dotnet 程式碼優化 聊聊邏輯圈複雜度
本文屬於 dotnet 程式碼優化系列部落格。相信大家都對圈複雜度這個概念很是熟悉,本文來和大家聊聊邏輯的圈複雜度。程式碼優化裡面,一個關注的重點在於程式碼的邏輯複雜度。一段程式碼的邏輯複雜度越高,那麼維護起來的難度也就越大。衡量程式碼的邏輯複雜度的一個維度是通過邏輯圈複雜度進行衡量。本文將告訴大家如何判斷程式碼的邏輯圈複雜度以及一些降低圈複雜度的套路,讓大家瞭解如何寫出更好維護的程式碼
回顧一下程式碼設計的目標,其中一個很重要的點就是解決 複雜的程式碼邏輯 和 人類有限的智商 的矛盾。假設人類的智商非常的高,無論再複雜的程式碼邏輯都能理解,且人類寫出的邏輯也不存在漏洞,那其實很多程式碼設計都是不需要的。現實剛好不是,一個稍微複雜的專案,就已經不是人類輕而易舉能夠掌控的。即使是自己編寫的程式碼,也會隨著時間逐漸遺忘程式碼裡面當初的實現邏輯。何況在團隊共同作業中,可能會遇到需要閱讀其他開發者留下的程式碼的時候,假設前輩們沒有好好的進行編寫和設計,自然可能是給後來者挖了一個大坑
邏輯的圈複雜度屬於一個度量程式碼複雜度的維度,但稍微特別的是,當邏輯的圈複雜度比較低時,能意味著程式碼複雜度比較低,比較好維護。但反過來不成立,比較好維護的程式碼,不一定是邏輯的圈複雜度比較低的程式碼。程式碼的可維護是需要綜合考慮多個維度的,雖然說降低邏輯的圈複雜度基本上都是屬於正確的事情,但由於實際專案遇到的情況比較特殊,還請識別主次矛盾,不要強行優化
邏輯的圈複雜度是指在程式碼執行過程中,邏輯上形成的圈的數量,更多的是指在物件導向設計裡面的類和方法之間的關係。至於方法內的迴圈判斷等,只屬於(程式碼)圈複雜度(Cyclomatic complexity)而不是邏輯圈複雜度
