機器學習--起手式
幾個貫穿始終的概念
當我們把人類學習簡單事物的過程抽象為幾個階段,再將這些階段通過不同的方法具體化為程式碼,依靠通過計算機的基礎能力--計算。我們就可以讓機器能夠「學會」一些簡單的事物。
我們首先將視線聚焦在最簡單的判斷題上。而包括OCR,CV,自然語言處理在本質上來說就是對給定的影象(語句)做判斷
判斷:給定輸入,得到一個輸出
資料由我們學習的內容所決定.但是從現實生活中收集而來的資料,並不是機器能夠"食用"的,需要我們通過一定的資料預處理,清洗資料以備使用.
而演演算法和模型決定了了輸出端和輸入端之間的關係.機器是否能夠學會處理輸入端的資料,需要合適的演演算法和模型的幫助
而機器學習不僅要從0到1,還要從1到100.這就意味著機器需要不斷的練習.來提高正確率.
所以資料、模型、演演算法和訓練是貫穿我們學習機器學習過程的四個關鍵詞.也是一個面對問題建立模型最終實現的過程.
-
資料部分:學習瞭解流行的資料流.知道資料處理的benchmark.學會常見的資料預處理方法,總結資料處理技巧.
-
模型部分:學習常見的模型.各個模型相互關聯加強記憶
-
演演算法部分:誤差損失函數,反向傳播,梯度下降.
演演算法和模型的區別在於:模型是靜態的神經網路,沒有特殊性;而演演算法就是模型動態的調整以吻合特定問題的需要
- 訓練部分:降低訓練時間,提高效能
環境設定
