輸入兩個樣本作為一個樣本對計算損失函數。
- 效果如何?
文中進行了一個衡量兩張人臉的相似度的實驗,使用了多個資料庫,較複雜。siamese network現在依然有很多地方使用,可以取得state-of-the-art的效果。
- 還存在什麼問題?
- contrastive loss的訓練樣本的選擇需要注意,論文中都是儘量保證了50%的正樣本對和50%的負樣本對。
分類問題:
-
第一類,分類數量較少,每一類的資料量較多,比如ImageNet、VOC等。這種分類問題可以使用神經網路或者SVM解決,只要事先知道了所有的類。
-
第二類,分類數量較多(或者說無法確認具體數量),每一類的資料量較少,比如臉部辨識、人臉驗證任務。
文中提出的解決方案:
learn a similar metric from data。核心思想是,尋找一個對映函數,能夠將輸入影象轉換到一個特徵空間,每幅影象對應一個特徵向量,通過一些簡單的「距離度量」(比如歐式距離)來表示向量之間的差異,最後通過這個距離來擬合輸入影象的相似度差異(語意差異)。
2.1.1 簡介
- Siamese Network 是一種神經網路的框架,而不是具體的某種網路,就像seq2seq一樣,具體實現上可以使用RNN也可以使用CNN。
- Siamese network就是「連體的神經網路」,神經網路的「連體」是通過共用權值來實現的。(共用權值即左右兩個神經網路的權重一模一樣)
- siamese network的作用是衡量兩個輸入的相似程度。孿生神經網路有兩個輸入(Input1 and Input2),將兩個輸入feed進入兩個神經網路(Network1 and Network2),這兩個神經網路分別將輸入對映到新的空間,形成輸入在新的空間中的表示。通過Loss的計算,評價兩個輸入的相似度。

Siamese Network有兩個結構相同,且共用權值的子網路。分別接收兩個輸入X1與X2,將其轉換為向量Gw(X1)與Gw(X2),再通過某種距離度量的方式計算兩個輸出向量的距離Ew。
訓練Siamese Network採用的訓練樣本是一個tuple (X1,X2,y)(X1,X2,y),標籤y=0表示X1與X2屬於不同型別(不相似、不重複、根據應用場景而定)。y=1則表示X2與X2屬於相同型別(相似)。
LOSS函數的設計應該是
- 當兩個輸入樣本不相似(y=0)時,距離Ew越大,損失越小,即關於Ew的單調遞減函數。
- 當兩個輸入樣本相似(y=1)時,距離Ew越大,損失越大,即關於Ew的單調遞增函數。
用L+(X1,X2)表示y=1時的LOSS,L−(X1,X2)表示y=0時的LOSS,則LOSS函數可以寫成如下形式:
Lw(X1,X2)=(1−y)L−(X1,X2)+yL+(X1,X2)
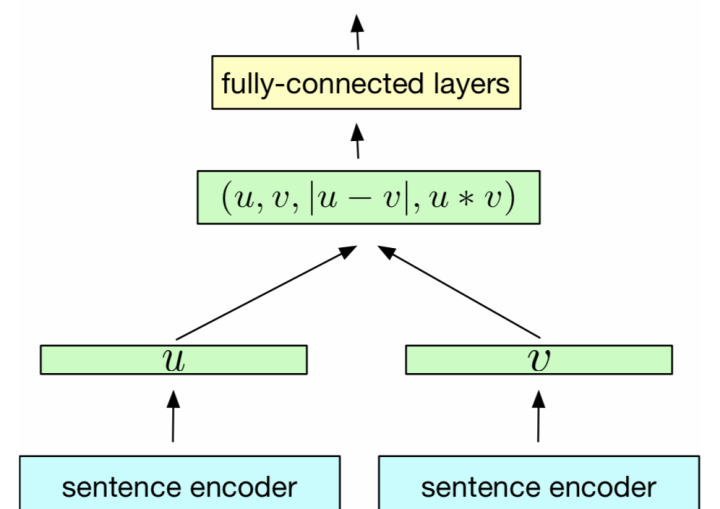
簡單來說:孿生體現在使用相同的編碼器(sentence encoder),將文字轉為高維向量。具體步驟為,有文字A和文字B分別輸入 sentence encoder 進行特徵提取和編碼,將輸入對映到新的空間得到特徵向量u和v;最終通過u、v的拼接組合,經過下游網路來計算文字A和B的相似性
- 在訓練和測試中,模型的編碼器是權重共用的,編碼器可以選擇CNN、RNN、LSTM等
