精準測試之覆蓋
作者:京東工業 宛煜昕
測試的覆蓋通常是指需求範圍的執行程度,如需求、測試用例、缺陷的正向與逆向的雙向追溯。便於對其相關屬性的度量,即使用了覆蓋率。
一、覆蓋率與測試策略
覆蓋率是度量測試完整性的一個手段,是測試有效性的一個度量。測試覆蓋是對測試完全程度的評測。
測試策略按測試過程一般分為單元測試、整合測試、系統測試和驗收測試四大階段;按軟體內部工作過程又有白盒、灰盒、黑盒;從過程是否執行軟體又可將測試方法分為靜態和動態。這樣白盒測試對應著軟體測試過程中的單元測試,一般由開發人員完成,而灰盒測試與黑箱測試一般測試人員介入較多,對應著整合測試、系統測試和驗收測試。
二、覆蓋率的基本應用
測試時擔心之一就是無止境的、沒有範圍的,比如程式碼的改動或調整一個需求,需要全量回歸測試,影響範圍不清楚,某個功能或功能點是否需要測試,測試的程度如何不清楚等等的問題。
舉個例子:需求是查詢id與展示id相關資料的功能,進一步分析要做(開發)id輸入框,【查詢】按鈕,顯示的列表,涉及1個查詢介面(HTTP),查庫(資料庫)的話,需要1條SQL語句。
開發後得到前端id輸入框,【查詢】按鈕和結果列表,
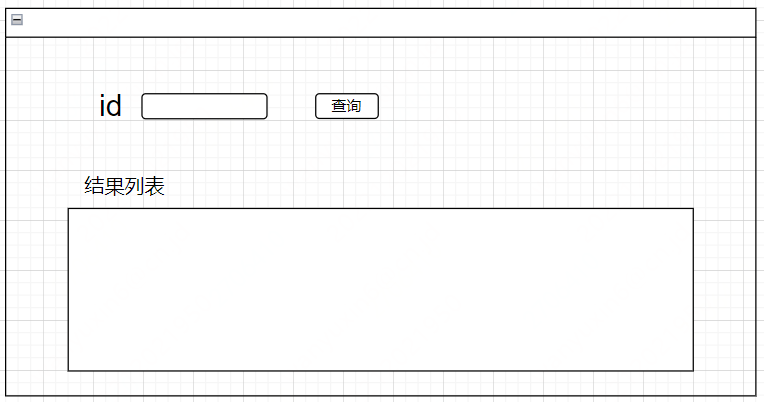
