刺激,執行緒池的一個BUG直接把CPU幹到100%了。
你好呀,我是歪歪。
給大家分享一個關於 ScheduledExecutorService 執行緒池的 BUG 啊,這個 BUG 能直接把 CPU 給飈到 100%,希望大家永遠踩不到。
但是,u1s1,一般來說也很難踩到。
到底咋回事呢,讓我給你細細嗦嗦。
Demo
老規矩,按照慣例,先搞個 Demo 出來玩玩:
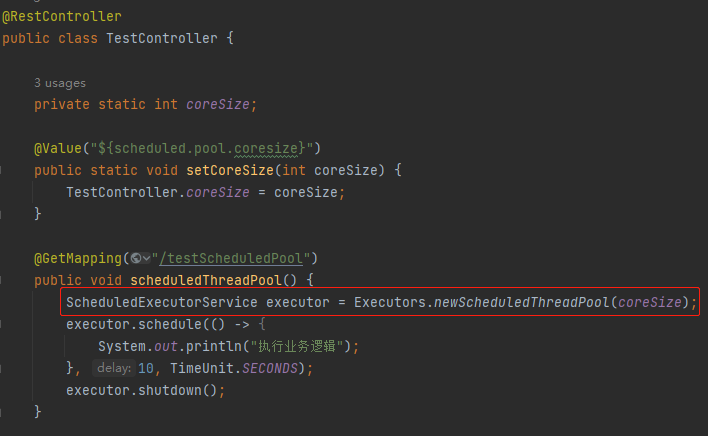
專案裡面使用到了 ScheduledThreadPoolExecutor 執行緒池,該執行緒池對應的核心執行緒數放在組態檔裡面,通過 @Value 註解來讀取組態檔。
然後通過介面觸發這個執行緒池裡面的任務。
具體來說就是在上面的範例程式碼中,在呼叫 testScheduledPool 介面之後,程式會在 60 秒之後輸出「執行業務邏輯」。
這個程式碼的邏輯還是非常簡單清晰的,但是上面的程式碼有一個問題,不知道你看出來沒有?

沒看出來也沒關係,我這裡都是鼓勵式教學的,不打擊同學的積極性。
所以,彆著急,我先給你跑起來,你瞅一眼立馬就能看出問題是啥:
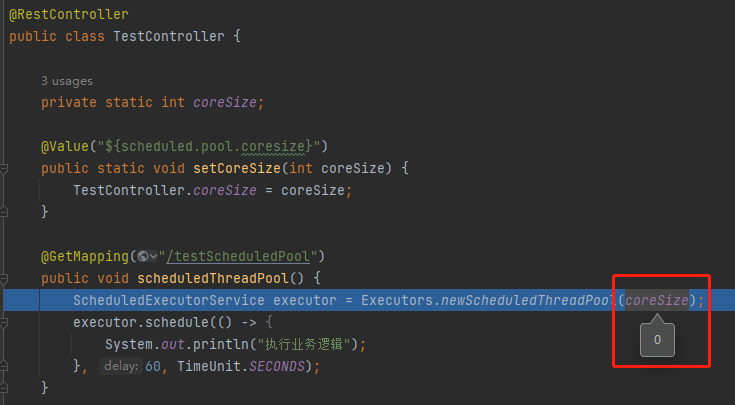
為什麼 coreSize 是 0 呢,我們組態檔裡面明明寫的是 2 啊?
因為 setCoreSize 方法是 static 的,導致 @Value 註解失效。
如果去掉 static 那麼就能正確讀取到組態檔中的設定:
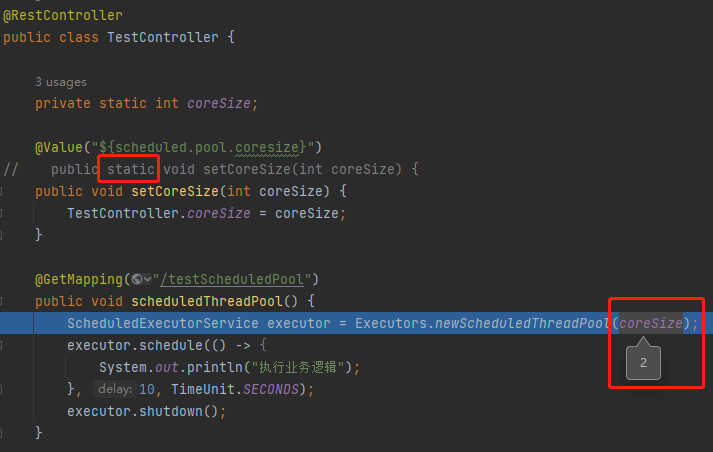
雖然這裡面也大有學問,但是這並不是本文的重點,這只是一個引子,
為的是引出為什麼會在專案裡面出現下面這種 coreSize 等於 0 的奇怪的程式碼:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(0);
如果我直接給出上面的程式碼,一點有人說只有小(大)可(傻)愛(逼)才會這樣寫。
但是鋪墊一個背景之後,就容易接受的多了。
你永遠可以相信我的行文結構,老司開車穩得很,你放心。
好,經過前面的鋪墊,其實我們的 Demo 能直接簡化到這個樣子:
public static void main(String[] args){
ScheduledExecutorService e = Executors.newScheduledThreadPool(0);
e.schedule(() -> {
System.out.println("業務邏輯");
}, 60, TimeUnit.SECONDS);
e.shutdown();
}
這個程式碼是可以正常執行的,你粘過去直接就能跑,60 秒後是會正常輸出的。
如果你覺得 60 秒太長了,那麼你可以改成 3 秒執行一下,看看程式是不是正常執行並結束了。
但是就這個看起來問題不大的程式碼,會導致 CPU 飈到 100% 去。
真的,兒豁嘛。

