vivo 故障定位平臺的探索與實踐
作者:vivo 網際網路伺服器團隊- Liu Xin、Yu Dan
本文基於故障定位專案的實踐,圍繞根因定位演演算法的原理進行展開介紹。鑑於演演算法有一定的複雜度,本文通過圖文的方式進行說明,希望即使是不懂技術的同學也能理解。
一、背景介紹
1.1 程式設計師的困擾
作為一名IT從業人員,比如開發和運維,多少有過類似的經歷:睡覺的時候被電話叫醒,過節的時候在值班,遊玩的時候被通知處理故障。作為一名程式設計師,我們時時刻刻都在想著運用資訊科技,為別人解決問題,提升效率,節省成本。隨著微服務架構的快速發展,帶來一系列複雜的呼叫鏈路和海量的資料。對於我們來說,排查問題是一個大挑戰,尋找故障原因猶如大海撈針,需要花費大量的時間和精力。
1.2 現狀分析
vivo已經建立了一套完整的端到端監控體系,涵蓋了基礎監控、通用監控、呼叫鏈、紀錄檔監控、撥測監控等。這些系統每天都會產生海量的資料,如何利用好這些資料,挖掘資料背後的潛在價值,讓資料更好的服務於人,成為了監控體系的探索方向。目前行業內很多廠商都在朝AIOps探索,業界有一些優秀的根因分析演演算法和論文,部分廠商分享了在故障定位實踐中的解決方案。vivo有較完整的監控資料,業界有較完整的分析演演算法和解決方案,結合兩者就可以將故障定位平臺run起來,從而解決困擾網際網路領域的定位問題。接下來我們看下實施的效果。
二、實施效果
目前主要針對平均時延指標的問題,切入場景包括兩種:主動查詢和呼叫鏈告警。
2.1 主動查詢場景
