跳躍表資料結構與演演算法分析
作者:京東物流 紀卓志
目前市面上充斥著大量關於跳躍表結構與Redis的原始碼解析,但是經過長期觀察後發現大都只是在停留在程式碼的表面,而沒有系統性地介紹跳躍表的由來以及各種常數的由來。作為一種概率資料結構,理解各種常數的由來可以更好地進行變化並應用到高效能功能開發中。本文沒有重複地以對現有優秀實現進行程式碼分析,而是通過對跳躍表進行了系統性地介紹與形式化分析,並給出了在特定場景下的跳躍表擴充套件方式,方便讀者更好地理解跳躍表資料結構。
跳躍表[1,2,3]是一種用於在大多數應用程式中取代平衡樹的概率資料結構。跳躍表擁有與平衡樹相同的期望時間上界,並且更簡單、更快、是用更少的空間。在查詢與列表的線性操作上,比平衡樹更快,並且更簡單。
概率平衡也可以被用在基於樹的資料結構[4]上,例如樹堆(Treap)。與平衡二元樹相同,跳躍表也實現了以下兩種操作
- 通過搜尋參照[5],可以保證從任意元素開始,搜尋到在列表中間隔為k的元素的任意期望時間是O(logk)
- 實現線性表的常規操作(例如_將元素插入到列表第k個元素後面_)
這幾種操作在平衡樹中也可以實現,但是在跳躍表中實現起來更簡單而且非常的快,並且通常情況下很難在平衡樹中直接實現(樹的線索化可以實現與連結串列相同的效果,但是這使得實現變得更加複雜[6])
預覽
最簡單的支援查詢的資料結構可能就是連結串列。Figure.1是一個簡單的連結串列。在連結串列中執行一次查詢的時間正比於必須考查的節點個數,這個個數最多是N。

Figure.1 Linked List
Figure.2表示一個連結串列,在該連結串列中,每個一個節點就有一個附加的指標指向它在表中的前兩個位置上的節點。正因為這個前向指標,在最壞情況下最多考查⌈N/2⌉+1個節點。

Figure.2 Linked List with fingers to the 2nd forward elements
Figure.3將這種想法擴充套件,每個序數是4的倍數的節點都有一個指標指向下一個序數為4的倍數的節點。只有⌈N/4⌉+2個節點被考查。

Figure.3 Linked List with fingers to the 4th forward elements
這種跳躍幅度的一般情況如Figure.4所示。每個2i節點就有一個指標指向下一個2i節點,前向指標的間隔最大為N/2。可以證明總的指標最大不會超過2N(見空間複雜度分析),但現在在一次查詢中最多考查⌈logN⌉個節點。這意味著一次查詢中總的時間消耗為O(logN),也就是說在這種資料結構中的查詢基本等同於二分查詢(binary search)。

Figure.4 Linked List with fingers to the 2ith forward elements
在這種資料結構中,每個元素都由一個節點表示。每個節點都有一個高度(height)或級別(level),表示節點所擁有的前向指標數量。每個節點的第i個前向指標指向下一個級別為i或更高的節點。
在前面描述的資料結構中,每個節點的級別都是與元素數量有關的,當插入或刪除時需要對資料結構進行調整來滿足這樣的約束,這是很呆板且低效的。為此,可以_將每個2i節點就有一個指標指向下一個2i節點_的限制去掉,當新元素插入時為每個新節點分配一個隨機的級別而不用考慮資料結構的元素數量。


