面對集中式快取實現上的挑戰,Redis交出的是何種答卷?聊聊Redis在分散式方面的能力設計

大家好,又見面了。
本文是筆者作為掘金技術社群簽約作者的身份輸出的快取專欄系列內容,將會通過系列專題,講清楚快取的方方面面。如果感興趣,歡迎關注以獲取後續更新。
在本專欄前面的文章中,我們介紹了各種本地快取框架,也知曉了本地快取的常見特性與設計理念。在前兩篇文章中,我們介紹了集中式快取 Redis的一些主流特性與典型使用場景。現在我們來對比一下,分散式快取相比於本地快取,在實現層面需要關注的點有哪些不同。梳理如下:
| 維度 | 本地快取 | 集中式快取 |
|---|---|---|
| 快取量 | 受限於單機記憶體大小,儲存資料有限 | 需要提供給分散式系統裡面所有節點共同使用,對於大型系統而言,對集中式快取的容量訴求非常的大,遠超單機記憶體的容量大小。 |
| 可靠性 | 影響有限,只有本程序使用,不會影響其他程序的可靠性。 | 作為整個系統扛壓屏障,系統內所有節點共同依賴的通用服務,一旦集中式快取出問題,會影響與其對接的所有業務節點,對系統的影響是致命性的。 |
| 承壓性 | 承載單機節點的壓力,請求量有限 | 承載整個分散式叢集所有節點的流量,系統內業務分散式節點部署數量越多、業務體量越大,會導致集中快取要承載的壓力就越大,甚至是上不封頂的。 |
從上述幾個維度的對比可以發現,同樣是快取,但集中式快取所承擔的使命是完全不一樣的,業務對集中式快取的儲存容量、可靠性、承壓性等方面的訴求也是天壤之別,不可等同視之。以Redis為例:
- 如何打破redis快取容量受限於機器單機記憶體大小的問題?
- 如何使得redis能夠扛住多方過來的請求壓力?
- 如何保證redis不會成為單點故障源?
其實答案很簡單,加機器!通過多臺機器的疊加使用,達到比單機更優的效果 —— 現在業務系統的叢集化部署,也都是採用的這個思路。Redis的分散式之路亦是如此,但相比於常規的業務系統分散式叢集化構建更加複雜:
- 很多業務實現叢集化部署會很簡單,因為每個業務程序節點都是無狀態的,只需要部署下然後通過負載均衡的方式對外提供請求應答即可。