後端是通過一個查詢方法調到資料庫得到資料,顯示在前端頁面。

應用測試覆蓋率
1、建立測試範圍,這裡簡單些了,只是功能的
| 模組/功能 | 功能點 |
|---|---|
| 查詢 | 輸入框 |
| 查詢 | 查詢按鈕 |
| 結果列表 | 顯示結果列表 |
2、需求分析、用例設計、執行、提bug等,就是執行測試的過程
3、得到功能測試的結果
| 模組/功能 | 功能點 | 測試結果 |
|---|---|---|
| 查詢 | 輸入框 | 測試通過 |
| 查詢 | 查詢按鈕 | 測試通過 |
| 結果列表 | 顯示結果列表 | 測試通過 |
這麼看上去沒什麼問題,雙相的追溯(需求、用例、缺陷)已經是全覆蓋了,那怕在算上介面,但也僅僅是功能上的覆蓋,實則缺失了對程式碼等層面上的覆蓋,
比如:程式碼中要有對查詢id的判斷,這裡可能會有所遺漏,因為僅從功能或黑箱測試來講,不知道這個判斷是否執行。
這時測試覆蓋是要由測試需求和測試用例的覆蓋或已執行程式碼的覆蓋表示。建立在對測試結果的評估和對測試過程中確定的變更請求(缺陷)的分析的基礎上。
在"2、需求分析、用例設計、執行、提bug等,就是執行測試的過程"要介入程式碼覆蓋率的工具,彌補這一缺失,覆蓋率的表格也需要優化下。
