基於ERNIELayout&pdfplumber-UIE的多方案學術論文資訊抽取
本專案連結:https://aistudio.baidu.com/aistudio/projectdetail/5196032?contributionType=1
基於ERNIELayout&pdfplumber-UIE的多方案學術論文資訊抽取,小樣本能力強悍,OCR、版面分析、資訊抽取一應俱全。
0.問題描述
可以參考issue: ERNIE-Layout在(人名和郵箱)資訊抽取的諸多問題闡述#4031
- ERNIE-Layout因為看到功能比較強大就嘗試了一下,但遇到資訊抽取錯誤,以及抽取不全等問題
- 使用PDFPlumber庫和PaddleNLP UIE模型抽取,遇到問題:無法把姓名和郵箱一一對應。
1.基於ERNIE-Layout的DocPrompt開放檔案抽取問答模型
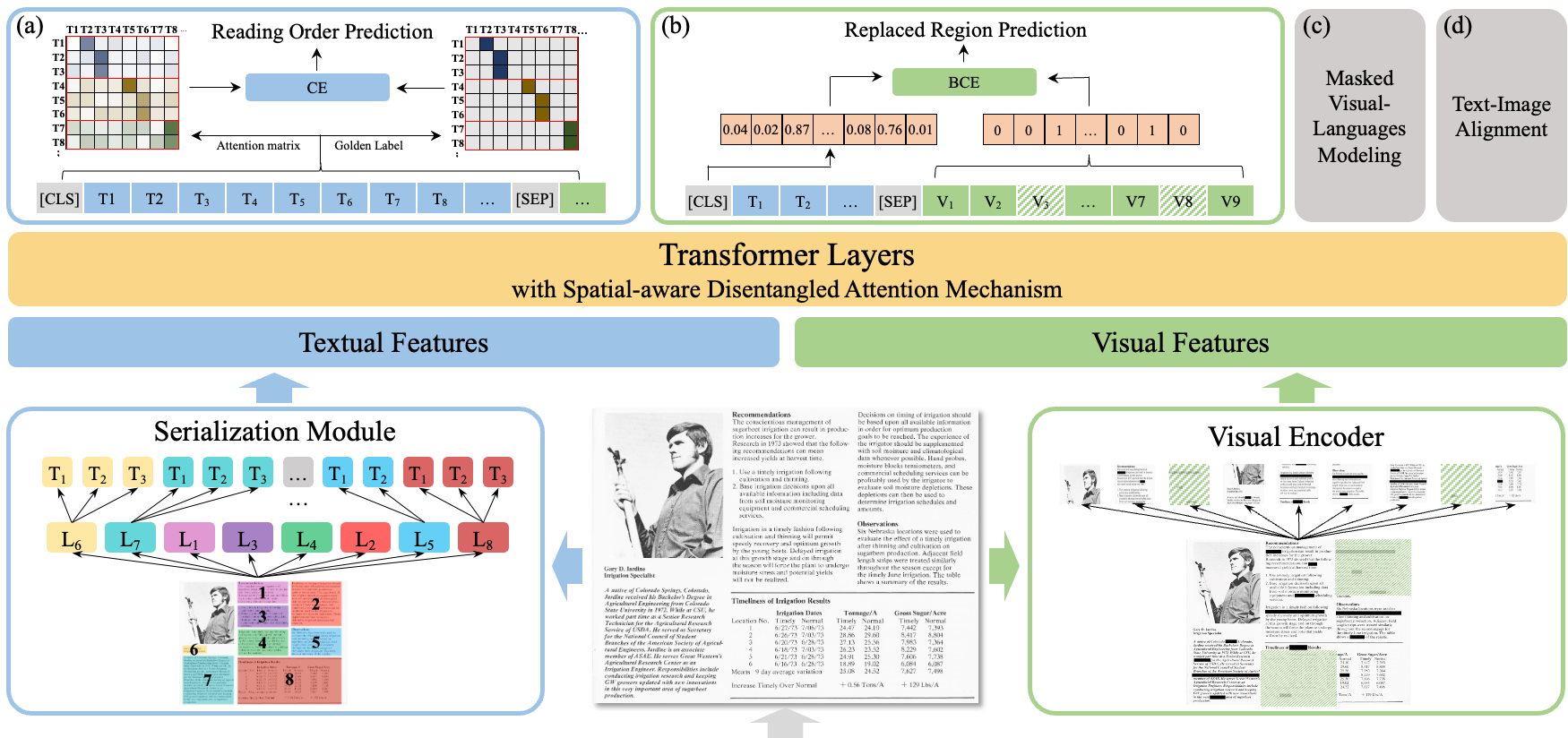
ERNIE-Layout以文心文字大模型ERNIE為底座,融合文字、影象、佈局等資訊進行跨模態聯合建模,創新性引入佈局知識增強,提出閱讀順序預測、細粒度圖文匹配等自監督預訓練任務,升級空間解偶注意力機制,在各資料集上效果取得大幅度提升,相關工作ERNIE-Layout: Layout-Knowledge Enhanced Multi-modal Pre-training for Document Understanding已被EMNLP 2022 Findings會議收錄[1]。考慮到檔案智慧在多語種上商用廣泛,依託PaddleNLP對外開源業界最強的多語言跨模態檔案預訓練模型ERNIE-Layout。
支援:
- 發票抽取問答
- 海報抽取
- 網頁抽取
- 表格抽取
- 長檔案抽取
- 多語言票據抽取
- 同時提供pipelines流水線搭建
更多參考官網,這裡就不展開了
ERNIE-Layout GitHub地址:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
Hugging Face網頁版:https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout
#環境安裝
!pip install --upgrade opencv-python
!pip install --upgrade paddlenlp
!pip install --upgrade paddleocr --user
#如果安裝失敗多試幾次 一般都是網路問題
!pip install xlwt
# 支援單條、批次預測
from paddlenlp import Taskflow
docprompt_en= Taskflow("document_intelligence",lang="en",topn=10)
docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名和郵箱" ]})
# batch_size:批次處理大小,請結合機器情況進行調整,預設為1。
# lang:選擇PaddleOCR的語言,ch可在中英混合的圖片中使用,en在英文圖片上的效果更好,預設為ch。
# topn: 如果模型識別出多個結果,將返回前n個概率值最高的結果,預設為1。
[{'prompt': '人名和郵箱',
'result': [{'value': '[email protected]@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': '[email protected]',
'prob': 0.98,
'start': 153,
'end': 159}]}]
可以看到效果不好,多個實體不能一同抽取,需要構建成單個問答,比如姓名和郵箱分開抽取,嘗試構造合理的開放式prompt。
小技巧
-
Prompt設計:在DocPrompt中,Prompt可以是陳述句(例如,檔案鍵值對中的Key),也可以是疑問句。因為是開放域的抽取問答,DocPrompt對Prompt的設計沒有特殊限制,只要符合自然語言語意即可。如果對當前的抽取結果不滿意,可以多嘗試一些不同的Prompt。
-
支援的語言:支援本地路徑或者HTTP連結的中英文圖片輸入,Prompt支援多種不同語言,參考以上不同場景的例子。
docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名是什麼","郵箱是多少", ]})
#無法羅列全部姓名
[{'prompt': '人名是什麼',
'result': [{'value': 'AA.Momtazi-Borojeni',
'prob': 0.74,
'start': 0,
'end': 4}]},
{'prompt': '郵箱是多少',
'result': [{'value': '[email protected]@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79}]}]
