雖然是我遇到的一個棘手的生產問題,但是我寫出來之後,就是你的了。
你好呀,是歪歪。
前幾天,就在大家還沉浸在等待春節到來的喜悅氛圍的時候,在一個核心鏈路上的核心繫統中,我踩到一個坑的一比的坑,要不是我沉著冷靜,解決思路忙中有序,處理手段雷厲風行,把它給扼殺在萌芽階段了,那這玩意肯定得引發一個比較嚴重的生產問題。
從問題出現到定位到這個問題的根本原因,我大概是花了兩天半的時間。
所以寫篇文章給大家覆盤一下啊,這個案例就是一個純技術的問題導致的,和業務的相關度其實並不大,所以你拿過去直接添油加醋,稍微改改,往自己的服務上套一下,那就是你的了。
我再說一次:雖然現在不是你的,但是你看完之後就是你的了,你明白我意思吧?
表象
事情是這樣的,我這邊有一個服務,你可以把這個服務粗暴的理解為是一個商城一樣的服務。有商城肯定就有下單嘛。
然後接到上游服務反饋,說呼叫下單介面偶爾有呼叫超時的情況出現,斷斷續續的出現好幾次了,給了幾筆流水號,讓我看一下啥情況。當時我的第一反應是不可能是我這邊服務的問題,因為這個服務上次上線都至少是一個多月前的事情了,所以不可能是由於近期服務投產導致的。
但是下單介面,你聽名字就知道了,核心連結上的核心功能,不能有一點麻痺大意。
每一個請求都很重要,客戶下單體驗不好,可能就不買了,造成交易損失。
交易上不去營業額就上不去,營業額上不去利潤就上不去,利潤上不去年終就上不去。
想到這一層關係之後,我立馬就登陸到伺服器上,開始定位問題。
一看紀錄檔,確實是我這邊介面請求處理慢了,導致的呼叫方超時。
為什麼會慢呢?

於是按照常規思路先根據紀錄檔判斷了一下下單介面中呼叫其他服務的介面相應是否正常,從資料庫獲取資料的時間是否正常。
這些判斷沒問題之後,我轉而把目光放到了 gc 上,通過監控發現那個時間點觸發了一次耗時接近 1s 的 full gc,導致響應慢了。
由於我們監控只採集服務近一週的 gc 資料,所以我把時間拉長後發現 full gc 在這一週的時間內出現的頻率還有點高,雖然我還沒定位到問題的根本原因,但是我定位到了問題的表面原因,就是觸發了 full gc。
因為是核心鏈路,核心流程,所以此時不應該急著去定位根本原因,而是先緩解問題。
好在我們提前準備了各種原因的應急預案,其中就包含這個場景。預案的內容就是擴大應用堆記憶體,延緩 full gc 的出現。
所以我當即進行操作報備並聯絡運維,按照緊急預案執行,把服務的堆記憶體由 8G 擴大一倍,提升到 16G。
雖然這個方法簡單粗暴,但是既解決了當前的呼叫超時的問題,也給了我足夠的排查問題的時間。

定位原因
當時我其實一點都不慌的,因為問題在萌芽階段的時候我就把它給幹掉了。

不就是 full gc 嗎,哦,我的老朋友。
先大膽假設一波:程式裡面某個邏輯不小心搞出了大物件,觸發了 full gc。
所以我先是雙手插兜,帶著監控圖和紀錄檔請求,閒庭信步的走進專案程式碼裡面,想要憑藉肉眼找出一點蛛絲馬跡......

沒有任何收穫,因為下單服務涉及到的邏輯真的是太多了,服務裡面 List 和 Map 隨處可見,我很難找到到底哪裡是大物件。
但是我還是一點都不慌,因為這半天都沒有再次發生 Full GC,說明此時留給我的時間還是比較充足的,
所以我請求了場外援助,讓 DBA 幫我匯出一下服務的慢查詢 SQL,因為我想可能是從資料庫裡面一次性取的資料太多了,而程式裡面也沒有做控制導致的。
我之前就踩過類似的坑。
一個根據客戶號查詢客戶有多少訂單的內部使用介面,介面的返回是 List<訂單>,看起來沒啥毛病,對不對?
一般來說一個個人客戶就幾十上百,多一點的上千,頂天了的上萬個訂單,一次性拿出來也不是不可以。
但是有一個客戶不知道咋回事,特別鍾愛我們的平臺,也是我們平臺的老客戶了,一個人居然有接近 10w 的訂單。
然後這麼多訂單物件搞到到專案裡面,本來響應就有點慢,上游再發起幾次重試,直接觸發 Full gc,降低了服務響應時間。
所以,經過這個事件,我們定了一個規矩:用 List、Map 來作為返回物件的時候,必須要考慮一下極端情況下會返回多少資料回去。即使是內部使用,也最好是進行分頁查詢。
好了,話說回來,我拿到慢查詢 SQL 之後,根據幾個 Full gc 時間點,對比之後提取出了幾條看起來有點問題的 SQL。
然後拿到資料庫執行了一下,發現返回的資料量其實也都不大。
此刻我還是一點都不慌,反正記憶體夠用,而且針對這類問題,我還有一個場外援助沒有使用呢。
第二天我開始找運維同事幫我每隔 8 小時 Dump 一次記憶體檔案,然後第三天我開始拿著記憶體檔案慢慢分析。
但是第二天我也沒閒著,根據現有的線索反覆分析、推理可能的原因。
然後在觀看 GC 回收記憶體大小監控的時候,發現了一點點端倪。因為觸發 Full GC 之後,發現被回收的堆記憶體也不是特別多。
當時就想到了除了大物件之外,還有一個現象有可能會導致這個現象:記憶體洩露。
巧的是在第二天又發生了一次 Full gc,這樣我拿到的 Dump 檔案就更有分析的價值了。基於前面的猜想,我分析的時候直接就衝著記憶體漏失的方向去查了。
我拿著 5 個 Dump 檔案,分析了在 5 個 Dump 檔案中物件數量一直在增加的物件,這樣的物件也不少,但是最終定位到了 FutureTask 物件,就是它:
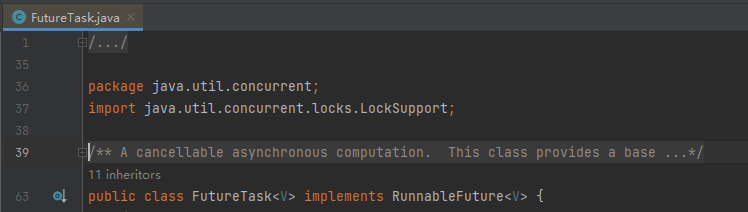
找到這玩意了再回去定位對應部分的程式碼就比較容易。
但是你以為定位了程式碼就完事了嗎?