- Redis作為一個集中式快取資料庫,它是有狀態的,不僅需要將程序分別部署在多個節點上,還需要將資料也分散儲存在各個節點上,同時還得保證整個Redis叢集對外是一個統一整體。
所以對於一個集中式快取的分散式能力構建,必須要額外提供一些機制,來保障資料在各個節點上的安全與一致性,還需要將分散在各個節點上的資料都組成一個邏輯上的整體。
下面,我們以Redis作為集中式快取的代表,來看下集Redis面對上述各種難題,交出的是怎樣的答卷。

Reids部署方式的演進史
單機部署 —— 原始形態,最簡單
單機部署只能算是一個開發或測試場景去小範圍使用的場景,它與普通本地快取無二,在可靠性與承壓性上無法得到保證。
雖說Redis的效能很高,但俗話也說雙拳難敵四手,單機效能再高,也無法抗住大規模叢集中所有節點過來的並行請求。此外,單機部署還有個致命點在於其不具備高可用性,系統容易出現單點故障。
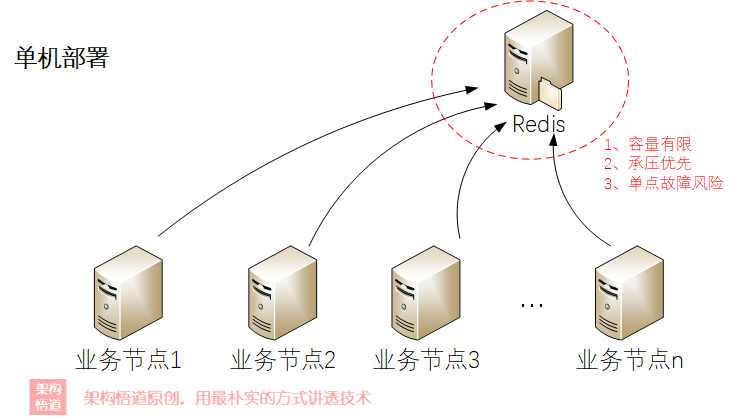
所以說,稍微正規點的專案,幾乎不會有人天真到會用單機模式去部署線上使用。
主從(master-replica)
前面說過單機節點存在諸多問題,很少在生產環境上使用。在實際專案中,有些專案的儲存容量要求其實並不是特別的高(比如常規的16G或者32G就已經足夠使用),但是需要保證資料的可靠、並且支援大並行量請求,這種情況下,就可以選擇主從部署的方式。
對於redis來說,一主兩從是比較常見的搭配,如下所示:
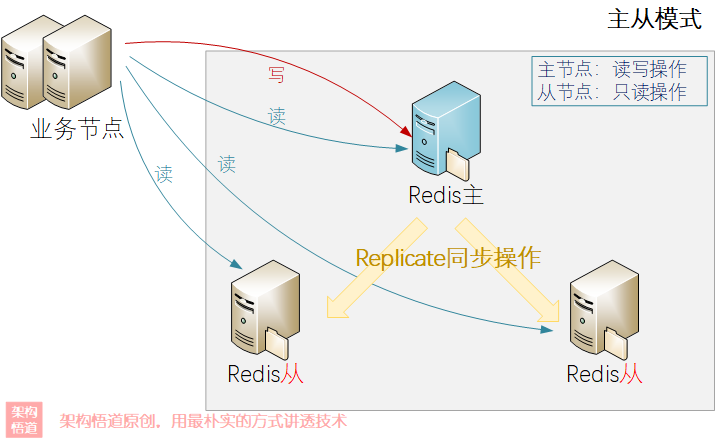
主從模式按照讀寫分離的策略來提升整體的請求處理能力:
-
主節點(Master)同時對外提供讀和寫操作
-
從節點(Slave)通過
replicate同步的方式,從主節點複製資料,保持自身資料與主節點一致 -
從節點只能對外提供讀操作
當然,對於讀多寫少類的操作,為了提升整體讀請求的處理能力,可以採用一主多從的方式:
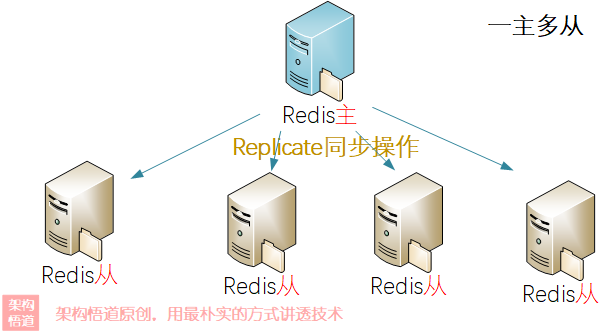
