RocketMQ訊息短暫而又精彩的一生
大家好,我是三友~~
這篇文章我準備來聊一聊RocketMQ訊息的一生。
不知你是否跟我一樣,在使用RocketMQ的時候也有很多的疑惑:
訊息是如何傳送的,佇列是如何選擇的? 訊息是如何儲存的,是如何保證讀寫的高效能? RocketMQ是如何實現訊息的快速查詢的? RocketMQ是如何實現高可用的? 訊息是在什麼時候會被清除? ...
本文就通過探討上述問題來探祕訊息在RocketMQ中短暫而又精彩的一生。
如果你還沒用過RocketMQ,可以看一下這篇文章 RocketMQ保姆級教學
核心概念
NameServer:可以理解為是一個註冊中心,主要是用來儲存topic路由資訊,管理Broker。在NameServer的叢集中,NameServer與NameServer之間是沒有任何通訊的。
Broker:核心的一個角色,主要是用來儲存訊息的,在啟動時會向NameServer進行註冊。Broker範例可以有很多個,相同的BrokerName可以稱為一個Broker組,每個Broker組只儲存一部分訊息。
topic:可以理解為一個訊息的集合的名字,一個topic可以分佈在不同的Broker組下。
佇列(queue):一個topic可以有很多佇列,預設是一個topic在同一個Broker組中是4個。如果一個topic現在在2個Broker組中,那麼就有可能有8個佇列。
生產者:生產訊息的一方就是生產者
生產者組:一個生產者組可以有很多生產者,只需要在建立生產者的時候指定生產者組,那麼這個生產者就在那個生產者組
消費者:用來消費生產者訊息的一方
消費者組:跟生產者一樣,每個消費者都有所在的消費者組,一個消費者組可以有很多的消費者,不同的消費者組消費訊息是互不影響的。
訊息誕生與傳送
我們都知道,訊息是由業務系統在執行過程產生的,當我們的業務系統產生了訊息,我們就可以呼叫RocketMQ提供的API向RocketMQ傳送訊息,就像下面這樣
DefaultMQProducer producer = new DefaultMQProducer("sanyouProducer");
//指定NameServer的地址
producer.setNamesrvAddr("localhost:9876");
//啟動生產者
producer.start();
//省略程式碼。。
Message msg = new Message("sanyouTopic", "TagA", "三友的java日記 ".getBytes(RemotingHelper.DEFAULT_CHARSET));
// 傳送訊息並得到訊息的傳送結果,然後列印
SendResult sendResult = producer.send(msg);
雖然程式碼很簡單,我們不經意間可能會思考如下問題:
程式碼中只設定了NameServer的地址,那麼生產者是如何知道Broker所在機器的地址,然後向Broker傳送訊息的? 一個topic會有很多佇列,那麼生產者是如何選擇哪個佇列傳送訊息? 訊息一旦傳送失敗了怎麼辦?
路由表
當Broker在啟動的過程中,Broker就會往NameServer註冊自己這個Broker的資訊,這些資訊就包括自身所在伺服器的ip和埠,還有就是自己這個Broker有哪些topic和對應的佇列資訊,這些資訊就是路由資訊,後面就統一稱為路由表。

當生產者啟動的時候,會從NameServer中拉取到路由表,快取到本地,同時會開啟一個定時任務,預設是每隔30s從NameServer中重新拉取路由資訊,更新本地快取。
佇列的選擇
好了通過上一節我們就明白了,原來生產者會從NameServer拉取到Broker的路由表的資訊,這樣生產者就知道了topic對應的佇列的資訊了。
但是由於一個topic可能會有很多的佇列,那麼應該將訊息傳送到哪個佇列上呢?