- CUDA 「訓練」時的算力由顯示卡提供。CUDA為英偉達的底層顯示卡驅動(AMD暫時不瞭解)。
- 主要使用Python內建的數學庫來實現,推薦使用Anaconda來設定.
CUDA
1.開啟NVIDIA控制檯
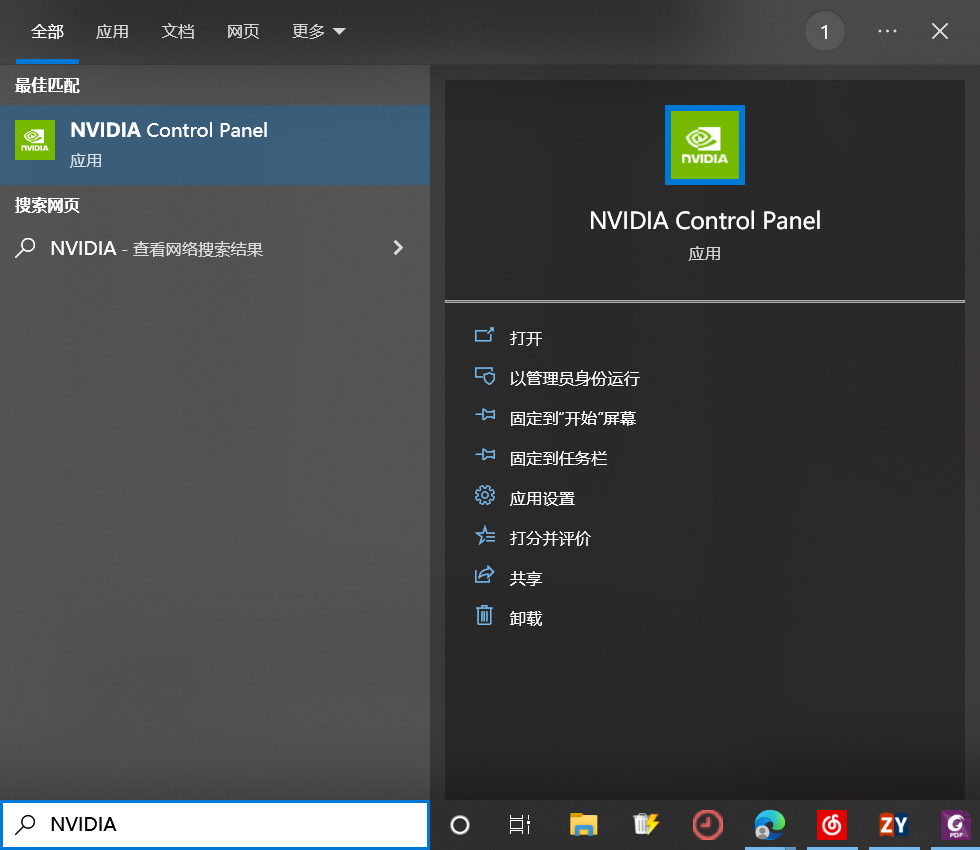
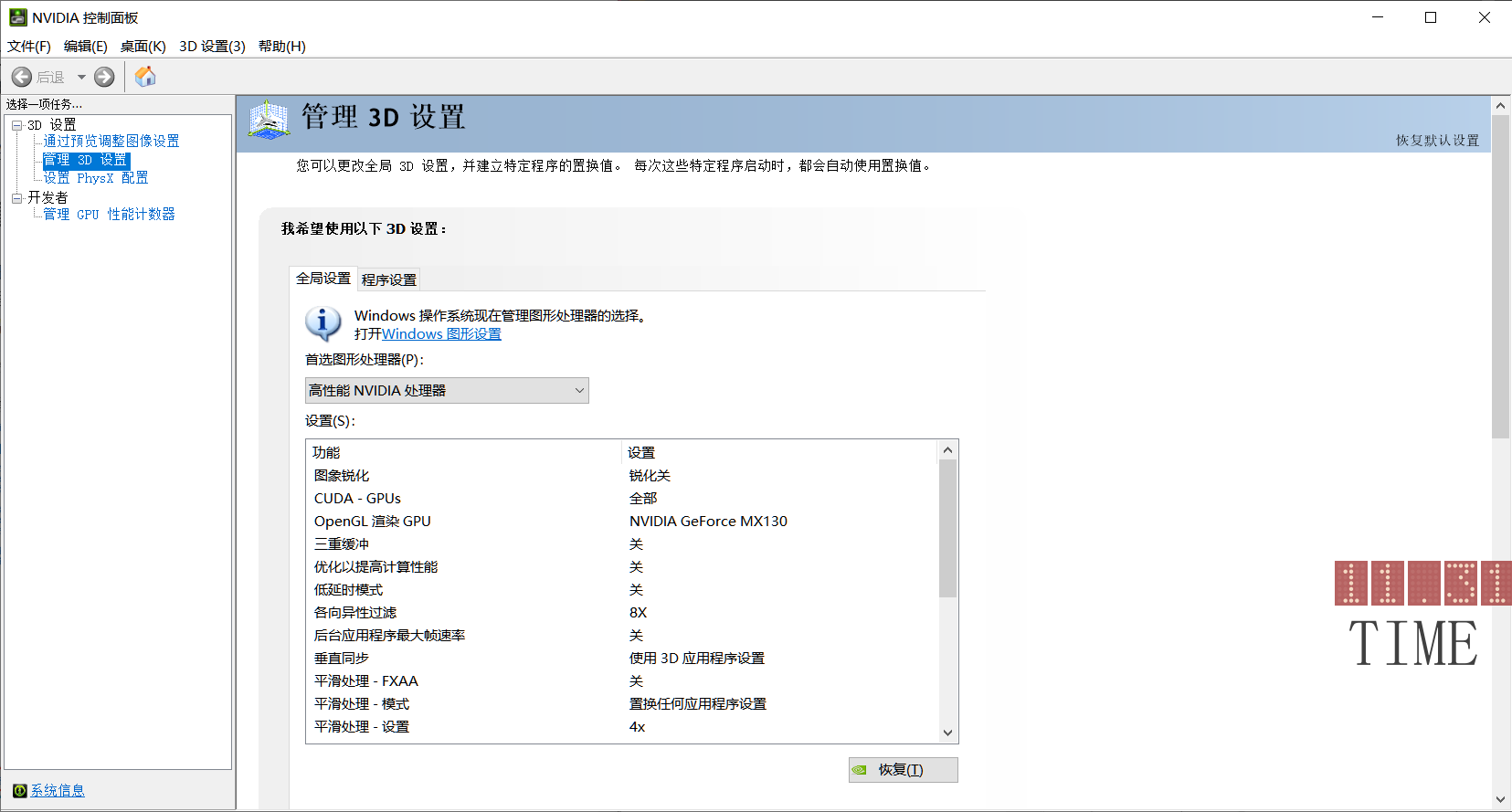
2.看一下有沒有CUDA-GPUs

3.下載CUBA
在NVIDIA控制介面的左下角,點選系統性息
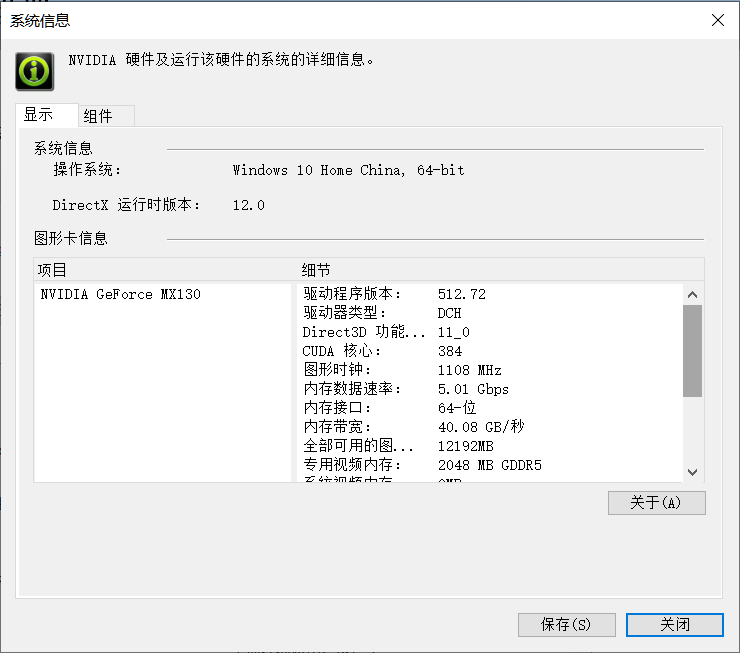
檢視一下驅動程式版本,對照下圖檢視,下載支援的CUDA的版本
我的驅動版本是512.72,所以支援的最新驅動是CUBA 11.8.X
附上連結以供查閱

安裝沒有難度,只不過建議 路徑不要出現中文字元,記住安裝路徑即可。安轉完成之後 按下win+r鍵 開啟cmd在命令列中輸入nvcc -V然後回車,成功的話就會返回CUBA的版本號
安裝Anaconda
這個安裝比較簡單(路徑不要出現中文字元)建議去清華或者其他映象庫安裝,下面講述如何設定環境變數
環境設定
1.設定 -> 系統 -> 關於 -> 右側目錄中選擇高階系統設定

點選環境變數
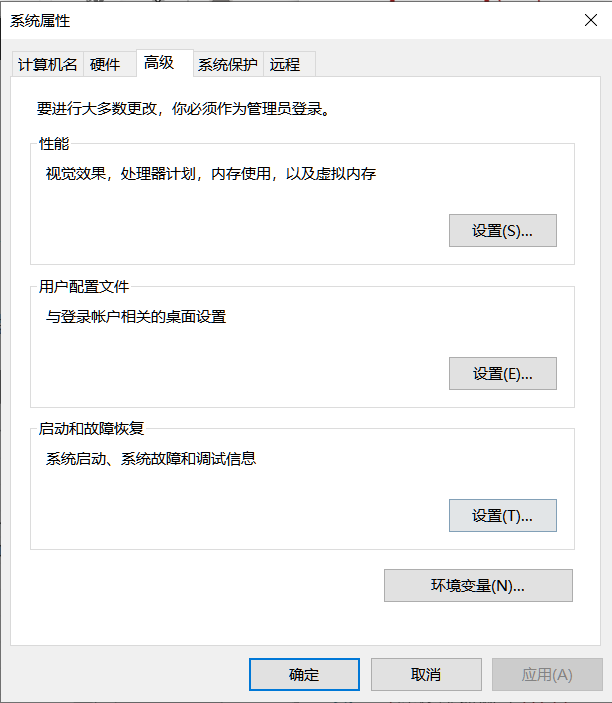
在path中新增anaconda資料夾和script