咋回事呢
到底咋回事呢?
這個其實就是 JDK 的 BUG 導致的,我帶你瞅瞅:
https://bugs.openjdk.org/browse/JDK-8065320
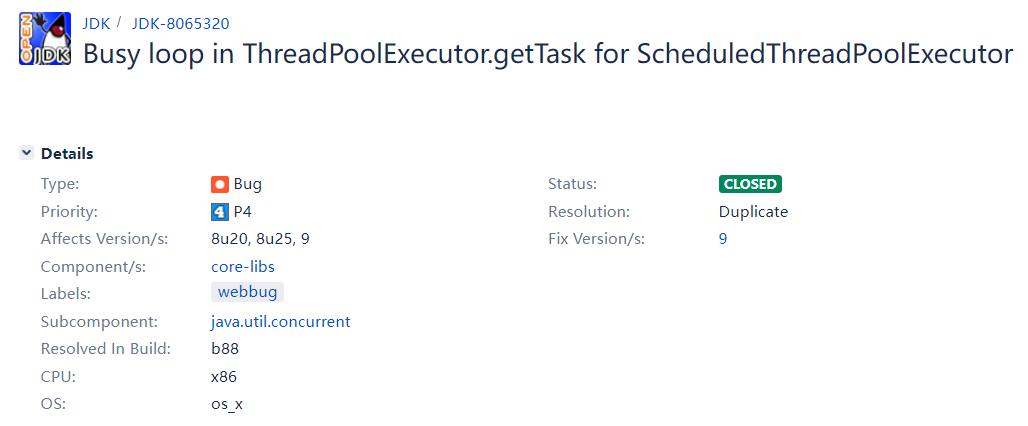
首先,你看 Fix Version 那個地方是 9,也就是說明這個 BUG 是在 JDK 9 裡面修復了。JDK 8 裡面是可以復現的。
其次,這個標題其實就包含了非常多的資訊了,它說對於 ScheduledExecutorService 來說 getTask 方法裡面存在頻繁的迴圈。
那麼問題就來了:頻繁的迴圈,比如 for(;;) ,while(true) 這樣的程式碼,長時間從迴圈裡面走不出來,會導致什麼現象?
那不就是導致 CPU 飆高嗎。
注意,這裡我說的是「長時間從迴圈裡面走不出來」,而不是死迴圈,這兩者之間的差異還是很大的。
我程式碼裡面的範例就是使用的提出 BUG 的哥們給出的範例:

他說,在這個範例下,如果你在一個只有單核的伺服器上跑,然後使用 TOP 命令,會看到持續 60 秒的 CPU 使用率為 100%。
為什麼呢?
答案就藏在前面提到的 getTask 方法中:
java.util.concurrent.ThreadPoolExecutor#getTask
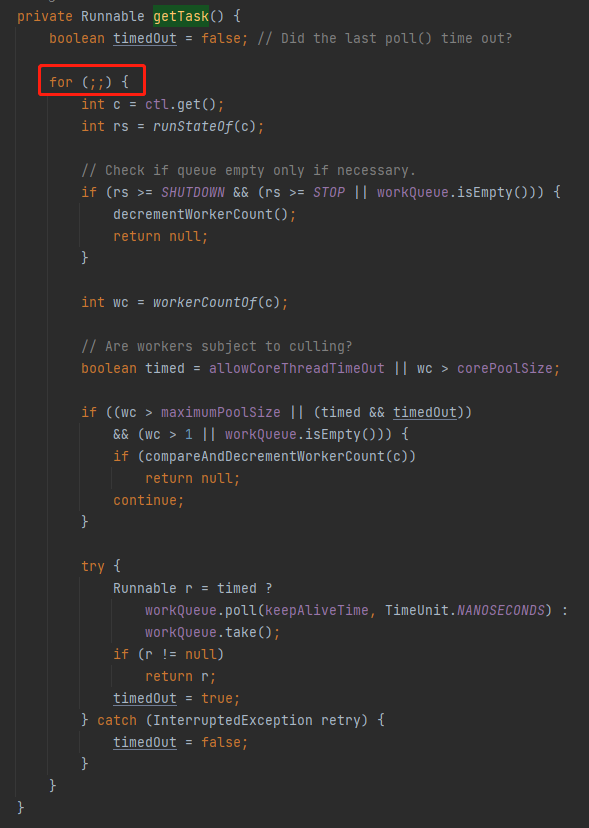
這個方法裡面果然是有一個類似於無線迴圈的程式碼,但是它為什麼不停的執行呢?
現在趕緊想一想執行緒池的基本執行原理。當沒有任務處理的時候,核心執行緒在幹啥?