面對這種情況,RocketMQ提供了兩種訊息佇列的選擇演演算法。
輪詢演演算法 最小投遞延遲演演算法
輪詢演演算法 就是一個佇列一個佇列傳送訊息,這些就能保證訊息能夠均勻分佈在不同的佇列底下,這也是RocketMQ預設的佇列選擇演演算法。
但是由於機器效能或者其它情況可能會出現某些Broker上的Queue可能投遞延遲較嚴重,這樣就會導致生產者不能及時發訊息,造成生產者壓力過大的問題。所以RocketMQ提供了最小投遞延遲演演算法。
最小投遞延遲演演算法 每次訊息投遞的時候會統計投遞的時間延遲,在選擇佇列的時候會優先選擇投遞延遲時間小的佇列。這種演演算法可能會導致訊息分佈不均勻的問題。
如果你想啟用最小投遞延遲演演算法,只需要按如下方法設定一下即可。
producer.setSendLatencyFaultEnable(true);
當然除了上述兩種佇列選擇演演算法之外,你也可以自定義佇列選擇演演算法,只需要實現MessageQueueSelector介面,在傳送訊息的時候指定即可。
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
//從mqs中選擇一個佇列
return null;
}
}, new Object());
MessageQueueSelector RocketMQ也提供了三種實現
隨機演演算法 Hash演演算法 根據機房選擇演演算法(空實現)
其它特殊情況處理
傳送例外處理
終於,不論是通過RocketMQ預設的佇列選擇演演算法也好,又或是自定義佇列選擇演演算法也罷,終於選擇到了一個佇列,那麼此時就可以跟這個佇列所在的Broker機器建立網路連線,然後通過網路請求將訊息傳送到Broker上。
但是不幸的事發生了,Broker掛了,又或者是機器負載太高了,傳送訊息超時了,那麼此時RockerMQ就會進行重試。
RockerMQ重試其實很簡單,就是重新選擇其它Broker機器中的一個佇列進行訊息傳送,預設會重試兩次。
當然如果你的機器比較多,可以將設定重試次數設定大點。
producer.setRetryTimesWhenSendFailed(10);
訊息過大的處理
一般情況下,訊息的內容都不會太大,但是在一些特殊的場景中,訊息內容可能會出現很大的情況。
遇到這種訊息過大的情況,比如在預設情況下訊息大小超過4M的時候,RocketMQ是會對訊息進行壓縮之後再傳送到Broker上,這樣在訊息傳送的時候就可以減少網路資源的佔用。
訊息儲存
好了,經過以上環節Broker終於成功接收到了生產者傳送的訊息了,但是為了能夠保證Broker重啟之後訊息也不丟失,此時就需要將訊息持久化到磁碟。
如何保證高效能讀寫
由於涉及到訊息持久化操作,就涉及到磁碟資料的讀寫操作,那麼如何實現檔案的高效能讀寫呢?這裡就不得不提到的一個叫零拷貝的技術。
傳統IO讀寫方式
說零拷貝之前,先說一下傳統的IO讀寫方式。
比如現在需要將磁碟檔案通過網路傳輸出去,那麼整個傳統的IO讀寫模型如下圖所示
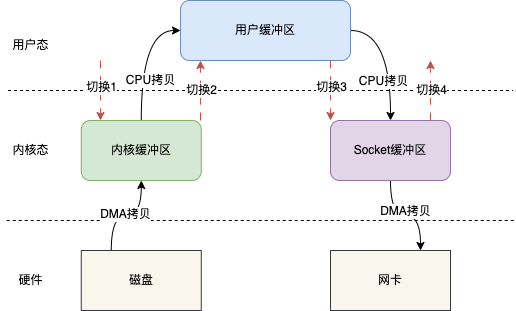
傳統的IO讀寫其實就是read + write的操作,整個過程會分為如下幾步
