group by 語句怎麼優化?
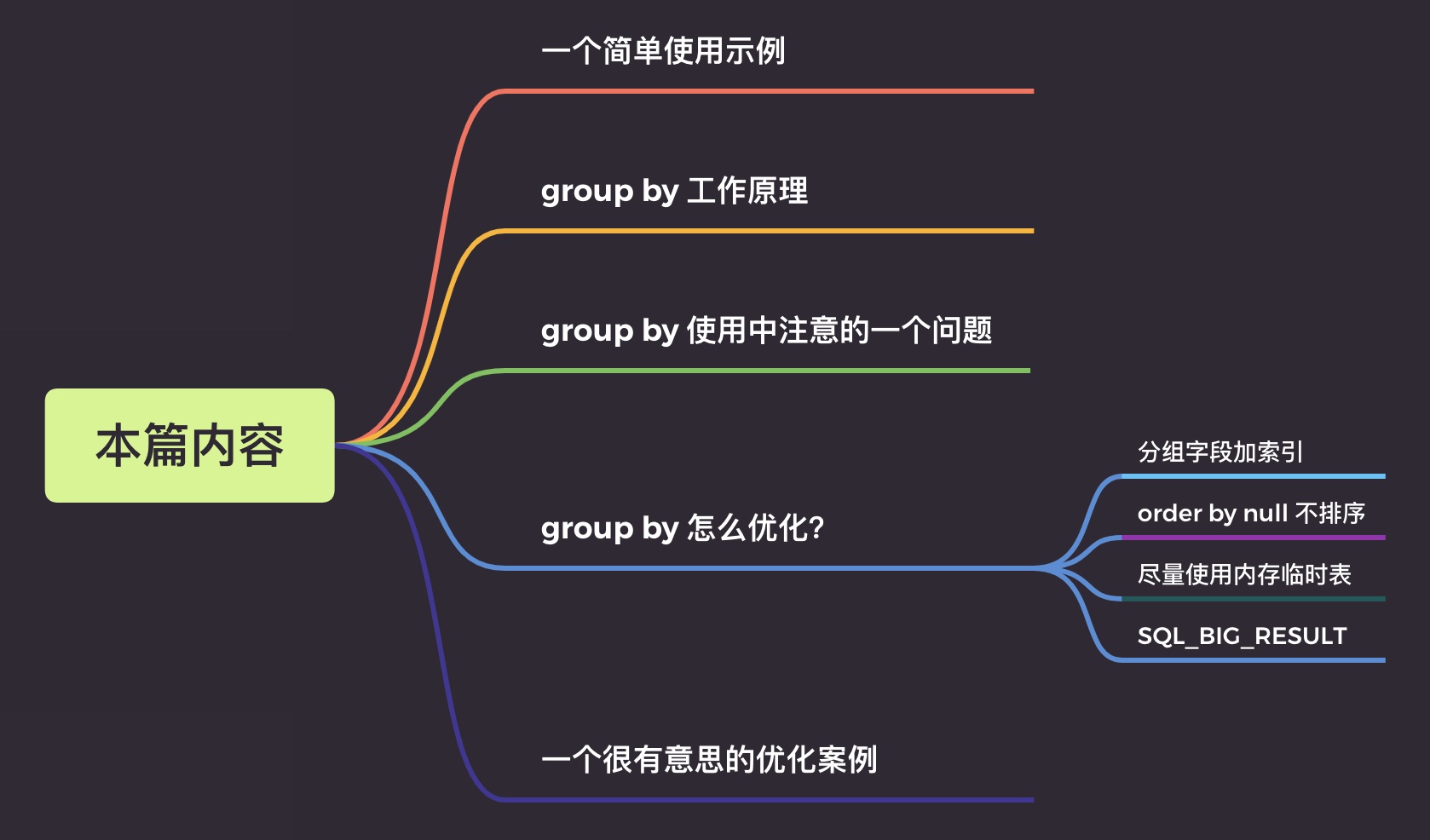
一、一個簡單使用範例
我這裡建立一張訂單表
CREATE TABLE `order_info` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`order_no` int NOT NULL COMMENT '訂單號',
`goods_id` int NOT NULL DEFAULT '0' COMMENT '商品id',
`goods_name` varchar(50) NOT NULL COMMENT '商品名稱',
`order_status` int NOT NULL DEFAULT '0' COMMENT '訂單狀態:1待支付,2成功支付,3支付失敗,4已關閉',
`pay_type` int NOT NULL DEFAULT '0' COMMENT '支付方式:1微信支付,2支付寶支付',
`price` decimal(11,2) DEFAULT NULL COMMENT '訂單金額',
`pay_time` datetime DEFAULT NULL COMMENT '支付時間',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_order_no` (`order_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='訂單資訊表';
同時也在表裡插了一些資料
現在我們這裡執行group by語句
select goods_name, count(*) as num
from order_info
group by goods_name
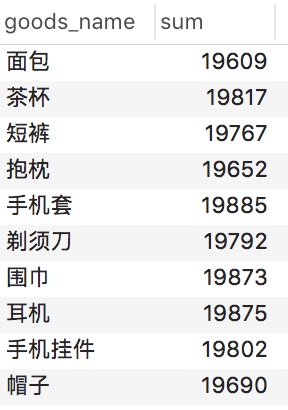
很明顯,這裡就可以統計出來 每件商品一共有多少訂單資料!
