國家圖書館,學習流式計算是種怎樣的體驗
有點懷念起北京來。
史鐵生小說裡的地壇,滿山楓葉的香山,如詩如畫的頤和園,美侖美奐的天壇 , 很多景點都讓我流連忘返。
在我心裡,有一處很神聖的地方,它是知識和希望的象徵,那就是國家圖書館 。
一段在國家圖書館學習流式計算的經歷 ,就如同刀刻斧鑿一般,刻在我的腦中 。
寫這篇文章,想和大家聊聊這段學習流式計算的經歷,希望對大家有所啟發。
1 國圖知識點
中國國家圖書館位於北京市中關村南大街33號,與海淀區白石橋高粱河、紫竹院公園相鄰。它是國家總書庫,國家書目中心,國家古籍保護中心,同時也是世界最大、最先進的國家圖書館之一 。
中國國家圖書館前身是籌建於1909年9月9日的京師圖書館,1931年,文津街館舍落成(現為國家圖書館古籍館)。新中國成立後,更名為北京圖書館。1987年新館落成,1998年12月12日經國務院批准,北京圖書館更名為國家圖書館,對外稱中國國家圖書館。
中國國家圖書館總建築面積28萬平方米,圖書館分為總館南區、總館北區和古籍館,館藏文獻3768.62萬冊,其中古籍文獻近200萬冊,數位資源總量超過1000 TB,是亞洲規模最大的圖書館,居世界國家圖書館第三位。

每到週末,當我想安靜下來,專注思考時,我就會揹著筆記型電腦來到國家圖書館。
選擇自己喜歡的書,然後將筆記型電腦開啟,一邊看書,一邊在電腦上寫點筆記。
偶爾擡起頭,望著那些正在閱讀的讀者,心裡面感覺很陽關,覺得生命充滿了希望。
2 優惠券計算服務
2014年,我在藝龍旅行網促銷團隊負責紅包系統。彼時,促銷大戰如火如荼,優惠券計算服務也成為藝龍業務系統中最重要的系統之一。
而優惠券計算服務正是採用當時大名鼎鼎的流式計算框架 Storm。
何為流式計算 ?