使用者呼叫read()方法,開始讀取資料,此時發生一次上下文從使用者態到核心態的切換,也就是圖示的切換1 將磁碟資料通過DMA拷貝到核心快取區 將核心快取區的資料拷貝到使用者緩衝區,這樣使用者,也就是我們寫的程式碼就能拿到檔案的資料 read()方法返回,此時就會從核心態切換到使用者態,也就是圖示的切換2 當我們拿到資料之後,就可以呼叫write()方法,此時上下文會從使用者態切換到核心態,即圖示切換3 CPU將使用者緩衝區的資料拷貝到Socket緩衝區 將Socket緩衝區資料拷貝至網路卡 write()方法返回,上下文重新從核心態切換到使用者態,即圖示切換4
整個過程發生了4次上下文切換和4次資料的拷貝,這在高並行場景下肯定會嚴重影響讀寫效能。
所以為了減少上下文切換次數和資料拷貝次數,就引入了零拷貝技術。
零拷貝
零拷貝技術是一個思想,指的是指計算機執行操作時,CPU不需要先將資料從某處記憶體複製到另一個特定區域。
實現零拷貝的有以下幾種方式
mmap() sendfile()
mmap()
mmap(memory map)是一種記憶體對映檔案的方法,即將一個檔案或者其它物件對映到程序的地址空間,實現檔案磁碟地址和程序虛擬地址空間中一段虛擬地址的一一對映關係。
簡單地說就是核心緩衝區和應用緩衝區共用,從而減少了從讀緩衝區到使用者緩衝區的一次CPU拷貝。
比如基於mmap,上述的IO讀寫模型就可以變成這樣。
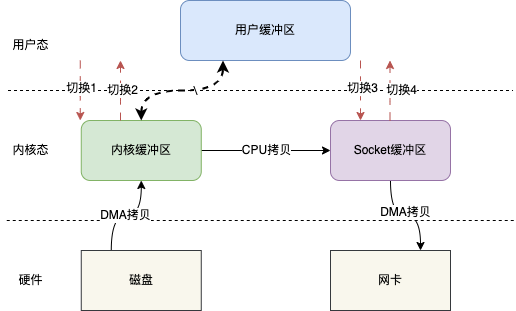
基於mmap IO讀寫其實就變成mmap + write的操作,也就是用mmap替代傳統IO中的read操作。
當用戶發起mmap呼叫的時候會發生上下文切換1,進行記憶體對映,然後資料被拷貝到核心緩衝區,mmap返回,發生上下文切換2;隨後使用者呼叫write,發生上下文切換3,將核心緩衝區的資料拷貝到Socket緩衝區,write返回,發生上下文切換4。
整個過程相比於傳統IO主要是不用將核心緩衝區的資料拷貝到使用者緩衝區,而是直接將資料拷貝到Socket緩衝區。上下文切換的次數仍然是4次,但是拷貝次數只有3次,少了一次CPU拷貝。
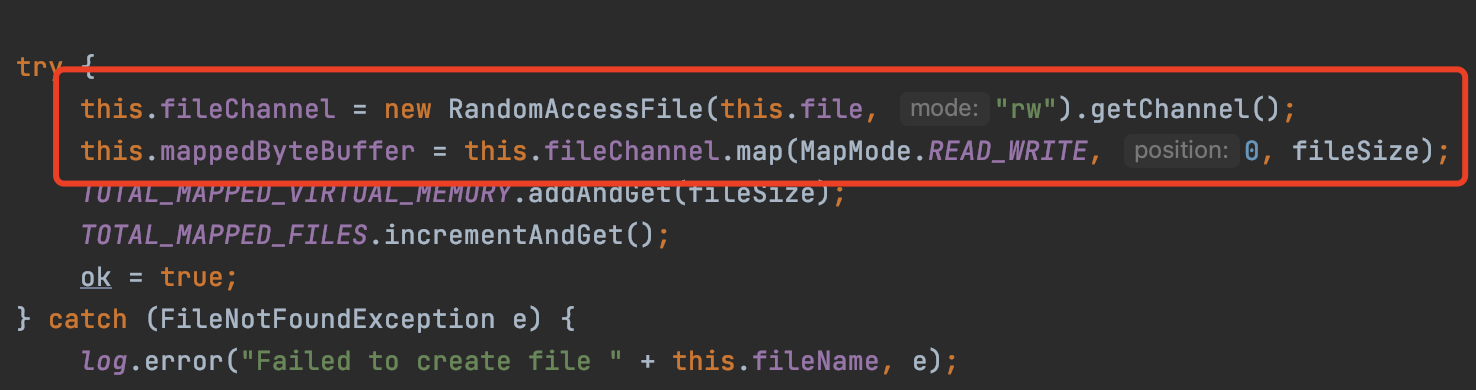
在Java中,提供了相應的api可以實現mmap,當然底層也還是呼叫Linux系統的mmap()實現的
FileChannel fileChannel = new RandomAccessFile("test.txt", "rw").getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileChannel.size());
如上程式碼拿到MappedByteBuffer,之後就可以基於MappedByteBuffer去讀寫。
sendfile()
sendfile()跟mmap()一樣,也會減少一次CPU拷貝,但是它同時也會減少兩次上下文切換。

如圖,使用者發起sendfile()呼叫時會發生切換1,之後資料通過DMA拷貝到核心緩衝區,之後再將核心緩衝區的資料CPU拷貝到Socket緩衝區,最後拷貝到網路卡,sendfile()返回,發生切換2。