[{'prompt': '人名是什麼',
'result': [{'value': 'AA.Momtazi-Borojeni',
'prob': 0.74,
'start': 0,
'end': 4}]},
{'prompt': '郵箱是多少',
'result': [{'value': '[email protected]@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79}]}]
[{'prompt': '人名',
'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82},
{'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113},
{'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225},
{'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]},
{'prompt': 'email',
'result': [{'value': '[email protected]@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': '[email protected]',
'prob': 0.98,
'start': 153,
'end': 159}]}]
docprompt_en({"doc": "./image/paper_1.jpg", "prompt": ["人名","郵箱","姓名","名字","email"]})
[{'prompt': '人名',
'result': [{'value': 'J.Mosafer', 'prob': 0.95, 'start': 80, 'end': 82},
{'value': 'B.Nikfar', 'prob': 0.94, 'start': 111, 'end': 113},
{'value': 'AVaezi', 'prob': 0.94, 'start': 225, 'end': 225},
{'value': 'AA.Momtazi-Borojeni', 'prob': 0.88, 'start': 0, 'end': 4}]},
{'prompt': '郵箱',
'result': [{'value': '[email protected]@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': '[email protected]',
'prob': 0.87,
'start': 153,
'end': 159}]},
{'prompt': '姓名',
'result': [{'value': 'AA.Momtazi-Borojeni',
'prob': 0.76,
'start': 0,
'end': 4}]},
{'prompt': '名字',
'result': [{'value': 'AA.', 'prob': 0.7, 'start': 0, 'end': 1}]},
{'prompt': 'email',
'result': [{'value': '[email protected]@yahoo.com',
'prob': 1.0,
'start': 69,
'end': 79},
{'value': '[email protected]',
'prob': 0.98,
'start': 153,
'end': 159}]}]
可以看出得到的效果不是很好,比較玄學,原因應該就是ocr識別對應姓名人名準確率相對不高,無法全部命中;並且無法一一對應。
這塊建議看看paddleocr具體實現步驟,研究一下在看看怎麼處理。
下面講第二種方法
2.基於PDFplumber-UIE資訊抽取
2.1 PDF檔案解析(pdfplumber庫)
安裝PDFPlumber
!pip install pdfplumber --user
官網連結:https://github.com/jsvine/pdfplumber
pdf的文字和表格處理用多種方式可以實現, 本文介紹pdfplumber對文字和表格提取。這個庫在GitHub上stars:3.3K多,使用起來很方便, 效果也很好,可以滿足對pdf中資訊的提取需求。
pdfplumber.pdf中包含了.metadata和.pages兩個屬性。
- metadata是一個包含pdf資訊的字典。
- pages是一個包含pdfplumber.Page範例的列表,每一個範例代表pdf每一頁的資訊。
每個pdfplumber.Page類:pdfplumber核心功能,對PDF的大部分操作都是基於這個類,類中包含了幾個主要的屬性:文字、表格、尺寸等
- page_number 頁碼
- width 頁面寬度
- height 頁面高度