- 提取到特徵u、v後,可以使用餘弦距離、歐氏距離等得到兩個文字的相似度。
- 缺點是兩個文字在編碼時候沒有互動,缺乏互動的結構沒有充分利用到兩個文字相互影響的資訊
2.2 匹配聚合網路(ESIM,BIMPM)
在上述孿生網路的基礎上,得到特徵u、v但是不直接計算向量相似度,而是通過注意力機制將兩個文字進行資訊互動,最後通過全連線層得到相似度。
代表的模型有ESIM,BIMPM等
以ESIM為例
-
首先是對兩個文字的初期編碼,就是對兩個文字做分詞、文字表徵,即對句子進行資訊的提取。如果使用LSTM作為encoder,可以得到每個時刻(每個單詞)的輸出,通常維度為[batch_size, seq_len, embedding_dim]。舉例子為,句子A長度10,句子B長度也為10,那麼進過編碼以後句子A的維度[1,10,300],句子B[1,10,300],這裡就得到了上述所提到的u、v
-
接下來是互動操作,為了操作簡單忽略batchsize維度,互動即矩陣相乘得到[10,10],矩陣需要對句子A做橫向概率歸一,對句子B做縱向概率歸一。上面這句話其實就是ESIM的核心要點。它是一個兩個item之間互相做attention,簡單稱之為both attention。
-
對attention後得到的向量做拼接後輸出編碼器,輸出再接到全連線層、softmax就可以得到結果,即兩個文字相似(label 1)或不相似(label 0)
3.預訓練語言模型
-
第一階段,使用通用的預料庫訓練語言模型,
-
第二階段預訓練的語言模型(BERT相關衍生的模型)做相似度任務,得到資訊互動後的向量,
-
連線全連線層,輸出概率。即將兩個短文字拼接(CLS A1 A2 … A 10 SEP B1 B2 … B10 SEP),然後CLS向量連線全連線層,判斷相似與否。
這種模型引數多,並且使用了通用的語料庫,能夠獲取到短文字之間隱藏的互動資訊,效果較好。
簡單來說用拼接的方法類似「單塔」,孿生網路的方法類似「雙塔」,不完全準確後續會詳細說明,預訓練模型就不展開講了,大家去官網或者多看幾篇學術論文吧,BERT ERNIE。
4.有監督方式 + 無監督方式
無監督:直接相加得到句向量,不能很好的表達語意資訊,並且詞的位置資訊沒有得到體現,也不包含上下文的語意資訊。
有監督學習:時間複雜度太高。可以將標準庫中的句向量計算完成並儲存。新的文字來臨時,只需要解決使用者問題即可,然後與儲存在庫中的標準問句進行距離度量。
可以使用BERT代替孿生網路的CNN或LSTM結構,獲取更多語意資訊的句向量,還可以通過蒸餾降低BERT模型的引數,節約時間成本。
4.1 Sentence-BERT
文章連結:https://arxiv.org/pdf/1908.10084.pdf
論文程式碼:https://github.com/UKPLab/
為了讓BERT更好地利用文字資訊,作者們在論文中提出瞭如下的SBERT模型。SBERT沿用了孿生網路的結構,文字Encoder部分用同一個BERT來處理。之後,作者分別實驗了CLS-token和2種池化策略(Avg-Pooling、Mean-Pooling),對Bert輸出的字向量進一步特徵提取、壓縮,得到u、v。