學術的定義,相信大家都不感興趣,下面來舉一個例子,相信大家看完很快就懂了
例子依然是老套的圖書管理系統的故事,假定書籍有 人文、哲學、物理、數學、計算機 等型別的書籍,在圖書管理系統裡面,需要有一定的業務邏輯,對其進行處理。其工序有些是所有型別共用的,有些是需要根據型別而來的,假定每個工序都能用一個程式碼方法完成。原始的邏輯設計抽象起來如下圖
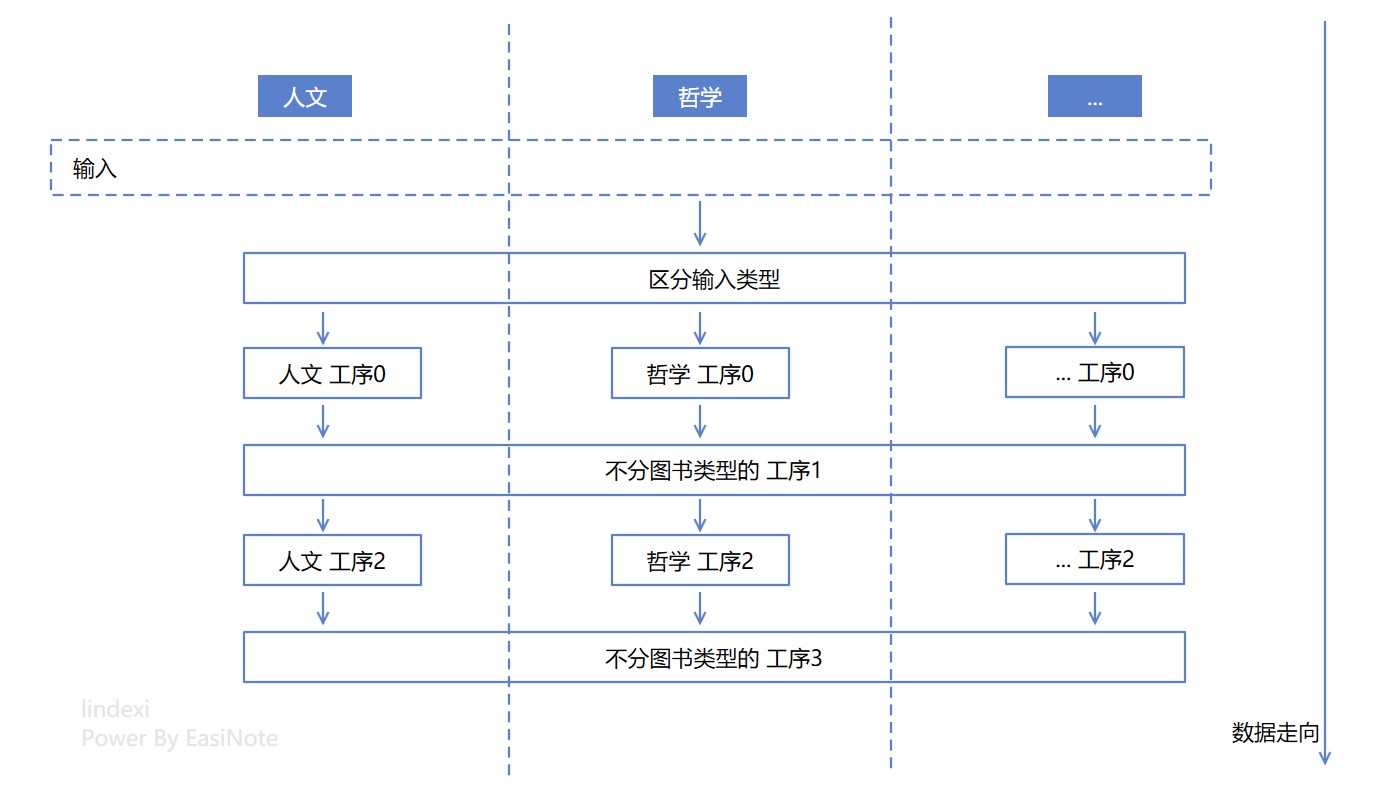
從邏輯上看,以上的邏輯設計是存在很多個圈圈的,相當於不停的拆分、聚合,每一次都是在增加邏輯圈複雜度,這樣的邏輯設計對應到程式碼裡面,大概就是一堆 if 或者 switch 判斷,控制其後續走向,或者是物件導向的繼承關係,讓呼叫穿插在基礎類別和子類之間。假定以上的邏輯設計屬於使用了 一堆 if 或者 switch 判斷的方式,那自然在區分輸入型別和工序1裡面,都會存在判斷書籍型別,以呼叫後續邏輯的程式碼,虛擬碼如下
void 區分輸入型別()
{
if (書籍型別 == 人文)
{
人文_工序0();
}
else if (書籍型別 == 哲學)
{
哲學_工序0();
}
else if(...)
{
...
}
}
void 人文_工序0()
{
// 工序的邏輯
...
不分圖書型別的_工序1();
}
void 哲學_工序0()
{
// 工序的邏輯
...
不分圖書型別的_工序1();
}
void 不分圖書型別的_工序1()
{
// 工序的邏輯
...
if (書籍型別 == 人文)
{
人文_工序2();
}
else if (書籍型別 == 哲學)
{
哲學_工序2();
}
else if(...)
{
...
}
}
...
