Curve 檔案儲存在 Elasticsearch 冷熱資料儲存中的應用實踐
Elasticsearch在生產環境中有廣泛的應用,本文介紹一種方法,基於網易數帆開源的Curve檔案儲存,實現Elasticsearch儲存成本、效能、容量和運維方面的顯著提升。
ES 使用 CurveFS 的四大收益
1.CurveFS提供的成本優勢
為了高可靠,ES如果使用本地盤的話一般會使用兩副本,也就是說儲存1PB資料需要2PB的物理空間。但是如果使用CurveFS,由於CurveFS的後端可以對接S3,所以可以利用物件儲存提供的EC能力,既保證了可靠性,又可以減少副本數量,從而達到了降低成本的目的。
以網易物件儲存這邊當前主流的EC 20+4使用為例,該使用方式就相當於是1.2副本。所以如果以ES需要1PB使用空間為例,那麼使用CurveFS+1.2副本物件儲存只需要1.2PB空間,相比本地盤2副本可以節省800TB左右的容量,成本優化效果非常顯著。
2.CurveFS提供的效能優勢
以下文將要介紹的使用場景為例,對比ES原來使用S3外掛做snapshot轉儲存的方式,由於每次操作的時候索引需要進行restore操作,以100G的紀錄檔索引為例,另外會有傳輸時間,如果restore的恢復速度為100M,那麼也要300多秒。實際情況是在一個大量寫入的叢集,這樣的操作可能要幾個小時。
而使用CurveFS後的新模式下基本上只要對freeze的索引進行unfreeze,讓對應節點的ES將對應的meta資料載入記憶體就可以執行索引,大概耗時僅需30S左右,相比直接用S3儲存冷資料有數量級的下降。
3.CurveFS提供的容量優勢
本地盤的容量是有限的,而CurveFS的空間容量可以線上無限擴充套件。同時減少了本地儲存的維護代價。
4.CurveFS提供的易運維優勢
ES使用本地盤以及使用S3外掛方式,當需要擴容或者節點異常恢復時,需要增加人力運維成本。CurveFS實現之初的一個目標就是易運維,所以CurveFS可以實現數條命令的快速部署以及故障自愈能力。
另外如果ES使用CurveFS,就實現了存算分離,進一步釋放了ES使用者的運維負擔。
選用 CurveFS 的原因
背景: 在生產環境有大量的場景會用到ES做檔案、紀錄檔儲存後端,因為ES優秀的全文檢索能力在很多時候可以大大的簡化相關係統設計的複雜度。比較常見的為紀錄檔儲存,鏈路追蹤,甚至是監控指標等場景都可以用ES來做。