不是的,到這裡才剛剛開始,朋友。
因為我發現這個程式碼對應的 Bug 隱藏的還是比較深的,而且也不是我最開始假象的記憶體洩露,就是一個純粹的記憶體溢位。
所以值得拿出來仔細嗦一嗦。
範例程式碼
為了讓你沉浸式體驗找 BUG 的過程,我高低得給你整一個可復現的 Demo 出來,你拿過去就可以跑的那種。
首先,我們得搞一個執行緒池:
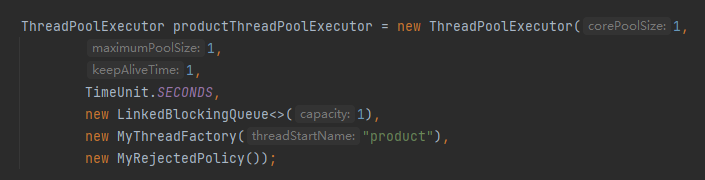
需要說明一下的是,上面這個執行緒池的核心執行緒數、最大執行緒數和佇列長度我都取的 1,只是為了方便演示問題,在實際專案中是一個比較合理的值。
然後重點看一下執行緒池裡面有一個自定義的叫做 MyThreadFactory 的執行緒工廠類和一個自定義的叫做 MyRejectedPolicy 的拒絕策略。
在我的服務裡面就是有這樣一個叫做 product 的執行緒池,用的也是這個自定義拒絕策略。
其中 MyThreadFactory 的程式碼是這樣的:
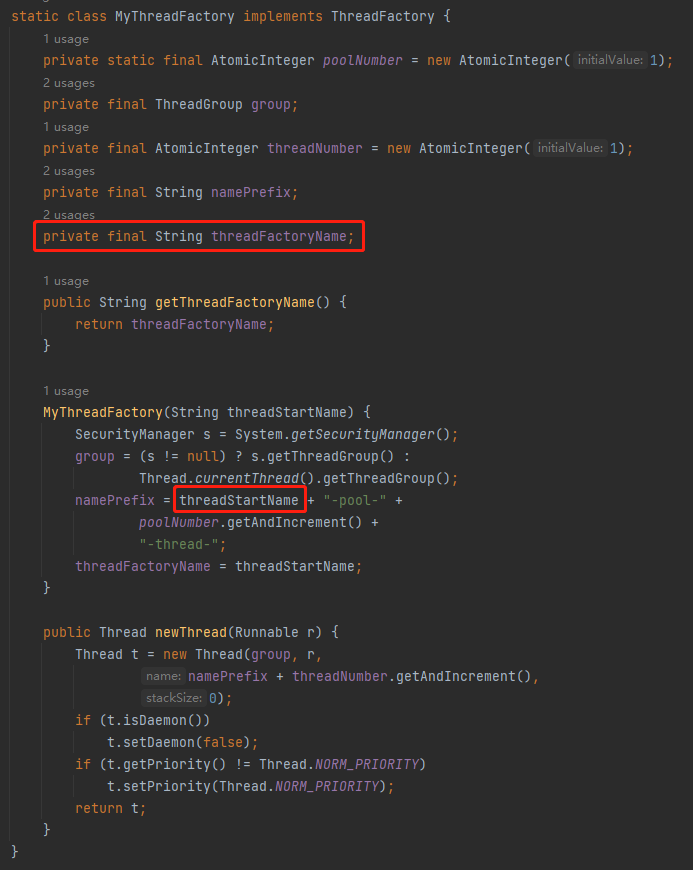
它和預設的執行緒工廠之間唯一的區別就是我加了一個 threadFactoryName 欄位,方便給執行緒池裡面的執行緒取一個合適的名字。
更直觀的表示一下區別就是下面這個玩意:
原生:pool-1-thread-1
自定義:product-pool-1-thread-1
接下來看自定義的拒絕策略:
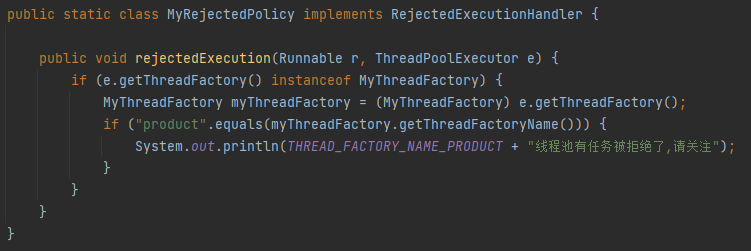
這裡的邏輯很簡單,就是當 product 執行緒池滿了,觸發了拒絕策略的時候列印一行紀錄檔,方便後續定位。
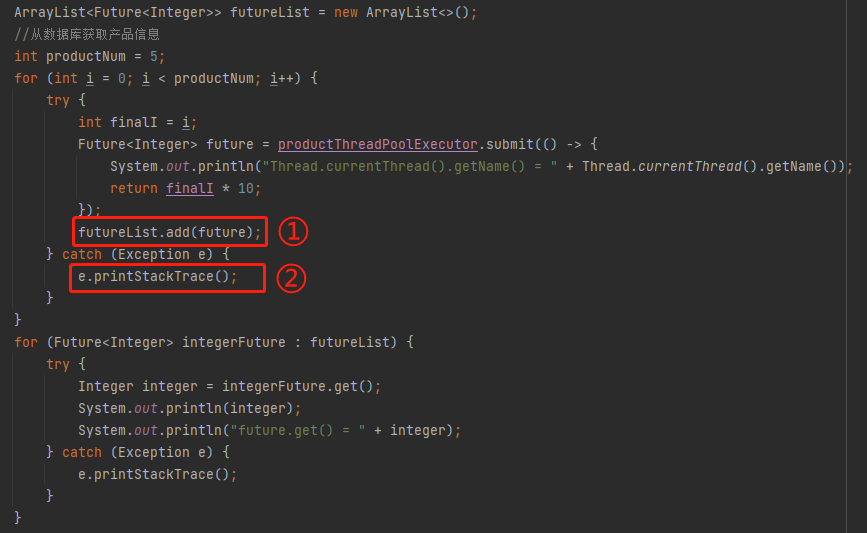
然後接著看其他部分的程式碼:
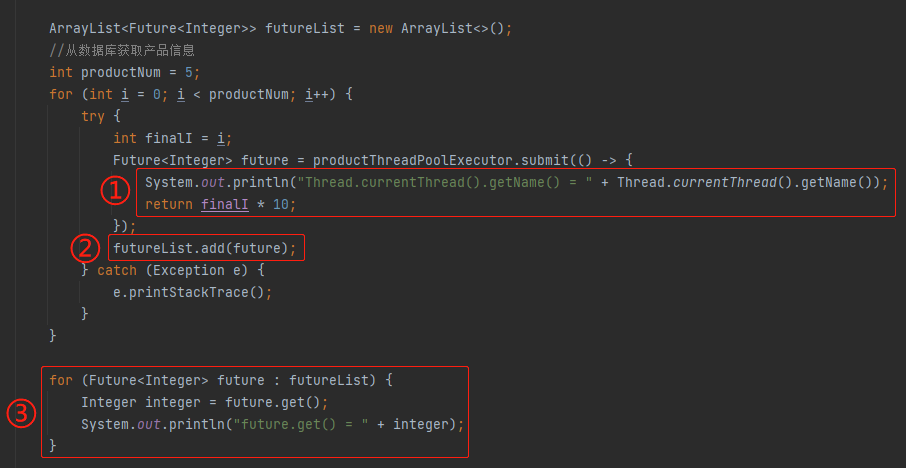
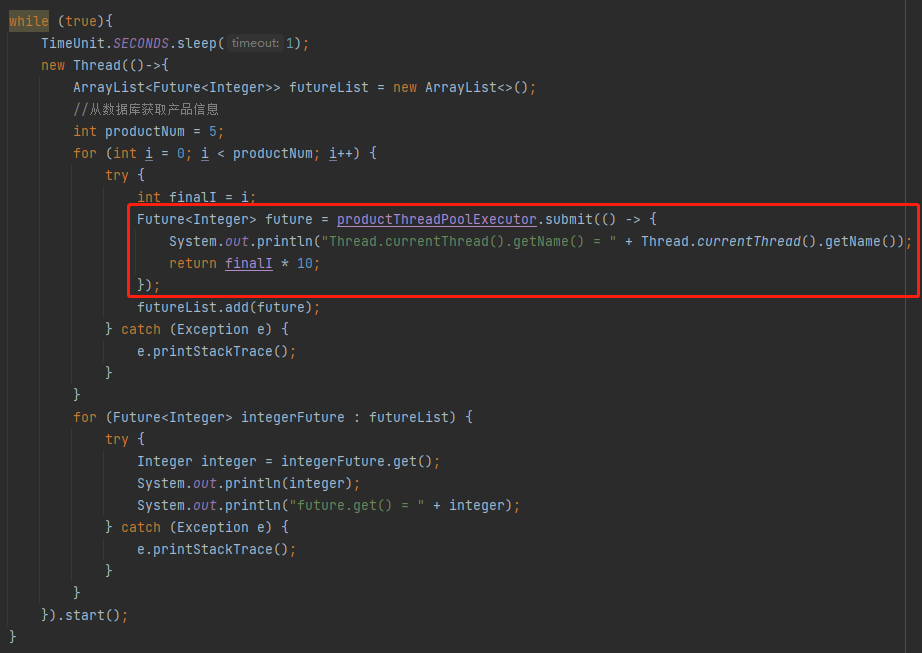
標號為 ① 的地方是執行緒池裡面執行的任務,我這裡只是一個示意,所以邏輯非常簡單,就是把 i 擴大 10 倍。實際專案中執行的任務業務邏輯,會複雜一點,但是也是有一個 Future 返回。
標號為 ② 的地方就是把返回的 Future 放到 list 集合中,在標號為 ③ 的地方迴圈處理這個 list 物件裡面的 Future。
需要注意的是因為範例中的執行緒池最多容納兩個任務,但是這裡卻有五個任務。我這樣寫的目的就是為了方便觸發拒絕策略。
然後在實際的專案裡面剛剛提到的這一坨邏輯是通過定時任務觸發的,所以我這裡用一個死迴圈加手動開啟執行緒來示意:
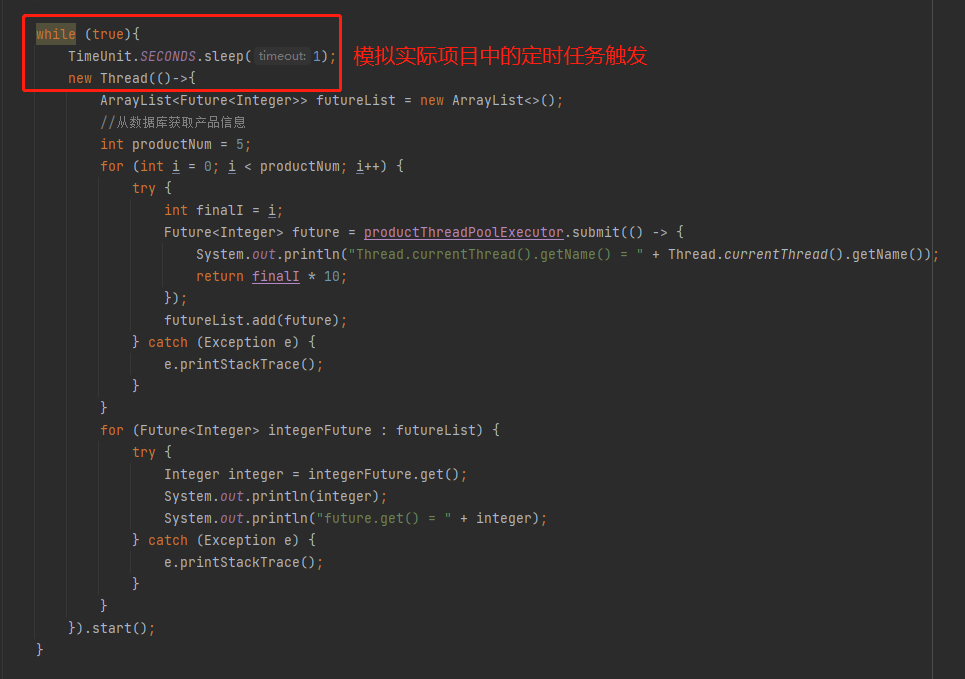
整個完整的程式碼就是這樣的,你直接粘過去就可以跑,這個案例就可以完全復現我在生產上遇到的問題:
public class MainTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor productThreadPoolExecutor = new ThreadPoolExecutor(1,
1,
1,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(1),
new MyThreadFactory("product"),
new MyRejectedPolicy());
while (true){
TimeUnit.SECONDS.sleep(1);
new Thread(()->{
ArrayList<Future<Integer>> futureList = new ArrayList<>();
//從資料庫獲取產品資訊
int productNum = 5;
for (int i = 0; i < productNum; i++) {
try {
int finalI = i;
Future<Integer> future = productThreadPoolExecutor.submit(() -> {
System.out.println("Thread.currentThread().getName() = " + Thread.currentThread().getName());
return finalI * 10;
});
futureList.add(future);
} catch (Exception e) {
e.printStackTrace();
}
}
for (Future<Integer> integerFuture : futureList) {
try {
Integer integer = integerFuture.get();
System.out.println(integer);
System.out.println("future.get() = " + integer);
} catch (Exception e) {
e.printStackTrace();
}
}
}).start();
}
}
static class MyThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