二、group by 原理分析
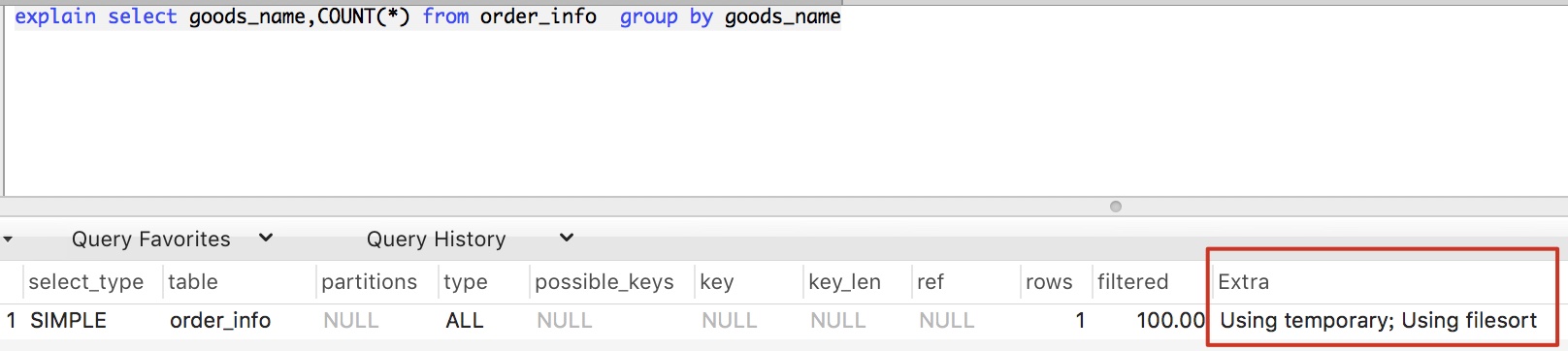
2.1、explain 分析
不同的資料庫版本,用explain執行的結果並不一致,同樣是上面sql語句
MySQL 5.7版本
-
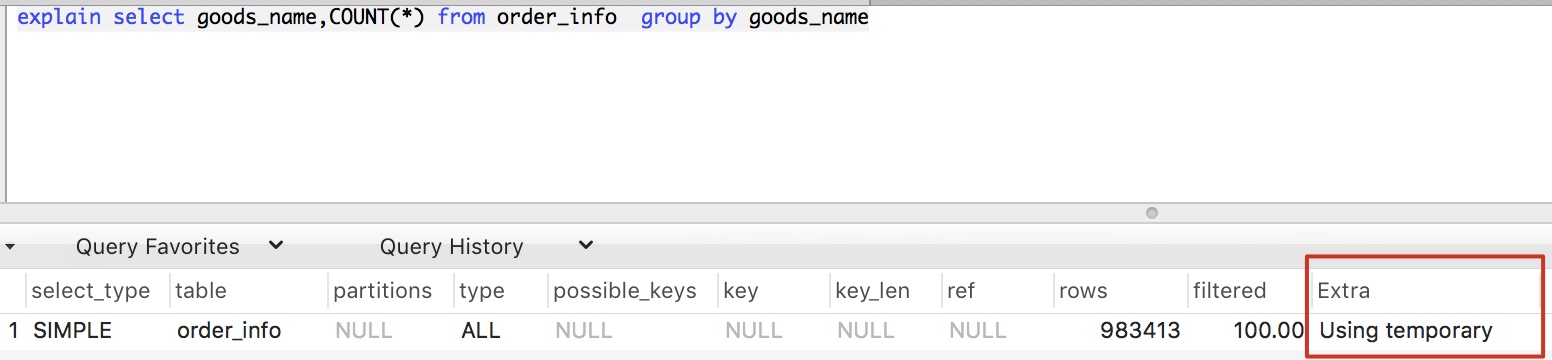
Extra 這個欄位的
Using temporary表示在執行分組的時候使用了臨時表 -
Extra 這個欄位的
Using filesort表示使用了排序
MySQL 8.0版本
我們通過對比可以發現:mysql 8.0 開始 group by 預設是沒有排序的了!