從以上的虛擬碼也可以看到,在 區分輸入型別 和 不分圖書型別的_工序1 之間,存在邏輯比較相似的程式碼,那就是拆分書籍型別,然後呼叫不同的方法。當書籍的型別足夠多的時候,這個邏輯維護起來就開始令人煩躁起來了,當工序同樣多起來的時候,那就更加不好玩咯
來數數邏輯的圈圈數量,猜猜有多少個圈圈?如下圖示記出來的只有 4 個圈圈對不
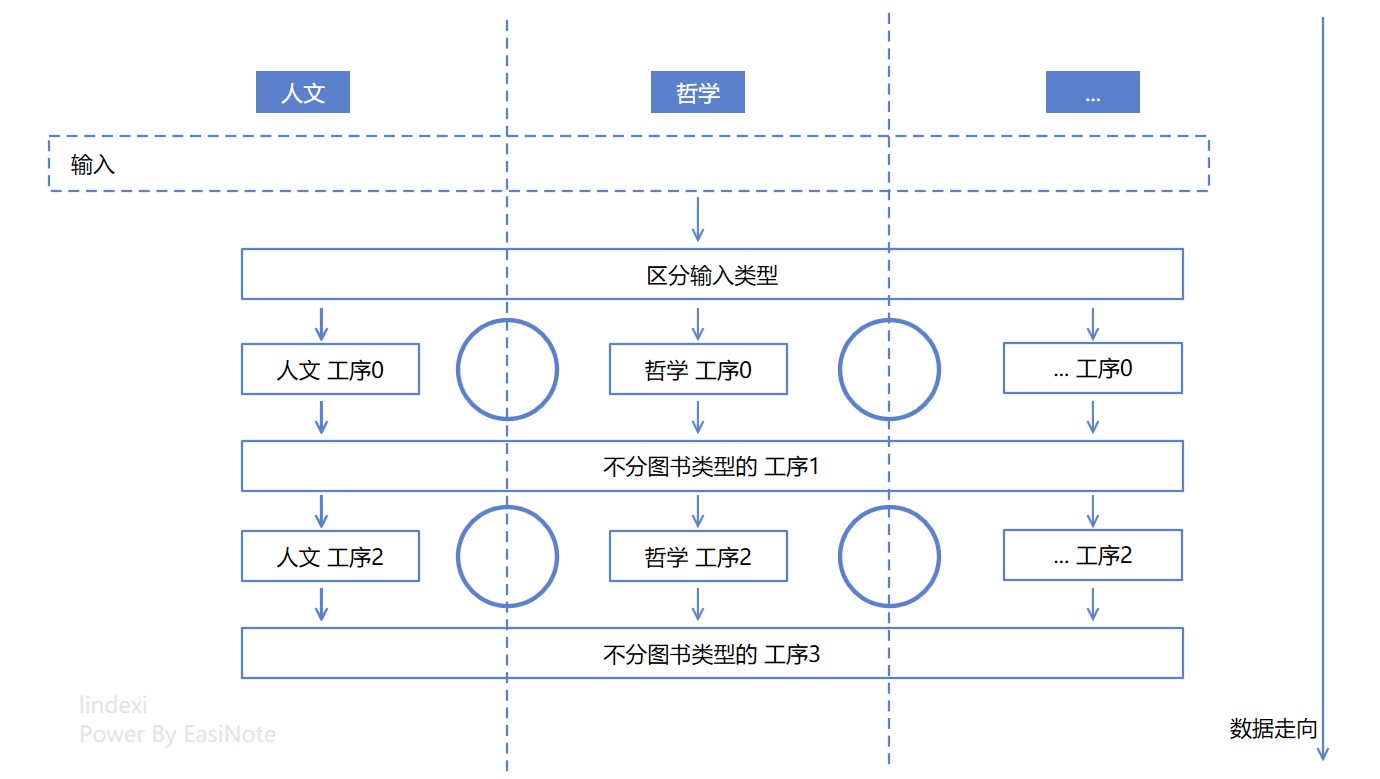
其實沒有那麼簡單。嗯,不嚴謹的算,上面的邏輯設計圖至少有 9 個圈圈
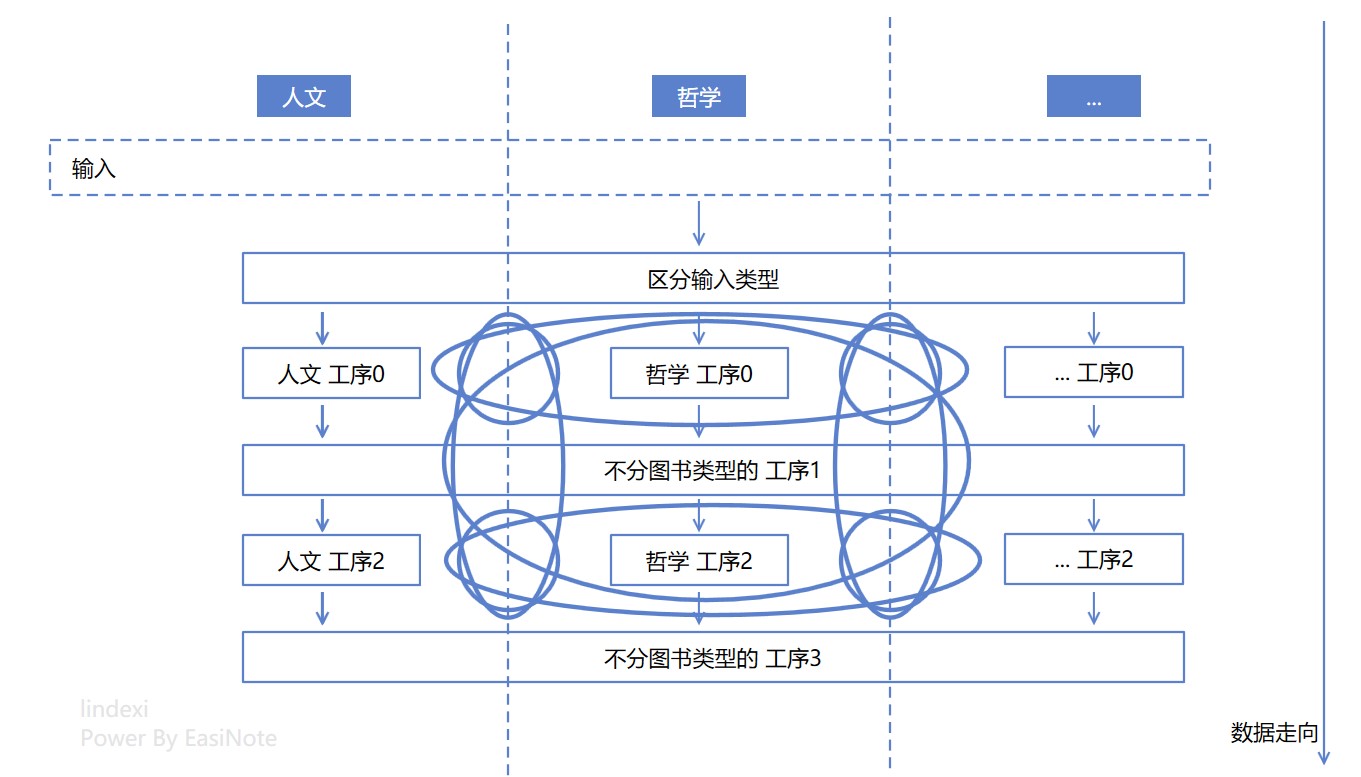
如果列出更多的書籍型別,以及更多的工序,那這個圈的數量能夠更加龐大
大家也可以想想看,每加一個書籍型別,會加多少個圈圈?世界上還有一群專家也在研究加一個模組或一個功能時,圈複雜度的增加速率。在某些時候的設計上,會導致加一個模組或加一個功能時,增加的圈圈數量會越來越多。例如上面的邏輯設計圖在兩個書籍型別,也就是兩個模組時,只有三個圈圈,但是在有三個模組時,就有 9 個圈圈了。也可以看到,隨著書籍型別的數量,也就是模組的數量,不斷增加的時候,每加一個時,增加的圈圈數量會越來越多,這也就表示了邏輯複雜度每次增加都會越來越多