所有的從節點都從主節點進行資料同步,這樣會導致主節點的同步處理壓力過大而成為瓶頸。為了解決這個問題,redis還支援了從slave節點分發的能力:

Redis的主從模式重點在於解決整體的承壓能力,利用從節點分擔讀取操作的壓力。但是其在容錯恢復等可靠性層面欠缺明顯,不具備自動的故障轉移與恢復能力:
- 如果slave從節點宕機,整個redis依舊可以正常提供服務,待slave節點重新啟動後,可以恢復從master節點的資料同步、然後繼續提供服務。
- 如果master主節點宕機,則redis功能受損,無法繼續提供寫服務,直到手動修復master節點方可恢復。
當然,master節點故障後,也可以手動將其中一個從節點切換為新的master節點來恢復故障。而原先的master節點恢復後,需要手動將其降級為slave節點,對外提供唯讀服務。
實際使用的時候,手動故障恢復的時效無法得到保證,為了支援自動的故障轉移與恢復能力,Redis在主從模式的基礎上進行優化增強,提供了哨兵(Sentinel)架構模式。
哨兵(sentinel)
哨兵模式是在現代自動化系統裡面常見的一種模式。比如特斯拉汽車就設定了哨兵模式,當車輛停車鎖定並啟動哨兵模式時,會通過車輛四周的攝像頭持續的監控車輛四周的環境,如果發現異常則啟動報警系統。
同樣地,在軟體架構領域,也可以通過設定一些主程序之外的輔助程序,充當「哨兵」的角色時刻監控著主服務,一旦主服務出現異常則進行報警或者自動介入輔助故障轉移,以最大限度的保證系統功能的持續性。
Redis的哨兵模式,就是在主從模式的基礎上,額外部署若干獨立的哨兵程序,通過哨兵程序去監視者Redis主從節點的狀態,一旦發現主節點宕機,則哨兵可以重新從剩餘slave節點中推選一個新的節點並將其升級為master節點,以此保證整個系統功能可以正常使用。
比較典型的一個Redis sentinel部署場景是「一主二從三哨兵」的組合,如下:

哨兵可以準實時的監控著組網內所有的節點的狀態資訊,如果判定master節點宕機之後,所有的sentinel節點會一起推選出一個新的master節點。由於sentinel哨兵節點需要承擔著master節點推選的責任,所以實施的時候要去sentinel節點個數必須為奇數(比如3個、5個等),這是為了保證投票的時候不會出現平局的情況。
