elasticsearch實現基於拼音搜尋
1、背景
一般情況下,有些搜尋需求是需要根據拼音和中文來搜尋的,那麼在elasticsearch中是如何來實現基於拼音來搜尋的呢?可以通過elasticsearch-analysis-pinyin分析器來實現。
2、安裝拼音分詞器
# 進入 es 的外掛目錄
cd /usr/local/es/elasticsearch-8.4.3/plugins
# 下載
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v8.4.3/elasticsearch-analysis-pinyin-8.4.3.zip
# 新建目錄
mkdir analysis-pinyin
# 解壓
mv elasticsearch-analysis-pinyin-8.4.3.zip analysis-pinyin && cd analysis-pinyin && unzip elasticsearch-analysis-pinyin-8.4.3.zip && rm -rvf elasticsearch-analysis-pinyin-8.4.3.zip
cd ../ && chown -R es:es analysis-pinyin
# 啟動es
/usr/local/es/elasticsearch-8.4.3/bin/elasticsearch -d
3、拼音分詞器提供的功能
拼音分詞器提供如下功能

每個選項的含義 可以通過 檔案中的例子來看懂。
4、簡單測試一下拼音分詞器
4.1 dsl
GET _analyze
{
"text": ["我是中國人"],
"analyzer": "pinyin"
}
"analyzer": "pinyin" 此處的pinyin是拼音分詞器自帶的。
4.2 執行結果

從圖片上,實現了拼音分詞,但是這個不一定滿足我們的需求,比如沒有中文了,單個的拼音(比如:wo)是沒有什麼用的,需要對拼音分詞器進行客製化化。
5、es中分詞器的組成
在elasticsearch中分詞器analyzer由如下三個部分組成:
character filters:用於在tokenizer之前對文字進行處理。比如:刪除字元,替換字元等。tokenizer:將文字按照一定的規則分成獨立的token。即實現分詞功能。tokenizer filter:將tokenizer輸出的詞條做進一步的處理。比如:同義詞處理,大小寫轉換、移除停用詞,拼音處理等。