換一句話說,如果按照上面的邏輯設計圖的方式進行開發,會發現越開發越複雜。即使開發者有著很好的編寫程式碼的能力,也會逐漸發現整個專案越來越難以掌控。在設計上存在將會導致必然出現的程式碼邏輯圈複雜度時,會導致專案在開發過程中是上帝和程式猿才能看懂程式碼,開發一定時間之後,就只有上帝才能看懂程式碼了
在瞭解基礎的知識之後,大家也許會問,那如何改造降低圈複雜度呢?一個套路方法就是在區分型別之後,讓資料的走向被具體型別進行控制,這也是物件導向裡,多型的一個用法。具體來做就是在 區分輸入型別 的型別之後,進入某個型別的書籍的總處理方法,在某個型別的總處理方法裡面,可以愉快的從工序的開始執行到工序的結束
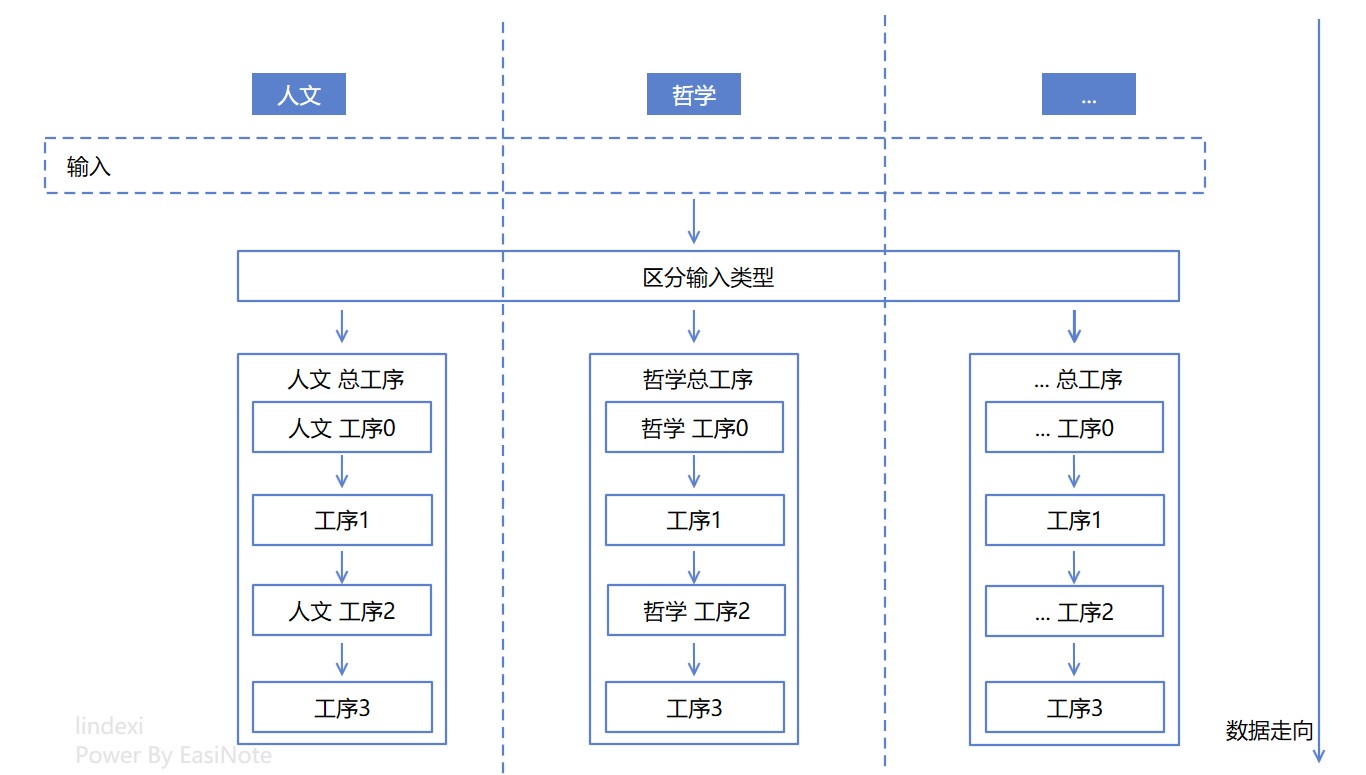
再來數一下邏輯的圈複雜度,是不是一個圈也數不到了?對應的程式碼大概如下,可以看到每個總工序裡面處理的邏輯一目瞭然
void 人文_總工序()
{
人文_工序0();
工序1();
人文_工序2();
工序3();
}
void 哲學_總工序()
{
哲學_工序0();
工序1();
哲學_工序2();
工序3();
}
啥都不用說,對比程式碼量就知道,看程式碼的清晰程度也能看起來降低圈複雜度之後的優化
那這時,也許有夥伴說,如果各個總工序都十分相似,是不是也可以再抽一下?是的,但是也需要看情況,如果少部分的重複邏輯可以帶來更多的程式碼清晰度,那這部分的邏輯留著也是可以接受的。但如果在抽一下基礎型別之後,發現邏輯依然清晰,那就開幹吧,畢竟重複的邏輯也不是什麼好的事情
定義一個書籍處理的抽象基礎類別,然後在此基礎類別裡面放總工序,接著各個具體的書籍處理型別,繼承基礎類別,編寫實現方法,虛擬碼如下
abstract class 書籍管理基礎類別
{
public void 總工序()
{
工序0();
工序1();
工序2();
工序3();
}
protected abstract void 工序0();
private void 工序1()
{
// ...