接下來我們來解釋下,為什麼在沒有加索引的情況下會有臨時表產生。
2.2、聊一聊 Using temporary
Using temporary表示由於排序沒有走索引、使用union、子查詢連線查詢,group_concat()或count(distinct)表示式的求值等等建立了一個內部臨時表。
注意這裡的臨時表可能是記憶體上的臨時表,也有可能是硬碟上的臨時表,理所當然基於記憶體的臨時表的時間消耗肯定要比基於硬碟的臨時表的實際消耗小。
但不是說多大臨時資料都可以直接存在記憶體的臨時表,而是當超過最大記憶體臨時表的最大容量就是轉為存入磁碟臨時表
當mysql需要建立臨時表時,選擇記憶體臨時表還是硬碟臨時表取決於引數tmp_table_size和max_heap_table_size,當所需臨時表的容量大於兩者的最小值時,mysql就會使用硬碟臨時表存放資料。
使用者可以在mysql的組態檔裡修改該兩個引數的值,兩者的預設值均為16M。
mysql> show global variables like 'max_heap_table_size';
+---------------------+----------+
| Variable_name | Value |
+---------------------+----------+
| max_heap_table_size | 16777216 |
+---------------------+----------+
1 row in set
mysql> show global variables like 'tmp_table_size';
+----------------+----------+
| Variable_name | Value |
+----------------+----------+
| tmp_table_size | 16777216 |
+----------------+----------+
1 row in set
2.3、group by 是如何產生臨時表的
同樣以該sql分析
select goods_name, count(*) as num
from order_info
group by goods_name
這個SQL產生臨時表的執行流程如下
-
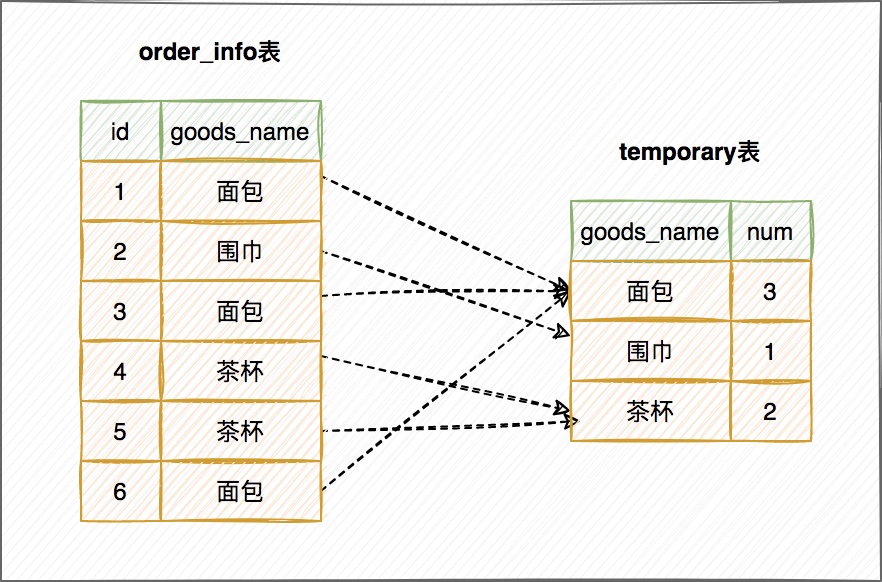
建立記憶體臨時表,表裡面有兩個欄位:goods_name 和 num;
-
全表掃描 order_info 表,取出 goods_name = 某商品(比如圍巾、耳機、茶杯等)的記錄
-
- 臨時表沒有 goods_name = 某商品的記錄,直接插入,並記為 (某商品,1);
- 臨時表裡有 goods_name = 某商品的記錄,直接更新,把 num 值 +1
-
重複步驟 3 直至遍歷完成,然後把結果集返回使用者端。
這個流程的執行圖如下:
三、group by 使用中注意的一個問題
我們來思考一個問題
select的 列 和group by的 列 不一致會報錯嗎?
