MySQL join語句怎麼優化?
在MySQL的實現中,Nested-Loop Join有3種實現的演演算法:
1、 Simple Nested-Loop Join:簡單巢狀迴圈連線
2、 Block Nested-Loop Join:快取塊巢狀迴圈連線
3、 Index Nested-Loop Join:索引巢狀迴圈連線
MySQL 8.0.18版本推出了hash join的方式以替代BNLJ(快取塊巢狀迴圈連線)。提高非索引的join操作查詢效率,這篇有關hash join並沒有整理,以後會整理的!
一、原理篇
1、Simple Nested-Loop Join
比如:
SELECT *
FROM user u
LEFT JOIN class c ON u.id = c.user_id
我們來看一下當進行 join 操作時,mysql是如何工作的:
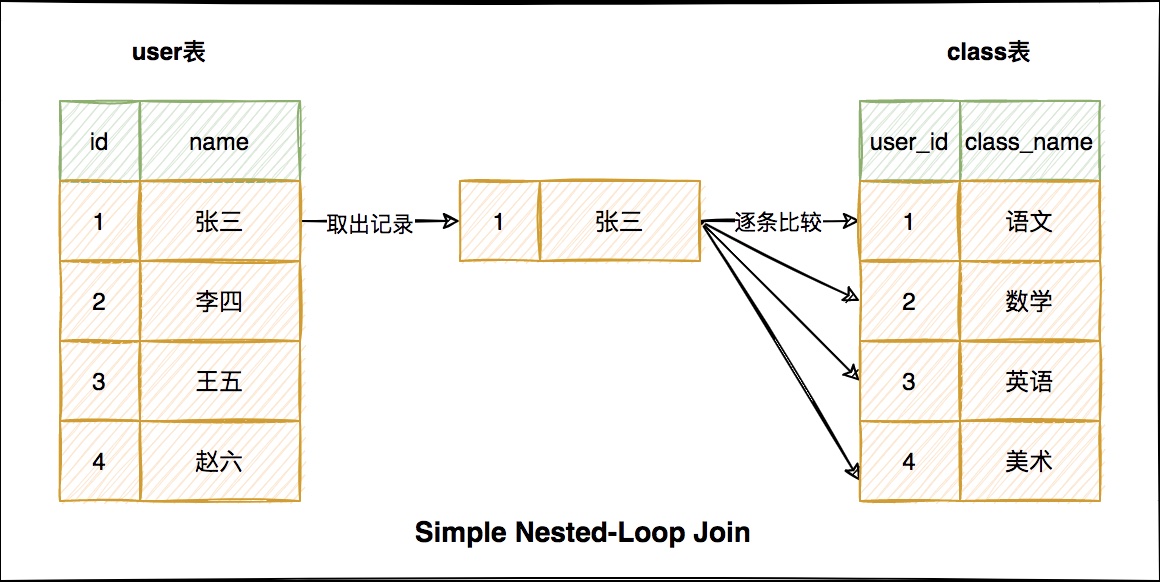
當我們進行left join連線操作時,左邊的表是驅動表,右邊的表是被驅動表
特點:
Simple Nested-Loop Join 簡單粗暴容易理解,就是通過雙層迴圈比較資料來獲得結果,但是這種演演算法顯然太過於粗魯,如果每個表有1萬條資料,那麼對資料比較的次數
=1萬 * 1萬 =1億次,很顯然這種查詢效率會非常慢。這個全是磁碟掃描!
因為每次從驅動表取資料比較耗時,所以MySQL即使在沒有索引命中的情況下也並沒有採用這種演演算法來進行連線操作,而是下面這種!