- objects/.chars/.lines/.rects 這些屬性中每一個都是一個列表,每個列表都包含一個字典,每個字典用於說明頁面中的物件資訊, 包括直線,字元, 方格等位置資訊。
一些常用的方法
- extract_text() 用來提頁面中的文字,將頁面的所有字元物件整理為的那個字串
- extract_words() 返回的是所有的單詞及其相關資訊
- extract_tables() 提取頁面的表格
2.1.1 pdfplumber簡單使用
# 利用metadata可以獲得PDF的基本資訊,作者,日期,來源等基本資訊。
import pdfplumber
import pandas as pd
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf:
print(pdf.metadata)
# print("總頁數:"+str(len(pdf.pages))) #總頁數
print("pdf檔案總頁數:", len(pdf.pages))
# 讀取第一頁的寬度,頁高等資訊
# 第一頁pdfplumber.Page範例
first_page = pdf.pages[0]
# 檢視頁碼
print('頁碼:', first_page.page_number)
# 檢視頁寬
print('頁寬:', first_page.width)
# 檢視頁高
print('頁高:', first_page.height)
{'CreationDate': "D:20180428190534+05'30'", 'Creator': 'Arbortext Advanced Print Publisher 9.0.223/W Unicode', 'ModDate': "D:20180428190653+05'30'", 'Producer': 'Acrobat Distiller 9.4.5 (Windows)', 'Title': '0003617532 1..23 ++', 'rgid': 'PB:324947211_AS:677565220007936@1538555545045'}
pdf檔案總頁數: 24
頁碼: 1
頁寬: 594.95996
頁高: 840.95996
# 匯入PDFPlumber
import pdfplumber
#列印第一頁資訊
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as pdf:
first_page = pdf.pages[0]
textdata=first_page.extract_text()
print(textdata)
#列印全部頁面
import pdfplumber as ppl
pdf_path = "/home/aistudio/work/input/test_paper.pdf"
pdf = ppl.open(pdf_path)
# 獲得 PDFPlumber 的物件,下面檢視pdf全部內容
for page in pdf.pages:
print(page.extract_text())
!pip install xlwt
#讀取表格第一頁
import pdfplumber
import xlwt
# 載入pdf
path = "/home/aistudio/Scan-1.pdf"
with pdfplumber.open(path) as pdf:
page_1 = pdf.pages[0] # pdf第一頁
table_1 = page_1.extract_table() # 讀取表格資料
print(table_1)
# 1.建立Excel物件
workbook = xlwt.Workbook(encoding='utf8')
# 2.新建sheet表
worksheet = workbook.add_sheet('Sheet1')
# 3.自定義列名
clo1 = table_1[0]
# 4.將列表元組clo1寫入sheet表單中的第一行
for i in range(0, len(clo1)):
worksheet.write(0, i, clo1[i])
# 5.將資料寫進sheet表單中
for i in range(0, len(table_1[1:])):
data = table_1[1:][i]
for j in range(0, len(clo1)):
worksheet.write(i + 1, j, data[j])
# 儲存Excel檔案分兩種
workbook.save('/home/aistudio/work/input/test_excel.xls')
#讀取表格全頁
import pdfplumber
from openpyxl import Workbook
class PDF(object):
def __init__(self, file_path):
self.pdf_path = file_path
# 讀取pdf檔案
try:
self.pdf_info = pdfplumber.open(self.pdf_path)
print('讀取檔案完成!')