比如
select goods_id, goods_name, count(*) as num
from order_info
group by goods_id;
上面我們想根據商品id進行分組,統計每個商品的訂單數量,但是我們分組只根據 goods_id分組,但在查詢列的時候,既要返回goods_id,也要返回goods_name。
我們這麼寫因為我們知道:一樣的goods_id一定有相同的 goods_name,所以就沒必要寫成 group by goods_id,goods_name;
但上面這種寫法一定會被支援嗎?未必!
我們分別以mysql5.7版本和8.0版本做下嘗試。
mysql5.7版本
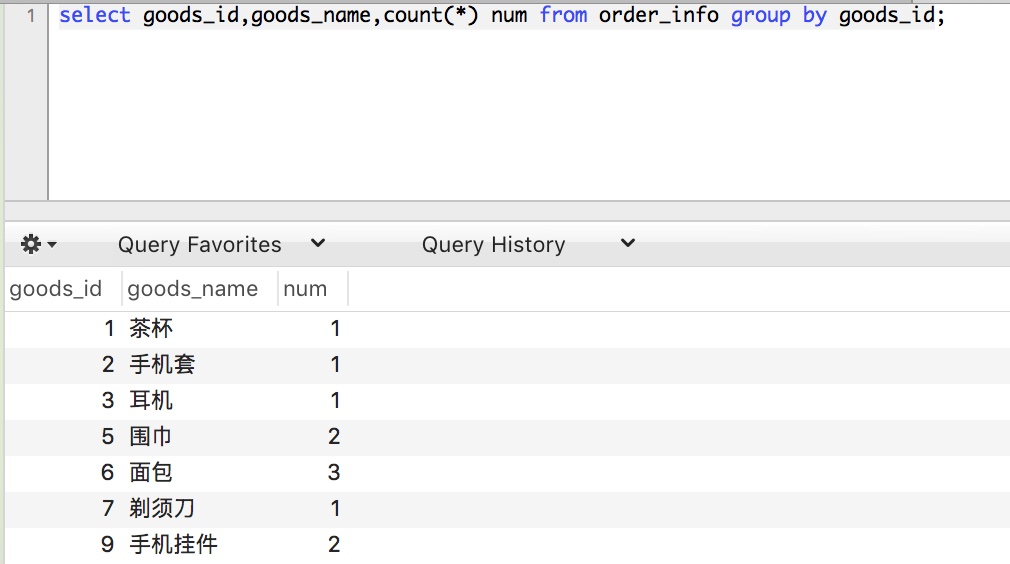
我們發現是可以查詢的到的。
mysql8.0版本

我們在執行上面sql發現報錯了,沒錯同樣的sql在不同的mysql版本執行結果並不一樣,我們看下報什麼錯!