當用戶反饋某個應用很慢或超時,我們第一反應可能是檢視對應服務的響應時間,並定位出造成問題的原因,通常這兩個步驟是分別進行,需要用到一系列的監控工具,費時費力。如果使用故障定位平臺,只需從vivo的paas平臺上進入故障定位首頁,找到故障服務和故障時間,剩下的事情就交給系統完成。
2.2 告警場景
當收到一條關於平均響應時間問題的呼叫鏈告警,只需檢視告警內容下方的檢視原因連結,故障定位平臺就能幫助我們快速定位出可能的原因。下圖是呼叫鏈告警範例:

呼叫鏈是vivo服務級監控的重要手段,上圖紅框內原因連結是故障定位平臺提供的根因定位能力。
2.3 分析效果
通過以上兩種方式進入故障定位平臺後,首先看到的是故障現場,下圖表示服務A的平均響應時間突增。
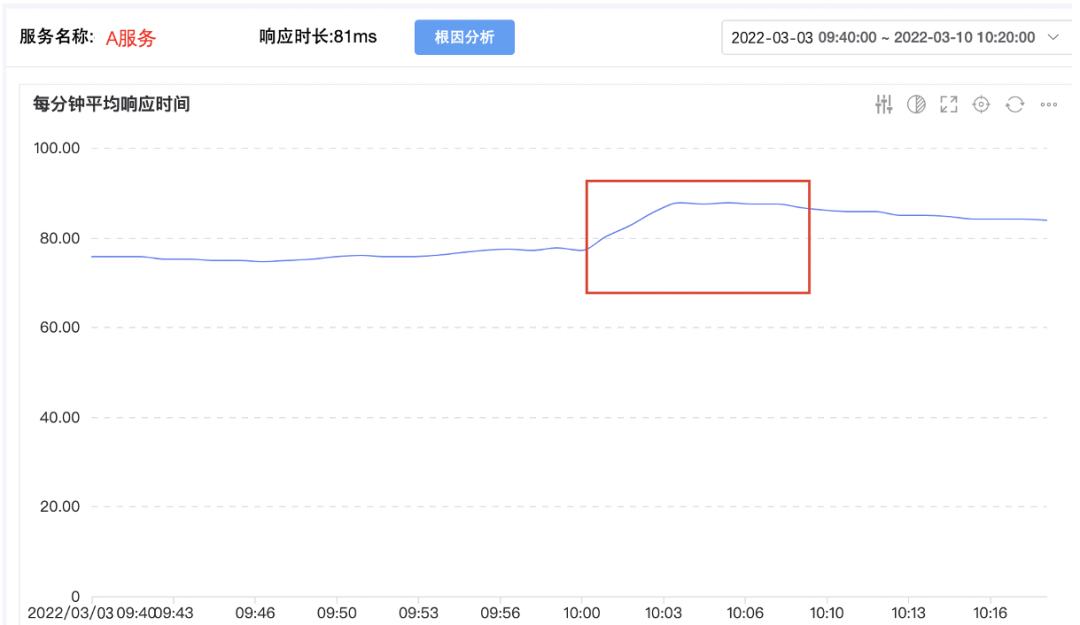
上圖紅框區域,A服務從10:00左右,每分鐘平均時延從78ms開始增長,突增到10:03分的90ms左右。
直接點選圖2藍色的【根因分析】按鈕,就可以分析出下圖結果:

從點選按鈕到定位出原因的過程中,系統是如何做的呢?接下來我們看下系統的分析流程。
三、分析流程
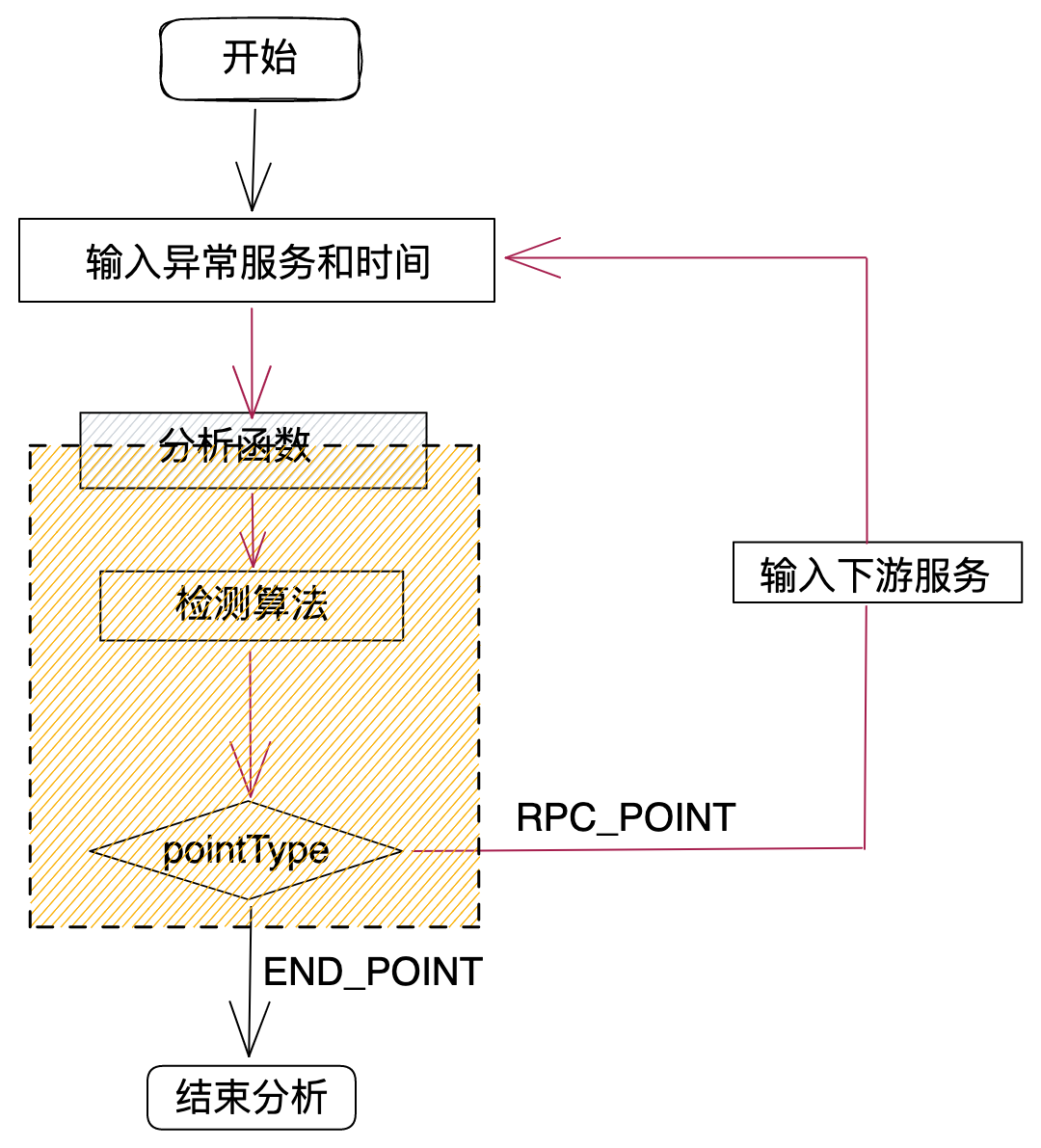
圖4是根因分析的主要流程,下面將通過文字詳細描述:
-
第一步:前端將異常服務名和時間作為引數通過介面傳遞到後端;
-
第二步:後端執行分析函數,分析函數呼叫檢測演演算法,檢測演演算法分析後,返回一組下游資料給分析函數(包括下游服務及元件、波動方差及pointType);