except Exception as e:
print('讀取檔案失敗:', e)
# 列印pdf的基本資訊、返回字典,作者、建立時間、修改時間/總頁數
def get_pdf(self):
pdf_info = self.pdf_info.metadata
pdf_page = len(self.pdf_info.pages)
print('pdf共%s頁' % pdf_page)
print("pdf檔案基本資訊:\n", pdf_info)
self.close_pdf()
# 提取表格資料,並儲存到excel中
def get_table(self):
wb = Workbook() # 範例化一個工作簿物件
ws = wb.active # 獲取第一個sheet
con = 0
try:
# 獲取每一頁的表格中的文字,返回table、row、cell格式:[[[row1],[row2]]]
for page in self.pdf_info.pages:
for table in page.extract_tables():
for row in table:
# 對每個單元格的字元進行簡單清洗處理
row_list = [cell.replace('\n', ' ') if cell else '' for cell in row]
ws.append(row_list) # 寫入資料
con += 1
print('---------------分割線,第%s頁---------------' % con)
except Exception as e:
print('報錯:', e)
finally:
wb.save('\\'.join(self.pdf_path.split('\\')[:-1]) + '\pdf_excel.xlsx')
print('寫入完成!')
self.close_pdf()
# 關閉檔案
def close_pdf(self):
self.pdf_info.close()
if __name__ == "__main__":
file_path = "/home/aistudio/Scan-1.pdf"
pdf_info = PDF(file_path)
# pdf_info.get_pdf() # 列印pdf基礎資訊
# 提取pdf表格資料並儲存到excel中,檔案儲存到跟pdf同一檔案路徑下
pdf_info.get_table()
更多功能(表格讀取,圖片提取,視覺化介面)可以參考官網或者下面連結:
https://blog.csdn.net/fuhanghang/article/details/122579548
2.1.2 學術論文特定頁面文字提取
發表論文作者資訊通常放在論文首頁的腳末行或參考文獻的後面,根據這種情況我們可以進行分類(只要獲取作者的郵箱資訊即可):
- 第一種國外論文:首頁含作者相關資訊 or 首頁是封面第二頁才是作者資訊 【獲取前n頁即可,推薦是2頁】
- 第二種國內論文:首頁含作者資訊(郵箱等)在參考文獻之後會有各個做的詳細資訊,比如是職位,研究領域,科研成果介紹等等 【獲取前n頁和尾頁,推薦是2頁+尾頁】
這樣做的好處在於兩個方面:
- 節約了儲存空間和資料處理時間
- 節約資源消耗,在模型預測時候輸入文字數量顯著減少,在資料面上加速推理
針對1簡單闡述:PDF原始大小614.1KB
| 處理方式 | pdf轉文字時延 | 儲存佔用空間 |
|---|---|---|
| 儲存指定前n頁面文字 | 242ms | 2.8KB |
| 儲存指定前n頁面文字和尾頁 | 328ms | 5.3KB |
| 儲存全文 | 2.704s | 64.1KB |
針對二:以下6中方案提速不過多贅述,可以參考下面專案
- 模型選擇 uie-mini等小模型預測,損失一定精度提升預測效率
- UIE實現了FastTokenizer進行文字預處理加速
- fp16半精度推理速度更快
- UIE INT8 精度推理
- UIE Slim 資料蒸餾
- SimpleServing支援支援多卡負載均衡預測
UIE Slim滿足工業應用場景,解決推理部署耗時問題,提升效能!:https://aistudio.baidu.com/aistudio/projectdetail/4516470?contributionType=1
之後有時間重新把paddlenlp技術路線整理一下
#第一種寫法:儲存指定前n頁面文字
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p:
for i in range(3):
page = p.pages[i]
textdata = page.extract_text()
# print(textdata)
data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定寫入模式為追加寫入
data.write(textdata)