同樣地,Java也提供了相應的api,底層還是作業系統的sendfile()
FileChannel channel = FileChannel.open(Paths.get("./test.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
//呼叫transferTo方法向目標資料傳輸
channel.transferTo(position, len, target);
通過FileChannel的transferTo方法即可實現。
transferTo方法(sendfile)主要是用於檔案傳輸,比如將檔案傳輸到另一個檔案,又或者是網路。
在如上程式碼中,並沒有檔案的讀寫操作,而是直接將檔案的資料傳輸到target目標緩衝區,也就是說,sendfile是無法知道檔案的具體的資料的;但是mmap不一樣,他是可以修改核心緩衝區的資料的。假設如果需要對檔案的內容進行修改之後再傳輸,只有mmap可以滿足。
通過上面的一些介紹,主要就是一個結論,那就是基於零拷貝技術,可以減少CPU的拷貝次數和上下文切換次數,從而可以實現檔案高效的讀寫操作。
RocketMQ內部主要是使用基於mmap實現的零拷貝(其實就是呼叫上述提到的api),用來讀寫檔案,這也是RocketMQ為什麼快的一個很重要原因。
CommitLog
前面提到訊息需要持久化到磁碟檔案中,而CommitLog其實就是儲存訊息的檔案的一個稱呼,所有的訊息都存在CommitLog中,一個Broker範例只有一個CommitLog。
由於訊息資料可能會很大,同時兼顧記憶體對映的效率,不可能將所有訊息都寫到同一個檔案中,所以CommitLog在物理磁碟檔案上被分為多個磁碟檔案,每個檔案預設的固定大小是1G。

當生產者將訊息傳送過來的時候,就會將訊息按照順序寫到檔案中,當檔案空間不足時,就會重新建一個新的檔案,訊息寫到新的檔案中。

訊息在寫入到檔案時,不僅僅會包含訊息本身的資料,也會包含其它的對訊息進行描述的資料,比如這個訊息來自哪臺機器、訊息是哪個topic的、訊息的長度等等,這些資料會和訊息本身按照一定的順序同時寫到檔案中,所以圖示的訊息其實是包含訊息的描述資訊的。
刷盤機制
RocketMQ在將訊息寫到CommitLog檔案中時並不是直接就寫到檔案中,而是先寫到PageCache,也就是前面說的核心快取區,所以RocketMQ提供了兩種刷盤機制,來將核心快取區的資料刷到磁碟。
非同步刷盤
非同步刷盤就是指Broker將訊息寫到PageCache的時候,就直接返回給生產者說訊息儲存成功了,然後通過另一個後臺執行緒來將訊息刷到磁碟,這個後臺執行緒是在RokcetMQ啟動的時候就會開啟。非同步刷盤方式也是RocketMQ預設的刷盤方式。
其實RocketMQ的非同步刷盤也有兩種不同的方式,一種是固定時間,預設是每隔0.5s就會刷一次盤;另一種就是頻率會快點,就是每存一次訊息就會通知去刷盤,但不會去等待刷盤的結果,同時如果0.5s內沒被通知去刷盤,也會主動去刷一次盤。預設的是第一種固定時間的方式。
同步刷盤
同步刷盤就是指Broker將訊息寫到PageCache的時候,會等待非同步執行緒將訊息成功刷到磁碟之後再返回給生產者說訊息儲存成功。