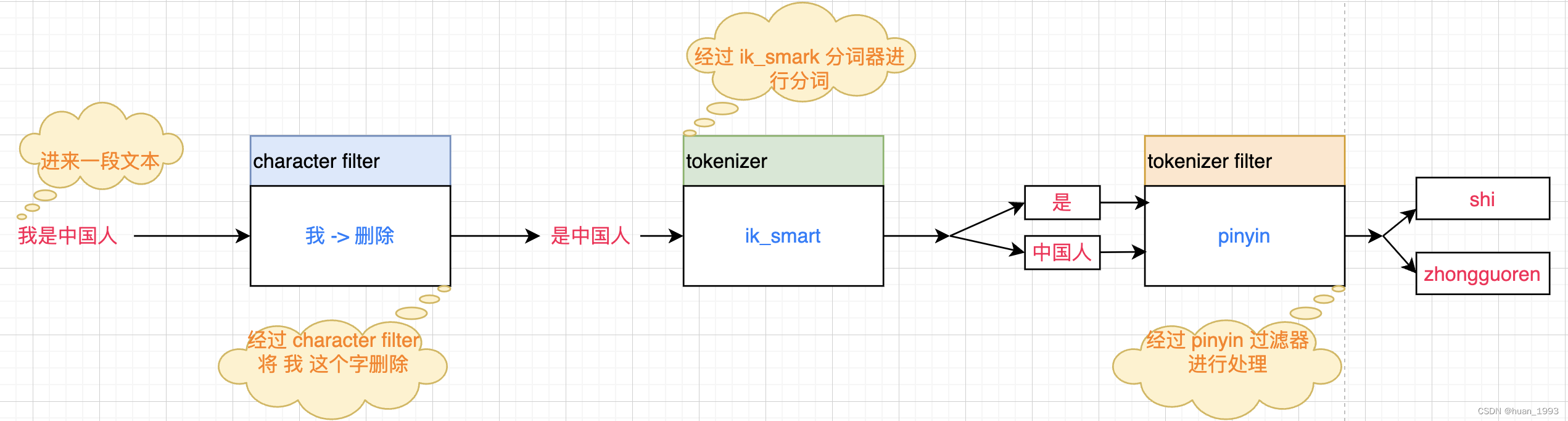
6、自定義一個分詞器實現拼音和中文的搜尋
需求: 自定義一個分詞器,即可以實現拼音搜尋,也可以實現中文搜尋。
1、建立mapping
PUT /test_pinyin
{
"settings": {
// 分析階段的設定
"analysis": {
// 分析器設定
"analyzer": {
// 自定義分析器,在tokenizer階段使用ik_max_word,在filter上使用py
"custom_analyzer": {
"tokenizer": "ik_max_word",
"filter": "custom_pinyin"
}
},
// 由於不滿足pinyin分詞器的預設設定,所以我們基於pinyin
// 自定義了一個filter,叫py,其中修改了一些設定
// 這些設定可以在pinyin分詞器官網找到
"filter": {
"custom_pinyin": {
"type": "pinyin",
// 不會這樣分:劉德華 > [liu, de, hua]
"keep_full_pinyin": false,
// 這樣分:劉德華 > [liudehua]
"keep_joined_full_pinyin": true,
// 保留原始token(即中文)
"keep_original": true,
// 設定first_letter結果的最大長度,預設值:16
"limit_first_letter_length": 16,
// 當啟用此選項時,將刪除重複項以儲存索引,例如:de的> de,預設值:false,注意:位置相關查詢可能受影響
"remove_duplicated_term": true,
// 如果非漢語字母是拼音,則將其拆分為單獨的拼音術語,預設值:true,如:liudehuaalibaba13zhuanghan- > liu,de,hua,a,li,ba,ba,13,zhuang,han,注意:keep_none_chinese和keep_none_chinese_together應首先啟用
