TensorRT基礎筆記
一,概述
TensorRT 是 NVIDIA 官方推出的基於 CUDA 和 cudnn 的高效能深度學習推理加速引擎,能夠使深度學習模型在 GPU 上進行低延遲、高吞吐量的部署。採用 C++ 開發,並提供了 C++ 和 Python 的 API 介面,支援 TensorFlow、Pytorch、Caffe、Mxnet 等深度學習框架,其中 Mxnet、Pytorch 的支援需要先轉換為中間模型 ONNX 格式。截止到 2021.4.21 日, TensorRT 最新版本為 v7.2.3.4。
深度學習領域延遲和吞吐量的一般解釋:
- 延遲 (
Latency): 人和機器做決策或採取行動時都需要反應時間。延遲是指提出請求與收到反應之間經過的時間。大部分人性化軟體系統(不只是 AI 系統),延遲都是以毫秒來計量的。 - 吞吐量 (
Throughput): 在給定建立或部署的深度學習網路規模的情況下,可以傳遞多少推斷結果。簡單理解就是在一個時間單元(如:一秒)內網路能處理的最大輸入樣例數。
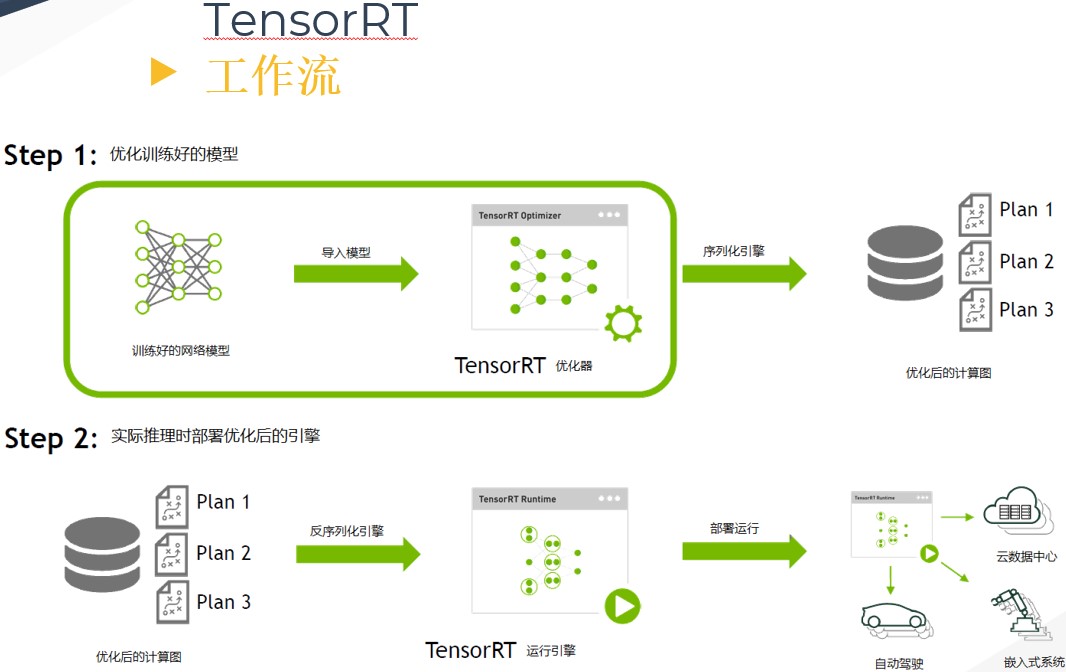
二,TensorRT 工作流程
在描述 TensorRT 的優化原理之前,需要先了解 TensorRT 的工作流程。首先輸入一個訓練好的 FP32 模型檔案,並通過 parser 等方式輸入到 TensorRT 中做解析,解析完成後 engin 會進行計算圖優化(優化原理在下一章)。得到優化好的 engine 可以序列化到記憶體(buffer)或檔案(file),讀的時候需要反序列化,將其變成 engine以供使用。然後在執行的時候建立 context,主要是分配預先的資源,engine 加 context 就可以做推理(Inference)。
三,TensorRT 的優化原理
TensorRT 的優化主要有以下幾點:
-
運算元融合(網路層合併):我們知道
GPU上跑的函數叫Kernel,TensorRT是存在Kernel呼叫的,頻繁的Kernel呼叫會帶來效能開銷,主要體現在:資料流圖的排程開銷,GPU核心函數的啟動開銷,以及核心函數之間的資料傳輸開銷。大多數網路中存在連續的折積conv層、偏置bias層和 啟用relu層,這三層需要呼叫三次 cuDNN 對應的 API,但實際上這三個運算元是可以進行融合(合併)的,合併成一個CBR結構。同時目前的網路一方面越來越深,另一方面越來越寬,可能並行做若干個相同大小的折積,這些折積計算其實也是可以合併到一起來做的(橫向融合)。比如GoogLeNet網路,把結構相同,但是權值不同的層合併成一個更寬的層。 -
concat層的消除。對於channel維度的concat層,TensorRT通過非拷貝方式將層輸出定向到正確的記憶體地址來消除concat層,從而減少記憶體訪存次數。 -
Kernel可以根據不同batch size大小和問題的複雜度,去自動選擇最合適的演演算法,TensorRT預先寫了很多GPU實現,有一個自動選擇的過程(沒找到資料理解)。其問題包括:怎麼呼叫CUDA核心、怎麼分配、每個block裡面分配多少個執行緒、每個grid裡面有多少個block。 -
FP32->FP16、INT8、INT4:低精度量化,模型體積更小、記憶體佔用和延遲更低等。 -
不同的硬體如
P4卡還是V100卡甚至是嵌入式裝置的卡,TensorRT都會做對應的優化,得到優化後的engine。
四,參考資料
- 核心融合:GPU深度學習的「加速神器」
- 高效能深度學習支援引擎實戰——TensorRT
- 《NVIDIA TensorRT 以及實戰記錄》PPT
- https://www.tiriasresearch.com/wp-content/uploads/2018/05/TIRIAS-Research-NVIDIA-PLASTER-Deep-Learning-Framework.pdf