後邊的類、方法的覆蓋率可以根據情況不同自行獲取
| 功能/模組 | 功能點 | HTTP介面型別 | HTTP介面 | 類名 | 方法名 | 覆蓋率 | 測試結果 |
|---|---|---|---|---|---|---|---|
| 查詢 | 輸入框 | 無 | 無 | 無 | 無 | 100% | 測試通過 |
| 查詢 | 查詢按鈕 | POST | /api/queryById | query | queryById | 100% | 測試通過 |
| 結果列表 | 顯示結果列表 | POST | /api/results | query | results | 100% | 測試通過 |
覆蓋率的計算由淺入深來說一般從功能、功能點、介面、程式碼中類、方法等得到,如:兩個功能、三個功能點,以功能點為覆蓋,覆蓋率公式為(至少執行一次的功能點 / 功能點總數)* 100% = (1 / 1)*100%,查詢按鈕的覆蓋率為100%
注:測試結果是否通過,不單是看覆蓋率,還要通過測試用例的執行,缺陷的關閉等情況來決定。
三、視覺化系統
通過完全手工繪製已經有了初步概念,考慮些許情況,這種已經不能滿足於此。
面對複雜的業務系統,經驗已經把業務功能、邏輯關係等相關知識點深深的印在當事人的腦子裡,而要沉澱、展示於旁人,這就是一個讓人很頭疼的問題,就像告訴一個人從哪裡到哪裡一樣,講的人清楚,但聽得人卻有些一頭霧水,此時如果有個地圖就一目瞭然了。

通過一些維度的圖形展示,誰都可以直觀、更好的加深對系統的瞭解。"知識庫"中儲存著涉及到的功能、介面等資訊。簡單實現,現在有了共用表格,可以直接維護上去,形式是哪種並不重要,主要是掌握了方法。
鏈路關係像這樣,業務系統-頁面-功能-介面-程式碼(拓撲圖),業務系統-頁面-功能-介面-架構(拓撲圖)。
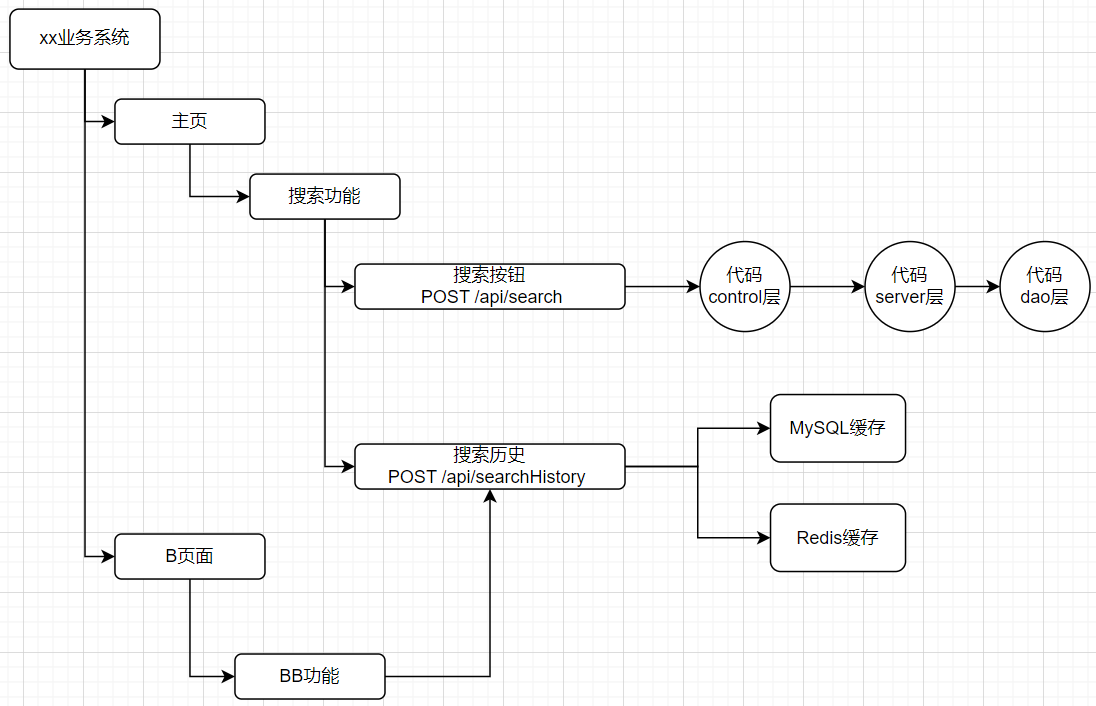
·功能層面
實現方式上比如可以像檔案目錄那樣實現一顆樹,某個頁面下有哪些功能,功能中有哪些介面,而介面中有程式碼的類、方法及覆蓋率等資訊。
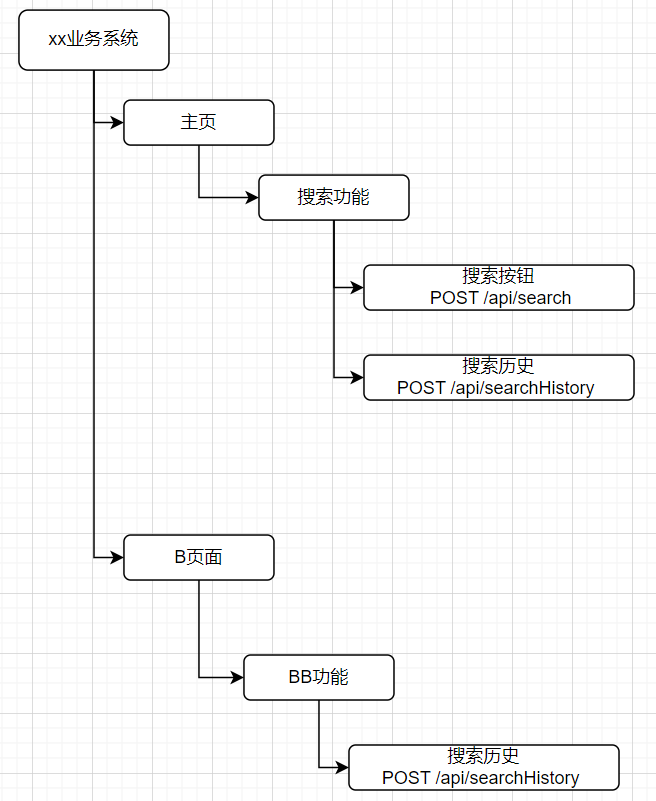
或者可以採用類似知識圖譜來構建一個結構化的語意知識庫,頁面、功能、介面資訊,可視為實體-節點,而彼此間的關係既是連線的線。或者介面資訊也可看做是屬性值。
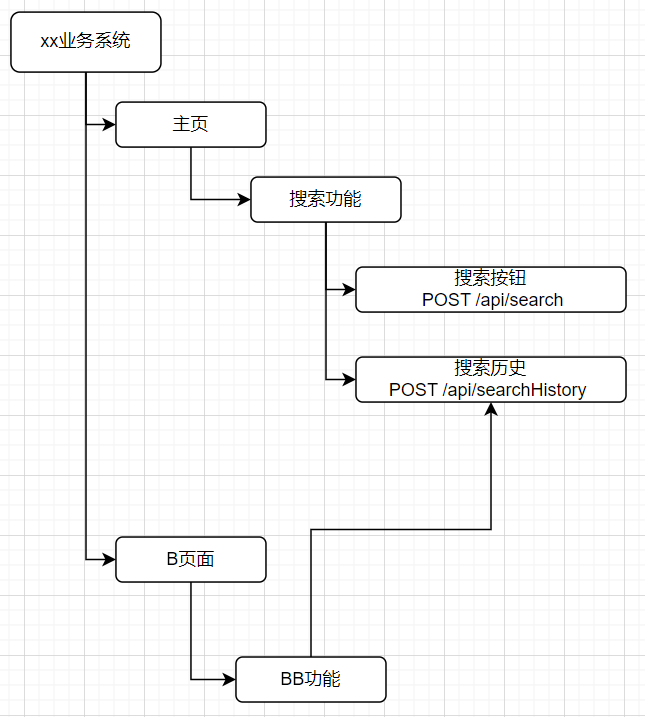
·程式碼層面
從介面下去就到了程式碼層面,可以看到程式碼的關係拓撲圖

這裡不僅能看到單個介面中程式碼和關係圖,還能展示出不同介面與程式碼的關係