本地盤到 MinIO
為了符合國內的法律約束,線上系統需要按照要求儲存6個月到1年不等的系統紀錄檔,主要是國內等保、金融合規等場景。按照內部管理的伺服器數量,單純syslog的紀錄檔儲存空間每天就需要1T,按照當前手頭有的5臺12盤位4T硬碟的伺服器,最多隻能儲存200多天的日子,無法滿足紀錄檔儲存1年的需求。
針對ES使用本地盤無法滿足儲存容量需求這一情況,網易ES底層儲存之前單獨引入過基於S3的儲存方案來降低儲存空間的消耗。如下圖,ES配合minio做資料儲存空間的壓縮。舉例來說100G的紀錄檔,到了ES裡面因為可靠性需求,需要雙副本,會使用200G的空間。ES針對索引分片時間,定期性轉儲存到minio倉庫。

MinIO 到 CurveFS
這個方案從一定程度上緩解了儲存空間的資源問題,但是實際使用的時候還會感覺非常不便利。
- 運維成本。ES節點升級的時候需要額外解除安裝安裝S3外掛,有一定的運維成本。
- 效能瓶頸。自己私有化搭建的Minio隨著bucket裡面資料量的增長,資料儲存和抽取都會成為一個很大的問題
- 穩定性問題。在內部搭建的Minio叢集在做資料restore的時候,因為檔案處理效能等因素,經常遇到存取超時等場景,所以一直在關注是否有相關的系統可以提供更好的讀寫穩定性。
由於S3協定經過多年的演化,已經成了物件儲存的工業標準。很多人都有想過用fuse的方式使用S3的儲存能力。事實上基於S3的檔案系統有很多款,例如開源的s3fs-fuse、ossfs、RioFS、CurveFS等。
在通過實際調研以及大量的測試後,基於Curve的效能(尤其是後設資料方面,CurveFS是基於RAFT一致性協定自研的後設資料引擎,與其他沒有後設資料引擎的S3檔案系統(比如s3fs,ossfs)相比具備巨大的效能優勢),易運維,穩定性,Curve可以同時提供塊儲存以及檔案儲存能力等能力以及Curve活躍的開源氛圍,最終選用了CurveFS。
CurveFS 結合 ES 的實踐
CurveFS簡介
CurveFS是一個基於 Fuse實現的相容POSIX 介面的分散式檔案系統,架構如下圖所示:
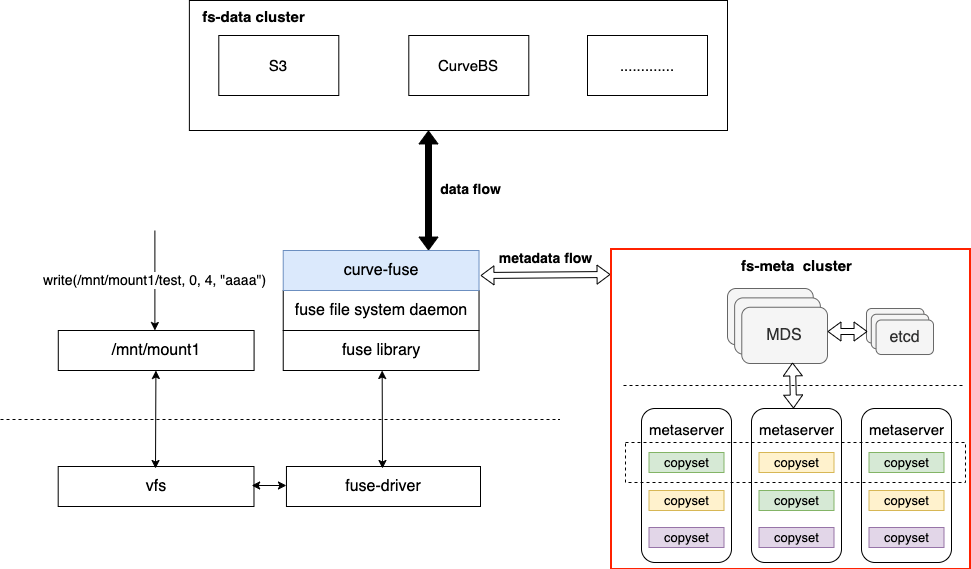
CurveFS由三個部分組成:
-
使用者端curve-fuse,和後設資料叢集互動處理檔案後設資料增刪改查請求,和資料叢集互動處理檔案資料的增刪改查請求。
