梯度下降演演算法 Gradient Descent
梯度下降演演算法 Gradient Descent
梯度下降演演算法是一種被廣泛使用的優化演演算法。在讀論文的時候碰到了一種引數優化問題:
在函數\(F\)中有若干引數是不確定的,已知\(n\)組訓練資料,期望找到一組引數使得殘差平方和最小。通俗一點地講就是,選擇最合適的引數,使得函數的預測值與真實值最相符。
其中,\(\hat{f}\)為真實值,\(f\)為測量值。在函數\(F\)中,存在n,m,p等引數,也存在自變數。訓練資料給出了若干組自變數與真實值,演演算法需要找到合適的引數使得函數與訓練資料相符。
這時就要用到今天的演演算法:梯度下降演演算法!
梯度下降演演算法的分類:
- 梯度下降演演算法 Batch Gradient Descent
- 隨機梯度下降演演算法 Stochastic Gradient Descent
- 小批次梯度下降演演算法 Mini-batch Gradient Descent
梯度下降演演算法
在梯度下降演演算法中,我們根據梯度方向,迭代地調整引數。我們把所有引數(例如n,m,p之類的)打包進一個變陣列\(\theta=\{n,m,p,..\}\),然後對這個變陣列迭代更新;定義函數\(L=\sum_{i=1}^n (\hat{f}_i - f_i)^2\)為誤差函數。
其中,\(r\)為學習率。r的大小決定了引數移動的「步幅」,若r值過小,往往需要更長的時間才能算出結果;而值過大又可能導致無法得到最優值。
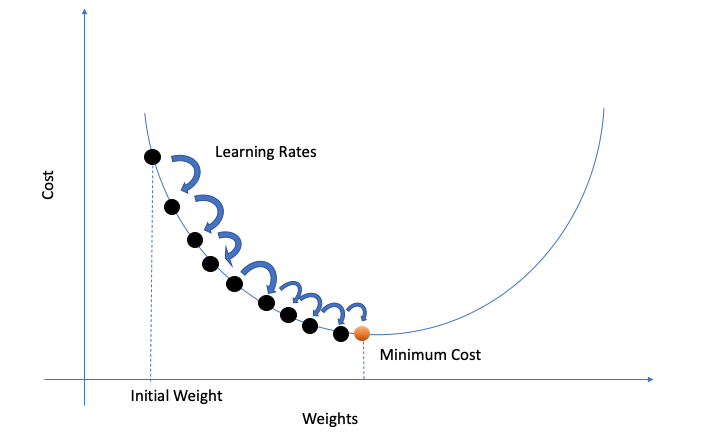
梯度的方向是函數增大最快的方向,那麼梯度的反方向就是減小最快的方向。因此我們沿著梯度更小的方向進行引數更新可以有效地找到全域性最優解。
def SGD(f, theta0, alpha, num_iters):
"""
Arguments:
f -- the function to optimize, it takes a single argument
and yield two outputs, a cost and the gradient
with respect to the arguments
theta0 -- the initial point to start SGD from
num_iters -- total iterations to run SGD for
Return:
theta -- the parameter value after SGD finishes
"""
theta = theta0
for iter in range(num_iters):
# For python 2.x - use xrange
grad = f(theta)[1]
# there is NO dot product ! return theta
theta = theta - r*(alpha * grad)
隨機梯度下降演演算法
梯度下降演演算法看似已經解決了問題,但是還面臨著「資料運算量過大」的問題。假設一下,我們現在有10000組訓練資料,有10個參量,那麼僅迭代一次就產生了10000*10=100000次運算。如果想讓它迭代1000次的話,就需要10^8的運算量。顯然易見,這個演演算法沒法處理大規模的資料。
那麼如何改進呢?在一次迭代中,將訓練資料的量由「全體」改為「隨機的一個」。這便是隨機梯度下降演演算法(SGD)
優點:
打個比方,我們開發了一個新的軟體,需要向100個使用者收集體驗資料並進行產品升級。在梯度下降方法中,我們會先向這100個使用者挨個詢問,然後進行一次優化;再挨個詢問,再進行一次調整...在隨機梯度下降方法中,我們會在詢問完第一個使用者之後就進行一次優化,然後拿著優化後的使用者詢問第二個客戶,然後再優化;這樣我們在完成一輪調查之後,就已經調整了100次!可以大大提高執行效率!
缺點:
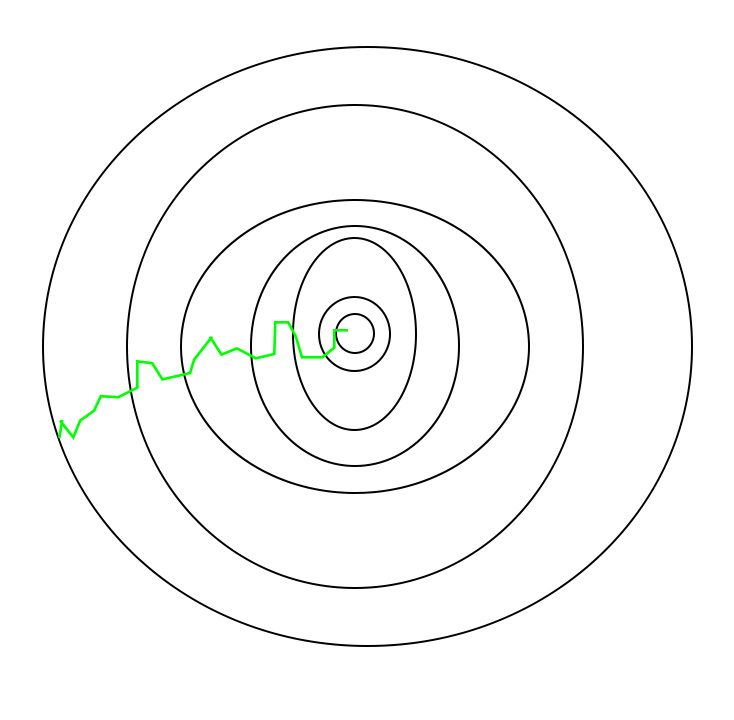
但是SGD在接近最優點之後很難穩定下來,而是在最優點附近徘徊,而難以到達最優。這一問題可以通到在後期適度降低學習率來解決。
並且由於隨機性較大,所以下降的過程中較為曲折:
小批次梯度下降演演算法
小批次梯度下降演演算法則是吸收了前兩者的優點。該演演算法存在一個變數Batch_size,指一次迭代中隨機的選擇多少的訓練資料。如果Batch_size=n,就是梯度下降演演算法;如果Batch_size=1,就是隨機梯度下降演演算法。
這樣的小批次不僅可以減少計算的成本,還可以提高演演算法的穩定性。