conda install映象設定
軟體本體下載慢,python的一些包也下載慢。所以我們可以設定清華的映象。清華映象網站
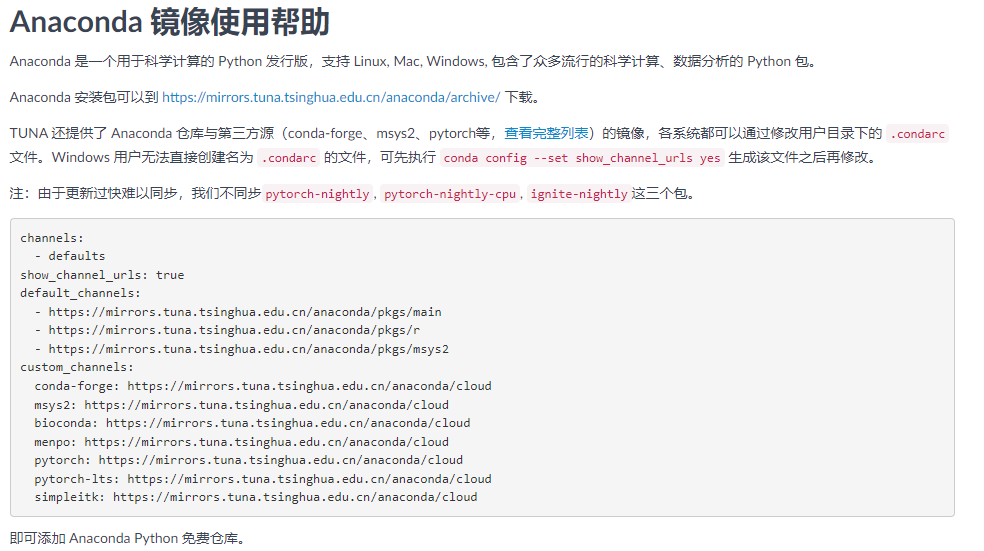
簡要介紹:
1、現在使用者目錄下檢視是否有.condarc檔案 沒有的話 在cmd命令列中執行
conda config -set show_channel_urls yes
然後進行修改。
2、修改之後執行
conda clean -i
Anaconda的使用
conda的好處在於我們可以按照需要設定環境,無論是Python版本還是其中包的版本和依賴
conda命令列
注意:使用conda命令時應該確定是對某個特定環境使用
conda –version #檢視conda版本,驗證是否安裝
conda update conda #更新至最新版本,也會更新其它相關包
conda update –all #更新所有包
conda update package_name #更新指定的包
conda create -n env_name package_name #建立名為env_name的新環境,並在該環境下安裝名為package_name 的包,可以指定新環境的版本號,例如:conda create -n python3 python=python3.7 numpy pandas,建立了python3環境,python版本為3.7,同時還安裝了numpy pandas包