同步刷盤相對於非同步刷盤來說訊息的可靠性更高,因為非同步刷盤可能出現訊息並沒有成功刷到磁碟時,機器就宕機的情況,此時訊息就丟了;但是同步刷盤需要等待訊息刷到磁碟,那麼相比非同步刷盤吞吐量會降低。所以同步刷盤適合那種對資料可靠性要求高的場景。
如果你需要使用同步刷盤機制,只需要在組態檔指定一下刷盤機制即可。
高可用
在說高可用之前,先來完善一下前面的一些概念。
在前面介紹概念的時候也說過,一個RokcetMQ中可以有很多個Broker範例,相同的BrokerName稱為一個組,同一個Broker組下每個Broker範例儲存的訊息是一樣的,不同的Broker組儲存的訊息是不一樣的。
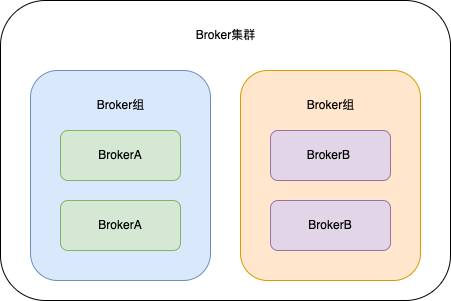
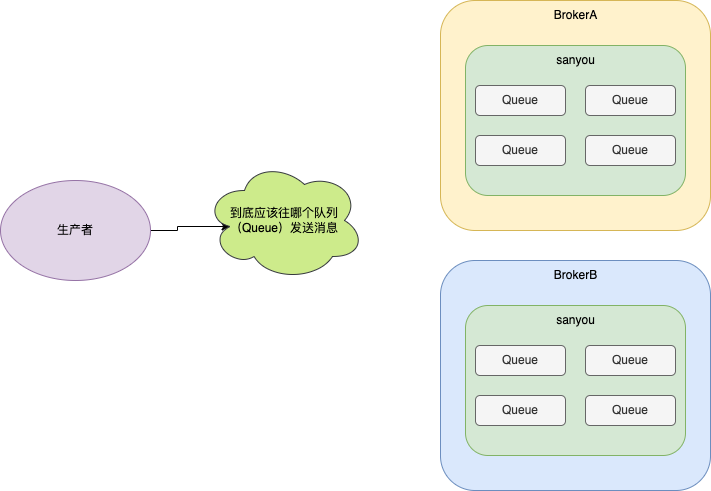
如圖所示,兩個BrokerA範例組成了一個Broker組,兩個BrokerB範例也組成了一個Broker組。
前面說過,每個Broker範例都有一個CommitLog檔案來儲存訊息的。那麼兩個BrokerA範例他們CommitLog檔案儲存的訊息是一樣的,兩個BrokerB範例他們CommitLog檔案儲存的訊息也是一樣的。
那麼BrokerA和BrokerB存的訊息不一樣是什麼意思呢?
其實很容易理解,假設現在有個topicA存在BrokerA和BrokerB上,那麼topicA在BrokerA和BrokerB預設都會有4個佇列。
前面在說發訊息的時候需要選擇一個佇列進行訊息的傳送,假設第一次選擇了BrokerA上的佇列傳送訊息,那麼此時這條訊息就存在BrokerA上,假設第二次選擇了BrokerB上的佇列傳送訊息,那麼那麼此時這條訊息就存在BrokerB上,所以說BrokerA和BrokerB存的訊息是不一樣的。
那麼為什麼同一個Broker組內的Broker儲存的訊息是一樣的呢?其實比較容易猜到,就是為了保證Broker的高可用,這樣就算Broker組中的某個Broker掛了,這個Broker組依然可以對外提供服務。
那麼如何實現同Broker組的Broker存的訊息資料相同的呢?這就不得不提到Broker的高可用模式。
RocketMQ提供了兩種Broker的高可用模式
主從同步模式 Dledger模式
主從同步模式
在主從同步模式下,在啟動的時候需要在組態檔中指定BrokerId,在同一個Broker組中,BrokerId為0的是主節點(master),其餘為從節點(slave)。
當生產者將訊息寫入到主節點是,主節點會將訊息內容同步到從節點機器上,這樣一旦主節點宕機,從節點機器依然可以提供服務。
主從同步主要同步兩部分資料
topic等資料 訊息
topic等資料是從節點每隔10s鍾主動去主節點拉取,然後更新本身快取的資料。
訊息是主節點主動推播到從節點的。當主節點收到訊息之後,會將訊息通過兩者之間建立的網路連線傳送出去,從節點接收到訊息之後,寫到CommitLog即可。
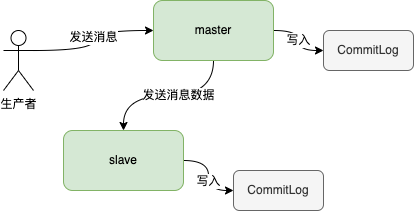
從節點有兩種方式知道主節點所在伺服器的地址,第一種就是在組態檔指定;第二種就是從節點在註冊到NameServer的時候會返回主節點的地址。