是不是就阻塞在這個地方,等著任務過來進行處理的,這個能理解吧:
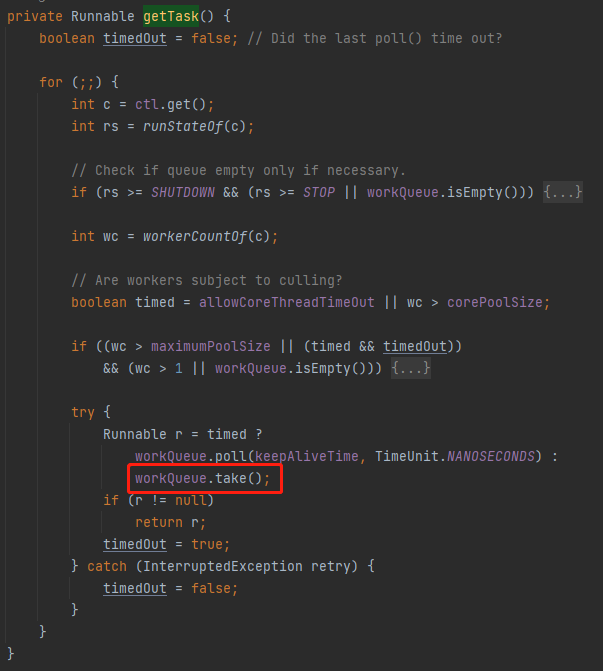
那我再問你一個問題,這行程式碼的作用是幹啥:
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
是不是在指定時間內如果沒有從佇列裡面拉取到任務,則丟擲 InterruptedException。
那麼它什麼時候會被觸發呢?
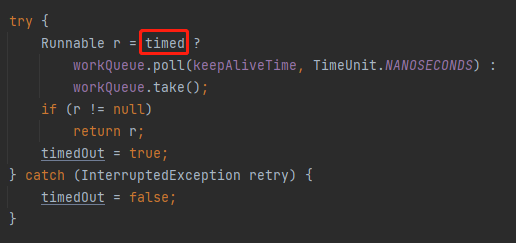
在 timed 引數為 true 的時候。
timed 引數什麼時候會為 true 呢?
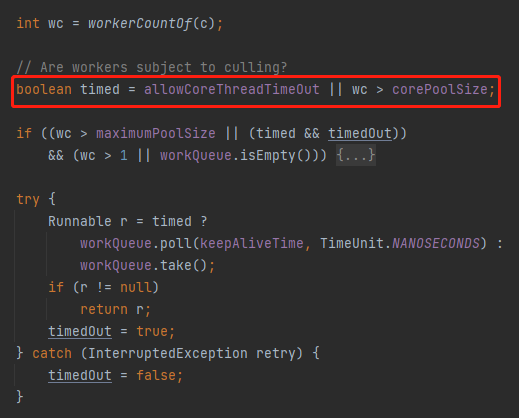
當 allowCoreThreadTimeOut 為 true 或者當前工作的執行緒大於核心執行緒數的時候。
而 allowCoreThreadTimeOut 預設為 false:
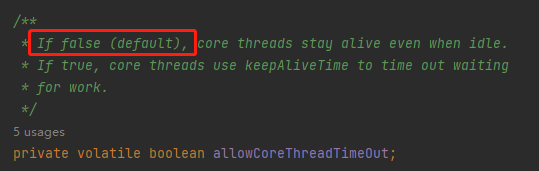
那麼也就是在這個案例下滿足了當前工作的執行緒大於核心執行緒數這個條件:
wc > corePoolSize
通過 Debug 知道,wc 是 1,corePoolSize 為 0:

所以 timed 變成了 true。
好,這裡要注意了,朋友。

經過前面的分析,我們已經知道了在當前的案例下,會觸發 for(;;)這個邏輯:
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
那麼這個 keepAliveTime 到底是多少呢?
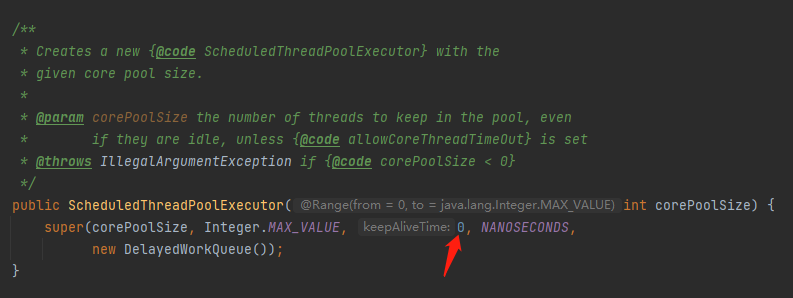
來,大聲的喊出這個數位:0,這是一個意想不到的、詭計多端的 0。