出現這個錯誤的原因是 mysql 的 sql_mode 開啟了 ONLY_FULL_GROUP_BY 模式
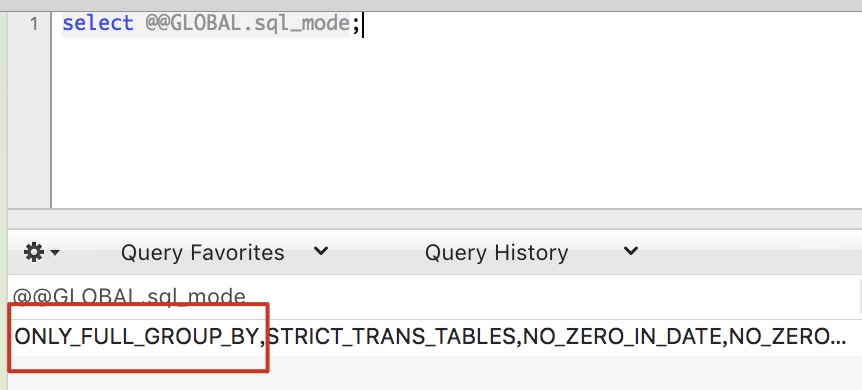
該模式的含義就是: 對於group by聚合操作,如果在select中的列,沒有在group by中出現,那麼這個sql是不合法的,因為列不在group by從句中。
這其實是一種更加嚴謹的做法。
就比如上面這個sql,如果存在這個商品的名稱被修改過了,但是它們的id確還是一樣的,那麼這個時候展示的商品名稱是修改前的還是修改後的呢?
那對於上面這種情況,mysql5.7版本是如何做的呢?
1.建立記憶體臨時表,表裡面有三個欄位:goods_id,goods_name 和 num;
2.當我第一次這個goods_id=1對應 goods_name=麵包 時,那麼這個id對應goods_name就是麵包,就算後面這個id對應的是火腿麵包,雞腿麵包,這都不管,
只要第一個是麵包,那就固定是這個名稱了。這叫先到先得原則。
如果你的8.0版本不想要 ONLY_FULL_GROUP_BY 模式,那關閉就可以了。
四、group by 如何優化
group by在使用不當的時候,很容易就會產生慢SQL 問題。因為它既用到臨時表,又預設用到排序。有時候還可能用到磁碟臨時表。
這裡總結4點優化經驗
-
分組欄位加索引
-
order by null 不排序
-
儘量使用記憶體臨時表
-
SQL_BIG_RESULT
4.1、分組欄位加索引
-- 我們給goods_id新增索引
alter table order_info add index idx_goods_id (goods_id)
然後再看下執行計劃

很明顯 之前的 Using temporary 和 Using filesort 都沒有了,只有Using index(使用索引了)
4.2、order by null 不排序
如果需求是不用排序,我們就可以這樣做。在 sql 末尾加上 order by null
select goods_id, count(*) as num
from order_info
group by goods_id
order by null
但是如果是已經走了索引,或者說8.0的版本,那都不需要加 order by null,因為上面也說了8.0預設就是不排序的了。
4.3、儘量使用記憶體臨時表
因為上面也說了,臨時表也分為記憶體臨時表和磁碟臨時表。如果資料量實在過大,大到記憶體臨時表都不夠用了,這時就轉向使用磁碟臨時表。
記憶體臨時表的大小是有限制的,mysql 中 tmp_table_size 代表的就是記憶體臨時表的大小,預設是 16M。當然你可以自定義社會中適當大一點,這就要根據實際情況來定了。
4.4、SQL_BIG_RESULT
如果資料量實在過大,大到記憶體臨時表都不夠用了,這時就轉向使用磁碟臨時表。
而發現不夠用再轉向這個過程也是很耗時的,那我們有沒有一種方法,可以告訴 mysql 從一開始就使用 磁碟臨時表呢?