流式計算是利用分散式的思想和方法,對海量「流」式資料進行實時處理的系統,它源自對海量資料「時效」價值上的挖掘訴求。
優惠券計算服務的邏輯是:每個城市每個酒店的使用優惠券的規則並不相同,當運營人員修改規則之後,觸發優惠券計算服務,計算完成之後,使用者下單時在使用優惠券時會呈現最新的規則。
優惠券計算服務是我們團隊的明星專案,很多研發的同學都對 Storm 特別感興趣 , 因為 Storm 的核心開發語言是 clojure , 比較小眾。
於是,在團隊內部,發現一個很有趣的現象:很多同學的辦公桌上放著《clojure in Action 》這本書。

彼時,藝龍開始發力行動網際網路,業務量的激增,優惠券計算服務遇到了瓶頸。
比如運營人員修改全量規則時,整個計算流程要耗時一上午,也就談不上實時計算了。
CTO 幾次找團隊負責人,並嚴厲批責成他儘快優化。
沒想到,經過一個半月幾次優化,系統的瓶頸依然明顯,時不時運營同事會走到我們的工位附近,催促我們:「系統生效了麼? 」
每到這個時候,我都感到很疑惑:「難道優惠券計算服務真的那麼複雜嗎? Storm 框架真的那麼難以維護麼? 」
3 國圖學習Storm
想要揭開 Storm 神祕面紗的探索欲,同時解決公司技術問題的渴望,讓我好幾天晚上沒睡好。
於是週六上午9點半, 我揹著筆記型電腦來到國家圖書館。
學習一門技術,首先需要了解 Storm 的整體概念。
當我在官網上看到 Storm 的邏輯流程圖時, 做為程式設計師,我第一次感覺到抽象之美。
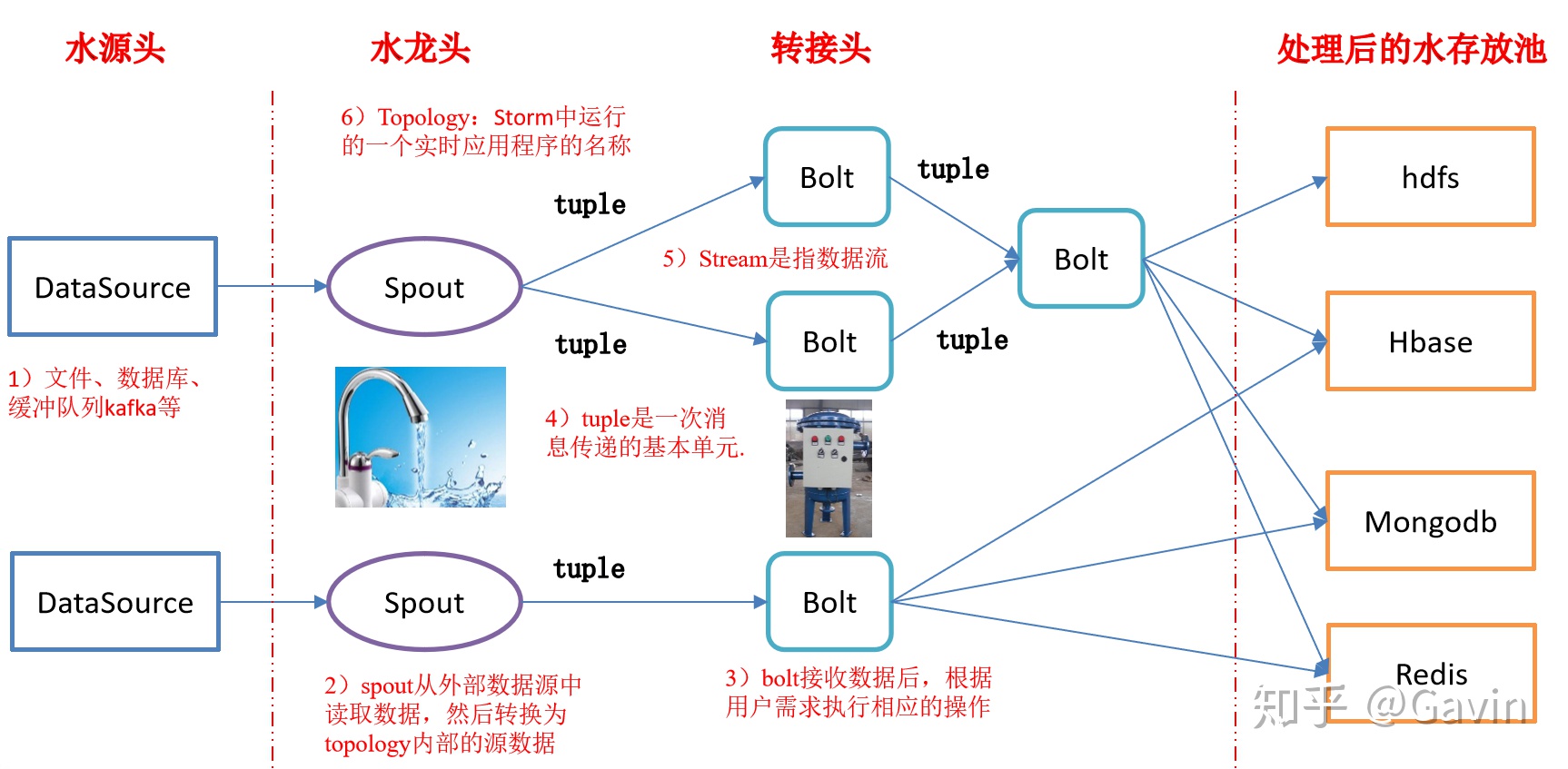
從源頭流下來的水通過水龍頭( Spout ),再經過層層轉接頭( Bolt )過濾,不就是我們想要的純淨水嗎?