#這裡列印出n頁文字,因為是追加儲存內容是n-1頁
#第一種寫法:儲存指定前n頁面文字
with pdfplumber.open("/home/aistudio/work/input/test_paper.pdf") as p:
for i in range(3):
page = p.pages[i]
textdata = page.extract_text()
# print(textdata)
data = open('/home/aistudio/work/input/text.txt',"a") #a表示指定寫入模式為追加寫入
data.write(textdata)
#這裡列印出n頁文字,因為是追加儲存內容是n-1頁
#儲存指定前n頁面文字和尾頁
pdf_path = "/home/aistudio/work/input/test_paper.pdf"
pdf = ppl.open(pdf_path)
texts = []
# 按頁開啟,合併所有內容,保留前2頁
for i in range(2):
text = pdf.pages[i].extract_text()
texts.append(text)
#保留最後一頁,index從0開始
end_num=len(pdf.pages)
text_end=pdf.pages[end_num-1].extract_text()
texts.append(text_end)
txt_string = ''.join(texts)
# 儲存為和原PDF同名的txt檔案
txt_path = pdf_path.split('.')[0]+"_end" + '.txt'
with open(txt_path, "w", encoding='utf-8') as f:
f.write(txt_string)
f.close()
#保留全部文章:
pdf_path = "/home/aistudio/work/input/test_paper.pdf"
pdf = ppl.open(pdf_path)
texts = []
# 按頁開啟,合併所有內容,對於多頁或一頁PDF都可以使用
for page in pdf.pages:
text = page.extract_text()
texts.append(text)
txt_string = ''.join(texts)
# 儲存為和原PDF同名的txt檔案
txt_path = pdf_path.split('.')[0] +"_all"+'.txt'
with open(txt_path, "w", encoding='utf-8') as f:
f.write(txt_string)
f.close()
#從txt中讀取文字,作為資訊抽取的輸入。對於比較長的文字,可能需要人工的設定一些分割關鍵詞,分段輸入以提升抽取的效果。
txt_path="/home/aistudio/work/input/test_paper2.txt"
with open(txt_path, 'r') as f:
file_data = f.readlines()
record = ''
for data in file_data:
record += data
print(record)
2.2 UIE資訊抽取(論文作者和郵箱)
2.2.1 零樣本抽取
from pprint import pprint
import json
from paddlenlp import Taskflow
def openreadtxt(file_name):
data = []
file = open(file_name,'r',encoding='UTF-8') #開啟檔案
file_data = file.readlines() #讀取所有行
for row in file_data:
data.append(row) #將每行資料插入data中
return data
data_input=openreadtxt('/home/aistudio/work/input/test_paper2.txt')
schema = ['人名', 'email']
few_ie = Taskflow('information_extraction', schema=schema, batch_size=16)
results=few_ie(data_input)
print(results)
with open("./output/reslut_2.txt", "w+",encoding='UTF-8') as f: #a : 寫入檔案,若檔案不存在則會先建立再寫入,但不會覆蓋原檔案,而是追加在檔案末尾
for result in results:
line = json.dumps(result, ensure_ascii=False) #對中文預設使用的ascii編碼.想輸出真正的中文需要指定ensure_ascii=False