因此,如果預估資料量比較大,我們使用SQL_BIG_RESULT 這個提示直接用磁碟臨時表。
explain select sql_big_result goods_id, count(*) as num
from order_info
group by goods_id

從執行結果來看 確實已經不存在臨時表了。
五、一個很有意思的優化案例
為了讓效果看去明顯點,我在這裡在資料庫中新增了100萬條資料(整整插了一下午呢)。
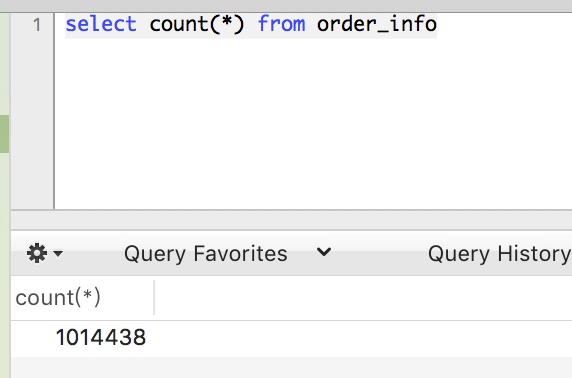
同時說明下當前資料庫版本是8.0.22。
執行得sql如下:
select goods_id, count(*) as num
from order_info
where pay_time >= '2022-12-01 00:00:00' and pay_time <= '2022-12-31 23:59:59'
group by goods_id;
5.1、不加任何索引
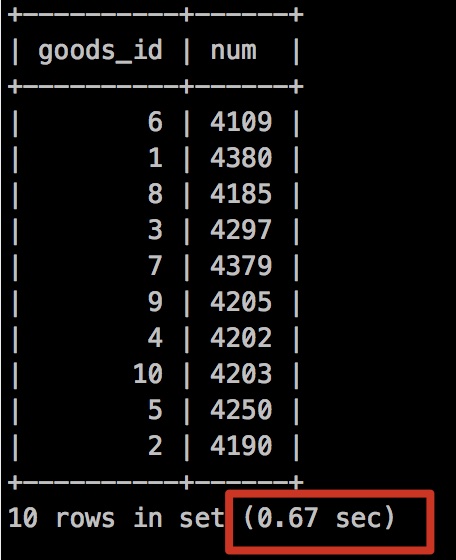
我們發現當我們什麼索引都沒加執行時間是: 0.67秒。
我們在執行下explain

我們發現沒有走任何索引,而且有臨時表存在,那我是不是考慮給goods_id 加一個索引?
5.2、僅分組欄位加索引
alter table order_info add index idx_goods_id(goods_id);
我們在執行下explain

確實是走了 上面建立的idx_goods_id,索引,那查詢效率是不是要起飛了?
我們在執行下上面的查詢sql
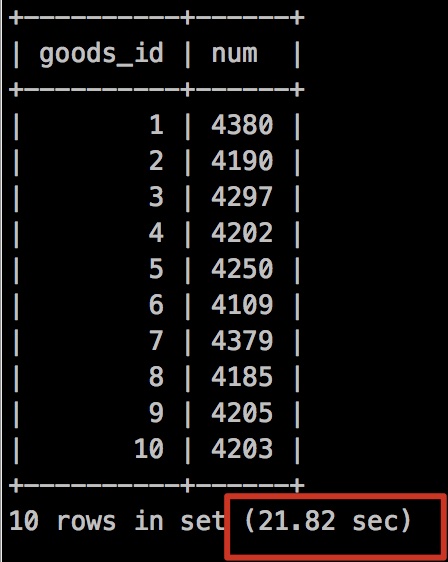
執行時間是: 21.82秒!
是不是很神奇,明明我的分組欄位加了索引,而且從執行計劃來看確實走了索引,而且也不存在Using temporary臨時表了,怎麼速度反而下來了,這是為什麼呢?
原因:
雖然說我們用到了idx_goods_id 索引,那我們看上圖執行計劃中 rows = 997982,說明啥,說明雖然走了索引,但是從掃描資料來看依然是全表掃描呢,為什麼會這樣?
首先group by用到索引,那就在索引樹上索引資料,但是因為加了where條件,還是需要在去表裡檢索幾乎所有的資料, 這樣子,還不如直接去表裡進行全表掃,這樣還更快些。
所以沒有索引反而更快了
5.3、查詢欄位和分組欄位建立組合索引
那我們給 pay_time 和 goods_id建立組合索引呢?
-- 先刪除idx_goods_id索引
drop index idx_goods_id on order_info;
-- 再新建組合索引
alter table order_info add index idx_payTime_goodsId(pay_time,goods_id);
我們在執行下explain

這次可以很明顯的看到
-
Extra 這個欄位的
Using index表示該查詢條件確實用到了索引,而且是索引覆蓋 -
Extra 這個欄位的
Using temporary表示在執行分組的時候使用了臨時表
為什麼會這樣,其實原因很簡單
range型別查詢欄位後面的索引全都無效
因為pay_time是範圍查詢,索引goods_id無效,所以分組一樣有臨時表存在!
