Pytorch建模過程中的DataLoader與Dataset
處理資料樣本的程式碼會因為處理過程繁雜而變得混亂且難以維護,在理想情況下,我們希望資料預處理過程程式碼與我們的模型訓練程式碼分離,以獲得更好的可讀性和模組化,為此,PyTorch提供了torch.utils.data.DataLoader 和 torch.utils.data.Dataset兩個類用於資料處理。其中torch.utils.data.DataLoader用於將資料集進行打包封裝成一個可迭代物件,torch.utils.data.Dataset儲存有一些常用的資料集範例以及相關標籤。
同時PyTorch針對不同的專業領域,也提供有不同的模組,例如 TorchText(自然語言處理), TorchVision(計算機視覺), TorchAudio(音訊),這些模組中也都包含一些真實資料集範例。例如TorchVision模組中提供了CIFAR, COCO, FashionMNIST 資料集。
1 定義資料集¶
pytorch中提供兩種風格的資料集定義方式:
- 字典對映風格。之所以稱為對映風格,是因為在後續載入資料迭代時,pytorch將自動使用迭代索引作為key,通過字典索引的方式獲取value,本質就是將資料集定義為一個字典,使用這種風格時,需要繼承
Dataset類。
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
dataset = {0: '張三', 1:'李四', 2:'王五', 3:'趙六', 4:'陳七'}
dataloader = DataLoader(dataset, batch_size=2)
for i, value in enumerate(dataloader):
print(i, value)
0 ['張三', '李四'] 1 ['王五', '趙六'] 2 ['陳七']
- 迭代器風格。在自定義資料集類中,實現
__iter__和__next__方法,即定義為迭代器,在後續載入資料迭代時,pytorch將依次獲取value,使用這種風格時,需要繼承IterableDataset類。這種方法在資料量巨大,無法一下全部載入到記憶體時非常實用。
from torch.utils.data import DataLoader
from torch.utils.data import IterableDataset
dataset = [i for i in range(10)]
dataloader = DataLoader(dataset=dataset, batch_size=3, shuffle=True)
for i, item in enumerate(dataloader): # 迭代輸出
print(i, item)
0 tensor([3, 1, 2]) 1 tensor([9, 7, 5]) 2 tensor([0, 8, 4]) 3 tensor([6])
如下所示,我們有一個螞蟻蜜蜂影象分類資料集,目錄結構如下所示,下面我們結合這個資料集,分別介紹如何使用這兩個類定義真實資料集。
data
└── hymenoptera_data
├── train
│ ├── ants
│ │ ├── 0013035.jpg
│ │ ……
│ └── bees
│ ├── 1092977343_cb42b38d62.jpg
│ ……
└── val
├── ants
│ ├── 10308379_1b6c72e180.jpg
│ ……
└── bees
├── 1032546534_06907fe3b3.jpg
……1.2 Dataset類¶
自定義一個Dataset類,繼承torch.utils.data.Dataset,且必須實現下面三個方法:
-
Dataset類裡面的
__init__函數初始化一些引數,如讀取外部資料來源檔案。 -
Dataset類裡面的
__getitem__函數,對映取值是呼叫的方法,獲取單個的資料,訓練迭代時將會呼叫這個方法。 -
Dataset類裡面的
__len__函數獲取資料的總量。
import os
import pandas as pd
from PIL import Image
from torchvision.transforms import ToTensor, Lambda
from torchvision import transforms
import torchvision
class AntBeeDataset(Dataset):
# 把圖片所在的資料夾路徑分成兩個部分,一部分是根目錄,一部分是標籤目錄,這是因為標籤目錄的名稱我們需要用到
def __init__(self, root_dir, transform=None, target_transform=None):
"""
root_dir:存放資料的根目錄,即:data/hymenoptera_data
transform: 對影象資料進行處理,例如,將圖片轉換為Tensor、圖片的維度可能不一致需要進行resize
target_transform:對標籤資料進行處理,例如,將文字標籤轉換為數值
"""
self.root_dir = root_dir
self.transform = transform
self.target_transform = target_transform
# 獲取資料夾下所有圖片的名稱和對應的標籤
self.img_lst = []
for label in ['ants', 'bees']:
path = os.path.join(root_dir, label)
for img_name in os.listdir(path):
self.img_lst.append((os.path.join(root_dir, label, img_name), label))
def __getitem__(self, idx):
img_path, label = self.img_lst[idx]
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
# 這個地方要注意,我們在計算loss的時候用交叉熵nn.CrossEntropyLoss()
# 交叉熵的輸入有兩個,一個是模型的輸出outputs,一個是標籤targets,注意targets是一維tensor
# 例如batchsize如果是2,ants的targets的應該[0,0],而不是[[0][0]]
# 因此label要返回0,而不是[0]
return img, label
def __len__(self):
return len(self.img_lst)
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224), # 將給定影象隨機裁剪為不同的大小和寬高比,然後縮放所裁剪得到的影象為制定的大小
transforms.RandomHorizontalFlip(), # 以給定的概率隨機水平旋轉給定的PIL的影象,預設為0.5
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 驗證集並不需要做與訓練集相同的處理,所有,通常使用更加簡單的transformer
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 根據標籤目錄的名稱來確定圖片是哪一類,如果是"ants",標籤設定為0,如果是"bees",標籤設定為1