f.write(line + "\n")
print("資料結果已匯出")
2.3長文字的答案獲取
UIE對於詞和句子的抽取效果比較好,但是對應大段的文字結果,還是需要傳統的正則方式作為配合,在本次使用的pdf中,還需要獲得法院具體的判決結果,使用正規表示式可靈活匹配想要的結果。
start_word = '如下'
end_word = '特此公告'
start = re.search(start_word, record)
end = re.search(end_word, record)
print(record[start.span()[1]:end.span()[0]])
:
海口中院認為:新達公司的住所地在海口市國貿大道 48
號新達商務大廈,該司是由海南省工商行政管理局核准登記
的企業,故海口中院對本案有管轄權。因新達公司不能清償
到期債務,故深物業股份公司提出對新達公司進行破產清算
1
的申請符合受理條件。依照《中華人民共和國企業破產法》
第二條第一款、第三條、第七條第二款之規定,裁定如下:
受理申請人深圳市物業發展(集團)股份有限公司對被
申請人海南新達開發總公司破產清算的申請。
本裁定自即日起生效。
二、其他情況
本公司已對海南公司賬務進行了全額計提,破產清算對
本公司財務狀況無影響。
具體情況請查閱本公司2011年11月28日釋出的《董事會
決議公告》。
2.4正則提升效果
對於長文字,可以根據關鍵詞進行分割後抽取,但是對於多個實體,比如這篇公告中,通過的多個議案,就無法使用UIE抽取。
# 匯入正規表示式相關庫
import re
schema = ['通過議案']
start_word = '通過以下議案'
start = re.search(start_word, record)
input_data = record[start.span()[0]:]
print(input_data)
ie = Taskflow('information_extraction', schema=schema)
pprint(ie(input_data))
# 正則匹配「一 二 三 四 五 六 七 八 九 十」
print(re.findall(r"[\u4e00\u4e8c\u4e09\u56db\u4e94\u516d\u4e03\u516b\u4e5d\u5341]、.*\n", input_data))
['一、2021 年第三季度報告 \n', '二、關於同意全資子公司收購擔保公司 60%股權的議案 詳見公司於 2021 年 10 月 29 日刊登在《證券時報》、《中國證券\n', '三、關於同意控股子公司廣西新柳邕公司為認購廣西新柳邕項\n', '四、關於續聘會計師事務所的議案 \n', '五、關於向銀行申請綜合授信額度的議案 \n', '一、向中國民生銀行股份有限公司深圳分行申請不超過人民幣 5\n', '二、向招商銀行股份有限公司深圳分行申請不超過人民幣 6 億\n', '六、經理層《崗位聘任協定》 \n', '七、經理層《年度經營業績責任書》 \n', '八、經理層《任期經營業績責任書》 \n', '九、關於暫不召開股東大會的議案 \n']
# 3.基於基於UIE-X的資訊提取
## 3.1 跨模態檔案資訊抽取
跨模態檔案資訊抽取能力 UIE-X 來了。 資訊抽取簡單說就是利用計算機從自然語言文字中提取出核心資訊,是自然語言處理領域的一項關鍵任務,包括命名實體識別(也稱實體抽取)、關係抽取、事件抽取等。傳統資訊抽取方案基於序列標註,需要大量標註語料才能獲得較好的效果。2022年5月飛槳 PaddleNLP 推出的 UIE,是業界首個開源的面向通用資訊抽取的產業級技術方案 ,基於 Prompt 思想,零樣本和小樣本能力強大,已經成為業界資訊抽取任務上的首選方案。
除了純文字內容外,企業中還存在大量需要從跨模態檔案中抽取資訊並進行處理的業務場景,例如從合同、收據、報銷單、病歷等不同型別的檔案中抽取所需欄位,進行錄入、比對、稽核校準等操作。為了滿足各行業的跨模態檔案資訊抽取需求,PaddleNLP 基於文心ERNIE-Layout[1]跨模態佈局增強預訓練模型,整合PaddleOCR的PP-OCR、PP-Structure版面分析等領先能力,基於大量資訊抽取標註集,訓練並開源了UIE-X–––首個兼具文字及檔案抽取能力、多語言、開放域的資訊抽取模型。
* 支援實體抽取、關係抽取、跨任務抽取
* 支援跨語言抽取
* 整合PP-OCR,可靈活客製化OCR結果
* 使用PP-Structure版面分析功能
* 增加渲染模組,OCR和資訊抽取結果視覺化
專案連結:
[https://aistudio.baidu.com/aistudio/projectdetail/5017442](https://aistudio.baidu.com/aistudio/projectdetail/5017442)
## 3.2 產業實踐分享:基於UIE-X的醫療檔案資訊提取
PaddleNLP全新發布UIE-X