我們在看下查詢時間
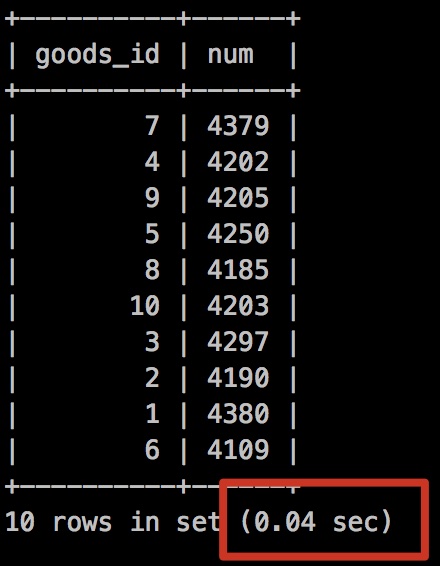
執行時間是: 0.04秒!
是不是快到起飛,雖然我們從執行計劃來看依然還是存在 Using temporary ,但查詢速度卻非常快。
關鍵點就在Using index(索引覆蓋),雖然排序是無法走索引了,但是不需要回表查詢,這個效率提升是驚人的!
5.4、僅查詢欄位建立索引
上面說了就算建立了 pay_time,goods_id 組合索引,對於goods_id 分組依然不走索引的。
這裡我自建立 pay_time單個索引
-- 先刪除組合索引
drop index idx_payTime_goodsId on order_info;
-- 再新建單個索引
alter table order_info add index idx_pay_time(pay_time);

這次可以很明顯的看到
-
Extra 這個欄位的
using index condition需要回表查詢資料,但是有部分資料是在二級索引過濾後,再回表查詢資料,減少了回表查詢的資料行數 -
Extra 這個欄位的
Using MRR優化器將隨機 IO 轉化為順序 IO 以降低查詢過程中 IO 開銷 -
Extra 這個欄位的
Using temporary表示在執行分組的時候使用了臨時表
檢視查詢時間
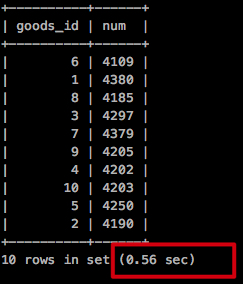
執行時間 0.56秒!
從結果看出,跟最開始不加索引查詢速度相差不多,原因是什麼呢?
最主要原因就是雖然走了索引,但是依然還需要回表查詢,查詢效率並沒有提高多少!
那我們思考如何優化呢,既然上面走了回表,我們是不是可以不走回表查詢,這裡修改下sql
select goods_id, count(*) as num
from order_info
where id in (
select id
from order_info
where pay_time >= '2022-12-01 00:00:00'
and pay_time <= '2022-12-31 23:59:59'
)
group by goods_id;
檢視查詢時間
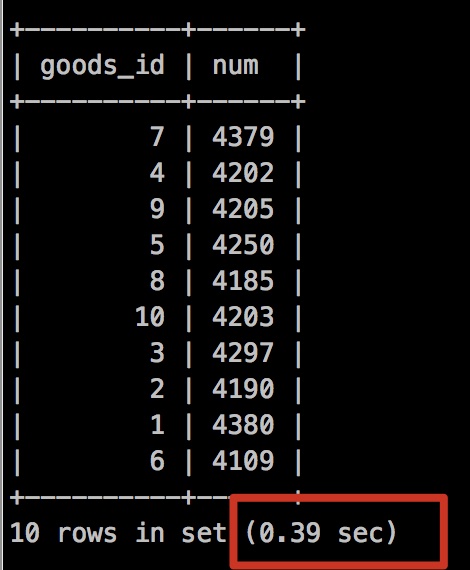
執行時間 0.39秒!
速度確實有提升,我們在執行下explain

我們可以看到 沒有了using index condition,而有了Using index,說明不需要再回表查詢,而是走了索引覆蓋!
宣告: 公眾號如需轉載該篇文章,發表文章的頭部一定要 告知是轉至公眾號: 後端元宇宙。同時也可以問本人要markdown原稿和原圖片。其它情況一律禁止轉載!