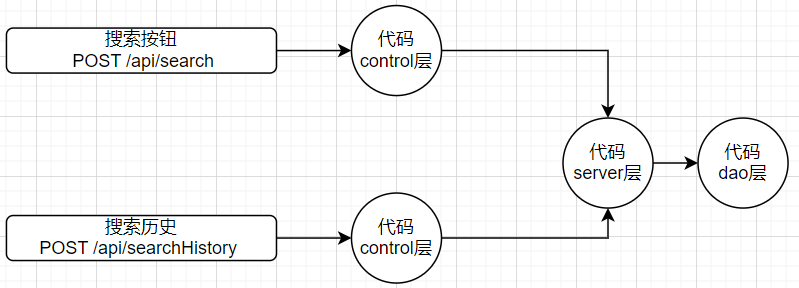
當關注到程式碼層面的覆蓋後,好處很多,其中之一是可以更好幫助開發提高或約束程式碼質量,比如:程式碼中有時判斷會使用常數,而不是列舉或宏/全域性變數。當然也可以看到執行的程式碼分支,每條程式碼邏輯分支是否執行到。
·架構層面
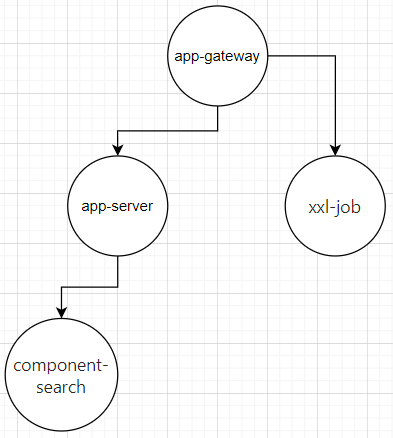
通過平臺獲取到的資料,不僅可以做功能、程式碼層面的覆蓋,系統架構也可完成視覺化的呈現,
比如:應用服務的環境模組拓撲圖
分散式呼叫鏈的拓撲圖
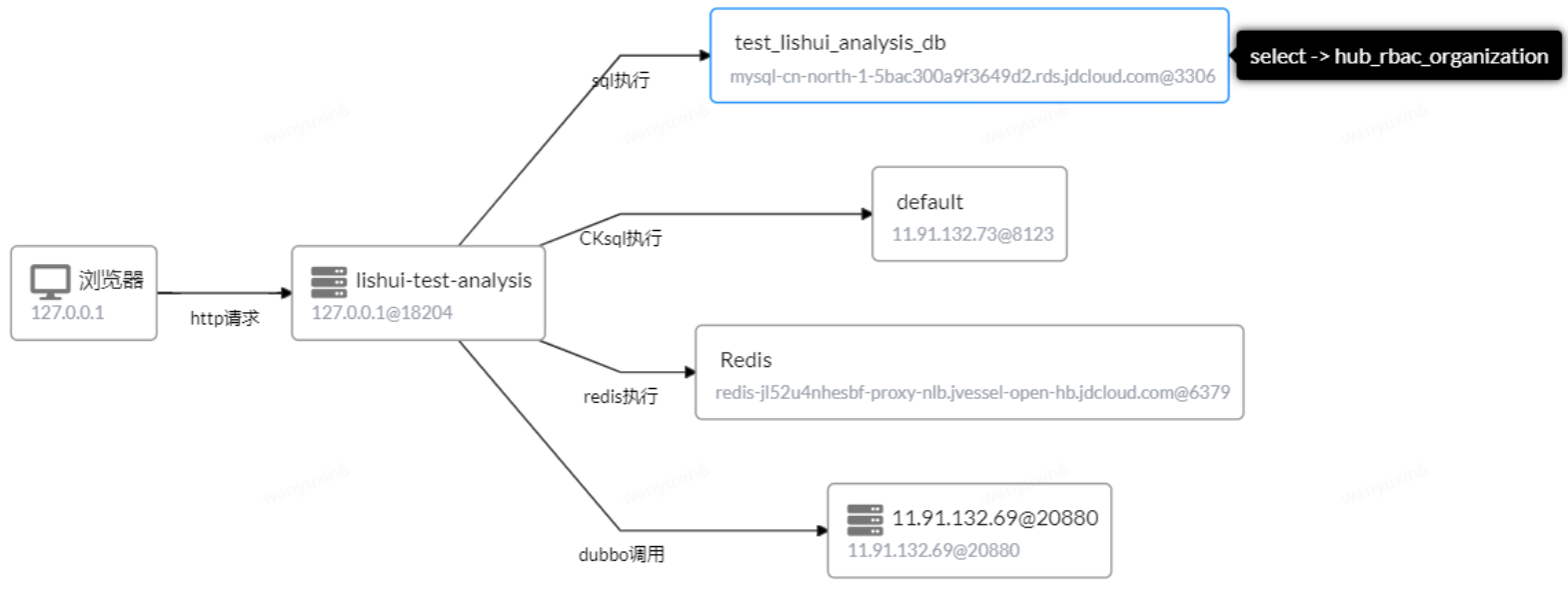
還是用查詢功能舉例,有時因為一些需要,該功能下使用了快取。當第一次查詢是直接從資料庫中查詢回來的資料,同時也在快取中記錄了該條資料,而在一定時間內再查詢,實則是從快取中查詢回來的。同樣的,如果只覆蓋了功能,這裡可能會有所遺漏,從功能來看,查詢後資料是返回了,而至於是從資料庫還是從快取獲取到的,就不得而知了。再有是獲取到的資料可能未必是想要的,奇怪的是,為什麼輸入/請求的資料,功能、介面都是一樣的,而返回的資料在一段時間後就發生了變化。中間發生了什麼不清楚,真的是"黑盒子"。想要知道SQL語句,只能費勁的從紀錄檔、程式碼或xml中查詢,還有等等的不便問題。