關於u、v整合,作者提供了3種策略:
-
將u、v拼接,接入全連線網路,經過softmax輸出,損失函數用交叉熵損失
-
直接計算兩個文字的餘弦相似度,損失函數用均方根誤差

- 如果輸入的是三元組
SBERT直接用BERT的原始權重初始化,在具體資料集微調,訓練過程和傳統Siamese Network類似。但是這種訓練方式能讓Bert更好的捕捉句子之間的關係,生成更優質的句向量。在測試階段,SBERT直接使用餘弦相似度來衡量兩個句向量之間的相似度,極大提升了推理速度。
使用NLI和STS為代表的匹配資料集,在分類目標函數訓練時,作者測試了不同的整合策略,結果顯示「(u, v, |u-v|)」的組合效果最好。最重要的部分是元素差:(|u - v|)。句向量之間的差異度量了兩個句子嵌入維度間的距離,確保相似的pair更近,不同的pair更遠。
4.2 對比學習
深度學習的本質是做兩件事情:①表示學習 ②歸納偏好學習。對比學習(ContrastiveLearning)則是屬於表示學習的範疇,它並不需要關注樣本的每一個細節,但是學到的特徵要使其能夠和其他樣本區分開。對比學習作為一種無監督表示學習方法,最開始也是在CV領域掀起浪潮,之後NLP跟進,在文字相似度匹配等任務上超過SOTASOTA。該任務主要是對文字進行表徵,使相近的文字距離更近,差別大的文字距離更遠。
NLP的對比學習演演算法下文將不詳細講述簡單展示更多內容參考連結。
4.2.1 BERT-Flow 2020.11
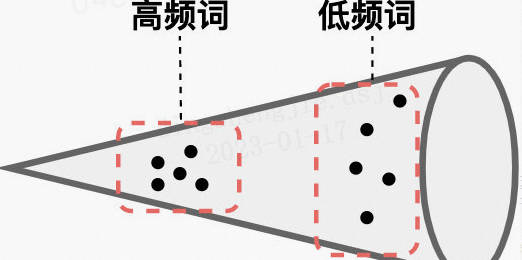
很多研究發現BERT表示存在問題:未經微調的BERT模型在文字相似度匹配任務上表現不好,甚至不如Glove?作者通過分析BERT的性質,如圖:
在理論上BERT確實提取到了足夠的語意資訊,只是這些資訊無法通過簡單的consine直接利用。主要是因為:
- ①BERT的詞向量在空間中不是均勻分佈,而是呈錐形。高頻詞都靠近原點,而低頻詞遠離原點,相當於這兩種詞處於了空間中不同的區域,那高頻詞和低頻詞之間的相似度就不再適用;
- ②低頻詞的分佈很稀疏。低頻詞表示得到的訓練不充分,分佈稀疏,導致該區域存在語意定義不完整的地方(poorly defined),這樣算出來的相似度存在問題。
針對以上問題,提出了BERT-Flow,基於流式生成模型,將BERT的輸出空間由一個錐形可逆地對映為標準的高斯分佈空間。
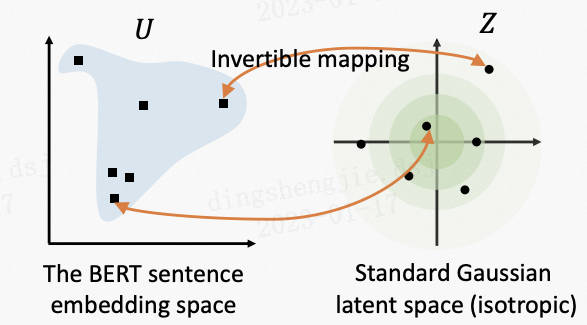
4.2.2 BERT-Whitening 2021.03
BERT-Whitening首先分析了餘弦相似度為什麼可以衡量向量的相似度:向量A 與B 的乘積等於A AA在B BB所在直線上投影的長度。將兩個向量擴充套件到d維
$\cos (A, B)=\frac{\sum_{i=1}^d a_i b_i}{\sqrt{\sum_{i=1}^d a_i^2} \sqrt{\sum_{i=1}^d b_i^2}}$
$\text { 模的計算公式: }|A|=\sqrt{a_12+a_22+\ldots+a_n^2}$
上述等式的成立,都是在標準正交基(忘了的同學可以自行復習一下)的條件下,也就是說向量依賴我們選擇的座標基,基底不同,內積對應的座標公式就不一樣,從而餘弦值的座標公式也不一樣。
所以,BERT的句向量雖然包含了足夠的語意,但有可能是因為此時句向量所屬的座標系並非標準正交基,而導致用基於標準正交基的餘弦相似度公式計算時效果不好。那麼怎麼知道具體用了何種基底呢?可以依據統計學去判斷,在給向量集合選擇基底時,儘量平均地用好每一個基向量,這就體現為每個分量的使用都是獨立的、均勻的,如果這組基是標準正交基,那麼對應的向量集應該表現出「各向同性」來,如果不是,可以想辦法讓它變得更加各向同性一寫,然後再用餘弦公式計算,BERT-Flow正是想到了「flow模型」的辦法,而作者則找到了一種更簡單的線性變換的方法。
標準化協方差矩陣
BERT-Whitening還支援降維操作,能達到提速和提效的效果。
★PCA和SVD差異分析:PCA可以將方陣分解為特徵值和特徵向量,SVD則可以分解任意形狀的矩陣。
4.2.3 ConSERT 2021.05
https://arxiv.org/pdf/2105.11741.pdf
美團技術團隊提出了基於對比學習的句子表示遷移方法——ConSERT,主要證實了以下兩點:
①BERT對所有的句子都傾向於編碼到一個較小的空間區域內,這使得大多數的句子對都具有較高的相似度分數,即使是那些語意上完全無關的句子對。我們將此稱為BERT句子表示的「坍縮(Collapse)」現象。

②BERT句向量表示的坍縮和句子中的高頻詞有關。當通過平均詞向量的方式計算句向量時,高頻詞的詞向量將會主導句向量,使之難以體現其原本的語意。當計算句向量時去除若干高頻詞時,坍縮現象可以在一定程度上得到緩解。
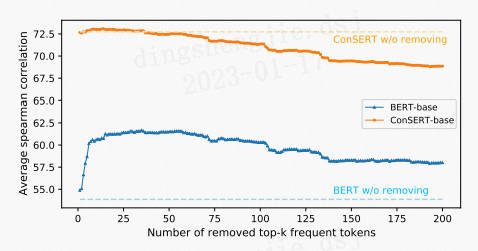
為了解決BERT存在的坍縮問題,作者提出了句子表示遷移框架:

