【Java復健指南15】連結串列LinkedList及其說明
連結串列LinkedList by Java
之前有寫過一些記錄(參照),但是忘了亂了,現在重新梳理一遍
連結串列是Java中List介面的一種實現
定義(參照)
連結串列(linked list)是一種物理儲存結構上非連續儲存結構,資料元素的邏輯順序是通過連結串列中的參照連結次序實現的.
連結串列由一系列結點(連結串列中每一個元素稱為結點)組成,結點可以在執行時動態生成。每個結點包括兩個部分:一個是儲存資料元素的資料域(data),另一個是儲存下一個結點地址的指標域(next),如下圖所示:
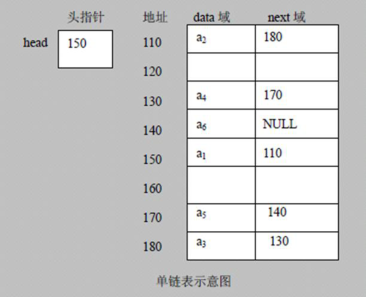
總結一下
1)連結串列是以節點的方式來儲存,是鏈式儲存
2)每個節點包含 data 域, next 域:指向下一個節點
3)如圖:發現連結串列的各個節點不一定是連續儲存.
4)連結串列分帶頭節點的連結串列和沒有頭節點的連結串列,根據實際的需求來確定
優勢
相比於線性表順序結構,操作複雜。由於不必須按順序儲存,連結串列在插入的時候可以達到O(1)的複雜度,比另一種線性表順序錶快得多,但是查詢一個節點或者存取特定編號的節點則需要O(n)的時間,而線性表和順序表相應的時間複雜度分別是O(logn)和O(1)。
構建連結串列
由前面的介紹可知,連結串列這一資料結構中,最關鍵的東西就是節點
簡單來說:要實現連結串列,需要先實現(定義)構成連結串列的節點
不同型別的連結串列主要也取決於對節點的不同定義
實現連結串列節點類
單連結串列的節點結構
Class Node<V>{
V value;
Node next;
}
對應到具體程式碼實現,每個ListNode物件(注意是物件)就代表一個節點
class ListNode{
public int val;//資料域
//ps:為什麼這麼寫?
//基於連結串列節點的定義,指標域存放的是下一個節點的地址
//那麼下一個節點怎麼樣才可以產生地址呢?當然是在建立下一個節點物件的時候產生咯
//所以這裡需要範例化節點類來建立下一個節點,同時獲取到下一個節點的地址,於是便有了下面的寫法
public ListNode next;//指標域
//建構函式(無參)
public ListNode(){
}
//建構函式(有一個引數)
public ListNode(int val){
this.val = val;
}
//建構函式(有兩個引數)
public ListNode(int val, ListNode next){
this.val = val;
this.next = next;
}
}
由以上結構的節點依次連線起來所形成的鏈叫單連結串列結構。
雙連結串列的節點結構
Class Node<V> {
V value;
Node prev;
Node next;
}
對應到具體程式碼實現
class ListNode{
public int val;//資料域
public ListNode prev;//指向上一個節點,前指標
public ListNode next;//指向下一個節點,後指標
//建構函式
public ListNode(int a){
this.val = a;
}
}
由以上結構的節點依次連線起來所形成的鏈叫雙連結串列結構。
如何使用連結串列
連結串列是一種資料結構
本質上是利用了"建立物件會產生地址"這一機制實現的(詳見P3)
使用連結串列的一個過程:定義連結串列節點類-->定義連結串列類-->為連結串列類編寫一系列你需要的類方法(為了操控連結串列)-->在主類中範例化連結串列類並使用各種類方法達成目的
那現在連結串列節點定義完了,把這些節點按照定義給連線起來,就構成一個連結串列了
範例:翻轉連結串列
疑問
我在剛接觸連結串列的時候常常會有疑惑:
我到底需要完成哪些部分?
刷題時要寫哪些部分?
下面通過一個範例來說明連結串列的完整實現過程
例子:實現連結串列的翻轉(完整程式碼,包括main方法)
public class TestLinkedList {
public static void main(String[] args) {
//這裡用手動連線節點的方式建立了一個連結串列
//要是你願意也可以在MyLinkedList寫一個方法來建立連結串列
ListNode head1 = new ListNode(1);
head1.next = new ListNode(2);
head1.next.next = new ListNode(3);
MyLinkedList myLinkedList = new MyLinkedList();
myLinkedList.printLinkedList(head1);
head1 = myLinkedList.reverseList(head1);
myLinkedList.printLinkedList(head1);
}
}
// 定義一個連結串列節點類
class ListNode{
public int val;//資料域
public ListNode next;//指標域
//建構函式(無參)
public ListNode(){
}
//建構函式(有一個引數)
public ListNode(int val){
this.val = val;
}
//建構函式(有兩個引數)
public ListNode(int val, ListNode next){
this.val = val;
this.next = next;
}
}
//定義一個操控連結串列節點的類
class MyLinkedList {
// 建立一個單連結串列反轉方法
public ListNode reverseList(ListNode head) {
ListNode pre = null; //指向當前節點的前一個節點的指標
ListNode cur = head; //指向當前節點的指標
ListNode tmp; //用於儲存當前節點的下一節點,防止連結串列斷掉
while (cur != null) {
//先將當前節點的後一個節點的地址儲存
tmp = cur.next;
//將當前節點的後一個節點指標指向當前節點的前一個節點
cur.next = pre;
//將pre指向當前節點位置
pre = cur;
//將當前節點位置後移
//此時已經是2-1-3了
cur = tmp;
}
//等pre指到連結串列尾部(null)時結束並返回前一個值
//此時連結串列變為3-2-1
return pre;
}
//建立一個連結串列列印方法
public void printLinkedList(ListNode head) {
System.out.print("Linked List: ");
while (head != null) {
System.out.print(head.val + " ");
head = head.next;
}
System.out.println();
}
}
這個例子中我嘗試將使用連結串列這個資料結構的整個流程都寫清楚
那麼無非就分為兩大部分:連結串列節點類和操控連結串列節點的類
連結串列節點類
這裡就只是單純定義一個連結串列的節點應該是什麼樣的,其餘的工作不用管
比如在LeetCode中,如果涉及連結串列的題,答題模板開頭都會給出他們是怎麼定義連結串列節點的
(類似這種)
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
操控連結串列節點的類
這裡是實現"連結串列節點-->連結串列"的類
所有對於節點的操作都可以在這裡定義
比如最基本的:建立節點、對節點進行CURD等
我們需要對節點實現的一些演演算法也需要以類方法的形式給出(比如例子中的翻轉操作)
結論
在LeetCode時,涉及連結串列的題,我們需要寫兩個部分:
- 建立節點的方法
這沒什麼好說的,先要把人家給的連結串列節點連線成需要的連結串列
- 操控節點的某種演演算法(以方法的形式實現)
後臺會去呼叫這個演演算法來驗證你對於連結串列的操控情況