當我瞭解了 Storm 整體概念 , 下一步也就是大家熟知的寫 Hello World 階段了 。
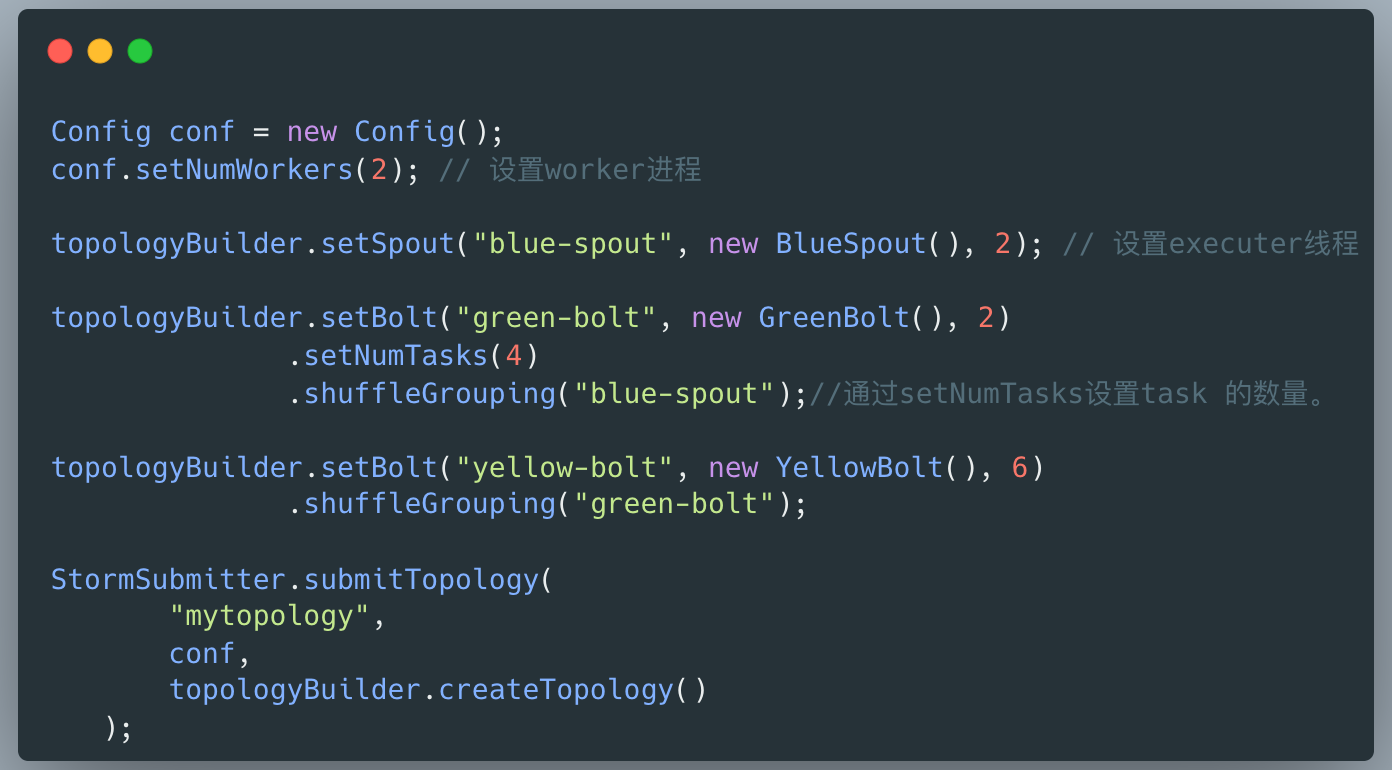
我參考教學寫了一個簡單的 Storm 應用(簡稱:拓撲),在部署後,程式正常跑了起來。
我腦海裡一直有一個概念:「是不是優惠券計算服務的 storm 叢集的設定沒有調優,導致計算的效能太差 ? 」 所以我必須去理解 storm 的並行度是如何計算的。
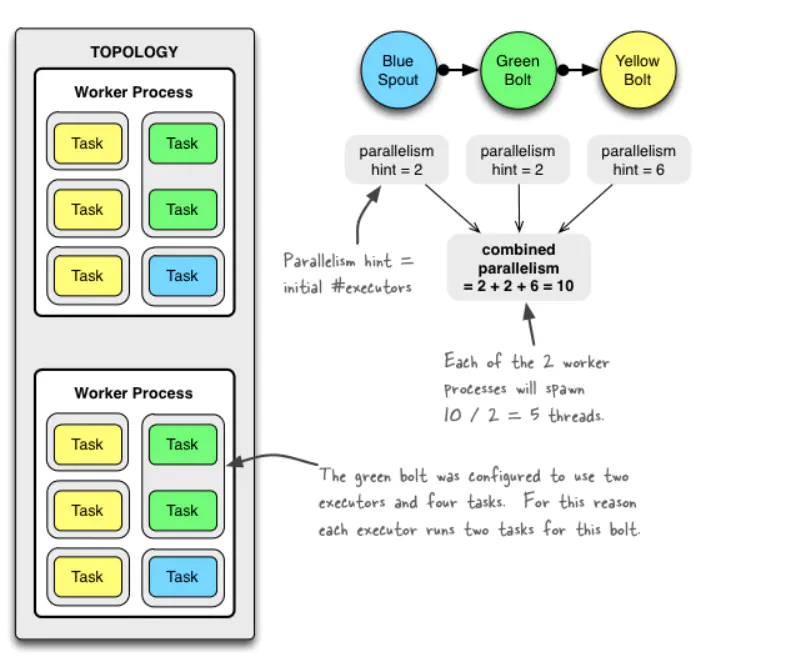
整個下午,我一直在查閱相關的資料,並結合上圖思考:Nimbus, Supervisor ,Worker ,Task 這些名詞到底是什麼概念。拓撲到底會啟動幾個程序,每個程序內部執行緒模型是怎樣的,頗有些庖丁解牛的味道。
等天色已黑,我走出國圖的大門,內心裡面,有莫名的自信,我相信自己可以解決優惠券計算服務的問題了。
感覺自己就像仙劍奇俠傳裡的酒劍仙,伴隨著激昂的 BGM ,拔劍四顧,斬妖除魔。
御劍乘風來,除魔天地間,有酒樂逍遙,無酒我亦癲。
一飲盡江河,再飲吞日月,千杯醉不倒,唯我酒劍仙。
4 推動重構優化
雖然我大體瞭解了 Storm 的機制,但是我還不太瞭解優惠券計算服務整體邏輯,所以我必須梳理流式計算的整體流程。
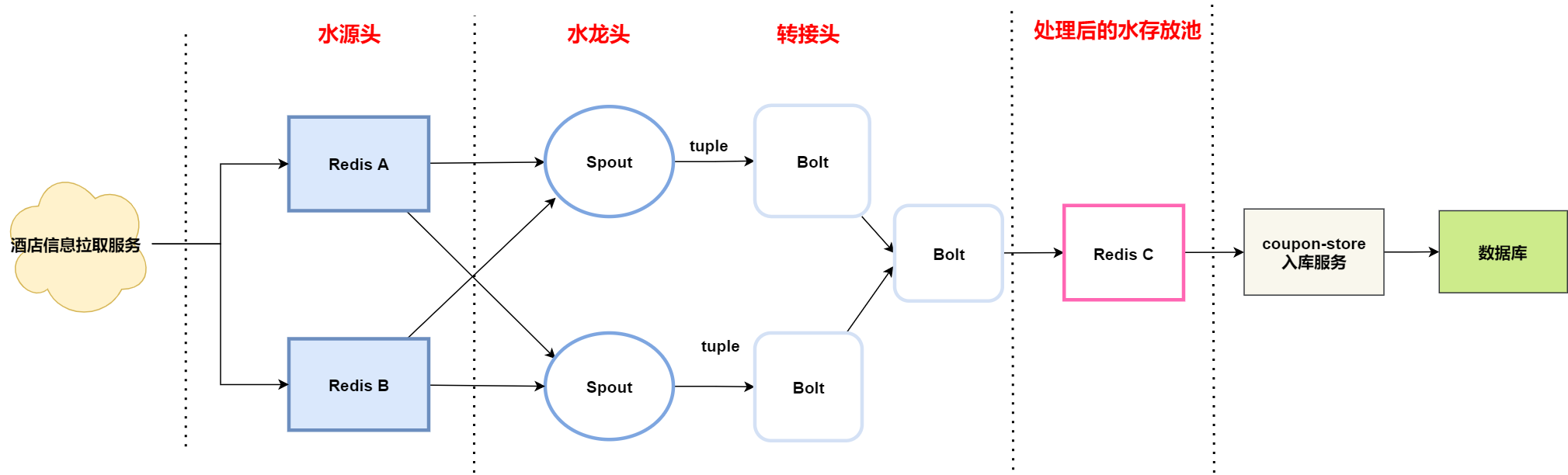
流式計算整體流程分為三個步驟 :
- 酒店資訊拉取服務拉取酒店資訊,並儲存到水源頭( Redis A/B 叢集 ) ;