private final String threadFactoryName;
public String getThreadFactoryName() {
return threadFactoryName;
}
MyThreadFactory(String threadStartName) {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = threadStartName + "-pool-" +
poolNumber.getAndIncrement() +
"-thread-";
threadFactoryName = threadStartName;
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
public static class MyRejectedPolicy implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (e.getThreadFactory() instanceof MyThreadFactory) {
MyThreadFactory myThreadFactory = (MyThreadFactory) e.getThreadFactory();
if ("product".equals(myThreadFactory.getThreadFactoryName())) {
System.out.println(THREAD_FACTORY_NAME_PRODUCT + "執行緒池有任務被拒絕了,請關注");
}
}
}
}
}
你跑的時候可以把堆記憶體設定的小一點,比如我設定為 10m:
-Xmx10m -Xms10m
然後用 jconsole 監控,你會發現記憶體走勢圖是這樣的:
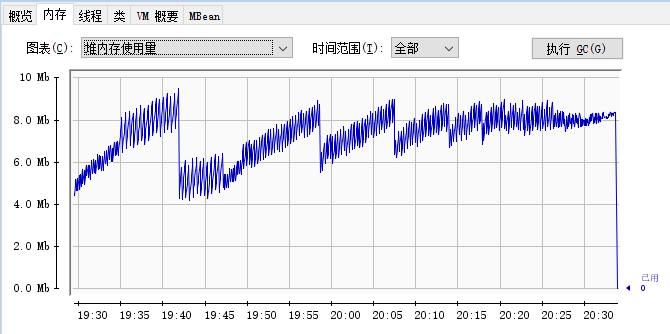
哦,我的老天爺啊,這個該死的圖,也是我的老夥計了,一個緩慢的持續上升的記憶體趨勢圖, 最後瘋狂的觸發 gc,但是並沒有記憶體被回收,最後程式直接崩掉:
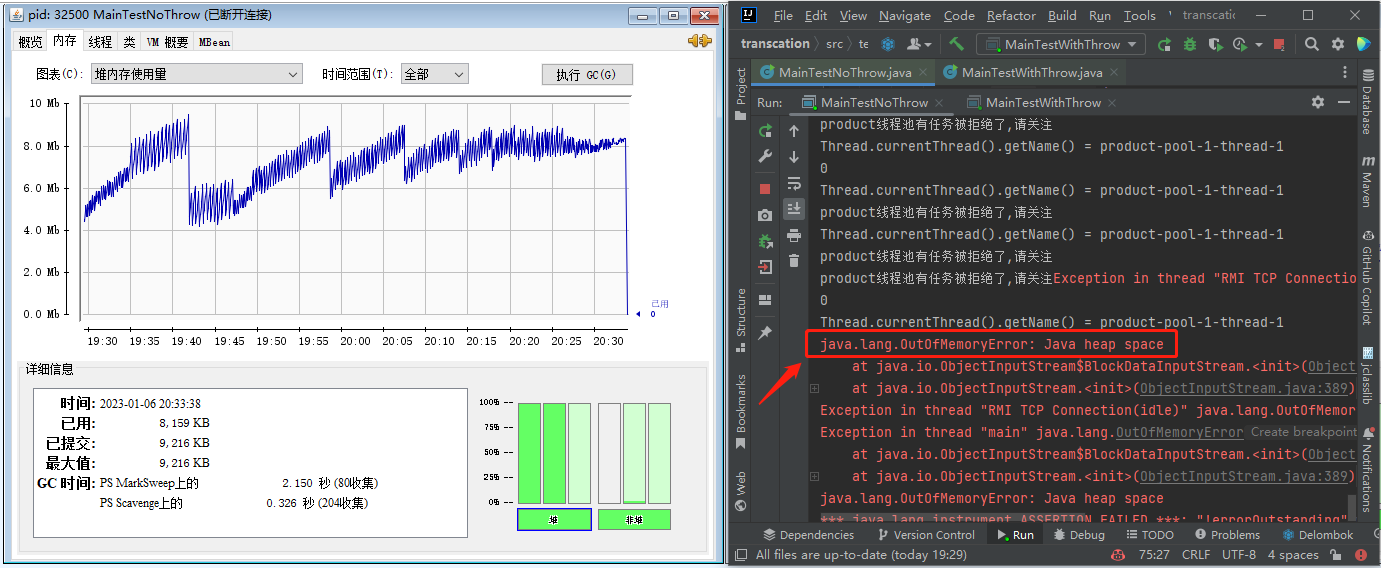
這絕大概率就是記憶體漏失了啊。
但是在生產上的記憶體走勢圖完全看不出來這個趨勢,我前面說了,主要因為 GC 情況的資料只會保留一週時間,所以就算把整個圖放出來也不是那麼直觀。
其次不是因為我牛逼嘛,萌芽階段就幹掉了這個問題,所以沒有遇到最後頻繁觸發 gc,但是沒啥回收的,導致 OOM 的情況。