對BERT encoder做了改進,主要包括三個部分:
*①資料增強模組,作用於embedding層,為同一文字生成不同的編碼。
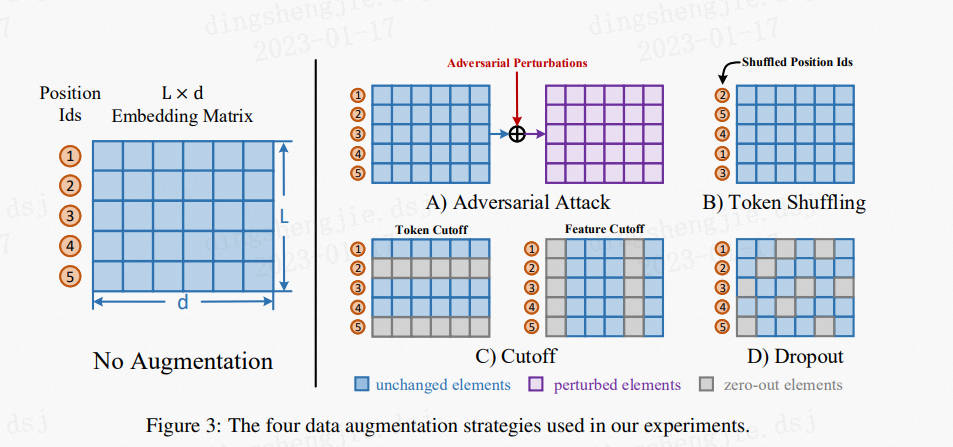
- shuffle:更換position id的順序
- token cutoff:在某個token維度把embedding置為0
- feature cutoff:在embedding矩陣中,有768個維度,把某個維度的feature置為0
- dropout:embedding中每個元素都有一定概率為0,沒有行或列的約束
資料增強效果:Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None
-
②共用的Bert encoder,生成句向量。
-
③一個對比損失層,在一個Batch內計算損失,拉近同一樣本不同句向量的相似度,使不同樣本之間相互遠離。損失函數:
$L_{i, j}=-\log \frac{\exp \left(\operatorname{sim}\left(r_i, r_j\right) / \tau\right)}{\sum_{k=1}^{2 N} 1_{[k \neq i]} \exp \left(\operatorname{sim}\left(r_i, r_k\right) / \tau\right)}$
N:Batchsize,2N表示2種資料增強方式,sim():餘弦相似度函數,r:句向量,τ:實驗0.08−0.12最優
除了無監督訓練之外,作者還提出了三種進一步融合監督訊號的策略:
-
①聯合訓練(joint):有監督的損失和無監督的損失通過加權聯合訓練模型。
-
②先有監督再無監督(sup-unsup):先使用有監督損失訓練模型,再使用無監督的方法進行表示遷移。
-
③聯合訓練再無監督(joint-unsup):先使用聯合損失訓練模型,再使用無監督的方法進行表示遷移。
參考連結:https://blog.csdn.net/PX2012007/article/details/127614565
4.2.4 SimCSE:2021.04
前幾節講述了對比學習的原理和幾種基於 Bert 的方式獲取句子向量,例如 BERT-flow和 BERT-whitening 等,對預訓練 Bert 的輸出進行變換從而得到更好的句子向量。後面將通過 ①構造目標函數 ②構建正負例 的對比學習方法訓練模型,取得SOTA的效果。
SimCSE是有大神陳丹琦發表的《Simple Contrastive Learning of Sentence Embeddings》,簡單高效

SimCSE包含無監督(圖左部分)和有監督(圖右部分)兩種方法。實線箭頭代表正例,虛線代表負例。
- Unsupervised
創新點在於使用Dropout對文字增加噪音。
1.正例構造:利用Bert的隨機Dropout,同一文字經過兩次Bert enconder得到不同的句向量構成相似文字。
2.負例構造:同一個Batch中的其他樣本作為負例被隨機取樣。
- Supervised
1.正例:標註資料
2.負例:同Batch內的其他樣本
4.2.5 R-Drop(Supervised):2021.06
https://arxiv.org/abs/2106.14448
Dropout雖然可以防止模型訓練中的過擬合併增強魯棒性,但是其操作在一定程度上會使訓練後的模型成為一種多個子模型的組合約束。SimCSE就是希望Dropout對模型結果不會有太大影響,也就是模型輸出對Dropout是魯棒的。所以,「Dropout兩次」這種思想是可以推廣到一般任務的,這就是R-Drop(Regularized Dropout),由微軟亞洲研究院和蘇州大學提出的更加簡單有效的正則方法。
-
R-Drop與傳統作用於神經元或模型引數的約束方法不同,而是作用於輸出層,彌補了Dropout在訓練和測試時的不一致性。在每個mini-batch中,每個資料樣本過兩次帶有Dropout的同一個模型,R-Drop再使用KL-divergence(KL散度)約束兩次的輸出一致。所以,R-Drop約束了由於Dropout帶來的兩個隨機子模型的輸出一致性。
-
R-Drop只是簡單增加了一個KL-散度損失函數項,並沒有其他任何改動。雖然該方法看起來很簡單,但在NLP和CV的任務中,都取得了非常不錯的SOTA結果。
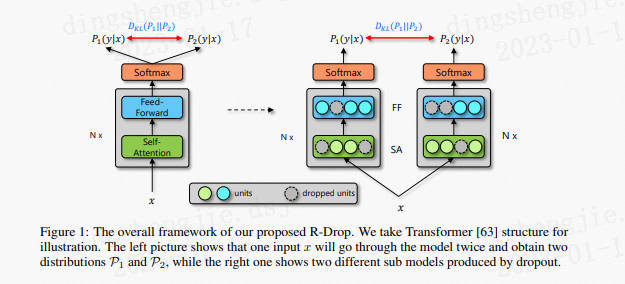
同樣的輸入,同樣的模型,經過兩個 Dropout 得到的將是兩個不同的分佈,近似將這兩個路徑網路看作兩個不同的模型網路。基於此,這兩個不同的模型產生的不同分佈而這篇文章的主要貢獻就是在訓練過程中不斷拉低這兩個分佈之間的KL 散度。由於KL 散度本身具有不對稱性,作者通過交換這兩種分佈的位置以間接使用整體對稱的KL 散度,稱之為雙向KL 散度。
4.2.6 ESimCSE(Unsupervised):2021.09
https://arxiv.org/abs/2109.04380
SimCSE構建正負例時存在兩個兩個缺點:
-
①構造正例長度相等,導致模型預測時存在偏差,長度相等的文字會傾向預測相似度高。
-
②對比學習理論上負例越多,對之間模型學習的越好,但增大Batch會受到效能的限制。
ESimCSE針對以上問題做了相應的改進:

-
正例構造:通過引入噪聲較小的「單詞重複」方式改變正例的長度,設定重複率dup_rate,確定dup_len後利用均勻分佈隨機選取dup_len子詞進行重複。
-
負例構造:為了更有效的擴充套件負對,同時不降低效能,通過維護一個佇列,重用前面緊接的mini-batch的編碼嵌入來擴充套件負對:
- ①將當前mini-batch的句嵌入放入佇列,同時將「最老的」句子踢出佇列。由於排隊句子嵌入來自前面的mini-batch,通過取其引數的移動平均來保持動量更新模型,並利用動量模型生成排隊句子嵌入。
- 在使用動量編碼器時,關閉了dropout,這可以縮小訓練和預測之間的差距。
4.2.7 PromptBERT(Unsupervised):2022.01
https://arxiv.org/pdf/2201.04337v1.pdf
Prompt Learning比較火熱,號稱NLP的第四規格化,
-
作者發現BERT在語意相似度方面表現不好,主要由:static token embeddings biases和ineffective layers,而不是high cosine similarity of the sentence embedding。static token embedding是在bert結構中,輸入進block前,通過embedding layer產生的結果,這裡強調是靜態的embedding,就是embedding metrics中每個token都唯一對應的embedding,是不隨句子環境而變化的。至於ineffective layers就很好理解了,就是bert中堆疊的block結構,比如bert-base中的12層。作者認為這些結構,對語意相似度的表徵這個方面是無效的。
-
Anisotropy(各向異性):上篇我們已經提到,詞向量是有維度的,每個維度上基向量單位向量長度不一樣,就是各向異性的。這會造成計算向量相似度的時候產生偏差。如何度量Anisotropy:
作者分析了造成embedding bias的原因,除了token frequency是造成bias的原因,作者又提出了:subwords,case sentitive
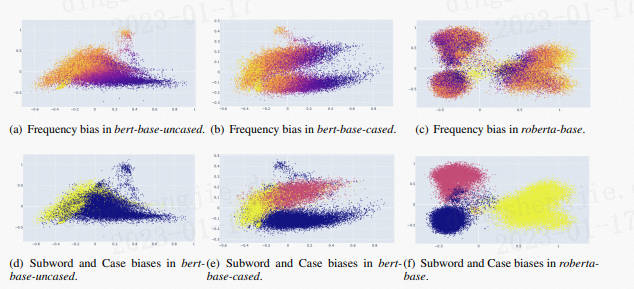
圖中不同詞頻token的分佈情況,顏色越深代表詞頻越高,我們可以看出詞頻高的token,分佈比較緊湊,詞頻低的token,分佈較分散。作者輸出這個影象還有一個目的是他提出各向異性(anisotropy)和偏差(bias)是不相關的,各向異性不是導致偏差的原因。
Embedding bias意思是對映分佈被一些不相關的資訊所幹擾,是可以用降維的方式去視覺化的。
更多細節參考原論文,Prompt效果就不贅述了,百度開發的UIE模型在NLP就很強大!
4.2.8 SNCSE(Unsupervised):2022.01
https://arxiv.org/abs/2201.05979
SNCSE同樣是由微軟團隊提出,主要是針對以上方法存在的問題:當前對比學習的資料增強方式,獲取的正樣本都極為相似,導致模型存在特徵抑制,即模型不能區分文字相似度和語意相似度,並更偏向具有相似文字,而不考慮它們之間的實際語意差異。

為了減輕特徵抑制,該論文提出了通過軟負樣本結合雙向邊際損失的無監督句子嵌入對比學習方法。其中,軟負樣本,即具有高度相似,但與原始樣本在語意上存在明顯的差異的樣本。雙向邊際損失,即通過擴大原始樣本與正例和原始樣本與軟負例之間的距離,使模型更好地學習到句子之間的語意差別。
軟負樣本構造:為原文字新增顯示的否定詞。
- 在獲取句子表徵時,受PromptBERT啟發,通過三種模板表示原樣本、正樣本和軟負樣本:

4.2.9 DiffCSE(Unsupervised):2022.04
https://arxiv.org/pdf/2204.10298.pdf
結合句子間差異的無監督句子嵌入對比學習方法——DiffCSE主要還是在SimCSE上進行優化(可見SimCSE的重要性),通過ELECTRA模型的生成偽造樣本和RTD(Replaced Token Detection)任務,來學習原始句子與偽造句子之間的差異,以提高句向量表徵模型的效果。