"none_chinese_pinyin_tokenize": false
}
}
}
},
// 定義mapping
"mappings": {
"properties": {
"name": {
"type": "text",
// 建立倒排索引時使用的分詞器
"analyzer": "custom_analyzer",
// 搜尋時使用的分詞器,搜尋時不使用custom_analyzer是為了防止 詞語的拼音一樣,但是中文含義不一樣,導致搜尋錯誤。 比如: 科技 和 客機,拼音一樣,但是含義不一樣
"search_analyzer": "ik_smart"
}
}
}
}
注意:
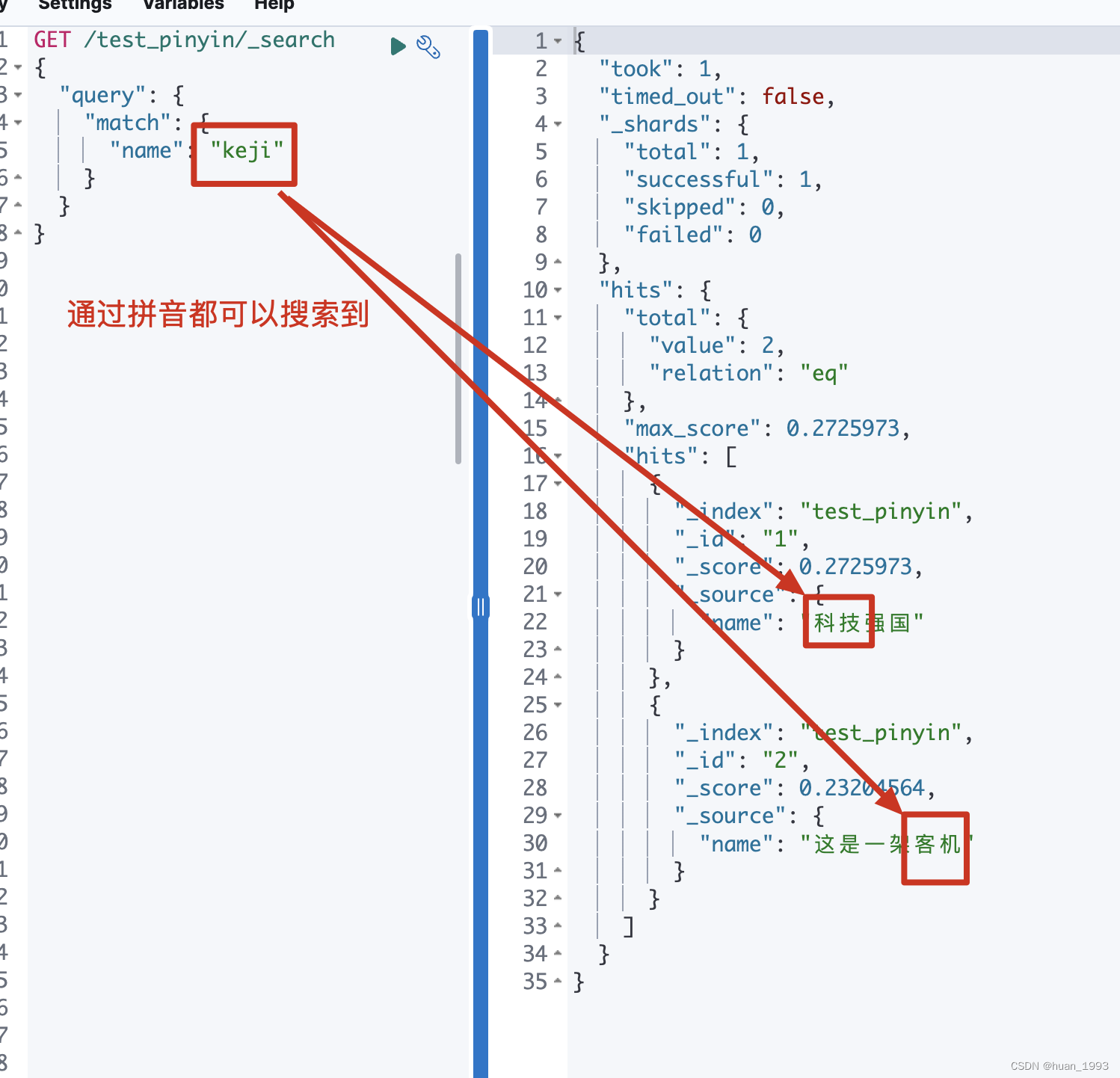
可以看到 我們的 name欄位 使用的分詞器是 custom_analyzer,這個是我們在上一步定義的。但是搜尋的時候使用的是 ik_smart,這個為甚麼會這樣呢?
假設我們存在如下2個文字 科技強國和 這是一架客機, 那麼科技和客機的拼音是不是就是一樣的。 這個時候如果搜尋時使用的分詞器也是custom_analyzer那麼,搜尋科技的時候客機也會搜尋出來,這樣是不對的。因此在搜尋的時候中文就以中文搜,拼音就以拼音搜。
{
"name": {
"type": "text",
"analyzer": "custom_analyzer",
"search_analyzer": "ik_smart"
}
}
當 analyzer和search_analyzer的值都是custom_analyzer,搜尋時也會通過拼音搜尋,這樣的結果可能就不是我們想要的。
2、插入資料
PUT /test_pinyin/_bulk
{"index":{"_id":1}}
{"name": "科技強國"}
{"index":{"_id":2}}
{"name": "這是一架客機"}
{"index":{"_id":3}}
3、搜尋資料
7、參考檔案
1、https://github.com/medcl/elasticsearch-analysis-pinyin/tree/master
本文來自部落格園,作者:huan1993,轉載請註明原文連結:https://www.cnblogs.com/huan1993/p/17053317.html