所以我再帶著你看看另外一個視角,這是我真正定位到問題的視角。就是分析記憶體 Dump 檔案。
分析記憶體 Dump 檔案的工具以及相關的文章非常的多,我就不贅述了,你隨便找個工具玩一玩就行。我這裡主要是分享一個思路,所以就直接使用 idea 裡面的 Profiler 外掛了,方便。
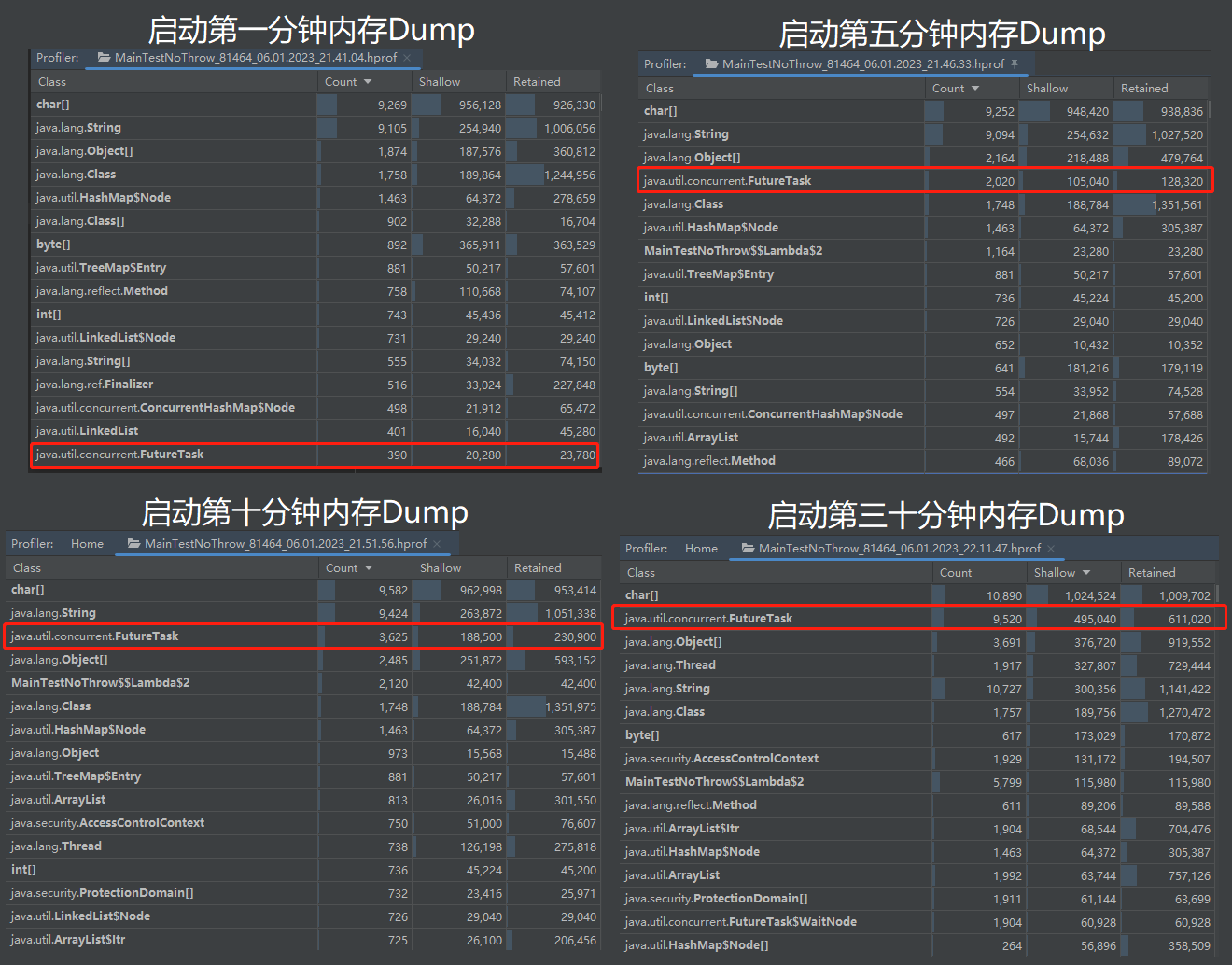
我用上面的程式碼,啟動起來之後在四個時間點分別 Dump 之後,觀察記憶體檔案。記憶體洩露的思路就是找檔案裡面哪個物件的個數和佔用空間是在持續上升嘛,特別是中間還發生過 full gc,這個過程其實是一個比較枯燥且複雜的過程,在生產專案中可能會分析出很多個這樣的物件,然後都要到程式碼裡面去定位相關邏輯。
但是我這裡極大的簡化了程式,所以很容易就會發現這個 FutureTask 物件特別的搶眼,數量在持續增加,而且還是名列前茅的:
然後這個工具還可以看物件佔用大小,大概是這個意思:
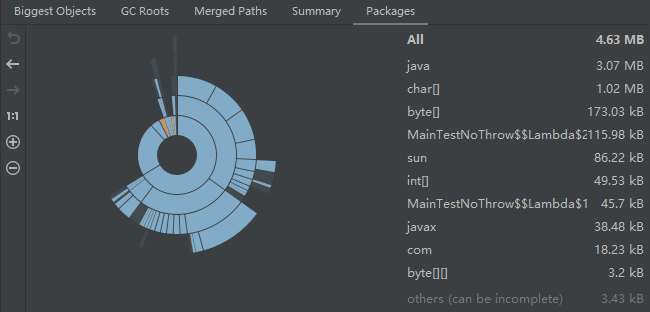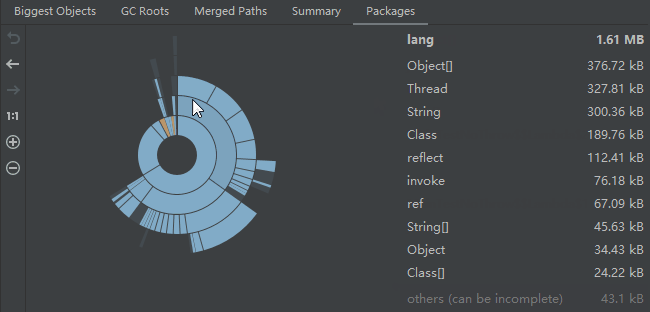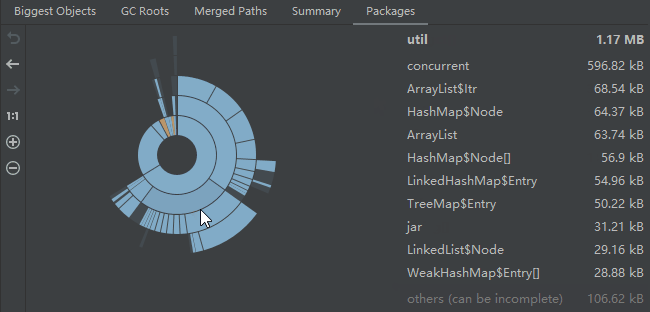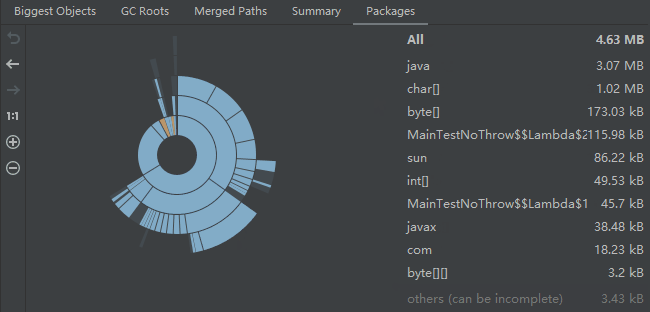
所以我還可以看看在這幾個檔案中 FutureTask 物件大小的變化,也是持續增加:
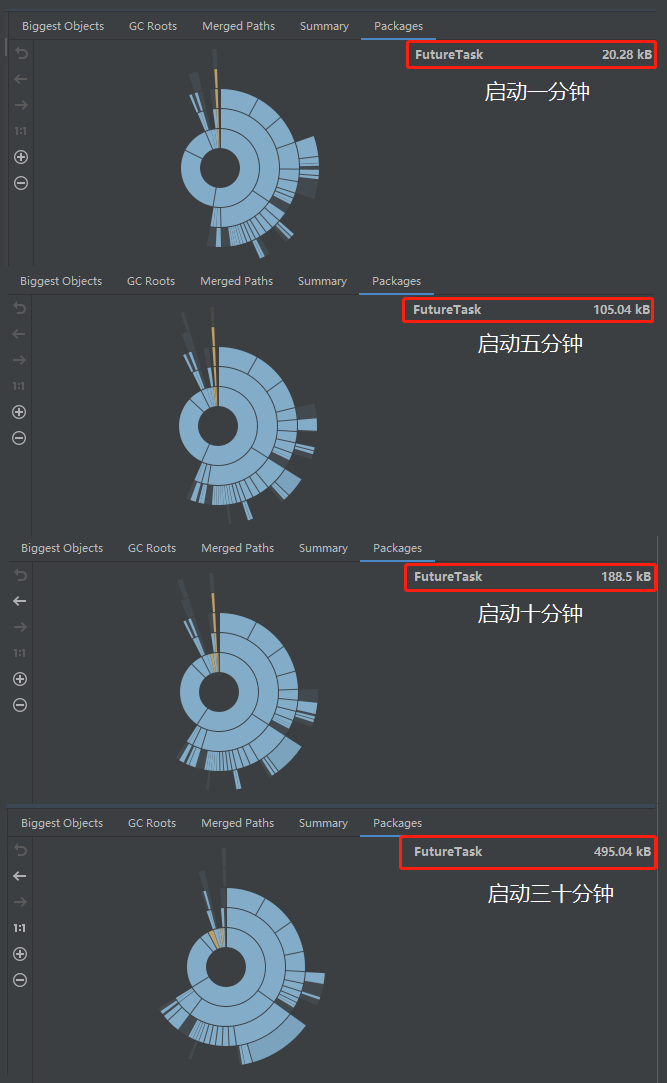
就它了,準沒錯。
好,問題已經能復現了,GC 圖和記憶體 Dump 的圖也都給你看了。
到這裡,如果有人已經看出來問題的原因了,可以直接拉到文末點個贊,感謝大佬閱讀我的文章。
如果你還沒看出端倪來,那麼我先給你說問題的根本原因:
問題的根本原因就出在 MyRejectedPolicy 這個自定義拒絕策略上。
在帶你細嗦這個問題之前,我先問一個問題:
JDK 自帶的執行緒池拒絕策略有哪些?
這玩意,老八股文了,存在的時間比我從業的時間都長,得張口就來:
AbortPolicy:丟棄任務並丟擲 RejectedExecutionException 異常,這是預設的策略。 DiscardOldestPolicy:丟棄佇列最前面的任務,執行後面的任務 CallerRunsPolicy:由呼叫執行緒處理該任務 DiscardPolicy:也是丟棄任務,但是不丟擲異常,相當於靜默處理。
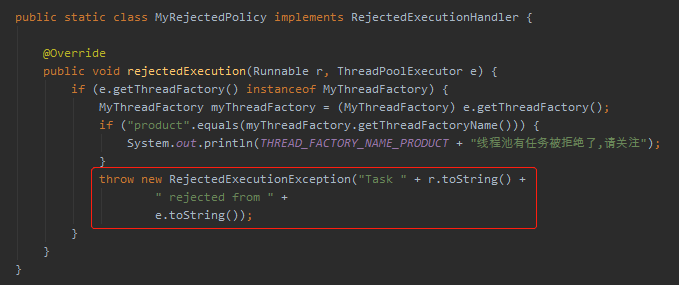