2、Block Nested-Loop Join
同樣以上面的sql為例,我們看下mysql是如何工作的
SELECT *
FROM user u
LEFT JOIN class c ON u.id = c.user_id
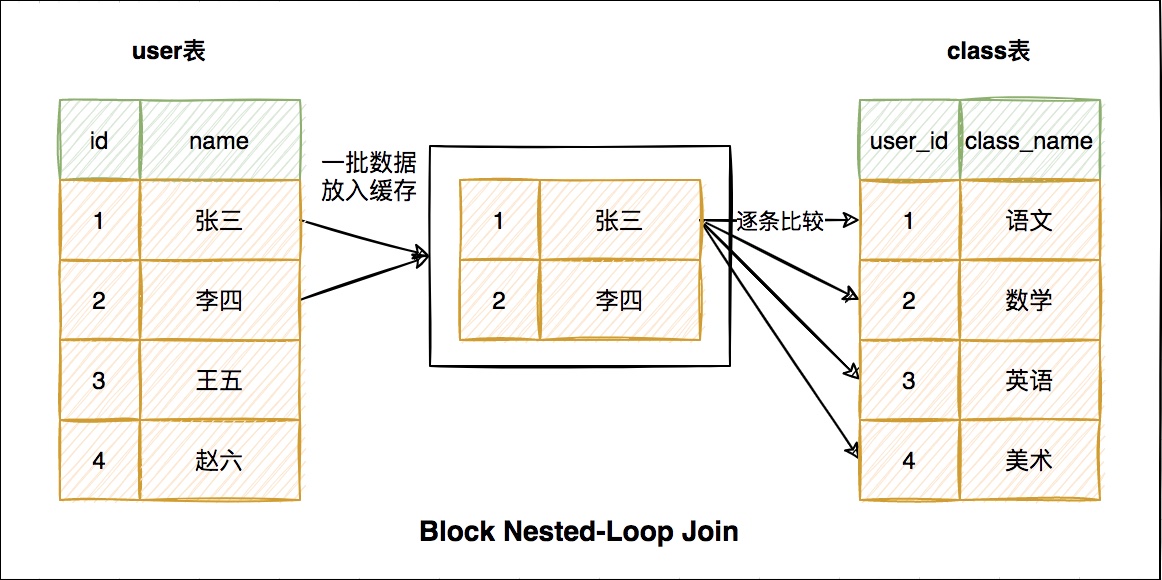
因為每次從驅動表取一條資料都是磁碟掃描所有比較耗時。
這裡就做了優化就是每次從驅動表取一批資料放到記憶體中,然後對這一批資料進行匹配操作。
這批資料匹配完畢,再從驅動表中取一批資料放到記憶體中,直到驅動表的資料全都匹配完畢。
這塊記憶體在MySQL中有一個專有的名詞,叫做 join buffer,我們可以執行如下語句檢視 join buffer 的大小
show variables like '%join_buffer%'
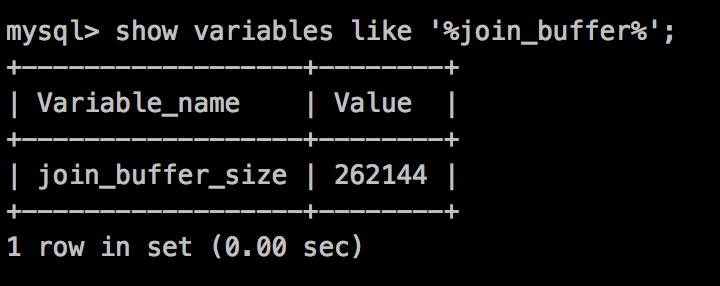
思考,Join Buffer快取的物件是什麼,這個問題相當關鍵和重要。
Join Buffer儲存的並不是驅動表的整行記錄,具體指所有參與查詢的列都會儲存到Join Buffer,而不是隻有Join的列。
比如下面sql
SELECT a.col3
FROM a JOIN b ON a.col1 = b.col2
WHERE a.col2 > 0 AND b.col2 = 0
上述SQL語句的驅動表是a,被驅動表是b,那麼存放在Join Buffer中的列是所有參與查詢的列,在這裡就是(a.col1,a.col2,a.col3)。
也就是說查詢的欄位越少,Join Buffer可以存的記錄也就越多!
變數join_buffer_size的預設值是256K,顯然對於稍複雜的SQL是不夠用的。好在這個是對談級別的變數,可以在執行前進行擴充套件。
建議在對談級別進行設定,而不是全域性設定,因為很難給一個通用值去衡量。另外,這個記憶體是對談級別分配的,如果設定不好容易導致因無法分配記憶體而導致的宕機問題。
-- 調整到1M
set session join_buffer_size = 1024 * 1024 * 1024;
-- 再執行查詢
SELECT a.col3
FROM a JOIN b ON a.col1 = b.col2
WHERE a.col2 > 0 AND b.col2 = 0
3、Index Nested-Loop Join
當我們瞭解Block Nested-Loop Join 演演算法,我們發現雖然可以將驅動表的資料放入Join Buffer中,但是快取中的每條記錄都要和被驅動表的所有記錄都匹配一遍,
也會非常耗時,所以我們應該如何提高被驅動表匹配的效率呢?其實很簡單 就是給被驅動表連線的列加上索引,這樣匹配的過程就非常快,如圖所示
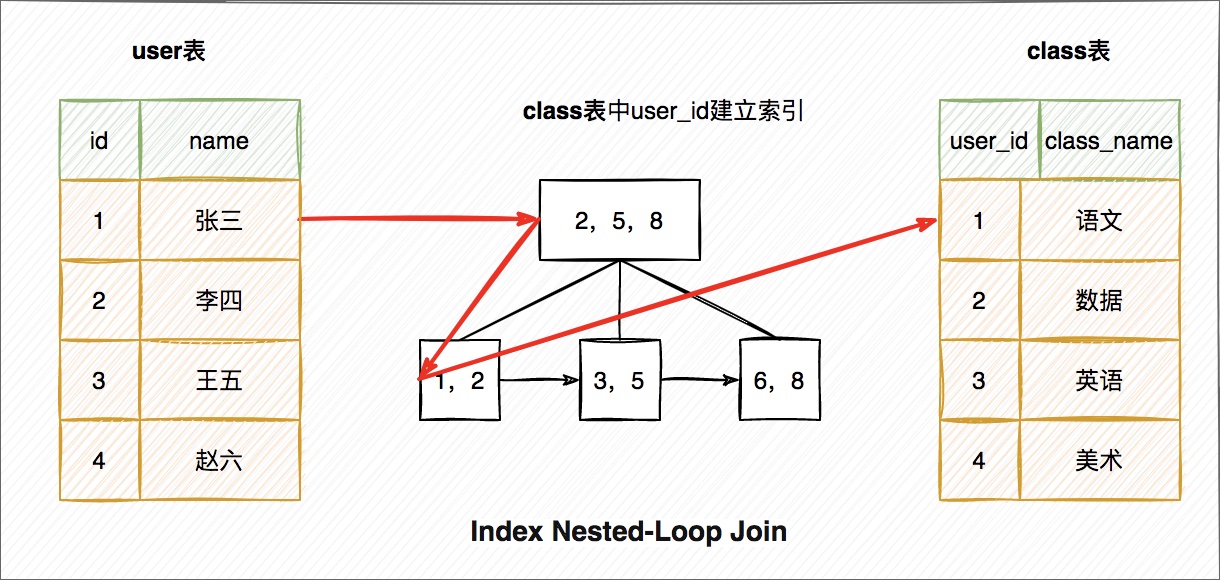
上面圖中就是先匹配索引看有沒有命中的資料,有命中資料再回表查詢這條記錄,獲取其它所需要的資料,但列的資料在索引中都能獲取那都不需要回表查詢,效率更高!
