經典 backbone 總結
目錄
VGG
VGG網路結構參數列如下圖所示。

ResNet
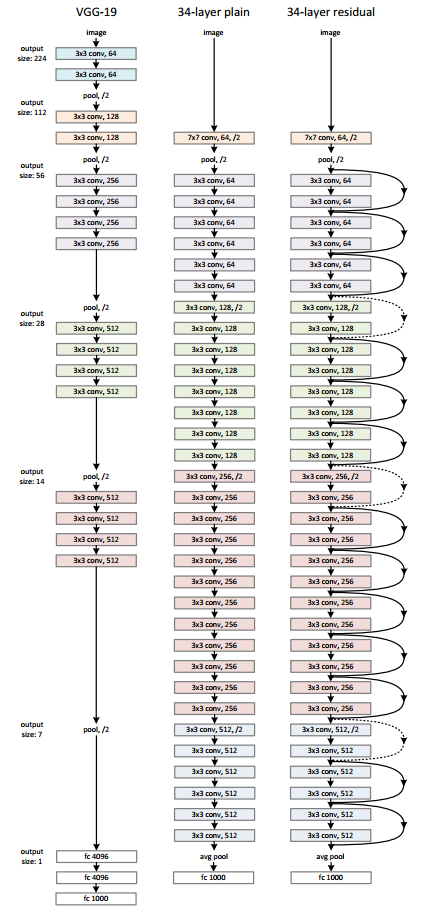
ResNet 模型比 VGG 網路具有更少的濾波器數量和更低的複雜性。 比如 Resnet34 的 FLOPs 為 3.6G,僅為 VGG-19 19.6G 的 18%。
注意,論文中算的
FLOPs,把乘加當作1次計算。
ResNet 和 VGG 的網路結構連線對比圖,如下圖所示。
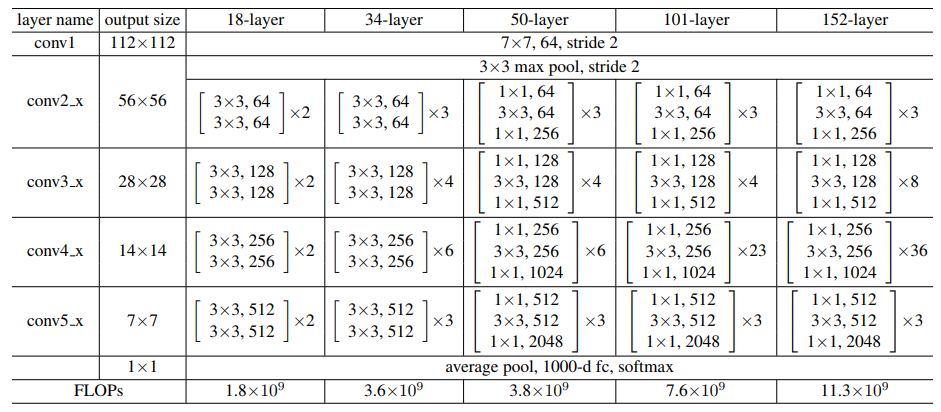
不同層數的 Resnet 網路參數列如下圖所示。
看了後續的
ResNeXt、ResNetv2、Densenet、CSPNet、VOVNet等論文,越發覺得ResNet真的算是Backone領域劃時代的工作了,因為它讓深層神經網路可以訓練,基本解決了深層神經網路訓練過程中的梯度消失問題,並給出了系統性的解決方案(兩種殘差結構),即系統性的讓網路變得更「深」了。而讓網路變得更「寬」的工作,至今也沒有一個公認的最佳方案(Inception、ResNeXt等後續沒有廣泛應用),難道是因為網路變得「寬」不如「深」更重要,亦或是我們還沒有找到一個更有效的方案。
Inceptionv3
常見的一種 Inception Modules 結構如下:
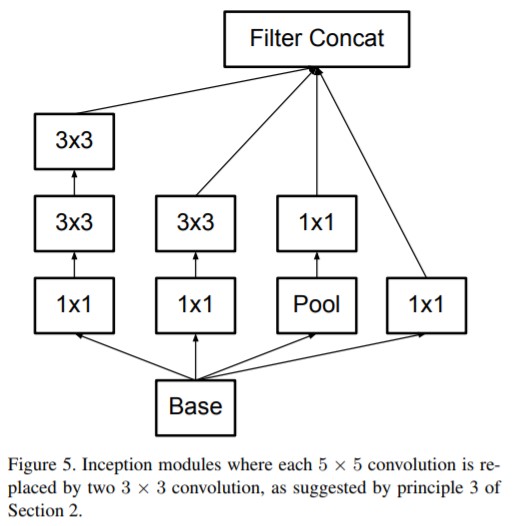
Resnetv2
作者總結出恆等對映形式的快捷連線和預啟用對於訊號在網路中的順暢傳播至關重要的結論。
ResNeXt
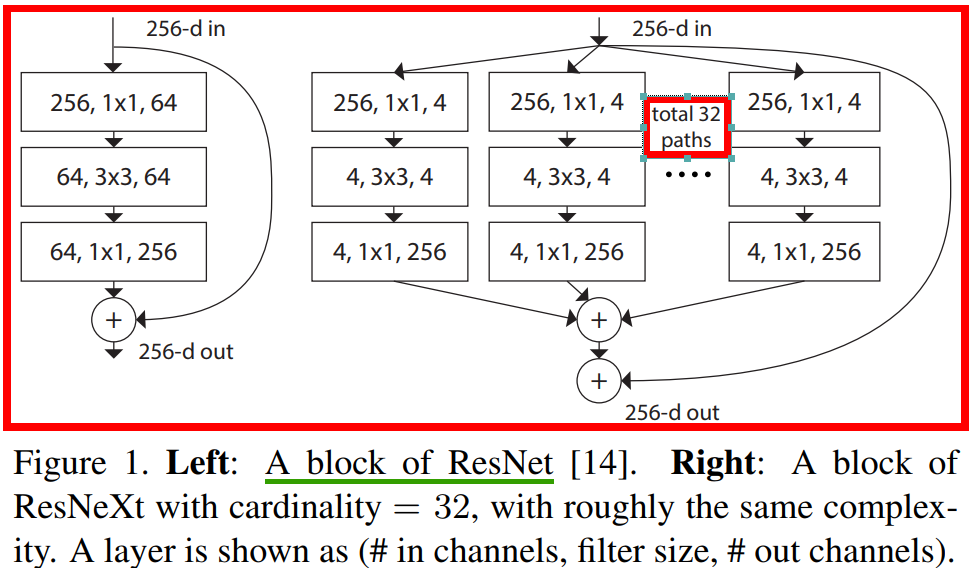
ResNeXt 的折積block 和 Resnet 對比圖如下所示。
ResNeXt 和 Resnet 的模型結構引數對比圖如下圖所示。

Darknet53
Darknet53 模型結構連線圖,如下圖所示。

DenseNet
作者
Gao Huang於2018年發表的論文Densely Connected Convolutional Networks。
在密集塊(DenseBlock)結構中,每一層都會將前面所有層 concate 後作為輸入。DenseBlock(類似於殘差塊的密集塊結構)結構的 3 畫法圖如下所示:
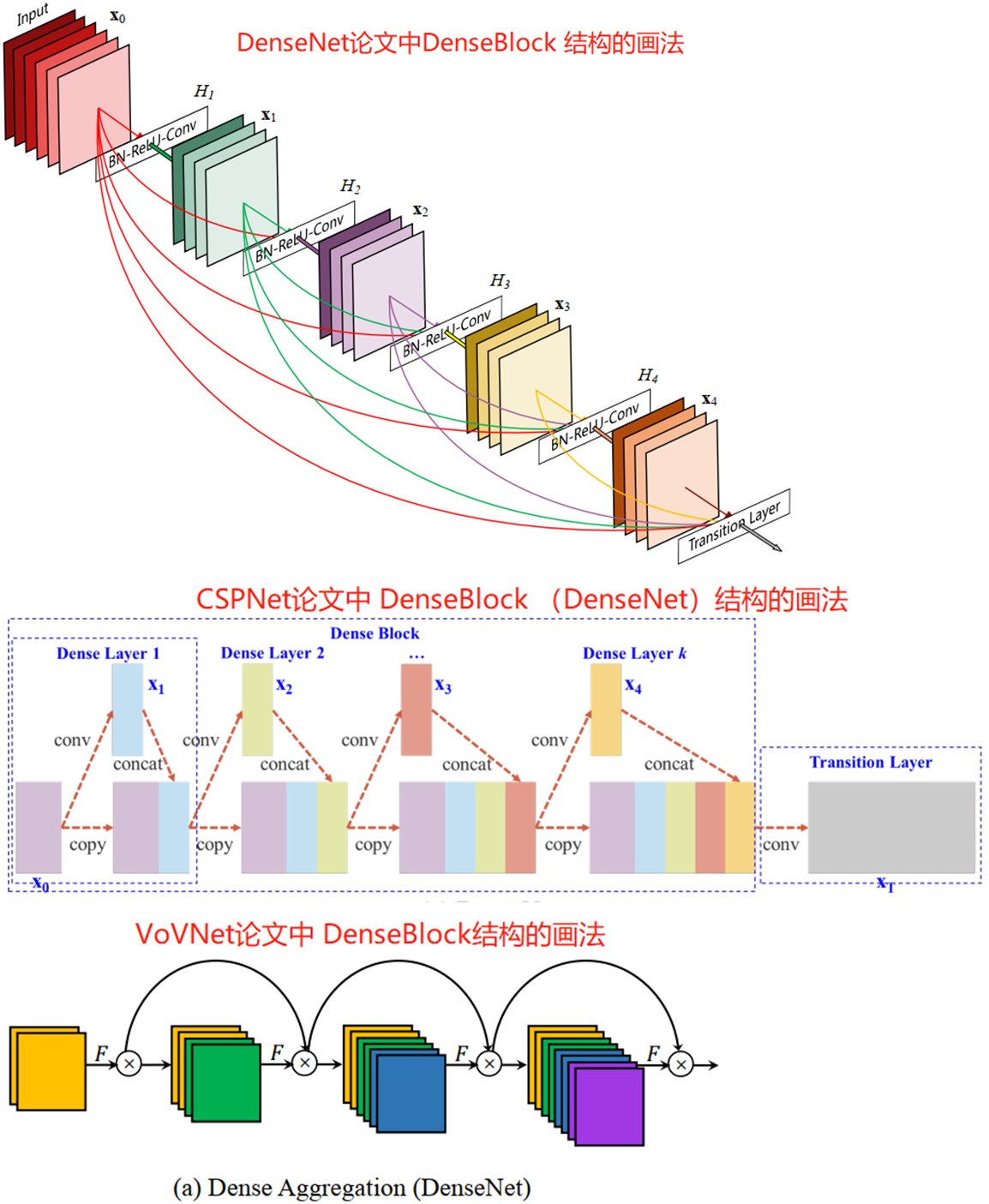
可以看出 DenseNet 論文更側重的是 DenseBlock 內各個折積層之間的密集連線(dense connection)關係,另外兩個則是強調每層的輸入是前面所有層 feature map 的疊加,反映了 feature map 數量的變化。
CSPNet