在哨兵模式下:
- 如果Redis的master節點宕機之後,Sentinel監控到之後,需要先判定確認master節點已經宕機,然後會從剩餘存活的slave節點中投票選出一個新的節點作為master節點。
- Sentinel監控到此前宕機的master節點重新恢復之後,會將其作為slave節點,掛到現有的新的master節點下面。
哨兵模式有效的解決了高可用的問題,保證了主節點的自動切換操作,進一步保障了Redis快取節點的可靠性。但是,不管是哨兵模式還是主從模式,其增加的多臺部署機器,都僅僅是擴充套件其承壓能力與可靠性,並沒有解決分散式場景下對於集中快取容量的焦慮 —— 只能適用於資料量有限的場景。
成年人的世界總是貪婪的。如果我們既想要保證Redis的可靠性與承壓性,還想要突破容量上的限制,就需要Redis的叢集模式登場了。
叢集(cluster)
Redis提供了去中心化的叢集部署模式,叢集內所有Redis節點之間兩兩連線,而很多的使用者端工具會根據key將請求分發到對應的分片下的某一個節點上進行處理。
一個典型的Redis叢集部署場景如下圖所示:

在Redis叢集裡面,又會劃分出分割區的概念,一個叢集中可有多個分割區。分割區有幾個特點:
- 同一個分割區內的Redis節點之間的資料完全一樣,多個節點保證了資料有多份副本冗餘儲存,且可以提供高可用保障。
- 不同分片之間的資料不相同。
- 通過水平增加多個分片的方式,可以實現整體叢集的容量的擴充套件。
按照Cluster模式進行部署的時候,要求最少需要部署6個Redis節點(3個分片,每個分片中1主1從),其中叢集中每個分片的master節點負責對外提供讀寫操作,slave節點則作為故障轉移使用(master出現故障的時候充當新的master)、對外提供唯讀請求處理。
叢集資料分佈策略
Redis Sharding(資料分片)