-
後設資料叢集metaserver cluster,用於接收和處理後設資料(inode和dentry)的增刪改查請求。metaserver cluster的架構和CurveBS類似,具有高可靠、高可用、高可擴的特點:MDS用於管理叢集拓撲結構,資源排程。metaserver是資料節點,一個metaserver對應管理一個物理磁碟。CurveFS使用Raft保證後設資料的可靠性和可用性,Raft複製組的基本單元是copyset。一個metaserver上包含多個copyset複製組。
-
資料叢集data cluster,用於接收和處理檔案資料的增刪改查。data cluster目前支援兩儲存型別:支援S3介面的物件儲存以及CurveBS(開發中)。
Curve除了既能支援檔案儲存,也能支援塊儲存之外,從上述架構圖我們還能看出Curve的一個特點:就是CurveFS後端既可以支援S3,也可以支援Curve塊儲存。這樣的特點可以使得使用者可以選擇性地把效能要求高的系統的資料儲存在Curve塊儲存後端,而對成本要求較高的系統可以把資料儲存在S3後端。
ES使用CurveFS
CurveFS定位於網易運維的雲原生系統,所以其部署是簡單快速的,通過CurveAdm工具,只需要幾條命令便可以部署起CurveFS的環境,具體部署見[1][2];部署後效果如下圖:

在紀錄檔儲存場景,改造是完全基於歷史的伺服器做的線上改造。下圖是線上紀錄檔的一個儲存架構範例,node0到node5可以認為是熱儲存節點,機器為12*4T,128G的儲存機型,每個節點跑3個ES範例,每個範例32G記憶體,4塊獨立盤。node6到node8為12*8T的儲存機型,3臺伺服器跑一個Minio叢集,每臺機器上的ES範例不做資料本地寫。
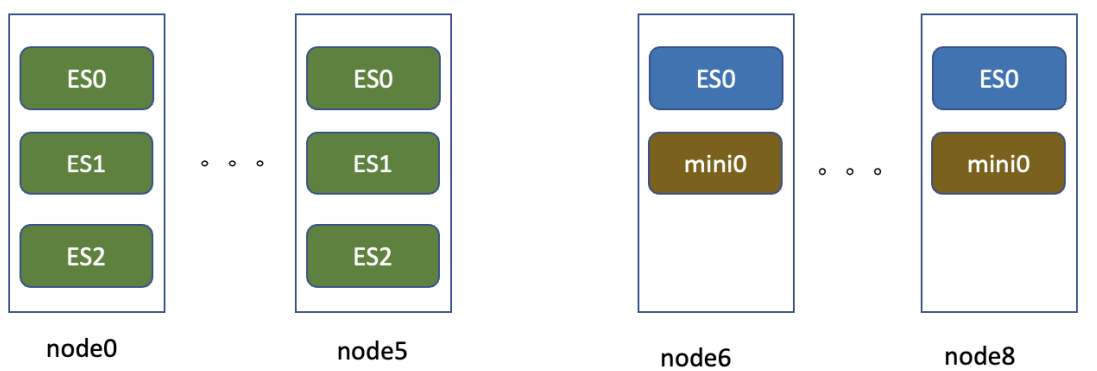
可以看到主要的改造重點是將node6到node8,3個節點進行ES的設定改造,其中以node6節點的設定為例:
cluster.name: ops-elk
node.name: ${HOSTNAME}
network.host: [_local_,_bond0_]
http.host: [_local_]
discovery.zen.minimum_master_nodes: 1
action.auto_create_index: true