CSPDenseNet 的一個階段是由區域性密集塊和區域性過渡層組成(a partial dense block and a partial transition layer)。
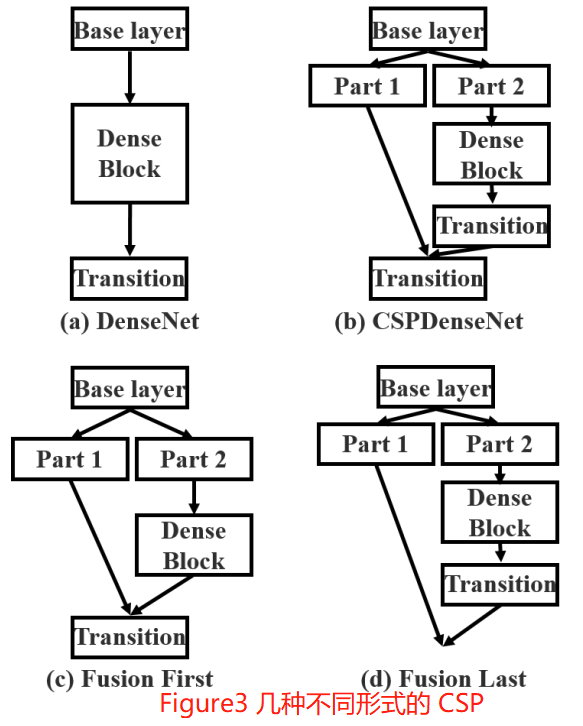
CSP 方法可以減少模型計算量和提高執行速度的同時,還不降低模型的精度,是一種更高效的網路設計方法,同時還能和 Resnet、Densenet、Darknet 等 backbone 結合在一起。
VoVNet
One-Shot Aggregation(只聚集一次)是指 OSA 模組的 concat 操作只進行一次,即只有最後一層(\(1\times 1\) 折積)的輸入是前面所有層 feature map 的 concat(疊加)。OSA 模組的結構圖如圖 1(b) 所示。

在 OSA module 中,每一層產生兩種連線,一種是通過 conv 和下一層連線,產生 receptive field 更大的 feature map,另一種是和最後的輸出層相連,以聚合足夠好的特徵。通過使用 OSA module,5 層 43 channels 的 DenseNet-40 的 MAC 可以被減少 30%(3.7M -> 2.5M)。
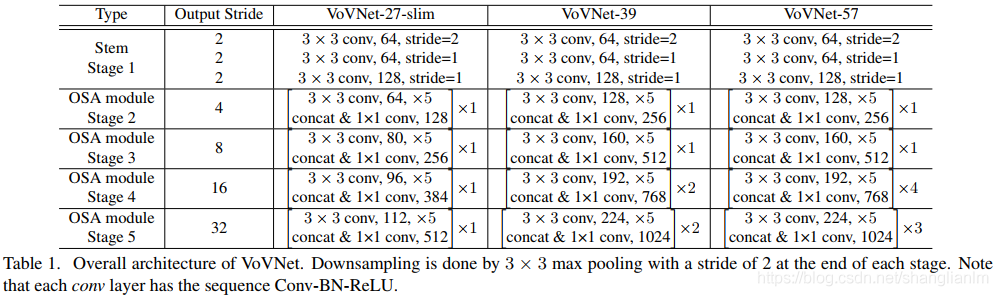
基於 OSA 模組構建的各種 VoVNet 結構參數列如下。
作者認為 DenseNet 用更少的引數與 Flops 而效能卻比 ResNet 更好,主要是因為concat 比 add 能保留更多的資訊。但是,實際上 DenseNet 卻比 ResNet要慢且消耗更多資源。
GPU 的計算效率:
GPU特性是擅長parallel computation,tensor越大,GPU使用效率越高。- 把大的折積操作拆分成碎片的小操作將不利於
GPU計算。 - 設計
layer數量少的網路是更好的選擇。 - 1x1 折積可以減少計算量,但不利於 GPU 計算。
在 CenterMask 論文提出了 VoVNetv2,其折積模組結構圖如下:

一些結論
- 當折積層的輸入輸出通道數相等時,記憶體存取代價(
MAC)最小。 - 影響 CNN 功耗的主要因素在於記憶體存取代價 MAC,而不是計算量 FLOPs。
- GPU 擅長平行計算,Tensor 越大,GPU 使用效率越高,把大的折積操作拆分成碎片的小操作不利於 GPU 計算。
- 1x1 折積可以減少計算量,但不利於 GPU 計算。
參考資料
VGG/ResNet/Inception/ResNeXt/CSPNet論文- 深度學習論文: An Energy and GPU-Computation Efficient Backbone Network for Object Detection及其PyTorch