由char和byte的關係引申出去——總結一下java中的字元編碼相關知識
由char和byte的關係引申出去——總結一下java中的字元編碼相關知識
一、字元編碼
手持兩把錕斤拷,口中直呼燙燙燙
在文章伊始,先來複習一下計算機中關於編碼的一些基礎知識,著重理清以下幾個基本概念。
1. 碼點(code point)
計算機只能以二進位制的形式儲存文字,故而計算機中每一個字母,文字,符號,emoji都對應著一個二進位制數,而這個二進位制數就是碼點。
2. 字元集
光有碼點還不夠,我們還得知道有哪些碼點,這些碼點又能表示哪些字元,於是便又到了喜聞樂見的制定標準環節。標準所支援的所有字元及其對應碼點的集合被稱為字元集。例如學過C語言的同學都知道的ASCII字元集,它共包含了128個字元,包括數位,26個字母的大小寫及一些符號,對應的碼點就是0-127。再有就是後面要提到的Unicode字元集。
3. 編碼
以ASCII字元集為例,它的碼點為0-127,最大不超過7bit,而計算機中一般是以8bit的位元組(byte)為單位。出於種種考量,實際儲存在計算機中的碼點的二進位制都會在頭部添0,以8bit儲存。例如A對應碼點65,二進位制為100 0001,實際在計算機中儲存為0100 0001。這種在計算機中實際儲存的內容到字元的對映就是編碼。
我們熟悉的編碼方式有ASCII,UTF-8,UTF-16,歐洲的ISO,中國大陸的GBK等等。計算機中儲存的同一段二進位制,用不同的編碼方式,會得到完全不同的內容。
4. Unicode字元集
ASCII一共只包含了128個字元,顯然不夠用,於是便有了Unicode字元集。Unicode字元集中收錄了世界上絕大多數文字,符號等,反正就是非常多。
行文至此,筆者想到自己當初學習時的一個疑惑,即字元集已經規定好了字元到碼點的對映,為啥還有各種不同的編碼方式。如果讀者仔細理解了上文不難發現,在計算機中以何種方式儲存碼點是需要編碼來確定。最簡單的方法就是直接將碼點轉成二進位制儲存,比如對ASCII字元集的ASCII編碼,對Unicode的UTF-32編碼。
由於Unicode字元集數量極其旁大,單個字元最大已超過了3個位元組(具體多大我也不清楚,目前用4個位元組還足夠表示),同時為了區分前後兩個字元在哪裡斷開,utf-32編碼簡單粗暴得將每個字元以32位元4位元組的形式儲存在計算機中。這樣很好理解,但帶來了嚴重的空間浪費,對於常用的字母得要存一堆0,簡直就是0溢事件。
5. UTF-8編碼
我們常見的utf-8便是為了解決上述問題而誕生的,他是針對於Unicode的可變長度編碼方式,可以把不同字元以1,2,3,4位元組大小儲存到計算機中,同時utf-8相容ascii,具體規則參考下圖,也推薦大家看一下圖片下方連結的視訊,講的很好:

圖片來源:【你懂亂碼嗎?錕斤拷燙燙燙(詳解ASCII、Unicode、UTF-32、UTF-8編碼)】 https://www.bilibili.com/video/BV1xP4y1J7CS/?share_source=copy_web&vd_source=f5db843fce15b7c3e2990f4f7a6e8921
二、Java中的字元編碼
1. 編碼方式:
有了以上知識的鋪墊,其實接下來的問題就很好解決了。
首先,java中採用的是基於Unicode字元集的UTF-16編碼方式。utf-16可以將不同字元以2或4位元組大小儲存在計算機中,可能有同學已經發現規律了,utf-8是以8bit為最小單位,而utf-16是以16 bit為最小單位,而這個最小單位實際上就是所謂的程式碼單元(code unit)。
2. char型別:
基本型別char型別就是一個16bit的程式碼單元。我們日常裡常用的字元,如字母,漢字等只需要一個char,而對於一些類似於emoji這樣的碼點值很大的字元,需要兩個char。
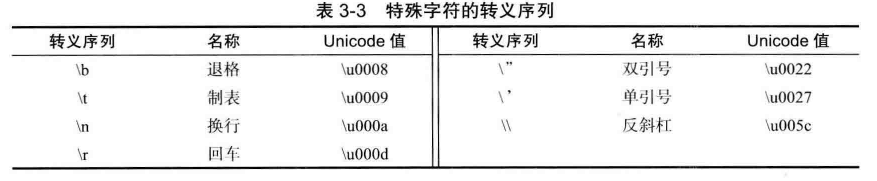
java中char型別的字面量用'A'單引號括起來,表示一個字元常數。對於一些特殊字元,如回車,換行,我們要用到跳脫字元來表示,如下圖:
3. 應用:
行文至此,筆者又想起之前曾經看到過的一個相關的案例。
簡言之就是需要對資料庫中取出的使用者名稱做一個截斷,比如某些情況下只需要呈現使用者名稱的前三個字。而這個系統允許使用者上傳的使用者名稱中包含emoji表情。
在這種情況下就要注意了,一個emoji字元由兩個char組成,如果簡單得用String.subString()或者String.length是有問題的,因為這些方法都是以char為單位,可能會造成把一個emoji字元只截了一個char出來,從而導致問題。在這裡就需要用String的codePoint相關的方法去擷取,以碼點為單位,因為一個碼點一定代表一個字元,而一個char則未必。
詳情見該視訊:【Emoji 表情導致線上故障2個小時。老闆直接損失10萬。到底是什麼問題?| 故障覆盤 | 實戰經驗分享】 https://www.bilibili.com/video/BV1MG41177pT/?share_source=copy_web
三、 總結:
如果您堅持看到了這裡,那麼我想一定已經對於我標題提出的問題的答案瞭然於胸了。
char和byte的關係,現在看來這倆也沒啥關係嘛,只能說我這個引申不是很合適。本文著重介紹了計算機字元編碼的相關知識,同時也總結了java中有關字元編碼的一些內容,希望能對你有所幫助。
四、 參考資料:
- 【你懂亂碼嗎?錕斤拷燙燙燙(詳解ASCII、Unicode、UTF-32、UTF-8編碼)】 https://www.bilibili.com/video/BV1xP4y1J7CS/?share_source=copy_web&vd_source=f5db843fce15b7c3e2990f4f7a6e8921
- 《java核心技術卷Ⅰ》
鄙人只是一名在讀的軟體工程專業的本科生,正在複習找工作,故而將複習時遇到的一些有意思的東西總結出來,既是加深理解,也是便於日後複習。
鄙人才疏學淺,若文中有謬誤之處,還望諸位不吝斧正,以免誤人子弟。若有同道中人想一同討論學習,也可以聯絡我=>[email protected]。未經本人同意,請勿轉載!
路漫漫其修遠兮,吾將上下而求索。