transport.tcp.compress: true
indices.fielddata.cache.size: 20%
path.data: /home/nbs/elk/data1/data
path.logs: /home/nbs/elk/data1/logs
- /curvefs/mnt1
xpack.ml.enabled: false
xpack.monitoring.enabled: false
discovery.zen.ping.unicast.hosts: ["ops-elk1:9300","ops-elk7:9300","ops-elk
7:9300","ops-elk8.jdlt.163.org:9300"]
node.attr.box_type: cold
如設定所示,主要的改造為調整ES的資料儲存目錄到CurveFS的fuse掛載目錄,然後新增 node.attr.box_type 的設定。在node6到node8上分別設定為cold,node1到node5設定對應屬性為hot,所有節點設定完成後進行一輪捲動重啟。
ES設定
除了底層設定外,很重要的一點就是調整index索引的設定。這塊的設定難度不高,要點是:
- 對應索引設定資料分配依賴和aliases
- 設定對應的index Lifecycle policy
其實在新節點開放資料儲存後,如果沒有親和性設定,叢集馬上會啟動relocating操作。因此建議對存量的索引新增routing.alloction.require的設定來避免熱資料分配到CurveFS儲存節點。針對每天新增索引,建議加入以下這樣的index template設定。
{
"template": {
"settings": {
"index": {
"lifecycle": {
"name": "syslog",
"rollover_alias": "syslog"
},
"routing": {
"allocation": {
"require": {
"box_type": "hot"
}
}
},
"number_of_shards": "10",
"translog": {
"durability": "async"
}
}
},
"aliases": {
"syslog": {}
},
"mappings": {}
}
}
這個index template設定的核心要點:
- routing部分要指定新索引寫到熱資料節點
- lifecycle中的新增rollover_alias設定
index部分的lifecycle是指索引的生命週期策略,需要注意rollover_alias裡面的值要和下面的aliases定義對齊。
冷資料的切換,可以在kibana的index_lifecycle_management管理頁面設定。針對上面的syslog場景,hot部分設定如下圖,其餘基本預設的就可以了。
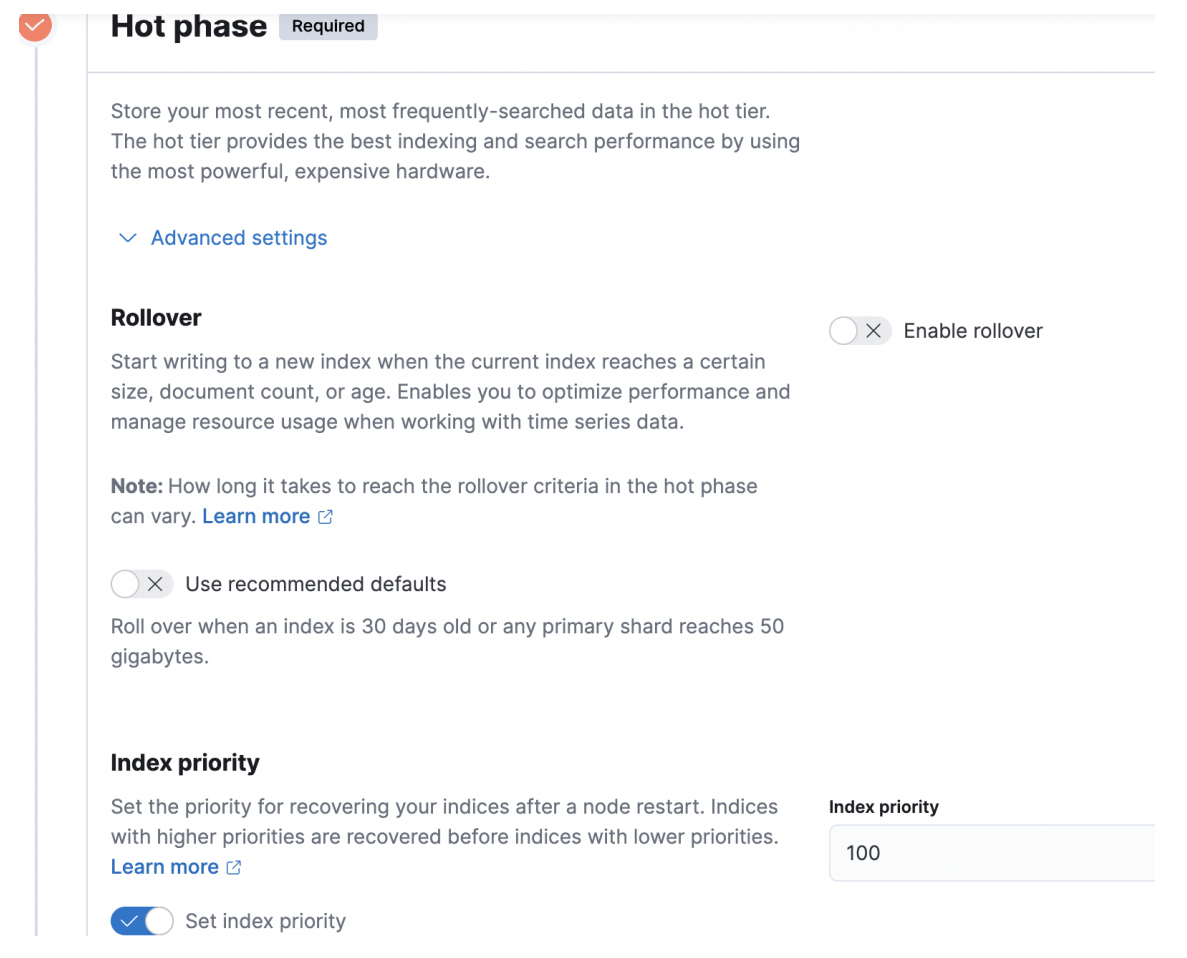
在索引週期管理設定頁面中,除了設定hot phase,還可以設定warm phase,在warm phase可以做一些shrink,force merge等操作,紀錄檔儲存場景我們直接做hot到cold的處理邏輯。
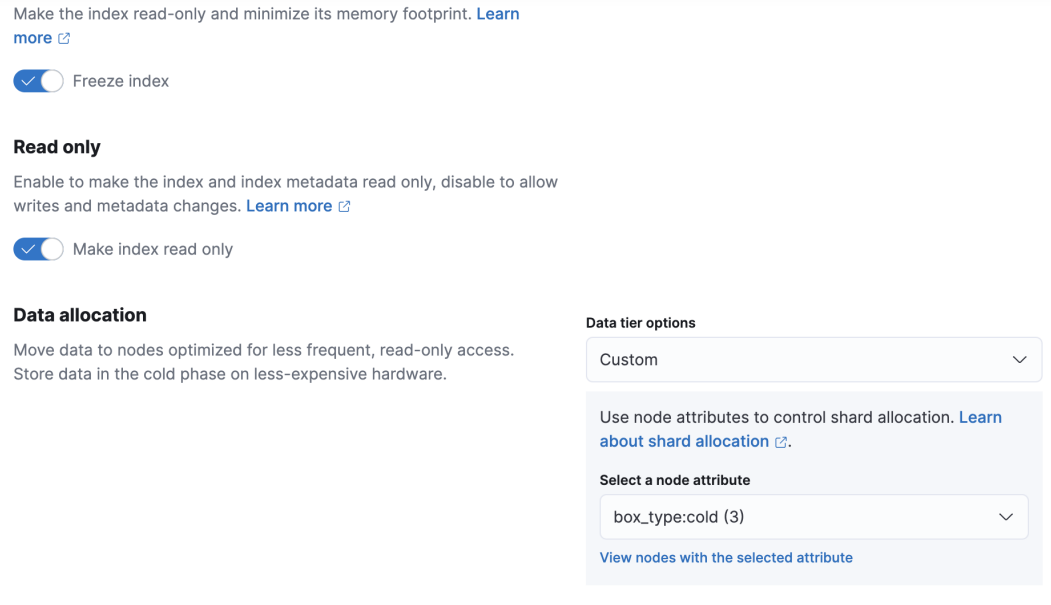
從技術上講,紀錄檔儲存型別的業務,底層索引一旦完成寫後基本不做再次的資料更改,設定索引副本數量主要是為了應對分散式系統節點宕機等異常場景的資料恢復。如果儲存層面有更可靠的方式,那麼自然而然可以將es的副本數量調整為0。因此杭研雲端計算儲存團隊研發的一款基於S3後端的儲存檔案系統CurveFS,自然而然進入了冷資料選型的視野。從技術上講內部S3儲存基於EC糾刪碼的實現,通過降低ES的副本數量為0,可以明顯的降低對儲存空間的使用需求。
後續規劃
與 Curve 社群小夥伴溝通後,社群在 CurveFS 在存算分離方向的後續規劃為:
- Curve檔案儲存後端完全支援Curve塊儲存,滿足一些場景下對效能的需求。預計2023 Q1釋出。
- Curve檔案儲存支援生命週期管理,支援使用者自定義資料冷熱,資料按需儲存在不同叢集中。預計2023 Q2釋出。
- Curve完全支援雲原生部署。當前使用者端已經支援CSI,叢集的部署支援預計2023 Q2釋出。
參考資料
[1]:https://github.com/opencurve/curveadm/wiki/curvefs-cluster-deployment
[2]:https://github.com/opencurve/curveadm/wiki/curvefs-client-deployment
本文作者
顧賢傑,網易系統運維專家,杭研SA&SRE團隊負責人
吳宏鬆,Curve Maintainer