- Storm 拓撲從水源頭獲取酒店資料,通過運營設定的規則對資料進行清洗 ,將計算好的資料儲存到水存放池 ( Redis C 叢集) ;
- 入庫服務從水存放池獲取資料,將計算結果儲存到資料庫 。
我找到負責優惠券計算服務的同事,匯出相關紀錄檔。
分析紀錄檔後,令人驚奇的是:一次全量計算需要耗時4個小時,但步驟1竟然需要2個多小時,因為我們需要找到效能最薄弱的點,攻堅解決。那麼應該優先優化酒店拉取服務。
之所以拉取慢,是因為它的執行緒模型不夠好,部署多個節點,每個節點只能有兩個執行緒執行拉取任務。而且老程式碼年久失修,維護成本頗高,於是和團隊負責人溝通後,我決定重構該服務。
在重構工程裡,我必須做到如下兩點:
- 拉取服務可水平擴充套件,若效能不足時,增加服務節點即可提升效能;
- 組態檔可設定 worker 數量。
因為 RocketMQ 剛開源不久 , 我將 RocketMQ 如何建立執行緒的知識點正好也用了上去。
這次重構也非常成功,我們將原來的老服務替換後,部署了3個節點, 每個節點8個 worker 並行拉取酒店資訊 。
驚喜的發現,原來需要4個小時的全量處理時間縮短成了1個半小時,看來我這次重構非常成功,而且沒有出現一例 BUG 。
優化結束了嗎? 沒有,當步驟1優化後,我們還有步驟2,步驟3可以優化。
在閱讀優惠券計算服務的程式碼中,我發現兩個問題:
- 流式計算邏輯中有大量網路 IO 請求,主要是查詢特定的酒店資料,用於後續計算;
- 每次計算時需要查詢基礎設定資料,它們都是從資料庫中獲取。
我提了兩點建議:
- 流式計算和酒店拉取服務各司其職,將流式計算中的網路 IO 請求挪到酒店拉取服務,將資料前置準備好;
- 基礎設定快取化,引入讀寫鎖(也是 RocketMQ 名字服務的技巧)。
步驟三也並行進行,一位研發同學將原來的單條資料入庫修改成批次入庫。
當所有的優化完成後,原來4個小時的全量計算已經縮短成四十多分鐘了。 以後,運營小姐姐就很少來我們工位了。(^-^)V
5 寫到最後
我至今都記得 :
當我第一次看到 Storm 的邏輯圖時,感嘆中介軟體設計的抽象之美 ;
當我走出國圖門口,那麼的意氣風發,那麼的捨我其誰 ,我就是酒劍仙,御劍乘風來,除魔天地間 ,那些技術問題算什麼,我一一給你們剷除;
當我和技術負責人保證我可以解決這個問題時,他不情願和難以置信的表情;
當我和同事做酒店拉取服務 Code Review 時,當講到如何建立執行緒時,同事們目瞪口呆的表情,我暗自竊喜:那是我學習 RocketMQ 的效果;
當酒店拉取服務上線後,全量資料計算的時間從4個小時變成1個半小時,我興奮著拍著桌子,旁邊的同事都神奇的看著我;
當我指出Storm 拓撲的問題時,我是那麼篤定 ,最後優化結果也和我預期的一樣 。
當優惠券計算服務優化完畢,一切塵埃落定,卻又好像什麼都沒發生。
時光荏苒,生命中遇到越來越多的挫折,有的時候也會讓人低落,但一想到那個時候的一往無前,頓覺生命又充滿了希望,對於人生也有了新的感悟。
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高質量的文章,非常感謝!