除此之外,還可以展示不同介面與資料庫的關係
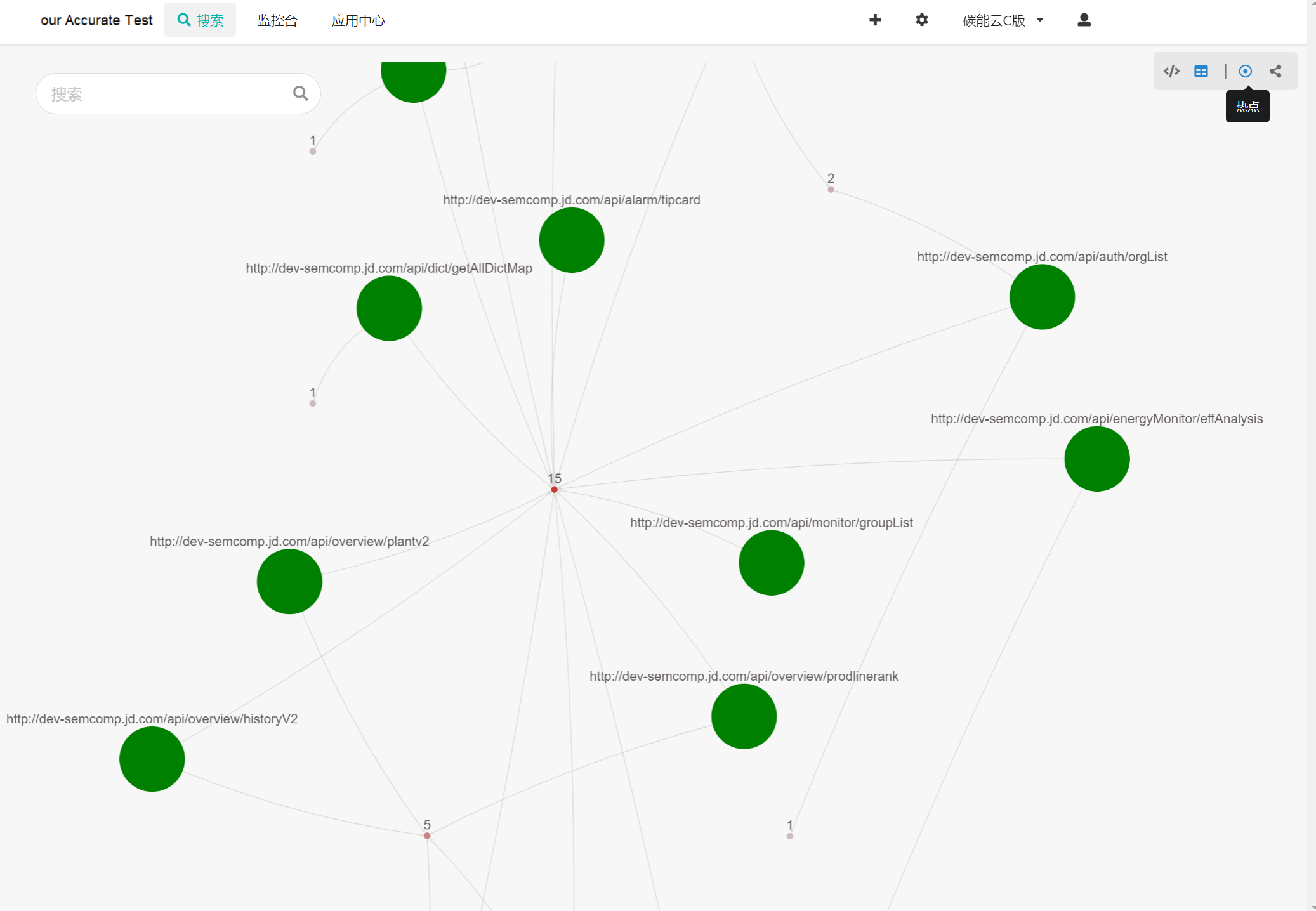
只要腦洞夠大,通過資料還可以實現出很多覆蓋,並呈現出各種視覺化圖形。
四、未來已來
使用資料驅動將抽象的字元、邏輯等等視覺化展示,從而得到想要的效果,但這種效果無論是靜態或動態產生的、主動或被動的等等,都會遇到時間的問題,而對時間有著強依賴的我們,無論採用哪種開發方式,即使在快,有著時間的限制和約束,這種苦惱始終會伴隨著,在現實世界中目前是無法解決,但有了虛擬世界,現在叫元宇宙,那就不同了,裡面有還原現實一切的1比1模型,在虛擬世界裡,可以搭建出想要的系統,每一個環節,無論是從專案或需求、產品設計、開發、測試到上線等,都可以清晰的關注到,無論功能與非功能均可以進行模擬,原來的專案或開發週期可能要1年,而現在可能半年不到的時間,虛擬世界的一切貼近現實,最終是通過空間換取時間從而得到這寶貴的經驗,然後這種虛擬產物可以搬到現實世界進行應用,從而避免很多試錯,也大大壓縮、節省了時間。目前這種方式已經慢慢被應用到各個行業、領域,這種虛擬與現實的結合可以更好地服務我們的生活。