-
第三步:分析函數根據pointType做不同邏輯處理,如果pointType=END_POINT,則結束分析,如果pointType=RPC_POINT,則將下游服務作為入參,繼續執行分析函數,形成遞迴。
RPC_POINT包含元件:HTTP、DUBBO、TARS
END_POINT包含元件:MYSQL、REDIS、ES、MONGODB、MQ
最終分析結果展示了造成服務A異常的主要鏈路及原因,如下圖所示:

在整個分析過程中,分析函數負責呼叫檢測演演算法,並根據返回結果決定是否繼續下鑽分析。而核心邏輯是在檢測演演算法中實現的,接下來我們看下檢測演演算法是如何做的。
四、檢測演演算法
4.1 演演算法邏輯
檢測演演算法的大體邏輯是:先分析異常服務,標記出起始時間、波動開始時間、波動結束時間。然後根據起始時間~波動結束時間,對異常服務按元件和服務名下鑽,將得到的下游服務時間線分成兩個區域:正常區域(起始時間~波動開始時間)和異常區域(波動開始時間~波動結束時間),最後計算出每個下游服務的波動方差。大體過程如下圖所示:
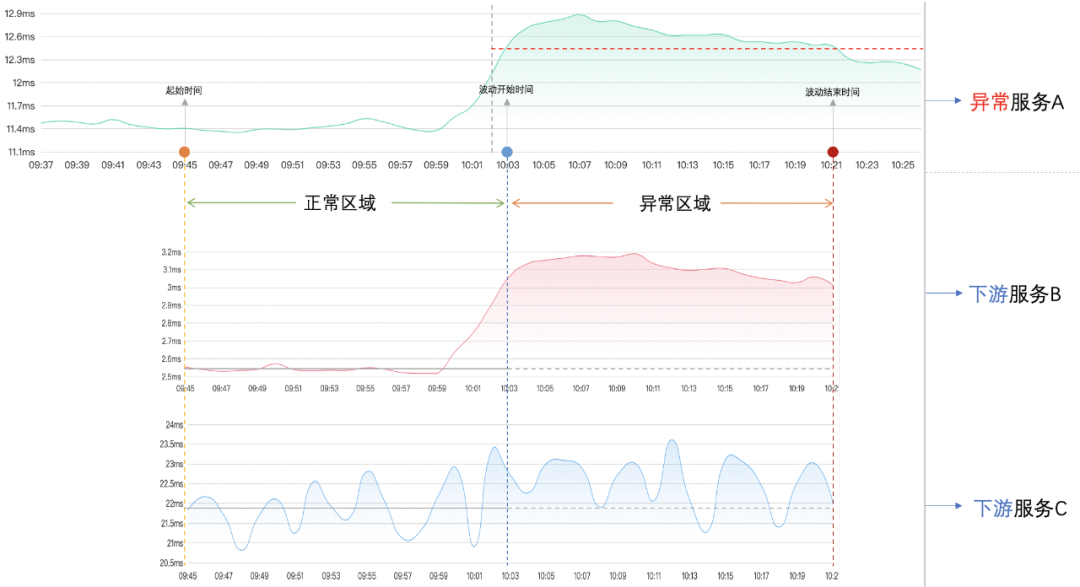
圖中異常服務A呼叫了兩個下游服務B和C,先標記出服務A的起始時間、波動開始時間、波動結束時間。然後將下游服務按時間線分成兩個正常區域和異常區域,標準是起始時間 到 波動開始時間屬於正常區域,波動開始時間 到 波動結束時間屬於異常區域。
那麼波動方差和異常原因之間有什麼關聯呢?