然後你再回頭看看我的自定義拒絕策略,是不是和 DiscardPolicy 非常像,也沒有丟擲異常。只是比它更高階一點,列印了一點紀錄檔。
當我們使用預設的策略的時候:
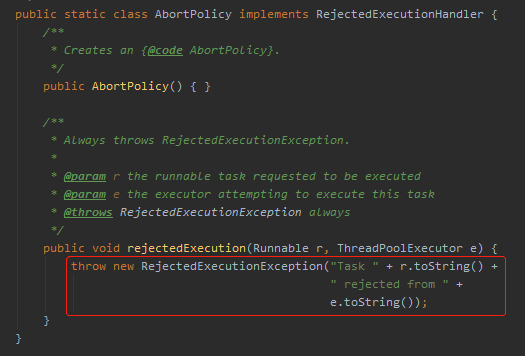
或者我們把框起來這行程式碼粘到我們的 MyRejectedPolicy 策略裡面:
再次執行,不管是觀察 gc 情況,還是 Dump 記憶體,你會發現程式正常了,沒毛病了。
下面這個走勢圖就是在拒絕策略中是否丟擲異常對應的記憶體走勢對比圖:
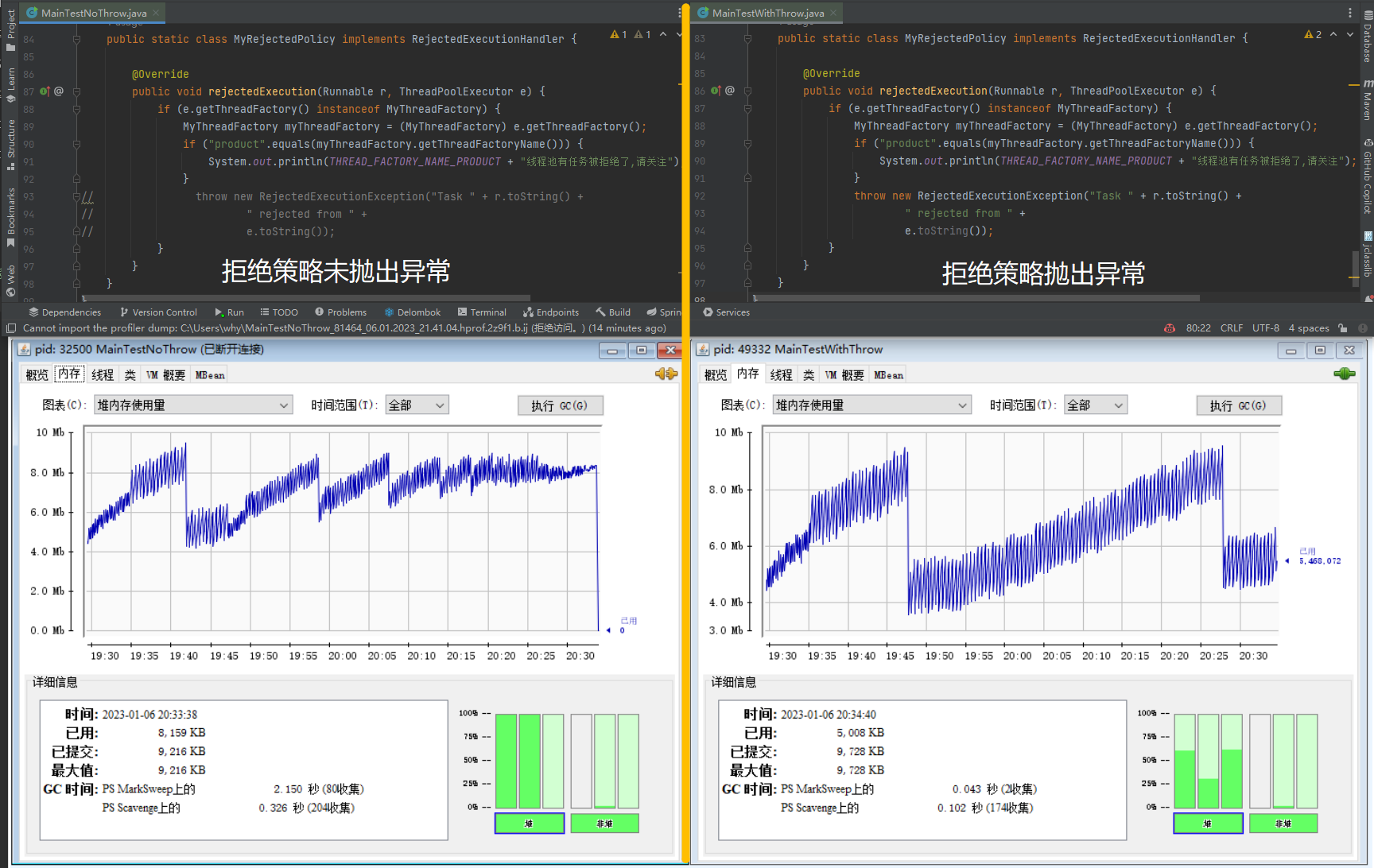
在拒絕策略中丟擲異常就沒毛病了,為啥?

探索
首先,我們來看一下沒有丟擲異常的時候,發生了什麼事情。
沒有丟擲異常時,我們前面分析了,出現了非常多的 FutureTask 物件,所以我們就找程式裡面這個物件是哪裡出來的,定位到這個地方:
future 沒有被回收,說明 futureList 物件沒有被回收,而這兩個物件對應的 GC Root 都是new 出來的這個執行緒,因為一個活躍執行緒是 GC Root。
進一步說明對應 new 出來的執行緒沒有被回收。
所以我給你看一下前面兩個案例對應的執行緒數對比圖:
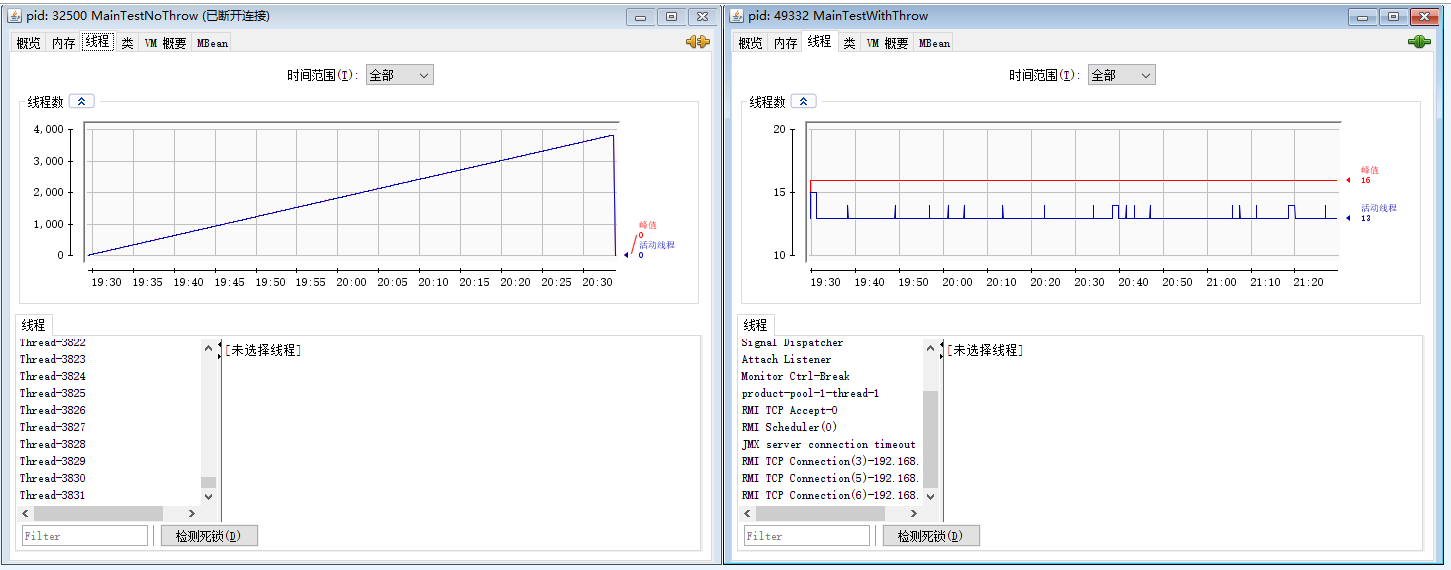
沒有在拒絕策略中丟擲異常的執行緒非常的多,看起來每一個都沒有被回收,這個地方肯定就是有問題的。
然後隨機選一個檢視詳情,可以看到執行緒在第 39 行卡著的:
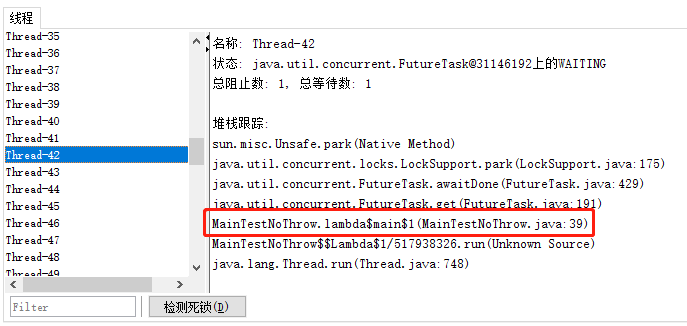
也就是這樣一行程式碼:
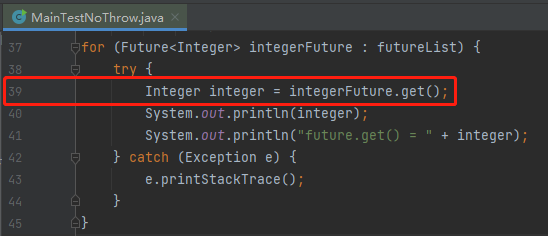
這個方法大家應該熟悉,因為也沒有給等待時間嘛,所以如果等不到 Future 的結果,執行緒就會在這裡死等。
也就導致執行緒不會執行結束,所以不會被回收。
對應著原始碼說就是有 Future 的 state 欄位,即狀態不正確,導致執行緒阻塞在這個 if 裡面:
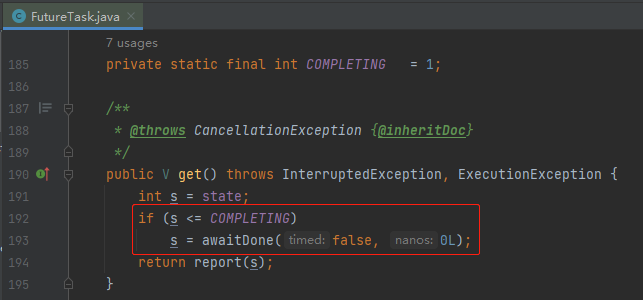
if 裡面的 awaitDone 邏輯稍微有一點點複雜,這個地方其實還有一個 BUG,在 JDK 9 進行了修復,這一點我在之前的文章中寫過,所以就不贅述了,你有興趣可以去看看:《Doug Lea在J.U.C包裡面寫的BUG又被網友發現了。》
總之,在我們的案例下,最終會走到我框起來的程式碼:
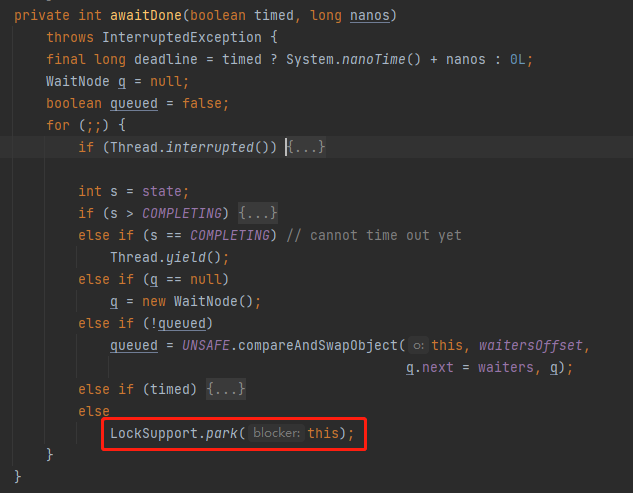
也就是當前執行緒會在這裡阻塞住,等到喚醒。
那麼問題就來了,誰來喚醒它呢?