Figure.5 Skip List
資料結構
到此為止,已經得到了所有讓連結串列支援快速查詢的充要條件,而這種形式的資料結構就是跳躍表。接下來將會使用更正規的方式來定義跳躍表
- 所有元素在跳躍表中都是由一個節點表示。
- 每個節點都有一個高度或級別,有時候也可以稱之為階(step),節點的級別是一個與元素總數無關的亂數。規定NULL的級別是∞。
- 每個級別為k的節點都有k個前向指標,且第i個前向指標指向下一個級別為i或更高的節點。
- 每個節點的級別都不會超過一個明確的常數MaxLevel。整個跳躍表的級別是所有節點的級別的最高值。如果跳躍表是空的,那麼跳躍表的級別就是1。
- 存在一個頭節點head,它的級別是MaxLevel,所有高於跳躍表的級別的前向指標都指向NULL。
稍後將會提到,節點的查詢過程是在頭節點從最高階別的指標開始,沿著這個級別一直走,直到找到大於正在尋找的節點的下一個節點(或者是NULL),在此過程中除了頭節點外並沒有使用到每個節點的級別,因此每個節點無需儲存節點的級別。
在跳躍表中,級別為1的前向指標與原始的連結串列結構中next指標的作用完全相同,因此跳躍表支援所有連結串列支援的演演算法。
對應到高階語言中的結構定義如下所示(後續所有程式碼範例都將使用C語言描述)
#define SKIP_LIST_KEY_TYPE int
#define SKIP_LIST_VALUE_TYPE int
#define SKIP_LIST_MAX_LEVEL 32
#define SKIP_LIST_P 0.5
struct Node {
SKIP_LIST_KEY_TYPE key;
SKIP_LIST_VALUE_TYPE value;
struct Node *forwards[]; // flexible array member
};
struct SkipList {
struct Node *head;
int level;
};
struct Node *CreateNode(int level) {
struct Node *node;
assert(level > 0);
node = malloc(sizeof(struct Node) + sizeof(struct Node *) * level);
return node;
}
struct SkipList *CreateSkipList() {
struct SkipList *list;
struct Node *head;
int i;
list = malloc(sizeof(struct SkipList));
head = CreateNode(SKIP_LIST_MAX_LEVEL);
for (i = 0; i < SKIP_LIST_MAX_LEVEL; i++) {
head->forwards[i] = NULL;
}
list->head = head;
list->level = 1;
return list;
}
從前面的預覽章節中,不難看出MaxLevel的選值影響著跳躍表的查詢效能,關於MaxLevel的選值將會在後續章節中進行介紹。在此先將MaxLevel定義為32,這對於232個元素的跳躍表是足夠的。延續預覽章節中的描述,跳躍表的概率被定義為0.5,關於這個值的選取問題將會在後續章節中進行詳細介紹。
演演算法
搜尋
在跳躍表中進行搜尋的過程,是通過Z字形遍歷所有沒有超過要尋找的目標元素的前向指標來完成的。在當前級別沒有可以移動的前向指標時,將會移動到下一級別進行搜尋。直到在級別為1的時候且沒有可以移動的前向指標時停止搜尋,此時直接指向的節點(級別為1的前向指標)就是包含目標元素的節點(如果目標元素在列表中的話)。在Figure.6中展示了在跳躍表中搜尋元素17的過程。

Figure.6 A search path to find element 17 in Skip List
整個過程的範例程式碼如下所示,因為高階語言中的陣列下標從0開始,因此forwards[0]表示節點的級別為1的前向指標,依此類推
struct Node *SkipListSearch(struct SkipList *list, SKIP_LIST_KEY_TYPE target) {
struct Node *current;
int i;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i] && current->forwards[i]->key < target) {
current = current->forwards[i];
}
}
current = current->forwards[0];
if (current->key == target) {
return current;
} else {
return NULL;
}
}
插入和刪除
在插入和刪除節點的過程中,需要執行和搜尋相同的邏輯。在搜尋的基礎上,需要維護一個名為update的向量,它維護的是搜尋過程中跳躍表每個級別上遍歷到的最右側的值,表示插入或刪除的節點的左側直接直接指向它的節點,用於在插入或刪除後調整節點所在所有級別的前向指標(與樸素的連結串列節點插入或刪除的過程相同)。
當新插入節點的級別超過當前跳躍表的級別時,需要增加跳躍表的級別並將update向量中對應級別的節點修改為head節點。
Figure.7和Figure.8展示了在跳躍表中插入元素16的過程。首先,在Figure.7中執行與搜尋相同的查詢過程,在每個級別遍歷到的最後一個元素在對應層級的前向指標被標記為灰色,表示稍後將會對齊進行調整。接下來在Figure.8中,在元素為13的節點後插入元素16,元素16對應的節點的級別是5,這比跳躍表當前級別要高,因此需要增加跳躍表的級別到5,並將head節點對應級別的前向指標標記為灰色。Figure.8中所有虛線部分都表示調整後的效果。