conda activate env_name #切換至env_name環境
conda deactivate #退出環境
conda info -e #顯示所有已經建立的環境 或者使用 conda env list
conda create –name new_env_name –clone old_env_name #複製old_env_name為new_env_name
conda remove –name env_name –all #刪除環境
conda list #檢視所有已經安裝的包
conda install package_name #在當前環境中安裝包
conda install –name env_name package_name #在指定環境中安裝包
conda remove – name env_name package #刪除指定環境中的包
conda remove package #刪除當前環境中的包
conda env remove -n env_name #強制刪除環境
先來安裝比較重要的一個包numpy來試試手
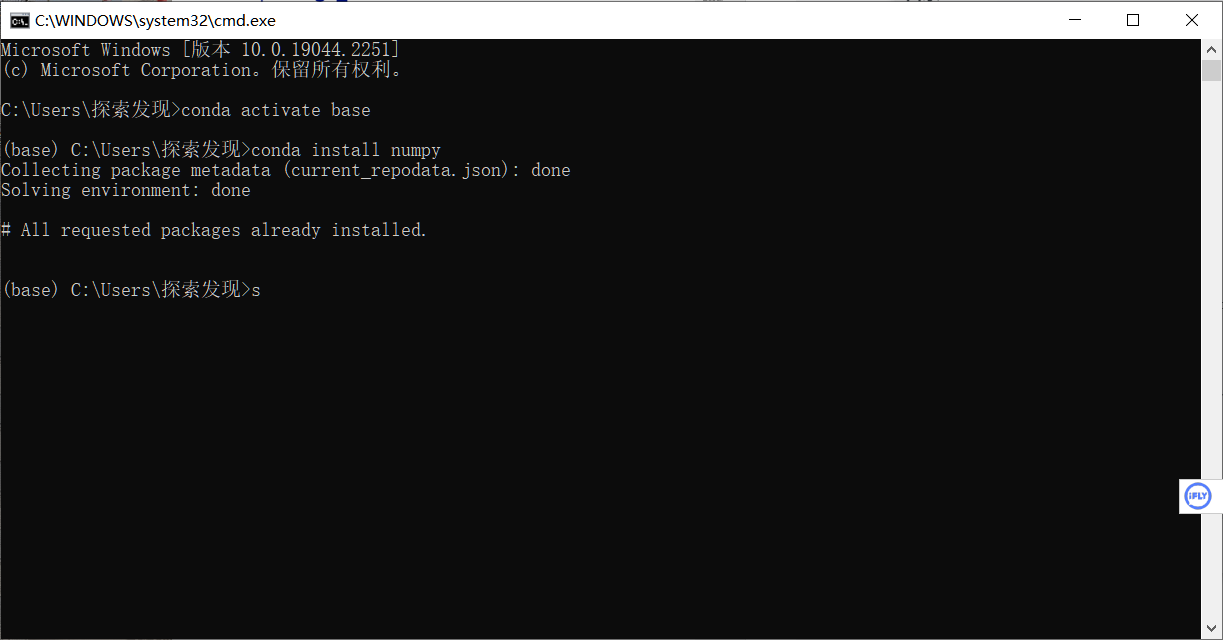
先要進入base環境 ,然後執行conda install 命令。