target_transform = transforms.Lambda(lambda y: 0 if y == "ants" else 1)
train_dataset = AntBeeDataset('data/hymenoptera_data/train', transform=train_transform, target_transform=target_transform)
val_dataset = AntBeeDataset('data/hymenoptera_data/val', transform=val_transform, target_transform=target_transform)
1.2 Dataset資料集常用操作¶
1. 檢視資料集大小:¶
len(train_dataset), len(val_dataset)
(245, 153)
2. 合併資料集¶
dataset = train_dataset + val_dataset
len(dataset)
398
3. 劃分訓練集、測試集¶
from torch.utils.data import random_split
# random_split 不能直接使用百分比劃分,必須指定具體數位
train_size = int( len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, test_size])
len(train_dataset), len(val_dataset)
(318, 80)
1.3 IterableDataset類¶
使用迭代器風格時,必須繼承IterableDataset類,且實現下面兩個方法:
-
__init__,函數初始化一些引數,如讀取外部資料來源檔案,在資料量過大時,通常只是獲取操作控制程式碼、資料庫連線。 -
__iter__,獲取迭代器。
雖然只需要實現這兩個方法,但是通常還需要在迭代過程中對資料進行處理。IterableDataset類實現自定義資料集,本質就是建立一個資料集類,且實現__iter__返回一個迭代器。一下提供兩種方法通過IterableDataset類自定義資料集:
方法一:¶
class AntBeeIterableDataset(IterableDataset):
# 把圖片所在的資料夾路徑分成兩個部分,一部分是根目錄,一部分是標籤目錄,這是因為標籤目錄的名稱我們需要用到
def __init__(self, root_dir, transform=None, target_transform=None):
"""
root_dir:存放資料的根目錄,即:data/hymenoptera_data
transform: 對影象資料進行處理,例如,將圖片轉換為Tensor、圖片的維度可能不一致需要進行resize
target_transform:對標籤資料進行處理,例如,將文字標籤轉換為數值
"""
self.root_dir = root_dir
self.transform = transform
self.target_transform = target_transform
# 獲取資料夾下所有圖片的名稱和對應的標籤
self.img_lst = []
for label in ['ants', 'bees']:
path = os.path.join(root_dir, label)
for img_name in os.listdir(path):
self.img_lst.append((os.path.join(root_dir, label, img_name), label))
def __iter__(self):
for img_path, label in self.img_lst:
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
yield img, label
方法二:¶
class AntBeeIterableDataset(IterableDataset):
# 把圖片所在的資料夾路徑分成兩個部分,一部分是根目錄,一部分是標籤目錄,這是因為標籤目錄的名稱我們需要用到
def __init__(self, root_dir, transform=None, target_transform=None):
"""
root_dir:存放資料的根目錄,即:data/hymenoptera_data
transform: 對影象資料進行處理,例如,將圖片轉換為Tensor、圖片的維度可能不一致需要進行resize
target_transform:對標籤資料進行處理,例如,將文字標籤轉換為數值
"""
self.root_dir = root_dir
self.transform = transform
self.target_transform = target_transform
# 獲取資料夾下所有圖片的名稱和對應的標籤
self.img_lst = []
for label in ['ants', 'bees']:
path = os.path.join(root_dir, label)
for img_name in os.listdir(path):
self.img_lst.append((os.path.join(root_dir, label, img_name), label))
self.index = 0
def __iter__(self):
return self
def __next__(self):
try:
img_path, label = self.img_lst[self.index]
self.index += 1
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
return img, label
except IndexError:
raise StopIteration()
train_dataset = AntBeeIterableDataset('data/hymenoptera_data/train', transform=train_transform, target_transform=target_transform)
val_dataset = AntBeeIterableDataset('data/hymenoptera_data/val', transform=val_transform, target_transform=target_transform)
在處理巨量資料集時,IterableDataset會比Dataset更有優勢,例如資料儲存在檔案或者資料庫中,只需要在自定義的IterableDataset之類中獲取檔案操作控制程式碼或者資料庫連線和遊標驚喜迭代,每次只返回一條資料即可。我們把上文中螞蟻蜜蜂資料集的所有圖片、標籤這裡後寫入hymenoptera_data.txt中,內容如下所示,假設有數億行,那麼,就不能直接將資料載入到記憶體了:
data/hymenoptera_data/train/ants/2288481644_83ff7e4572.jpg, ants
data/hymenoptera_data/train/ants/2278278459_6b99605e50.jpg, ants
data/hymenoptera_data/train/ants/543417860_b14237f569.jpg, ants
...