Figure.7 Search path for inserting element 16

Figure.8 Insert element 16 and adjust forward pointers
struct Node *SkipListInsert(struct SkipList *list, SKIP_LIST_KEY_TYPE key, SKIP_LIST_VALUE_TYPE value) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int i;
int level;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i] && current->forwards[i]->key < target) {
current = current->forwards[i];
}
update[i] = current;
}
current = current->forwards[0];
if (current->key == target) {
current->value = value;
return current;
}
level = SkipListRandomLevel();
if (level > list->level) {
for (i = list->level; i < level; i++) {
update[i] = list->header;
}
}
current = CreateNode(level);
current->key = key;
current->value = value;
for (i = 0; i < level; i++) {
current->forwards[i] = update[i]->forwards[i];
update[i]->forwards[i] = current;
}
return current;
}
在刪除節點後,如果刪除的節點是跳躍表中級別最大的節點,那麼需要降低跳躍表的級別。
Figure.9和Figure.10展示了在跳躍表中刪除元素19的過程。首先,在Figure.9中執行與搜尋相同的查詢過程,在每個級別遍歷到的最後一個元素在對應層級的前向指標被標記為灰色,表示稍後將會對齊進行調整。接下來在Figure.10中,首先通過調整前向指標將元素19對應的節點從跳躍表中解除安裝,因為元素19對應的節點是級別最高的節點,因此將其從跳躍表中移除後需要調整跳躍表的級別。Figure.10中所有虛線部分都表示調整後的效果。

Figure.9 Search path for deleting element 19

Figure.10 Delete element 19 and adjust forward pointers
struct Node *SkipListDelete(struct SkipList *list, SKIP_LIST_KEY_TYPE key) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int i;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i] && current->forwards[i]->key < key) {
current = current->forwards[i];
}
update[i] = current;
}
current = current->forwards[0];
if (current && current->key == key) {
for (i = 0; i < list->level; i++) {
if (update[i]->forwards[i] == current) {
update[i]->forwards[i] = current->forwards[i];
} else {
break;
}
}
while (list->level > 1 && list->head->forwards[list->level - 1] == NULL) {
list->level--;
}
}
return current;
}
生成隨機級別

int SkipListRandomLevel() {
int level;
level = 1;
while (random() < RAND_MAX * SKIP_LIST_P && level <= SKIP_LIST_MAX_LEVEL) {
level++;
}
return level;
}
以下表格為按上面演演算法執行232次後,所生成的隨機級別的分佈情況。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| 2147540777 | 1073690199 | 536842769 | 268443025 | 134218607 | 67116853 | 33563644 | 16774262 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 8387857 | 4193114 | 2098160 | 1049903 | 523316 | 262056 | 131455 | 65943 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 32611 | 16396 | 8227 | 4053 | 2046 | 1036 | 492 | 249 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 |
| 121 | 55 | 34 | 16 | 7 | 9 | 2 | 1 |
MaxLevel的選擇
在Figure.4中曾給出過對於10個元素的跳躍表最理想的分佈情況,其中5個節點的級別是1,3個節點的級別是2,1個節點的級別是3,1個節點的級別是4。
這引申出一個問題:既然相同元素數量下,跳躍表的級別不同會有不同的效能,那麼跳躍表的級別為多少才合適?

分析
空間複雜度分析
前面提到過,分數p代表節點同時帶有第i層前向指標和第i+1層前向指標的概率,而每個節點的級別最少是1,因此級別為i的前向指標數為npi−1。定義S(n)表示所有前向指標的總量,由等比數列求和公式可得
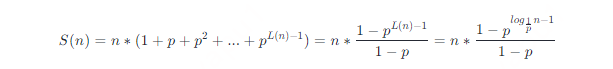
對S(n)求極限,有

易證,這是一個關於p的單調遞增函數,因此p的值越大,跳躍表中前向指標的總數越多。因為1−p是已知的常數,所以說跳躍表的空間複雜度是O(n)。
時間複雜度分析
非形式化分析