也可以自行建立新環境,然後在新環境中安裝。
Anaconda Navigator 使用
四個主要的介面:
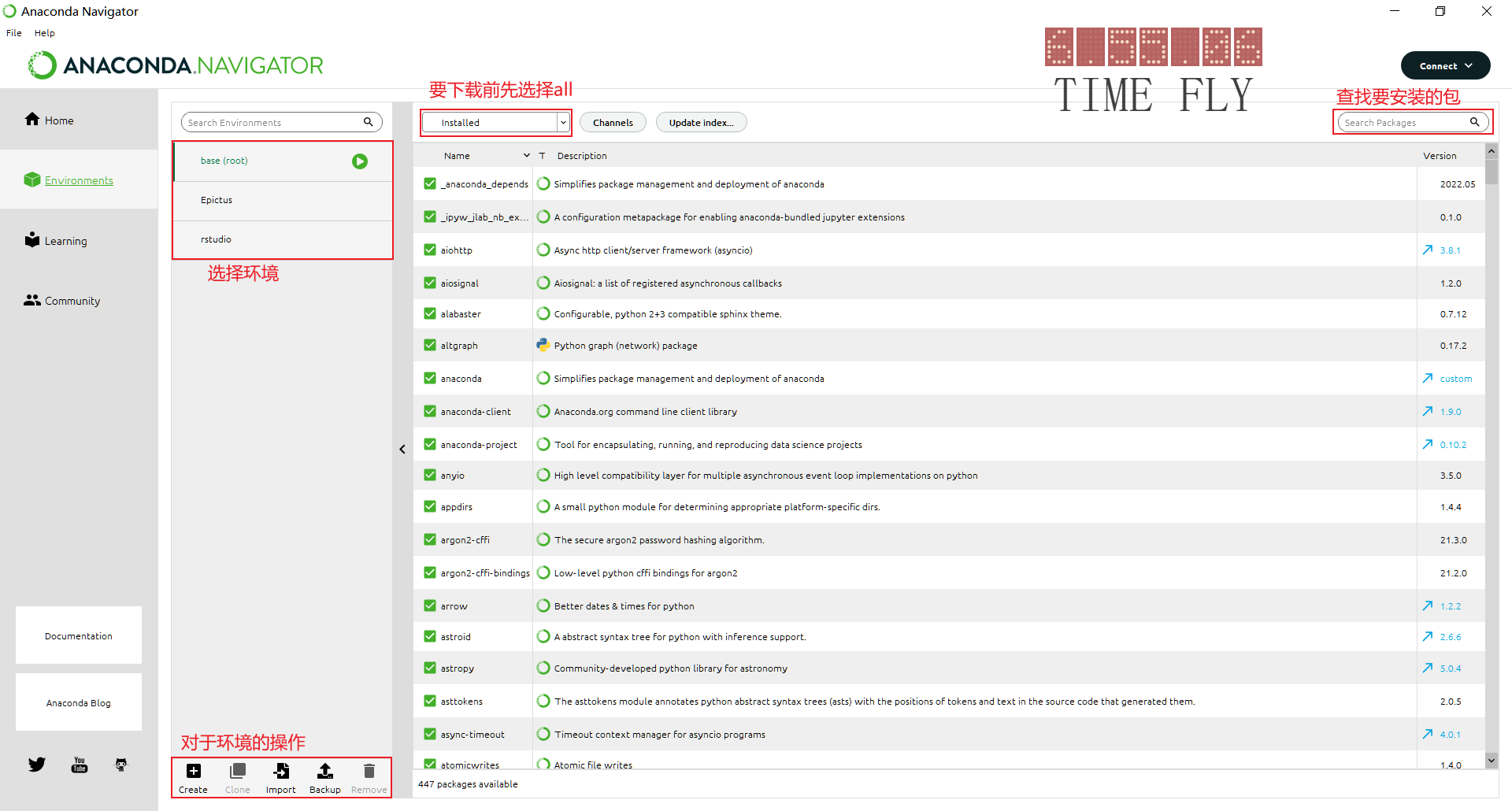
home頁面

選擇一個環境,然後開啟應用開發.
有一些是自帶安裝了的,有一些是我們可以安裝的
比如我們可以點選launch開啟預先安裝了的Jupyter Notebook
environment頁面
learning頁面
提供了絕大多數python相關的官方檔案.相比B站上的教學這裡講述的會更加具體詳細系統可以按需查詢
community頁面
提供了常見的python論壇,像著名的stack overflow
Jupyter Notebook 使用
Jupyter Notebook小巧玲瓏,實時互動,單獨的cell之中可以單獨執行,無需從頭執行程式碼,自動儲存,支援markdown,Latex公式學習思路,非常適合學習者使用.
+ Jupyter Notebook
+ 安裝,開啟,問題偵錯
+ Anaconda
+ 命令列
+ 調教
+ 修改開啟的預設目錄
+ 關閉,退出
+ 使用
+ 快捷鍵
+ Markdown
開啟,安裝,問題偵錯
可以在anaconda navigator中直接點lauch就行,不再贅述,如果打不開,修復bug,或者嘗試通過命令列開啟。
下面講述
base環境
已經預設安裝了Jupyter Notebook