...可以參考一下方式定義IterableDataset子類:
class AntBeeIterableDataset(IterableDataset):
# 把圖片所在的資料夾路徑分成兩個部分,一部分是根目錄,一部分是標籤目錄,這是因為標籤目錄的名稱我們需要用到
def __init__(self, filepath, transform=None, target_transform=None):
"""
filepath:hymenoptera_data.txt完整路徑
transform: 對影象資料進行處理,例如,將圖片轉換為Tensor、圖片的維度可能不一致需要進行resize
target_transform:對標籤資料進行處理,例如,將文字標籤轉換為數值
"""
self.filepath = filepath
self.transform = transform
self.target_transform = target_transform
def __iter__(self):
with open(self.filepath, 'r') as f:
for line in f:
img_path, label = line.replace('\n', '').split(', ')
img = Image.open(img_path).convert('RGB')
if self.transform:
img = self.transform(img)
if self.target_transform:
label = self.target_transform(label)
yield img, label
train_dataset = AntBeeIterableDataset('hymenoptera_data.txt', transform=train_transform, target_transform=target_transform)
注意,IterableDataset方法在處理巨量資料集時確實比Dataset更有優勢,但是,IterableDataset在迭代過程中,樣本輸出順序是固定的,在使用DataLoader進行載入時,無法使用shuffle進行打亂,同時,因為在IterableDataset中並未強制限定必須實現__len__()方法(很多時候確實也沒法獲取資料總量),不能通過len()方法獲取資料總量。
2 DataLoad¶
DataLoader的功能是構建可迭代的資料裝載器,在訓練的時候,每一個for迴圈,每一次Iteration,就是從DataLoader中獲取一個batch_size大小的資料,節省記憶體的同時,它還可以實現多程序、資料打亂等處理。我們通過一張圖來了解DataLoader資料讀取機制:
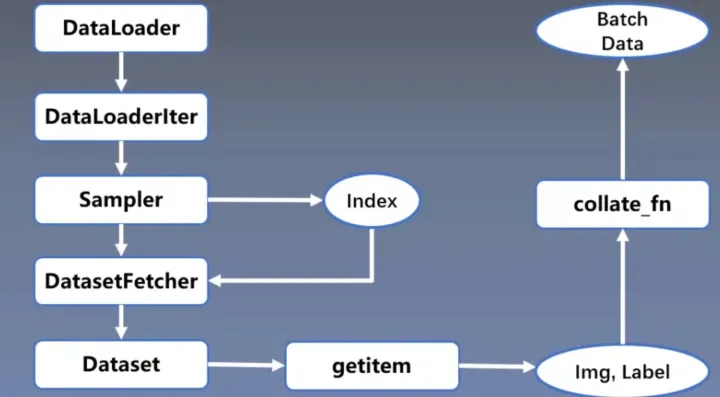
首先,在for迴圈中使用了DataLoader,進入DataLoader後,首先根據是否使用多程序DataLoaderIter,做出判斷之後單執行緒還是多執行緒,接著使用Sampler得索引Index,然後將索引給到DatasetFetcher,在這裡面呼叫Dataset,根據索引,通過getitem得到實際的資料和標籤,得到一個batch size大小的資料後,通過collate_fn函數整理成一個Batch Data的形式輸入到模型去訓練。
在pytorch建模的資料處理、載入流程中,DataLoader應該算是最核心的一步操作DataLoader有很多引數,這裡我們列出常用的幾個:
- dataset:表示Dataset類,它決定了資料從哪讀取以及如何讀取;
- batch_size:表示批大小;
- num_works:表示是否多程序讀取資料;
- shuffle:表示每個epoch是否亂序;
- drop_last:表示當樣本數不能被batch_size整除時,是否捨棄最後一批資料;
- num_workers:啟動多少個程序來載入資料。
我們重點說說多程序模式下使用DataLoader,在多程序模式下,每次 DataLoader 建立 iterator 時(遍歷DataLoader時,例如,當呼叫時enumerate(dataloader)),都會建立 num_workers 工作程序。dataset, collate_fn, worker_init_fn 都會被傳到每個worker中,每個worker都用獨立的程序。
對於對映風格的資料集,即Dataset子類,主執行緒會用Sampler(取樣器)產生indice,並將它們送到程序裡。因此,shuffle是在主執行緒做的
對於迭代器風格的資料集,即IterableDataset子類,因為每個程序都有相同的data複製樣本,並在各個程序裡進行不同的操作,以防止每個程序輸出的資料是重複的,所以一般用 torch.utils.data.get_worker_info() 來進行輔助處理。
這裡,torch.utils.data.get_worker_info() 返回worker程序的一些資訊(id, dataset, num_workers, seed),如果在主執行緒跑的話返回None
注意,通常不建議在多程序載入中返回CUDA張量,因為在使用CUDA和在多處理中共用CUDA張量時存在許多微妙之處(檔案中提出:只要接收過程保留張量的副本,就需要傳送過程來保留原始張量)。建議採用 pin_memory=True ,以將資料快速傳輸到支援CUDA的GPU。簡而言之,不建議在使用多執行緒的情況下返回CUDA的tensor。
dataload = DataLoader(train_dataset, batch_size=2)
img, label = next(iter(dataload))
img.shape, label
(torch.Size([2, 3, 224, 224]), tensor([0, 0]))

作者:奧辰
微訊號:chb1137796095
Github:https://github.com/ChenHuabin321
歡迎加V交流,共同學習,共同進步!
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連結,否則保留追究法律責任的權利。