形式化分析

延續_分數p代表節點同時帶有第i層前向指標和第i+1層前向指標的概率_的定義,考慮反方向分析搜尋路徑。
搜尋的路徑總是小於必須執行的比較的次數的。首先需要考查從級別1(在搜尋到元素前遍歷的最後一個節點)爬升到級別L(n)所需要反向跟蹤的指標數量。雖然在搜尋時可以確定每個節點的級別都是已知且確定的,在這裡仍認為只有當整個搜尋路徑都被反向追蹤後才能被確定,並且在爬升到級別L(n)之前都不會接觸到head節點。
在爬升過程中任何特定的點,都認為是在元素x的第i個前向指標,並且不知道元素x左側所有元素的級別或元素x的級別,但是可以知道元素x的級別至少是i。元素x的級別大於i的概率是p,可以通過考慮視認為這個反向爬升的過程是一系列由成功的爬升到更高階別或失敗地向左移動的隨機獨立實驗。
在爬升到級別L(n)過程中,向左移動的次數等於在連續隨機試驗中第L(n)−1次成功前的失敗的次數,這符合負二項分佈。期望的向上移動次數一定是L(n)−1。因此可以得到無限列表中爬升到L(n)的代價C C=prob(L(n)−1)+NB(L(n)−1,p) 列表長度無限大是一個悲觀的假設。當反向爬升的過程中接觸到head節點時,可以直接向上爬升而不需要任何向左移動。因此可以得到n個元素列表中爬升到L(n)的代價C(n)
C(n)≤probC=prob(L(n)−1)+NB(L(n)−1,p)
因此n個元素列表中爬升到L(n)的代價C(n)的數學期望和方差為
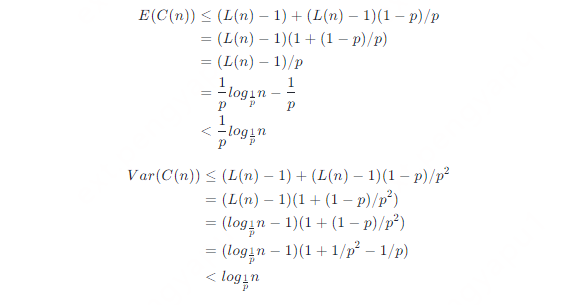
因為1/p是已知常數,因此跳躍表的搜尋、插入和刪除的時間複雜度都是O(logn)。
P的選擇