我們win+r 再輸入cmd 開啟命令列
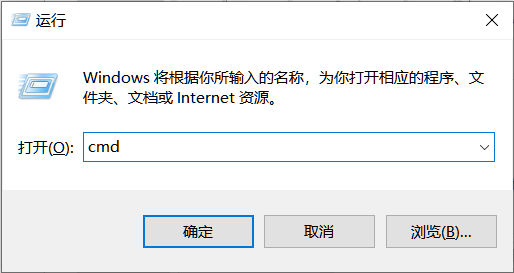
conda activate base啟用base環境
Jupyter Notebook開啟 Jupyter Notebook
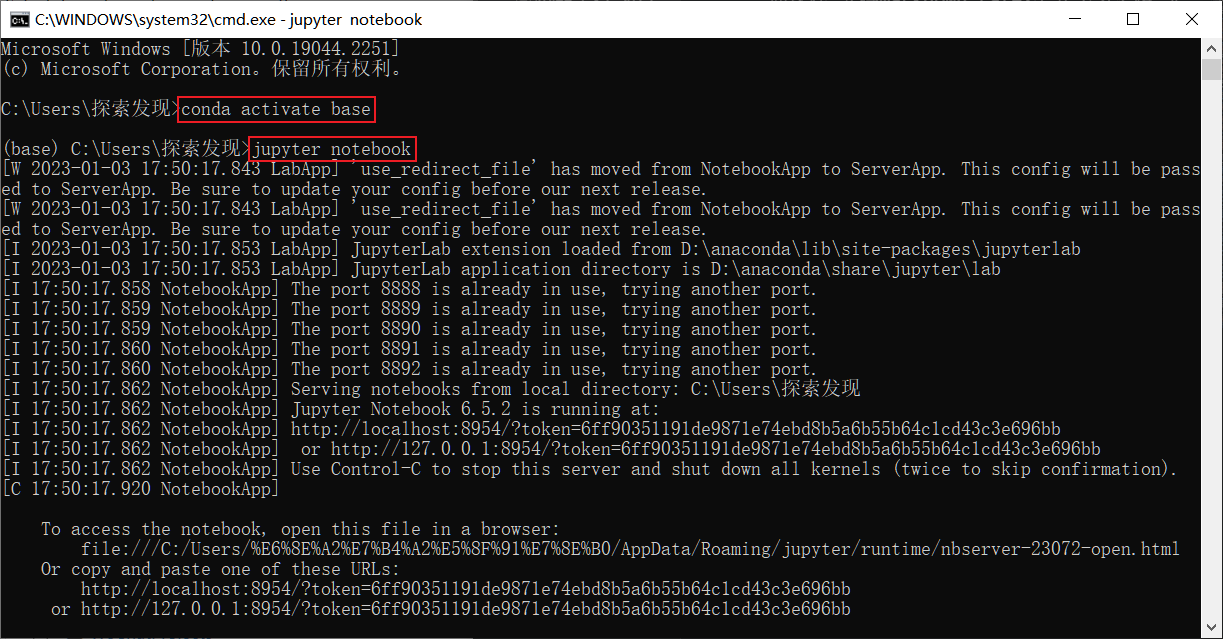
1.請不要關閉命令列視窗不然無法操作
2.如果沒有跳轉瀏覽器, 修復bug,或者開啟瀏覽器開啟最後的連結
新環境
建立一個名為Epictus的python環境
conda create -n Epictus python
不要忘記加上python了
也可以使用
conda create -n Epictus python=版本
安裝指定版本的Python
新建立的環境中不包含 Jupyter Notebook使用
conda install Jupyter Notebook
再輸入
Jupyter Notebook
調教
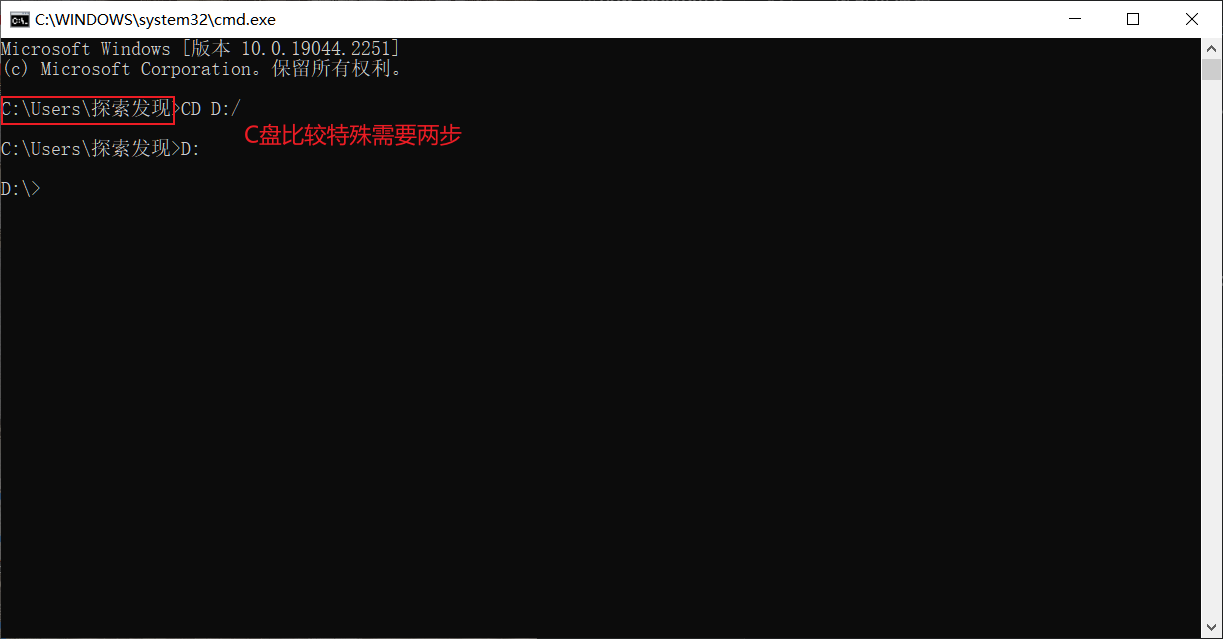
改變儲存目錄
我們只要在目標目錄下開啟 Jupyter Notebook即可
cd 目標路徑
碟符:
關閉,退出
使用完畢可以在命令列視窗連按兩次[Ctrl+c]關閉服務
使用
快捷鍵