二、SQL範例
1、新增表和填充資料
-- 表1 a欄位加索引 b欄位沒加
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`a` int DEFAULT NULL COMMENT '欄位a',
`b` int DEFAULT NULL COMMENT '欄位b',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 表2
create table t2 like t1;
-- t1插入10000條資料 t2插入100條資料
drop procedure if exists insert_data;
delimiter ;;
create procedure insert_data()
begin
declare i int;
set i = 1;
while ( i <= 10000 ) do
insert into t1(a,b) values(i,i);
set i = i + 1;
end while;
set i = 1;
while ( i <= 100) do
insert into t2(a,b) values(i,i);
set i = i + 1;
end while;
end;;
delimiter ;
call insert_data();
2、Block Nested-Loop Join演演算法範例
-- b欄位沒有索引
explain select t2.* from t1 inner join t2 on t1.b= t2.b;
-- 執行結果
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10337 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
從執行計劃我們可以得出一些結論:
-
驅動表是t2,被驅動表是t1。所以使用 inner join 時,排在前面的表並不一定就是驅動表。 -
Extra 中 的 Using join buffer (Block Nested Loop) 說明該關聯查詢使用的是 BNLJ 演演算法。
上面的sql大致流程是:
- 將 t2 的所有資料放入到
join_buffer中 - 將 join_buffer 中的每一條資料,跟表t1中所有資料進行比較
- 返回滿足join 條件的資料
3、Index Nested-Loop Join 演演算法
-- a欄位有索引
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
執行結果

從執行計劃我們可以得出一些結論:
-
我們可以看出 t1的type不在是all而是ref,說明不在是全表掃描,而是走了idx_a的索引。
-
這裡並沒有出現 Using join buffer (Block Nested Loop) ,說明走的是Index Nested-Loop Join。
上面的sql大致流程是:
- 從表 t2 中讀取一行資料
- 從第 1 步的資料中,取出關聯欄位 a,到表 t1 idx_a 索引中查詢;
- 從idx_a 索引上找到滿足條件的資料,如果查詢資料在索引樹都能找到,那就可以直接返回,否則回表查詢剩餘欄位屬性再返回。
- 返回滿足join 條件的資料
發現這裡效率最大的提升在於t1表中rows=1,也就是說因為idx_a 索引的存在,不需要把t1每條資料都遍歷一遍,而是通過索引1次掃描可以認為最終只掃描 t1 表一行完整資料。
三、join優化總結
根據上面的知識點我們可以總結以下有關join優化經驗:
在關聯查詢的時候,儘量在被驅動表的關聯欄位上加索引,讓MySQL做join操作時儘量選擇INLJ演演算法。
2)小表做驅動表!
當使用left join時,左表是驅動表,右表是被驅動表,當使用right join時,右表是驅動表,左表是被驅動表,當使用join時,mysql會選擇資料量比較小的表作為驅動表,
大表作為被驅動表,如果說我們在 join的時候明確知道哪張表是小表的時候,可以用straight_join寫法固定連線驅動方式,省去mysql優化器自己判斷的時間。
對於小表定義的明確:
在決定哪個表做驅動表的時候,應該是兩個表按照各自的條件過濾,過濾完成之後,計算參與 join 的各個欄位的總資料量,資料量小的那個表,就是「小表」,應該作為驅動表。
3)在適當的情況下增大 join buffer 的大小,當然這個最好是在對談級別的增大,而不是全域性級別。
4)不要用 * 作為查詢列表,只返回需要的列!
這樣做的好處可以讓在相同大小的join buffer可以存更多的資料,也可以在存在索引的情況下儘可能避免回表查詢資料。
宣告: 公眾號如需轉載該篇文章,發表文章的頭部一定要 告知是轉至公眾號: 後端元宇宙。同時也可以問本人要markdown原稿和原圖片。其它情況一律禁止轉載!