其實波動方差代表當前服務波動的一個量化值,有了這個量化值後,我們利用K-Means聚類演演算法,將波動方差值分類,波動大的放一起聚成一類,波動小的放一起聚成一類。如下圖:
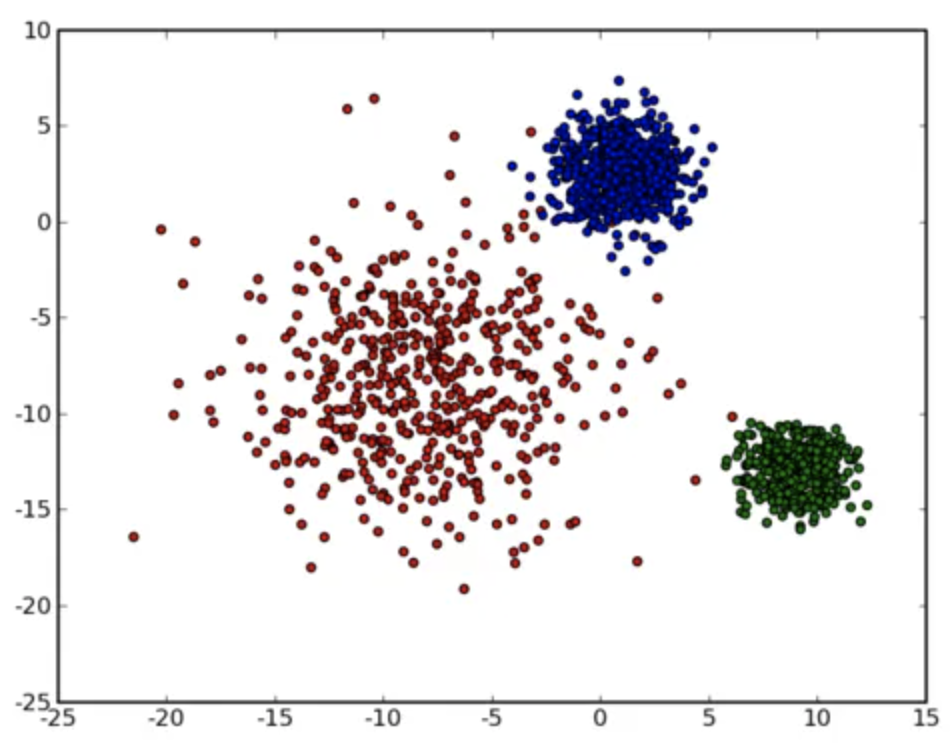
最後我們通過聚成類的波動方差,過濾掉波動小的聚類,找到最可能造成異常服務的原因。以上是對演演算法原理的簡要介紹,接下來我們更進一步,深入到演演算法實現細節。
4.2 演演算法實現
(1)切分時間線:將異常時間線從中點一分為二,如下圖:

(2) 計算波動標準差:運用二級指數平滑演演算法對前半段進行資料預測,然後根據觀測值與預測值計算出波動標準差,如下圖:
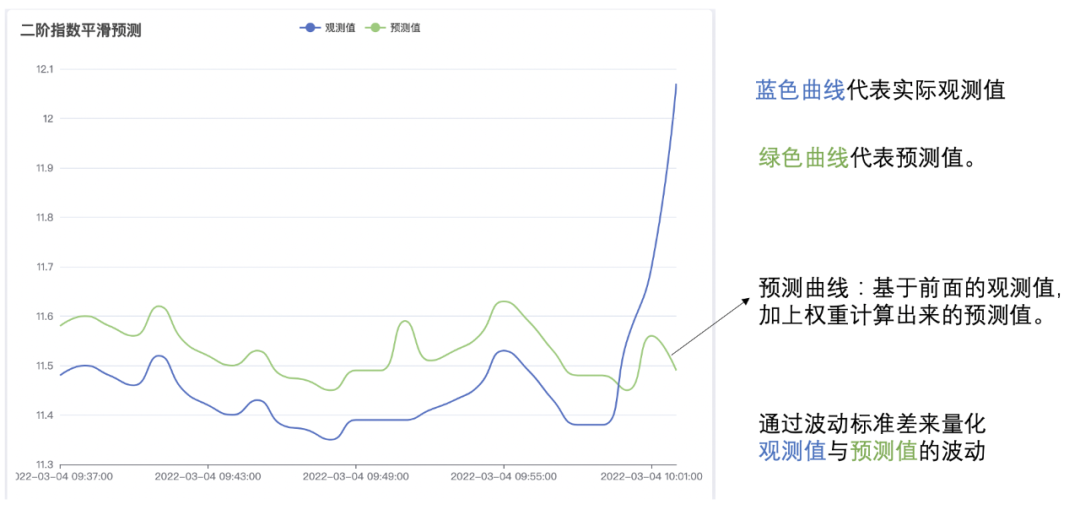
(3)計算異常波動範圍:後半段大於3倍波動標準差的時間線屬於異常波動,下圖紅線代表3倍波動標準差,所以異常波動是紅線以上的時間線,如下圖:

(4)時間點標記:紅線與時間線第一次相交的時間點是波動開始時間,紅線與時間線最後一次相交的時間點是波動結束時間,起始時間和波動結束時間關於波動開始時間對稱,如下圖:

(5)服務下鑽:根據起始時間~波動結束時間,對異常服務按元件和服務名下鑽,得到下游服務時間線,如下圖:
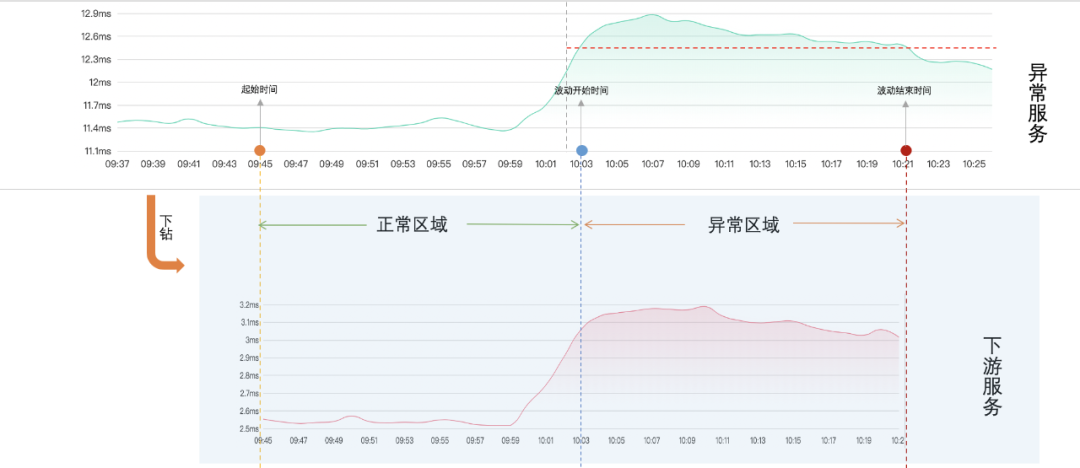
(6)計算正常區域平均值:下游服務的前半段是正常區域,後半段是異常區域,先求出正常區域的平均值,如下圖:
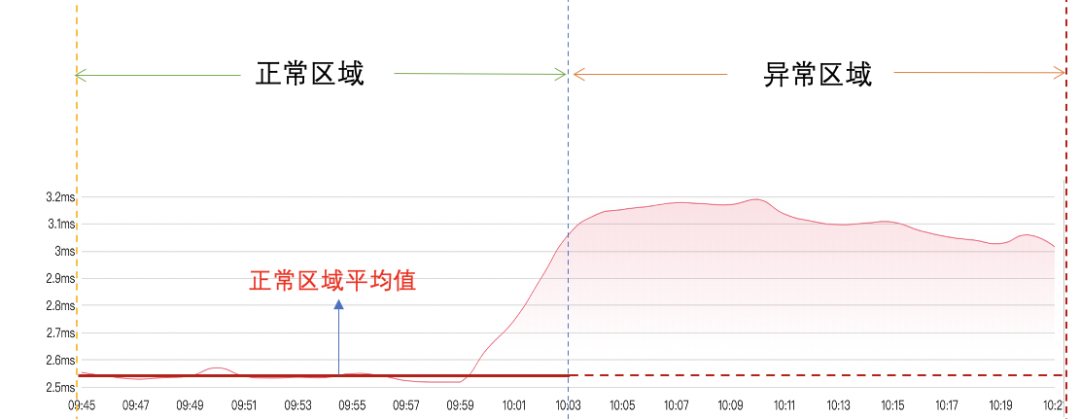
(7)計算異常區域波動方差:根據異常區域波動點與正常區域均值之間的波動計算波動方差和波動比率,如下圖:
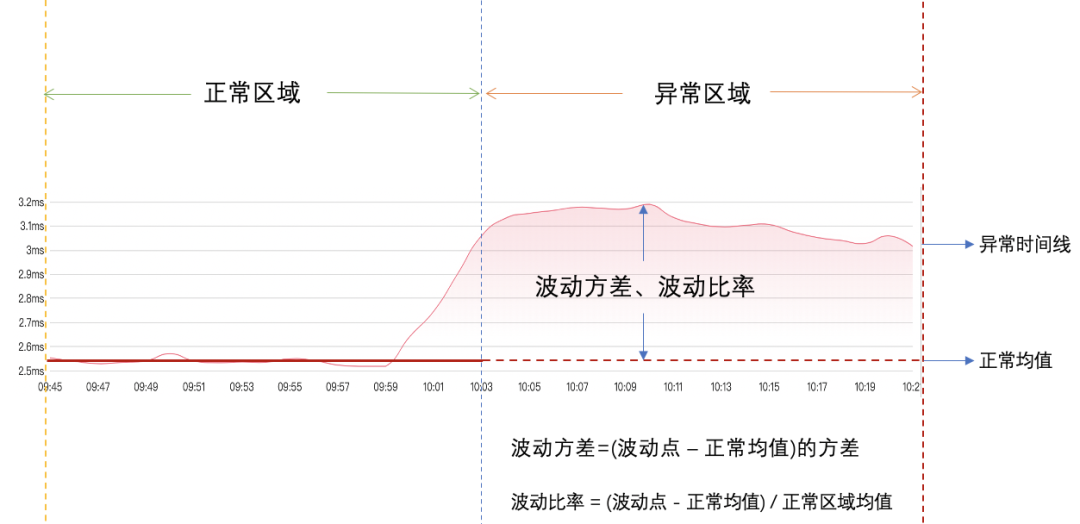