巧了,這個問題我之前也寫過,在這篇文章中,有這樣一句話:《關於多執行緒中拋異常的這個面試題我再說最後一次!》
如果子執行緒捕獲了異常,該異常不會被封裝到 Future 裡面。是通過 FutureTask 的 run 方法裡面的 setException 和 set 方法實現的。在這兩個方法裡面完成了 FutureTask 裡面的 outcome 變數的設定,同時完成了從 NEW 到 NORMAL 或者 EXCEPTIONAL 狀態的流轉。
帶你看一眼 FutureTask 的 run 方法:
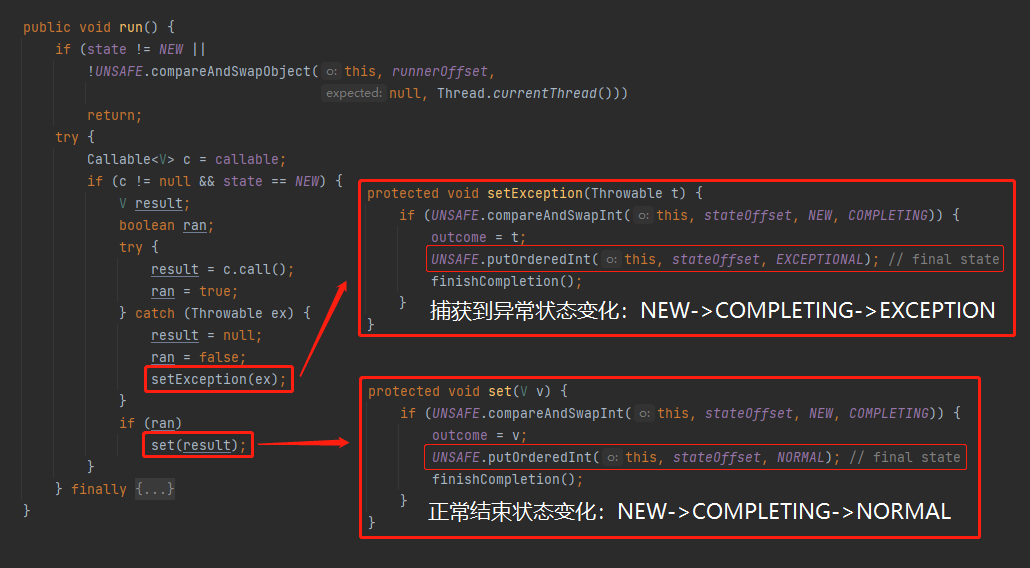
也就是說 FutureTask 狀態變化的邏輯是被封裝到它的 run 方法裡面的。
知道了它在哪裡等待,在哪裡喚醒,揭曉答案之前,還得帶你去看一下它在哪裡誕生。
它的出生地,就是執行緒池的 submit 方法:
java.util.concurrent.AbstractExecutorService#submit
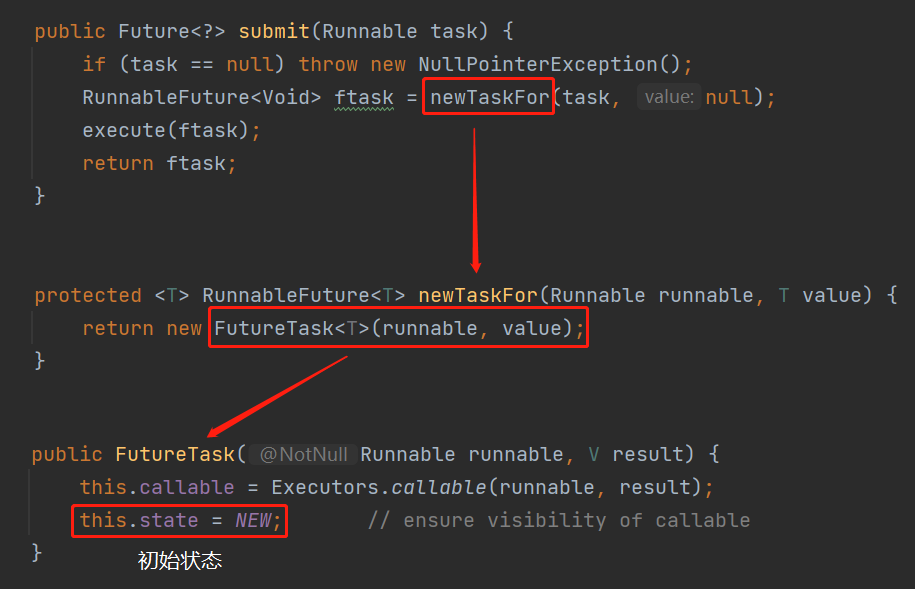
但是,朋友,注意,我要說但是了。
首先,我們看一下當執行緒池的 execute 方法,當執行緒池滿了之後,再次提交任務會觸發 reject 方法,而當前的任務並不會被放到佇列裡面去:
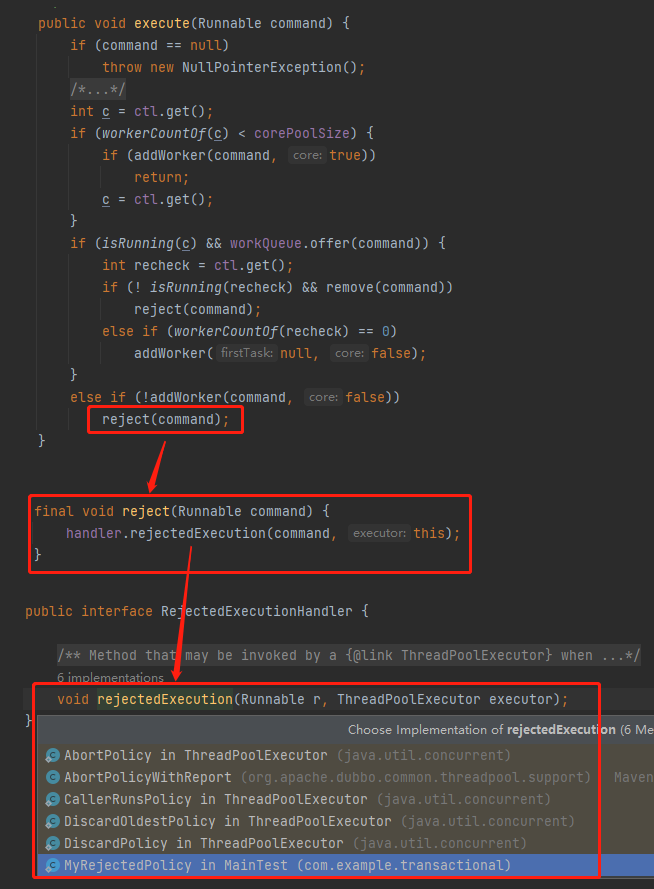
也就是說當 submit 方法不丟擲異常就會把正常返回的這個狀態為 NEW 的 future 放到 futureList 裡面去,即下面編號為 ① 的地方。然後被標號為 ② 的迴圈方法處理:
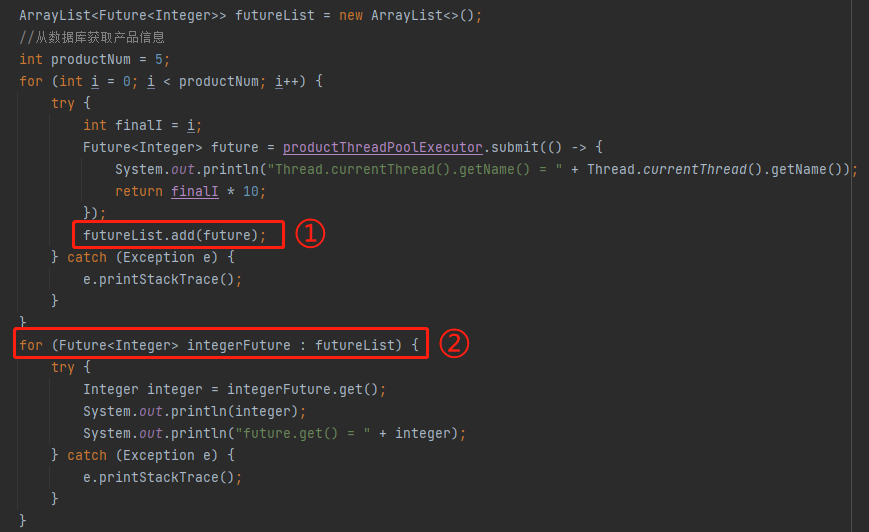
那麼問題就來了:被拒絕了的任務,還會被執行緒池觸發 run 方法嗎?
肯定是不會的,都被拒絕了,還觸發個毛線啊。
不會被觸發 run 方法,那麼這個 future 的狀態就不會從 NEW 變化到 EXCEPTION 或者 NORMAL。
所以呼叫 Future.get() 方法就一定一直阻塞。又因為是定時任務觸發的邏輯,所以導致 Future 物件越來越多,形成一種記憶體洩露。
submit 方法如果丟擲異常則會被標號為 ② 的地方捕獲到異常。
不會執行標號為 ① 的地方,也就不會導致記憶體洩露:
道理就是這麼一個道理。
解決方案
知道問題的根本原因了,解決方案也很簡單。
定位到這個問題之後,我發現專案中的執行緒池引數設定的並不合理,每次定時任務觸發之後,因為資料庫裡面的資料較多,所以都會觸發拒絕策略。
所以首先是調整了執行緒池的引數,讓它更加的合理。當時如果你要用這個案例,這個地方你也可以包裝一下,動態執行緒池,高大上,對吧,以前講過。
然後是呼叫 Future.get() 方法的時候,給一個超時時間,這樣至少能幫我們兜個底。資源能及時釋放,比死等好。