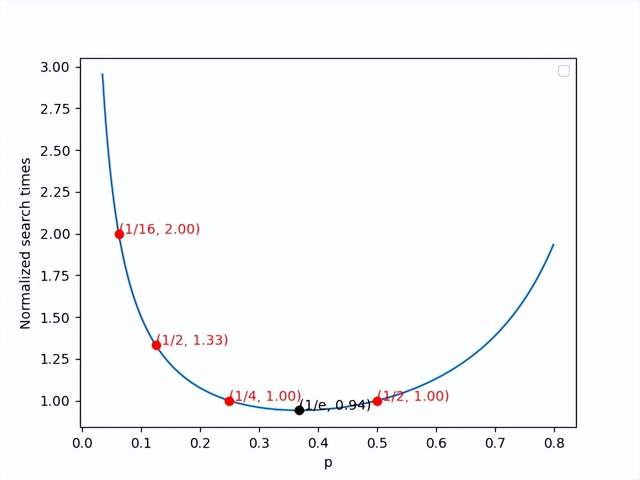
Figure.11 Normalized search times

擴充套件
快速隨機存取

#define SKIP_LIST_KEY_TYPE int
#define SKIP_LIST_VALUE_TYPE int
#define SKIP_LIST_MAX_LEVEL 32
#define SKIP_LIST_P 0.5
struct Node; // forward definition
struct Forward {
struct Node *forward;
int span;
}
struct Node {
SKIP_LIST_KEY_TYPE key;
SKIP_LIST_VALUE_TYPE value;
struct Forward forwards[]; // flexible array member
};
struct SkipList {
struct Node *head;
int level;
int length;
};
struct Node *CreateNode(int level) {
struct Node *node;
assert(level > 0);
node = malloc(sizeof(struct Node) + sizeof(struct Forward) * level);
return node;
}
struct SkipList *CreateSkipList() {
struct SkipList *list;
struct Node *head;
int i;
list = malloc(sizeof(struct SkipList));
head = CreateNode(SKIP_LIST_MAX_LEVEL);
for (i = 0; i < SKIP_LIST_MAX_LEVEL; i++) {
head->forwards[i].forward = NULL;
head->forwards[i].span = 0;
}
list->head = head;
list->level = 1;
return list;
}
接下來需要修改插入和刪除操作,來保證在跳躍表修改後跨度的資料完整性。
需要注意的是,在插入過程中需要使用indices記錄在每個層級遍歷到的最後一個元素的位置,這樣通過做簡單的減法操作就可以知道每個層級遍歷到的最後一個元素到新插入節點的跨度。
struct Node *SkipListInsert(struct SkipList *list, SKIP_LIST_KEY_TYPE key, SKIP_LIST_VALUE_TYPE value) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int indices[SKIP_LIST_MAX_LEVEL];
int i;
int level;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
if (i == list->level - 1) {
indices[i] = 0;
} else {
indices[i] = indices[i + 1];
}
while (current->forwards[i].forward && current->forwards[i].forward->key < target) {
indices[i] += current->forwards[i].span;
current = current->forwards[i].forward;
}
update[i] = current;
}
current = current->forwards[0].forward;
if (current->key == target) {
current->value = value;
return current;
}
level = SkipListRandomLevel();
if (level > list->level) {
for (i = list->level; i < level; i++) {
indices[i] = 0;
update[i] = list->header;
update[i]->forwards[i].span = list->length;
}
}
current = CreateNode(level);
current->key = key;
current->value = value;
for (i = 0; i < level; i++) {
current->forwards[i].forward = update[i]->forwards[i].forward;
update[i]->forwards[i].forward = current;
current->forwards[i].span = update[i]->forwards[i].span - (indices[0] - indices[i]);
update[i]->forwards[i].span = (indices[0] - indices[i]) + 1;
}
list.length++;
return current;
}
struct Node *SkipListDelete(struct SkipList *list, SKIP_LIST_KEY_TYPE key) {
struct Node *update[SKIP_LIST_MAX_LEVEL];
struct Node *current;
int i;
current = list->head;
for (i = list->level - 1; i >= 0; i--) {
while (current->forwards[i].forward && current->forwards[i].forward->key < key) {
current = current->forwards[i].forward;
}
update[i] = current;
}
current = current->forwards[0].forward;
if (current && current->key == key) {
for (i = 0; i < list->level; i++) {
if (update[i]->forwards[i].forward == current) {
update[i]->forwards[i].forward = current->forwards[i];
update[i]->forwards[i].span += current->forwards[i].span - 1;
} else {
break;
}
}
while (list->level > 1 && list->head->forwards[list->level - 1] == NULL) {
list->level--;
}
}
return current;
}
當實現了快速隨機存取之後,通過簡單的指標操作即可實現區間查詢功能。
參考文獻
- Pugh, W. (1989). A skip list cookbook. Tech. Rep. CS-TR-2286.1, Dept. of Computer Science, Univ. of Maryland, College Park, MD [July 1989]
- Pugh, W. (1989). Skip lists: A probabilistic alternative to balanced trees. Lecture Notes in Computer Science, 437–449. https://doi.org/10.1007/3-540-51542-9_36
- Weiss, M. A. (1996).Data Structures and Algorithm Analysis in C (2nd Edition)(2nd ed.). Pearson.
- Aragon, Cecilia & Seidel, Raimund. (1989). Randomized Search Trees. 540-545. 10.1109/SFCS.1989.63531.
- Wikipedia contributors. (2022b, November 22).Finger search. Wikipedia. https://en.wikipedia.org/wiki/Finger_search
- Wikipedia contributors. (2022a, October 24).Threaded binary tree. Wikipedia. https://en.wikipedia.org/wiki/Threaded_binary_tree
- Wikipedia contributors. (2023, January 4).Negative binomial distribution. Wikipedia. https://en.wikipedia.org/wiki/Negative_binomial_distribution
- Redis contributors.Redis ordered set implementation. GitHub. https://github.com/redis/redis
後續工作
- 確定性跳躍表
- 無鎖並行安全跳躍表