主從同步模式有一個比較嚴重的問題就是如果叢集中的主節點掛了,這時需要人為進行干預,手動進行重啟或者切換操作,而非叢集自己從從節點中選擇一個節點升級為主節點。
為了解決上述的問題,所以RocketMQ在4.5.0就引入了Dledger模式。
Dledger模式
在Dledger模式下的叢集會基於Raft協定選出一個節點作為leader節點,當leader節點掛了後,會從follower中自動選出一個節點升級成為leader節點。所以Dledger模式解決了主從模式下無法自動選擇主節點的問題。
在Dledger叢集中,leader節點負責寫入訊息,當訊息寫入leader節點之後,leader會將訊息同步到follower節點,當叢集中過半數(節點數/2 +1)節點都成功寫入了訊息,這條訊息才算真正寫成功。
至於選舉的細節,這裡就不多說了,有興趣的可以自行谷歌,還是挺有意思的。
訊息消費
終於,在生產者成功傳送訊息到Broker,Broker在成功儲存訊息之後,消費者要消費訊息了。
消費者在啟動的時候會從NameSrever拉取消費者訂閱的topic的路由資訊,這樣就知道訂閱的topic有哪些queue,以及queue所在Broker的地址資訊。
為什麼消費者需要知道topic對應的哪些queue呢?
其實主要是因為消費者在消費訊息的時候是以佇列為消費單元的,消費者需要告訴Broker拉取的是哪個佇列的訊息,至於如何拉到訊息的,後面再說。

消費的兩種模式
前面說過,消費者是有個消費者組的概念,在啟動消費者的時候會指定該消費者屬於哪個消費者組。
DefaultMQPushConsumer consumer = new DefaultMQPushConsumer("sanyouConsumer");
一個消費者組中可以有多個消費者,不同消費者組之間消費訊息是互不干擾的。
在同一個消費者組中,訊息消費有兩種模式。
叢集模式 廣播模式
叢集模式
同一條訊息只能被同一個消費組下的一個消費者消費,也就是說,同一條訊息在同一個消費者組底下只會被消費一次,這就叫叢集消費。
叢集消費的實現就是將佇列按照一定的演演算法分配給消費者,預設是按照平均分配的。
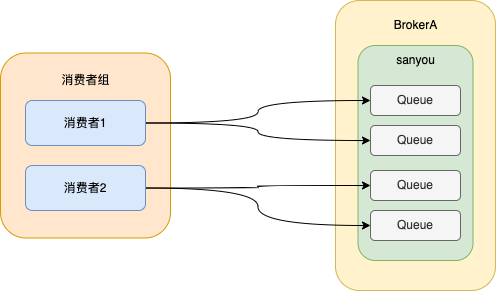
如圖所示,將每個佇列分配只分配給同一個消費者組中的一個消費者,這樣訊息就只會被一個消費者消費,從而實現了叢集消費的效果。
RocketMQ預設是叢集消費的模式。
廣播模式
廣播模式就是同一條訊息可以被同一個消費者組下的所有消費者消費。
其實實現也很簡單,就是將所有佇列分配給每個消費者,這樣每個消費者都能讀取topic底下所有的佇列的資料,就實現了廣播模式。
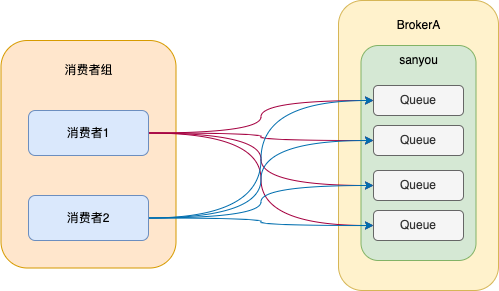
如果你想使用廣播模式,只需要在程式碼中指定即可。
consumer.setMessageModel(MessageModel.BROADCASTING);
ConsumeQueue
上一節我們提到消費者是從佇列中拉取訊息的,但是這裡不經就有一個疑問,那就是訊息明明都存在CommitLog檔案中的,那麼是如何去佇列中拉的呢?難道是去遍歷所有的檔案,找到對應佇列的訊息進行消費麼?