最後就是一個教訓:自定義執行緒池拒絕策略的時候,一定一定記得要考慮到這個場景。
比如我前面丟擲異常的自定義拒絕策略其實還是有問題的,我故意留下了一個坑:
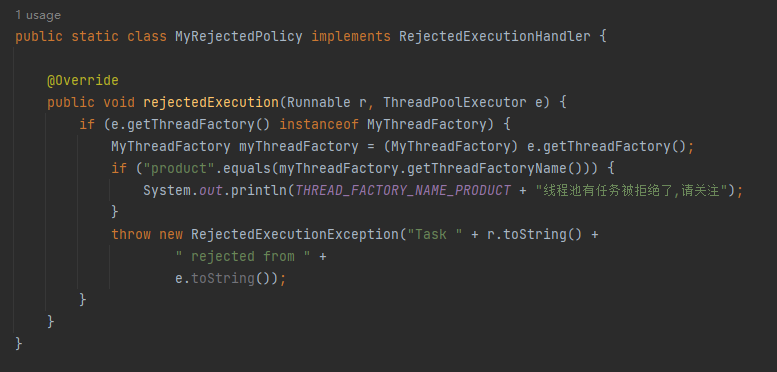
丟擲異常的前提是要滿足最開始的 if 條件:
e.getThreadFactory() instanceof MyThreadFactory
如果別人誤用了這個拒絕策略,導致這個 if 條件不成立的話,那麼這個拒絕策略還是有問題。
所以,應該把丟擲異常的邏輯移到 if 之外。
同時在排查問題的過程中,在專案裡面看到了類似這樣的寫法:

不要這樣寫,好嗎?
一個是因為 submit 是有返回值的,你要是不用返回值,直接用 execute 方法不香嗎?
另外一個是因為你這樣寫,如果執行緒池裡面的任務執行的時候出異常了,會把異常封裝到 Future 裡面去,而你又不關心 Future,相當於把異常給吞了,排查問題的時候你就哭去吧。
這些都是編碼過程中的一些小坑和小注意點。
反轉
這一小節的題目為什麼要叫反轉?
因為以上的內容,除了技術原理是真的,我鋪墊的所有和背景相關的東西,全部都是假的。

整篇文章從第二句開始就是假的,我根本就沒有遇到過這樣的一個生產問題,也談不上扼殺在搖籃裡,更談不上是我去解決的了。
但是我在開始的時候說了這樣一句話,也是全文唯一一句加粗的話:
雖然現在不是你的,但是你看完之後就是你的了,你明白我意思吧?
所以這個背景其實我前幾天看到了「嚴選技術」釋出的這篇文章《嚴選庫存穩定性治理系列:一個執行緒池拒絕策略引發的血案》。
看完他們的這篇文章之後,我想起了我之前寫過的這篇文章:《看起來是執行緒池的BUG,但是我認為是原始碼設計不合理。》
我寫的這篇就是單純從技術角度去解析的這個問題,而「嚴選技術」則是從真實場景出發,層層剝繭,抵達了問題的核心。
但是這兩篇文章遇到的問題的核心原因其實是一模一樣的。
我在我的文章中的最後就有這樣一段話:

巧了,這不是和「嚴選技術」裡面這句話遙相呼應起來了嗎:

在我反覆閱讀了他們的文章,瞭解到了背景和原因之後,我潤色了一下,寫了這篇文章來「騙」你。
如果你有那麼幾個瞬間被我「騙」到了,那麼我問你一個問題:假設你是面試官,你問我工作中有沒有遇到過比較棘手的問題?
而我是一個只有三年工作經驗的求職者。
我用這篇文章中我假想出來的生產問題處理過程,並輔以技術細節,你能看出來這是我「包裝」的嗎?
然後在描述完事件之後,再體現一下對於事件的覆盤,可以說一下基於這個事情,後面自己對監控層面進行了豐富,比如介面超時率監控、GC 導致的 STW 時間監控啥的。然後也在公司內形成了「經驗教訓」檔案,主動同步給了其他的同事,以防反覆踩坑,巴拉巴拉巴拉...
反正吧,以後看到自己覺得好的案例,不要看完之後就完了,多想想怎麼學一學,包裝成自己的東西。
這波包裝,屬於手摸手教學了吧?
求個贊,不過分吧?