其思想同樣來自於CV領域(採用不變對比學習和可變對比學習相結合的方法可以提高影象表徵的效果)。作者提出使用基於dropout masks機制的增強作為不敏感轉換學習對比學習損失和基於MLM語言模型進行詞語替換的方法作為敏感轉換學習「原始句子與編輯句子」之間的差異,共同優化句向量表徵。
在SimCSE模型中,採用pooler層(一個帶有tanh啟用函數的全連線層)作為句子向量輸出。該論文發現,採用帶有BN的兩層pooler效果更為突出,BN在SimCSE模型上依然有效。
- ①對於掩碼概率,經實驗發現,在掩碼概率為30%時,模型效果最優。
- ②針對兩個損失之間的權重值,經實驗發現,對比學習損失為RTD損失200倍時,模型效果最優。
參考連結:https://blog.csdn.net/PX2012007/article/details/127696477
4.2.10 小結
SimCSE以來幾種比較重要的文字增強式的對比學習演演算法,按時間順序,理論上應該是距離越近的演演算法效果越好,但使用時,還是要結合具體的業務場景,演演算法沒有好壞,還是用看怎麼用。對於有些內容,可能敘述的不是很細緻或是需要一定的知識鋪墊,感興趣的同學可以針對性的研讀論文和輔助其他資料。當然,演演算法層出不窮,更新很快,後續出現比較重要的對比學習演演算法。
5.文字匹配常見思路(技巧提升)
- TextCNN/TEXTRNN
- Siamese-RNN
- 採用多種BERT類預訓練模型
- 對單模型進行調參
- 多模型融合
- BERT後接上RCNN/RNN/CNN/LSTM/Siamese等等
5.1方案一
特徵工程
-
資料淨化:大賽給的資料比較規整,資料淨化部分工作不多,簡單做了特殊字元處理等操作。
-
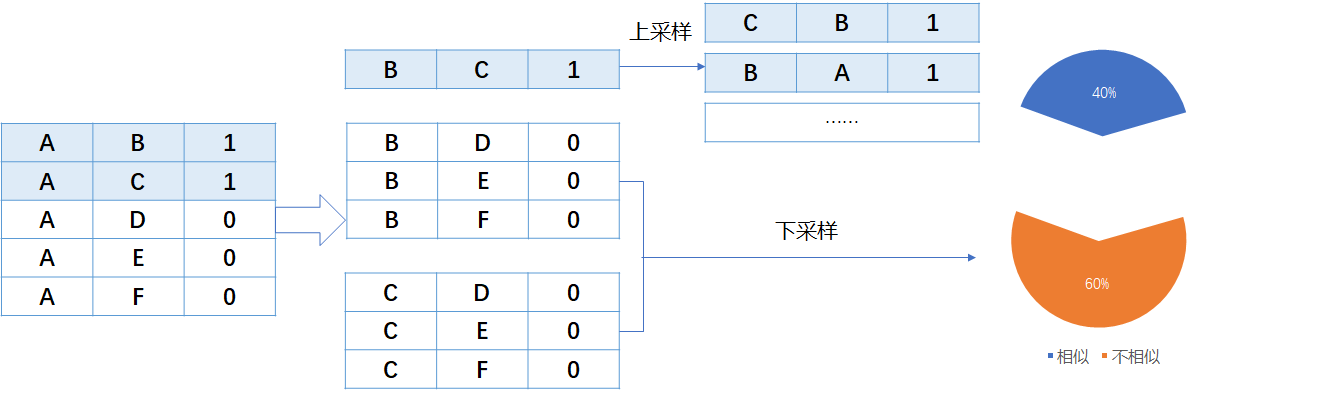
資料增強
- 傳遞閉包擴充(標籤傳遞)
根據IF A=B and A=C THEN B=C的規則,對正樣本做了擴充增強。
根據IF A=B and A!=C THEN B!=C的規則,對負樣本做了擴充增強。
在對負樣本進行擴充後, 正負樣本比例從原始的1.4:1, 變成2.9:1。 所以又對負樣本進行了下取樣, 是的正負樣本比例1:1。
- 同義詞替換
使用開源包synormise的效果不太好, 後面可以嘗試使用公開醫學預料訓練word2vec模型來做同義詞替換(時間問題, 沒有嘗試)。
隨機刪除,隨機替換, 隨機交換
句式比較短, 隨機刪除更短。
很多query僅僅相差一個單詞, 隨機替換改變語意。
多數屬於問句, 隨機交換改變了語意。
- 模型選擇
在預訓練模型的基礎上通過對抗訓練增強模型的泛化效能。
-
BRET
Bert的一個下游基礎任務語句對分類(Sentence Pair Classification Task), [CLS] Bert的輸出有一個維度的向量表示 -
BERT+CNN(LSTM)
將BERT的輸出特徵作為文字的表示向量, 然後後面再接上LSTM或者CNN(效果下降) -
BERT+siamese
將大賽提供的category資訊利用上, 借用孿生網路的思想與兩個Query進行拼接(效果下降)。
- 結果分析
- 單模型線上效果
目前所訓練的模型中:
小模型中BERT-wwm-ext表現是最好的,
大模型中RoBERTa-large-pair表現最好。
在現有的資源和模型上, 對單模型的引數尋優到達一個天花板,線上最高的分數為0.9603。後面開始探索多模型融合。
- 多模型融合線上效果
將不同型別的預訓練模型作為基模型進行多模型融合。基模型的挑選準則基於單模型的線上提交效果,從不同型別的單模型中挑選線上表現最好的引數, 重新訓練融合。
基模型:
BERT-wwm-ext + FGM
RoBERTa-large-pair + FGM
Ernie(BaiDu)+ FGM
模型融合策略使用的是averaging, 為了降低差別比較小的模型對結果的影響,採用sigmoid反函數的方式進行ensemble。
關於對抗訓練在NLP中的作用,參照大佬的一句話叫緣,妙不可言~
5.2方案二
- 探索分析
文字長度:訓練集和驗證集分佈類似,大都集中在10-20個字