在Redis Cluster前,為了解決資料分發到各個分割區的問題,普遍採用的是Redis Sharding(資料分片)方案。所謂的Sharding,其實就是一種資料分發的策略。根據key的hash值進行取模,確定最終歸屬的節點。
使用Redis Sharding方式進行資料分片的時候,當叢集內資料分割區個數出現變化的時候,比如叢集擴容的時候,會導致請求被分發到錯誤節點上,導致快取命中率降低。
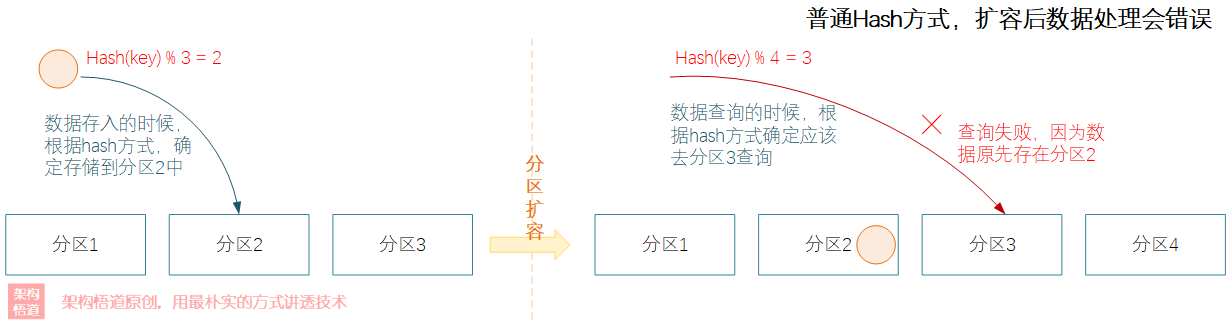
如果需要解決這個問題,就需要對原先擴容前已經儲存的資料重新進行一次hash計算和取模操作,將全部的資料重新分發到新的正確節點上進行儲存。這個操作被稱為重新Sharding,重新sharding期間服務不可用,可能會對業務造成影響。
一致性Hash
為了降低節點的增加或者移除對於整體已有快取資料存取的影響,最大限度的保證快取命中率,改良後的一致性Hash演演算法浮出水面。
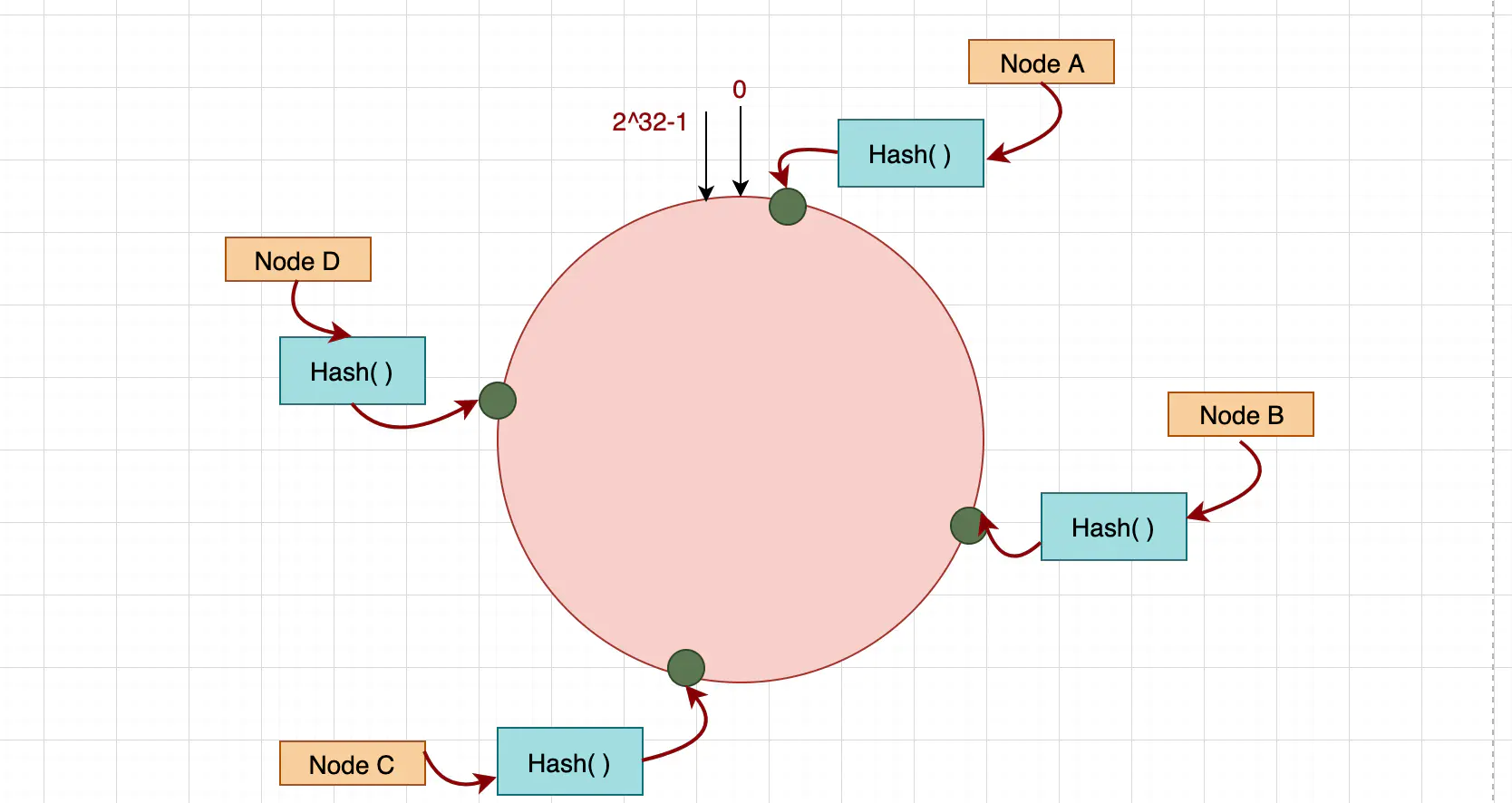
通過一致性Hash演演算法,將所有的儲存節點排列在首尾相接的Hash環上,每個key在計算Hash後會順時針找到最近的儲存節點存放。而當有新的分割區節點加入或退出時,僅影響該節點在Hash環上順時針相鄰的後續一個節點。
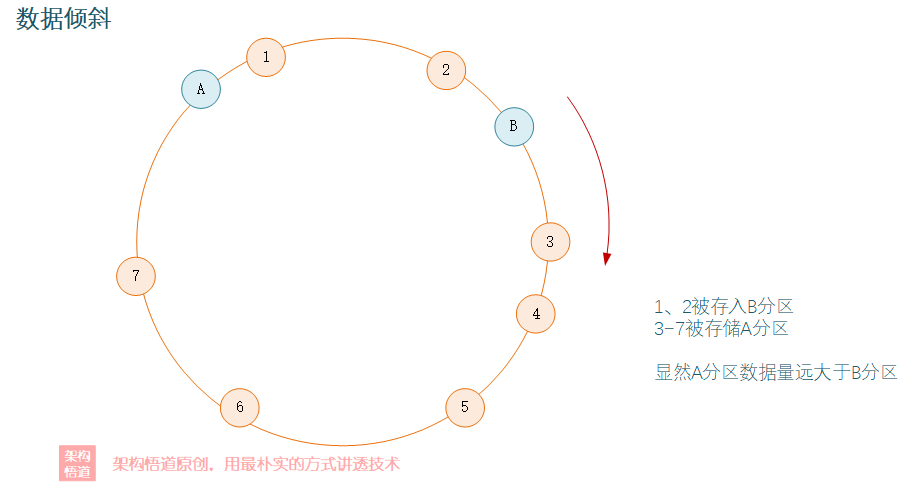
當然咯,如果Hash圓環上的分割區節點數太少,可能會出現資料在各個分片中分佈不均衡的情況,也即出現資料傾斜。
為了解決這個問題,引入了虛擬節點的機制,通過增加虛擬節點,來實現資料儘可能的均勻分佈在各個節點上。

上圖中,A1、A2實際上都對應真實的A分割區節點,而B1、B2則對應真實的B分割區節點。通過虛擬節點的方式,儘可能讓節點在Hash環上保持均分,實現資料在分割區內的均分。
Hash槽
不管是原本的Hash取模,還是經過改良後的一致性Hash,在節點的新增或者刪減的時候,始終都會出現部分快取資料丟失的問題 —— 只是丟失的資料量的多少區別。如何才能實現擴充套件或者收縮節點的時候,保持已有資料不丟失呢?