所以,這個地方中的 r 每次都會返回一個 null,然後再次開啟迴圈。
對於正常的執行緒池來說,觸發了這個邏輯,代表沒有任務要執行了,可以把對應執行緒進行回收了。
回收,對應的就是這部分程式碼會返回一個 null:
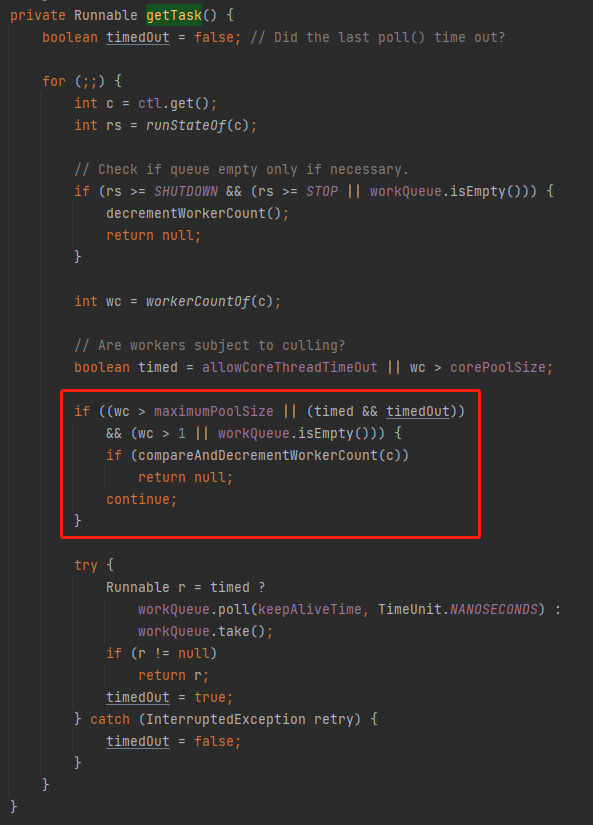
然後在外面 runWorker 方法中的,由於 getTask 返回了 null,從而執行了 finally 程式碼裡面的邏輯,也就是從當前執行緒池移除執行緒的邏輯:
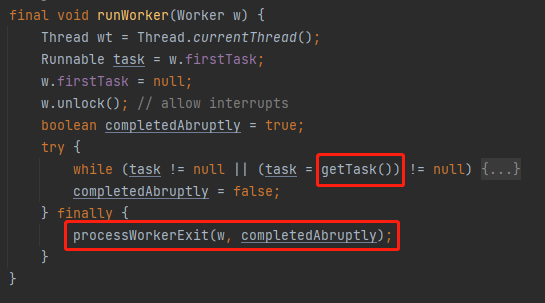
但是,朋友,我要說但是了。
在我們的案例下,你看 if 判斷的條件:
5a5qbwiy54i.jpg)
這裡面的 wc > 1 || workQueue.isEmpty()) 是 false
所以這個 if 條件不成立,那麼它又走到了 poll 這裡:
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS)
由於這裡的 keepAliveTime 是 0,所以馬不停蹄的的開啟下一輪迴圈。
那麼這個迴圈什麼時候結束呢?
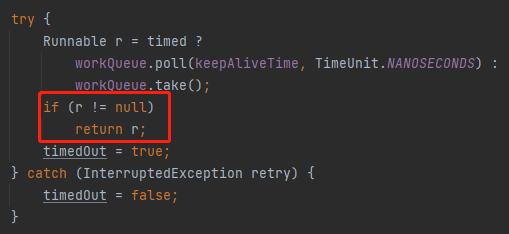
就是在從佇列裡面獲取到任務的時候。
那麼佇列裡面什麼時候才會有任務呢?
在我們的案例裡面,是 60 秒之後。
所以,在這 60 秒內,這部分程式碼相當於是一個「死迴圈」,導致 CPU 持續飆高到 100%。
這就是 BUG,這就是根本原因。
但是看到這裡是不是覺得還差點意思?
我說 100% 就 100% 嗎?
得拿出石錘來才行啊。
所以,為了拿出實錘,眼見為實,我把核心流程拿出來,然後稍微改動一點點程式碼:
public static void main(String[] args) {
ArrayBlockingQueue<Runnable> workQueue =
new ArrayBlockingQueue<>(100);
//繫結到 5 號 CPU 上執行
try (AffinityLock affinityLock = AffinityLock.acquireLock(5)) {
for (; ; ) {
try {
Runnable r = workQueue.poll(0, TimeUnit.NANOSECONDS);
if (r != null)
break;
} catch (InterruptedException retry) {
}
}
}
}
AffinityLock 這個類在之前的文章裡面出現過:《面試官:Java如何繫結執行緒到指定CPU上執行?》
就是把執行緒繫結到指定 CPU 上去執行,減少 CPU 抖動帶來的損耗, 具體我就不介紹了,有興趣去看我之前的文章。
把這個程式跑起來之後,開啟資源監視器,你可以看到 5 號 CPU 立馬就飈到 100% 了,停止執行之後,立馬就下來了:

這就是眼見為實,這真是 JDK 的 BUG,我真沒騙你。
怎麼修復
在 JDK 9 裡面是怎麼修復這個 BUG 的呢?
在前面提到的 BUG 的連結中,有這樣的一個連結,裡面就是 JDK 9 版本里面針對上述的 BUG 進行的修復:
http://hg.openjdk.java.net/jdk9/jdk9/jdk/rev/6dd59c01f011
點開這個連結之後,你可以找到這個地方:
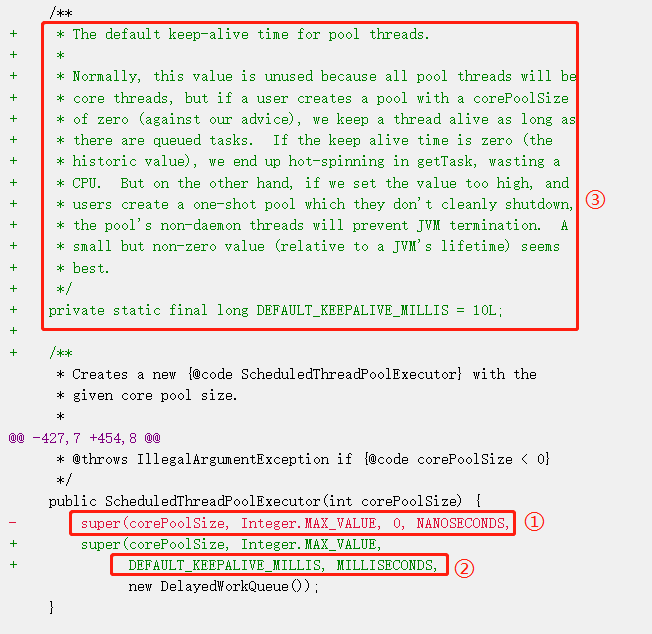
首先對比一下標號為 ① 和 ② 的地方,預設值從 0 納秒修改為了 DEFAULT_KEEPALIVE_MILLIS 毫秒。
而 DEFAULT_KEEPALIVE_MILLIS 的值為在標號為 ③ 的地方, 10L。
也就是預設從 0 納秒修改為了 10 毫秒。而這一處的改動,就是為了防止出現 coreSize 為 0 的情況。
我們重點關注一下 DEFAULT_KEEPALIVE_MILLIS 上面的那一坨註釋。
我給你翻譯一下,大概是這樣的:
這個值呢一般來說是用不上的,因為在 ScheduledThreadPoolExecutor 執行緒池裡面的執行緒都是核心執行緒。
但是,如果使用者建立的執行緒池的時候,不聽勸,頭鐵,要把 corePoolSize 設定為 0 會發生什麼呢?

因為 keepAlive 引數設定的為 0,那麼就會導致執行緒在 getTask 方法裡面非常頻繁的迴圈,從而導致 CPU 飆高。
那怎麼辦呢?
很簡單,設定一個小而非零的值就可以,而這個小是相對於 JVM 的執行時間而言的。
所以這個 10 毫秒就是這樣來的。
再來一個
在研究前面提到的編號為 8065320 的 BUG 的時候,我還發現一個意外收穫,編號為 8051859 的 BUG,它們是挨著的,排排坐。
有點意思,也很簡單,所以分享一波:
https://bugs.openjdk.org/browse/JDK-8051859