Jupyter Notebook有兩種不同的鍵盤輸入模式。編輯模式允許您在單元格中鍵入程式碼或文字,並由綠色單元格邊框指示。命令模式將鍵盤繫結到筆電級別的命令,並由帶有藍色左邊距的灰色單元格邊框指示。
具體的快捷鍵按H鍵
編輯模式和命令模式按Esc鍵切換
markdown
在markdown中還可以輸入latex公式
Matplotlib
最流行的Python繪相簿,名字取自MATLAB,資料視覺化工具
conda install Matplotlib進行安裝
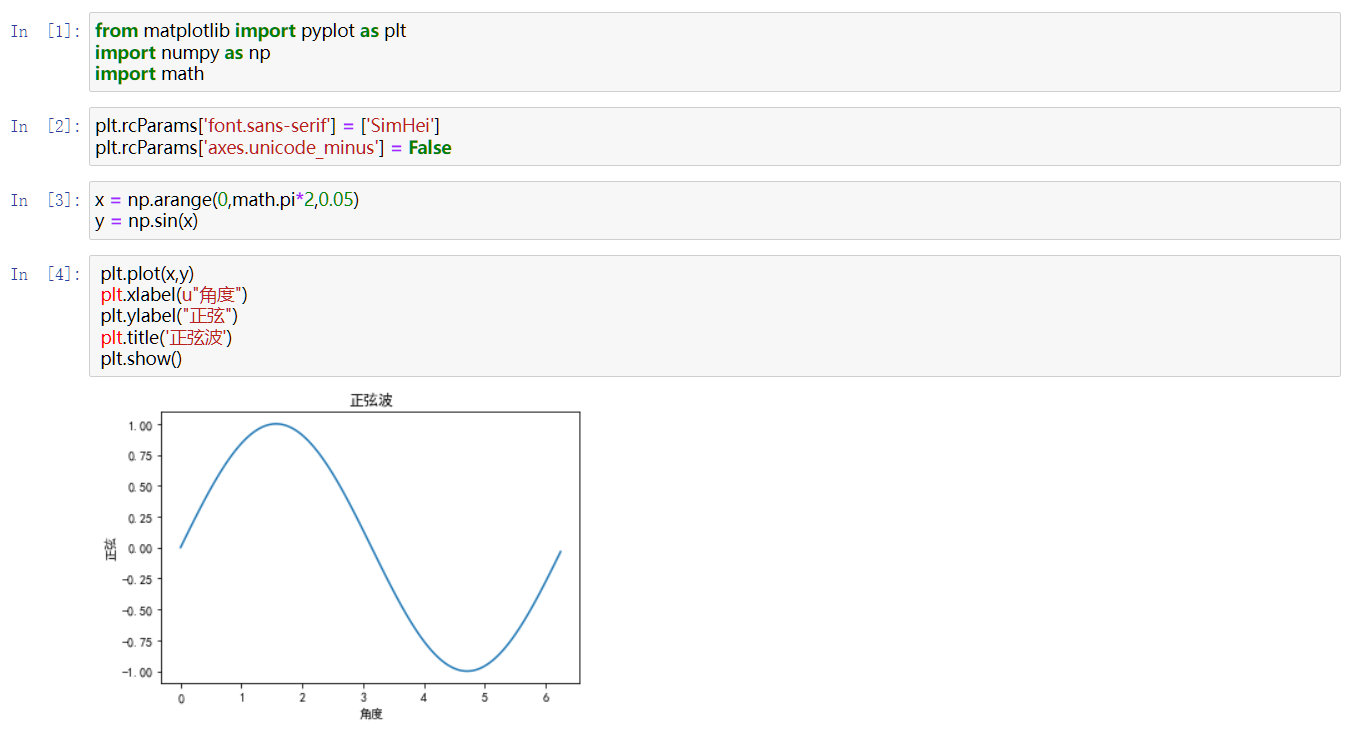
沒有必要從頭學,只要根據自己想要畫的圖找到程式碼再把自己的資料輸入就OK了,經常出現的圖程式碼也會熟悉的,屬於熟能生巧的技能。
Numpy
大名鼎鼎的 Numpy究竟是什麼
Numerical Python的縮寫
- 一個開源的Python科學計算庫
- 方便的矩陣,陣列運算(與matlab相比各有千秋 numpy官方檔案)
- 包括線性代數、傅立葉變換、亂數生成等大量函數
以上的特點使得Numpy比直接編寫python程式碼:
- 更加簡潔:陣列和矩陣的引入
- 更加高效:陣列儲存效率比原生list高,numpy以c語言來實現
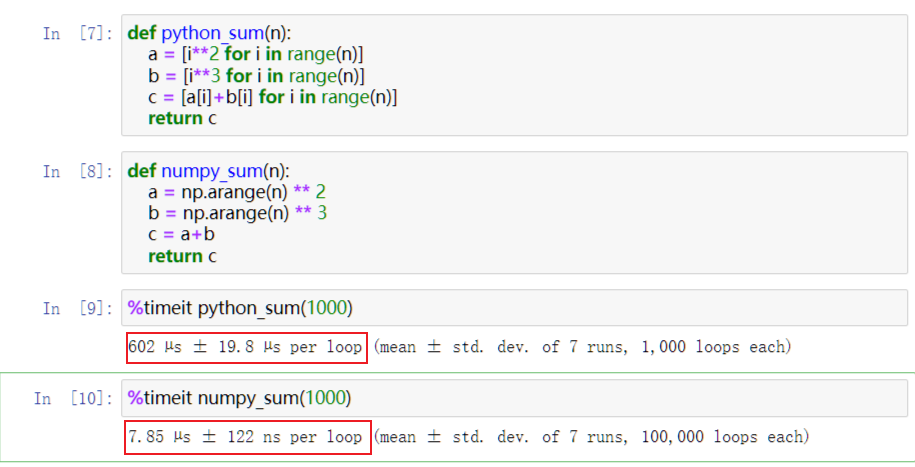
學習目標
主要利用的是其中narray這一物件,所以首先掌握對於narray的各項操作,然後對於其他的操作在後面實際操作中在學習.