(8)時間線過濾:過濾掉波動方向相反、波動比率小於總波動比率的1/10的時間線,排除正常時間線,如下圖:
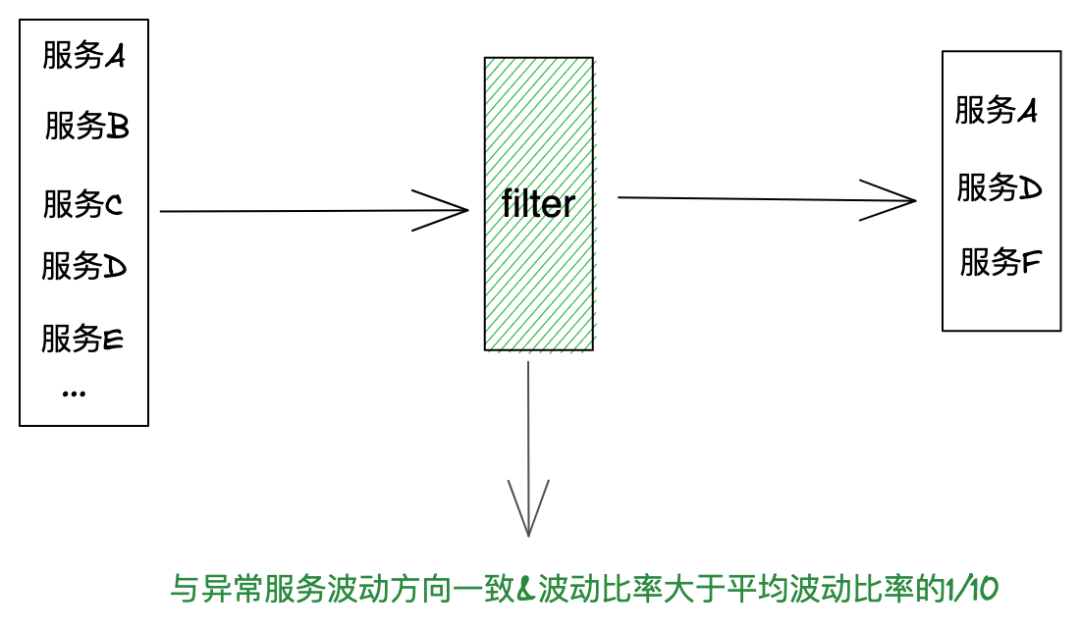
(9)對剩餘下鑽時間線進行KMeans聚類,如下圖:

五、簡要總結
1、一種小而美的根因定位演演算法,利用方差量化波動,再通過排除法過濾掉波動小的下游,留下可能的下游作為原因。這種演演算法可以利用我們較完善的鏈路資料,可實現的成本低;
2、針對下游依賴場景的原因定位,準確率可達85%以上。但沒有覆蓋自身原因造成的故障(如GC、變更、機器問題等);
3、分析結果只能提供大概的線索,最後一公里還是需要人工介入;
4、故障定位算是AI領域的專案,開發方式與傳統的敏捷開發有一定的區別:
-
角色職責:領域專家(提出問題) → AI專家(演演算法預研) → 演演算法專家(演演算法實現和優化) → 應用專家(工程化開發)
-
操作步驟:調研論文和git(業界、學界、同行) → 交流 → 實踐 → 驗證
-
專案實施:複雜問題簡單化,先做簡單部分;通用問題特例化,找出具體案例,先解決具體問題。
六、未來展望
1、故障預測:當前我們主要關注服務出現異常後,如何檢測異常和定位根因,未來是否能夠通過一些現象提前預判故障,將介入的時間點左移,防患於未然;
2、資料質量治理:當前我們的監控資料都有,但資料質量卻參差不齊,而且資料格式的差異很大(比如紀錄檔資料和指標資料),我們在做機器學習或AIOps時,想要從中找出一些有價值的規律,其實挺難的;
3、經驗知識化:當前我們的專家經驗很多都在運維和開發同學的腦海中,如果將這些經驗知識化,對於機器學習或AIOps將是一筆寶貴的財富;
4、從統計演演算法往AI演演算法演進:我們故障定位現在實際用的是統計演演算法,並沒有用到AI。統計往往是一種強關係描述,而AI偏向弱關係,可以以統計演演算法為主,然後通過AI演演算法優化的方式。
參考資料