既然動態變更調整的方式行不通,那就手動指定咯!Hash槽的實現策略因此產生。何為Hash槽?Hash槽的原理與HashMap有點相似,共有16384個槽位,每個槽位對應一個資料桶,然後每個Redis的分割區都可以負責這些hash槽中的部分割區間。儲存資料的時候,資料key經過Hash計算後會匹配到一個對應的槽位,然後資料儲存在該槽位對應的分片中。然後各個分割區節點會與Hash槽之間有個對映繫結關係,由指定的Redis分割區節點負責儲存對應的Has槽對應的具體分片檔案。
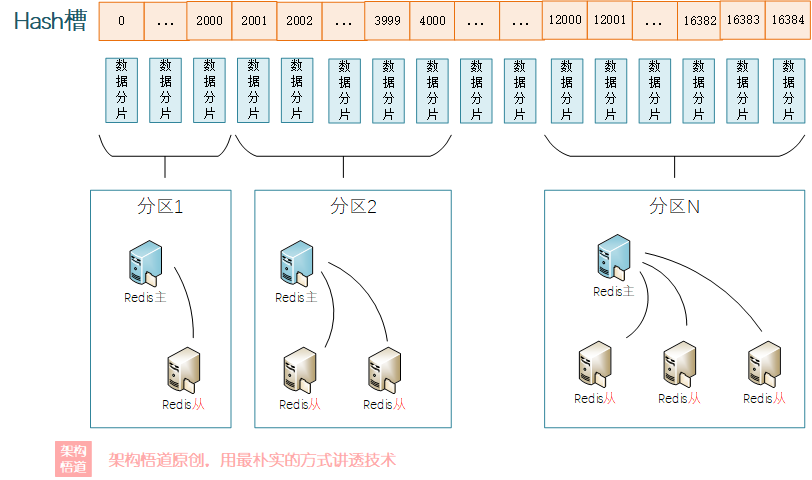
資料查詢的時候,先根據key的Hash值進行計算,確定應該落入哪個Hash槽,進而根據對映關係,確定負責此Hash槽資料儲存的redis分割區節點是哪個,然後就可以去做對應的查詢操作。
執行資料節點增加的時候,需要手動執行下處理:
- 為新的節點分配新其負責的Hash槽位區間段;
- 調整已有的節點的Hash槽位負責區間段;
- 將調整到新節點上的hash槽位區間段對應的資料分片檔案拷貝到新的節點上。
這樣,就不會出現已有資料無法使用的情況了。鑑於Hash槽的自主可控性以及節點伸縮場景下的優勢,其也成為了Redis Cluster中使用的方案。
小結回顧
好啦,關於Redis部署模式的演進探討,就聊到這裡了。通過本篇文章,我們也可以感受出集中式快取相對本地而言,在實現與設計機制上要更加的複雜,因為需要考慮與解決多方面的問題,比如可靠性、承壓性、容量以及後期的水平擴容能力等等,而這些也都是一個合格的集中式快取所必須要具備的基本品格。
那麼,瞭解Redis對於集中式快取在節點安全性與擴充套件性上的實現後,如果讓你來設計一個集中快取的話,你會採用何種方式來保證其可靠性與後續的擴充套件性呢?歡迎評論區一起交流下,期待和各位小夥伴們一起切磋、共同成長。