標籤分佈


總體思路

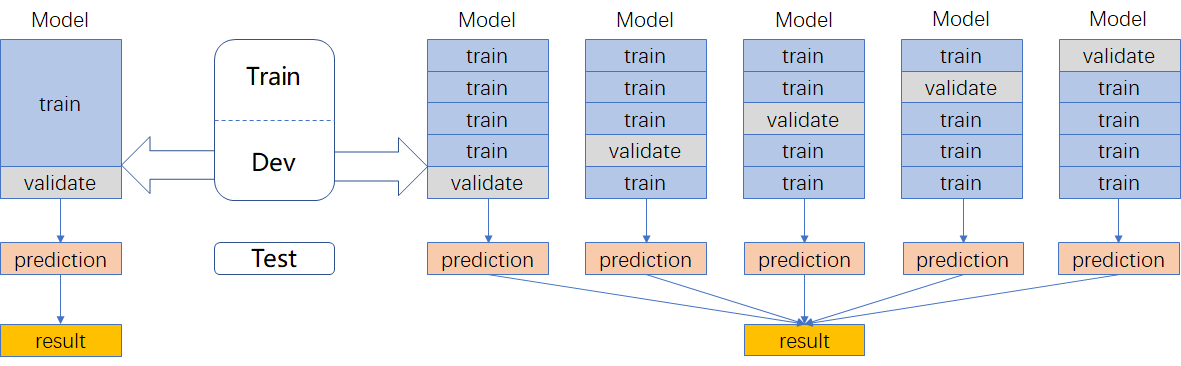
- 資料劃分
採用kfold交叉驗證(右邊的劃分方式)
•利用全部資料,獲得更多資訊
•降低方差,提高模型效能
- 模型設計

二分類交叉熵損失函數:
- 模型融合
小模型同時加入CHIP2019資料訓練
| 模型 | 特點 | 權重 | 加入外部句對資料 |
|---|---|---|---|
| BERT-wwm-ext | 全詞Mask | 1 | YES |
| Ernie-1.0 | 對詞、實體及實體關係建模 | 1 | YES |
| RoBERTa-large-pair | 面向相似性或句子對任務優化 | 1 | NO |
- 資料預處理
對稱擴充、傳遞擴充(注意要保持原來的分佈,否則會過擬合)
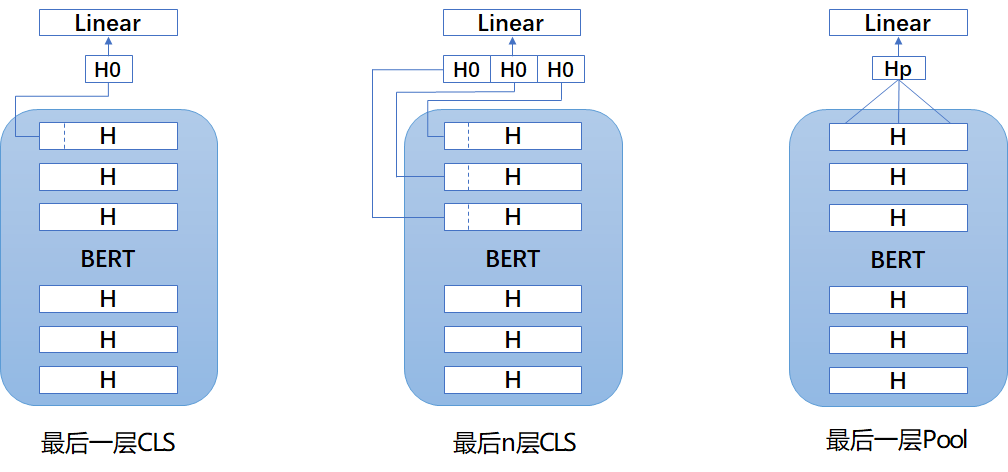
- 訓練
- 三種結構:(實際使用差別不大,第一種又好又簡單)
- 對抗訓練