這個 BUG 又說的是啥事兒呢:
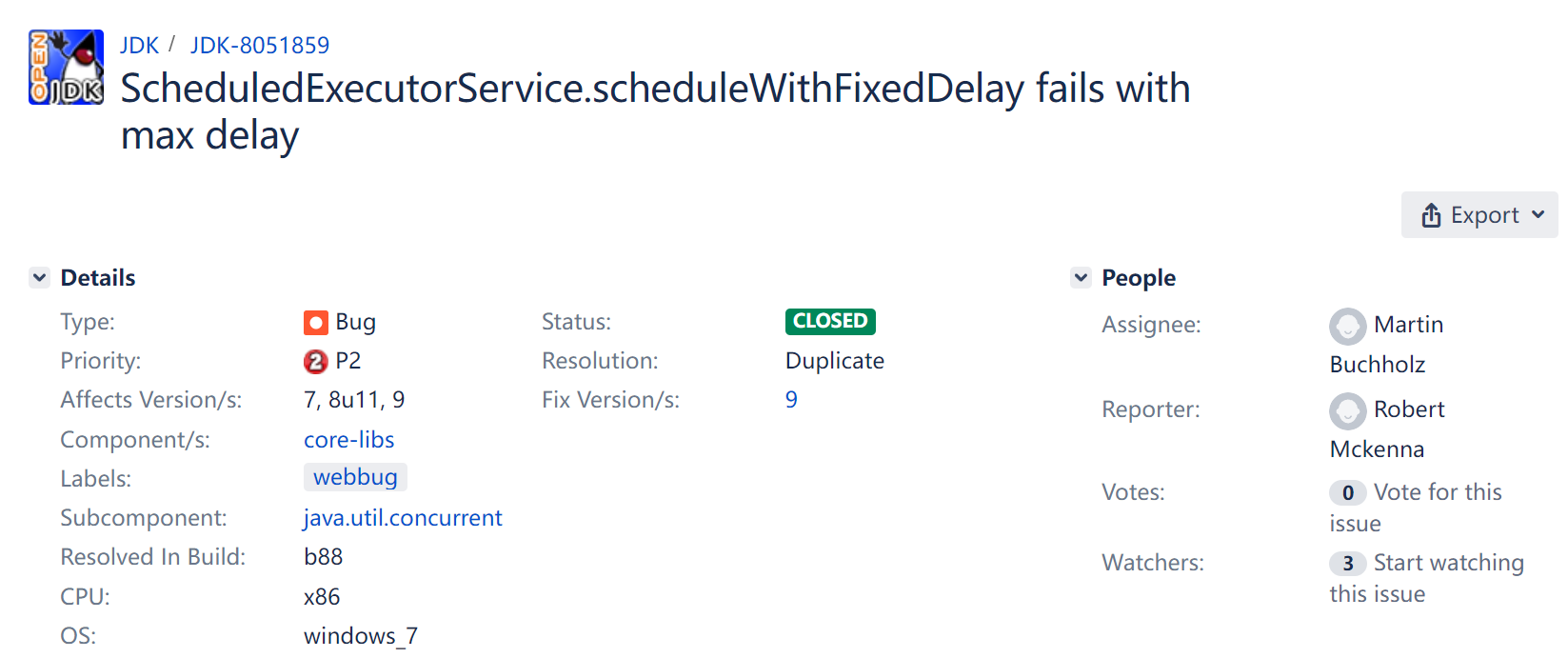
看截圖這個 BUG 也是在 JDK 9 版本之後修復的。
這個 BUG 的標題說的是 ScheduledExecutorService 執行緒池的 scheduleWithFixedDelay 方法,遇到大延遲時會執行失敗。
具體啥意思呢?
我們還是先拿著 Demo 說:
public class ScheduledTaskBug {
static public void main(String[] args) throws InterruptedException {
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
//第一個任務
executor.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
System.out.println("running scheduled task with delay: " + new Date());
}
}, 0, Long.MAX_VALUE, TimeUnit.MICROSECONDS);
//第二個任務
executor.submit(new Runnable() {
@Override
public void run() {
System.out.println("running immediate task: " + new Date());
}
});
Thread.sleep(5000);
executor.shutdownNow();
}
}
你把這個程式碼粘過去之後,發現輸出是這樣的:
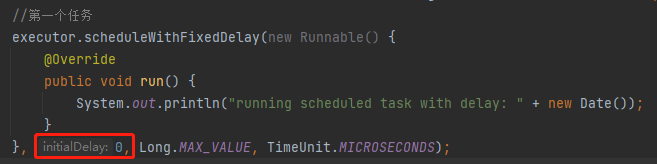
只有第一個任務執行了,第二個任務沒有輸出結果。
正常來說,第一個任務的延遲時間,也就是 initialDelay 引數是 0,所以第一次執行的時候是立即執行:
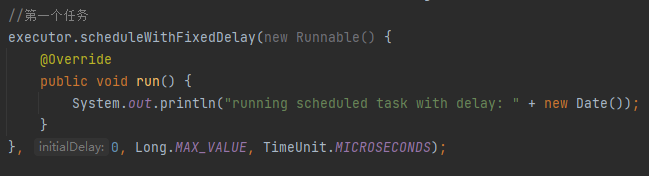
比如我改成這樣,把週期執行的時間單位,由微秒修改為納秒,就正常了:
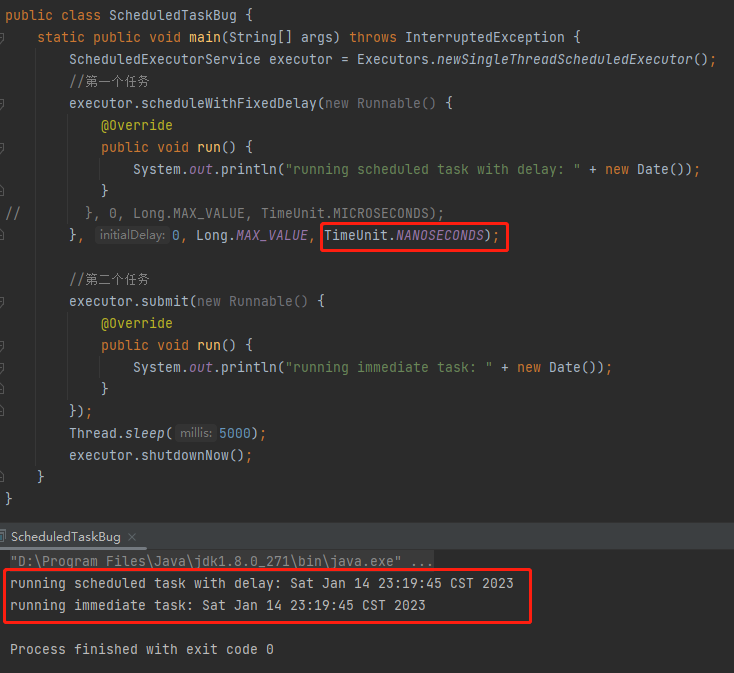
神奇不神奇?你說這不是 BUG 這是啥?
提出 BUG 的這個哥們在描述裡面介紹了 BUG 的原因,主要是提到了一個欄位和兩個方法:

一個欄位是指 period,兩個方法分別是 TimeUnit.toNanos(-delay) 和 ScheduledFutureTask.setNextRunTime()。
首先,在 ScheduledThreadPoolExecutor 裡面 period 欄位有三個取值範圍:
正數,代表的是按照固定速率執行(scheduleAtFixedRate)。 負數,代表的是按照固定延時執行(scheduleWithFixedDelay)。 0,代表的是非重複性任務。
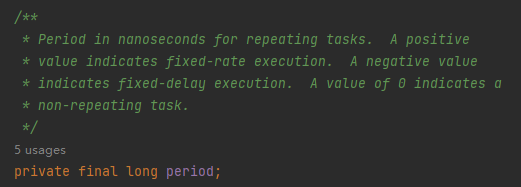
比如我們的範例程式碼中呼叫的是 scheduleWithFixedDelay 方法,它裡面就會在呼叫 TimeUnit.toNanos 方法的時候取反,讓 period 欄位為負數:

好,此時我們開始 Debug 我們的 Demo,先來一個正常的。
比如我們來一個每 30ms 執行一次的週期任務,請仔細看:

在執行 TimeUnit.toNanos(-delay) 這一行程式碼的時候,把 30 微秒轉化為了 -30000 納秒,也就是把 period 設定為 -30000。
然後來到 setNextRunTime 方法的時候,計算任務下一次觸發時間的時候,又把 period 轉為正數,沒有任何毛病:
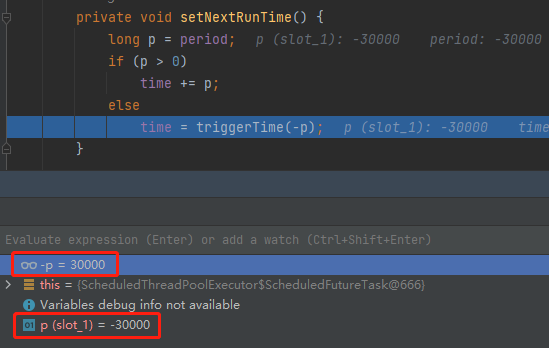
但是,當我們把 30 修改為 Long.MAX_VALUE 的時候,有意思的事情就出現了:
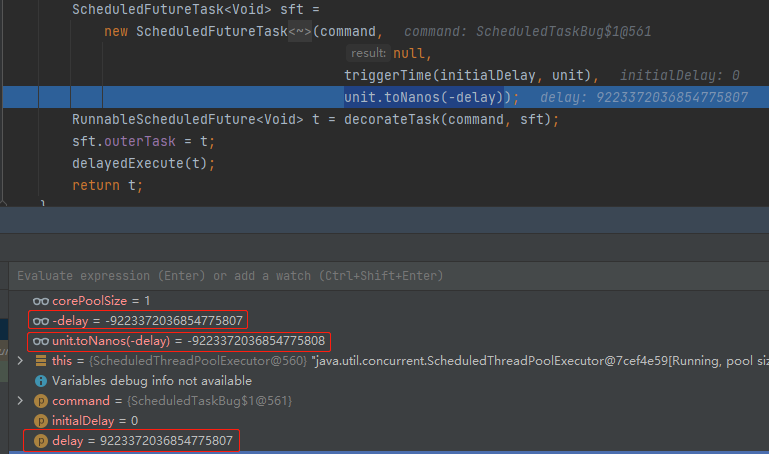
delay=9223372036854775807
-delay=-9223372036854775807
unit.toNanos(-delay)=-9223372036854775808
直接給幹溢位了,變成了 Long.MIN_VALUE:
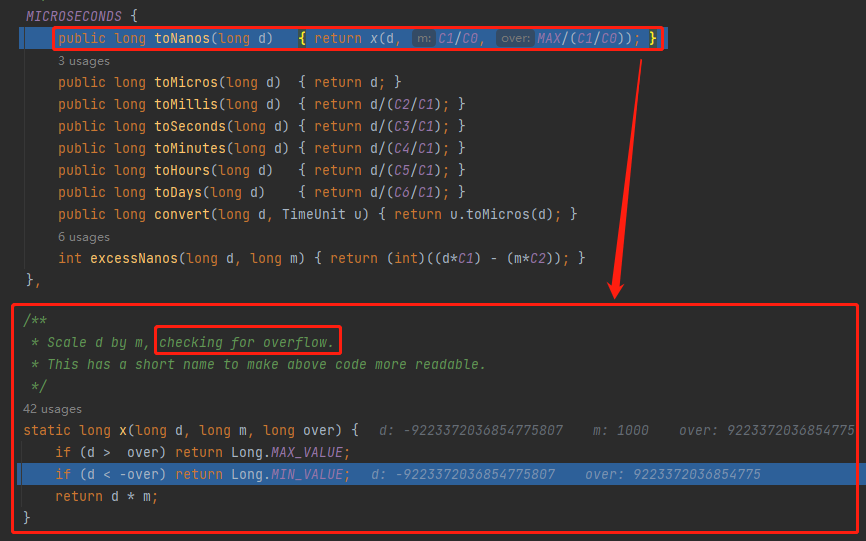
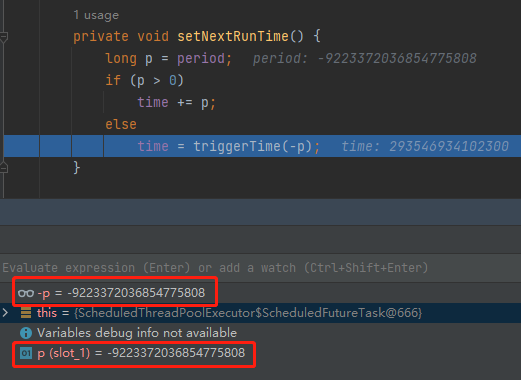
當來到 setNextRunTime 方法的時候,你會發現由於我們的 p 已經是 Long.MIN_VALUE 了。
那麼 -p 是多少呢?
給你跑一下:
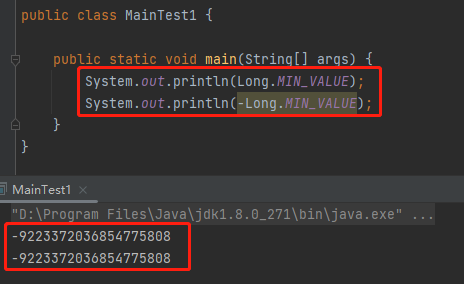
Long.MIN_VALUE 的絕對值,還是 Long.MIN_VALUE。一個神奇的小知識點送給你,不客氣。
所以 -p 還是 Long.MIN_VALUE:
我們來算一下啊,一秒等於 10 億納秒:

那麼下一次觸發時間就變成了這樣:
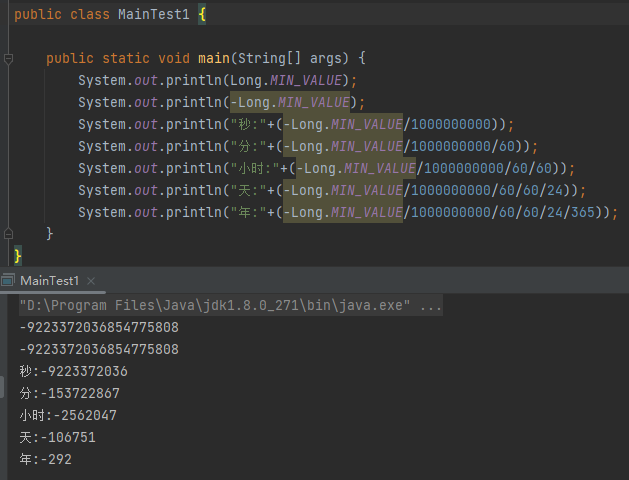
292 年之前。
這就是在 BUG 描述中提到的:
This results in triggerTime returning a time in the distant past.

the distant past,就是 long long ago,就是 292 年之前。就是 1731 年,雍正九年,那個時候的皇帝還是九子奪嫡中一頓亂殺,衝出重圍的胤禛大佬。
確實是很久很久以前了。
那麼這個 BUG 怎麼修復呢?
其實很簡單:

把 unit.toNanos(-delay) 修改為 -unit.toNanos(delay),搞定。
我給你盤一下:
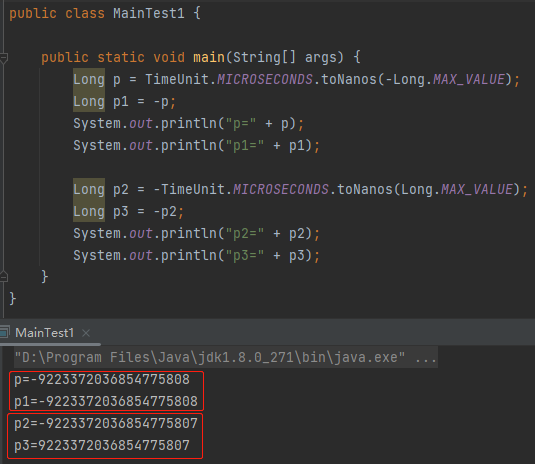
這樣就不會溢位,時間就變成了 292 年之後。
那麼問題就來了,誰特麼會設定一個每 292 年執行一次的 Java 定時任務呢?
好,你看到這裡了,本文就算結束了,我來問你一個問題:你知道了這兩個 BUG 之後,對你來說有什麼收穫嗎?

沒有,是的,除了浪費了幾分鐘時間外,沒有任何收穫。
那麼恭喜你,又在我這裡學到了兩個沒有卵用的知識點。

彙總
這個小節為什麼叫做彙總呢?
因為我發現這裡出現的一串 BUG,除了本文提到的 2 個外,還有 3 個我都寫過了,所以在這裡匯個總,充點字數,湊個篇幅:

8054446: Repeated offer and remove on ConcurrentLinkedQueue lead to an OutOfMemoryError
《我的程式跑了60多小時,就是為了讓你看一眼JDK的BUG導致的記憶體漏失。》
這篇文章就是從 ConcurrentLinkedQueue 佇列的一個 BUG 講起。jetty 框架裡面的執行緒池用到了這個佇列,導致了記憶體漏失。
同時通過 jconsole、VisualVM、jmc 這三個視覺化監控工具,讓你看見「記憶體漏失」的發生。
8062841: ConcurrentHashMap.computeIfAbsent stuck in an endless loop
《震驚!ConcurrentHashMap裡面也有死迴圈,作者留下的「彩蛋」瞭解一下?》
這個 BUG 在 Dubbo 和 Seata 裡面都有提到過,也被 Seata 官方的一篇部落格中被參照過:
https://seata.io/zh-cn/blog/seata-dsproxy-deadlock.html
8073704: FutureTask.isDone returns true when task has not yet completed
《Doug Lea在J.U.C包裡面寫的BUG又被網友發現了。》
這個 BUG 也是在 JDK 9 版本里面修復的,邏輯彎彎繞繞的,但是理解之後,對於 FutureTask 狀態流轉就能有一個比較深刻的認知了。有興趣可以看看。