}
protected abstract void 工序2();
private void 工序3()
{
// ...
}
}
class 人文書籍管理 : 書籍管理基礎類別
{
protected override void 工序0()
{
人文_工序0();
}
private void 人文_工序0()
{
// ...
}
protected override void 工序2()
{
人文_工序2();
}
private void 人文_工序2()
{
// ...
}
}
class 哲學書籍管理 : 書籍管理基礎類別
{
protected override void 工序0()
{
哲學_工序0();
}
private void 哲學_工序0()
{
// ...
}
protected override void 工序2()
{
哲學_工序2();
}
private void 哲學_工序2()
{
// ...
}
}
可以看到,這大概也就是一個超級簡單的框架了,具備了一定的擴充套件性,也就是後續如果還需要加上新的書籍型別,也是非常方便的,只需要定義多一個型別即可,同時邏輯上也相對來說比較清真,沒有那麼複雜
以上是藉助 C# 裡面的抽象類實現的,這個套路需要不斷讓子型別進行重寫方法,導致邏輯上可能部分是在基礎類別,部分是在子類。不過以上的程式碼寫法是沒有問題的,因為繼承關係才只有兩層,但如果繼承關係更多了呢?假設有三層甚至更高呢?這時執行邏輯可能需要跨越多個型別,那邏輯複雜度也會上來
假定有如下圖的邏輯,需要按照順序或者是執行時間,分別呼叫方法1到6來完成業務端的任務。當存在讓子型別層層繼承的基礎類別有三個的時候,如果呼叫方法散落在這個基礎類別裡面,那邏輯複雜度將會是非常高的,很多時候靜態閱讀程式碼都非常有難度
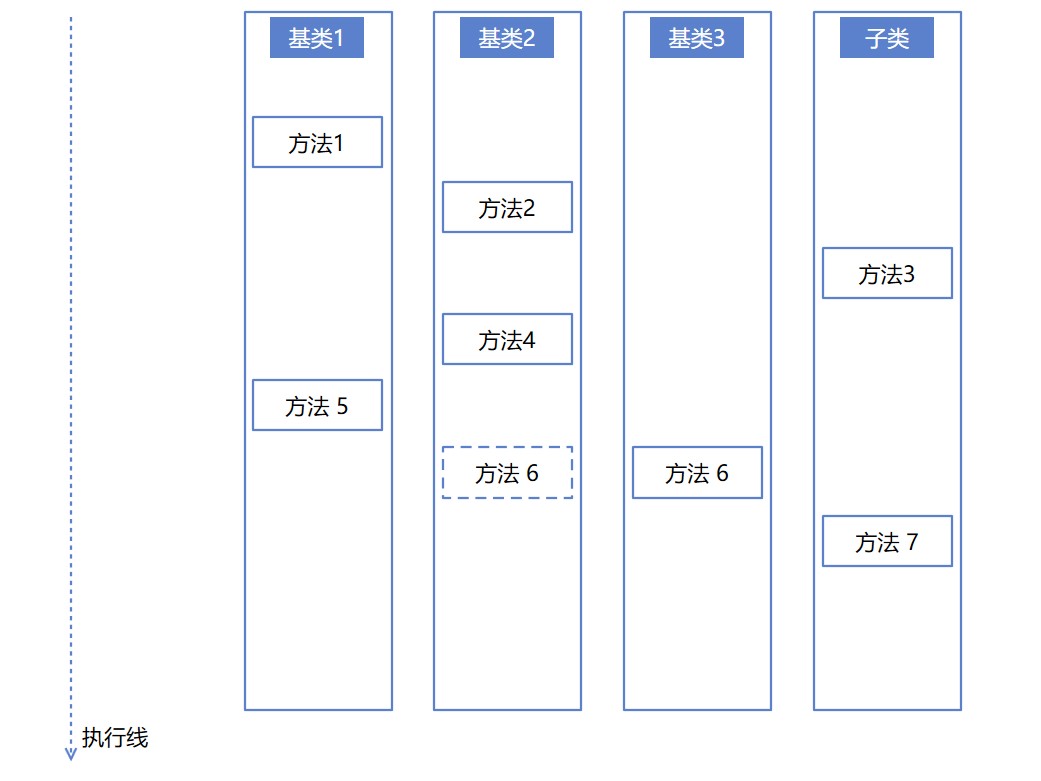
如上圖,假設以上沒有畫出來圖,而是寫成程式碼,那想要靜態閱讀程式碼,瞭解其中的執行邏輯,預計看了一會開始亂了,不知道對應的方法應該在哪個型別裡面,哪個檔案裡面。好在 C# 裡面禁用了多型別繼承,否則能寫出連示意圖畫出來都能勸退人的程式碼。