#程式碼來自蘇劍林bert4keras
def adversarial_training(model, embedding_name, epsilon=1):
"""給模型新增對抗訓練
其中model是需要新增對抗訓練的keras模型,embedding_name
則是model裡邊Embedding層的名字。要在模型compile之後使用。
"""
if model.train_function is None: # 如果還沒有訓練函數
model._make_train_function() # 手動make
old_train_function = model.train_function # 備份舊的訓練函數
# 查詢Embedding層
for output in model.outputs:
embedding_layer = search_layer(output, embedding_name)
if embedding_layer is not None:
break
if embedding_layer is None:
raise Exception('Embedding layer not found')
# 求Embedding梯度
embeddings = embedding_layer.embeddings # Embedding矩陣
gradients = K.gradients(model.total_loss, [embeddings]) # Embedding梯度
gradients = K.zeros_like(embeddings) + gradients[0] # 轉為dense tensor
# 封裝為函數
inputs = (model._feed_inputs +
model._feed_targets +
model._feed_sample_weights) # 所有輸入層
embedding_gradients = K.function(
inputs=inputs,
outputs=[gradients],
name='embedding_gradients',
) # 封裝為函數
def train_function(inputs): # 重新定義訓練函數
grads = embedding_gradients(inputs)[0] # Embedding梯度
delta = epsilon * grads / (np.sqrt((grads**2).sum()) + 1e-8) # 計算擾動
K.set_value(embeddings, K.eval(embeddings) + delta) # 注入擾動
outputs = old_train_function(inputs) # 梯度下降
K.set_value(embeddings, K.eval(embeddings) - delta) # 刪除擾動
return outputs
model.train_function = train_function # 覆蓋原訓練函數
寫好函數後,啟用對抗訓練只需要一行程式碼
adversarial_training(model, 'Embedding-Token', 0.5)
- 預測
- 算數平均→幾何平均→sigmoid平均(用反函數取出sigmoid/softmax歸一化之前的狀態做平均,資訊量更大,提升明顯)

-
分類閾值微調(0.47)
-
偽標籤

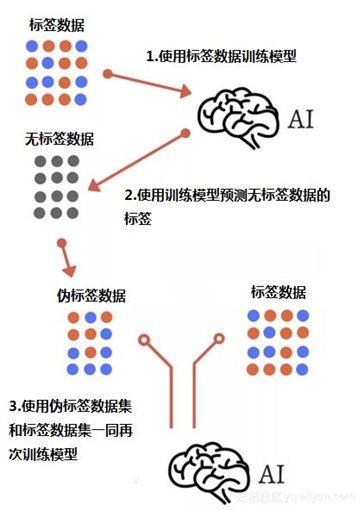
5.3 更多方案
更多方案就不一一展開了,參考下方連結:
https://tianchi.aliyun.com/notebook/101626
https://tianchi.aliyun.com/notebook/101648
https://tianchi.aliyun.com/notebook/101648
參考連結:
https://tianchi.aliyun.com/competition/entrance/231776/forum
https://tianchi.aliyun.com/notebook/102057
6.特定領域知識圖譜(Domain-specific KnowledgeGraph:DKG)融合方案(重點!)
在前面技術知識下可以看看後續的實際業務落地方案和學術方案
關於圖神經網路的知識融合技術學習參考下面連結:PGL圖學習專案合集&資料集分享&技術歸納業務落地技巧[系列十]
從入門知識到經典圖演演算法以及進階圖演演算法等,自行查閱食用!
文章篇幅有限請參考專欄按需查閱:NLP知識圖譜相關技術業務落地方案和碼源
6.1 特定領域知識圖譜知識融合方案(實體對齊):優酷領域知識圖譜為例
方案連結:https://blog.csdn.net/sinat_39620217/article/details/128614951
6.2 特定領域知識圖譜知識融合方案(實體對齊):文娛知識圖譜構建之人物實體對齊
方案連結:https://blog.csdn.net/sinat_39620217/article/details/128673963
6.3 特定領域知識圖譜知識融合方案(實體對齊):商品知識圖譜技術實戰
方案連結:https://blog.csdn.net/sinat_39620217/article/details/128674429
6.4 特定領域知識圖譜知識融合方案(實體對齊):基於圖神經網路的商品異構實體表徵探索
方案連結:https://blog.csdn.net/sinat_39620217/article/details/128674929
6.5 特定領域知識圖譜知識融合方案(實體對齊)論文合集
方案連結:https://blog.csdn.net/sinat_39620217/article/details/128675199
論文資料連結:兩份內容不相同,且按照序號從小到大重要性依次遞減
知識圖譜實體對齊資料論文參考(PDF)+實體對齊方案+特定領域知識圖譜知識融合方案(實體對齊)
知識圖譜實體對齊資料論文參考(CAJ)+實體對齊方案+特定領域知識圖譜知識融合方案(實體對齊)
6.6 知識融合演演算法測試方案(知識生產質量保障)
方案連結:https://blog.csdn.net/sinat_39620217/article/details/128675698
7.總結
本專案主要圍繞著特定領域知識圖譜(Domain-specific KnowledgeGraph:DKG)融合方案:技術知識前置【一】-文字匹配演演算法、知識融合學術界方案、知識融合業界落地方案、演演算法測評KG生產質量保障講解了文字匹配演演算法的綜述,從經典的傳統模型到孿生神經網路「雙塔模型」再到預訓練模型以及有監督無監督聯合模型,期間也涉及了近幾年前沿的對比學習模型,之後提出了文字匹配技巧提升方案,最終給出了DKG的落地方案。這邊主要以原理講解和技術方案闡述為主,之後會慢慢把專案開源出來,一起共建KG,從知識抽取到知識融合、知識推理、質量評估等爭取走通完整的流程。