答案是否定的,因為這種每次都遍歷資料的效率會很低,所以為了解決這種問題,引入了ConsumeQueue的這個概念,而消費實際是從ConsumeQueue中拉取資料的。
使用者在建立topic的時候,Broker會為topic建立佇列,並且每個佇列其實會有一個編號queueId,每個佇列都會對應一個ConsumeQueue,比如說一個topic在某個Broker上有4個佇列,那麼就有4個ConsumeQueue。
前面說過,訊息在傳送的時候,會根據一定的演演算法選擇一個佇列,之後再傳送訊息的時候會攜帶選擇佇列的queueId,這樣Broker就知道訊息屬於哪個佇列的了。當訊息被存到CommitLog之後,其實還會往這條訊息所在的佇列的ConsumeQueue插一條資料。
ConsumeQueue也是由多個檔案組成,每個檔案預設是存30萬條資料。
插入ConsumeQueue中的每條資料由20個位元組組成,包含3部分資訊,訊息在CommitLog的起始位置(8個位元組),訊息在CommitLog儲存的長度(8個位元組),還有就是tag的hashCode(4個位元組)。
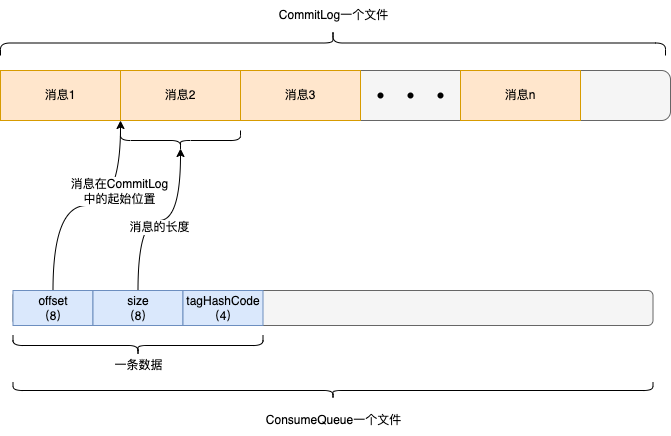
所以當消費者從Broker拉取訊息的時候,會告訴Broker拉取哪個佇列(queueId)的訊息、這個佇列的哪個位置的訊息(queueOffset)。
queueOffset就是指上圖中ConsumeQueue一條資料的編號,單調遞增的。
Broker在接受到訊息的時候,找個指定佇列的ConsumeQueue,由於每條資料固定是20個位元組,所以可以輕易地計算出queueOffset對應的那條資料在哪個檔案的哪個位置上,然後讀出20個位元組,從這20個位元組中在解析出訊息在CommitLog的起始位置和儲存的長度,之後再到CommitLog中去查詢,這樣就找到了訊息,然後在進行一些處理操作返回給消費者。
到這,我們就清楚的知道消費者是如何從佇列中拉取訊息的了,其實就是先從這個佇列對應的ConsumeQueue中找到訊息所在CommmitLog中的位置,然後再從CommmitLog中讀取訊息的。
RocketMQ如何實現訊息的順序性
這裡插入一個比較常見的一個面試,那麼如何保證保證訊息的順序性。
其實要想保證訊息的順序只要保證以下三點即可
生產者將需要保證順序的訊息傳送到同一個佇列 訊息佇列在儲存訊息的時候按照順序儲存 消費者按照順序消費訊息

第一點如何保證生產者將訊息傳送到同一個佇列?