narray
實際上就是一個數表,只起到儲存數的作用.
厲害的不是narray,而是其背後的代數學的發展.當然我們不能否認採用c語言之後對於效能的優化.但是歸根到底是因為數表這一個方式更加適合運算.
更加適合求解方程組(在代數學中矩陣的出現就是為了求解方程)
更加適合加減乘除
屬性
| 屬性名 | 含義 |
|---|---|
| shape | array的形狀 |
| ndim | 表示array的維度 |
| size | 表示array元素的數目 |
| dtype | array中元素的資料型別 |
| itemsize | 陣列中每個元素的位元組大小 |
| {.small} |
建立array的方法
- 轉化python原生的list和巢狀列表
- 使用預定函數arrange,linspace等建立等差陣列
- 使用ones,ones_like,zeros,zeros_like,empty,empty_like,full,full_like,eye等建立
- 生成隨機書的random模組建立
array的兩個要點就是元素和形狀,確定兩者array就確定了.
前菜--Numpy;詳細介紹
資料處理
- 資料採集
- 資料淨化
- 資料標準化
- 資料增強
資料採集
實際上就是爬蟲。現代的資料網路每秒產生的資料就成千上萬個,想要得到我們想要的資料,我們就必須要學會使用爬蟲自動存取網頁回去資訊。
資料淨化
爬蟲返回的資料千奇百怪,不乏有錯誤的「髒」資料,主要包括一致性檢查和無效值/缺失值處理
但是對於聖都學習來說,這些錯誤本來就是需要,甚至對於乾淨的資料我們還要人為新增噪聲.
所以我們的資料淨化主要是針對人為造成的錯誤
資料標準化
歸一化,歸一化有很多的理解的方式.把資料進行歸一化的最直觀的好處就是單位消失了.那後續的好處會在演演算法和模型的使用中顯現出來的.
最簡單的歸一化方法就是離差標準化,也叫做min-max標準化或者縮放歸一化.
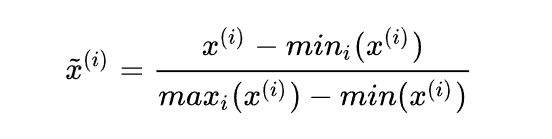
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
但是這種方法在每次最大值和最小值變化的時候都要重新計算
所以最為常見的方法是標準差歸一化,也叫做z-score標準化。經過處理的資料符合高斯分佈,均值為0,標準差為1
先求出整體樣本的均值和標準差,讓每個樣本的取值減去均值在除以標準差
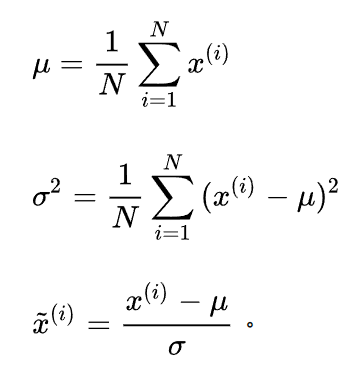
import numpy as np
def z_score(x):
x -= np.mean(x)
x /= np.std(x)
return x
還有Decimal scaling小數定標標準化,對數Logistic模式,atan模式,模糊量化模式。可以Google scholar一下
資料增強
深度學習模型是否強大和訓練的資料集有很大的關係,至少要幾千次的訓練才能完成一個簡單的人物。
當資料不夠的時候怎麼辦呢?
我們可以對已有的資料進行整容,新增噪聲等等的方法來自己造資料。
- PyTorch中就自帶影象的旋轉功能
- Mixup把幾張圖片混合起來
- 新增噪聲
- GAN網路中有一個自動生成模型的功能
- 那對於自然語言處理,我們可以先機翻到英文在翻回來