可是 C# 裡面也有一個叫虛方法的定義,允許在基礎類別裡面定義虛方法,看子類的心情去進行重寫,有重寫就使用子類的,沒重寫就採用基礎類別的,上圖裡面的方法 6 是一個虛方法,在基礎類別 2 裡面定義,但是在 基礎類別 3 被重寫。這時將會發現靜態閱讀的程式碼,不見得就是實際執行的程式碼。例如閱讀到基礎類別 2 裡面定義了方法 6 的邏輯,然而實際執行的時候,執行的是基礎類別 3 的邏輯
這裡需要補充一點的是靜態閱讀程式碼指的是和偵錯閱讀程式碼相對的閱讀程式碼方式,指的是在不開始進行偵錯的方式進行閱讀程式碼,可以在 IDE 的輔助下,例如在 VisualStudio 這樣的 IDE 輔助下閱讀程式碼。好維護的程式碼是需要考慮靜態閱讀程式碼的,因為很多時候偵錯的時候能跑的路徑不會特別全,也不會特別多,甚至有些邏輯是存在很多前置條件的,僅靠偵錯來了解執行方式,可能瞭解到不全面
這也是某些開發老司機會說的「組合優於繼承」的其中一點原因,大量的繼承將會導致邏輯散落在各地,不夠「內聚」導致邏輯複雜度上升。值得一提是 「組合優於繼承」 這句話是具備大量前提的,還請不要將這句話作為開發的規範
那什麼時候應該選擇什麼方法?其實十分主觀,我的推薦是多試試看,寫多了,然後將自己坑多了,自然就知道了。主動去看自己之前寫過的複雜邏輯(最好別去看別人的,否則心態可能會炸)看看是否會感覺自己無法理解邏輯,如果會的話,再想想可以使用什麼方式,如果再寫一次的話,可以更加方便閱讀程式碼理清邏輯
回顧一下,本文告訴了大傢什麼是程式碼邏輯圈複雜度,以及降低邏輯圈複雜度的套路方法。同時也告訴了大家,這個套路也不是萬能的,做的不好也可以提升程式碼複雜度
更多程式碼編寫相關部落格,請參閱我的 部落格導航
特別感謝 小方 幫忙改正
部落格園部落格只做備份,部落格釋出就不再更新,如果想看最新部落格,請到 https://blog.lindexi.com/

本作品採用知識共用署名-非商業性使用-相同方式共用 4.0 國際許可協定進行許可。歡迎轉載、使用、重新發布,但務必保留文章署名[林德熙](https://www.cnblogs.com/lindexi)(包含連結:https://www.cnblogs.com/lindexi ),不得用於商業目的,基於本文修改後的作品務必以相同的許可釋出。如有任何疑問,請與我[聯絡](mailto:[email protected])。