上文提到過RocketMQ生產者在傳送訊息的時候需要選擇一個佇列,並且選擇演演算法是可以自定義的,這樣我們只需要在根據業務需要,自定義佇列選擇演演算法,將順序訊息都指定到同一個佇列,在傳送訊息的時候指定該演演算法,這樣就實現了生產者傳送訊息的順序性。
第二點,RocketMQ在存訊息的時候,是按照順序儲存訊息在ConsumeQueue中的位置的,由於消費訊息的時候是先從ConsumeQueue查詢訊息的位置,這樣也就保證了訊息儲存的順序性。
第三點消費者按照順序消費訊息,這個RocketMQ已經實現了,只需要在消費訊息的時候指定按照順序訊息消費即可,如下面所示,註冊訊息的監聽器的時候使用MessageListenerOrderly這個介面的實現。
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
//按照順序消費訊息記錄
return null;
}
});
訊息清理
由於訊息是存磁碟的,但是磁碟空間是有限的,所以對於磁碟上的訊息是需要清理的。
當出現以下幾種情況下時就會觸發訊息清理:
手動執行刪除 預設每天凌晨4點會自動清理過期的檔案 當磁碟空間佔用率預設達到75%之後,會自動清理過期檔案 當磁碟空間佔用率預設達到85%之後,無論這個檔案是否過期,都會被清理掉
上述過期的檔案是指檔案最後一次修改的時間超過72小時(預設情況下),當然如果你的老闆非常有錢,伺服器的磁碟空間非常大,可以將這個過期時間修改的更長一點。
有的小夥伴肯定會有疑問,如果訊息沒有被訊息,那麼會被清理麼?
答案是會被清理的,因為清理訊息是直接刪除CommitLog檔案,所以只要達到上面的條件就會直接刪除CommitLog檔案,無論檔案內的訊息是否被消費過。
當訊息被清理完之後,訊息也就結束了它精彩的一生。
訊息的一生總結
為了更好地理解本文,這裡再來總結一下RokcetMQ訊息一生的各個環節。
訊息傳送
生產者產生訊息 生產者在傳送訊息之前會拉取topic的路由資訊 根據佇列選擇演演算法,從topic眾多的佇列中選擇一個佇列 跟佇列所在的Broker機器建立網路連線,將訊息傳送到Broker上
訊息儲存
Broker接收到生產者的訊息將訊息存到CommitLog中 在CosumeQueue中儲存這條訊息在CommitLog中的位置
由於CommitLog和CosumeQueue都涉及到磁碟檔案的讀寫操作,為了提高讀寫效率,RokcetMQ使用到了零拷貝技術,其實就是呼叫了一下Java提供的api。。
高可用
如果是叢集模式,那麼訊息會被同步到從節點,從節點會將訊息存到自己的CommitLog檔案中。這樣就算主節點掛了,從節點仍然可以對外提供存取。
訊息消費
消費者會拉取訂閱的Topic的路由資訊,根據叢集消費或者廣播消費的模式來選擇需要拉取訊息的佇列 與佇列所在的機器建立連線,向Broker傳送拉取訊息的請求 Broker在接收到請求知道,找到佇列對應的ConsumeQueue,然後計算出拉取訊息的位置,再解析出訊息在CommitLog中的位置 根據解析出的位置,從CommitLog中讀出訊息的內容返回給消費者
訊息清理
由於訊息是存在磁碟的,而磁碟的空間是有限的,所以RocketMQ會根據一些條件去清理CommitLog檔案。
最後
最後,如果有對RocketMQ原始碼感興趣的小夥伴可以在微信公眾號三友的java日記回覆rocketmq,即可獲得有註釋的原始碼地址,我已經對RocketMQ核心元件的原始碼進行了註釋。
往期熱門文章推薦
掃碼或者搜尋關注公眾號 三友的java日記 ,及時乾貨不錯過,公眾號致力於通過畫圖加上通俗易懂的語言講解技術,讓技術更加容易學習,回覆 面試 即可獲得一套面試真題。
